
基于数据起源提升高校数据质量的方法研究
2023-04-21 13:10袁旭琦李景奇
计算机技术与发展 2023年4期
杨 莉,袁旭琦,李景奇
(1.河海大学 网络与信息技术中心,江苏 南京 210024;2.江苏省水利工程科技咨询股份有限公司,江苏 南京 210029)
0 引 言
随着《教育信息化2.0行动计划》的颁布,教育改革与发展的核心内涵更强调一个“化”字——数据化、服务化、智慧化[1-2]。如何科学地运用信息技术有效地催化教育数据“发酵”,创新地促进教育、科研、管理的服务方式,已经成为教育信息化的核心工作[1]。
然而,目前高校的教育数据普遍存在“发酵”能力不足的现象,例如:数据共享能力不足,缺乏数据质量管理制度和体系,开放的高质量数据太少,等等。这些“发酵”能力不足的现象,归根结底,在于数据质量达不到数据使用的期望和需求。如何提升数据质量受到越来越多的关注。目前,国内高校经过数十年的信息化建设发展,许多已经进入智慧校园建设阶段,也逐渐意识到数据质量问题成为了限制学校信息化进一步发展的绊脚石,所以陆陆续续建设了数据治理平台,拟通过数据梳理、确权调研、数据清洗、质量评估、质量管理等提升数据质量。但目前实施的高校数据治理,大多仅公共数据平台管理员和业务数据管理员参与其中,甚至仅有公共数据平台管理员参与其中,而普通的师生用户往往对数据质量一无所知,也无法参与到数据治理的环节中,使得数据治理缺少良性互动、无法形成治理合力,而最终流于形式。
而数据起源不仅能很好地记录数据的来源和治理过程信息,在判断数据的质量和可信度方面也有非常重要的意义。所以,该文将数据起源引入到数据治理的过程中,从两个方面探索提升高校数据质量的方法:一是基于数据起源记录数据变化过程的特性,提出了提升数据质量的治理构架,通过数据起源记录数据治理的过程,特别是用户反馈的过程,并展现给数据使用者,让数据使用者明晰数据治理的进展,方便其反馈数据的质量,形成数据治理的闭环;二是基于数据起源对数据质量评估的作用,设计了一种数据质量评估方法,将用户反馈的过程转化为可定量评估的数据质量,并结合基于规则的数据质量评估方法,实现定性+定量的数据质量的综合评价,并通过提出的治理构架展现给数据使用者,辅助其参与到数据治理的过程中。
1 相关技术
1.1 数据起源及可信度
数据起源(Data Provenance,Data Lineage,Data Pedigree,Data Derivation),又称为数据世系、数据来源、数据血统、数据血缘等等,指产生数据的原始数据及其一系列的演化过程[3-4]。数据起源在数据质量评价[5]、数据核查、数据恢复及数据引用等方面都具有非常重要的意义[6],具体为:(1)分析数据起源信息,实现数据质量、可靠性评价[4];(2)根据数据起源审计、追踪数据出处[4];(3)重现数据演变过程、重造数据;(4)对数据的版权和知识产权进行管理;(5)快速定位出错位置,确定错误原由;(6)解析数据现状的产生原因。
Batini和Scannapieco[7]分析了数据质量的各种问题及评估和提升数据质量的主要方法,强调对数据来源和数据可信度的关注。张志强等[8]着重分析了基于数据源依赖关系的数据评价方法,并通过改进ACCU算法,实现基于数据源依赖关系的数据源间可信度计算,提高了数据质量计算的精度。Nicolas PRAT等[5]从信任度、合理性及暂时性三方面衡量数据质量可信性,构造了一个起源模型,基于所有数据源和处理历史设计了数据可信性评估的计算方法。
