
基于CNN和多注意力机制的XSS检测模型
2023-04-21 13:10曹同洲
计算机技术与发展 2023年4期
关 慧,曹同洲
(1.沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142;2.辽宁省化工过程工业智能化技术重点实验室,辽宁 沈阳 110142)
0 引 言
当前,随着互联网的快速发展,基于Web的应用也变得越来越普及。然而,互联网在带给人们便利的同时,也给不法分子提供了违法犯罪的机会,这严重危害到互联网用户的切身利益,给整个社会带来了极大的安全隐患。当下,跨站脚本(cross-site scripting,XSS)随着互联网的发展变得越来越普遍,攻击者可以通过XSS攻击进行网络钓鱼、会话劫持、盗取受害者的cookie等非法活动。根据国家信息安全漏洞库(CNNVD)统计,2020年4月新增安全漏洞共2 155个,从漏洞类型看,跨站脚本漏洞占比达10.53%,仅次于缓冲区错误[1],因此,当下对于XSS攻击的检测与防范尤为重要。XSS检测方法主要有静态分析方法、动态分析方法、机器学习方法等,由于深度学习具有自动提取特征、识别准确率高等优点,近些年人们开始把目光转向深度学习,并利用深度学习技术对XSS攻击进行检测。基于上述情况,该文研究并构建针对XSS攻击的深度学习模型。
1 相关工作
Mohammadi等[2]提出了一种基于单元测试的方法自动检测XSS漏洞;曹黎波等[3]先提交合法向量以确定输出点的所在页面与具体位置,然后对输出点分类并使用不同类型的攻击向量,有效提高了检测效率;李洁等[4]在构造DOM模型与修改Firefox Spider Monkey脚本引擎的基础上,设计了一种动态的、基于bytecode的污点分析的检测算法以对DOM-Based XSS进行检测;Wang R等[5]提出了一个检测DOM-XSS的框架TT-XSS;谷家腾等[6]设计了一种基于动态分析的XSS漏洞检测模型,通过试探载荷测试及载荷单元的组合测试与单独测试判断是否存在XSS漏洞。
当下,随着机器学习的发展,网络安全领域开始引入机器学习来进行恶意攻击的检测与防范。Rathore等[7]根据SNSs网页的特性与前人的经验,共提取了25个XSS特征,并使用ADTree等分类器进行XSS攻击检测;赵澄等[8]提出了一种基于SVM的XSS攻击检测方案;王培超等[9]利用贝叶斯网络对XSS攻击进行检测,并搜集恶意IP信息和恶意域名改善模型的准确性。
