
图像与激光点云融合的实时目标定位算法
2023-04-28 05:54崔善尧贾述斌黄劲松
导航定位学报 2023年2期
崔善尧,贾述斌,黄劲松
图像与激光点云融合的实时目标定位算法
崔善尧,贾述斌,黄劲松
(武汉大学 测绘学院,武汉 430079)
针对单一传感器在自动驾驶实时目标定位中的局限性,提出一种基于图像与激光点云融合的实时目标定位算法:对图像进行目标检测,得到目标在图像坐标系中的区域;然后将激光点云投影到图像坐标系中,使用基于密度的带有噪声的空间聚类(DBSCAN)算法对目标区域内的少量点云进行聚类以提取目标真实点云,降低计算量的同时获取目标准确的位置信息。实验结果表明,该算法可以有效提升在遮挡情况下目标定位的准确性;并通过在嵌入式平台上进行部署,验证了该算法在算力受限的平台上也具有较好的实时性。
自动驾驶;图像检测;点云聚类;数据融合;实时目标定位
0 引言
环境感知是自动驾驶车辆实现自主行驶的基础和前提[1]。提高车辆感知附近目标的实时性和准确性,不仅可以提高车辆的自动驾驶能力,也对自动驾驶安全具有重要意义[2]。因此,如何对车辆周围目标进行及时、精准的定位具有重要的研究价值。
目标定位首先要对目标进行检测,已有大量学者针对图像目标检测算法进行了研究,目前的主流方法是基于深度学习的算法,主要包括只看一次(you only look once,YOLO)系列[3-6]、单次多视窗检测(single shot multibox detector,SSD)[7]、区域卷积神经网络(region-based convolutional neural network,R-CNN)系列[8-10]、特征金字塔网络(feature pyramid networks,FPN)[11]等。这些图像目标检测算法虽然可以较好地获取目标方位,但受限于图像无法提供深度信息,难以准确判定目标的距离。
激光雷达可以获取目标准确的空间位置,因此对于自动驾驶具有重要的应用价值。基于激光点云的目标检测算法也是一直以来的研究热点,其可分为传统算法和基于深度学习的算法。传统算法一般先进行地面点云滤除、滤波等操作,然后对点云进行空间聚类,从而确定各目标的位置。传统算法受聚类方法、点云数量的影响,难以保证较好的检测效果和实时性。基于深度学习的算法有采用单阶段网络的体素网络(voxel network,VoxelNet)[12]、点云柱状特征网络[13]、点云图神经网络(point-based graph neural network,Point-GNN)[14]等,以及采用双阶段检测的点云体素区域卷积神经网络(point voxel region-based convolutional neural network,PV-RCNN)[15]、体素区域卷积神经网络(voxel-based region-based convolutional neural network,Voxel R-CNN)[16]等算法。相较于单阶段,双阶段的检测精度更高,但速度较慢。同时,基于深度学习的点云目标检测对计算资源的需求较高,在算力受限的平台上实时性较差。
