
RCAR-UNet:基于粗糙通道注意力机制的视网膜血管分割网络
2023-04-19 18:33丁卫平黄嘉爽鞠恒荣
计算机研究与发展 2023年4期
孙 颖 丁卫平 黄嘉爽 鞠恒荣 李 铭 耿 宇
(南通大学信息科学技术学院 江苏南通 226019)
(17805056265@163.com)
眼健康作为国民健康中的重要组成部分,涉及到公共卫生和社会领域的民生福祉,引起了国家健康委的高度重视[1].视网膜血管中蕴含丰富的形态特征,如血管直径、旁支角度、尺寸和弯曲度等[2].各种眼科疾病以及心脑血管疾病都会导致视网膜血管出现形态结构变化、出血等不同程度的病变,从而导致视力受损[3],所以在临床上医生广泛使用眼底图像来分析视网膜血管的形态变化并辅助诊断各种眼科及心脑血管等疾病具有重要意义[4]. 然而眼底图像中视网膜血管分布密集而无规律,存在大量易与背景混淆、对比度较低的细小血管,血管边界模糊不清,同时易受采集设备和光照以及病变组织的影响[5]. 这些问题使得临床上手动分割视网膜血管不仅工作量巨大而且对医疗人员的经验和技能要求颇高. 此外,不同专家对同一张图像的血管提取也存在主观上的差异,手动分割已不能满足临床的需要.
随着计算机技术的不断发展,实现眼底视网膜血管的智能分割并对眼科疾病进行辅助诊断和决策,成为国内外学者关注的研究热点. 深度学习凭借其在识别应用中超高的预测准确率,在图像处理领域获得了极大关注[6-9]. 与传统方法相比,深度学习模型能够以端到端的方式自动提取特征.全卷积神经网络[10-11](fully convolutional network,FCN)是首个应用于图像语义分割任务的神经网络,在此基础上形成目前分割任务中最流行的编解码结构[12-13]. 而U-Net模型不仅具有编解码结构,同时在U 型对称层之间添加跳跃连接,实现低层特征和高层特征的拼接和融合,在图像分割领域有显著的优势,在医学图像分割领域获得较好的效果. 何慧等人[14]利用改进预测编码器U-Net 模型实现PET 肿瘤的自动分割,实现了更准确、快速、稳定的肿瘤分割,分割结果可以达到金标准的88.5%;Rundo 等人[15]为了解决前列腺区域分割任务,将Squeeze-and-Excitation 块合并到U-Net中,提出了一种新的卷积神经网络,称为USE-Net;Jin 等人[16]将可变形卷积集成到U-Net 模型中,提出DUNet 网络模型,根据血管的大小和形状自适应地调节感受野来捕获各种形状和大小的视网膜血管等.
Attention 机制是模仿人类注意力而提出的一种解决问题的方法,是一种能让模型对与任务相关的重要信息重点关注的技术,能够作用于任何序列模型,其应用领域包括文本、图片等. Basiri 等人[17]将Attention 机制和长短期记忆模型相融合,提出一种基于注意力的双向CNN-RNN(convolutional neural networkrecurrent neural network)深度模型用于情感分析;Haut等人[18]将Attention 机制和残差网络模型相结合用于分析遥感高光谱图像,得到更为准确的分类准确率.
进一步地,将符合人类视觉机制的Attention 机制与能够实现低层特征和高层特征融合的U-Net 模型相结合,实现对显著性区域的关注,在医学图像分割中广泛应用. Guo 等人[19]开发了一个3D 深度注意力U-Net,从冠状动脉计算机断层扫描血管造影中分割左心室心肌轮廓;Cui 等人[20]将注意力机制和UNet 模型相结合,在短轴磁共振成像图像中进行心脏分割. 基于注意力机制的U-Net 模型在眼底视网膜血管分割中也取得不错效果[21-24],Guo 等人[21]提出了一种空间注意力U-Net 的轻量级网络实现对视网膜血管的精确分割;Tang 等人[22]提出多尺度的通道注意力模块和空间信息定位模块来提高血管末端的分割准确率.
上述模型与方法将Attention 机制融合U-Net 网络用于眼底视网膜血管分割中仍然存在一定的不足,视网膜血管分布密集、杂乱且形状不规则,血管粗细不一,存在大量细小血管,血管边界不清晰,且易受采集设备和光照以及病变组织等噪声的影响,上述模型无法解决血管边界的不确定性和细小血管的分割. 为弥补该不足之处,本文引入能有效分析不精确、不一致、不完整等各种不完备信息的粗糙集理论中上下近似概念设计粗糙神经元,对特征通道依赖关系进行合理粗糙化.
本文针对视网膜血管分布密集而杂乱,存在大量对比度低的细小血管,血管边界模糊,且易受采集设备和光照以及病变区域等噪声影响的特点,提出一种粗糙通道注意力残差U 型网络(RCAR-UNet),有效提高对细微血管的分割精度. 该网络以U-Net 模型为主干,首先引入粗糙集上下近似概念设计粗糙神经元. 然后利用粗糙神经元对每一层下采样视网膜血管特征图建立通道之间的依赖关系,构建粗糙通道注意力机制,将全局最大池化和全局平均池化分别作为通道重要性权重的上下近似神经元,将全局平均池化作为通道重要性权重的下近似神经元,对每个通道重要性权重设置上下限,并对上下限赋予自适应权重系数,进行神经元间加权求和,得到更加合理的Attention 系数;对下采样的视网膜血管特征图进行特征的重标定,并与U-Net 模型对称层的上采样视网膜血管特征图进行高低层特征之间的拼接融合. 最后为解决经典U-Net 网络的退化问题,在该模型中添加残差连接,实现将低层视网膜特征直接传递给高层,可有效提取更加准确的视网膜血管特征.
1 相关工作
1.1 粗糙集理论
粗糙集于1982 年由波兰数学家Pawlak[25]提出,是一种可以定量分析处理不精确、不一致、不完整信息与知识的数学工具.粗糙集理论基于不可分辨关系[26]对数据进行划分,利用上下近似集对目标进行描述,形成正域、负域和边界域3 个互不重叠的区域[27].
假设决策信息系统表示为S=(U,AT,f,V),其中,U={x1,x2,…,xn}表示非空有限对象集合,n表示系统中对象的个数;AT表示信息系统的属性集合,它由条件属性集合C和决策属性集合D共同组成;表 示所有属性的值域;f:U×AT→V表示信息函数,∀a∈AT, x∈U ,f(x,a)∈Va.
粗糙集可以通过上、下近似集对目标概念X进行逼近. 粗糙集在属性集合R⊆A对论域U的任意对象子集X中的对象进行上、下近似集的划分,那么X基于属性集合R的上近似集R(X)和下近似集R(X)定义为
目标概念X基于属性集合R的正域POSR(X)、负域NEGR(X)和边界域BNDR(X)定义为
正域POSR(X)表示论域U中基于不可分辨关系R一定属于目标概念X的对象集合;负域NEGR(X)表示论域U中基于不可分辨关系R一定不属于目标概念X的对象集合;边界域BNDR(X)表示论域U中基于不可分辨关系R可能属于目标概念X,也可能不属于目标概念X的对象集合. 边界域BNDR(X)描述了X的粗糙度,若BNDR(X)=∅,说明其是精确的集合;若BNDR(X)≠∅,说明其是粗糙集.
1.2 Attention U-Net 模型
Attention U-Net 模型以U-Net 编解码的U 形网络结构为主干,其中U-Net 网络结构包括:
1) 收缩路径(编码器)包括卷积层、激活层和池化层. 卷积层具有局部感知、参数共享等特性,用于图像局部特征的自动提取;激活层的输出都是对上一层输入的线性映射,常用激活函数ReLu 和激活函数Sigmoid;池化层则是对所提取的特征进行数据的降维和压缩操作,常用平均池化和最大池化.
2) 扩展路径(解码器)包括反卷积层和卷积层,经过下采样特征图尺寸会越来越小,所以上采样主要用于恢复特征图的细节和尺寸.
3) 在上采样和下采样的同层结构中添加跳跃连接,将高层图像特征信息与低层图像特征信息相联合,实现上下特征信息的融合.
