
面向自然街景改进的文本检测
2023-04-21 13:10程艳云
计算机技术与发展 2023年4期
丁 泽,程艳云
(南京邮电大学 自动化学院、人工智能学院,江苏 南京 210023)
0 引 言
文本在人机交互中扮演着重要的角色,随着智能机器人、无人驾驶、医疗诊断的飞速发展,文本的检测与识别已经成为定位和理解物体信息的重要途径。
经典的文本检测方法可分为两大类:基于连通域分析的文本检测方法和基于滑动窗口的文本检测方法。然而,基于连通域的方法对噪声的包容性较差,而基于滑动检测窗的方法虽然可以避免该问题,但该方法却对滑窗依赖极大,通用性不强。近年来,出现了大量的基于深度学习的自然场景文本检测方法,这些方法多采用2种深度学习图像处理策略:(1)目标检测算法中得到区域建议的策略;(2)图像语义分割策略。
基于区域建议的方法一般以通用目标检测网络作为基本模型,并在此基础上结合实际应用对算法进行改良。2017年Liao等人[1]提出的TextBoxs网络可根据不同卷积层的多尺度特征有效检测出不同尺度文本。2018年,Liao等人[2]又在此基础上提出了TextBoxs++文本检测模型,利用旋转角度的倾斜文本框实现不规则的文本检测窗。2019年,Zhong等人[3]提出一种无锚区域建议网络(AF-RPN)替代Faster R-CNN中的基于参考框的区域建议方法。该方法能够摆脱复杂的参考框设计,在水平和多方向文本检测任务中均取得了更高的召回率。2020年,Wang等人[4]提出了ContourNet文本检测模型,该模型设计了一种与尺度无关的自适应区域建议网络(Adaptive-RPN),该网络能有效地解决算法产生的伪召回及对尺度变化剧烈的文本检测不准确的问题。然而,上述方法在检测任意形状或极端纵横比的文本时效果依旧不理想。
基于分割的方法以语义分割为基本技术手段,通过深度学习语义分割网络对自然场景图片进行处理,获取像素级别的标签预测。2018年,Deng等人[5]提出PixelLink模型,采用实例分割的方法,分割出文本行区域,然后直接找对应文本行的外接矩形框,但其需针对不同数据集调整pixel和link的阈值,并设计不同的后处理方法,且无法处理背景复杂的数据。2019年,Xu等人[6]提出Text Field来学习一个方向场来链接相邻像素,并使用一个简单的基于形态学的后处理来实现最终检测,但其后处理过程过于复杂,模型的检测速度很慢。2019年,Wang等人[7]提出了PAN模型,通过像素聚合的方式来让网络学习文本相似性矢量,有选择地聚合文本内核附近的像素,有效地提升了文本的检测速率但对任意形状的文本检测不够鲁棒。2021年,Wang等人[8]在PAN的基础上又提出了PAN++网络,该网络展示了一种基于文本内核的任意形状文本的表示方法,不仅能够描述任意形状的文本,还能在保持精度的同时实现较高的推理速度,但该方法表征能力较弱,在应对极端纵横比和旋转文本的效果不佳。2020年,Liao等人[9]提出的MaskTextSpotterV3采用ResNet50作为主干网络,能有效地提取文本特征,并且该模型设计了一个无锚分割建议网络,可以提供对任意形状建议的准确描述,并且在检测旋转、极端长高比或不规则形状的文本实例时具有鲁棒性,但该方法因感受野较小且在特征融合阶段将不同尺度特征直接融合,故在处理极端纵横比、大尺度文本检测时容易出现漏检、误检的现象且易引入过多的噪声,影响模型对小尺度文本的检测效果。
为解决以上问题,该文在MaskTextSpotterV3的基础上提出了一种融合多尺度模块的文本检测方法(text detection method incorporating multi-scale modules,IMSM)。该检测方法采用改进的特征提取模块和改进的特征融合模块,在有效扩大感受野的同时抑制噪声信息,能有效地捕捉中长文本的特征信息,减少漏检、误检的现象且对极端纵横比的文本具有鲁棒性。
1 融合多尺度模块的文本检测网络
1.1 总体网络架构
该文提出的IMSM模块如图1所示,具体分为三个模块,分别是改进的特征提取模块、改进的特征融合模块和分割候选模块。主要内容如下:为了平衡模型的体积和检测效果,采用Resnet50作为主干网络,同时将FPN与改进的感受野模块(receptive field block for integrating attention,RFBIA)相融合以扩大感受野、捕捉中长文本的特征信息。针对RFB模块[10]下采样融合后与输入特征图相加引入过多的噪声信息,嵌入极化自注意力机制[11](polarized self attention,PSA)对特征进行处理,以提取有效的文本特征。针对特征分布不确定性及远距离特征融合效果不佳的问题,在特征融合模块中引入条形池化(strip pooling module,SPM)模块[12]来捕获更长距离之间的依赖关系,以此提升检测方法的鲁棒性。