结合相机可准确获取目标方位和激光雷达能准确获取目标空间位置的特点,众多学者对基于图像和点云数据融合的目标检测算法进行了研究。文献[17]先对点云进行聚类得到目标感兴趣区域,然后将其投影到图像坐标系下,再使用卷积神经网络对感兴趣区域内的目标进行检测,提升了检测速度。文献[18]分别对点云和图像数据进行目标检测,然后通过决策级融合获取目标的位置、类别等信息,但是目标被遮挡时距离准确度不高。文献[19]先对图像中目标进行识别,然后将图像检测框与点云进行快速配准,降低了图像漏检的概率。文献[20]先用参数自适应的基于密度的带有噪声的空间聚类(density-based spatial clustering of applications with noise,DBSCAN)算法对点云进行聚类,然后融合深度学习图像检测的结果,以去除聚类结果中的冗余目标。该算法虽然具有较高的精度和鲁棒性,但是处理的点云数量较多,融合时会剔除较多的点云聚类结果,消耗了计算资源。这些方法一定程度上提高了目标的检测率,但是在算力受限的平台上难以保证较好的实时性。
针对以上单一传感器在实时目标定位中难以准确获取目标距离、算力要求高,多传感器融合在算力受限的平台上实时性难以保证的不足,本文提出了一种基于图像与激光点云融合的实时目标定位算法。该算法将图像的检测结果和激光点云进行融合,从而剔除目标区域外的点云以降低数据量,并使用DBSCAN算法对目标区域内的点云进行聚类,以提取目标的真实点云,实现对目标的定位。
1 算法介绍
1.1 目标定位算法流程
本文设计的图像与激光点云融合的实时目标定位算法流程如图1所示,主要包括数据融合和目标定位2个部分。首先采集激光点云和图像数据,并对其进行数据同步;再将去畸变后的图像使用YOLOv4进行目标检测,得到多个目标在图像坐标系中的位置、类别等信息;然后利用相机与激光雷达间的外参,将点云投影到图像平面上,并剔除图像中目标区域外的点云,完成点云与图像之间的数据融合;最后对图像目标区域内的少量点云进行聚类,提取目标的真实点云,从而获取目标准确的空间位置和距离,完成目标定位工作。
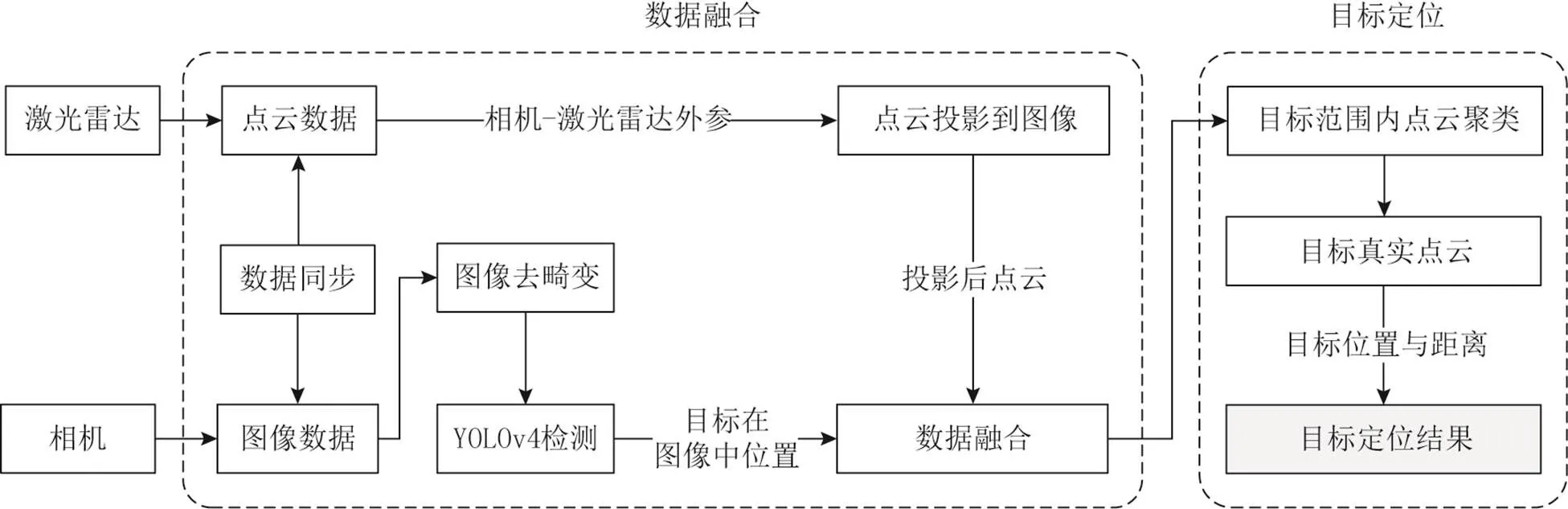
图1 算法流程
1.2 图像和点云数据同步
1.2.1 时间同步
在相机和激光雷达构成的多传感器系统中,由于各传感器的时钟基准不一致,需要对传感器间进行硬件时间同步,以保证各传感器工作在同一时间基准下;又由于各传感器的曝光频率不一致,需要对各传感器数据进行软件时间同步,以保证各传感器对同一环境事件的感知数据都拥有相同的时间戳,从而保证图像和点云数据的正确融合。
