
基于ISSA-LSTM模型的短时交通流预测
2023-04-21 13:10王海晨
计算机技术与发展 2023年4期
陈 雄,王海晨
(长安大学 信息工程学院,陕西 西安 710064)
0 引 言
进入21世纪以来,随着人们的生活水平不断提高,私人汽车拥有量持续攀升,伴随而来的就是交通流急剧增长、交通拥堵问题越来越严重。实时精确的交通流量预测能够帮助出行者选择合适的出行方案,提高出行效率,有效缓解城市交通的压力,提高道路资源的利用率,对于交通管控和规划具有重要的价值[1-2]。
对交通流进行预测,不同时期有不同的方式,早期是使用基于统计分析的预测方法,如差分整合移动平均自回归模型ARIMA[3]、卡尔曼滤波模型[4]等。这类统计模型对于数据会有比较高的要求,只能预测对精度要求不高的场合,对具有较高随机性的交通流数据无法很好地拟合,不能处理实时突发性的交通状况。
交通流数据受多方面因素影响,有着复杂的非线性特征,基于统计分析的预测模型存在局限性,因此出现了一些非线性预测模型,拟合数据的非线性特征。如小波分析预测模型[5]将时间序列分解为不同的信号序列,然后再对这些序列分别预测,将预测结果合成得到最后的预测结果。该模型在预测精度上优于基于统计分析的模型,但是其计算量大,需要配合其他预测模型进行预测,且理论复杂,可用性不高。
伴随着交通数据量的增长,能够处理大量数据的机器学习和深度学习的模型在交通流预测方向已经发展起来。与之前的模型相比,机器学习和深度学习不对数据分布进行基本假设,有较强的学习能力和挖掘数据深层特征的能力,预测精度有显著提升。经典的机器学习模型有支持向量机(SVM)[6]、K近邻算法(KNN)[7]等,深度学习模型有BP神经网络[8]、LSTM网络等。其中LSTM模型由于其循环性结构和长期记忆能力,在处理大数据量的时序问题上有着巨大的优势,预测精度更高、效果更好。如陈治亚[9]使用LSTM进行多维度的交通流预测,探究各种维度对于模型预测精度的影响;罗向龙[10]提出了基于KNN-LSTM的预测模型,预测准确率相较传统模型有显著提高;张阳[11]将改进小波包分析算法和LSTM相结合,提高了在样本数量较少时模型的可用性和预测精度。但是LSTM模型预测结果的好坏与神经元数量、学习率等超参数有着直接的关系,且其超参数通常受经验影响,有着较强的主观性,需要进行大量的调试。因此,如何优化LSTM、确定合适的超参数来进行模型的训练是一个难题。
