
基于对抗学习的自适应加权方面级情感分类算法
2023-04-19 05:17张华辉廖凌湘刘鑫磊
小型微型计算机系统 2023年4期
张华辉,冯 林,廖凌湘,刘鑫磊,王 俊
1(四川师范大学 计算机科学学院,成都 610100)2(四川师范大学 商学院,成都 610100) E-mail:fenglin@sicnu.edu.cn
1 引 言
方面级情感分类是一种细粒度的情感分类任务,旨在识别文本中不同方面的情感,如文本:“Good food but dreadful service at that restaurant.”中,方面词food表达了积极情感,起作用的情感词是Good,方面词service表达了消极情感,起作用的情感词是dreadful.在文本含有多个情感词的情况下,如何令情感词动态地自适应方面词是值得关注的一个问题.
在处理方面级情感分类问题上,传统的机器学习算法取得了一定的效果.通过复杂的人工规则和特征工程构造机器学习模型,但是这类做法往往需要消耗大量的时间和宝贵人力资源,而且训练出来的分类器存在精度较低、泛化能力较弱等问题.
近年来,方面级情感分类问题在深度网络模型中取得了长足的进步,特别是深度网络模型结合注意力机制能更好的提取深层次的文本特征、减少人工干预、提升模型的精度和泛化能力.Sun等人[1]通过方面词构造辅助句子,将方面级情感分类任务转化为句子对分类任务,分类效果有一定提升.Xu等人[2]基于BERT模型添加后训练任务,让模型增加领域和任务相关知识,取得了不错的分类效果.Yang等人[3]提出了一种基于上下文的局部注意力联合模型,模型能处理中英文数据,集成训练了领域适应的后训练任务,在多个基准数据集上有最佳表现.
然而,大多数深度网络神经网络情感分类模型采用均值注意力,不能很好的感知到文本情感词,突出情感词对文本分类的影响.同时,在一条文本中,还会有上文提到的多个情感词的情况.所以,如何令情感词动态地自适应方面词是非常值得研究的问题.为此,本文提出一种基于对抗学习的自适应加权方面级情感分类算法AWSCM(Adaptive Weighted aspect-level Sentiment Classification Model based on adversarial learning),AWSCM通过动态加权机制对文本的每个单词自适应地学习权重,提升情感词影响.同时,为提升模型的鲁棒性,AWSCM采用了对抗学习,通过对抗学习算法和训练样本计算扰动以获得对抗样本,再通过学习对抗样本扩大模型的决策边界.实验结果表明,AWSCM与基线模型相比较有提升,而且通过消融实验也验证了AWSCM的注意力机制和对抗学习方法有效,AWSCM的结构设计合理.
2 相关知识
2.1 对抗学习
在对抗学习[4]的训练中,标签采用的是原训练样本的标签,通过对抗学习,模型可以优化决策边界,提升模型的鲁棒性和泛化能力.
在有标签的环境下,对抗训练损失为:
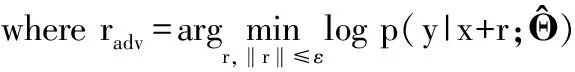
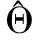
在无标签的环境下,对抗训练损失为:

由Goodfellow等人[5]提出的FGSM(Fast Gradient Sign Method)算法是一种基于梯度计算扰动的方法.FGSM算法先通过输入数据计算梯度,再通过梯度计算扰动,公式如下:
g=▽xL(Θ,x,y)
radv=ε·sign(g)
式中,L表示损失函数,g表示梯度,sign表示激活函数.
由Dai等人提出的FGM(Fast Gradient Method)算法[6]是基于FGSM的改进.FGM提出一种基于输入梯度L2范数缩放的优化计算扰动公式为:
radv=ε·g/‖g‖2,where g=∇xlog p(y|x;Θ)
FGSM和FGM都是依据超参数ε可以一步到位获得扰动radv,为获得更优解的扰动,Madry等人[7]提出基于多次迭代的PGD(Projected Gradient Descent)算法,PGD算法的对抗样本计算公式为:
xt+1=Πx+R(xtαsign(∇xL(Θ,x,y)))
式中,R表示扰动集合,α表示步长,Πx+R表示以某个扰动阈值为半径的球上投影,如果迭代扰动幅度过大会投影回球面.PGD算法通过α步长迭代多次获得和学习对抗样本,再最优化内部损失和外部损失,公式如下:
式中,D表示一种数据分布.对比FGSM和FGM算法,PGD算法需要多次迭代优化扰动,存在计算资源消耗较大的问题.因此,FreeAT算法[8]和YOPO算法[9]都是基于PGD的训练消耗问题,相继提出的优化算法.