本文选用了车规级千兆多媒体串行链路(gigabit multimedia serial links,GMSL)相机和非重复扫描式激光雷达作为实验用传感器。GMSL相机支持触发式曝光,通过记录相机触发时间并对数据传输延迟进行修正,可获取图像的真实时间戳,该时间基准由上位机提供;激光雷达通过精确时间协议(precision time protocol,PTP)进行硬件时间同步,其时间基准由上位机提供。至此,相机和激光雷达便工作在了同一时间基准下,然后可对其数据进行软件时间同步。本文采用时间索引的方式,即对每一帧激光点云数据寻找与其采样时刻最近的图像数据,从而完成图像和点云数据间的软件时间同步。
1.2.2 空间同步
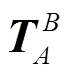
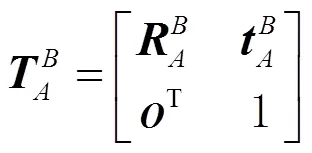
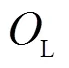
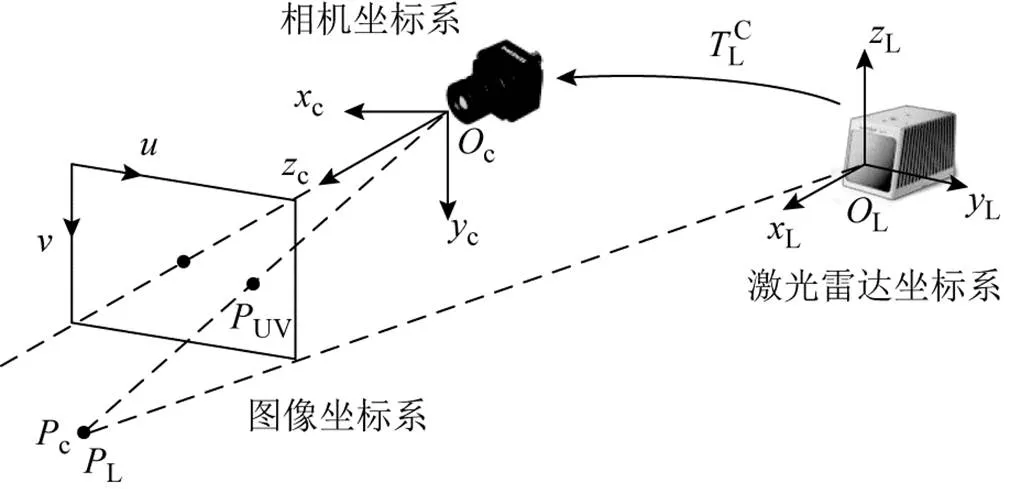
图2 坐标系空间转换关系

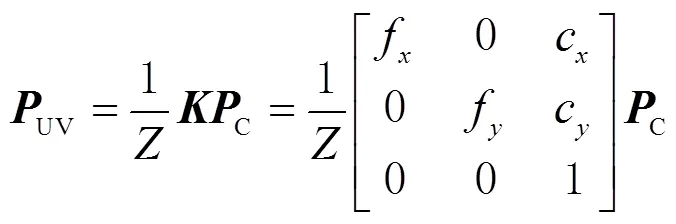

1.3 图像目标检测
基于深度学习的图像目标检测算法是目前的主流方法,其主要可分为2类,一类是单阶段算法,通过端到端的网络直接获取目标位置和类别,常见有YOLO系列[3-6]等;另一类是双阶段算法,先产生一系列的目标候选区域,再对候选区域进行分类,常见有R-CNN系列[8-10]等。虽然双阶段的检测精度高于单阶段,但是对计算资源需求较高,检测速度较慢,实时性差于单阶段。本文考虑到在算力受限的平台上进行实时目标检测与定位的需求,选用YOLOv4[6]作为图像的目标检测算法,并在部署时采用统一计算设备架构(compute unified device architecture,CUDA)[22]和深度学习推导优化器(TensorRT)[23]对算法中的神经网络推导进行加速,以提高目标检测的实时性。
1.4 数据融合与目标定位
图像目标检测完成后,得到个目标在图像中的区域为
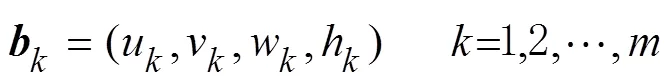
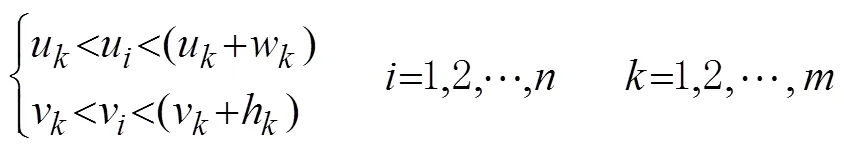
图3为数据融合后的效果。可以看出,图像目标检测只能提供目标的大致区域,目标边框内存在一定背景,且目标易受遮挡影响,会存在目标边框内一部分点云不属于目标的情况,进而影响目标定位的准确性,因此需要对这些点云进行判别并提取出目标真实点云。

图3 点云和图像融合效果