U-Net 模型最主要的思想是在收缩路径上捕获全局特征,在扩展路径上实现精确定位. 为解决扩展路径的上采样过程中重建的空间信息不精确问题,使用跳跃连接将下采样的空间信息与上采样的空间信息相结合,然而跳跃连接也带来了许多冗余的底层特征,造成大量的无效计算,浪费大量的计算资源.对此,Oktay 等人[28]将注意力门作用于U-Net 模型的跳跃连接中,提出Attention U-Net 模型,该模型能够有效地抑制不相关区域中的激活,从而减少冗余特征的数量,并且不会引入大量的参数和计算量,得到更加符合人类视觉机制的网络模型,其结构如图1所示. 同一张图像的不同区域关注度不同,对此,通过注意力门系数控制关注区域,得到更加具有语义的特征图. 注意力门具体结构如图2 所示. 将收缩路径得到的特征图g∈与扩展路径中同层通道数相同的特征图p∈相加,经过一系列的线性变换,得到注意力系数A∈将其与特征图p相乘,实现对特征图p的不同区域特征值的重新标定,得到新的特征图p′.
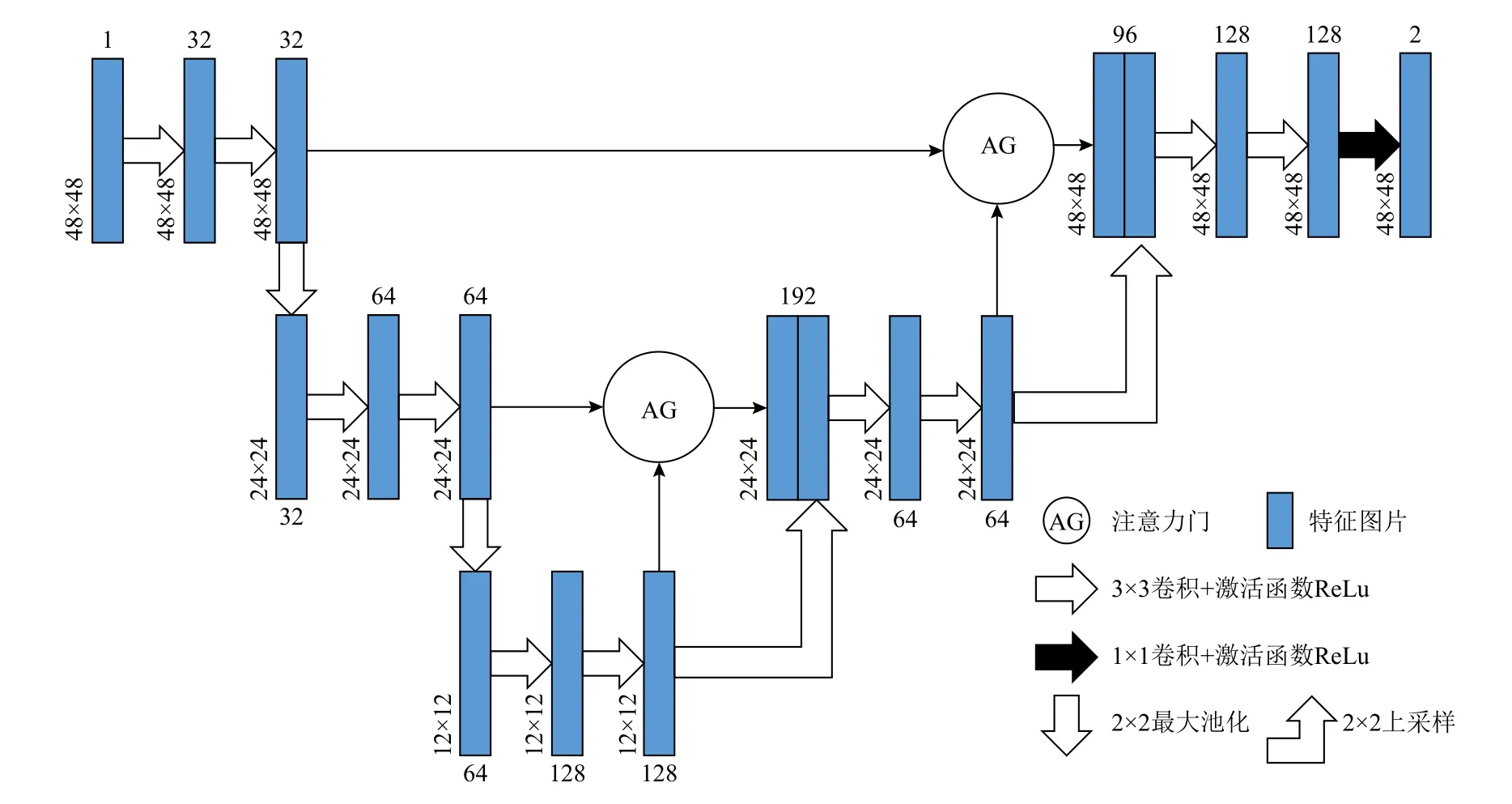
Fig.1 Attention U-Net network architecture图1 Attention U-Net 网络结构
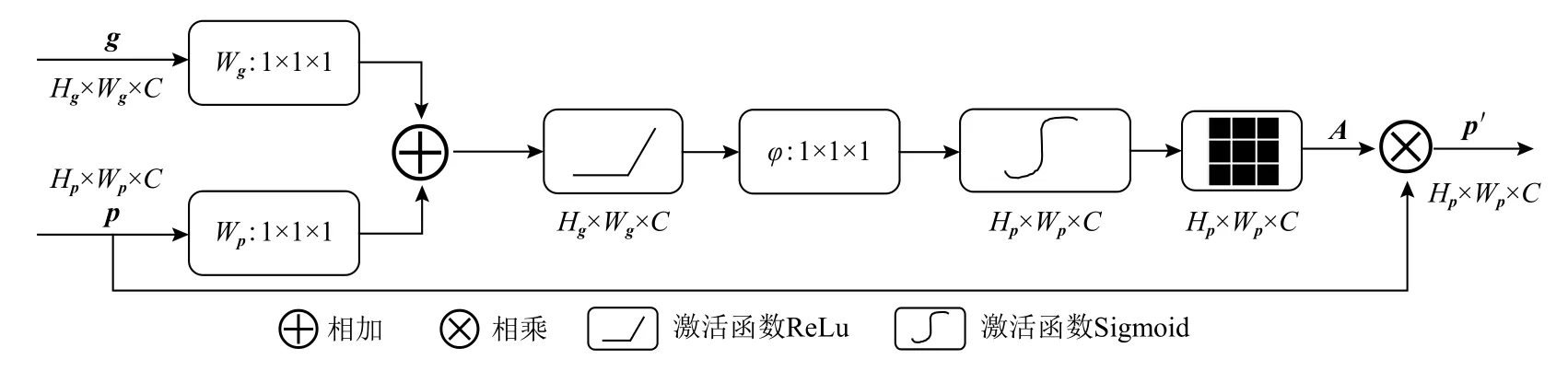
Fig.2 Attention gate architecture图2 注意力门结构
2 粗糙神经网络
图像信息复杂多样,其内容蕴含着诸如随机性、模糊性等不确定性信息,例如眼底视网膜血管分布杂乱,形状不规则并且边缘模糊不清,且易受采集设备和光照以及病变影响,这些眼底视网膜血管图像中蕴含的不确定信息使得深度神经网络效果不佳. 1996年,Lingras[29]使用上下界的一般概念引入了粗糙神经网络. 深度神经网络在学习复杂特征方面的成功以及粗糙神经网络处理不确定性的能力,促进了将粗糙神经网络与深度架构相结合[30-31].
2.1 粗糙神经元
上下限的概念已在人工智能的各种应用中使用,特别是粗糙集理论中上下近似集证明了上下限在规则生成中的有效性,粗糙集理论利用上下近似集对目标概念进行逼近,本文引入粗糙集的上下近似集的思想,构建上下近似神经元对注意力模块所得的注意力系数进行合理粗糙化,粗糙神经元[32-35]结构如图3 所示.