此外,基于计算扰动优化问题,Zhu等人[10]提出FreeLB算法,通过求取多次迭代的平均梯度计算扰动.Jiang等人[11]提出关于对抗正则损失的扰动优化计算,提升模型的鲁棒性.
2.2 BERT模型
2018年,Devlin等人[12]提出的BERT模型,刷新了NLP大多数任务的最佳表现.BERT模型与以往的卷积神经网络和循环神经网络完全不同,采用Transformer[13]的编码器Encoder结构.
首先,BERT模型注意力机制的一个核心组件是缩放注意力机制(Scaled Dot-Product Attention,SDA).其计算公式为:
式中,Q、K、V是文本向量化后的查询、键、值矩阵.dk代表K的维度,dk使内积不至于太大,防止梯度消失.
其次,BERT模型注意力机制的另一个关键组件是多头注意力(Multi-Head Attention,MHA),如图1所示,Q、K、V要先进行线性变换,再进行SDA操作,得到某一个头的计算公式如下:
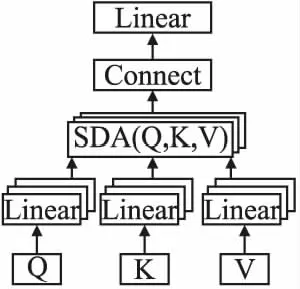
图1 多头注意力机制Fig.1 Multi-head attention mechanism
一次SDA计算操作是一种角度的特征提取,这种操作要进行多次,即多角度进行特征的提取,也就是多头注意力,然后把SDA提取的所有特征进行拼接和线性变换,得到多头注意力的表示如下:
MHA=(MHA1⨁MHA2⨁…⨁MHAh)·W*
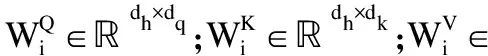
3 AWSCM模型
假设数据集文本表示为context={w1,w2,…,wk,wk+1,…,wk+t-1,…,wm},方面词表示为aspect={wk,wk+1,…,wk+t-1},方面词情感标签polarity∈{-1,0,1}.其中,m表示文本长度、t表示方面词长度、k∈[1,m)表示方面词在文本中的起始位置.那么,方面级情感分类的任务可以描述为:
Function:F[(context,aspect)]→polarity
即从上下文中学习方面词的情感.
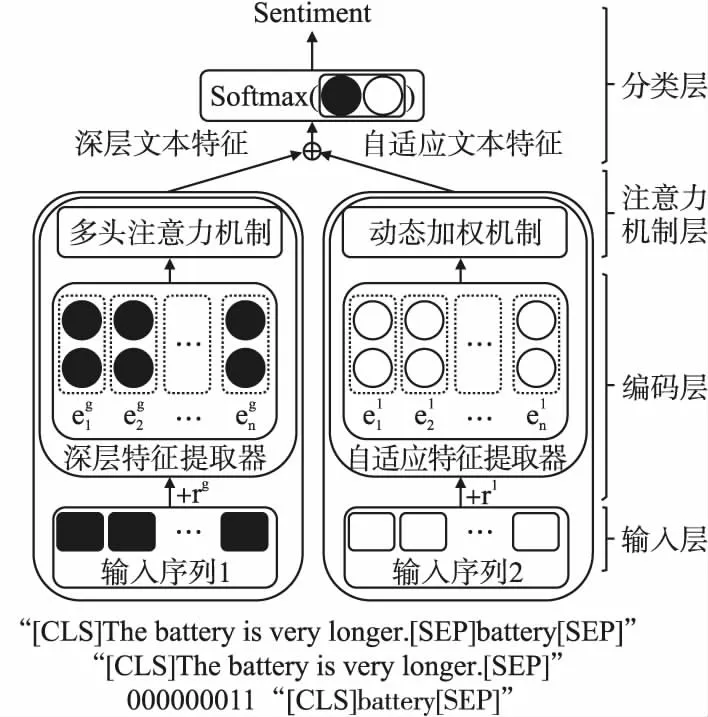
图2 AWSCM模型结构Fig.2 Structure of AWSCM model
AWSCM的结构如图2所示,主要有4部分组成:输入层、编码层、注意力机制层、分类层.输入层输入通过特定预处理后的文本序列.编码层采用BERT模型对文本编码,通过训练样求取梯度以计算扰动,扰动加在训练样本上生成对抗样本.在注意力机制层,动态加权机制提取到自适应权重文本特征、多头注意力机提取深层文本特征.在分类层,模型联合学习文本特征,并完成对抗样本的训练.