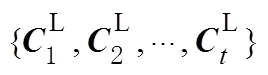
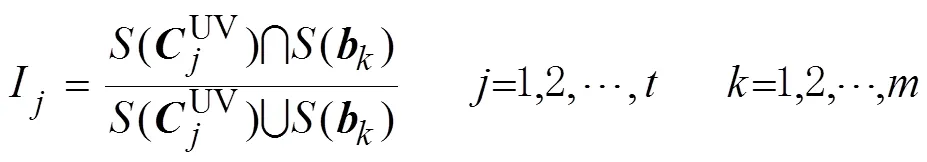
综合上述策略,即可提取目标真实点云数据,然后取点云聚类中心作为目标的空间位置,从而实现对目标的精准定位。
2 实验与结果分析
图4为本文所用实验平台,相机采用森云智能车规级GMSL相机,分辨率为1280×720个像素,激光雷达采用大疆览沃Mid-70非重复扫描式激光雷达,嵌入式计算平台采用米文动力Apex Xavier。平台上安装Ubuntu18.04操作系统,并使用机器人操作系统(robot operating system,ROS)作为本文算法的运行平台。

图4 实验平台
2.1 目标定位效果
为验证本算法的有效性,在校园多个场景下进行实时目标定位实验。经统计,一共采集了4659张图像,图像成功检测目标23095次,算法成功定位目标22563次,定位成功率为97.7%。图5为不同场景下的目标定位效果,其中点表示目标点云,叉表示被剔除的点云,目标边框上标明了目标类别和距离信息。

图5 不同场景下的目标定位效果
从图5可以看出:在场景1中,大部分的地面点以及前车被后车遮挡部分的点被有效剔除;在场景2中,树上的点被有效剔除;在场景3中,摩托车背景的点被有效剔除;在场景4中,非货车上的点被有效剔除。说明了本算法在目标受其他物体遮挡、目标区域存在一定背景点云时,能有效分辨目标的真实点云,剔除非目标的点云,提高了目标定位的准确性。
2.2 定位精度分析
为评价本文目标定位算法的定位精度,在校园场景下采集图像和点云数据,并使用语义分割编辑软件(semantic segmentation editor,SSE)对点云中的车辆和行人进行手工标注,从而获取目标的位置信息作为真值。数据集中共标注了150帧数据。图6所示为所标注的点云数据。
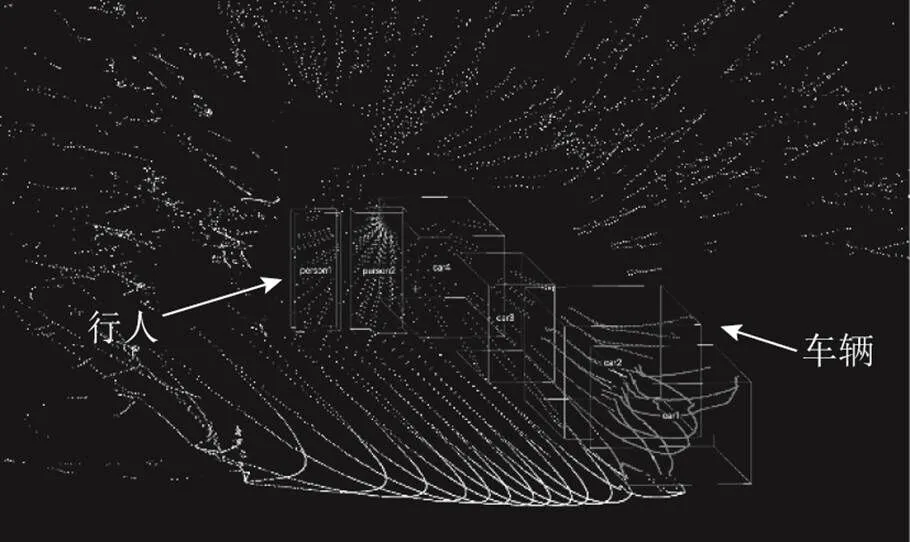
图6 点云数据标注
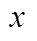

表1 不同距离下对行车和车辆定位的方位角和距离的平均误差
实验发现,随着距离的增加,目标在图像中所占面积减少,目标上的点云密度和数量在降低,对应非目标点的数量也在降低,因此目标定位的方位角误差呈减小趋势。同时受该激光雷达自身测距精度影响,在距离小于5 m时,测距平均误差较大。较大体积的目标易受其他物体遮挡,导致一部分目标自身点云缺失,影响整体的定位精度;因此本算法对行人的定位效果一定程度上优于对车辆的定位效果。
2.3 算法实时性
为验证本算法的实时性,分别在嵌入式平台上和高性能笔记本上对算法进行部署和测试。2个平台的硬件参数如表2所示。可以看出,嵌入式平台的处理器和显卡均大幅弱于高性能笔记本。

表2 测试平台硬件参数