针对以上问题,该文提出了一种基于改进麻雀搜索算法与长短时记忆网络的交通流预测模型。利用SSA优秀的全局搜索能力对LSTM模型的两个关键参数(隐藏层神经元数目和学习率大小)进行优化,并且改进了SSA算法麻雀初始化时位置分布随机的特点,使其能均匀地分布在各个维度,避免出现局部最优的结果。根据优化后的参数构建ISSA-LSTM组合预测模型,减少了参数选择过程中人为因素的影响,提高了模型的泛化能力,也在一定程度上提高了LSTM模型的预测精度。模型在Python3.8的keras API环境下进行预测实验,将预测结果与BP、GRU、LSTM、PSO-LSTM、SSA-LSTM网络的预测进行对比,从而证明其具备良好的预测精度和预测稳定性。
1 研究方法
1.1 LSTM网络
长短时记忆网络(long short-term memory)是一种时间循环神经网络,简称LSTM,它是循环神经网络RNN的变体,在一定程度上解决了传统RNN在训练过程中容易出现的梯度爆炸和消失问题。LSTM引入输入门、遗忘门和输出门,设置三个门相应的门限来调节长期记忆信息和短期记忆信息的记忆和遗忘程度,还引入了细胞状态来保存长期记忆信息,从而有效地缓解模型训练中的梯度爆炸和消失问题,LSTM的结构如图1所示。

图1 LSTM结构示意图
其中,遗忘门的作用是将上一个细胞状态中传下来的信息进行有选择地遗忘,公式为:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
输入门的作用是将当前时刻有价值的信息更新到细胞状态中,公式为:
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
输出门的作用是输出当前时刻的细胞状态和当前时刻LSTM网络的输出值。具体表达式为:
Ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=Ot*tanh(Ct)
(6)
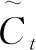
1.2 SSA算法
麻雀搜索算法(sparrow search algorithm,SSA)是受到麻雀在觅食过程中不同分工所做出的不同行为的启发而提出的群智能优化算法,其全局的搜索能力强、搜索精度高、稳定性好,在一定程度上优于现有算法[12-14]。