上近似神经元的参数θU={WU,bU,α},下近似神经元的参数θL={WL,bL,β},其中WU,bU表示上近似神经元的权重和偏差,WL,bL表示下近似神经元的权重和偏差. 图3 中OU,OL表示上下近似神经元的输出.与常规神经元的单个输出值不同的是,粗糙神经元的输出是一对上下限,其计算公式为:
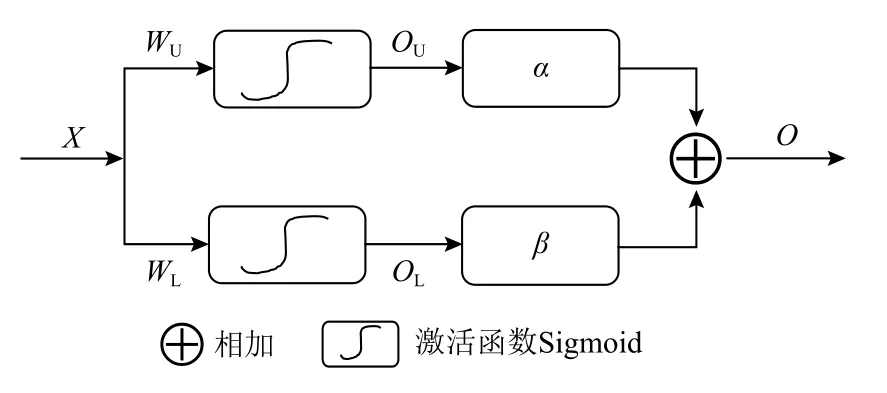
Fig.3 Rough neuron architecture图3 粗糙神经元结构
最终给定上下边界神经元一定的权重 α 和 β,加权求和得到最终粗糙神经元的输出O,表示为
粗糙神经元是对输入的数值映射为一个粗糙的范围,最后的输出取决于上下神经元的输出,对于不同的输出赋予一定的权重值,以区分不同神经元对最终输出的贡献. 该方法能够对输入的确定数值粗糙化,对确定性的数值进行重标定,得到更合理、准确的输出值.
2.2 通道注意力机制
特征图的通道数取决于卷积操作中卷积核的个数,以往认为得到的多通道特征图中每个通道所蕴含的信息重要程度相同,即不对特征通道的重要性加以区分. 然而同一张图像的不同区域关注度不同,同样,每个特征通道的关注度也有所差异. 例如1 张眼底视网膜血管图像有2 个通道,分割目标是血管,那么会更加关注与分割任务相关的血管通道,也就是需要赋予每个特征通道一个表征通道蕴含信息重要度的权重,以此对不同特征通道信息加以区分. 将表征每个特征通道信息重要性的权重与原特征图对应的每个通道相乘得到的对应值就是真实的特征图值.
为了建立特征通道之间的关系,引用一个新的维度信息来表征特征通道重要度,进行特征通道之间的融合,即通过训练网络参数的方式计算每个特征通道信息的重要性权重,依照所得到的特征通道重要性权重提升与当前分割任务相关的特征并抑制对当前分割任务无关的特征. 通道注意力机制[36-38]主要包括激励部分,其结构如图4 所示.
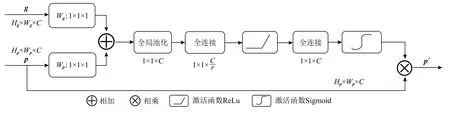
Fig.4 Channel attention mechanism图4 通道注意力机制
首先是压缩操作,对特征通道维度进行特征图的压缩,通过全局池化,将维度为Hp×Wp×C的特征图的每个通道的2 维数据转化为一个实数 R;然后是激励操作,包括2 层全连接:第1 个全连接层是把C个通道压缩成C/r个通道来减少模型所需的参数和计算时间,第2 个全连接层将特征图恢复为C个通道,使模型更加非线性,更好地适应通道之间的复杂关系,激活函数ReLu 降低了梯度消失的概率,激活函数Sigmoid 使C中每个通道的特征权值在0~1 之间;最后是特征重标定,重新计算特征通道值,通过权值乘法运算完成特征通道内对原始各个特征通道重要程度的重新标定,并作为下一级的输入数据.
2.3 基于粗糙通道注意力机制U-Net 模型
基于粗糙神经元和通道注意力机制,提出粗糙通道注意力机制模块,并将其嵌入到U-Net 模型的跳跃连接中. RCAR-UNet 模型结构分别如图5 和表1 所示.
在U-Net 模型的特征编码部分,构建一个简单的特征提取模块包括:残差连接的2 个3×3的卷积层和1 个2×2的最大池化层. 加入残差连接是因为残差连接能够实现将低层特征直接传播到高层,在一定程度上解决了网络退化的问题,以此提高模型性能.
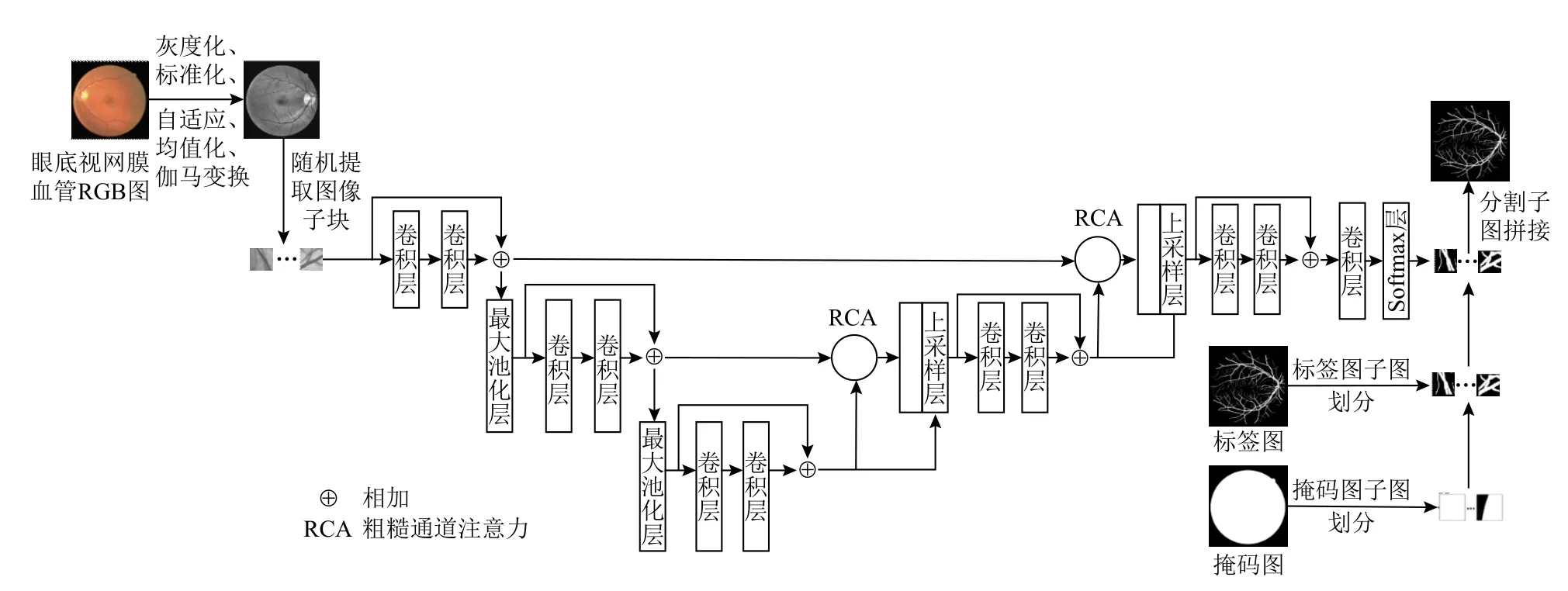
Fig.5 Architecture of RCAR-UNet图5 RCAR-UNet 模型结构
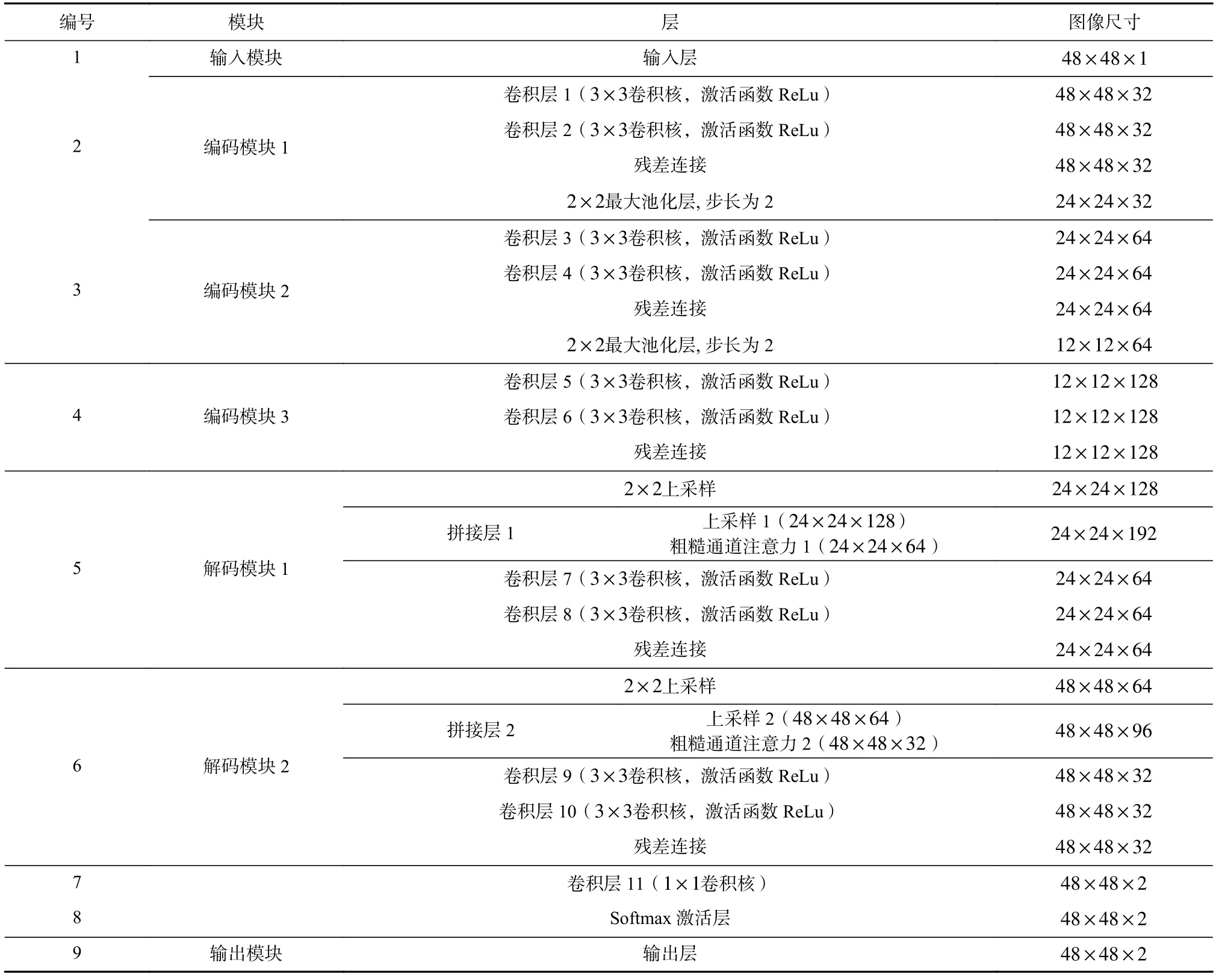
Table 1 U-Net Model Architecture Based on Rough Channel Attention表1 基于粗糙通道注意力U-Net 模型结构