1.2 数据质量及评估
数据质量一般定义为“数据适合使用的程度”,是一个多维度的概念,包括准确性、完整性、一致性和时效性等[9-11]。数据质量评估是通过度量数据的综合特征来估计数据质量与数据价值的过程[12-13]。
业界对于数据质量的维度已经有相当多的成熟的研究,例如Strong-Wang[9]提出数据质量包括内在、语境、表达、访问等4大类质量和15个指标;Thomas Redman[14]制定了一套基于数据结构的20多个数据质量维度;DAMA UK分会2013年发布的一份白皮书,描述了6个核心数据质量维度——完整性、唯一性、及时性、有效性、准确性、一致性,并描述了置信度、可用性等其他对质量有影响的特性。
数据质量评估方法,一般可分为三类:定性评估、定量评估和综合性评估。常见的定性评估方法有用户反馈法、专家评议法和第三方评测法[15-16]。定量评估多是通过规则、算法实现对数据质量的度量,也是较多研究者的关注重点。综合性评估是定性和定量的有机结合,常见的有德尔菲法、层次分析法、扎根理论等。例如,蔡莉等[17]利用层次分析法对构建的评估体系中的质量指标进行权重赋值,宋俊典等[18]提出了一种面向多维度数据质量的模糊综合评价方法。
1.3 数据治理与提升
数据质量来源于数据产生的过程,其优劣直接影响数据价值的高低,进而影响管理者的分析和决策[12]。数据质量问题的出现催生了数据治理技术,提高数据质量也成了数据治理的核心目标之一[19]。
郝志杰等[20]从战略目标、组织架构、数据标准、数据集成、数据质量、数据仓库六个方面提出了高校数据治理框架,并基于“一张表”工程进行了具体的应用和实践。刘雅琴等[21]则是从高校数据管理现状出发,提出了“一张表”平台的技术架构,并通过网上办事大厅和“一张表”平台建设,提升了高校教师的数据质量。张国宝等[22]系统阐述了智慧校园中数据质量的若干问题,设计了统一的数据管理服务平台体系,针对性地解决数据不一致、不准确等质量问题。陆成松等[23]则从对高校数据劣质问题的原因分析中,通过借鉴PDCA循环理论,从制度、标准、策略、工作内容等方面构建了数据治理体系,从而实现数据质量的提升。
综上,数据起源不仅可以记录数据来源和治理过程,而且在数据质量评价方面有着不可估量的作用。所以,将数据起源引入到数据治理中,对于提升数据质量,具有非常重要的研究价值和探索意义。
2 数据起源标注模型
为了记录数据来源和数据治理的过程,需要对数据起源信息进行收集,所以需要建立一个模式及实现模式的模型来描述数据来源和处理步骤。针对数据治理过程重现和质量评估的要求,本节设计了一种数据起源标注模型,并对模型中的属性用本体描述语言OWL-S进行数据起源约束性描述。
2.1 标注模型及其细化
为了提高数据起源存储和查询的性能,该数据起源模型仅包含治理过程信息及必要的数据来源信息,包括什么人、通过什么环境、什么时间、对哪个源数据、实施了怎样的治理。因此,将数据起源定义为数据治理过程中实施治理前(后)数据的产生及其演变过程。因为数据治理是一个过程性的动作,所以设计的是一种过程标注模型,包括六大部分:Process、Time、Parameter、Data、Agent、Instrument。图1是具体的过程标注模型及其细化。