在觅食的过程中,麻雀有两种不同的分工:发现者和加入者。发现者的觅食范围大,容易发现食物,在算法中体现为适应度的函数值小。发现者在找到食物后,将食物所在的地方提供给其他发现者和加入者,而食物通常是有限的,距离食物地点较远的麻雀来不及获取食物,只能自己再从其他地方去找。在这个觅食的过程中,如果某只加入者先找到食物,它就自动成为发现者,而发现者的数量是固定的,因此就会有一只发现者变成加入者,保持寻找食物的麻雀占麻雀总体比例的平衡。同时,种群中还有一定比例麻雀会进行侦察预警,当发现危险时,它们会迅速转向其他安全区域进行觅食,负责侦察预警的麻雀和他们本身分工并不冲突,即预警麻雀可能是发现者,也可能是加入者。
SSA算法发现者位置迭代公式如下:
(7)

加入者位置迭代公式如下:
(8)

进行侦察预警的麻雀在种群中的初始位置是随机产生的,其位置迭代公式如下:
(9)
式中,Xbest是当前的全局最优位置,β和K(K∈[-1,1])是步长控制参数,且都是随机数,β服从方差为1、均值为0的正态分布。fi、fg和fw分别是当前麻雀个体、当前全局最佳和最差的适应度值。ε是一个为了防止分母出现零(fi=fw)而加入的极小常数。当fi>fg时,表示该麻雀的适应度值不是最优适应度值,即麻雀在种群的外围位置,这个时候麻雀为了安全会向全局最优位置Xbest的方向移动;fi=fg时,表明麻雀处于中心位置,此时该麻雀的最优解就是靠近周围的麻雀,减轻自己被捕食的风险。
1.3 ISSA模型
SSA算法在对函数进行优化时,其种群的位置初始化通常是完全随机的,麻雀在各维度空间的分布是不均匀的,这会导致算法的收敛性变慢,且容易得到局部最优解。而混沌序列在一定范围内具有随机性、规律性以及便利性的特点,其能够使麻雀在初始化时分布更加均匀、提高全局搜索能力、维持种群的多样性。
现有的混沌映射主要有Logistic映射、Tent[15]映射等。不同的混沌映射对于提高函数的优化能力有很大区别,Logistic映射本身分布不均匀,有较高概率分布在[0,0.1]和[0.9,1]区间,这会影响其寻找最优解的速度和难度。而Tent映射能将参数更均匀分布在各个维度,遍历均匀性更好,因此,该文将利用Tent映射初始化种群的位置,其表达式为:
(10)
当u=0.5时,Tent映射得到的序列分布最均匀,此时的公式为:
(11)
使用公式(11)对麻雀的初始位置进行初始化,具体为:
yn+1=xn+1(ub-lb)+lb
(12)
其中,ub、lb分别是参数在各维度的上下限,xn+1是在[0,1]区间均匀分布的混沌序列。
1.4 ISSA-LSTM模型
实践证明,LSTM的预测精度与隐藏神经元和学习率有很大关系。隐藏层神经元数目一般是凭经验加以调试,而学习率在keras的Adam优化器中默认为0.001,都无法确定是否选择了最优超参数。
