
基于Storm的自适应弹性资源分配策略组件实现
2023-04-29 05:56李丽娜刘世龙马钰博靳德政李念峰
吉林大学学报(理学版) 2023年2期
关键词:资源分配
李丽娜 刘世龙 马钰博 靳德政 李念峰
摘要: 针对Storm平台的静态资源分配问题,提出一种分布式自适应弹性资源分配策略,能最优满足应用的资源需求. 基于该策略,结合Storm的资源分配机制、 应用编程接口和用户界面的参数,实现了一个面向Storm的弹性资源分配组件,支持应用资源的自适应动态调整. 实验结果表明,在真实的流数据集上,分布式最优策略与中值式动态资源分配策略和Storm的静态资源分配策略相比,在吞吐量、 丢失率和资源利用率上均有优势. 同时,该自适應弹性资源分配组件能很好地与Storm系统交互,为其他弹性资源调度组件开发提供了可借鉴的解决方案.
关键词: 流数据处理; 资源分配; 弹性调度; 组件实现
中图分类号: TP391 文献标志码: A 文章编号: 1671-5489(2023)02-0384-09
Component Implementation of Adaptive ElasticResource Allocation Strategy Based on Storm
LI Lina1,LIU Shilong1,MA Yubo1,JIN Dezheng2,LI Nianfeng1
(1. College of Computer Science and Technology,Changchun University,Changchun 130022,China;
2. College of Cyber Security,Changchun University,Changchun 130022,China)
收稿日期: 2021-11-22.
第一作者简介: 李丽娜(1978—),女,汉族,博士,副教授,从事分布式系统和深度学习的研究,E-mail: liln@ccu.edu.cn. 通信作者简介:
李念峰(1974—),男,汉族,博士,教授,博士生导师,从事分布式系统和区块链的研究,E-mail: linf@ccu.edu.cn.
基金项目: 吉林省自然科学基金(批准号: YDZJ202101ZYTS191)、 吉林省科技厅重点研发项目(批准
号: 20210201083GX)和教育部产学研创新项目(批准号: 2020HYB03002; 2021ALA03004).
Abstract: Aiming at the problem of static resource allocation of the Storm platform,we proposed a distributed adaptive elastic resource allocation strategy,
which could optimally meet the resource requirements of applications. Based on this strategy,combined with the resource allocation mechanism,application prog
ramming interface and user interface parameters of Storm,an elastic resource allocation component deployed in Storm was implemented to support adaptive and dyna
mic adjustment of application resources. The experimental results show that on the real stream data set,compared with the middle-value dynamic resource alloca
tion strategy and the static resource allocation strategy of Storm,this distributed optimal strategy has advantages in throughput,loss rate and resource utiliz
ation. Meanwhile,this adaptive elastic resource allocation component can well interact with the Storm system,providing a reference solution for the development of other elastic resource scheduling components.
Keywords: stream data processing; resource allocation; elastic scheduling; component implementation
Storm[1]是一个开源、 扩展性良好且容错能力强的分布式实时处理平台,其编程模型简单,支持多种编程语言,数据处理高效,但在资源调度上存在缺陷,即静态的资源分配和轮询式资源放置无法适应时变的流数据[2-3]. 其中静态资源分配是首要解决的问题[4]. Storm的资源分配以线程为单位,如果应用分配的线程数量较少,则并行执行的任务也随之变少,应用的处理能力变弱,反之亦然[5]. 在Storm中,应用分配的线程数量在应用部署时指定,并且在运行期间不能修改,称为静态的资源分配. 由于流数据的时变特性,该资源分配方法将导致出现下列情况: 当数据流速过低时,线程处于空闲状态,导致浪费资源; 当数据流速过高时,任务节点进入超载状态,应用性能下降. 因此,根据流数据的实时变化,实现弹性资源分配[6-7]组件,动态地调整线程的数量,支持以较小的资源使用代价满足应用性能的需求,已成为Storm资源调度亟待解决的问题.目前,基于Storm平台的资源调度策略组件研究较多,但多数工作主要关注如何优化资源配置,较少研究弹性资源分配组件. T-Storm[8]设计并实现了一种通信感知的任务配置方法,减少了节点间的通信量和节点数量,并保证节点不过载; R-Storm[9]实现了一种资源感知的调度方法,能最大化资源利用率,同时最小化应用的网络延迟,进而提高任务的吞吐量. 类似地,文献[10]也实现了一种资源感知调度,并考虑减少组件之间的网络传输距离,提高了系统的吞吐量和资源利用率; D-Storm[11]同时考虑了任务的资源需求和任务间的交互情况,将通信量大的任务尽量放置到同一节点,从而减少节点间通信开销; 文献[12]提出并实现了一种自适应的资源调度方案,该方案能较好地适应负载变化,支持有状态操作的迁移,并解决了资源竞争问题,在满足应用资源需求的同时,提高了资源利用率; 文献[13]针对集群通信开销大和负载不均衡问题,设计了一种基于拓扑结构的任务调度策略,提高了系统的实时性和平均吞吐量; 文献[14]提出了一个最优化的线程重分配与数据迁移节能策略,降低了节点间的通信开销和能耗,从而提升了集群的性能; 文献[15]提出了一种基于动态拓扑的流计算性能优化方法,增强了适应数据变化的动态资源调整能力,提高了应用的吞吐量和数据处理速度. 上述工作较好地解决了Storm的资源配置问题,只有文献[15]考虑了弹性资源分配,即自适应地调整任务的并发度,但未优化资源调整数量,且资源重分配方式较复杂,引入了额外的开销.
