
计算机视觉中的Transformer发展综述
2023-04-19 05:12李清格杨小冈卢瑞涛王思宇谢学立
小型微型计算机系统 2023年4期
李清格,杨小冈,卢瑞涛,王思宇,谢学立,张 涛
(火箭军工程大学 导弹工程学院,西安 710025) E-mail:doctoryxg@163.com
1 引 言
2017年,Google研究团队基于自注意力机制提出了Transformer[1]架构,随即在自然语言处理(Natural Language Processing,NLP)领域的序列建模和机器翻译等任务上显示出了巨大优势,目前已经成为NLP领域主流的深度学习模型.
Transformer在NLP领域的飞速发展引起了计算机视觉(Computer Version,CV)领域的广泛关注.计算机视觉任务通常面对的是图像或视频数据,卷积神经网络(Convolutional Neural Networks,CNN)具有平移不变性和局部敏感性等归纳偏置,可以很好地捕捉图像细粒度特征和局部信息,是计算机视觉领域的主流模型.但是CNN感受野有限,不具备获取全局信息的能力,且网络权重固定,无法动态适应输入的变化.且随着算力的提升,CNN模型对数据需求日趋饱和,需要更大体量的模型取代CNN.于是Transformer开始逐渐应用于CV领域.
目前,Transformer已经成功应用于计算机视觉任务和多模态任务当中,发展历程和典型模型如图1所示.2018年Image Transformer[2]首次将Transformer应用于计算机视觉领域,2020年目标检测模型DETR[3]和图像分类模型ViT[4]的提出是视觉Transformer迅猛发展的开端,此后,视觉Transformer开始席卷整个计算机视觉领域.但由于Transformer模型参数量大,计算成本高,于是许多学者开始将CNN中成功的先验知识引入到Transformer中,包括局部性、层次化、多尺度、残差连接和归纳偏置等设计.其中最成功的当属微软亚洲研究院提出的Swin Transformer[5],在多个视觉任务上取得了最先进的结果,成为ICCV2021的最佳论文.自此视觉Transformer对CNN产生了降维打击,成为了目前最流行的深度学习算法.

图1 Transformer发展历程Fig.1 Transformer development process

表1 视觉Transformer典型模型Table 1 Typical models of visual Transformers
本文根据各类视觉任务对视觉Transformer进行了系统的分类,总结了Transformer在各类视觉任务上的典型算法,如表1所示.本文剩余部分组织如下:第2节介绍了视觉Transformer的结构和原理,并梳理了Transformer在视觉分类任务上改进方向,同时分析了Transformer的特点和局限性;第3节总结了Transformer在目标检测、图像分割等高层视觉任务上的应用和发展;第4节介绍了Transformer在底层视觉任务上的应用;第5节总结了Transformer在多模态任务上的应用;第6节对视觉Transformer的发展趋势进行了展望并总结了全文.
2 视觉Transformer原理、分析及进展
ViT模型利用经典Transformer编码器结构实现了图像分类任务,是视觉Transformer模型的开端,模型结构如图2所示.首先将输入图像转换为无重叠、固定大小的图像块,其次将每个图像块拉平为一维向量,再通过线性投影压缩维度.
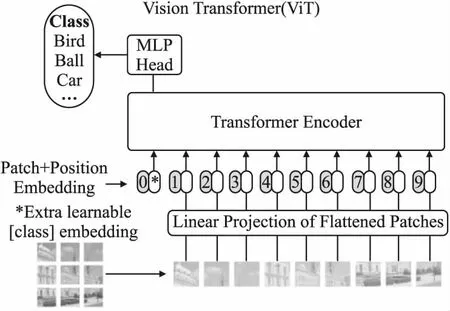
图2 ViT模型结构[4]Fig.2 Structure of ViT[4]
此外,图像序列前端引入可学习的分类标志位,以实现分类任务,再利用位置编码加入位置信息后输入到多个串行的标准Transformer编码器中进行注意力计算和特征提取.
2.1 ViT结构原理
2.1.1 编码器
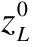
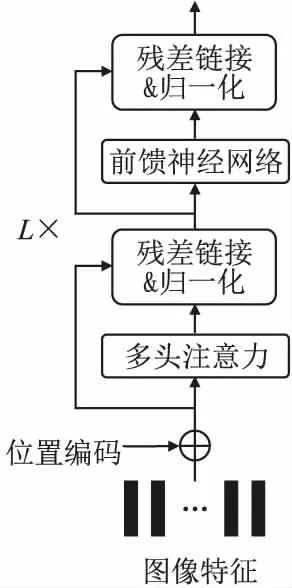
图3 Transformer编码器结构Fig.3 Structure of Transformer encoder
(1)
(2)
类别预测结果见公式(3):
(3)
2.1.2 自注意力机制
自注意力机制模仿了生物视觉的显著性检测和选择性注意,可以建立长距离依赖关系,解决了CNN感受野有限的问题.ViT中使用的是缩放点积注意力,如图4(左)所示.用X∈n×d表示包含n个元素的序列(x1,x2,…,xn),其中d表示每个元素的嵌入维数.自注意力机制定义了3个可学习的权重矩阵:查询矩阵(WQ∈n×dq)、键值矩阵(WK∈n×dk)以及值矩阵(WV∈n×dv).首先将输入序列X∈n×d投影到这3个权重矩阵上,得到查询向量Q、键值向量K以及值向量V,计算过程如公式(4)所示:

图4 自注意力与多头注意力Fig.4 Self-attention and multi-head self-attention
Q=XWQ,K=XWK,V=XWV
(4)
缩放点积注意力的计算过程如公式(5)所示:
(5)
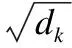
2.1.3 多头自注意力
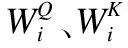
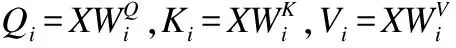
(6)
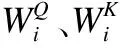
2.1.4 位置编码
由于自注意力计算过程中没有考虑到位置信息,而数据之间的关系又受位置信息的影响,因此将输入嵌入与一个额外的位置向量相加,得到的结果作为编码器的最终输入,这个过程就是位置编码.位置编码后的信息可以并行输入,计算效率大大提高.ViT模型采用的编码方式如公式(7)所示:
PE(pos,2i)=sin(pos/100002i/d)
PE(pos,2i+1)=cos(pos/100002i/d)
(7)
2.2 视觉Transformer特性分析
Transformer首先应用于NLP的机器翻译任务,是序列-序列的自回归模型.Transformer利用自注意力、交叉注意力和位置编码等方法,具备较强的全局信息交互能力,其在计算机视觉领域成功应用的原因有以下几个方面:
1)对图像的整体感知能力强.长期依赖问题令NLP和CV领域困扰已久,常用于图像特征提取的CNN感受野有限,更适用于局部信息的提取,因此只能通过设计更深的网络结构来提取图像的全局特征,导致模型复杂度增加,容易产生模型梯度消失,难以收敛等问题.Transformer由于其自身结构,可以获取上下文信息,具备获取并存储长距离依赖信息的能力,能够对图像实现整体感知和宏观理解.