对本算法分别使用中央处理器(central processing unit, CPU)、使用CPU/CUDA组合加速、使用CPU/CUDA/TensorRT组合加速,部署在嵌入式平台和高性能笔记本上,统计每帧数据的平均耗时,结果如表3所示。可以看出,尽管本算法在高性能笔记本上的表现优于嵌入式平台,但是功耗巨大,不适合自动驾驶场景下使用。对算法进行加速后,在嵌入式平台上能达到36.7毫秒/帧的性能,理论上可达到27帧/秒的目标定位能力,说明本算法在算力受限的平台上也能实时地运行。
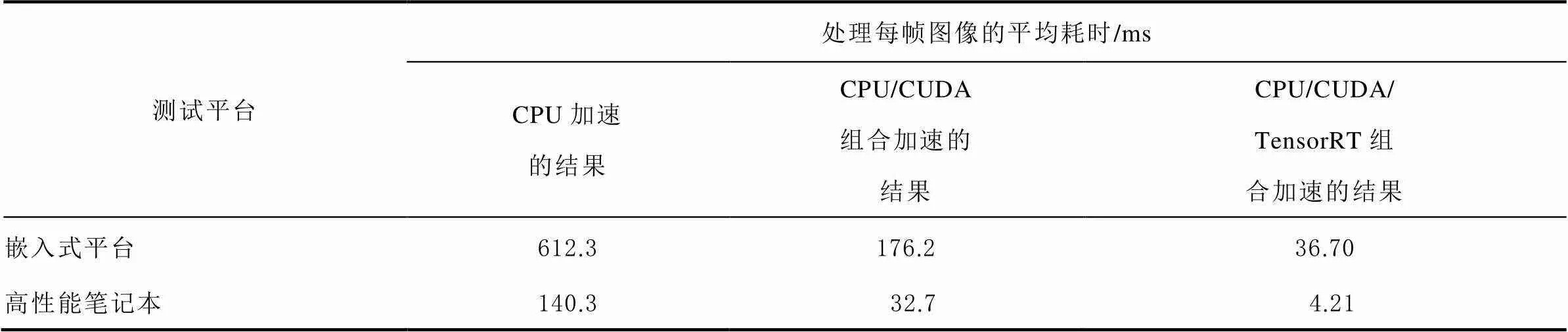
表3 在不同平台上算法采用不同加速的每帧平均耗时
在嵌入式平台上分别部署本文算法和文献[20]中的算法进行对比实验,其中深度学习网络推导部分均使用CUDA/TensorRT组合加速。利用2.2节中标注的数据,统计文献[20]中算法的目标定位精度和处理每帧数据的平均耗时,并与本文算法进行对比,结果如表4所示。可以看出,本文算法的方位角平均误差为1.36°,略优于文献[20]的1.39°,距离平均误差为5.8 cm,与文献[20]的5.7 cm相当。在实时性表现上,本文算法每帧平均耗时比文献[20]减少了70.9%,这主要得益于本算法在融合图像目标区域和点云的过程中,剔除了大量的非目标冗余点云,大幅降低了计算量,从而提高了算法的处理效率,证明了本算法在低算力平台上保证目标定位精度的同时,也可具备更好的实时性。

表4 算法定位误差和每帧平均耗时
3 结束语
本文设计了一种基于图像与激光点云融合的实时目标定位算法,通过对图像进行目标检测获取目标所在区域,然后将点云投影到图像平面并剔除目标区域外的点云以降低数据量,再通过DBSCAN算法对点云进行聚类,从而提取目标真实点云以实现目标精准定位。实验结果表明,该算法对不同距离下目标的定位误差较小,且在目标之间出现遮挡时,能有效提高目标定位的准确性。同时,该算法在算力受限的低功耗嵌入式平台上每秒可以处理27帧数据,具备较强的实时性,适合在自动驾驶感知中使用。但本算法在目标距离较远且点云较为稀疏时容易无法定位目标。未来可对融合方法进行优化,以更好地在该情况下进行目标定位。
[1] 甄先通, 黄坚, 王亮, 等. 自动驾驶汽车环境感知[M]. 北京: 清华大学出版社, 2020: 1-5.
[2] WANG Z, WU Y, NIU Q. Multi-sensor fusion in automated driving: a survey[EB/OL].[2022-05-06]. https://ieeexplore.ieee.org/abstract/document/8943388.