在特征解码部分,使用粗糙通道注意力机制来融合特征图的上下语义信息,以便生成更具代表性的特征图.粗糙通道注意力机制融合了粗糙神经元处理不确定信息的能力和通道注意力机制能够区分不同特征通道重要性的优点. 通道注意力机制可以实现对特征图不同特征通道重要度的区分,一般选用全局平均池化对特征图进行压缩,建立特征通道之间的关系,其值在一定程度上具有全局感受野. 然而视网膜血管粗细不一,存在大量对比度较低的细微血管,其结构细长,只有一个或者几个像素的宽度,局部图像细节信息也不容忽视,因此加以利用全局最大池化对特征图进行压缩,使得其值在一定程度上具有局部感受野. 对此,本文在构建粗糙神经元时,使用全局最大池化和全局平均池化作为上下近似神经元对特征通道重要性进行上下限描述,使得Attention系数值兼具全局信息和局部细节信息.在此基础上进行特征重标定,得到新的视网膜血管特征图. 设计粗糙通道注意力机制结构如图6 所示.
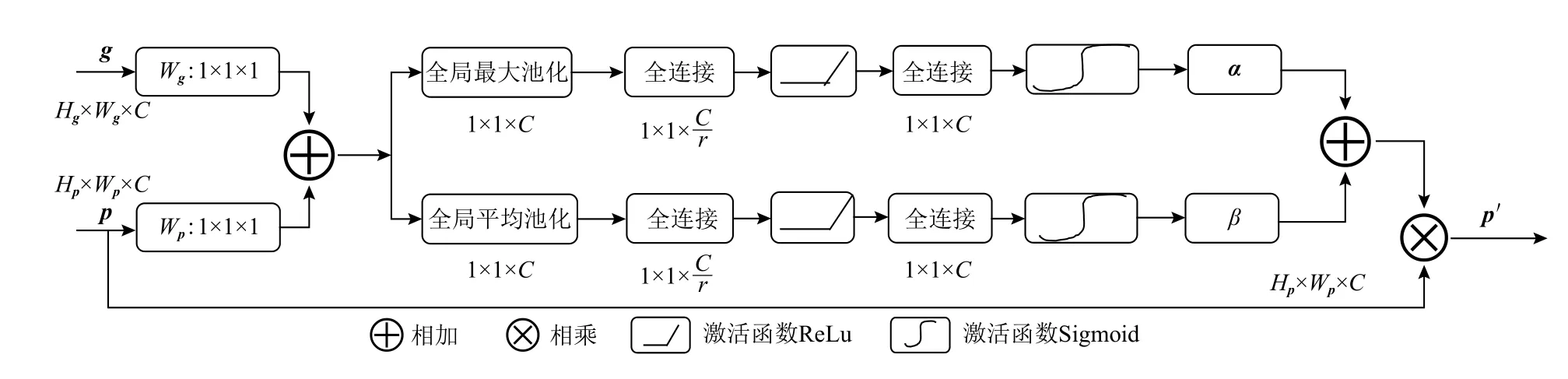
Fig.6 Rough channel attention mechanism图6 粗糙通道注意力机制
对高低特征图进行相加操作,得到融合特征图.表示为
利用全局最大池化层建立通道间的依赖关系,并保留全局信息,表示为
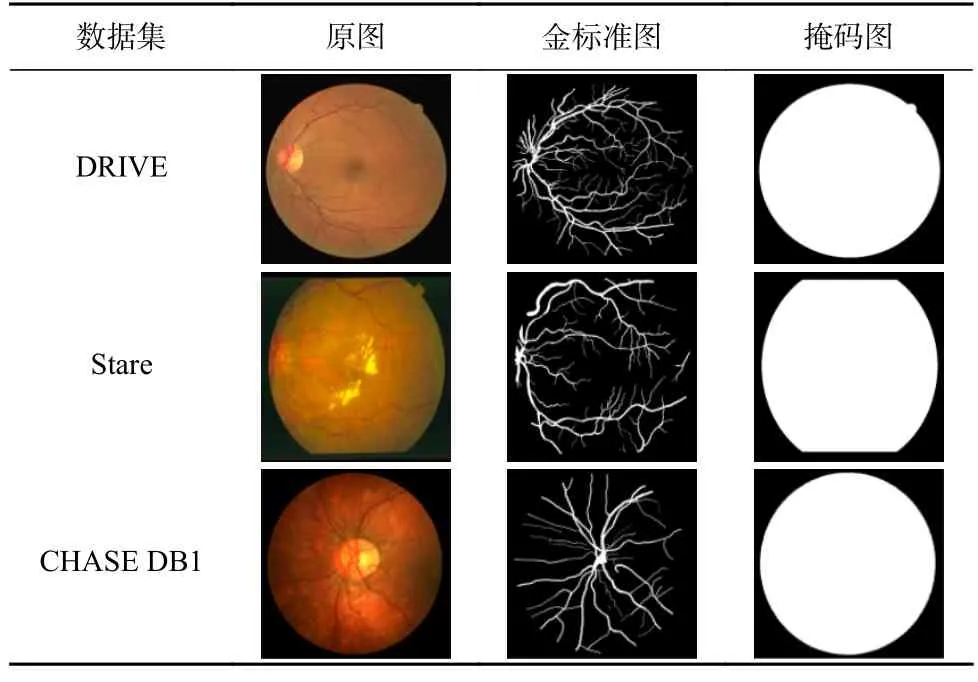
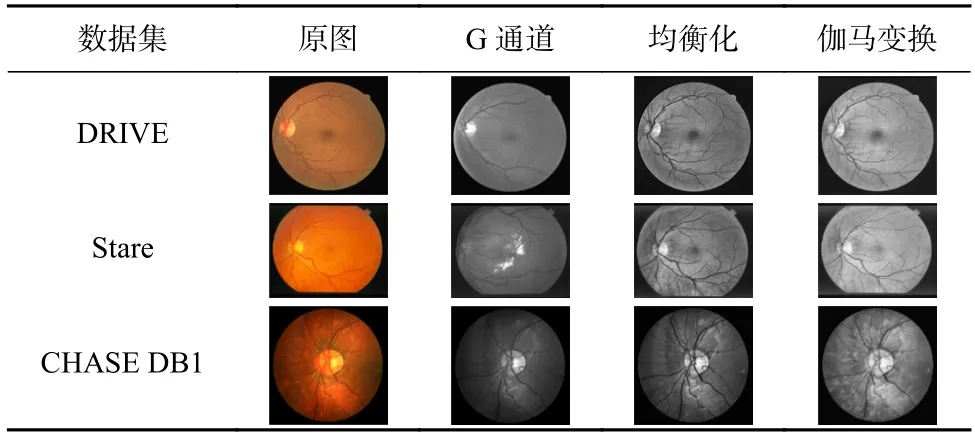
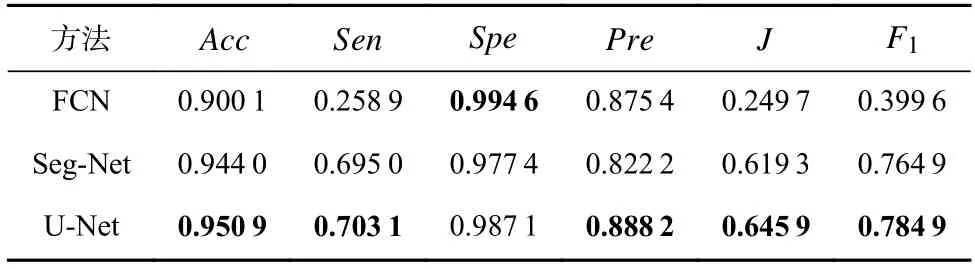
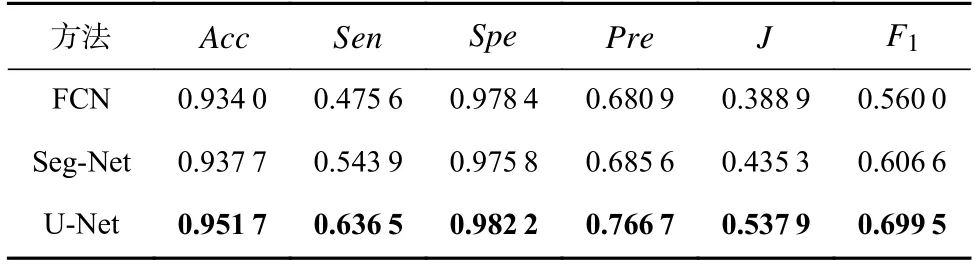
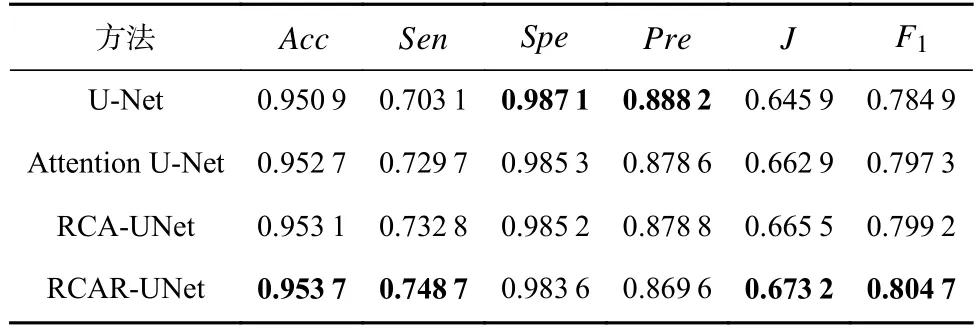
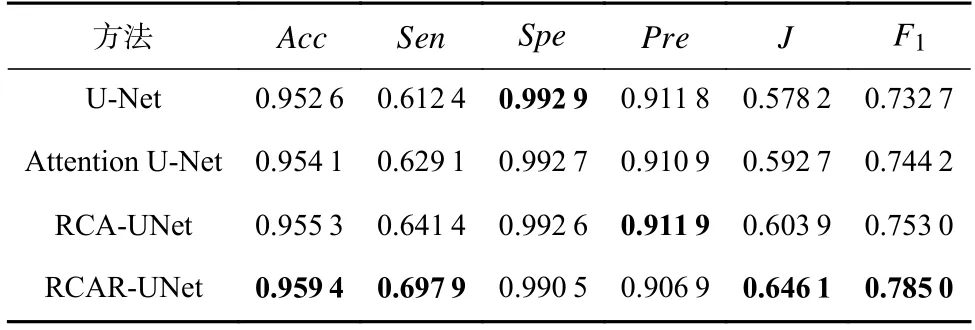
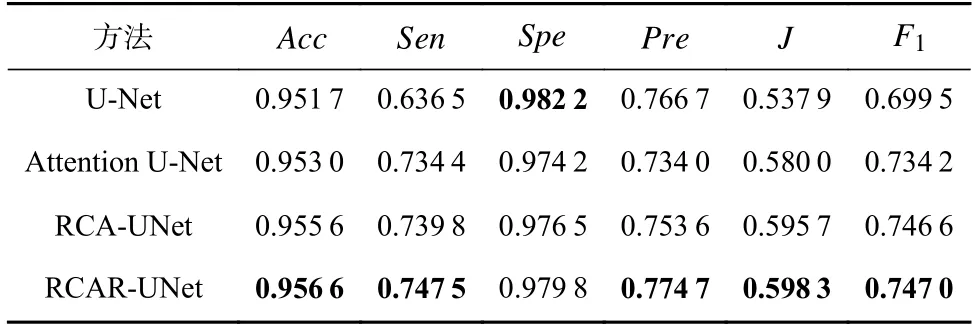
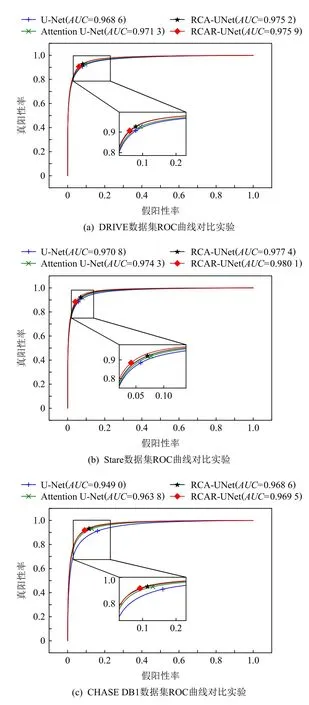
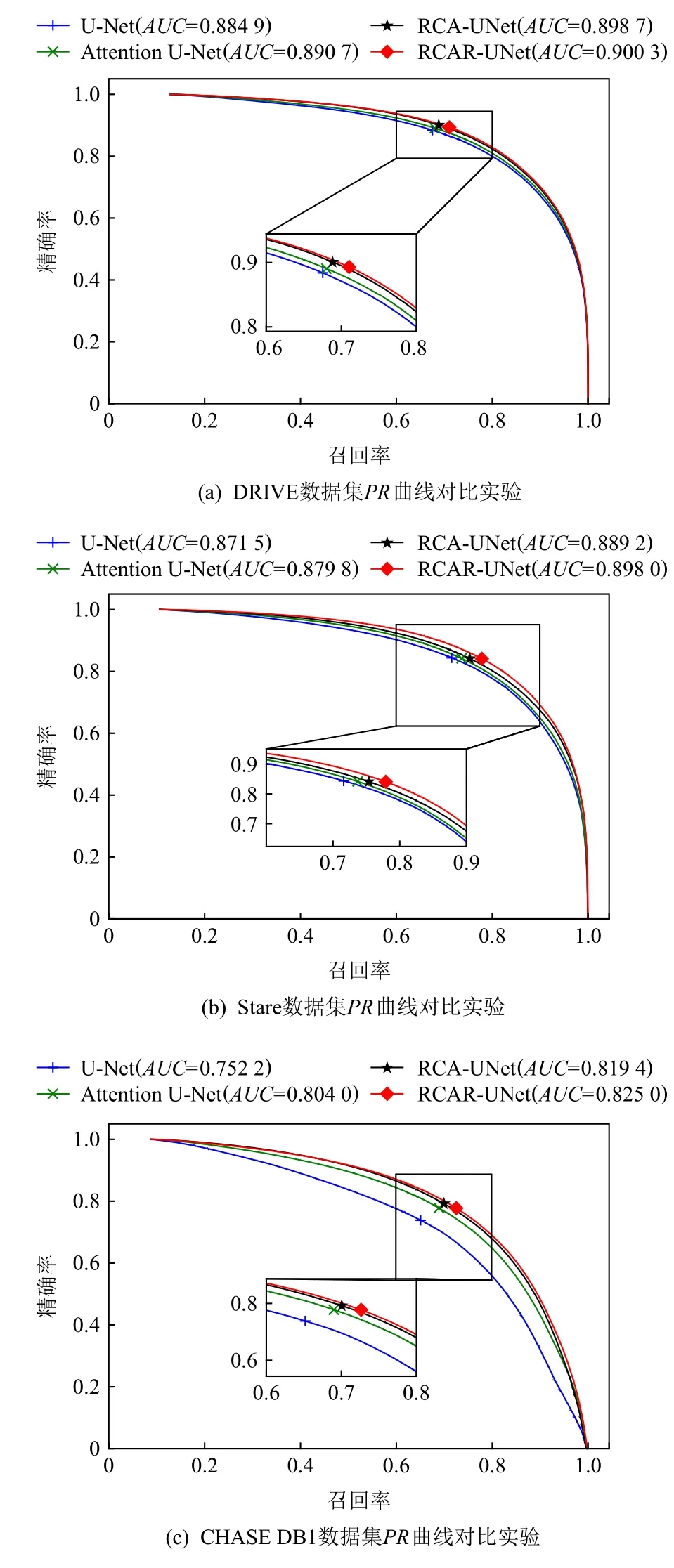
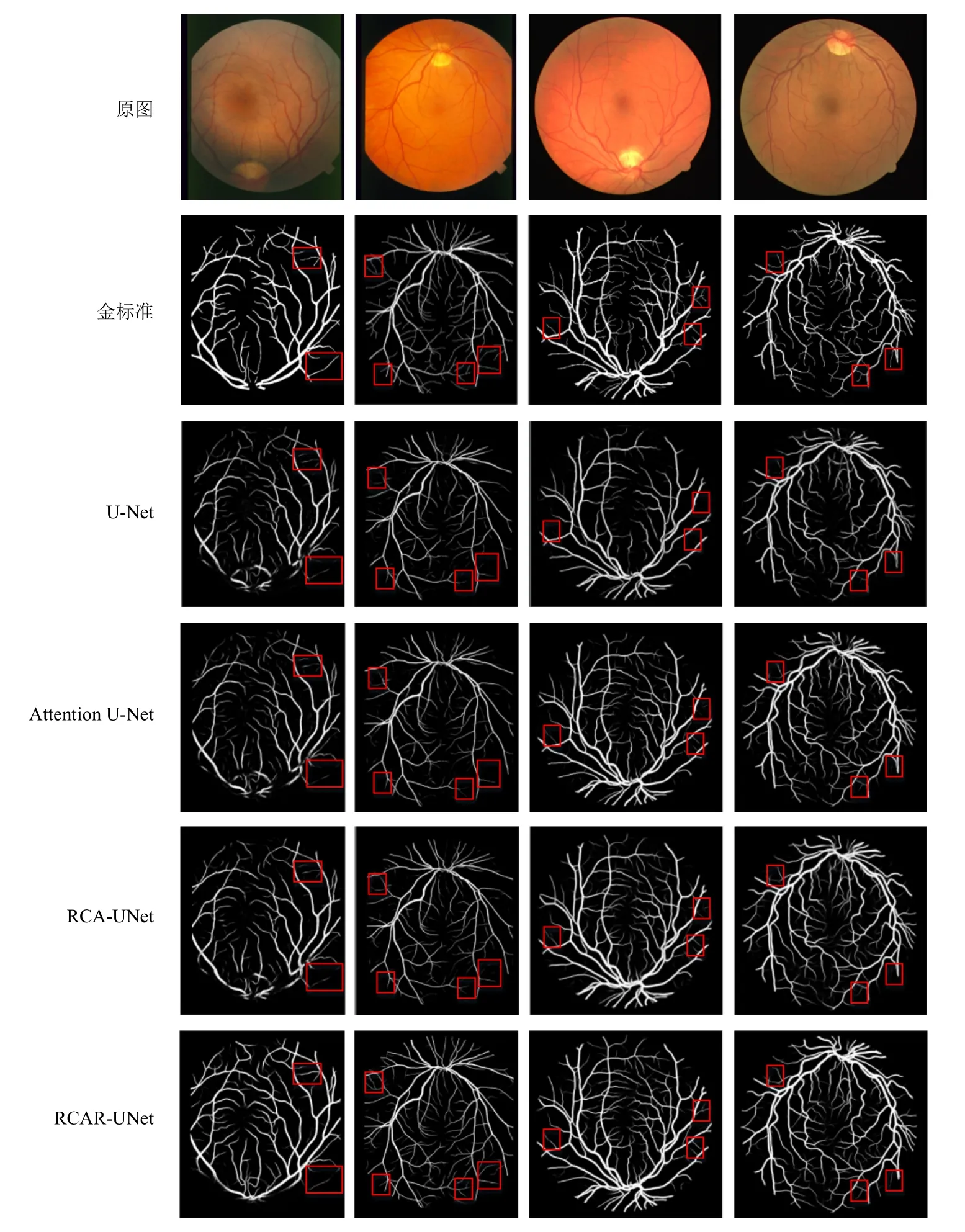
其中0 利用全局平均池化层建立通道之间的依赖关系,并保留局部信息,表示为 其中0 分别对全局平均池化和全局最大池化的2 个1×1×C的张量进行激励操作:第1 个全连接层是把C个通道压缩成C/r个通道来减少模型所需的参数和计算时间;第2 个全连接层将特征图恢复为C个通道,使模型更加非线性,更好地适应通道之间的复杂关系,r是指压缩的比例,本文设置r=16.激活函数ReLu 降低了梯度消失的概率,激活函数Sigmoid使C中每个通道的特征权值在0~1 之间,得到Attention 系数的上下限值,分别表示为 为了使得通道之间的依赖关系既包含全局信息,又包含局部细节信息.对所得到的通道重要性值的上下限进行加权操作,得到新的通道之间的依赖关系: 其中α,β分别表示上下神经元的权重信息. 利用输出的通道之间的依赖关系对特征图进行重新标定,得到新的特征图表示: 在U-Net 模型的特征解码部分,首先构建一个简单的恢复特征模块包括:一个2×2上采样层和残差连接的2 个3×3的卷积层;然后因为该任务包含血管类和非血管类2 类,所以在恢复特征尺寸后使用2 个1×1的卷积核进行卷积操作得到一个通道数为2 的特征图,一个通道表示血管类,另一个通道表示非血管类;最后使用Softmax层输出每个像素属于血管类的概率. 眼底图像分割的过程如算法1 所示. 算法1.RCA-UNet 模型的视网膜血管分割算法. 输入:彩色眼底视网膜血管图像input∈RH×W×3、掩码图mask∈RH×W×1; 输出:视网膜血管分割图out put∈RH×W×2. 1)对视网膜血管原图input∈RH×W×3进行灰度化、自适应均衡化等预处理,得到视网膜血管预处理图input′∈RH×W×1; 2)以步长patch_stride从视网膜血管预处理图input′∈RH×W×1中进行视网膜血管图像子块patch_image∈的划分,保证视网膜血管图像子块覆盖视网膜血管图; 3)将视网膜血管图像子块patch_image∈输入到训练好的RCAR-UNet 模型中,得到视网膜血管子块图patch_out put∈,其具体步骤为: ①利用卷积操作和残差连接提取眼底视网膜血管特征. ②利用最大池化对眼底视网膜血管特征进行降维. ③利用粗糙通道注意力机制求得较为合理的Attention 系数对收缩路径提取的视网膜血管特征进行准确重标定. ④利用上采样操作恢复视网膜血管特征图的尺寸,直到网络输入的视网膜血管图尺寸保持一致为止.1×1 ⑤采用2 个的卷积核进行操作得到通道为2 的视网膜血管特征图; ⑥利用Softmax 层得到视网膜血管特征图中的每个像素点属于血管类别和非血管类别的概率; ⑦设置阈值θ=0.5,如果视网膜血管特征图中的像素点属于血管类的概率值大于θ,则属于血管类;反之,属于非血管类. 