3.1 输入层
将文本预处理成两种形式的输入,由于BERT模型提取的特征较好,所以令这两种输入形式都能适配BERT模型输入,以充分发挥BERT模型的优势.假设有一条文本数据:“The battery is very longer.”那么,通过预处理会得到输入序列1样本:“[CLS] The battery is very longer [SEP] battery [SEP]”和000000011,其中“[CLS]”符号表示起始标识符,“[SEP]”表示分隔符,全0标记“起始符+句子+分隔符”,全1标记“方面词+分隔符”.以及输入序列2样本:“[CLS] The battery is very longer [SEP]”和“[CLS] battery [SEP]”.
3.2 编码层
为了获得更好的表现,AWSCM使用了两个独立的特征提取器.在编码层,使用的都是BERT编码,通过编码层每个词都可以映射到一个对应向量空间的位置[14].假设输入序列1和输入序列2分别表示为X1和Xg,那么有:
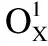
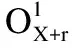

图3 BERT编码过程Fig.3 Encode process of BERT
1)嵌入模块
首先,根据BERT字典(1)https://github.com/google-research/bert,将预处理得到的输入序列替换成对应的BERT词序列.根据序列中的“[CLS]”和“[SEP]”等信息,得到与词序列同等长度的不同句子标志序列,再计算每个词的位置,由词位置组成位置序列.最后叠加计算词序列+不同句子标志序列+位置序列之和作为多头注意力机制模块的输入.
2)多头注意力机制模块
多头注意力机制见3.3节第1部分有详尽的描述.此部分值得注意的是这里的多头注意力机制输出要经过随机失活和归一化操作.
3)前馈网络模块
在前馈网络模块,要经过两次线性变换网络和RELU激活函数.假设多头注意力机制模块的输出为x*,那么有:
FFN(x*)=max(0,x*W1+b1)W2+b2
式中的权重矩阵、偏置都是可学习和随机初始化的.与多头注意力机制模块相似,FFN(x*)也要经过随机失活和归一化操作.
最后,AWSCM编码层的输出是图3的BERT编码过程重复执行6次提取特征的结果,上一BERT编码过程的输出作为下一BERT编码过程的输入.
3.3 注意力机制层
通过BERT模型自身的注意力机制提取的特征只有一种,较为单一.所以AWSCM采用多头注意机制提取深层文本特征,采用动态加权机制增强文本的局部特征.
1)多头注意力机制
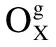
依据SDA公式有:

2)动态加权机制
在大多数情况下,一条文本中可能会有多个情感词.在多个情感词的文本环境下,情感词的位置很重要,一般而言,靠近方面词端的情感词起到的作用较大,而远离方面词端的情感词不仅对方面词的影响相对较小,还有可能产生相反效果干扰模型的学习.
为此,AWSCM采用动态加权机制增大靠近方面词端的情感词权重、减小远离方面词端的情感词权重.AWSCM定义了语义距离D,根据D来给上下文单词进行动态分配权重.根据本章的符号表示,对context中任意一个单词wc(1≤c≤m),语义距离D的计算公式为:
Dc=|c-(k+|t/2|)|-|t/2|
式中的k和t在上文有提及,分别表示方面词在文本中的起始位置和方面词长度.通过上面的公式得到每个位置的语义距离Dc后,进一步计算权重SC:
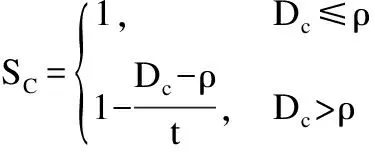
下面通过文本“Good food but dreadful service at that restaurant.”作为案例,展示动态加权机制.设阈值ρ为1,同时暂不考虑起始标识符“[CLS]” 和分隔符“[SEP]”的情况下.当方面词为food时,那么t=1,k=2,根据上面的公式有权重矩阵S={1,2,1,-1,-2,-3,-4},当方面词为service时,那么t=1,k=5,根据上面的公式有矩阵S={-2,-1,0,1,2,1,0,-1},将两种权重矩阵可视化展示,如图4所示.