2)模型可扩展性强.由于许多视觉任务缺乏大数据量的训练集,因此难以直接训练大体量的模型结构.Transformer可以在大规模数据集上进行自监督训练,无需人工标签的同时,在下游任务上进行微调即可迁移到所需任务上,大幅节省了训练所需的数据量.此外,现有Transformer模型的参数量最高可达数十亿,但是模型性能随着模型参数量的增加还在持续上升,Transformer模型的性能上限仍然是未知数.
3)对多模态数据的适应能力强.CNN擅长处理图像数据,递归神经网络(RNNs)擅长处理文本序列,而Transformer模型对于输入数据类型的适应更为灵活,只要能将输入数据抽象为序列嵌入,Transformer即可适用于任何类型的数据.
Transformer编码器-解码器结构使并行计算得以实现,提高了模型的训练效率.利用自注意力机制,能够捕获数据之间的长距离信息和依赖关系,在数据量越大的情况下Transformer的优势更加明显.但是视觉Transformer也存在如下问题:
1)ViT的训练成本高,训练数据需求量大.ViT与CNN相比计算复杂度高,导致计算量过于庞大,且ViT的归纳偏置能力比较弱,因此ViT只有在大规模数据集的预训练下才能获得较好的性能,当训练数据或硬件的计算能力有限时,ViT难以发挥其优势.
2)ViT将输入图像切分为图像块,一是破坏了图像的空间结构,忽略了图像的局部信息,特别是图像块的边缘信息.二是ViT无法直接适用于不同尺寸的图像输入,因为ViT切分的图像块大小是固定的,当图像尺寸发生变化时,输入序列长度就会改变,位置编码无法直接适用.
2.3 视觉Transformer研究新进展
本节针对视觉Transformer模型存在的问题,以图像分类这一基本视觉任务为基础,从引入局部性、层次化、与CNN融合和深度Transformer 4个研究方向出发,介绍了目前视觉Transformer模型研究的方向和新进展.
2.3.1 引入局部性计算
针对ViT将输入图像简单切分为图像块导致图像局部信息受损,且自注意力机制计算复杂度高的问题,部分学者引入局部注意力,首先提取图像的局部特征,再进行局部与全局特征交互.
1)基于局部窗口的特征提取
Swin Transformer[5]引入局部注意力思想,在无重合的窗口区域内进行局部自注意力计算,大幅度降低了计算复杂度,再利用移位窗口多头注意力(SW-MSA)实现了不重合窗口之间的信息交互.Swin Transformer作为通用的视觉主干网络,在图像分类ImageNet-1K数据集上达到了86.4%的Top-1准确率,在COCO数据集上的目标检测和实例分割,以及ADE20K数据集上的语义分割等视觉任务上的效果均位列榜首.CSWin Transformer[30]模型将Swin Transformer中W-MSA和SW-MSA模块用十字形局部窗口的替代,实现了跨窗口的局部注意力计算,不增加计算量的同时大幅提升了精度.
2)基于局部注意力
TNT[6]基于Transformer嵌套结构,外部Transformer模块用于获取图像块之间的关系,而内部Transformer模块则从各个图像块中提取局部特征,通过局部特征和全局特征的交互取得了很好结果.Twins[31]模型采用空间可分离自注意力计算方法,先对特征空间维度进行分组,再从全局对各组注意力计算的结果进行融合.VOLO[32]模型中引入了outlook注意力用来提取局部图像块的细粒度特征和语义信息,而自注意力机制仅关注粗粒度的全局依赖关系.与之思路相似的是Focal Transformer[33],在细粒度特征图上建立短期依赖,在粗粒度特征图上建立长期依赖.
2.3.2 基于层次化结构
为了解决纯Transformer计算量大,难以应用于密集预测任务的问题,有学者将层次化结构引入Transformer中,取得了很好的效果.
1)引入特征金字塔
PVT[7]将金字塔结构引入到Transformer中,是第一个纯Transformer用于像素级密集预测任务的主干网络.PVT模型分为4个阶段,每个阶段结构相似,后一阶段采用前一阶段的输出作为输入,可以生成不同尺度的特征图,降低了高分辨率特征图的学习成本.Pyramid TNT[34]将金字塔结构与TNT结合,Pyramid TNT-S只有3.3G FLOPs计算量的情况下在ImageNet数据集上获得了82.0%的分类准确率,明显优于TNT-S[6].与PVT设计思路相似的有PiT[35]和HVT[36]模型,都是在每一层特征图上对全局进行关系建模,再通过层级池化逐步缩小特征图尺寸,不断提纯特征.
2)层次化特征序列
T2T-ViT[8]在ViT的基础上提出了一种渐进式Tokens-to-Token(T2T)机制,用于同时建模图像的局部结构信息与全局相关性.T2T模块首先将上一层Transformer的输入特征序列恢复为图像,然后模拟CNN操作进行有重叠采样,将相邻的tokens聚合成一个新的token,得到新的序列,新序列的token数量减小且深度增加,然后输入至下一个T2T模块.与ViT相比,T2T-ViT改进了图像块嵌入模块,通过T2T机制先将图像结构化为特征序列,再逐步缩短序列长度,最终将层次化特征序列输入至Transformer中进行计算.
2.3.3 与CNN融合的视觉Transformer
许多学者对于如何将Transformer的全局信息建模能力和CNN的归纳偏置能力进行融合展开了研究.
1)训练方式
在训练方式上,有学者利用已经训练成熟的CNN模型来指导Transformer训练,该类方法典型模型如DeiT[9].为了缓解ViT对大型数据集的依赖性,DeiT模型在预训练过程中应用了师生策略,使用CNN作为教师模型,对知识进行提炼得到软标签,再将得到的软归纳偏置传递给Transformer学生模型.基于这种蒸馏方法,DeiT-B在没有额外训练数据的情况下最高达到了85.2%的Top-1精度.
2)位置编码
一些学者利用CNN对Transformer中的位置编码模块进行改进.CvT[10]利用卷积获得局部上下文信息,通过多层堆叠获得全局的相对位置关系,因此可以取代ViT中的位置编码模块.CvT模型输入图像通过卷积得到特征序列,通过控制步长获得不同长度的序列,同时利用深度卷积将特征转化成Q、K、V向量,减少了计算量.CPVT[37]模型在PVT[7]模型的基础上提出了条件位置编码方法,可以通过一系列卷积高效获取绝对位置信息.CoaT[38]模型设计了卷积注意力模块,采用类卷积的计算方式进行相对位置编码.