本文借鉴文献[6]关于弹性资源分配策略的研究工作,结合Storm的资源分配机制和用户界面(user interface,UI)参数,设计并实现一个基于Storm的弹性资源分配策略组件. 该组件以减少数据丢失率并提高资源利用率为目标,通过应用编程接口(application programming interface,API)实时监控应用的運行状态,并根据应用中每个任务节点的状态数据计算最优化的线程并行度,同时,调用Storm默认的rebalance命令重新部署资源分配,能以较低的重配置开销更好地适应流数据的变化.
1 Storm资源分配机制
1.1 Storm拓扑的构建和部署
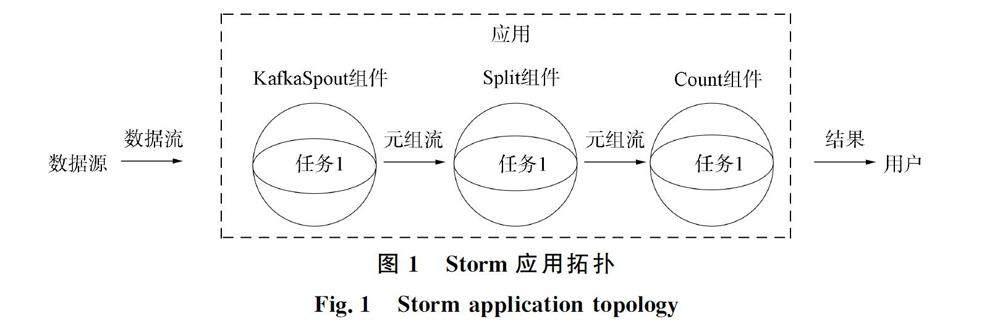
在Storm中,应用/实例以拓扑(有向无环图)的形式表示,由Spout组件和Bolt组件构成(表示为节点),组件之间通过数据流关联(表示为有向边). 其中,Spout从外部数据源读取数据,并转换为拓扑内部的源数据,Bolt执行不同的数据处理任务,并将数据处理结果传递给下游的Bolt或用户. 在应用拓扑中,数据以元组作为基本单元,连续的元组组成数据流[2]. 以单词统计应用(以下称WordCount应用)为例,如图1所示,该应用拓扑由KafkaSpout,Split(Bolt),Count(Bolt)三个组件构成. 其中,数据源是数据流,如Twitter中发表的文章,先存入数据库文件,并调用Python组件将数据存入Kafka的队列中,再提供给KafkaSpout使用. 在数据处理部分,KafkaSpout作为应用的Spout,将数据源的数据封装为元组形式(任务1),即句子,并采用随机分组策略将句子输出给Bolt组件Split; SplitBolt将获取的句子划分为新的元组(任务2),即单词,再通过字段分组策略发送给另一个Bolt组件Count; 最后,Count将同一单词计数并输出计数值给用户(任务3). Storm拓扑的创建过程如下: 首先,用户通过topologyBuilder类中的方法设置应用拓扑包含的组件,其中,setSpout方法设置Spout组件,setBolt方法设置Bolt组件; 其次,调用createTopology方法返回StormTopology对象,该对象作为拓扑提交方法submitTopology的输入参数; 最后,将应用拓扑组件打包成jar包上传到服务器(主节点)上.
