
一种期刊评价指标数据冗余消除法俞立平
2023-04-25 10:20:34舒光美
现代情报 2023年5期
舒光美

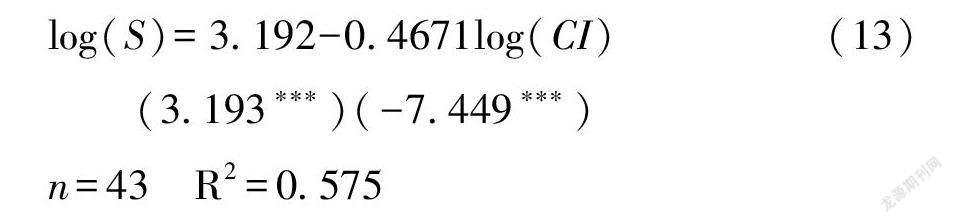
关键词: 独立信息; 评价指标; 数据冗余; 指标体系; 学术期刊
DOI:10.3969 / j.issn.1008-0821.2023.05.011
〔中图分类号〕G302 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 05-0114-09
在学术期刊评价中, 评价指标从不同视角提供了全方位的信息。早期的文献计量指标主要从影响力、来源指标等角度进行评价, 评价指标如影响因子、基金论文比、载文量、地区分布数、平均作者数等, 后面慢慢地拓展到其他视角, 如期刊时效性、网络下载、期刊跨学科特征等, 评价指标如被引半衰期、引用半衰期、Web 即年下载率、扩散因子等。目前, 已有几十余种学术期刊评价指标,这些指标的出现, 丰富了期刊的评价内容, 便于人们从多方面对学术期刊进行评价。
期刊评价指标之间往往是相关的, 因此分离出期刊特有的独立信息非常重要。期刊评价指标数量众多, 并且指标之间的相关度往往较高, 比如影响因子与5 年影响因子, 总被引频次与h 指数等。在多属性评价中, 除了少数采用主成分或因子分析进行降维的评价外, 大多数期刊评价方法均面临着由于评价指标相关导致的重复计算问题, 势必会严重影响评价结果。这是学术评价方法的基本理論问题, 迄今为止缺乏有效的研究, 必须加以重视。
信息价值测度与实现问题是信息社会面临的基本问题[1] 。信息冗余是信息相关问题的另一种表述方式, 必须加以关注。信息论认为, 如果一个信号所包含的信息可以从该系统其他信号中取得, 那么该信息就是冗余信息[2] 。Muller E 等[3] 从社会网络结构角度指出, 如果网络的重复程度低, 每个连接传递的信息都是有价值的。Harrigan N M 等[4] 分析了信息冗余的表现, 包括用户关注许多内容相似的信息, 或者收到许多重复的信息时。秦烁等[5]认为, 信息冗余过于严重会导致信息传播效率低,使信息丧失原有价值。刘伟超等[6] 提出, 当用户的信息需求超过其搜集能力, 导致无法在恰当的时间、以适当的形式对情报进行有效利用时, 就处于“信息冗余” 的困境之中。
关于指标相关问题的解决方法, 目前主要集中在删减指标上。Meyer P E 等[7] 提出, 为了降低信息重叠度, 实现指标的筛选功能, 应采取剔除删除相对不重要的指标的方式。陈洪海[8] 首先建立了信息可替代性标准, 然后剔除冗余信息较大指标,降低了评价指标之间的信息重叠程度。迟国泰等[9]为了解决主成分法无法赋权及合理筛选指标的问题, 提出了基于信息敏感性的指标筛选与赋权模型。蒋艳霞等[10] 通过遗传算法技术, 根据预测模型的预测正确率来选择指标, 以降低指标信息重叠问题。此外, 俞立平等[11] 采用1减去拟合优度R2的方法作为判断指标独立信息的标准。
基于现有的研究, 关于指标信息重叠或数据冗余问题及其后果已经得到了学术界的公认, 对于相关问题的解决方法, 从指标层面, 目前均集中在采用一定的规则删除冗余指标上, 相关研究主要集中在基本方法论上, 而从学术评价角度开展相关讨论的尚处于起步阶段。目前, 以下问题尚需要进一步探讨:
第一, 通过删除指标来降低指标之间相关带来的冗余问题是不得已的办法, 因为被删除的指标仍然包含一些重要的信息, 尤其在期刊数量较多的学科, 删除指标对评价结果的排序可能影响很大。
第二, 关于指标信息重叠的剔除, 目前尚没有有效方法, 有必要厘清思路, 从新的视角探索评价指标消除冗余后的“独立信息”。
第三, 如果采取某种方法获得指标的“独立信息”, 那么这些独立信息的特点如何, 其内涵有什么特征, 相关问题缺乏深入分析。
本文根据期刊评价指标与其他指标的相关度大小以及指标可预测性水平进行评价指标“独立信息” 的测度, 创造性地提出了一种新的测度方法,在此基础上, 首先按期刊综合指标CI 指数分类,分析指标独立信息的特点; 然后按独立信息对期刊进行评价, 分类后分析原始指标的特点; 再比较期刊CI 指数与独立信息评价指标之间的关系; 最后基于BP 人工神经网络, 研究原始指标与独立信息评价值的关系, 从而对期刊独立信息测度方法进行综合评价。
本文的贡献主要是创造性地提出了一种新的期刊评价指标独立信息测度方法, 解决了学术评价与多元统计的基本问题。对于情报学方法与多元统计方法具有开创性的贡献, 研究成果对于学术评价也具有一定意义, 解决了评价指标的数据冗余问题,降低了学术评价的系统误差, 因而具有非常重要的学术价值与应用价值。
1研究方法
1.1独立信息测度的基本原理
本文基于回归分析的基本原理来进行指标独立信息的测度, 如图1 所示。先考虑最简单的情况,假设只有两个评价指标X、Y, 两者具有相关关系,首先用X 作为自变量, Y 作为因变量进行回归, ei为残差。很明显, 具有如下特征:
第一, 当残差ei=0时, 说明该点(Xi,Yi)位于拟合直线上, 此时Yi 完全可以由Xi进行预测, 也就是说, Yi不具有独立信息。极限情况下, 当所有的残差为0 时, X和Y 之间的拟合优度R2= 1,此时Y 可以完全由X 计算得到, 即Y 不包含任何信息。
基于以上分析, 残差ei大小就决定了Yi的独立信息量。由于残差ei既有可能大于0, 也有可能小于0, 而评价指标的独有信息必须大于0, 因此需要取绝对值, 另外, 由于不同指标量纲不同, 显然不能直接用残差大小表示独立信息, 因此本文采用残差绝对值与Y 之比表示独立信息, 简写为Ⅲ(Independent Information Index):
1.2研究框架
本文的研究框架如图2 所示, 在对原始指标的独立信息进行测度后, 为了对独立信息的內涵特征进行综合分析, 主要沿着以下3 条脉络进行分析:
第一, 独立信息的内涵问题。鉴于独立信息是一种全新的处理方式, 其内涵特征有待进一步分析。计算独立信息后, 分析各指标与原始指标的相关系数, 各指标与原始指标的复相关系数, 并进行对比。
第二, CI 指数分类视角下独立信息的特征。基于中国知网CI 指数的分区, 将学术期刊进行分组,一组为Q1 区期刊, 另一组为其他期刊, 在此基础上, 基于独立样本t 检验分析独立信息指标两组均值是否有明显差异, 从而对单个指标独立信息的内涵特征进行分析。
第三, 基于独立信息指标进行评价, 比较CI指数与独立信息评价结果的关系, 从总体视角分析独立信息的特点。
第四, 独立信息评价视角下原始指标的特征。基于独立信息指标进行多属性评价, 然后对评价结果进行分组, 在此基础上, 对原始指标进行独立样本t 检验, 比较均值是否有显著差异, 从另外一个角度分析单个指标独立信息的特点。