3)CNN与自注意力机制融合的特征学习
此外,部分学者将Transformer中的部分模块与CNN模型相结合,同样取得了很好的结果.ConViT[39]提出一种具有CNN软归纳偏置的门控位置自注意力机制,模仿了卷积操作的局部性,通过调整学习到的门控参数来调整位置对内容信息的关注度,从而给予每个注意力头自由来规避局部性,在ImageNet上超出DeiT 0.6%~3.2%的Top-1精度.VOLO[32]、CoAtNet[40]等模型将深度卷积和注意力机制相结合,使模型具有更强的学习能力和泛化能力.BoTNet[41]是利用多头自注意力机制替换了ResNet[42]最后一个bottleneck中的3×3卷积,在ImageNet数据集上取得了84.7%的最高准确率.
2.3.4 深度视觉Transformer
根据深度学习模型的设计经验,模型深度增加能学习到更复杂的特征,从而提高模型性能.然而对于深度Transformer模型,随着网络层数的加深,注意力机制会发生坍塌,导致Transformer随着层数的加深模型性能不升反降.为了解决这个问题,CaiT[11]和DeepViT[43]都在ViT模型的基础上进行研究.CaiT设计了在网络加深情况下也能收敛的LayerScale结构,解决了残差连接过程中方差放大的问题.其次为了解决分类标志位在注意力计算和分类的过程中参数优化矛盾的问题,在自注意力计算阶段,分类标志位不参与运算,当提取的特征图不随网络加深而改变时,再加入分类标志位进行分类注意力计算,提高了深度ViT的收敛速度和精度.而DeepViT通过设计重注意力代替标准自注意力机制,重新生成注意力图,增加了深层特征的多样性,从而使具有32个Transformer模块的深度ViT模型提高了1.6%的分类精度.
2.4 典型模型性能对比
目前,视觉Transformer算法的研究和改进大多基于ViT模型,发展方向大致可以分为4类:部分方法是通过引入局部性计算降低模型的计算复杂度,有的方法是基于层次化结构提取不同尺度的特征,还有方法通过结合CNN和Transformer的优势提高模型性能,同时更深度的视觉Transformer算法也在不断发展.表2对比了视觉Transformer典型算法在ImageNet数据集上的分类性能.根据典型视觉Transformer方法在ImageNet上的实验结果,图 5(a)对比了模型性能与参数量的关系,图 5(b)对比了模型性能与计算量的关系.
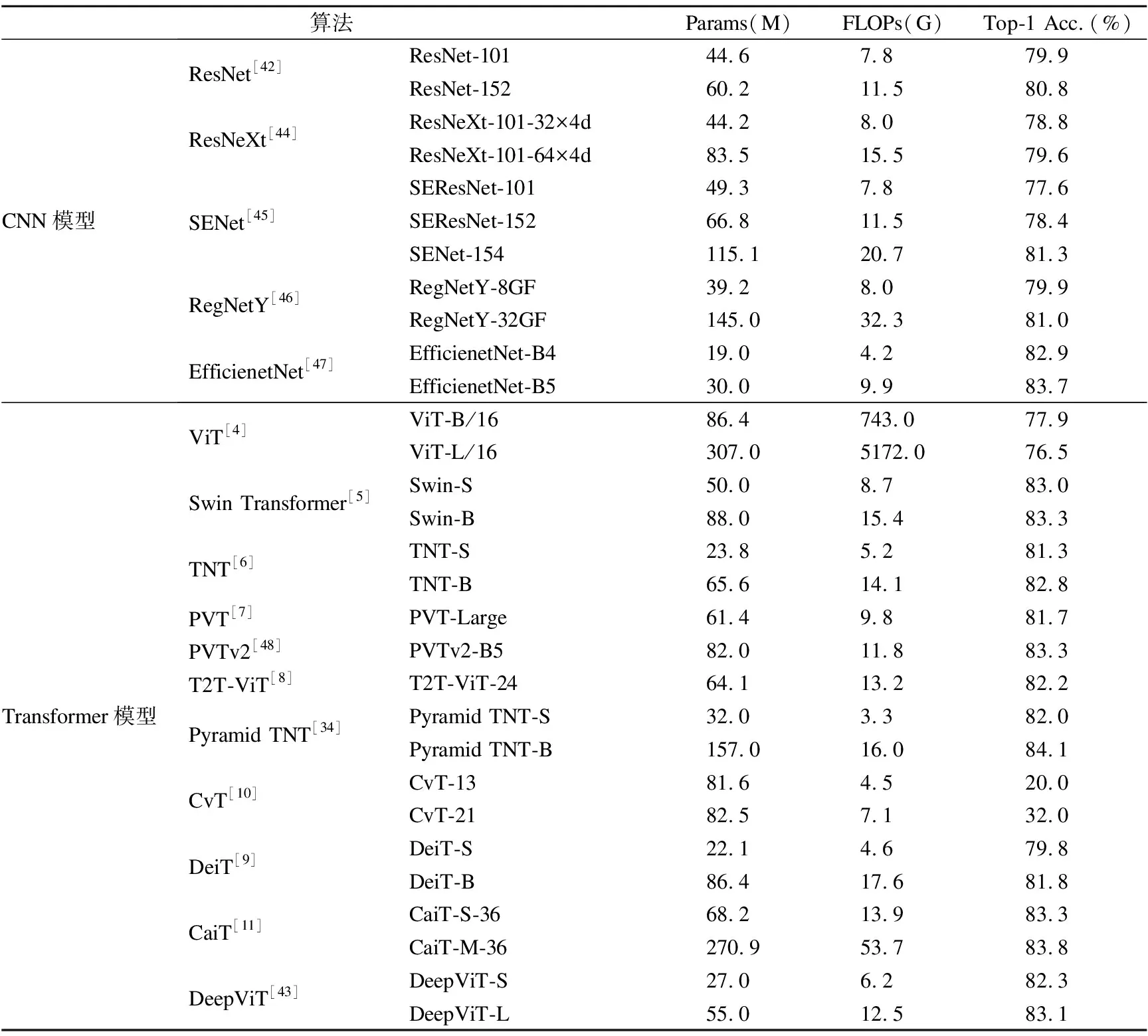
表2 视觉Transformer模型性能对比Table 2 Performance comparison of visual Transformers
从目前的研究趋势看来,未来基于Transformer的图像分类方法的研究将会集中在如何更好的引入局部性和层次化结构,从而达到和Transformer的全局性形成互补以提高模型的性能.同时,构建自监督学习的Transformer模型也是未来一个热门的研究方向.此外,由于Transformer和CNN各有优劣不可互相代替,因此如何结合二者的优势构建性能更佳的分类算法也是未来的研究热点之一.