4)将视网膜血管图像子块patch_out put∈按照提取顺序进行图像拼接,得到完整的视网膜血管分割图out put′∈ 5)对视网膜血管掩码mask∈RH×W×1进行通道的修改,使其通道数与视网膜血管网络分割图out put′∈保持一致,得到视网膜血管掩码图mask′∈ 6)利用视网膜血管掩码从视网膜血管网络输出图中抠出眼球部分,得到最终视网膜血管分割图out put∈RH×W×2. RCA-UNet 模型的时间复杂度可以表示为 时间复杂度与每一层的输出特征图尺寸Fi、每一个卷积核的尺寸Ki、上一层输出特征图的通道数Ci−1以及当前层输出特征图的通道数Ci有关,与此同时每一层特征图的输出尺寸F与输入尺寸X、卷积核的步长stride、填充的数量padding以及卷积核的尺寸K等相关,可表示为 3.1.1 数据集 DRIVE 数据集[39-41]发布于2004 年,包含40 张格式为tif. 尺寸为565×584 的彩色眼底图像,每张图像包含2 位专家手工标注的金标准图,并且自带视网膜血管的掩膜图. Stare 数据集[39-41]是1975 年Michael Goldbaum 发起的项目,用来进行视网膜血管分割的彩色眼底图数据库,包括20 张格式为ppm、尺寸为605×700 的彩色眼底图像,同样每张图像对应2 位专家手工标注的金标准图,相对应的掩膜需要自己通过代码进行掩膜的设置. CHASE DB1 数据集[39-41]包括从14 名学童的双眼中拍摄的28 张格式为jpg、尺寸为999×960 的视网膜图像. 每张图像具有2 位专家的手工分割标签,相对应的掩膜需要自己通过代码进行掩膜的设置. 一般情况下将前20 张图像用于训练,其余8 张图像用于测试. 3 个眼底视网膜血管图像数据集信息如表2 所示. Table 2 Information of Retinal Vessels Image Datasets表2 眼底视网膜血管图像数据集信息 3.1.2 预处理 由于眼底图像照明不均匀以及血管与背景之间的对比度较低等因素,为了捕获细小血管的更多特征并提高血管分割的准确性,需要将输入网络的眼底图像进行预处理. 首先对RGB 图像进行通道分离,发现G 通道的血管与背景之间的对比度最高,选取RGB 图像的G 通道完成图像的灰度变换,对视网膜血管灰度图像进行归一化;然后采用对比度受限的自适应直方图均衡化,在不放大眼底视网膜图像噪声的情况下增强视网膜血管与背景之间的对比度,以使眼底图像中血管的结构和特征更容易受到关注;最后使用Gamma 变换进行图像增强,对过白或者过暗的图像区域进行校正. 表3 分别表示原图和预处理之后的图像. Table 3 Information of Original Images and Preprocessed Images表3 原图与预处理图信息 3.1.3 数据集扩充 由于深度卷积神经网络的复杂性,训练一个深度卷积神经网络进行图像分割,通常需要大量标签图像,然而,只有几十张视网膜血管图像具有像素级的标签,因此,设计用于视网膜血管分割的深度学习模型容易出现过拟合现象. 对此,本文采用对原图进行分块的方式进行数据扩充,将训练图像以及相应的掩码图划分为大小为48×48 的图像子块,从中随机选取一定数量的图像子块数,图7 中展示了整合部分的图像子块以及相对应的掩码子块图. Fig.7 Sub-image and corresponding mask sub-image图7 图像子块以及相对应的掩码子块图 本研究使用基于Windows10 系统的工作站,运行在Intel®Core™i7-10750H CPU @2.60GHz 上,拥 有16GB 内存和NVidia GeForce RTX 2 060 6.0GB GPU,使用TensorFlow 和Keras 等框架构建文中所用的网络模型.