考虑到隐藏神经元和学习率对最终预测精度的影响,为了使预测达到最好的效果,该文通过ISSA算法来确定使LSTM网络预测精度最佳的隐藏神经元和学习率。ISSA-LSTM预测流程如图2所示。

图2 ISSA-LSTM预测流程
首先,确定ISSA-LSTM模型的初始参数:ISSA算法的麻雀数量、迭代次数和预警麻雀的安全值的大小;LSTM的隐藏层神经元数目和学习率大小的取值范围。根据LSTM这两个参数的取值范围,利用Tent映射对麻雀位置进行初始化。
其次,将麻雀位置对应的参数作为LSTM模型的参数的输入,将建立的LSTM模型在训练集上进行训练。将训练好的模型在测试集进行测试,得到每次测试的均方根误差RMSE。由于神经网络每次训练的效果有一定的偏差,本实验取3次训练RMSE的最佳值作为适应度值返回给ISSA算法。
然后,根据麻雀适应度值的大小确定其分工,前20%的麻雀为发现者,剩下的为加入者。按照20%预警麻雀的比例,随机确定此次迭代的预警值大小和负责预警的麻雀位置,记录最佳和最差的适应度值和对应的麻雀位置。
通过公式(7)、(8)分别对发现者和加入者的位置进行更新,然后再根据公式(9)更新预警麻雀的位置。
将更新后的位置所对应的数据作为LSTM模型的参数输入,重复之前过程,得到新的适应度值,然后更新麻雀分工。对比之前记录的最佳和最差适应度值,更新最佳和最差适应度值及其对应位置。
重复上述步骤,直到达到最大迭代次数,输出本次算法迭代得到的最佳适应度值及其对应的位置参数信息,将此参数设置为LSTM的超参数,构建ISSA-LSTM模型,对交通流数据进行预测,得到模型的最终预测结果。
2 实 验
2.1 实验数据与数据预处理
实验数据是从英国高速公路交通流数据集网站下载的M25公路4916A检测点的数据,该数据集每隔15分钟采集一条数据,从2021年1月1日到2021年1月31日共2 976条数据,有Local Date、Local Time、Total Carriageway Flow、Speed Value等11个特征。Local Date和Local Time是单条数据所采集的时间,Total Carriageway Flow是15分钟内经过该检测点的车流量总量,Speed Value是15分钟内经过该监测点的车流的平均速度。该数据集还有关于车长的属性,根据公式(13)计算道路占有率。
(13)
设定一个Festivals属性,查询2021年1月1日至2021年1月31日英国的节假日及周六日,将相应的属性值设为1,其余默认为0。经过处理后的数据集部分数据如表1所示。