3 Transformer在高层视觉任务上的应用
3.1 目标检测
目标检测的目的是找到特定目标在图像中的精确定位,并给出每个目标的具体类别.目前基于深度学习的目标检测方法主要分为两阶段和单阶段目标检测算法,两阶段目标检测算法以Faster R-CNN系列[49-53]为代表,单阶段目标检测算法以YOLO系列[54-58]为代表.基于Transformer的目标检测方法大多是在DETR[3]算法的基础进行改进,也有一些是将通用的Transformer主干网络[5,7,33,48,59]应用到目标检测任务中,同样取得了很好的结果.不同的目标检测算法在COCO数据集上的性能对比如表3所示.
3.1.1 基于目标查询机制的检测算法
DETR[3]是第1个基于Transformer的端到端的目标检测算法,整体结构如图6所示.DETR无需锚点(anchor)和非极大值抑制(NMS),而是将目标检测视为一种集合预测问题,利用目标查询机制实现特征交互,通过编码器-解码器的序列预测架构,并行输出每个目标查询中的预测结果,为端到端的目标检测提供了一种新思路.
DETR中的目标查询向量个数固定,代表了潜在目标特征和位置信息,其与图像特征交互的过程中不断进行更新.这种检测方式存在收敛速度慢、目标查询冗余以及小目标检测结果差的问题,在COCO数据集上比Faster R-CNN[50]慢了10~20倍,需要500个epoch才能收敛,小目标检测平均准确率仅有20.5%.
针对DETR中目标查询冗余的问题,ACT[62]采用局部敏感哈希[65]自适应地将查询特征进行聚类,从而压缩目标查询的个数.Sparse R-CNN[53]借鉴了DETR的目标查询机制,但查询向量依然是固定长度的可学习向量.在此基础上,Dynamic Sparse R-CNN[66]设计了动态目标查询机制,在训练阶段利用动态卷积生成动态样本相关的建议框和建议特征.动态可学习的目标查询机制更为灵活,对于小目标检测效果更佳.
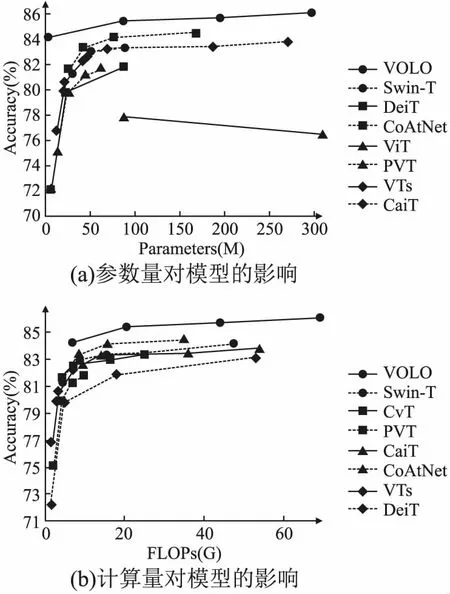
图5 视觉Transformer模型性能与影响因素Fig.5 Performance and influencing factors of visual Transformers
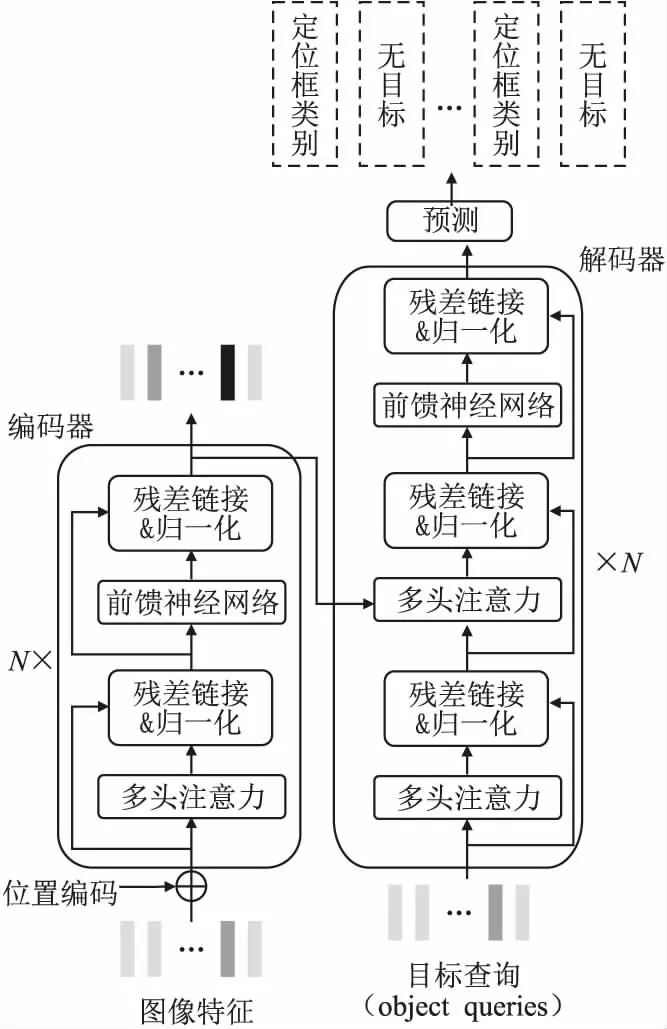
图6 DETR模型结构Fig.6 Structure of DETR
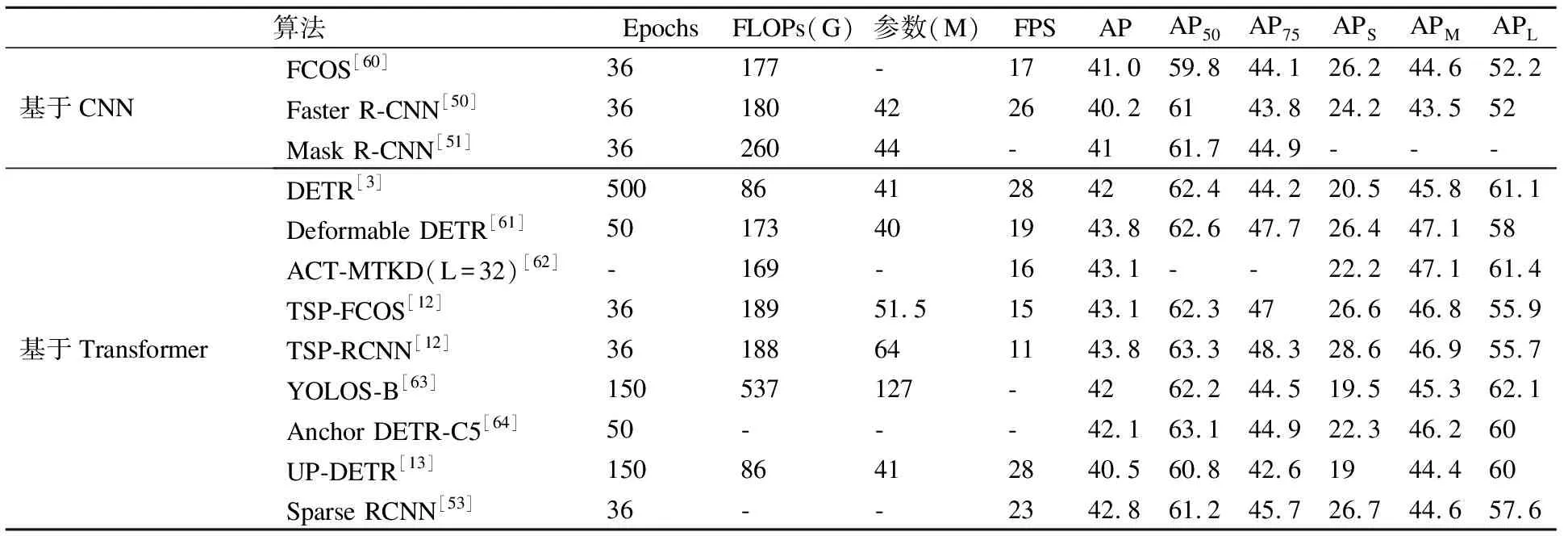
表3 目标检测算法性能对比Table 3 Performance comparison of object detection algorithms
3.1.2 提高DETR收敛速度的改进算法
为了解决以DETR为代表的目标检测模型收敛速度缓慢、计算复杂度高的问题,本节从自注意力机制的改进、目标查询初始化、编码器特征交互以及无监督训练4个方面总结提升DETR收敛速度的方法.