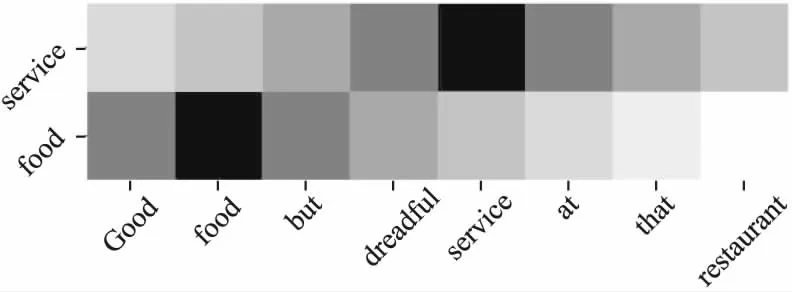
图4 权重分布Fig.4 Weight distribution
图4中,横轴是文本中的每个单词,纵轴是文本中的方面词,颜色越深代表响应权重越大.当food为方面词时,情感词Good的权重大于dreadful,而当方面词为service时,情感词dreadful的权重大于Good,展示了多情感词能自适应文本.同时,情感词Good在不同方面词food和service下的权重会不同,情感词dreadful在不同方面词下的权重也会不同,充分展示了情感词基于不同方面词对文本的自适应性.
3.4 分类层
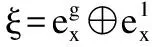
式中Ws和bs是线性网络的权重矩阵和偏置.通过最终语义表示X计算情感概率,有:
式中yi表示训练样本的情感预测概率,Z代表情感的类别数.
3.5 模型优化策略
假设模型的参数Θ,模型使用交叉熵损失函数进行参数学习,采用L2规范化防止过拟合,有模型训练损失L1:
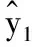
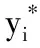
L=L1+L2
3.6 AWSCM模型实现
算法1.AWSCM学习策略
输入:数据集T,训练次数epoch,随机失活率dropout,
输出:情感分类模型F
1. 将数据处理成输入序列1和序列2的形式,表示为X1和Xg
2 .随机初始化模型F中所有网络参数
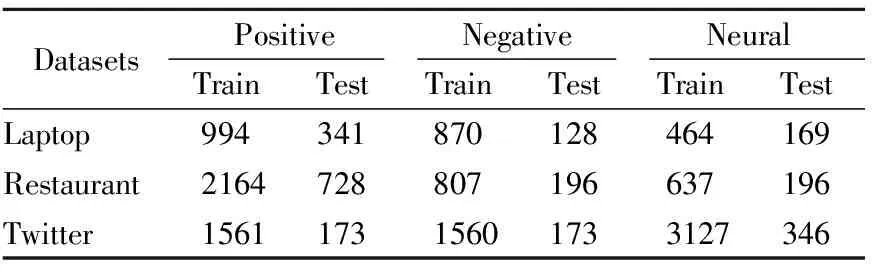
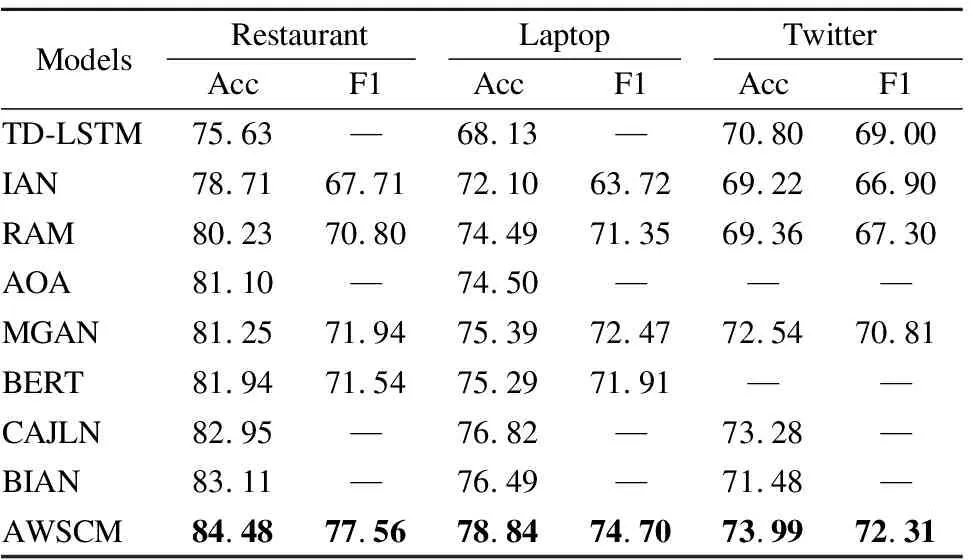
3. FOR(i=0;i 4. 通过PGD算法计算X1和Xg的扰动,得到rg和r1 8. 将y与真实标签做交叉熵损失,更新参数 12. 将y*与真实标签做交叉熵损失,更新参数 13.END FOR 14.输出分类模型F 本文采用SemEval2014任务4的Laptop、Restaurant评论数据集和ACL-14 Twitter社交数据集作为实验数据集,如表1所示,Laptop数据集一共有2328条训练数据和638条测试数据,Restaurant数据集一共有3608条训练数据和1120条测试数据,Twitter数据集一共有6248条训练数据和692条测试数据. 表1 实验数据集Table 1 Datasets of experiment 1)准确率:三类样本中,分类正确的样本所占的比例. 式中,Tpos、Tneu、Tneg代表分类正确的积极样本、中性样本、消极样本.Fpos、Fneu、Fneg代表分类错误的积极样本、中性样本、消极样本. 2)f1macro分数:f1macro分数是精度和查全率的加权平均值.f1macro分数的公式为: 式中,Z代表类别数、precisioni和recalli代表第i类的精度和召回率. 本文的实验在TeslaV100-32GPU、PyTorch深度学习框架、Linux操作系统环境下进行.模型采用Adam优化器快速迭代和最小化训练损失[15]、BERT词嵌入的维度为768、隐含层维度为300、学习率LR=2e-5、L2规范化的权重衰减率λ=1e-5、每个batch=16、一个token的最大长度为85、参数的初始化采用Xavier分布正态初始化、验证集和训练集的划分比为0.25、dropout参数依据不同的数据集灵活变动[16]、对抗样本的学习用PGD算法、扰动阈值为1、步长α=0.3、语义距离阈值ρ=5. 