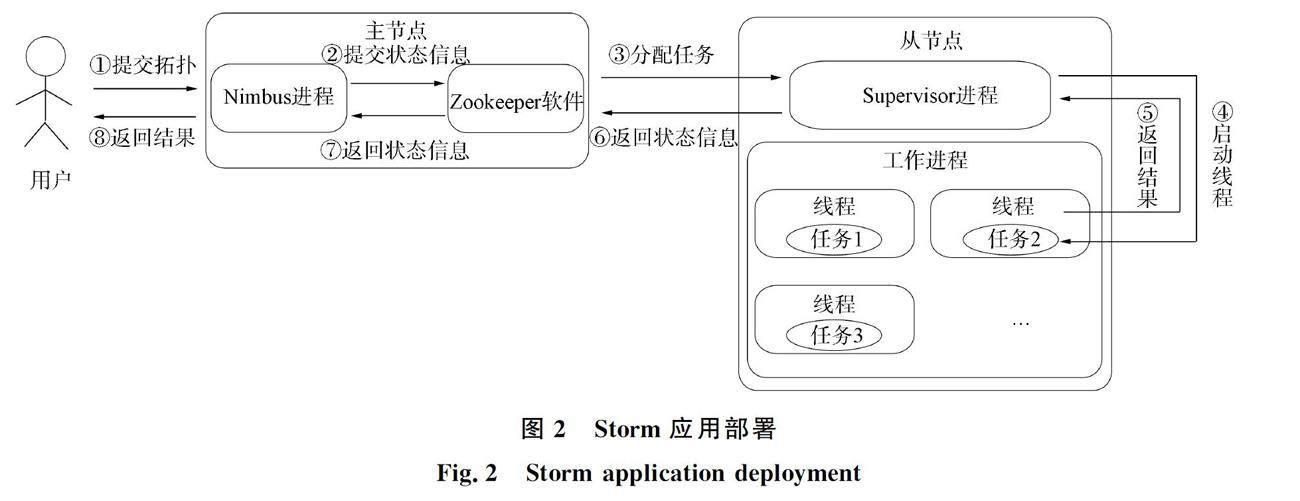
在Storm系统中,用户将应用拓扑提交给主节点上的Nimbus进程(负责资源分配和任务调度)并建立拓扑的本地目录; 分布式协调服务软件Zookeeper负责保存Nimbus与监督进程Supervisor的状态信息,并分配应用的任务到从节点的工作进程上,同时启动拓扑; 从节点上的Supervisor启动/停止工作进程,获取Zookeeper分配的任务,并在工作进程中启动线程(Executor)执行任务(线程与任务是一对一关系),同时建立任务之间的通信; 最后,应用的数据处理结果由Nimbus返回给用户[5]. 整个应用的部署过程,包括系统中各部分之间的关系如图2所示.
1.2 Storm拓扑调整
在拓扑运行过程中,可通过rebalance命令调整组件执行任务所需的线程数量,即并行度,包括扩展和收缩,如图3所示.
由图3可见,Bolt组件任务初始分配3个线程,在进行扩展或收缩调整后,分别重分配4个线程和2个线程,即并行度对应地由3变为4和2. 组件并行度调整需经历3个状态转换[2]:
首先,执行kill-transition方法将拓扑的状态由activated改为killed,即经过kill-time的时间重新启动拓扑; 然后,拓扑的状态变为do-rebalance,并通过Zookeeper将任务进行重新分配. 一旦执行rebalance命令,Spout组件会立即
停止发送数据,并通过Storm的ack/fail机制保证已经发送的数据都会得到处理,防止在进行组件的并行度扩展或收缩时发生数据丢失.
2 弹性资源分配算法
2.1 算法思想
本文借鉴文献[6]的方法,设计一个基于Storm的分布式最优弹性资源分配算法. 该算法的核心思想是: 每个组件根据输入元组数据量大小,动态地调整组件分配的线程数量,减少数据丢失,并提高Storm系统的资源利用率. 最优算法的设计包括以下4个步骤:
1) 获取组件的输入元组数量;
2) 计算组件的输入缓存占用率;
3) 判断组件是否需要调整; 4) 确定组件重分配的线程数量.
2.1.1 组件输入数据量
本文面向连续的流式数据源,每个组件处理的数据均为连续的数据流(元组流). 将组件的输入数据流离散为连续的固定时间窗口Δt内的数据块,其中时间窗口Δt也是资源重分配的时间间隔. 在每个时间窗口Δt,需要计算数据块的大小,即组件的输入数据量,该值通过Storm UI的监控参数获取.