[3] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[EB/OL]. [2022-05-06]. http://pjreddie.com/media/files/papers/yolo.pdf.
[4] REDMON J, FARHADI A. Yolo9000: better, faster, stronger[EB/OL].[2022-05-06]. https://arxiv.org/pdf/1612. 08242.
[5] REDMON J, FARHADI A. Yolov3: an incremental improvement[EB/OL]. (2018-04-08)[2022-05-06]. https://pjreddie.com/media/files/papers/YOLOv3.pdf.
[6] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23)[2022-05-06]. https://arxiv.org/pdf/2004.10934.
[7] LIU W, ANGUELOV D, ERHAN D, et al. Ssd: single shot multibox detector[EB/OL]. [2022-05-06]. https://link.springer.com/content/pdf/10.1007/978-3-319-46448-0.pdf.
[8] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[EB/OL]. [2022-05-06]. https://ieeexplore.ieee.org/document/6909475.
[9] GIRSHICK R. Fast r-cnn[EB/OL]. [2022-05-06]. http://arxiv.org/pdf/1504.08083.pdf.
[10] REN S, HE K, GIRSHICK R, et al. Faster r-cnn: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149.
[11] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[EB/OL]. [2022-05-06]. https://arxiv.org/pdf/1612.03144v2.
[12] ZHOU Y, TUZEL O. Voxelnet: end-to-end learning for point cloud based 3d object detection[EB/OL]. [2022-05-06]. https://arxiv.org/pdf/1711.06396.