特征提取模块 特征融合模块
1.2 特征提取与多尺度模块
在特征金字塔网络对主干网络提取的高语义特征和高分辨率特征进行融合时,由于采用3*3的卷积,其对于极端纵横比、大尺度文本的融合效果较差,易造成漏检、误检的现象。为解决此问题,该文将融合后的高语义特征和高分辨率特征送入RFBIA模块,通过扩大感受野来对大尺度文本进行检测,同时RFBIA模块也能有效抑制因为扩大感受野而引入的噪声信息,提取有效特征,从而提高文本检测效果。
RFBIA模块如图2所示,RFB模块由多分支卷积层和膨胀卷积层组成,图中用大小不同的圆形表示不同尺寸卷积核构成的卷积层;膨胀卷积层的作用在于增加感受野,图中用不同的rate表示膨胀卷积层的参数。其中,多分支卷积层使用多种尺寸的卷积核来实现,相比于固定尺寸的卷积核而言,多尺寸的卷积核提取的信息更加丰富,从而能尽量避免信息的丢失。每个分支的卷积层后面会级联一个膨胀卷积层,膨胀卷积层在保持参数量的同时能扩大感受野,用来获取更高分辨率的特征。

图2 RFBIA结构
然而,在RFB模块下采样得到高语义信息并扩大感受野的同时,由于分辨率的降低会丢失输入图像的部分特征信息。为了精确地从特征图像中分割出文本信息,需要底层的特征图提供重要的细节信息和边缘信息,所以该文设计将输入特征图通过一个极化自注意力机制(PSA)来提供所需的细节信息和边缘信息。输入特征图经过PSA模块后提取出丰富的局部信息和边缘信息;而RFB模块扩大感受野后,提取出不同尺度的空间信息,得到包含高语义、抽象化的特征信息的输出,将两者提取出的信息相融合以进行联合预测,从而提高检测效果。
在RFBIA模块中,为有效地提取重要的细节信息和边缘信息,并联了一个精细的双重注意力机制(PSA)。PSA采用了一种极化滤波(polarized filtering)的机制,类似于光学透镜过滤光一样,每个自注意力的作用都是用于增强或抑制特征,该机制在通道和空间维度能保持较高的分辨率,这能够减少降维所造成的信息损失。该模块还在通道和空间分支中采用了Softmax和Sigmoid相结合的非线性函数,从而能够拟合出细粒度回归结果的输出分布,如图3所示。PSA分为两个分支,一个分支做通道维度的自注意力机制,另一个分支做空间维度的自注意力机制。两分支采用并行的方式来获取注意力权重,这充分利用了自注意力结构的建模能力,在保证计算量的情况下,实现了一种非常有效的长距离建模。输入的特征再对分别经过这两个分支后产生的结果进行融合就得到了极化自注意力结构的输出。
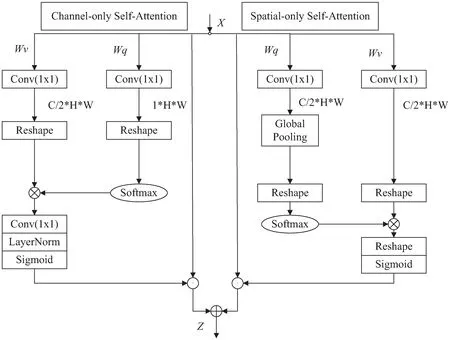
图3 PSA网络
通道维度的自注意力机制中,输入的特征会经过一个1*1的卷积将特征X转换成Q(C/2×H×W)和V(1×H×W),其中Q通道被完全压缩,而V的通道维度依旧保持在C/2的水平,由于Q的通道维度被完全压缩,故而采用Softmax对Q通道的信息进行增强。然后将Q和V进行矩阵乘法,特征图大小变为C/2×1×1,然后特征图再经过一个1×1的卷积和LayerNorm层将通道维度从C/2上升为C。最后使用Sigmoid函数使得所有的参数都保持在[0,1]的范围内。通道维度的注意力权重如下:
Ach(X)=FSG[WZ|θ1(σ1(Wv(X))×
FSM(σ2(Wq(X))))]
其中,Wq、Wv、Wz均为1×1的卷积层,σ1、σ2是两个张量reshape操作,而FSM(·)代表Softmax运算,×则代表矩阵乘法运算。通道分支的输出结果则为通道权重与输入特征的逐通道相乘。
与通道维度的自注意力机制相似,空间自注意力机制中输入的特征图也是先经过一个1×1的卷积,将特征转换为Q(C/2×H×W)和V(C/2×H×W),其中特征Q采用了全局池化来对空间维度进行压缩转换成1×1的大小,而特征V的空间维度则保持在H×W的水平。由于特征Q的空间维度被完全压缩,故而在全局池化后使用Softmax函数对Q的信息进行增强。然后再将Q和V进行矩阵乘法,将输出结果进行reshape和Sigmoid操作后,使得所有的参数都保持在[0,1]之间。空间维度的注意力权重如下:
Asp(X)=FSG[σ3(FSM(σ1(FGP(Wq(X))))×
σ2(Wv(X)))]
其中,Wq和Wv是1×1的卷积,σ1、σ2和σ3表示三个张量reshape操作,FSM(·)表示Softmax操作,FGP(·)表示全局池化函数,×表示矩阵点积运算。
以上两个分支并联运算输出的结果为PSA(X)=Ach(X)⊙Xch+Asp(X)⊙Xsp,其中+代表逐元素相加。
1.3 特征融合模块
在特征金字塔(FPN)融合高层信息和底层信息后,融合的特征图将送到后续分割模块中进行分割以进行文本的检测与后续的识别,这就需要对输出的特征进行融合,将多尺度的特征融合到一张特征图中。由于自然场景中的文本信息大多呈长条形,或离散分布,为解决特征分布不确定性及远距离特征融合效果不佳的问题,该文在特征融合中引入SPM来捕获更长距离之间的依赖关系,以此提升检测方法的鲁棒性。该模块与RFBIA模块相互补充,提升了整个网络的性能。
SPM是一个新的池化策略,该策略采用了一个长而窄的核即1×N或N×1,以此来捕获场景像素级预测任务的远程上下文信息,输入的特征图大小为C×H×W,图4所示为一个通道的处理过程。