表1 4916A监测点数据集部分数据
该数据集的交通流量、占有率、速度趋势如图3所示。经处理后的数据集共有Total Volume、Occupancy、Speed、Festivals四个特征输入。由图3可知,交通流量在不同时间段差异巨大,其最大车流为1 502辆,最小车流为23辆,平均值为488辆。为了便于预测,需要将数据进行归一化处理,将交通流数据映射到[0,1]范围内,采用MinMaxScaler函数进行归一化,具体公式是:
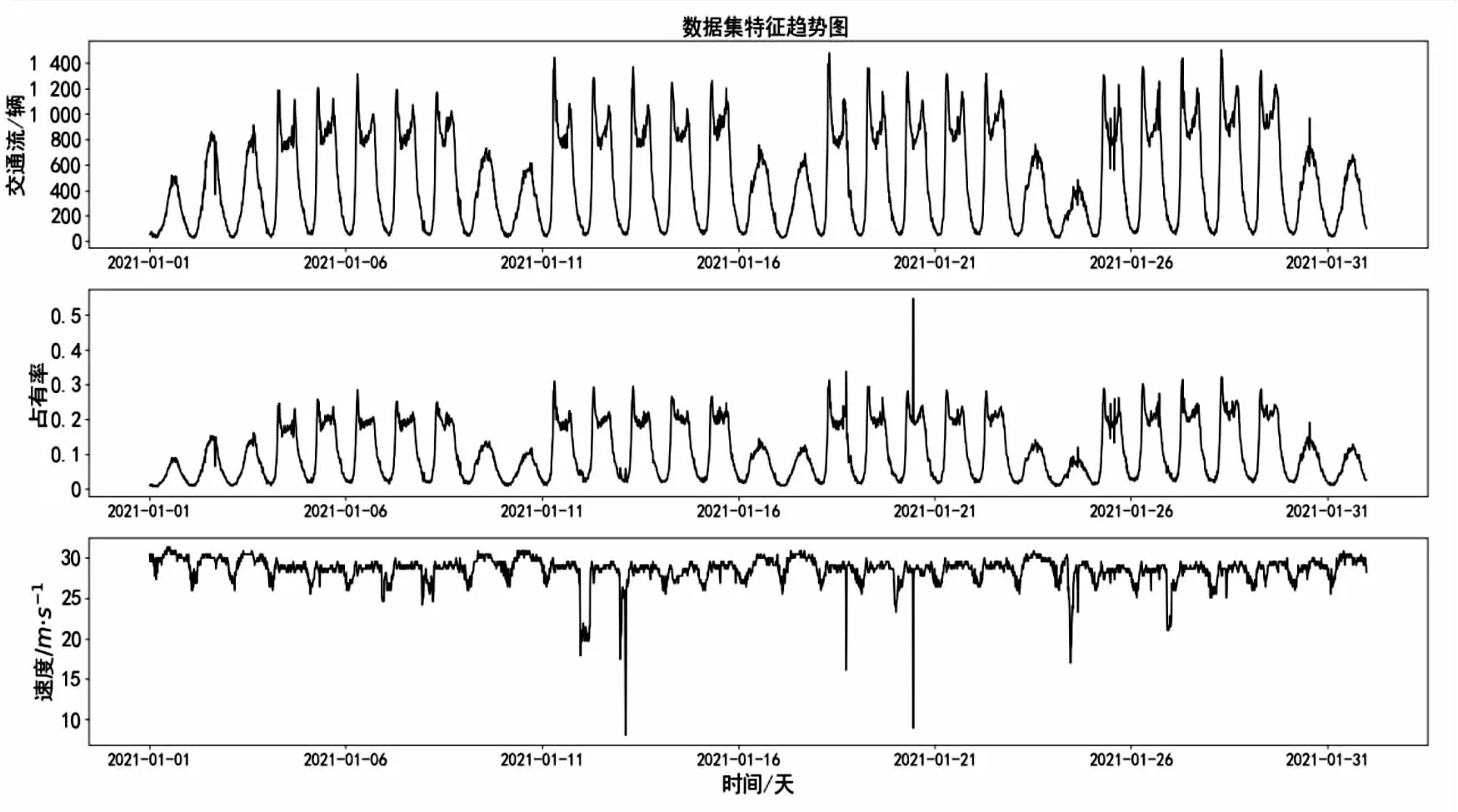
图3 数据集特征趋势
(14)
其中,x是车流量,min(x)、max(x)分别是交通流的最小值和最大值。
数据处理完后,按照8∶2的比例将数据分为训练集和测试集。
2.2 模型评价标准
该文选取的评价指标有RMSE、MAE、MAPE、R2。RMSE是均方根误差,MAE是平均绝对误差,MAPE是平均绝对百分比误差,R2是决定系数。计算公式如下:
(15)

(16)
(17)
(18)

2.3 ISSA-LSTM模型参数选择及优化结果
ISSA-LSTM模型中,LSTM由输入层、一个隐含层和输出层组成,隐藏层神经元数目和学习率范围分别设定为[1,300]和[0.000 1,0.005]。为了比较ISSA-LSTM模型同现有模型的区别,实验将BP、GRU、LSTM、PSO-LSTM、SSA-LSTM模型放在相同数据集上预测,其中PSO-LSTM、SSA-LSTM分别为粒子群算法和原始麻雀算法优化LSTM。LSTM、GRU的隐藏层神经元均为256,学习率为Adam默认值,迭代次数为300,BP迭代次数为1 000,学习率为0.01,decay为0.005。这些数据是经初步调参得到的值。为了避免模型出现过拟合现象,加入dropout层,参数0.2。PSO和SSA、ISSA三种模型的种群数量和迭代次数均为50,且除神经元和学习率外的其他参数均与LSTM参数相同。利用1.4节流程进行参数寻优,图4为ISSA、SSA和PSO寻优过程中适应度值迭代结果。

图4 适应度值收敛曲线
从图4可见,SSA和ISSA算法要比PSO算法收敛快,且ISSA算法收敛精度比SSA算法和PSO算法都高,ISSA在第12次迭代时出现最优适应度值,对应的最小RMSE是43.012,隐藏层神经元个数为108,学习率为0.001 5。六种模型对交通流进行预测得到的结果如图5所示。