深度学习能够自动提取特征,这有效解决了人工提取特征存在的特征选取具有主观性、不全面等问题,因此,近些年深度学习开始被应用在XSS攻击检测等领域中,并逐渐成为这些领域的主流方法。Li Zhen等[10]将深度学习引入到漏洞检测领域;Fang Y等[11]使用word2vec模型将样本转换为由词向量构成的序列,然后利用长短时记忆网络(LSTM)自动提取特征并进行分类;Wu F等[12]将CNN、LSTM、CNN+LSTM模型运用到漏洞检测领域;方忠庆[13]构建了CNN+LSTM模型对XSS攻击进行检测;程琪芩等[14]使用BiLSTM模型提取样本的特征;林雍博等[15]构建残差网络与GRU结合的模型检测XSS攻击。以上方法都取得了良好的效果,但是都没有解决普通深度学习模型难以区分数据中重要信息与非重要信息的问题。
自从Bahdanau等[16]提出注意力机制,它便引起学界的关注,并开始被广泛运用在各个领域。注意力机制能够帮助模型区分出重要特征与非重要特征,从而提升模型的整体性能。汪嘉伟等[17]利用卷积神经网络提取局部特征,并引入自注意力机制捕捉序列的长距离依赖特征;赵宇轩等[18]将注意力机制引入到深度学习模型,完成垃圾邮件的检测任务;陈莉媛等[19]在短文本情感分析的任务中引入自注意力机制,利用其捕获关键信息的特点提升模型性能;桂文明等[20]在歌声检测任务中应用点积自注意力模块使模型能够区分特征间的重要性差异;刘学平等[21]将通道注意力模块SENet结构嵌入到YOLOV3结构,以提升目标识别的查准率;康雁等[22]在文本情感分类任务中融合了SENet模块,提高了模型对深层次文本特征的抽取与分类能力;邱宁佳等[23]在文本主题识别任务中引入通道注意力模块SENet,强化重要的通道信息以提升模型性能。
以上方法大多数是单独使用自注意力机制或通道注意力机制,虽然实验证明这些注意力机制的加入能够提升模型性能,但单独使用其中一种还是会存在关注维度单一的问题。自注意力模块以序列中各位置的词向量作为单位,根据相应位置上的单位与其他单位之间的相关性,确定该位置的最终结果,显然,它没有从通道的维度考虑各通道特征图的重要程度;而通道注意力模块则是从通道维度计算各特征图的注意力权重,并通过加权的方式确定各通道特征图的最终结果,但它并没有从序列的维度探究各词向量间的相关性。因此,该文根据上述分析提出了卷积神经网络与多注意力机制相结合的模型,并以此对XSS攻击进行检测。
2 相关理论知识
2.1 跨站脚本攻击