图1 过程标注模型及其细化
(1)Process。
Process是一系列的数据治理实施过程。例如:数据使用者会对数据进行质量反馈,经业务管理员检查确认后,会执行更新数值项操作。具体将在2.2节介绍。
(2)Time。
Time描述Process的执行时间信息,包括Begin和End,代表Process开始执行的时间和结束的时间。具体如代码1所示。
代码1:Time约束描述。
(3)Parameter。
Parameter是Process实施的业务数据的参数信息,包括数据现值UseValue、数据源Source、治理标签Label、数据治理置信度Confidence。Label分为未实施治理、实施治理中、治理完成三类;Confidence表示数据治理的置信度[7],取值[0,1],数值越高表示数据治理过程的可信性越高。具体如代码2所示。
代码2:Parameter约束描述。
(4)Agent。
Agent是Process中涉及到的一切治理主体总称,包含三类:数据使用者User、数据提供者Provider和数据平台管理者Manager。User通过各种应用/服务使用数据进而对数据质量进行评估、反馈;Provider指源数据的业务管理员,是源头数据治理的实施者;Manager对业务数据执行采集、清洗、对标、转换等操作,并对其进行数据质量检测。具体如代码3所示。
代码3:Agent约束描述。
韩莎是被宠着长大的,向来说一不二,一听这话,立马冲到门口穿鞋:“你不买,那我回家找我爸,让他给我买……”
(5)Data。
Data是Process执行中所用到或所产生的数据集合,包括实施治理前的数据原值Original和治理后的现值Government。具体如代码4所示。
代码4:Data约束描述。
(6)Instrument。
Instrument是Process执行过程中反馈数据问题的工具,包括名称Name、业务应用/服务环境Environment及反馈内容描述Description。具体描述详见代码5。
代码5:Instrument约束描述。
2.2 Process起源构成
Process是一系列提升数据质量的治理实施过程,是标注模型的核心,与实施治理的主体有着非常重要的关系,该文从多元治理主体视角下分析确定Process起源的基本构成元素。
2.2.1 多元治理主体视角下的数据质量治理
根据Batini等[11]对数据质量定义可知,一般从数据准确性、完整性、一致性、时效性四方面进行提升数据质量的治理。具体为:
(1)数据准确性治理:包括语法和语义两个维度。语法准确性治理是指其与数据标准的治理实施,由于业务系统的历史遗留和不干扰原则,一般不对源头数据进行语法准确性治理,而是对集成到公共数据平台的共享数据进行语法准确性治理,即数据的清洗、转换、对标,该过程无需数据提供者变更源头数据;而语义准确性治理指数据值不准确的治理,一般由数据使用者通过反馈的方式,经由数据提供者检查、核实后进行数据值的更新;
(2)数据完整性治理:指数据缺失、不完整的治理,涉及各个维度是否有足够的数据,比如一个列由空变为填充具体的值,需要从源头去进行数据值的更新;