图4 条形池化网络

1.4 分割候选模块
分割候选模块采用了U-net结构,该结构沿用了全卷积网络(FCN)进行图像语义分割的思想,包括收缩路径和扩张路径,其中收缩路径用于捕获上下文,扩张路径用于精确定位。相较于FCN而言,U-net在扩张路径上采样的过程中拥有更多的通道数,这使得U-net网络能进行多尺度的图像特征识别,将上下文的信息向更高层分辨率传播。同时,U-net结构在上采样融合特征提取部分的输出时采用了拼接的特征融合方式,将特征在通道维度拼接在一起形成更厚的特征,这也提高了其对于尺度的鲁棒性。
与基于特征金字塔结构的区域候选网络在多个尺度的特征图上产生候选框不同,分割候选网络从分割图中生成候选区域,其中分割图由上文中融合后的特征图映射预测得到。融合后的特征图连接了不同感受野的特征映射,其大小为H/4×W/4,其中H和W分别是输入图像的高度和宽度。预测的文本分割图的大小为1×H×W,其值在[0,1]的范围内。
1.4.1 分割标签生成

图5 分割标签生成
左图中外多边形和内多边形分别是原始注释和收缩区域,右图为分段标签,黑色和白色分别代表0和1的值。
1.4.2 候选区域生成
给定一个值在[0,1]范围内的文本分割图S,将S二值化为二值图B。如上文所述,文本分割标签被收缩,然后分割候选网络在二值图中搜索出连通的区域,这些连通区域可以被视为收缩的文本区域,之后再通过Vatti clipping算法取消裁剪d像素,以此膨胀回文字区域。如上所述,分割候选网络能够精确地产生多边形候选区域。因此,它能够为极端长宽比的文字行和密集多方向、不规则形状的文字生成合适的候选区域,同时也为后续模块提供了精确的多边形位置信息。
1.4.3 损失函数