跨站脚本攻击主要分为3类[24]:反射型XSS(reflected XSS)、存储型XSS(stored XSS)及基于DOM的XSS(DOM-based XSS)。反射型XSS是现在最普遍的一种XSS,攻击者将恶意代码放在URL中,并诱使受害者点击,一旦受害者点击了该URL,恶意脚本便会被服务器发送给受害者,在其被解析和执行后,攻击者便实现了对受害者的XSS攻击;存储型XSS是一种持久性的XSS,与反射型XSS不同,存储型XSS是将恶意脚本存储在服务器端的数据库中,一旦有用户访问相应网站,攻击代码便会从服务器端数据库响应给受害者,该类型的XSS漏洞通常存在于留言板等能够进行交互的地方,并常被用于编写危害性更大的XSS蠕虫[25];基于DOM的XSS的请求不会被发送到服务器,而是在用户浏览器本地执行,因此,其威胁相较反射型XSS更大,防御难度也更高[4]。
2.2 自注意力
近些年,自注意力机制[26]被广泛运用在文本处理等领域。在处理文本类型数据时,人们希望模型在关注全局信息的同时,能更加关注序列中的重点信息,自注意力机制则可辅助模型达到这一目的。其总体框架如图1所示。自注意力机制的核心思想是通过计算单个词向量与序列中其他词向量的相似度来判定其在序列中的重要程度,它在训练时只关注自身信息,并且可以无视词向量之间的距离,在序列中的任意两个词向量之间建立联系,因此,自注意力机制具有提取长距离依赖特征的功能[19]。基于上述分析,该文在深度学习模型中加入自注意力模块以提高模型对长距离依赖特征的学习能力以及对序列中重点信息的关注能力。

图1 自注意力框架
2.3 通道注意力
通道注意力机制能够为各通道特征计算权值,常被用于辅助深度学习模型以提升其性能。Jie H等[27]提出通道注意力模块SENet(squeeze-and-ex-citation networks),这是一种最初应用在计算机视觉领域的轻量级模块,近些年在文本分类领域也开始被人们应用。SENet的原理是通过加权的方式强化与分类相关性更强的通道特征图以提升模型的分类性能[28],其结构如图2所示。

图2 SENet结构
SENet模块首先通过全局平均池化层(GAP)获取各特征图的信息,然后依次经过全连接层(FC)、ReLU激活函数、全连接层(FC),最后经由Sigmoid激活函数得到通道权值。
Woo S等[29]提出了轻量级注意力模块CBAM,该模块中通道注意力子模块的结构如图3所示,该子模块与SENet模块的不同之处在于它在获取通道信息时分别使用了全局平均池化层和全局最大池化层(GMP),全局平均池化与全局最大池化相配合能够生成更为合理的通道注意力权值。CBAM模块的提出者对其中的通道注意力子模块进行了实验,并证明了同时使用全局平均池化和全局最大池化比单独使用一种全局池化的效果更好。因此,该文参考了CBAM中通道注意力子模块的结构构建适用于文本类型数据的通道注意力模块。