(3)数据一致性治理:一般为不同业务数据间的不一致处理,由于该类治理从源头执行可能会影响到业务系统的功能,所以一般在公共数据平台对集成的共享数据进行一致性治理操作,所以该类治理也是无需数据提供者操作的;
(4)数据时效性治理:指数据是否为最新的数据。由于数据从业务源集成到公共数据平台,再从公共数据平台下发到第三方系统,天然地存在数据时差,不好衡量其实施质量,所以该类治理不在该文研究范围内。
进一步地,从多元治理主体治理视角,语法准确性治理、语义准确性治理、数据完整性治理、数据一致性治理具体过程如下:
(1)语法准确性治理,由数据平台管理员对集成到公共数据平台的业务数据实施,单向性过程,无需数据提供者复核,具体如图2(a)所示;
(2)语义准确性治理,由数据使用者反馈到数据提供者,再经数据提供者核实、更新,最终再由数据使用者分析、评估、反馈。该过程是双向性且可能存在多次循环,具体如图2(b)所示;
(3)数据完整性治理,由数据使用者或数据平台管理者反馈,再经数据提供者核实、更新,最终再由数据使用者、数据平台管理者分析、评估、反馈。是双向性过程,且可能存在多次循环, 具体如图2(c)所示;
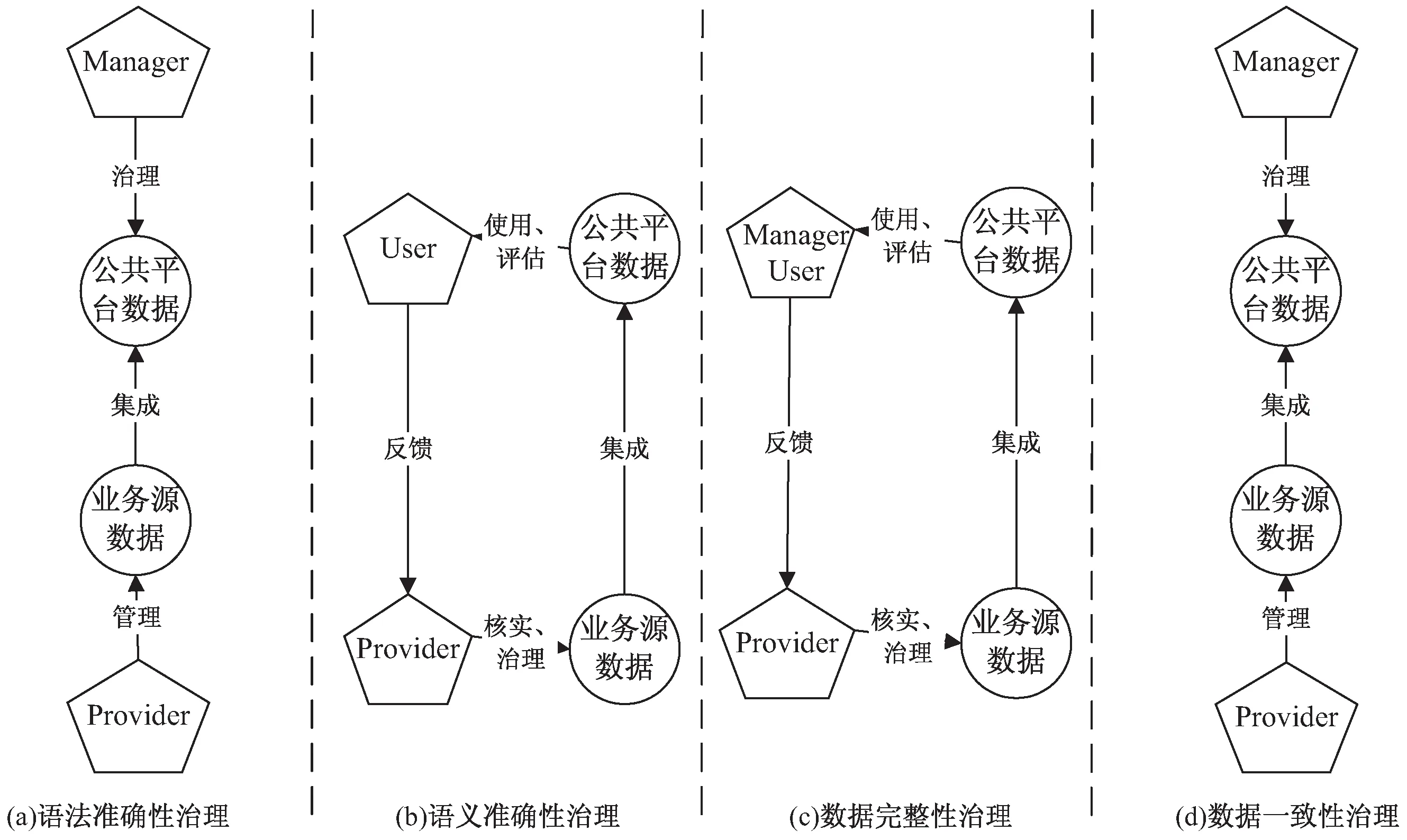
图2 多元治理主体参与下的提升数据质量的治理过程
(4)数据一致性治理,由数据平台管理员对公共数据平台的共享数据实施。该过程是单向性的,不需要经过数据提供者的复核,具体如图2(d)所示。
由图2可看出,实际治理过程中,多元治理主体视角下仅包含三种治理流转:
(1)单向性的数据平台管理员对集成到公共数据平台的共享数据进行单方面的质量治理操作,包括语法准确性治理和数据一致性治理两种,记为M;
(2)循环的数据平台管理员——数据提供者——数据平台管理员,仅包含数据完整性治理。一般这种治理是周期性、批量性的,治理的根据来源于检测得到的数据质量报告和整改报告,数据提供者完成数据的质量治理后,会经过再一次的数据质量检测,直到数据质量达标,记为MP—>PM;
(3)循环的数据使用者——数据提供者——数据使用者,包括语义准确性治理和数据完整性治理,都可认为是对源数据值的治理。数据使用者反馈质量问题一般是在使用某业务应用/服务时发现数据质量问题进行的文本性说明,需要数据提供者去核实、检查反馈的数据项问题,再进行数据项的更新处理,使用者能通过业务应用再次确认数据质量治理的结果,这种治理一般是一次性、不定期的,记为UP—>PU;如果数据提供者复核后确认不符合实际,记为UP—>P。
综上,多元治理主体视角下的数据质量治理过程如图3所示。

图3 多元主体治理视角下的数据质量治理过程
2.2.2 Process构成
根据图3可知,在数据质量的治理过程中,仅包含六个过程:UP、PU、MP、PM、M、P。所以,这六个过程即为数据起源Process的基本过程元素,通过并、串等组合为具体的治理过程。图4是具体的数据质量治理执行流程和对应的过程起源描述——Process。

图4 数据质量的治理过程实例及其过程起源描述
3 基于数据起源的治理构架
为了将数据质量的治理过程及数据质量呈现给数据使用者,需要对数据项进行定义:
定义1 data项:一个data项表示提供给第三方应用/服务使用的数据,是一个五元组,即data={G,V,L,Q,P}。其中G(government)为治理后的值,为实际第三方应用/服务使用的值;V(useValue)为data的源数据现值;L(label)为data的治理标签;Q为实施治理后的数据质量评估值,具体在第4节阐述;P为data的起源信息,详细记录了data的来源、治理过程。