2.1.2 输入缓存占用率
在Storm中,每个组件Ei分配的所有线程共用一个输入缓存,用于存储组件的输入元组并分发给线程处理. 如果元组的输入速率大于处理速率,则未处理的元组会暂存于缓存中,二者的差值越大,缓存的元组越多,甚至发生数据丢失; 反之,若缓存处于空置状态,则线程出现空闲,存在资源浪费的现象. 因此,缓存占用状态成为衡量组件是否进行资源调整的重要指标. 本文将输入缓存占用率定义为缓存中元组的数量与缓存容量的比值,最小值为0,表示为
Ri(n)=(Ii(n)-Pi(n))×Δt+Ri(n-1)×BsBs,(1)
其中: Ri(n)和Ri(n-1)分别表示组件Ei在时间窗口n和n-1的缓存占用率; Δt表示时间窗口的大小,可根据实际需要设置; Ii(n)表示组件Ei在窗口n的元组输入速率; Pi(n)表示组件Ei在窗口n的元组处理速率,Pi(n)=PE×Ni(n),PE为线程的处理速率,Ni(n)是组件Ei在窗口n的线程数量; Bs表示输入缓存的容量,所有组件相同.
2.1.3 资源调整判定
在算法中,定义3个阈值: α,β,υ,其中: α和β分别是输入缓存占用率的上、 下限阈值,用于触发组件的扩展调整和收缩调整; υ是输入缓存占用率的基准阈值,限制资源分配的数量,保证系统的资源利用率. 当输入缓存占用率Ri(n)大于上限阈值α时,触发扩展调整,增加组件并行度; 当输入缓存占用率Ri(n)小于下限阈值β时,进行收缩调整,减少并行度.
2.1.4 确定线程数量
在并行度调整过程中,采用最优化方法确定线程重分配的数量,在减少数据丢失量的同时,增大应用的资源利用率. 为提高资源利用率,调整后的组件处理能力至少应保证缓存占用率达到基准阈值υ. 在时间窗口n中,组件所需的并行线程数量为
Ni(n)=Di(n)PE×Δt,Di(n)>0,1,Di(n)≤0,(2)
其中Di(n)表示组件在当前窗口n需要处理的数据量,包括窗口n的输入数据和窗口n-1的缓存数据,同时减去基准阈值对应的缓存数据,即Di(n)=Ii×Δt+Bs×Ri(n-1)-Bs×υ.
2.2 算法伪代码
算法1 OERA(optimal elastic resource allocation)算法.
输入: Ri(n-1),Ri(n),Bs,PE,Ni(n),n,Δt,α,β,υ;
输出: Ni(n);
步骤1) IF n==1 THEN
步骤2) Ri(n-1)=0; //初始化缓存占用率
步骤3) WHILE (Ei未终止) //组件Ei每隔Δt进行一次资源重分配,直到组件的任务终止
步骤4) 计算窗口n内输入数据量Si(n); //通过Storm UI获取
步骤5) Ii(n)=Si(n)/Δt; //计算组件Ei在窗口n的输入速率Ii(n)
步骤6) Pi(n)=PE×Ni(n); //计算窗口n的处理速率Pi(n)
步骤7) 利用式(1)计算组件Ei的缓存占用率Ri(n); //资源重分配判定依据
步骤8) IF Ri(n)>α或Ri(n)<β THEN //进行资源重分配(扩展或收缩)判断
步骤9) 利用式(2)计算组件Ei重分配的资源量Ni(n); //资源重分配计算规则
步骤10) Ri(n-1)=Ri(n); //保存窗口n的缓存占用率,作为n+1时间窗口的前一个窗口缓存占用率
步骤11) n=n+1; //计算下一个时间窗口n+1
步骤12) RETURN Ni(n).
2.3 算法分析
在OERA算法中,每个组件在时间窗口n进行一次资源重分配数量计算,其中仅需要计算1次输入数据量、 1次输入速率、 1次处理速率和1次缓存占有率,进行1次资源调整判断,并计算1次或0次重分配资源量,共需要时间为O(1). 因此,在每个时间窗口n,OERA算法的时间复杂度均为O(1). 由于每个组件独立地计算资源重分配数量,因此整个应用的所有组件并行地执行OERA算法,应用在时间窗口n的资源重分配时间复杂度也是O(1),具有很小的执行开销.