第五, 原始指标对独立信息评价结果的解释能力。用原始指标作为输入变量, 独立信息评价结果作为输出变量, 建立BP人工神经网络模型学习模型, 分析原始指标的解释力, 从另外一个视角对独立信息的总体特征进行分析。
以上分析框架既有微观视角的分析, 也有宏观视角的分析, 可以更加全面地对指标独立信息测度方法及其对学术评价带来的影响进行全方位的分析。
1.3研究方法
1) 独立样本t 检验。独立样本t 检验统计量为:
式(3) 中, Xi为样本值, Si为其标准差, ni表示样本量。构造1 个t 检验值, 用来比较评价指标两组均值是否有显著差异。其前提条件是方差齐次性与正态分布, 一般情况下, 独立样本t 检验具有较好的稳健性, 只要样本容量足够, 往往效果较好。
2) BP 人工神经网络。对于采用指标独立信息的评价结果, 分析原始评价指标与其关系, 可以深度感知独立信息的总体内涵。本质上, 这相当于一个黑箱, 原始指标作为输入变量, 独立信息评价结果作为输出变量, 通过建立BP 人工神经网络学习模型, 分析两者的关系是一种全新的思路。
BP 神经网络模型本质上是模拟大脑神经网络的工作原理, 而且其具有分布式并行处理的特征,因而近年来应用越来越广泛[12] 。BP 神经网络包括输入、隐含、输出3 层。每层网络节点可有多个,算法的核心思想是通过调整网络连接的权重使其总体误差最小。
假设输入变量有m 个, 隐含层q 个, 输出变量l 个, 学习步骤如下:
第一, 进行网络初始化, 并给权重系数最小的随机数赋值。
2研究数据
本文以中国知网农业经济期刊为例进行研究,相关评价指标数据来源于《中国学术期刊影响因子年报(人文社会科学)》2020版以及中国知网引文数据库。知网农业经济期刊共51 种, 其中8 种期刊数据缺失, 将其删除, 实际还有43种。
作为一个评价指标相关度解决方法的算例, 本文选取的评价指标有平均引文数、引用期刊数、基金论文比、影响因子、h 指数、即年指标、被引期刊数、Web 即年下载率、总下载量、被引半衰期、引用半衰期。在期刊评价时, 同样基于算例原则,设定所有评价指标的权重相等。所有评价指标的描述统计如表1 所示。
3实证结果
3.1独立信息的测度及与原始指标的相关系数对比
首先进行评价指标独立信息的测度, 其描述统计如表2 所示。即年指标的独立信息数据偏倚情况比较严重, 其他指标总体上尚处于稳定状态。
原始指标与独立信息指标各类相关系数如表3所示。从原始指标与独立信息指标的相关系数看,其平均值为0.210, 总体上相关水平较低, 说明评价指标原始数据与独立信息相差较大, 从另外一个角度说明, 由于评价指标重叠信息的存在, 必将对评价结果产生较大影响。
原始指标与其他指标的复相关系数的平均值为0.889, 总体上水平均较高, 说明冗余比较严重, 即使最小的基金论文比, 其复相关系数也高达0.777,即77.7%的信息由其他指标解释, 只有22.3%的信息是自己的独立信息。而独立信息指标与其他指标复相关系数的均值为0.624, 大大降低了复相关系数, 说明独立信息指标的降低信息冗余效果较好, 能够较好地提高评价精度。
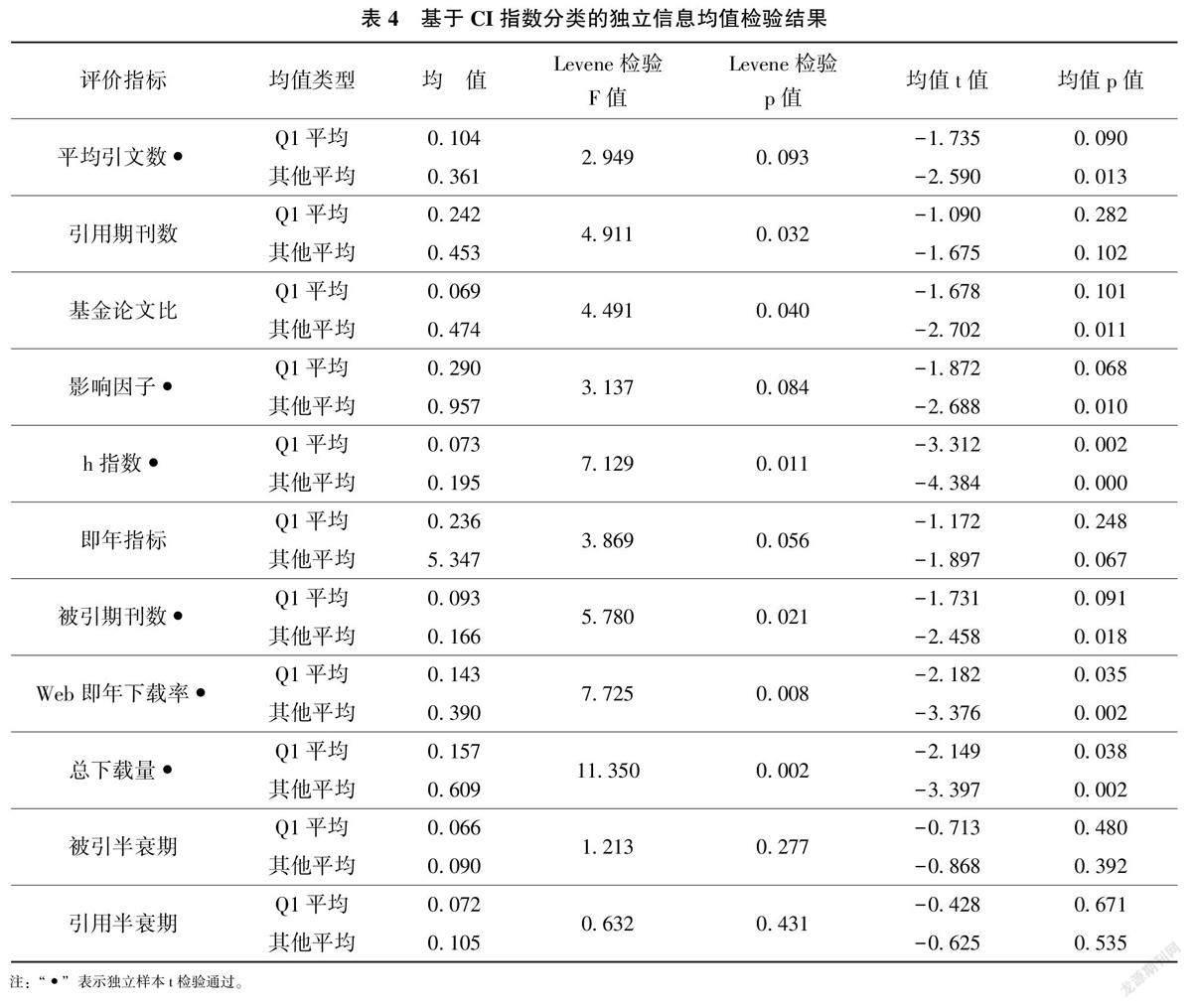
3.2基于CI 指数分区的独立信息指标特征分析