1)TD-LSTM模型[17],通过将方面词与上文、方面词与下文分别单独建模,放入长短期记忆网络(Long Short-Term Memory,LSTM),提取最后一层隐含层作为最后的语义表示. 2)交互注意力网络模型(Interactive Attention Networks,IAN)[18]分别采用两个长短期记忆网络对上下文和方面词编码,然后分别提取两个隐含层的注意力特征,最后将上下文注意力和方面词注意力进行交叉学习.效果比LSTM等模型有较大提升. 3)循环注意力记忆网络模型(Recurrent Attention Network on Memory,RAM)[19]使用双向的LSTM来生成记忆切片,记忆切片根据上下文与方面词的位置学习不同权重,然后再通过递归网络构建一个多层注意力模型. 4)AOA模型[20],模型采用Bi-LSTM对方面词和上下编码,然后在隐含层提取方面词和上下文矩阵乘积的行占比向量与列占比均值向量,二者相乘作为最终的注意力向量. 5)MGAN模型[21],MGAN模型在IAN模型的基础上,通过拼接上下文、方面词以及上下文与方面词的乘积矩阵提取了更细粒度的注意力网络. 6)BERT模型[12],基础版本的BERT模型采用多头注意力机制提取特征,在方面级情感分类上有很强的表现,超越了很多经典模型的深度网络模型. 7)CAJLN模型[22],由杨等人提出的一种面向上下文注意力联合学习网络的方面级短文本情感分类模型. 8)基于BERT的交互注意网络模型(BERT-base Interactive Attention Network,BIAN)[23],BINA模型在IAN模型的基础上,通过BERT采用多种注意力机制学习特征. 实验结果如表2所示,其中,Accuray用Acc表示,f1macro用F1表示. 表2 对比实验结果(%)Table 2 Result of compared experiment(%) 表2中,TD-LSTM、IAN、RAM、AOA、MGAN模型都是基于RNN的深度网络模型.TD-LSTM模型较为简单将方面词与上文、方面词与下文分别单独建模提取特征,在Restaurant和Laptop评论数据集上的表现低于其他RNN模型大约5%的准确率,结果表明TD-LSTM模型提取的特征不好,分类效果不佳.同TD-LSTM模型类似地,IAN模型也是分别对上下文和方面词单独建模,再交互学习提取特征,IAN模型提取的特征是浅层次的,实验效果上低于其他RNN模型大约2%到3%的准确率.RAM、AOA、MGAN模型提取的特征是较为复杂的深层次特征,从实验效果上整体来看,深层次注意力网络模型RAM、AOA、MGAN相对比浅层次注意力网络模型TD-LSTM、IAN效果更好. BERT模型的结构完全不同于RNN的模型,在3个公开数据集上有较高准确率.CAJLN、BIAN、AWSCM都是基于BERT结构的网络模型,AWSCM在Restaurant、Laptop、Twitter数据集上的准确率分别为84.48%、78.84%、73.99%,对比BERT模型准确率提升明显.AWSCM对比CAJLN模型准确率提升1.53%、2.02%、0.71%,对比BIAN模型准确率提升1.37%、2.35%、2.51%.综上所述,AWSCM与大多数深度神经网络情感分类模型相比有提升. 在本小结通过控制变量验证动态加权机制和对抗学习部分的设计是否合理.为区分带不同子部件的模型,用AWSCM_1表示模型不带动态加权注意力机制和对抗学习算法的情况,用AWSCM_2表示模型不带对抗学习算法的情况,用AWSCM_3表示模型不带动态加权注意力机制的情况,用AWSCM表示模型子部件完备的情况.