[13] LANG A H, VORA S, CAESAR H, et al. Pointpillars: fast encoders for object detection from point clouds[EB/OL]. (2019-05-07)[2022-05-06]. https://arxiv.org/pdf/1812.05784.
[14] SHI W, RAJKUMAR R. Point-gnn: graph neural network for 3d object detection in a point cloud[EB/OL]. [2022-05-06]. https://arxiv.org/pdf/2003.01251.
[15] SHI S, GUO C, JIANG L, et al. Pv-rcnn: point-voxel feature set abstraction for 3d object detection[EB/OL]. (2021-04-09)[2022-05-06]. https://arxiv.org/pdf/1912.13192.
[16] DENG J, SHI S, LI P, et al. Voxel r-cnn: towards high performance voxel-based 3d object detection[EB/OL]. (2020-12-31)[2022-05-06]. https://arxiv.org/pdf/2012.15712.
[17] ZHAO X, SUN P, XU Z, et al. Fusion of 3D lidar and camera data for object detection in autonomous vehicle applications[J]. IEEE Sensors Journal, 2020, 20(9): 4901-4913.
[18] 李研芳, 黄影平. 基于激光雷达和相机融合的目标检测[J]. 电子测量技术, 2021, 44(5): 112-117.
[19] 胡远志, 刘俊生, 何佳, 等. 基于激光雷达点云与图像融合的车辆目标检测方法[J]. 汽车安全与节能学报, 2019, 10(4): 451-458.
[20] 宫铭钱, 冀杰, 种一帆, 等. 基于激光雷达和视觉信息融合的车辆识别与跟踪[J]. 汽车技术, 2020(11): 8-15.
[21] ZHANG Z. A flexible new technique for camera calibration[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(11): 1330-1334.
[22] CHENG J, GROSSMAN M, MCKERCHER T. Professional CUDA c programming[M]. [S.l.]: John Wiley & Sons, 2014:23-65.
[23] VANHOLDER H. Efficient inference with tensorrt[EB/OL].[2022-05-06]. https://on-demand.gputechconf.com/gtc-eu/2017/presentation/23425-han-vanholder-efficient-inference-with-tensorrt.pdf.
Real-time target positioning algorithm based on image and laser point cloud fusion
CUI Shanyao,JIA Shubin,HUANG Jingsong
(School of Geodesy and Geomatics, Wuhan University, Wuhan 430079, China)
Aiming at the limitations of the single sensor in real-time target localization in autonomous driving, the paper proposed a real-time target localization algorithm based on fusion of images and laser point clouds: the target detection on the image was performed to obtain the area of the target in the image coordinate system; and the density-based spatial clustering of applications with noise (DBSCAN) algorithm was used to cluster a small number of point clouds in the target area to extract the real target points; then the accurate location of the target was obtained while reducing the amount of computation. Experimental results showed that the proposed algorithm could effectively improve the accuracy of target positioning in the case of occlusion; and through deploying it on the embedded platform, it could be verified that the algorithm would have good real-time performance even on limited computing resource.
autonomous driving; image detection; point cloud clustering; data fusion; real-time target localization
P228
A
2095-4999(2023)02-0099-07
崔善尧, 贾述斌, 黄劲松. 图像与激光点云融合的实时目标定位算法[J].导航定位学报, 2023, 11(2): 99-105.(CUI Shanyao, JIA Shubin, HUANG Jingsong. Real-time target positioning algorithm based on image and laser point cloud fusion[J]. Journal of Navigation and Positioning, 2023, 11(2): 99-105.)DOI:10.16547/j.cnki.10-1096.20230211.
2022-05-28
崔善尧(1997—),男,江苏淮安人,硕士研究生,研究方向为自动驾驶多源传感器融合。
猜你喜欢
北京测绘(2022年5期)2022-11-22
汽车观察(2021年8期)2021-09-01
高技术通讯(2021年3期)2021-06-09
中国交通信息化(2019年1期)2019-03-26
电子制作(2018年16期)2018-09-26
电测与仪表(2017年24期)2017-12-19
电子测试(2017年15期)2017-12-18
北京航空航天大学学报(2017年12期)2017-04-23
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