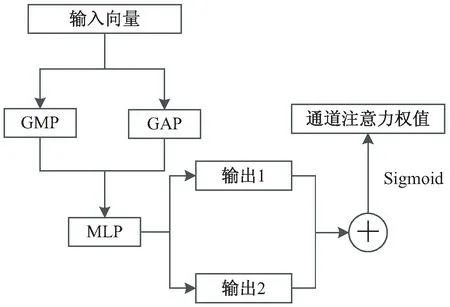
图3 CBAM通道注意力子模块结构
3 文中方法
3.1 深度学习模型设计思路
基于上一节的分析,该文提出了一种卷积神经网络与多注意力机制相结合的模型,它由两个卷积层、一个自注意力模块、通道注意力模块、最大池化层、Dropout层、全局平均池化层和softmax分类器构成。该模型结构如图4所示。

图4 深度学习模型整体结构
模型的核心部分由卷积层、自注意力模块以及通道注意力模块构成。其中,卷积层能够对样本的局部特征进行提取,然而,卷积神经网络存在提取长距离依赖特征的能力不足以及难以识别重要信息的缺陷,因此,在此基础上,加入了自注意力模块。自注意力模块能够在序列中的各个词向量之间建立联系,有效解决了卷积神经网络对长距离依赖特征提取能力不足的问题,并且能够使模型更加关注序列中的重要信息,自注意力机制的工作原理如图5所示。
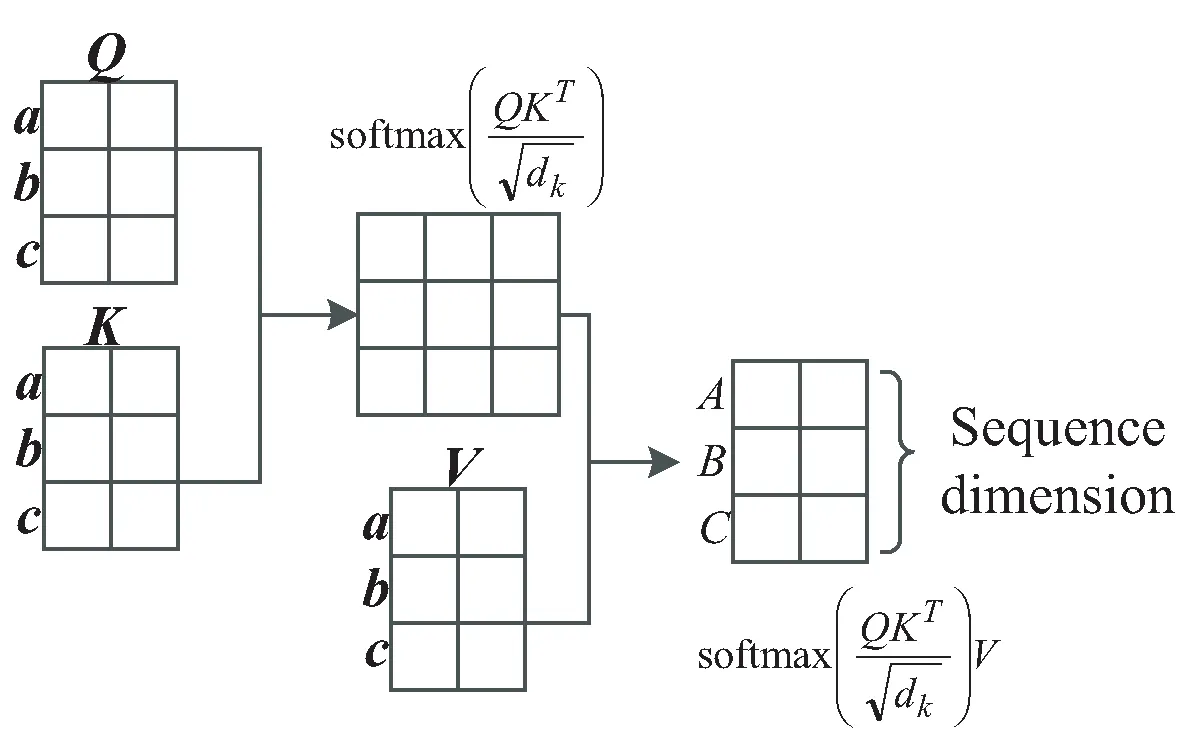
图5 自注意力机制工作原理

(1)
从自注意力机制的工作原理可以看出,自注意力机制能够通过注意力权重矩阵在序列维度上各个位置得到新的向量,但它并没有从通道维度分析各通道特征图之间存在的重要性差异。为了解决该问题,引入通道注意力模块。通道注意力的作用原理如图6所示。

图6 通道注意力作用原理
通道注意力模块接收由n个通道特征图构成的输入c={c1,c2,…,cn},各个通道特征图沿着通道维度(channel dimension)依次分布,通道注意力模块可以根据输入c分析出这n个通道的注意力权重a1,a2,…,an,并利用它们为相应的通道特征图加权得到新的特征C={C1,C2,…,Cn},其加权公式如下所示:
(2)
在注意力模块完成对特征图的处理后,便将优化后的特征送入最大池化层进行下采样,与此同时加入Dropout层提高模型的泛化能力,最后经过全局平均池化层和softmax分类器对样本进行分类。
3.2 数据预处理
在实验开始前,需要对数据集中的数据进行预处理。由于攻击者在构造XSS攻击向量时会通过恶意混淆的方式来躲避检测,因此,首先需要对数据集中的样本进行解码操作,以提高样本数据的可读性;其次,将样本中的数字用“0”替换,并将超链接用“http://u”替换;最后进行分词操作,从而将样本分割为由单词组成的序列。