在模型的训练过程中,采用交叉熵损失函数作为训练的损失函数,批大小batch_size设置为32,模型迭代的次数N_epochs设置为50,模型初始学习率设为0.01,选择SGD 随机梯度下降法作为优化器对模型的参数进行更新. 视网膜血管分割任务的实质是像素级的分类,判断像素点是血管类还是非血管类.血管是需要检测分割的目标,称作正类;非血管类的部位,称作负类.分割算法的结果与真实值比较可以得到混淆矩阵中的真阳性NTP、假阳性NFP、假阴性NTN、真阴性NFN,如表4 所示.其中NTP是将血管类正确分类为血管类的像素点数,NFP是将非血管类错分为血管类的像素点数,NTN是将非血管类分类为非血管类的像素点数,NFN是将血管类错分为非血管类的像素点数. Table 4 Confusion Matrix表4 混淆矩阵 为了评价视网膜血管分割算法的好坏,选用准确率Acc、灵敏度Sen、特异性Spe、精确率Pre等评价指标,其中Acc表示将血管类和背景类分类正确的概率,Sen表示将血管类分类正确的概率,Spe表示将背景类分类正确的概率,Pre表示预测为血管类的样本中真正为血管类所占的比例.为了进一步地评估分割模型的性能,利用Jaccard 相似度描述金标准图truth与分割图result之间的相似性和差异性,Jaccard 值越大说明相似度越高.各评价指标公式表示为: 本文所提模型是以U-Net 网络为基础网络,并针对视网膜血管的独特特性,将U-Net 网路和本文所提的粗糙通道注意力机制相融合.首先,为了验证基础网络U-Net 的有效性,选取目前较常使用的分割网络FCN 和Seg-Net[42]在眼底图像视网膜血管DRIVE,Stare,CHASE DB1 数据集上进行对比实验,从准确率Acc、灵敏度Sen、特异性Spe、精确率Pre、Jaccard 相似度J等评价指标对实验结果进行比较. FCN,Seg-Net,U-Net 模型在视网膜血管的3 个数据集上的对比结果分别如表5~7 所示,从表5~7 中可以发现,U-Net 模型具有更好的表现,总体表现优于其他2 个模型.更具体地说,U-Net 具有更高的分割准确率,对血管像素具有更好的识别能力,所得分割图和金标准图具有更高的相似度,对背景像素的识别能力也是具有竞争力的,综合考虑分割精度和敏感度,取得更高的F1值. Table 5 Comparison Results on DRIVE Dataset表5 DRIVE 数据集对比结果 Table 6 Comparison Results on Stare Dataset表6 Stare 数据集对比结果 Table 7 Comparison Results on CHASE DB1 Dataset表7 CHASE DB1 数据集对比结果 上述结果表明Seg-Net 和U-Net 这类基于编解码结构的网络在医学图像分割上具有更好的竞争力,而增加了跳跃连接结构的U-Net 在上采样过程中将对称层的特征图进行通道上的拼接,实现低层特征和高级特征的信息融合使得网络能够提取和保留更多视网膜血管局部细节信息,从而提高了图像分割精度.基于此,选用U-Net 作为基础网络具有一定的有效性. 为了进一步验证本文所提粗糙通道注意力机制的有效性,选取U-Net,Attention U-Net,RCA-UNet 在3 个眼底视网膜血管数据集中进行对比,从准确率Acc、灵敏度Sen、特异性Spe、精确率Pre、Jaccard 相似度J等评价指标对实验结果进行比较,实验结果分别如表8~10 所示.实验结果表明:在3 个数据集中RCA-UNet 模型都具有相对较好的性能.具体而言,RCA-UNet 模型具有较高的灵敏度Sen,对血管类具有更好的识别能力,在3 个数据集上相对于U-Net 模型提高了2.97%,2.9%,10.33%,相对于Attention UNet 模型提高了1.35%,1.23%,0.54%.