1)自注意力机制的改进
通过在DETR的注意力机制中引入稀疏性从而提高模型收敛速度.Deformable DETR[61]模型利用可形变卷积[67]中稀疏空间采样的优势,采用多尺度可形变注意力替换DETR中的标准注意力模块,降低了计算复杂度的同时将计算速度提高了1.6倍,在小目标检测上的精度提升了5.9%APs.
2)目标查询初始化
DETR中的目标查询采用随机初始化的方法,需要较长的时间才能完成对目标特征和位置的学习,影响了DETR的收敛速度.为了解决上述问题,TSP[12]模型利用CNN对目标查询进行初始化,通过生成一组固定大小的兴趣特征或候选框,然后将其输入至编码器进行密集预测,加快了模型的收敛速度.
3)基于编码器的特征交互
研究表明,DETR解码器中的交叉注意力机制存在固有的计算瓶颈,导致DETR收敛速度慢[12].因此仅采用编码器结构,可以提高模型的收敛速度.YOLOS[63]融合了ViT的模型架构和DETR的预测方式,用类似DETR中可学习的检测标志位代替了ViT中的分类标志位,利用编码器对图像信息进行目标估计.TSP同样是利用编码器对初始化的目标查询进行特征交互,得到最终结果.与DETR相比,TSP以更低的训练成本和更高的计算速度获得了更好的性能.
4)无监督训练
UP-DETR[13]是一种无监督预训练的目标检测算法.首先从给定的图像中随机裁剪图像块输入至解码器,经过预训练的解码器可以定位图像块在原始图像中的位置.为了解决多查询定位问题,将多个单查询块分配给不同的目标查询,其中每个查询块都通过注意力掩码和对象查询洗牌机制进行独立预测,从而模拟多目标检测任务,加速了DETR模型的收敛.
3.1.3 基于标签匹配策略的改进
DETR利用二分匹配将目标查询与对应的真值进行匹配,利用匈牙利算法(Hungarian Algorithm)快速实现,找到真实值与预测值的对应关系.与CNN模型中的真值匹配策略不同,二分匹配不依赖位置先验信息(如IoU、距离等),而是直接将预测结果与真实值进行匹配.定义真实值为yi,匹配策略为σ,预测值为yσ(i),则匹配损失如公式(8)所示:
(8)
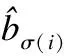
(9)
由于二分匹配初始化是随机的,匈牙利算法计算损失值时具有不稳定性,导致DETR训练早期收敛速度慢.针对此问题,TSP采用匹配蒸馏法,并基于FCOS算法设计了新的二分匹配算法,将落在标注框内或与标注框有一定重叠的预测值与真实值进行匹配,显著提高了收敛速度.匈牙利算法是一对一匹配,即每个预测框与一个标注框匹配,结果可能不是最优的.而动态Sparse R-CNN[66]将最优传输理论应用于Sparse R-CNN,提出了多对一的动态标签分配(DLA)策略,更有效地优化匹配结果.
3.1.4 基于Transformer主干的特征提取
在特征提取方面,Transformer模型比CNN模型更擅长提取全局上下文信息,具有更大的感受野,因此可以为下游密集预测任务提供丰富的特征输入.目前的许多视觉Transformer模型如Swin Transformer[5]、PVT[7]、PVTv2[48]、ViL[59]、Focal Transformer[33]等作为主干网络,替代基于CNN的主干网络进行特征提取,结合典型目标检测网络,同样可以很好地完成目标检测任务.此外,FPT[14]借鉴FPN[68]的思想,结合非局部特征和多尺度特征,可以作为密集预测任务的通用主干.相比基于CNN的特征提取网络,Transformer可以作为一种新的特征提取网络应用于目标检测模型中,从而取得更好的目标检测结果.