文中将分割图设为S,目标图设为G。损失函数表示为:
其中,I和U分别表示分割图与目标图的交集和并集,*则代表逐元素相乘。
2 实验与分析
该文评估了所提出的改进的文本检测方法,并在不同标准场景文本基准上测试了对旋转、纵横比、小尺度文字的鲁棒性,并对提出的方法进行了消融实验。
2.1 数据集
SynthText是一个包含800k文本图像的合成数据集,它为单词/字符边界框和文本序列提供了注释。
Rotated ICDAR 2013 dataset (RoIC13)是由ICDAR2013数据集生成的,该数据集的图像集中在文本内容周围,文本实例在水平方向上并且由轴对齐的矩形框标记,且该数据集提供了字符级的分割注释。该数据集包含229张训练图片和233张测试图片,为了测试旋转的鲁棒性,该文还创建了旋转的ICDAR2013数据集,方法是将ICDAR测试集中的图像和注释旋转到一些特定的角度。
S-CUT是一个具有挑战性的曲线文本数据集,由1 000张训练图像和500张测试图像组成。不同于传统的文本数据集,SCUT中的文本实例由14个点的多边形标记,因此它可以描述一个任意曲线文本的形状。
Total-Text数据集包含1 255张训练图片和300张测试图片。它提供各种形状的文本实例,包括水平的、定向的和弯曲的形状。尽管Total-Text数据集提供了字符级的注释,但该文并未使用。
ICADR2015数据集包含1 000张训练图像和500张测试图像,这些图像都用矩形边界框标注。该数据集中的大多数图像的分辨率较低,并且包含小文本实例。
2.2 实验细节
该文使用SGD来优化模型,权重衰减为0.001,动量为0.9。在消融实验和对比实验中使用SynthText预训练的ResNet 50模型作为主干网络,然后使用SynthText、ICDAR2013数据集、ICDAR2015数据集、S-CUT数据集和Total-Text数据集进行300 000次迭代的混合微调,这些数据集之间的采样率设置为2∶2∶2∶1∶1。
在微调期间,初始学习率为0.01,然后分别在100 000次迭代和200 000次迭代时降低10倍。在推理期间,输入图像的短边在RoIC13数据集上调整为1 000,在ICDAR2015数据集上调整为1 440,以保持纵横比。
2.3 实验环境
实验使用python3.7作为编程语言,pytorch版本为1.4.0。所有的实验都是在Linux18.04操作系统进行,显卡配置为两张NVIDIA RTX2080TI。
2.4 评价指标

2.5 消融实验
为了验证RFBIA和SPM的有效性,在ICDAR2015和RoIC13数据集上分别进行了消融实验。
如表1所示,在添加提出的RFBIA后,原始网络的准确率下降了0.7百分点,检测速率下降了0.3 fps,而召回率、F1值均有所提升。在添加SPM后,原始网络的准确率、召回率、F1值均有提升,其中召回率提升了4百分点,但检测速率下降了0.1 fps。而在RFBIA和SPM的联合使用下,原始网络的准确率上升了1.7百分点,召回率上升了4.2百分点,F1指标上升了3.3百分点,与此同时,检测速率也下降了0.4 fps。

表1 ICDAR2015消融实验
如表2所示,在添加提出的RFBIA后,在旋转45°、60°时,原始网络的准确率、召回率、F1指标、检测速率均有上升,其中在旋转60°时,各项指标提升较多。在添加SPM后,在旋转45°时,原始网络各项指标均有所下降,仅检测速率上升了0.6 fps;而在旋转60°时,原始网络的各项指标均有提升。在RFBIA+SPM联合使用下,在旋转45°时,原始网络的召回率、F1指标、检测速率有所提升,但准确率降低了1.6百分点;而在旋转60°时,原始网络的准确率、F1指标、召回率提升较大,其中召回率上升了5.8百分点,检测速率无变化。
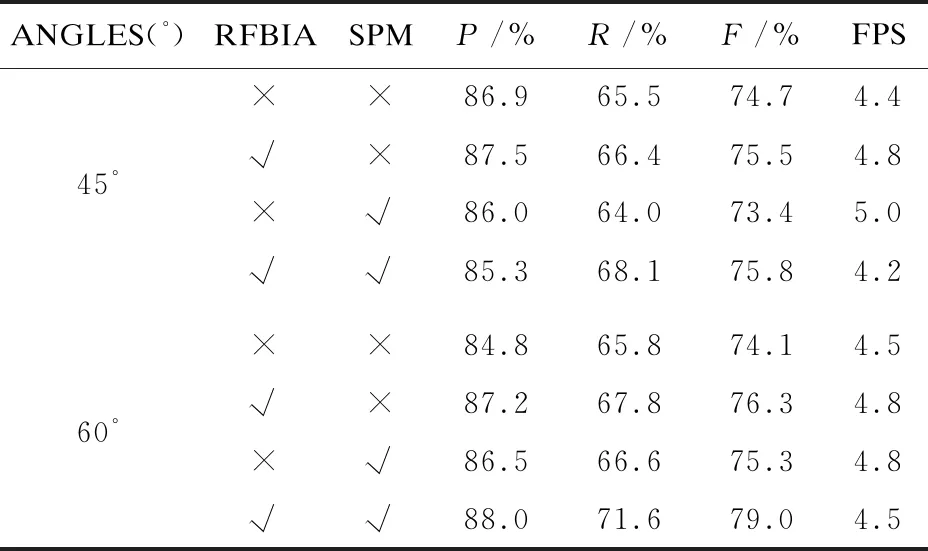
表2 RoIC13消融实验
提出的算法在ICDAR2015数据集和RoIC13数据集上消融实验的可视化测试结果如图6所示,其中按列从左到右分别为测试图、原始网络检测结果图和文中算法检测结果图。