在考虑模型性能的时候,单纯地追求精度Pre或者灵敏度Sen的提升并没有太大作用,在实际分割任务中,需要结合正负样本比进行综合评价,对此从精度Pre与灵敏度Sen的调和平均值F1可以看出RCA-UNet 模型具有较好的性能,提高0.19%~1.43%,0.88%~2.03%,1.24%~4.71%.另外,RCAR-UNet 所得的分割图与金标准的Jaccard相似度更高,相较于其他模型相似度提高了0.26%~1.96%,1.12%~2.57%和1.57%~5.78%. 上述实验结果清楚地表明利用全局最大池化和全局平均池化构建上下近似神经元的粗糙通道注意力机制的有效性.分析其原因在于考虑了特征通道之间的依赖关系,借助粗糙集的上下近似原理,利用全局最大池化和全局平均池化分别构建上下近似神经元,并赋予一定的自适应权重,得到较为合理的Attention 系数,并对特征图进行相应的重标定操作,使得在上采样的过程中,得到更加细致的特征信息. Table 8 Comparison Results on DRIVE Dataset表8 DRIVE 数据集对比结果 为了在说明粗糙通道注意力机制的有效性的同时,进一步验证残差连接的有效性,本文将RCAUNet 和RCAR-UNet 在3 个数据集上进行对比实验,实验结果分别如表8~10 所示. 实验结果表明,本文所提模型RCAR-UNet 能够得到更好的视网膜血管分割效果.从3 个表中可以发现,在3 个视网膜血管数据集中各个评价指标都有所提升. 从表8 中可以很直观地看出在DRIVE 数据集上,RCAR-UNet 相对于RCAUNet 模型,Acc提高了0.06%,Sen提高了1.59%,相似度J提高了0.77%,F1提高了0.55%;从表9 中可以看出,RCAR-UNet 在Acc,Sen,J,F1指标上都有明显的提升,分别提升了0.41%,5.65%,4.22%,3.2%;从表10中可以看出,RCAR-UNet 在CHASE DB1 数据集上相对于RCA-UNet 模型的提升不是很大,但是都有所改善,Acc提高了0.1%,Sen提高了0.33%,Pre提高了2.11%,Jaccard 相似度提高0.26%,F1指标提高了0.04%. 上述实验结果充分说明模型中添加残差连接实现特征映射的有效性,将低层特征直接传递给高层特征的短跳跃连接方式,不仅丰富网络特征提取,并且有助于训练模型时梯度的反向传播,可有效解决网络退化问题. Table 9 Comparison Results on Stare Dataset表9 Stare 数据集对比结果 Table 10 Comparison Results on CHASE DB1 Dataset表10 CHASE DB1 数据集对比结果 最后,本文还采用ROC 曲线和PR 曲线进行模型的评价. ROC 曲线是对假阳性率和真阳性率的安全考虑,横坐标表示假阳性率,纵坐标表示真阳性率;PR 曲线是对召回率和精确率的综合考虑,其横坐标表示召回率Recall(和灵敏度Sen一样),纵坐标表示精确率Pre.曲线与坐标系围成的面积表示AUC面积,AUC值越大,表明模型具有更好的性能. 4 个网络模型在不同数据集上的ROC 曲线和PR 曲线对比实验结果分别如图8 和图9所示. Fig.8 Comparison of ROC curves of different models on different datasets图8 不同模型在不同数据集上的ROC 曲线对比 Fig.9 Comparison of PR curves of different models on different datasets图9 不同模型在不同数据集上的PR 曲线对比 从图8 中可以看出,本文所提模型RCAR-UNet 在3 个数据集上的ROC 曲线的AUC值为0.975 9,0.980 1,0.969 5,相对于经典U-Net 模型,提高了0.73%,0.93%,2.05%. ROC 曲线的纵坐标为真阳性率,表示实际正样本中被预测成正样本的占比,也就是实际正样本的预测正确率,所以是越大越好;而其横坐标为假阳性率,表示实际负样本中被预测成正样本的占比,也就是实际正样本的预测错误率,所以是越小越好. 