图5是基于数据起源的提升数据质量的治理构架。主要包括两大部分:数据起源记录、数据质量治理。

图5 基于数据起源的提升数据质量的治理构架
数据起源记录:完成起源信息的记录,由工作流定制引擎、过程标注模块、工作流标注模块、领域本体库、语义标注库组成。过程标注模块是对过程进行起源信息标注的标注工具,工作流标注模块是对工作流进行起源信息标注的标注工具。过程标注模块和工作流标注模块都是在领域本体的支持下进行标注,标注的结果即是语义标注。
数据质量治理:主要包含四个模块,即数据使用、数据质量问题反馈、数据质量反馈核实、数据质量评估。图6为具体流转,涉及三类治理主体、两个治理循环。第一个循环称为内循环,首先,数据平台管理者在业务源数据集成到公共数据平台的过程中,会通过数据治理工具执行相应的清洗、对标及质量检查等;如果存在数据质量问题,会向数据提供者出具质量检查报告及整改报告;数据提供者根据整改报告进行质量检查及治理实施,完成后再次循环上述步骤直至数据质量达标。第二个循环称为外循环,共享数据下发给第三方校园应用/服务的使用过程中,数据使用者会根据数据质量评估结果、数据治理过程反馈数据质量,若发现数据质量问题,会向数据提供者反馈具体问题;然后数据提供者会去核实、检查反馈的质量问题,如果核实,会更新业务源头数据,且进行数据质量的重新评估;循环执行上述步骤直至复核数据质量达标。

图6 数据质量的治理流程
4 基于数据起源的数据质量评估
目前数据质量评估方法多是定量评价,即通过评估维度、规则、模型计算出某一数据表/视图的数据质量,是对源数据表/视图的一个整体评价,而实际上同一个表不同的字段属性往往质量不一,且对于某一列属性的值准确性评估,缺少用户(既是生产者也是使用者)的反馈评价。
所以,基于上节提出的提升数据质量的治理构架,对传统的数据质量评估方法做两点改进:一是将用户的评价反馈以数据起源的方式记录在了起源中(即UP、PU过程),设计了将定性评价转化为可定量评估的数据质量计算;二是结合文献[24]提出的定量数据质量评价方法,提出了定性+定量的综合评估方法,实现列粒度的数据质量评估。
4.1 基于用户反馈的数据质量评估
该文默认数据使用者仅能对自己的数据进行质量反馈,另外从数据全生命周期角度,数据最初来源于使用者,且最终为数据使用者使用,所以认定经过数据使用者反馈、业务提供者核实且更新过的数据是为高质量的,不需要再进行源头数据值治理,即只有Process_PU、Process_PM会执行源头数据值的更新操作,认为该次用户反馈是有效的。
为了将用户反馈转化为可衡量的数据质量定量计算,且与最终的数据质量评估有所区分,作如下规定:
定义2 数据起源可信性:指某一条数据列属性治理过程的可信性程度。与完整性治理、准确性治理过程相关,来源于用户反馈,用来衡量用户反馈的数据质量评估,用置信度Confidence来表示,并记录在Parameter起源中。
规定1 数据使用者、数据平台管理者执行反馈动作,即UP、MP,未经数据提供者复核、变更,不允许数据使用者、数据平台管理者对同一数据项执行第二次反馈,否则会存在数据不一致且重复操作的问题。