3 弹性资源分配组件实现
本文的组件实现主要包含两部分: 1) 数据监控接口,用于获取应用拓扑运行中的监控数据,如吞吐量、 处理延迟和线程数量等,通过向Storm的API接口发送网络请求实现; 2)弹性资源分配类,处理监控接口获得的数据,结合弹性资源分配算法判断组件当前状态是否需要调整,并计算调整后的线程数量,再通过调用Shell执行调整命令,进行资源重配置.
3.1 数据监控接口
在数据监控部分,需要从Storm UI获取组件的状态数据,时间窗口Δt的大小设为10 min,与Storm UI的监控时间相同. 状态数据主要包括拓扑ID、 元组累计传输总数transferred、 线程数executors和元组处理延迟executeLatency. 实现过程如下: 首先,通过API接口中的request方法向Storm UI发送监控请求,请求格式为requests.get(“http://IP: 端口号/api/v1/topology/Topology-Id”),其中,IP是當前Nimbus节点的IP地址,端口号是在storm.yaml文件中配置的ui.server参数,Topology-Id是当前监控的拓扑运行时的ID; 其次,设置Bolts和Spouts监控的节点,即res.json( )[“bolts”]和res.json( )[“spouts”]; 最后,通过spouts[“性能参数”]和bolts[“性能参数”]的方式,设置transferred,executors,executeLatency等监控参数.
输入缓存尺寸,即线程的接收队列大小,对应属性Config.TOPOLOGY_EXECUTOR_RECEIVE_BUFFER_SIZE,通过Storm.yaml文件的conf.put方法配置.
3.2 弹性资源分配类
3.2.1 监控数据获取和处理
在弹性资源分配类中,先通过数据监控接口分别获取组件传输的元组数、 线程数和平均元组处理时间,即spouts.transferred,bolts.executors,bolts.executeLatency. 然后,将上述监控数据转换为Storm拓扑的运行状态数据,即资源分配算法需要的组件信息. 因此,元组输入速率Ii(n)利用Ii(n)=(transferred(n)-transferred(n-1))/Δt计算,其中transferred(n)和transferred(n-1)分别为前n个和前(n-1)个时间窗口传输的元组总数. 元组处理速率Pi(n)是组件在窗口n中元组处理延迟的倒数,即Pi(n)=1/executeLatency. Bs为Storm.yaml文件中手动配置单个线程接收队列大小与线程数的乘积. 在获取上述状态信息后,根据式(1)计算组件在窗口n中的输入缓存占用率Ri(n).
3.2.2 资源分配数量计算
在资源分配数量计算过程中,首先,通过实现继承BaseRichSpout/BaseRichBolt类(或实现IRichSpout/IRichBolt接口)创建KafkaSpout,Split和Count组件,其中KafkaSpout组件利用nextTuple方法将数据源组织成元组并发送给Split组件,Split和Count组件分别实现分割句子和计数单词的任务; 其次,每个组件分别调用OERA算法计算资源分配数量.
定义If_Balance(buffer_occupy)方法判断组件是否进行资源重配置,其中参数buffer_occupy是组件的输入缓存占用率; Resource_Count(deal_tuple)方法用于计算组件的重分配资源数量,其中deal_tuple是组件当前需要处理的数据量,返回值是资源分配数量.
3.2.3 并行度重配置
在资源重配置过程中,通过调用Shell类执行应用的组件并行度重配置. 在Shell类中,定义execCmd(CMD,DIR)方法执行调整命令,其中: CMD变量为执行并行度重配置的调整命令,在CMD变量中,由exec_list参数接收所有组件的重分配资源数量N; DIR为执行命令的绝对路径. 在执行调整命令时,重配置拓扑并行度的整个过程延迟约为120 s.
4 实验结果与分析
4.1 实验设置
本文Storm集群由5个节点组成,其中1个主节点部署Nimbus,Zookeeper和Kafka,4个从节点部署Supervisor. 每个节点配置如下: AMD Ryzen 5 3500U 2.10 GHz 8核CPU, GPU为AMD Radeon(TM) Vega 8 Graphics,16 GB内存,ubuntu-20.04.2.0-desktop-amd-64操作系统. 实验数据集来自Twitter上某篇24 h内发表的关于Covid-19的推文,先将推文数据每10 min统计一次,统计结果作为1条记录传入Nimbus节点上部署的Kafka[16],再通过Kafka的消息队列与Storm应用的Spout建立连接,作为其数据源. Kafka数据在24 h内的变化趋势如图4所示. 为检验弹性资源分配组件在不同输入速率下的调整性能以及正确性,选择具有代表性的8~15 h的数据作为本文的测试数据集,并将负载数据量转换为元组数量,如图5所示. 采用WordCount应用作为测试实例,初始时,WordCount拓扑中的组件线程数配置如下: Spout组件线程数为5,不设置setNumTask参数; Split组件线程数为5,setNumTask参数为16; Count组件线程数为12,setNumTask参数为40. 在弹性资源分配算法中,将3个阈值α,β,υ分别设为0.8,0.2,0.7.