根据CI 指数, 农业经济期刊分为Q1、Q2、Q3、Q4 共4 区, 为简捷起见, 本文区分Q1 区期刊与其他区期刊, 其中Q1 区期刊共12种, 其他期刊31 种。CI 指数根据总被引频次和影响因子计算而来, 其计算公式如下:
式(12) 中, A为影响因子, B为总被引频次,k为权重调节系数, 根据量效指数进行适当调整。
独立样本t 检验结果如表4所示, 平均引文数、影响因子、h 指数、被引期刊数、Web 即年下载率、总下载量通过了统计检验, 其他指标独立信息没有通过统计检验。主要原因是CI 指数与期刊影响力高度相关, 因此, 期刊影响力指标以及和期刊影响力指标高度相关的指标就通过了统计检验。通过统计检验的指标中, 除影响力指标外, 平均引文数一定程度上说明期刊论文质量高, 容易被引, 而Web 即年下载率和总下载量本质上也是期刊影响力指标。作为影响力指标的即年指标没有通过统计检验, 主要原因可能是其数据偏倚比较严重造成。
从通过独立样本t 检验指标的均值看, 相对优秀的Q1 区期刊的独立信息均值都小于其他一般期刊。即使是没有通过统计检验的指标, 相对优秀的Q1 区期刊的独立信息均值也小于其他一般期刊,从这个角度可以看出, 独立信息属于反向指标。
3.3基于独立信息指标的学术期刊评价及其比较
作为一个算例, 基于等权重对所有独立信息指标进行加权汇总, 得到独立信息评价结果, 将其排序与CI 指数进行对比, 结果如表5所示。两者排序相差较大, 主要原因是独立信息提供了更多的信息, 而CI 指数提供的只是期刊影响力信息。
独立信息评价结果S 与CI指数的回归结果如下:
两者相关度中等, 回归系数为-0.467,并且通过了统计检验, 说明独立信息越小, 期刊影响力越大。
采用独立信息评价, 本质上是发挥各指标所提供的独立信息功能, 并且减少了信息冗余, 这样独立评价结果就和以影响力为主的CI 指数评价结果相差较大, 说明独立信息评价在减少冗余的同时能够提供评价的全方位信息。
3.4基于独立信息评价结果分类的期刊原始指标信息分析
根据CI 指数分区中Q1 区期刊的数量, 将独立信息评价结果分为12 种优秀期刊与31 种一般期刊, 再对原始指标进行独立样本t 检验, 以分析独立信息评价结果的侧重点和信息量, 结果如表6 所示。需要说明的是, 由于独立信息评价结果与CI指数负相关, 因此在筛选12 种独立信息评价优秀期刊时, 采取的是“越小越好” 原则。
原始指标独立样本t 检验的结果表明, 采用独立信息评价的优秀期刊与一般期刊, 平均引文数、基金论文比、影响因子、h 指数、即年指标、被引期刊数、Web 即年下载率、总下载量均通过了统计检验, 只有引用期刊数、被引半衰期、引用半衰期没有通过统计检验, 并且通过统计检验的指标中, 优秀期刊的相关指标均值均高于一般期刊, 这说明采用独立信息评价能够更好更全面地反映期刊相关信息。
3.5原始指标与独立信息评价结果的神经网络预测
建立3层BP神经网络模型, 输入变量为原始评价指标, 输出变量为学术期刊独立信息评价结果, 用来分析独立信息对原始指标信息量的解释程度。典型神经网络的预测的拟合结果如图3 所示,拟合度具有较高水平。由于BP神经网络模型每次训练的结果均不一致, 因此训练5 次, 取5 次的平均结果, 如表7 所示。
从BP 神经网络的预测结果看, 独立信息评价结果与原始指标的相关系数的平均值为0. 985, 拟合优度的平均值为0.961, 具有极高的相关度, 说明采用独立信息评价可以充分展示原始指标的各类信息。
4研究结论与讨论