图6 对比结果展示
将以上结果进行分析可得,在原始算法框架中添加了RFBIA模块后,由于RFBIA弥补了FPN提取特征时感受野较小的缺点,增强了模型检测大尺度弯曲文本的能力,模型的检测准确率在各数据集上均有提升,但该模块对于小尺度密集文本较多的ICDAR2015数据集的检测效果并不明显。在原始网络中添加SPM模块后,模型的各项检测指标在ICDAR2015数据集上有明显提升,但在其他数据集上则表现效果一般,这是因为SPM模块能有效捕获长距离的依赖关系,其条纹池化操作也可以认为是一种注意力机制,能有效地挖掘小尺度信息,对特征进行提取。而RFBIA和SPM的联合使用不仅增强了模型检测大尺度文本的能力,降低了特征图分辨率的损失,而且对有效文本特征信息的提取也有所增强。同时,该算法在RoIC13数据集旋转60°实验中的表现也证明了所提出的算法对于旋转的鲁棒性。
2.6 对比实验
该方法与其他方法在Total-Text数据集上对综合评价指标F值的对比结果如表3所示,表3展示了文中方法在检测(Detection)和端到端(End-to-End)识别的情况下与其他模型的对比分析,为了使对比分析更加直观、公平,端到端识别的情况又分为无词汇表识别(None)和有词汇表识别(Full)两种情况。提出的方法在检测效果方面相比于针对处理多方向和曲线文本的CharNet[13]高了0.1百分点,相较于MaskTextSpotter高出了0.5百分点,这是因为CharNet和MaskTextSpotter采用的传统的区域建议网络对极端纵横比的文本识别效果不佳。而在进行端到端的文本定位时,文中方法在没有词汇表的情况下相较于PAN++高出了2.9百分点,这是由于PAN++采用的轻量级网络的表征能力较弱,虽然其推理速度较高,但识别精度还有待提高;相较于MaskTextSpotter V3高出了0.3百分点,体现了文中方法在无监督的情况下对文本识别效果的提升。而在有词汇表的情况下相较于ABCNet[14]高出了1.2百分点,持平于PAN++;相较于MaskTextSpotter V3则高出了0.2百分点。MaskTextSpotter V3在提取特征时感受野较小,而在特征融合阶段则将不同尺度的特征直接相加,容易造成漏检、误检,从而导致学习到的特征较为分散,这也体现了文中方法在弯曲文本上的有效性及对多方向文本检测有较强的鲁棒性。在提升整体网络对文本识别性能的同时,所提出的算法由于后处理过程较为复杂,在识别效率方面仅比CharNet高出1.9,相较于其他网络模型还有待提升。

表3 Total-Text 数据集上模型性能对比
3 结束语
文中的研究具有一定的应用前景,例如检测路牌文字、辅助自动驾驶的导航、机器人送货上门等。但是,目前街景的文本检测中仍然存在一些问题,因此,提出了一个融合多尺度模块的文本检测方法(IMSM)。其中RFBIA和SPM能将有效特征精准地覆盖到目标文本区域,在突出特征的同时能有效抑制噪声影响。实验结果表明,文中算法在弯曲文本、旋转文本、密集小尺度文本的检测上有着优异的表现。后续工作将对提升文本对极端纵横比的鲁棒性、提高模型检测效率以及模型的轻量化展开深入研究,进一步提高检测效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
电视技术(2014年19期)2014-03-11