规定2 只要经过一次完整的数据使用者(User)——数据提供者(Provider)——数据使用者(User)治理流程,即UP—>PU,认定完成源数据质量治理,治理动作结束,Confidence=1,Label=治理完成。
规定3 每经过一次数据平台管理者(Manager)——数据提供者(Provider)——数据平台管理者(Manager),即MP—>PM,Confidence=a*Confidence +(1-a)*0.5,0≤a<1。
由规定可知,只有在Process起源中解析到PU、PM过程时,才需更新Confidence值,且不存在并行的MP—>PM过程,并PU、PM过程必伴随着相应的UP、MP过程。所以只需对过程起源提取PU、PM过程,即可实现Confidence计算。具体算法伪代码如下:
算法1 数据起源可信性计算
Input过程起源Process
Output用户反馈的数据质量评估值——Confidence
While过程起源未结束:
If有过程PU,则Confidence=1,跳出循环;
else if有过程PM,则Confidence=a*Confidence+(1-a)*0.5
else继续;
返回Confidence
4.2 数据质量评估方法
图7为提出的数据质量评估模型,数据质量治理的所有主体均参与其中,且将用户对数据质量的定性评估,通过数据起源记录以及算法1转换为定量评价结果,再结合传统的数据质量评价方法,实现最终的数据质量的评价。

图7 数据质量评估模型
根据图7以及已有文献研究,最终的数据质量评估结果计算如下:
其中,Q为某一列数据的质量评估结果;Qset为源头数据表/视图的数据质量评估结果,采用文献[24]的计算方法得到最终评估得分后,进行归一化处理;Qcon是用户反馈的数据质量评估结果,是对某一具体列数据的质量度量值Confidence。
例如,表1为人事部门提供的教职工信息表(为源头数据表),其通过文献[24]计算的评估得分是90,进行归一化处理后为0.9,即整个教职工信息表T_JZG的数据质量评估得分为Qset=0.9。

表1 教职工信息表T_JZG
张老师(001)在科研系统中发现个人信息中职称信息有误,去反馈在某年某月某日已聘为教授,经人事管理员核查后属实,在人事系统中更新了其职称信息,但该变更不会影响整个表的数据质量评价结果,因为基于规则的数据质量评估只能对一些字段属性设置、空、长度等限制评分,而无法精确地对值进行评估。
所以,对其进行用户反馈的数据质量评估,该次是一次完整的UP→PU过程,按照算法1,设置质量计算参数a=0.4,最终评估得分为Qcon=1。
所以,最终张老师(001)的职称属性(教授)的最终质量评估得分为Q=0.95。
4.3 原型实现
基于上文提出的治理构架,以及数据质量评估方法,设计了一个小型的基于H5的数据质量评估原型系统,具体如图8所示。开发环境为:开发平台Windows 7,开发工具WeX5 3.6,Web服务器Tomcat 6.0,数据库MySQL 5.0,本体开发工具Protege3.4,标注工具OWL-S Editor、OWLS-API3.0,推理机Jena2.6.0。

图8 基于数据起源的数据质量评估系统模型
数据质量评估原型系统包括反馈与评估、起源信息记录、公共数据库、业务数据库、起源数据库5大部分。反馈与评估是系统模型的核心,包括:
(1)质量问题反馈模块。提供给数据使用者、数据平台管理者进行质量问题的反馈,包括具体的数据问题描述、反馈的平台等;
(2)核实反馈问题。数据治理过程是需要线下和线上相结合的特殊信息化过程,特别是核实这块,需要数据提供者根据反馈的问题,进行线下的核实;
(3)数据质量评估模块。对核实的源数据,需要进行数据质量的重新评估。本模型中质量计算参数设为a=0.4。
4.3.1 数据质量问题反馈
图9(a)展示了李某的一系列个人数据,包括基本信息、教学信息及相应数据质量情况。如,李某入职日期是1999-01-15,该数据项尚在治理过程中,数据质量评估值为0.3,点击质量标签,可查看具体的治理过程,具体如图9(b)所示;当李某发现基本信息入职日期有误时,点击“去反馈”,进入数据质量问题反馈填写模块,填写具体的反馈内容,具体如图10所示。

图9 数据质量评估平台数据展示

图10 数据质量反馈填报
4.3.2 数据质量评估
在数据提供者核实了反馈的问题如实后,更新业务数据源,此时会重新评估数据质量,最终李某的数据服务展示如图11(a)所示,其治理过程如图11(b)所示。

图11 实施治理后数据值
5 结束语
数据使用者是数据的生产者,也是使用者,更是评价者。该文基于数据起源,从两方面探索提升数据质量的方法:一是设计了基于数据起源的治理构架,数据使用者能清晰了解治理过程和数据质量,形成治理合力,从而使数据治理落到实处;二是提出了基于数据起源的数据质量评估方法,将数据使用者的反馈从定性转化为定量评估,并实现了数据质量的综合性评价。实验表明提出的提升数据质量的方法具备以下优势:
(1)针对性。提出的数据起源标注模型是针对数据治理领域而提出的,仅包含治理标注信息和必要的数据来源信息,既满足了记录治理过程的需求,又保证了数据质量评估的需要。
(2)全面性。提出的数据治理构架涉及所有治理主体,特别是数据使用者,所有主体都能清晰、透明地了解数据质量治理实施的过程、数据当前的质量情况,从而切实参与到提升数据质量的过程中。
(3)有效性。提出的数据质量评估方法,既有基于用户反馈的定性评估,也包含基于规则的定量评估,是对数据质量的综合性评价,能准确、有效地辅助数据质量的提升。
(4)扩展性。提出的基于数据起源的治理构架和质量评估方法不仅可以应用于教育领域,也可扩展应用至水利等其他领域。
当然,也存在一定程度的不足。例如,提出的数据起源标注模型是针对提升数据质量的需求而设计的,并没有其他的语义信息,在起源依赖性分析和功能扩展性方面存在局限。但是,笔者认为这是值得的,毕竟,过多的语义信息不仅会增加存储的负担,也会降低数据应用的性能。
猜你喜欢
小学科学(学生版)(2021年12期)2021-12-31
小学科学(学生版)(2020年7期)2020-07-28
法制博览(2020年2期)2020-04-29
网络与信息安全学报(2019年6期)2019-12-13
疯狂英语·初中天地(2019年4期)2019-10-17
好日子(2018年5期)2018-05-30
中国漫画(2017年4期)2017-06-30
法制与社会(2017年9期)2017-04-18
中国新闻周刊(2016年33期)2016-10-27
专用汽车(2015年12期)2015-03-01