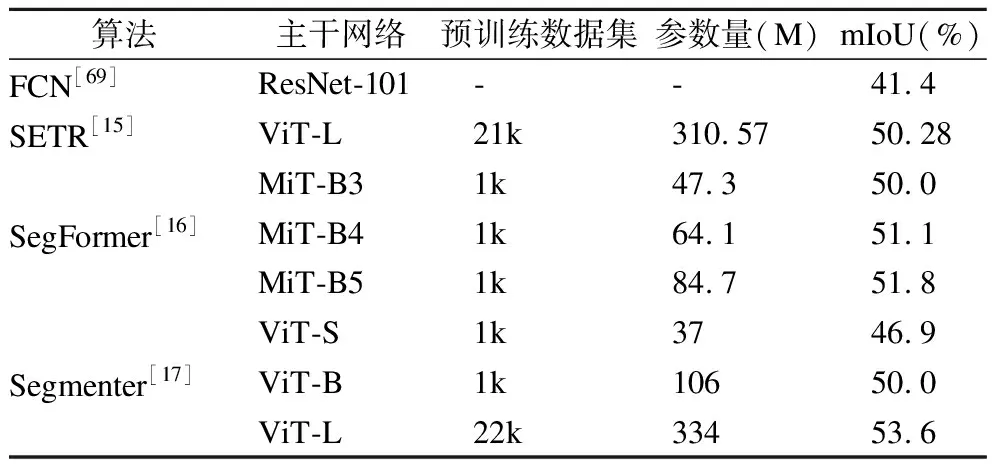
表4 分割算法性能对比Table 4 Comparison of segmentation algorithms
3.2 图像分割
图像分割包括语义分割和实例分割,语义分割需要区分图像中各类目标的每一个像素点,实例分割在此基础上还要区分同类物体的不同个体,是目标检测和语义分割的结合.目前基于深度学习的图像分割方法以FCN[69]、Mask RCNN[71]等基于CNN的模型为主,为了在不损失图像分辨率的情况下利用更大的感受野学习更多的语义信息,在远程上下文信息建模上具有显著优势的Transformer逐渐应用于分割任务.典型分割算法在ADE20K数据集上的性能对比见表4.
3.2.1 基于Transformer特征提取的分割算法
Transformer模型可以替换现有分割算法中的CNN主干网络,进行全局信息建模和特征提取.此外,还有算法设计了新的Transformer分割框架,利用全局感受野优势实现特征提取.SETR[15]借鉴ViT的设计思路,利用Transformer编码器提取全局语义信息,结构如图7所示.SETR将语义分割视为序列到序列的预测任务,设计了3种不同复杂度的解码器获取分割结果:朴素上采样、渐进上采样和多级特征聚合,结果虽然优于传统FCN方法,但具有十分庞大的计算量和参数量.为此,SegFormer[16]设计了一种具有层级结构的编码器,可以输出多尺度特征,采用轻量级MLP聚合各层特征,并通过引入卷积避免了位置编码,从而解决了输入图像尺寸变化对模型性能的影响,在ADE20K数据集上取得了51.8%的SOTA结果.
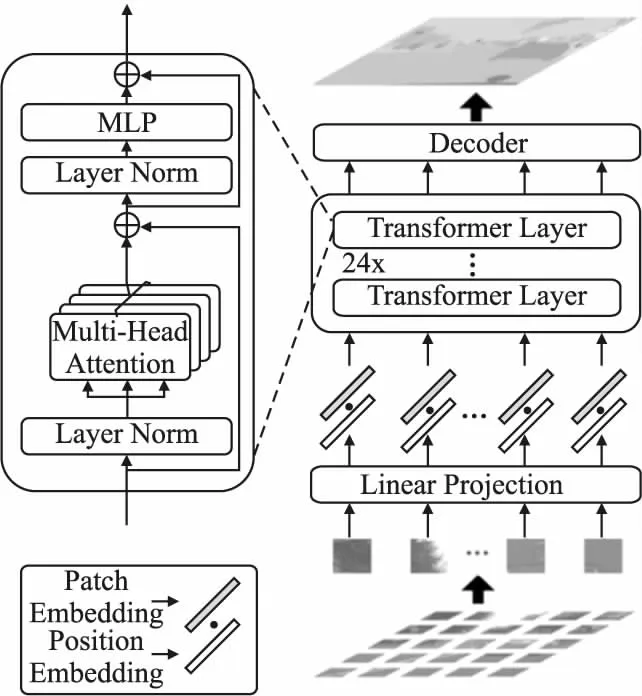
图7 SETR模型结构[15]Fig.7 SETR model structure[15]
3.2.2 基于目标查询的语义分割
Transformer的查询机制是类别信息、位置信息以及图像特征信息的通用表示形式,因此可以为语义分割提供基础.在语义分割任务中,查询机制的初始化是随机的,后续利用注意力机制进行特征的交互捕获重要信息,为每一个像素输出一个类别信息,从而实现语义分割.Segmenter[17]将语义分割任务视为一个序列到序列的问题,是一个无卷积的纯Transformer模型.Segmenter利用类别嵌入建立目标查询,编码器与ViT结构相同,结合逐点线性解码器或掩码Transformer解码器,利用交叉注意力与图像块进行信息交互,最终通过图像块和类别嵌入之间的注意力图生成逐像素预测的类别标签,最后利用softmax等操作获得分割结果.Segmenter在主流语义分割数据集(ADE20K、Pascal Context和Cityscapes)上的性能超越了基于CNN的SOTA模型.
3.2.3 基于目标检测的实例分割
基于Transformer的实例分割可以在目标检测网络的基础上实现,例如在DETR目标检测的结果上生成检测框嵌入,利用图像特征与检测框嵌入之间的信息交互提取目标特征,再基于查询与图像特征的注意力图进行目标和背景掩码的预测.此外,基于Sparse R-CNN,ISTR[70]提出了一种检测分割并行的实例分割Transformer.ISTR的目标查询采用随机初始化的方法,后续通过迭代计算不断更新目标查询以及特征提取,特征信息用于学习动态卷积参数以实现动态处理区域特征的目标,从而并行产生检测框和掩码预测.
3.3 目标跟踪
目标跟踪是根据已知视频序列某一帧中目标大小和位置,预测后续帧中该目标的大小和位置的过程,广泛应用在无人机、无人车、机器人等领域.目标跟踪可以分为单目标跟踪、多目标跟踪、目标重识别等子任务.Transformer在单目标跟踪任务和目标重识别任务中主要用于提取深度特征,在多目标跟踪任务中,主要借鉴了DETR的目标查询机制,以目标检测为基础进行跟踪算法设计.
3.3.1 基于Transformer深度特征提取的单目标跟踪
Transformer在单目标跟踪模型中主要用于对CNN主干网络提取的特征进行增强和融合,后续再进行分类和回归预测,典型算法有TrSiam[71]和TransT[19].TrSiam将Transformer与孪生网络跟踪器和判别相关滤波器结合,是首个基于Transformer的单目标跟踪模型.主干网络提取的特征利用编码器进行加强,再解码器处理搜索特征.解码器中的自注意力与编码器中的自注意力权值共享,从而使模板特征和搜索特征映射到同一特征空间中.TrSiam以端到端的方式训练,跟踪速度达到35 FPS.TransT利用Transformer特征融合网络对主干网络提取的两个分支特征进行融合,有效融合了目标和搜索区域的全局信息,精度显著提升的同时将运行速度提高到了50 FPS.