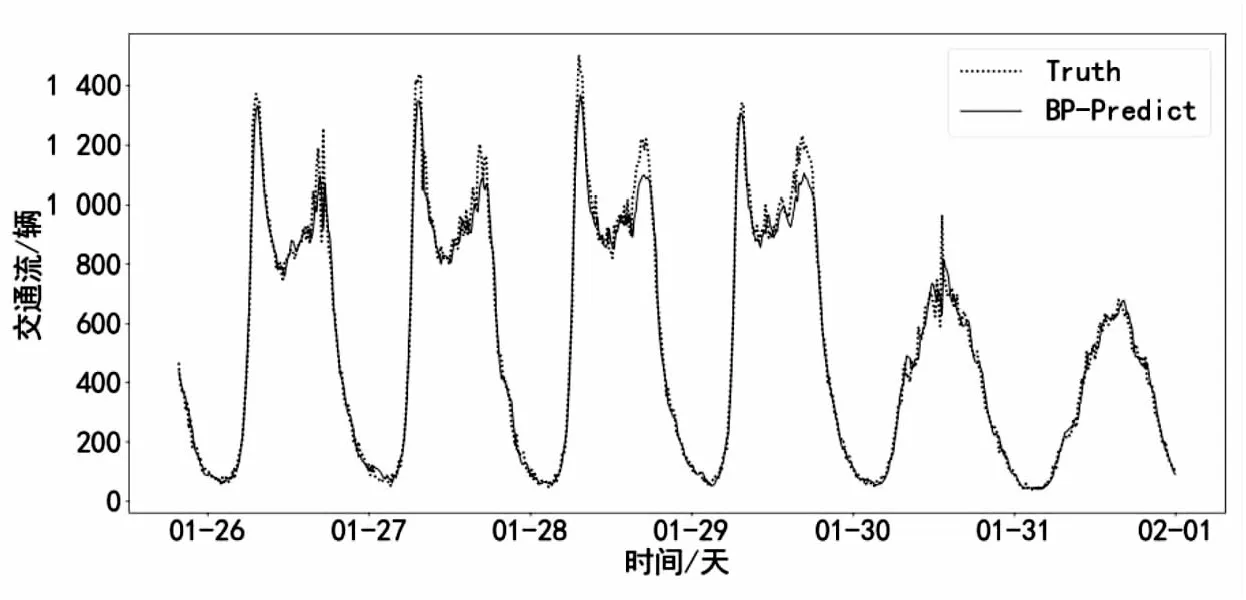
(a)BP
2.4 实验结果与分析
图5(a)是BP网络的预测效果,BP网络不能提取数据的时序特征,因此预测效果比其他网络的拟合效果差,数据的拟合出现了明显的偏差。而从图5(f)可以看出,ISSA-LSTM组合模型预测值与真实值有较大部分的重合,只有少部分拟合效果欠佳。6种模型对应的指标评价结果如表2所示。
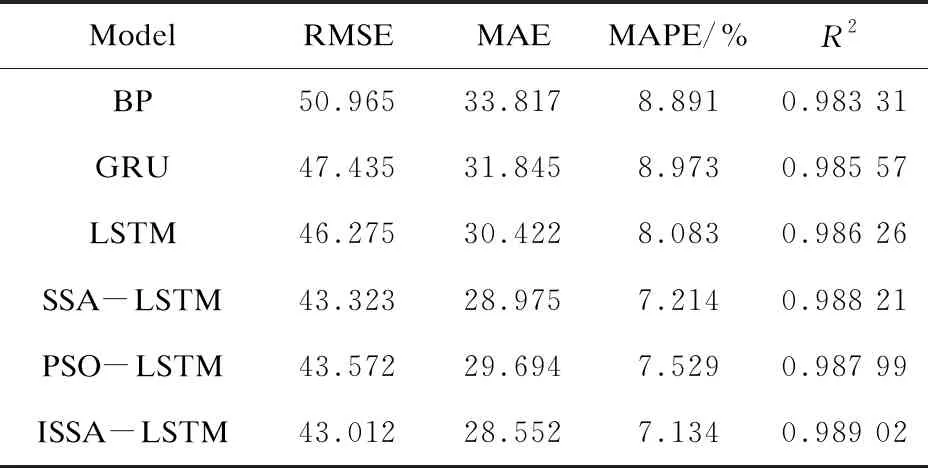
表2 模型评价指标
由表2可知,BP网络的确在拟合上的效果不佳,其RMSE、MAE、MAPE均显著高于其他几种网络的相同指标。GRU和LSTM网络能够提取数据的时序特征,因此预测效果比BP好,但是其参数仍有进一步优化的空间。从表中数据来看,提出的ISSA-LSTM模型效果最好,其RMSE为43.012,MAE为28.552,MAPE为7.134%,R2为0.989 02。ISSA-LSTM的RMSE相较于LSTM模型下降了3.263,MAE下降了1.87,MAPE下降了0.949百分点,R2上升了0.276百分点,相较于其他模型,ISSA-LSTM模型的各项评价指标效果均为最好,因此,ISSA-LSTM模型在短时交通流预测上有很好的预测效果。
3 结束语
为了更加准确地预测短时交通流,该文提出了使用ISSA优化LSTM参数的交通流预测模型。初步证明了经过优化后的ISSA算法在参数寻优方面有很好的效果,也为优化预测模型提供了思路。ISSA算法在第12次就迭代到最小,说明算法收敛较快,且实验结果表明,ISSA算法优化LSTM较SSA算法和PSO算法优化LSTM预测上效果更好。但实验还是存在一定局限性,交通流不是单纯的时序数据,其还会受到天气和空间位置等因素的影响,如果将天气等其他因素加入预测会有更好的效果。
猜你喜欢
作文小学中年级(2019年10期)2019-11-04
新世纪智能(高一语文)(2018年11期)2018-12-29
法律方法(2018年2期)2018-07-13
趣味(语文)(2018年2期)2018-05-26
魅力中国(2017年6期)2017-05-13
中学生数理化·八年级物理人教版(2017年11期)2017-02-15
西南交通大学学报(2016年3期)2016-06-15
山东青年(2016年1期)2016-02-28
中国工程咨询(2016年1期)2016-02-14
数学年刊A辑(中文版)(2014年1期)2014-10-30