4.2 算法性能测试
本文选择中值动态资源分配算法(以M作为前缀)和Storm的静态资源分配算法(以S作为前缀)作为OERA算法(以O作为前缀)的对比算法,进行吞吐量、 丢失率、 并行度和资源利用率上的性能测试. 其中: 中值动态资源分配算法是在最优资源分配算法的基础上,选择前一个固定时间间隔内(10Δt)所有Δt的资源分配数量中值作为后一个固定时间间隔的资源分配数量; Storm的静态资源分配算法采用固定方式分配资源,在整个应用运行过程中保持不变.
4.2.1 吞吐量测试
吞吐量是衡量组件数据处理能力的重要指标,不同算法的吞吐量对比如图6所示. 由图6(A),(B)可见,由于OERA算法在拓扑运行时进行了最优的资源分配,即设置为最优的并行度,能较好与组件的数据负载相匹配,组件O-Count和O-Split的吞吐量均高于其他两种算法的对应组件. 当输入负载变化较大时,最优资源分配的组件能自适应地调整资源分配数量,吞吐量性能最佳,中值动态资源分配以中间值代替最优值,性能次之,而传统的静态资源分配不能调整组件的并行度,从而无法增加吞吐量,吞吐量性能最差. 对于整个应用,OERA算法的吞吐量性能也优于中值动态资源配置和传统的静态资源配置,如图6(C)所示.
4.2.2 丢失率测试
在數据丢失率测试中,最优资源分配算法的每个组件(O-Count和O-Split)数据丢失率低于中值动态资源分配算法最多约20%,但明显比传统静态资源分配算法平均减少了50%~70%,如图7(A),(B)所示. 当输入负载增加时,最优资源分配算法会增加组件的资源数量,从而提高其数据处理能力,减少数据丢失量; 中值动态资源分配算法也会增加组件(M-Count和M-Split)的并行度,但增加的幅度无法完全与输入负载匹配,导致一定程度的数据丢失; 传统的静态分配方式保持组件(S-Count和S-Split)的并行度不变,导致节点的处理能力不够,数据丢失严重. 采用OERA算法进行资源分配时,应用的平均整体数据丢失率(O-WordCount)分别低于中值动态资源分配算法(M-WordCount)和传统静态分配算法(S-WordCount)约30%和90%,如图7(C)所示.
4.2.3 并行度测试
当组件的输入负载发生变化时,不同算法的组件并行度变化和均值如图8所示. 由图8可见,传统的静态分配策略不具备资源调整特性,S-Count和S-Split组件的并行度始终保持不变. 由于Count组件的输入负载大且变化较快(以单词作为元组),OERA算法和中值动态资源分配算法均根据负载进行资源扩展或收缩调整,同时OERA算法的调整幅度最优且粒度更小,O-Count组件的并行度变化最频繁,M-Count组件次之,如图8(A)所示. 相反,Split组件的输入负载小且变化不明显(以句子作为元组),O-Split和M-Split组件的并行度基本保持不变,如图8(B)所示. 对于应用,OERA算法的组件平均并行度略高于中值动态算法和传统静态算法,如图8(C)所示,但保证了应用的整体性能.