4.1研究结论
1) 由评价指标之间的相关性导致的信息重叠问题需引起足够的重视。在学术期刊评价中, 建立指标体系采用多属性评价是一类重要的评价方法,但由于文献计量指标之间往往相关性比较严重, 带来数据的冗余问题, 导致信息重叠, 严重扭曲专家权重, 从而使评价结果产生较大的误差, 降低了评价方法的科学性, 这个问题必须尽快加以解决。
2)基于回归的独立信息测度方法提供了一种较好的解决思路。本文基于多元回归原理, 采用残差绝对值除以原始指标的比值作为独立信息的一种测度方法, 这是一种全新的解决方法。研究结果表明,原始指标与独立信息指标的相关系数仅为0.210,说明独立信息指标能够提供更多的信息。独立信息指标的平均复相关系数与原始指标相比降低了30%,这也进一步说明独立信息指标较好地解决了指标信息重叠问题。此外, 基于原始指标与独立信息评价结果的人工神经网络分析也顯示, 独立信息包括了原始指标的绝大多数信息, 相关系数为0.985, 拟合优度为0.961, 具有极少的信息损失。
3) 独立信息指标是一个反向指标。根据CI 指数分类的独立信息独立样本t 检验的研究结果, 以及根据独立信息评价结果分类的原始指标独立样本t 检验的研究结果均表明, 独立信息指标均是反向指标, 此外, 独立信息评价结果与CI 指数也是负相关, 这充分说明, 根据本文方法计算得到的独立信息评价指标是反向指标。
4) 独立信息指标能够反映原始指标的“元信息”。根据CI 指数分级, 对独立信息指标的独立样本t 检验结果表明, 平均引文数、影响因子、h 指数、被引期刊数、Web 即年下载率、总下载量通过了统计检验, 引用期刊数、即年指标、被引半衰期、引用半衰期没有通过统计检验, 因为通过统计检验的指标, 总体上与影响力相关, 而CI 指数主要测度的就是影响力, 所以与影响力相关指标的独立信息能够较好地反映期刊的影响力。
根据独立信息评价结果分级, 对原始指标进行独立样本t 检验, 绝大多数指标均通过了统计检验, 只有引用期刊数、被引半衰期、引用半衰期没有通过统计检验, 这说明基于指标独立信息进行评价, 拥有更好的信息广度。
以上研究充分说明, 独立信息指标能够反映原始评价指标的原始信息, 也可以称为“元信息”,这是非常重要的, 也是独立信息指标测度方法正确的另一种佐证。
4.2讨论
本文根据农业期刊数据进行了实证研究, 对于其他学科期刊的指标独立信息测度及其深入分析,有待进一步研究。此外, 本文研究方法需要大样本数据支持, 因此, 当期刊数量较多时效果会更好。
猜你喜欢
宁夏医学杂志(2020年4期)2020-03-01 13:16:20
宁夏医学杂志(2020年3期)2020-02-27 14:17:11
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:34
领导决策信息(2017年11期)2017-05-17 04:49:12
水利科技与经济(2017年6期)2017-04-28 08:30:06
商(2016年33期)2016-11-24 23:50:25
中小企业管理与科技·上旬刊(2016年10期)2016-11-15 09:44:40
中国市场(2016年38期)2016-11-15 00:01:08
中国市场(2016年33期)2016-10-18 13:33:29
世界科学(2013年6期)2013-03-11 18:09:36