最为理想的点是(0,1),综上所述,ROC 曲线的AUC值越大,性能越好,所以RCAR-UNet 在3 个眼底视网膜血管数据集上具有较好的性能. PR 曲线描述的是精准率与召回率的关系,在分割过程中,期望精确率和召回率值均相对较高,达到较好的平衡点,同样利用曲线与坐标系围成的AUC面积对模型进行评估,图9结果表明RCAR-UNet 具有较好的性能. RCAR-UNet在3 个数据集上的AUC值为0.900 3,0.898 0,0.825 0,相对于其他模型都有所提高. 综上所述,RCAR-UNet 相对于经典U-Net,Attention U-Net 等模型能够得到更好的眼底视网膜血管分割精度,分析其主要原因在于:RCAR-UNet 在编码-解码的U-Net 模型主干上,利用粗糙集中上下近似理论构建粗糙上下近似神经元,对眼底视网膜血管特征通道重要性进行区分,对视网膜血管特征进行准确重标定,并融合残差连接,进行特征的映射. 为了进一步直观地说明RCAR-UNet 对于视网膜血管分割具有较好的分割效果,将之与U-Net,Attention U-Net 等模型的分割图进行比较,各模型分割效果图如图10 所示. 从视网膜血管分割效果图可以直观看出,本文所提RCAR-UNet 模型的分割结果和专家分割标准图基本一致,特别是在矩形框区域内细微血管的分割上有更好的效果. 针对视网膜血管结构复杂、血管较细、易受光照影响等,本文考虑了特征通道之间的关系,引入一种新的通道注意力机制来增加网络的鉴别能力. 具体而言:首先在编码-解码结构的U-Net 模型上利用粗糙集的上下近似概念构建粗糙注意力模块,对注意力系数设置上下限,利用全局最大池化构造上神经元作为注意力系数的上限,利用全局平均池化构造下神经元作为注意力系数的下限,通过赋予上下限一定的权重系数并求和得到较具语义的注意力系数,该注意力系数不仅包含全局信息也具有了一定的局部信息;然后引入残差连接,实现将低层特征直接传播到高层,在一定程度上解决了网络退化的问题,以此提高模型性能;最后在3 个眼底视网膜血管数据集进行网络模型性能验证,实验结果表明本文所提网络RCAR-UNet 模型能够分割出视网膜血管末端的细小分支,得到较好的视网膜血管分割精度. 我们会进一步研究将粗糙集理论融合到深度神经网络模型的卷积和池化层中,处理图像特征中不确定性、不精确性信息. Fig.10 Segmentation effect diagram of retinal blood vessels of each model图10 各模型视网膜血管分割效果图 作者贡献声明:孙颖提出了算法的核心思想,设计了实验方案,完成实验并撰写论文初稿;丁卫平提出了整个算法的框架并对整个算法思想进行完善,修改了论文;黄嘉爽、鞠恒荣完善了算法的思路,指导了论文写作并修改论文;李铭、耿宇协助实验数据的处理并修改论文.3 实 验
3.1 数据集和预处理

3.2 实验参数设置
3.3 评价指标

3.4 实验结果分析

4 总结
 猜你喜欢
科学技术与工程(2023年3期)2023-03-15数学物理学报(2022年4期)2022-08-22数学物理学报(2022年2期)2022-04-26小雪花·成长指南(2022年1期)2022-04-09软件导刊(2022年3期)2022-03-25新一代信息技术(2021年22期)2021-12-29计算机技术与发展(2019年1期)2019-01-21金桥(2018年4期)2018-09-26传媒评论(2017年3期)2017-06-13第二课堂(课外活动版)(2016年2期)2016-10-21
猜你喜欢
科学技术与工程(2023年3期)2023-03-15数学物理学报(2022年4期)2022-08-22数学物理学报(2022年2期)2022-04-26小雪花·成长指南(2022年1期)2022-04-09软件导刊(2022年3期)2022-03-25新一代信息技术(2021年22期)2021-12-29计算机技术与发展(2019年1期)2019-01-21金桥(2018年4期)2018-09-26传媒评论(2017年3期)2017-06-13第二课堂(课外活动版)(2016年2期)2016-10-21