4.2.4 资源利用率测试
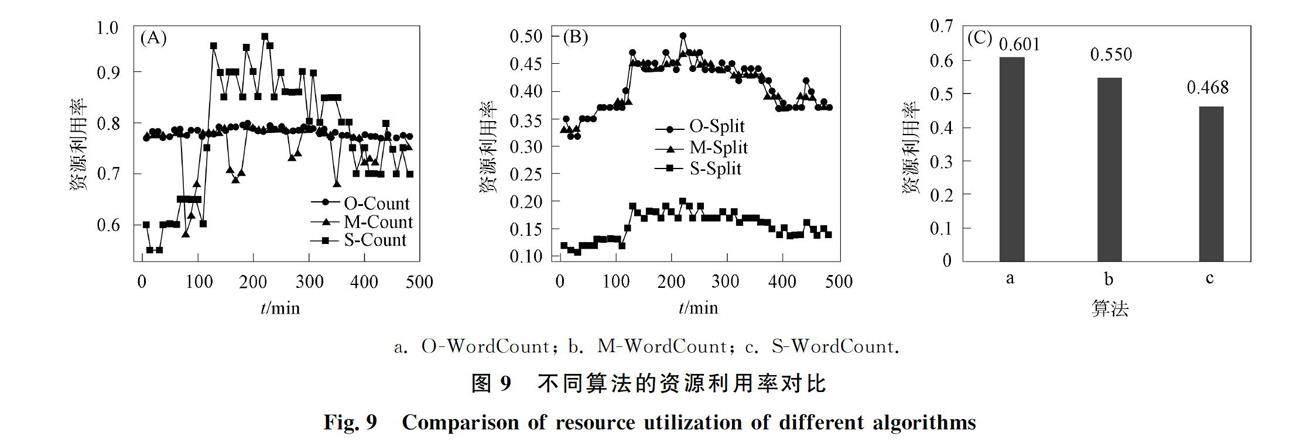
如图9(A),(B)所示,在资源利用率测试中,OERA算法根据输入负载进行最优的资源分配,以最大限度地提高资源利用率,且负载量和变化幅度越大,效果越明显,其中O-Count资源利用率始终接近于0.8,O-Split组件则平均约为0.4. 传统静态资源分配算法则无法在运行时调整资源数量(S-Count和S-Split),当输入负载较大时,组件资源被完全占用,资源利用率接近100%; 随着输入负载逐渐变小,则可能出现资源浪费,导致应用整体的资源利用率降低. 中值动态资源分配算法兼有最优动态调整和静态调整的特性,能在较大程度上满足负载需求,因此,M-Count和M-Split组件的资源利用率更接近于OERA算法组件. 如图9(C)所示,OERA的组件平均资源利用率整体上分别比中值动态算法和传统静态算法约提高9%和22%.
上述实验结果表明,面向时变的输入负载,本文设计和实现的OERA组件能自适应且准确地计算最优的组件并行度,较好地满足了应用的数据处理需求. OERA算法在吞吐量、 丢失率和资源利用率性能上,均优于中值动态算法和静态算法,其中吞吐量分别约提高了3%和4%,丢失率分别约降低了30%和90%,资源利用率约保持在60%,分别约提高了9%和22%. 当数据负载发生变化时,OERA算法性能最好,能最大程度地满足负载的资源需求,中值动态算法次之,且在较大负载时性能更优. 相比之下,由于资源分配方式固定,传统静态算法的性能与输入负载密切相关,过高或过低负载情况下明显均低于OERA算法.
综上所述,针对面向时变的大规模流数据,Storm的静态资源分配机制导致系统资源利用率较低,甚至无法满足应用性能需求的问题,以减少数据丢失率和提高资源利用率为目标,本文提出了一种最优的弹性资源分配算法. 通过研究Storm的资源分配机制、 API接口和UI参数,实现了一个基于Storm的自适应弹性资源分配组件. 该组件可根据输入负载的变化动态地调整应用组件的线程资源分配. 在真实数据集上进行性能測试的结果表明,与中值动态资源分配算法和静态资源分配算法相比,该组件在满足应用性能需求的同时,在应用的整体性能上均占优,其中数据丢失率约降低30%和90%,资源利用率约提高9%和22%,吞吐量约提高3%和4%.
参考文献
[1] TOSHNIWAL A,TANEJA S,SHUKLA A,et al. Storm@t
witter [C]//ACM SIGMOD International Conference on Management of Data. New York: ACM,2014: 147-156.
[2] 蔡宇,赵国锋,郭航. 实时流处理系统Storm的调度优化综述 [J]. 计算机应用研究,2018,35(9): 2567-2573. (CAI Y,ZHAO G F,GUO H. Over
view of Scheduling Optimization of Real-Time Stream Processing System Storm [J]. Computer Application Research,2018,35(9): 2567-2573.)
[3] MICHAEL K,MILLER K W. Big Data: New Opportunities and New Challenges [J]. Computer,2013,46(6): 22-24.
[4] WEI X H,LI L N,LI X,et al. Pec: Proactive Elastic Collaborative Resource
Scheduling in Data Stream Processing [J]. IEEE Transactions on Parallel and Distributed Systems,2019,30(7): 1628-1642.