3.3.2 基于目标查询机制的多目标跟踪算法
多目标跟踪由多步检测跟踪算法控制,包括目标检测、特征提取和时间关联等步骤,基于Tranformer的典型算法有TransTrack[72]和TrackFormer[18],二者都是基于DETR目标检测算法的查询机制,可实现在线联合检测跟踪,简化了传统方法的复杂组件和跟踪步骤.TransTrack首先检测出当前帧中的目标,利用可学习查询机制从其他帧中进行特征查询,得到与当前目标相关联的新目标,在MOT17数据集上得到了65.8%的跟踪准确率.TrackFormer是一个端到端的多目标跟踪模型,通过设计的自回归跟踪查询机制,利用DETR目标检测器得到上一帧中跟踪的轨迹特征变换结果,以自回归的方式跟踪视频序列中的目标.
3.3.3 利用Transformer特征学习的目标重识别方法
目标重识别(ReID)的目的是判断图像或视频序列中是否存在特定目标,目前广泛应用于智能视频监控、智能安保等领域.TransReID[20]是典型的基于Transformer设计的目标重识别模型.TransReID基于ViT主干网络,在网络最后一层设计了与全局分支并行的Jigsaw分支,并提出了一种JPM模块,通过对图像块的打乱重组,使模型适应扰动的同时能够获得图像的全局信息,因此取得了更好的训练结果.在MSMT17行人重识别数据集和VeRi-776车辆重识别数据集上,分别达到了69.4%和81.7%的mAP.
4 Transformer在底层视觉任务上的应用
底层视觉任务指的是像素级图像处理任务.目前,底层视觉任务上的Transformer模型大致可分为纯Transformer架构和Transformer与CNN结合的模型,前者对于高分辨率图像计算量巨大,因此构建模型时必须考虑如何降低模型的计算复杂度,一般通过采用窗口计算或通道自注意力机制将时间复杂度降低为线性复杂度.后者一般首先利用CNN的归纳偏置特性提取图像浅层特征和局部上下文信息,使模型更适用于底层视觉任务且便于训练.如何将Transformer与CNN进行更好的聚合,以及如何在降低自注意力机制计算复杂度的同时更好地获得远距离依赖关系是目前Transformer在底层视觉任务上的研究方向.
4.1 图像生成
图像生成是基于现有数据生成新图像的计算机视觉任务,基于Transformer的图像生成方法一开始以基于像素的生成方法为主,典型代表有Image-Transformer[2]、iGPT[21].二者将图像生成看作自回归序列生成问题,iGPT采用无监督的训练方式,可达到99.0%的准确率,缺点是计算成本高,无法处理高分辨率图像.目前,基于Transformer的图像生成方法大多是与GAN[73]网络的结合,以VQGAN[74]、TransGAN[75]为代表.TransGAN是基于内存友好的生成器和多尺度判别器的纯Transformer架构,生成器生成的图像切分为图像块后输入判别器,然后利用编码器区分真实图像和生成图像.VQGAN用感知丰富的图像成分组成表示图像,利用Transformer对图像成分的长距离关系建模,更适用于处理高分辨率图像.
4.2 超分辨率图像重建
超分辨率图像重建是从低分辨率图像中恢复出高分辨率图像的计算机视觉任务.为了解决Transformer在图像超分任务中计算成本高、内存占用大的问题,SwinIR[24]、ESRT[76]等模型将卷积和Transformer进行结合,有效降低了计算量.二者都是首先利用卷积提取浅层特征,再利用Transformer提取深度特征.SwinIR的深度特征提取模块是由多个残差Swin Transformer模块(RSTB)构成,每个RSTB利用多个堆叠的Swin Transformer对深层特征进行提取,然后通过卷积层增强特征,最后通过残差连接进行特征聚合.在Urban100数据集上,SwinIR比其他SOTA方案精度高了0.14~0.45dB,同时降低的参数量高达67%.ESRT通过设计高效多头注意力降低计算成本和GPU的内存占用.与原始Transformer占用16057M GPU内存相比,ESRT仅占用4191M GPU内存,在计算性能和成本之间达到了最好的平衡.
4.3 图像增强
图像增强的目的是增强图像中的有用信息,抑制不感兴趣的特征,从而改善图像质量.IPT[23]是典型的基于Transformer的图像增强模型,结构如图8所示.IPT采用多头结构和多尾结构来处理超分辨率、去噪、去雨等底层视觉任务,不同任务共享同一个Transformer模块.其中多头结构利用卷积层提取图像特征,特征图经分块展平后通过编码器和解码器进行处理,最后通过多尾结构将解码器输出的特征图转换为目标图像.IPT可同时对多个任务进行预训练,每个训练批次随机选择一个任务,训练与其对应的头部和尾部结构,再通过微调得到针对所需任务的特定模型.对于不同的高斯噪声水平,IPT在BSD68和Urban100数据集上的实验结果最具优越性.

图8 IPT模型结构[23]Fig.8 IPT model structure[23]
4.4 图像恢复
图像恢复是从低质量或失真的退化图像中恢复出理想图像的过程,Uformer[77]是Transformer在此类任务上的典型模型.Uformer用编码器和解码器替换了U-Net中的卷积层,编码器负责提取退化图像的特征,解码器负责重构图像,二者均设计为局部增强窗口的Transformer模块,利用基于窗口的非重叠自注意力机制来捕获长距离依赖关系,降低了模型计算复杂度.每个编码器的输出下采样后输入下一编码器,同时也送入对应的解码器.最后一个解码器的输出经过卷积得到残差图像,再结合输入图像最终得到恢复后的图像.在SIDD数据集上,Uformer以更小结构取得了比U-Net更高的精度,在DND数据集上,超过了之前最佳的算法NBNet[78].
4.5 图像质量评估
图像质量评估是对图像的质量水平进行分类,根据有无参考图像,分为全参考、部分参考和无参考3种.典型基于Transformer的图像质量评估算法有TRIQ[25]、IQT[79].二者都是先用CNN网络提取图像特征,然后输入Transformer进行特征聚合,最后利用多层感知机对图像质量进行预测.TRIQ首次将Transformer应用于无参考图像质量评估,基于ViT结构,CNN提取到的特征经过自适应位置嵌入后输入至编码器,可以处理任意分辨率的图像.IQT是一种全参考图像质量评估方法,首先基于孪生神经网络获取失真图像和参考图像间的差值特征图,经过映射后进行质量嵌入和位置嵌入然后输入至Transformer.IQT在2021年感知图像质量评估比赛中排名第一.
5 Transformer在多模态任务上的应用
多模态任务研究的是不同类型数据的融合问题,与计算机视觉相关的多模态任务有文本到图像生成、视频-文本检索、视觉-语音导航、视频字幕生成等.由于Transformer中的自注意力机制具有强大的序列特征提取能力,不同模态的信息都可转换为序列数据进行处理,因此开始应用于多模态任务.