消融实验结果如表3所示. 通过表3可以看出,AWSCM_1在Restaurant、Laptop、Twitter数据集上准率分别达到了81.61%、75.08%、71.24%,表现好于AOA等5个基线模型,证明模型的基础部件提取特征能力强.AWSCM_2在Restaurant、Laptop、Twitter数据集上比AWSCM_1分别提升2.69%、2.98%、0.73%准确率,F1值也不同程度提升,证明了动态加权机制有效,分类效果提升明显.AWSCM_3在Restaurant、Laptop、Twitter数据集上比AWSCM_1分别提升2.32%、1.25%、2.75%准确率,F1值也不同程度提升,证明了AWSCM的对抗学习算法能扩大模型的决策边界.AWNBLA对比AWSCM_2、AWSCM_3在不同数据集上有不同程度的提升,验证了模型的结构设计合理. 由表1可知,Twitter数据集对比Laptop和Restaurant数据集有更明显的数据不平衡问题.在Twitter数据上,AWSCM对比AWSCM_3准确率没有提升,F1值小幅度提升0.11%,同时AWSCM_2比较AWSCM_1(即动态加权机制的消融)也是只有0.73%的较小幅度提升.类似的情况,还有基线模型中的RAM模型对比TD-LSTM模型,在Restaurant和Laptop数据集上表现好于TD-LSTM模型,然而在Twitter数据集上反而差于TD-LSTM.AWSCM的一个局限性就是没有采取有效的方法处理数据不平衡问题.另外,AWSCM的另一个局限性在于AWSCM的动态加权机制是一种模糊注意力机制,不能直接感知情感词的位置,准确的赋予情感词更大的权重. 方面级情感分类是情感分析的子任务.早期的传统机器学习方法在处理方面级情感分类问题上取得了一定的成就,然而存在繁琐的特征工程处理、训练出的分类器准确率低、泛化能力弱等问题.近年来,深度神经网络结合注意力机制模型有更好的表现,能提取出更深层次的文本特征,提升模型的准确率,然而大多数模型的注意力机制使用的是均值注意力,均值注意力机制无法有效的赋予情感词比较大的权重.为此,AWSCM采用了一种动态加权机制,通过动态加权机制能有效降低远离方面词端的情感词影响,提升靠近方面词端的情感词作用.同时,为了提升模型的鲁棒性,AWSCM还通过训练对抗样本扩大模型的决策边界,提升分类效果.实验结果表明,动态加权机制能增强靠近方面词端的情感词作用,提升分类准确率,基于对抗样本的训练能扩大模型决策边界,提升模型的鲁棒性. 但是,AWSCM没有处理不平衡数据的机制,以及在情感词的感知上采用的是模糊注意力机制.所以,下一步的工作将围绕不平衡数据处理问题和靠近方面词端的情感词感知问题展开.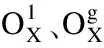
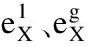
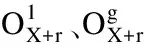
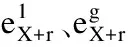
4 实验及结果分析
4.1 实验数据集
4.2 评估标准
4.3 实验环境
4.4 对比实验
4.5 消融实验
5 总结及未来的工作
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
数学学习与研究(2017年3期)2017-03-09
第二课堂(课外活动版)(2016年2期)2016-10-21