[5] 张洲,黄国锐,金培权. 基于Storm的任务调度: 现状与研究展望 [J]. 计算机科学,
2019,46(9): 28-35. (ZHANG Z,HUANG G R,JIN P Q. Task Scheduling on Storm: Current Situations and Research Prospects [J]. Computer Science,2019,46(9): 28-35.)
[6] 李丽娜,魏晓辉,李翔,等. 流数据处理中负载突发感知的弹性资源分配 [J]. 计算机学报,2018,41(10): 2193-2208. (LI L N,WEI X H,LI X,et al. Elastic Resourc
e Allocation of Load Burst Perception in Streaming Data Processing [J]. Journal of Computer Science,2018,41(10): 2193-2208.)
[7] 李丽娜,魏晓辉,郝琳琳,等. 大规模流数据处理中代价有效的弹性资源分配策略 [J]. 吉林大学学报(工学版),2020,50(5): 1832-1843. (LI L
N,WEI X H,HAO L L,et al. Cost-Effective Elastic Resource Allocation Strategy in Large-Scale Streami
ng Data Processing [J]. Journal of Jilin University (Engineering and Technology Edition),2020,50(5): 1832-1843.)
[8] XU J L,CHEN Z H,TANG J,et al. T-Storm: Traffic-Aware Online Scheduling in Storm [C]//International Conference on Distri
buted Computing Systems. Piscataway,NJ: IEEE,2014: 535-544.
[9] PENG B,HOSSEINI M,HONG Z,et al. R-Storm: Resource-Aware Scheduling in Storm [C]//MIDDLEWARE Conference. New York: ACM,2015: 149-161.
[10] 刘月超,于炯,鲁亮. Storm环境下一种改进的任务调度策略 [J]. 新疆大学学报(
自然科学版),2017,34(1): 90-95. (LIU Y C,YU J,LU L. An Improved Task Schedule Strategy in Storm Environment [J]. Journal of Xinjiang University (Natural Science Edition),2017,34(1): 90-95.)
[11] LIU X Y,BUYYA R. D-Storm: Dynamic Resource-Efficient Scheduling of Stream P
rocessing Applications [C]//IEEE 23rd International Conference on Parallel and Distributed Systems (ICPADS). Piscataway,NJ: IEEE,2017: 485-492.
[12] LIU S C,WENG J P,WANG J H,et al. An Adaptive Online Sc
heme for Scheduling and Resource Enforcement in Storm [J]. IEEE/ACM Transactions on Networking (TON),2019,27(4): 1373-1386.
[13] 刘粟,于炯,鲁亮,等. Storm环境下基于拓撲结构的任务调度策略 [J]. 计算机应用,2018,38(12): 133-141. (LIU S,YU J,LU L,et al. T
opology Based Task Scheduling Strategy in Storm Environment [J]. Computer Applications,2018,38(12): 133-141.)
[14] 蒲勇霖,于炯,鲁亮,等. Storm平台下的线程重分配与数据迁移节能策略 [J]. 软件学报,2021,32(8): 2557-2579. (PU Y L,YU J,LU L,et al. Energy-Efficient S
trategy Based on Executor Reallocation and Data Migration in Storm [J]. Journal of Software,2021,32(8): 2557-2579.)
[15] 陆佳炜,吴涵,陈烘,等. 一种基于动态拓扑的流计算性能优化方法及其在Storm中的实现 [J]. 电子学报,2020,48(5): 878-890. (LU J W,W
U H,CHEN H,et al. A Performance Optimization Method Based on Dynamic Topology for Stream Computing and Its Implementation in Storm [J]. Chinese Journal of Electronics,2020,48(5): 878-890.)
[16] 杨立鹏,张仰森,张雯,等. 基于Storm实时流式计算框架的网络日志分析方法 [J]. 计算机科学,2019,46(9): 176-183. (YANG L P,ZHANG Y
S,ZHANG W,et al. Web Log Analysis Method Based on Storm Real-Time Streaming Computing Framework [J]. Computer Science,2019,46(9): 176-183.)
(责任编辑: 韩 啸)
猜你喜欢
中国商论(2024年9期)2024-05-14
计算机仿真(2023年9期)2023-10-29
英语文摘(2020年10期)2020-11-26
测控技术(2018年7期)2018-12-09
计算机系统应用(2018年7期)2018-07-18
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
计算机应用(2016年10期)2017-05-12
无线互联科技(2017年3期)2017-04-21
电子技术与软件工程(2017年6期)2017-04-14