3.3 词向量转换
完成预处理的工作后,就可以利用词向量模型word2vec将原数据转换为由词向量构成的语句序列,并将其作为深度学习模型的标准输入。
3.4 特征提取与分类
完成词向量转换的工作后,就可以利用构建的深度学习模型提取样本的特征并对样本进行分类。在深度学习模型中,卷积神经网络负责提取样本的局部特征,自注意力模块负责提高模型对长距离依赖特征的学习能力以及对重要序列特征的关注能力,通道注意力模块则负责加强模型对重要通道特征的关注度。提取完特征后,经由最大池化层以及Drouout层进行下采样及泛化处理,并通过全局平均池化层及分类器完成样本的分类工作。
3.5 算法设计
在训练模型之前需要对训练样本以及测试样本进行预处理及词向量转换等操作以得到适应深度学习模型的标准训练集Train_set以及标准测试集Test_set。文中模型的算法设计如下所示:
输入:训练集Train_set与测试集Test_set。
输出:经分类器预测得到的结果。
构建深度学习模型并初始化参数。
训练模块:
Fori in epochs:
将训练集Train_set的数据送入输入层得到result1;
将result1送入卷积神经网络提取特征得到result2;
将result2送入自注意力模块进行处理得到result3;
将result3送入通道注意力模块,从通道维度对特征图加权得到result4;
将result4送入最大池化层进行下采样,然后再利用Dropout层进行泛化得到result5;
将result5送入全局平均池化层,然后输入到soft-max分类器中进行预测得到分类结果result;
将分类结果与实际类别进行对比,并根据误差进行反向传播以调整参数;
更新深度学习模型各层的参数;
end for;
测试模块:
将测试集Test_set中的数据送入训练好的模型中进行预测,并将预测结果与实际类别进行对比,判定模型的检测性能。
4 实验及分析
将攻击样本设置为正样本,将正常样本设置为负样本。为了验证文中所提模型的性能,使用准确率(accuracy)、精确率(precision)、召回率(recall)、和F1值作为模型的评价指标。其中,准确率表示被正确预测的样本数占总样本数的比例;精确率表示被正确预测的正样本数占所有被预测为正样本的样本数的比例;召回率表示被正确预测的正样本数占所有正样本的样本数的比例;F1值是综合精确率和召回率的评价指标,它们的公式如下所示:
(3)
(4)
(5)
(6)
其中,TN是指被正确预测的负样本数量,FP是被预测为正样本的负样本数量,FN是被预测为负样本的正样本数量,TP是被正确预测的正样本数量。
4.1 实验准备
实验的硬件环境为:处理器Intel(R) Core(TM) i5-10300H、内存8 GB;软件环境为:Win10(64位)操作系统、Python3.5、TensorFlow1.8.0、Keras2.2.0。
实验使用从Github收集到的24 687个XSS攻击样本以及24 818个正常样本,两类样本的总数为49 505。按照7∶3的比例将样本划分为训练集与测试集。样本的分布情况如表1所示。
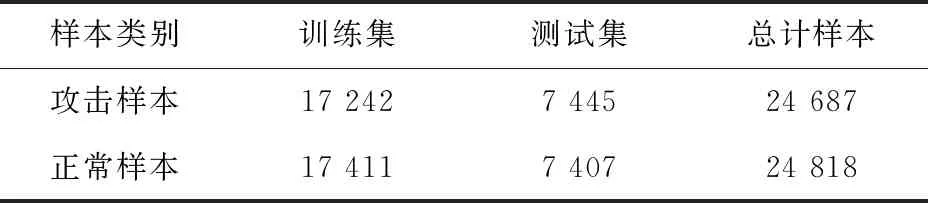
表1 样本分布情况
由于深度学习模型要求所有输入数据的序列长度和词向量维度保持一致,因此,该文需要统一输入数据的形状。为了确定输入数据的序列长度,对分词后样本序列长度的分布情况进行了统计,结果显示,序列长度小于等于100的样本数量超过总样本数量的99%,因此将所有输入样本的序列长度统一为100,对于长度超过100的样本进行截断处理,并对长度小于100的样本使用零向量进行填补。为了确定epoch值,对模型的性能与epoch之间的关系进行了探究,模型在测试集的准确率曲线及F1值曲线如图7和图8所示。从图中可以看出,当训练轮数到达3的时候,模型的准确率与F1值都达到了高位水平,当继续增加训练轮数时可以发现,模型的性能并没有明显的提升,曲线趋向平稳,因此,将epoch设置为3。

图7 模型测试集准确率曲线
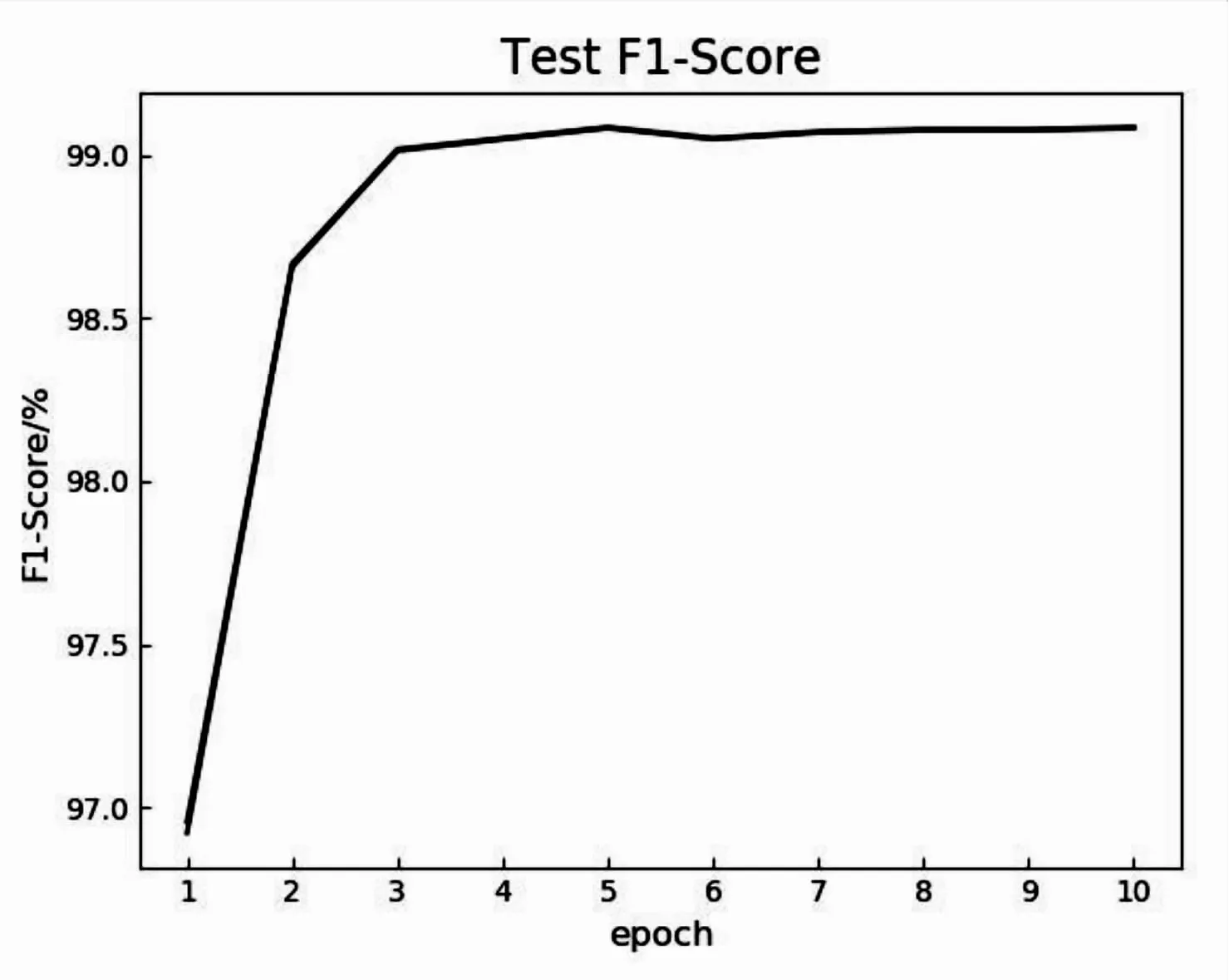
图8 模型测试集F1值曲线
实验参数如表2所示。

表2 实验参数
4.2 实验数据与分析
在实验训练阶段与测试阶段所用的数据集均为经过预处理及词向量转换处理的标准数据集。首先使用标准训练集训练文中提出的模型,并在该模型训练完成后将其应用在标准测试集中。为了探究注意力机制对模型性能的影响,进行了消融实验,对文中提出的模型进行了拆解。实验的结果如表3所示,其中基准模型为在文中模型基础上去掉所有注意力模块的模型,方法1为基准模型加通道注意力模块的模型,方法2为基准模型加自注意力模块的模型。从实验结果可以看出,加入通道注意力模块或者加入自注意力模块都能提高卷积神经网络的性能,而文中模型的准确率与F1值分别为99.02%与99.01%,明显高于其他3个对照组。与基准模型相比,文中模型的准确率提升了1.07百分点,召回率提升了2.09百分点,F1值提升了1.09百分点,其相对于基准模型的提升幅度大于单独使用一种注意力机制的方法1和方法2。

表3 消融实验结果 %
为了继续验证该模型的性能,还将其与深度学习中常用的RNN模型和LSTM模型进行了对比。此外,由于数据集及预处理等方面存在差异,根据文献[13]、文献[30]、文献[14]中所提供的信息构建了相应的CNN+LSTM、LSTM-Attention、BiLSTM模型进行实验,因为未明确文献[30]中L-STM的units参数,所以,在进行对照实验时将该参数设置为128。对照实验依旧使用表3实验所用的标准数据集,其中,对照实验的batch_size、epoch均依照表3设置。模型主要性能指标的对比结果如表4所示。
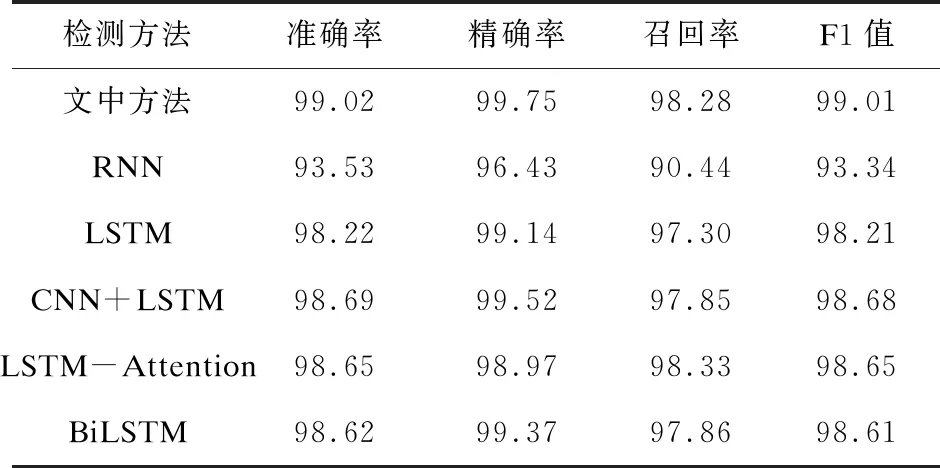
表4 文中模型与其他深度学习模型对比结果 %
从表4可以看出,RNN模型、LSTM模型、CNN+LSTM模型、LSTM-Attention模型、BiLSTM模型的准确率分别为93.53%、98.22%、98.69%、98.65%、98.62%,F1值分别为93.34%、98.21%、98.68%、98.65%、98.61%。相比RNN模型,文中方法在准确率与F1值方面均提升了超过5百分点,召回率提升了接近8百分点,除此之外,其他几个对照模型均取得了不错的检测效果,但是,相比之下文中提出的模型在准确率、精确率与F1值这些指标上都表现得更加优秀。因此,通过对照实验可以得出结论,文中提出的模型在XSS攻击检测方面有着良好的表现。
5 结束语
如今,随着Web应用的普及,XSS攻击的威胁也变得越来越大,如何有效地检测XSS攻击成为当前一项重要的任务。针对这一情况,构建了基于卷积神经网络和多注意力机制的XSS攻击检测模型。在卷积神经网络的基础上,引入了自注意力模块及通道注意力模块,从序列与通道两个维度对特征进行优化处理。首先,对输入数据进行解码、替换、分词等预处理工作;然后,使用word2vec模型进行词向量的转换工作,并利用提出的模型进行特征提取等工作;最后,根据提取到的特征进行分类。为了验证文中所提模型的性能,进行了消融实验,并将该模型与其他深度学习模型进行了对比。下一步,可以继续收集样本构建数据集以观察该模型的效果,并继续尝试改进模型,以提高检测的性能,应对日益复杂的XSS攻击。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