5.1 文本到图像生成
CogView[26]将VQ-VAE框架与Transformer相结合,用于解决文本到图像生成问题.首先利用训练好的编码器将图像压缩到低维离散空间,再通过解码器从隐藏变量中恢复图像,最后采用自回归模型学习拟合隐藏变量的先验.这种离散压缩方法比直接下采样损失更少的保真度,同时保持了像素空间的相关性.CogView在3亿个高质量文本-图像对上进行预训练后再微调.通过提出的精度瓶颈松弛和“三明治”层归一化模块,解决了由于文本-图像数据异质性而导致预训练过程不稳定情况,提高了文本到图像生成的质量.
5.2 视频-文本检索
HiT[27]跨视频文本模态检索模型基于层次化对比学习,利用Transformer不同网络层的输出具有不同尺度的特性,设计了层次跨模态对比匹配模块,对Transformer底层网络和高层网络信息分别进行对比匹配,从而得到更好的视频文本检索性能.此外基于动量更新机制,设计了动量跨模态对比模块,使跨模态对比匹配的过程能充分利用负样本,从而得到更好的视频和文本表征,克服了端到端的方法受显存容量限制的缺点.HiT在多个视频-文本检索数据集上取得了更加高效且精准的结果.
5.3 视觉-语音导航
VLN-BERT[28]是视觉-语音导航(VLN)领域中的典型模型.该模型利用大量成对的视觉-语言数据进行预训练,然后根据特定任务利用少量数据进行微调,取得了不错的结果.但模型计算量大,结构还需要进一步优化.Chen等[80]提出了一种基于自然语言指令和拓扑图的跨模态注意力模型.在给定拓扑图和自然语言输入的情况下,首先使用单模态编码器对单个语言和地图编码进行处理,然后采用跨模态编码器聚合跨模态信息.此外,利用可学习的轨迹位置编码表示地图中的位置,利用注意力机制来生成可解释的导航计划,从而实现对环境的自由探索和智能导航.
5.4 视频字幕生成
SwinBERT[29]是一种基于Transformer的端到端的视频字幕生成模型,利用Swin Transformer提取视频帧序列的特征,然后输入至多模态Transformer编码器中,经过处理生成自然语言描述.在多模态编码器中,通过引入可学习的稀疏注意掩码约束解决了视频长序列计算量大的问题.与利用多个2D/3D特征提取器的字幕生成方法相比,SwinBERT可适应不同长度的视频输入,同时在性能上也有了很大的提升.
6 发展趋势及展望
虽然视觉Transformer取得了许多突破性的进展,成为了CV领域最热门的研究方向之一,但是仍然无法取代CNN在CV领域的主导地位.下面将根据视觉Transformer发展现状以及存在的问题和挑战,讨论其在未来研究方向.
1)多任务的统一框架.传统处理多模态任务的模型是首先提取不同类型数据的特征,然后经过特征拼接等操作后,再传入分类器进行训练,此时的分类器同时对两种不同形式的数据进行学习,模型基线庞大且复杂.简而言之,传统的多模态模型对不同数据类型采取了不同的处理方法,因此在特征拼接的时候难免会存在模式无法对齐的问题,不仅模型结构复杂,而且对两种类型数据的处理结果也欠佳.Transformer自注意力机制具有十分强大的特征提取能力,适合处理不同类型的数据,各种数据类型只要可以转化为一维长序列,就可以直接被Transformer处理,因此相比于CNN和RNN模型更具优势.实践证明,Transformer在各种类型数据的特征提取和模式对齐上极具潜力.对于不同领域的不同任务类型,Transformer是否可以成为一个通用框架,实现不同领域模型架构的大一统,在未来还有待进一步研究.
2)高维数据计算模型.现有的视觉Transformer模型由于参数量大、计算复杂度高,因此模型的训练过程对硬件要求高,即使芯片和处理器等硬件设备的性能在不断提升,仍然无法满足Transformer运算效率和效果的需求,导致训练时间长,运算效率不佳,存在计算成本高的问题.与NLP领域相比,CV领域中的Transformer存在两个主要问题:1)NLP领域中输入数据的长度是固定的,但在CV领域,由于同一场景中存在的物体大小不一,因此输入图像数据的尺度比例各异,变化范围大;2)与文本数据相比,图像数据中的像素需要更高的分辨率,又因为Transformer是一种基于全局自注意力的计算方式,它的计算复杂度与图像尺度呈平方增长关系,这就会导致计算量过于庞大.因此,CV任务中的Transformer对于高分辨率输入的适用性较差,限制了算法的发展及应用.在未来,如何降低Transformer模型的计算成本,提高模型的计算效率,设计适用于高维数据的计算模型,同样是研究的热点和难点问题.
3)自监督学习.自监督学习的监督信息来源于数据本身,是无监督学习的一个变种,可以在不依赖数据标注的情况下学习特征表示,是当前研究的热点问题之一.目前,基于自监督学习的Transformer模型在NLP领域已经取得了巨大的成功,如拥有1750亿参数的GPT-3模型,模型经过自监督训练后,在下游任务上的表现性能可以得到显著提高.但在CV领域,虽然目前有许多性能显著的视觉Transformer模型,但是它们的成功都依赖于十分庞大的数据需求,监督的训练方式需要进行大量的手工标注工作,增加了模型训练的难度,限制了模型性能的提升.目前,将自监督学习与视觉Transformer相结合的研究工作已经开展,但是仍然存在巨大的研究空间.因此,基于自监督学习的视觉Transformer将会是未来一个非常值得研究的方向.
4)小样本学习.小样本学习的目的是在数据有限的情况下训练出性能良好的模型,这是近几年新兴的一个研究方向.Transformer模型与CNN相比具有更多参数,因此其训练通常依赖于大量的训练样本.目前切实可行的方法是在大规模数据集上对视觉Transformer模型进行预训练,然后针对任务类型利用少量数据对模型进行微调.然而对于一些训练样本稀缺的视觉任务来说,很多时候获取海量的训练数据十分困难,而训练数据的数量和品质又限制了模型的训练和性能的提高,因此难以有效地训练出高性能模型.为了解决视觉Transformer模型的发展受训练数据数量限制的难题,小样本学习逐渐受到研究人员的关注.主流的小样本学习方法是通过数据增强、模型改进和算法优化3个方面来充分利用少量样本的先验知识,训练出学习能力强大的高性能模型,从而减少模型对数据数量的依赖.未来,如何降低视觉Transformer模型训练的数据成本,利用先验知识实现小样本学习依然具有很大的研究空间和发展潜力.
5)模型结构可解释性.Transformer模型性能强大,更深入地理解模型的特点和潜在的缺陷,可以更好的根据需求和实际应用任务对其进行改进.目前最常用的理解Transformer的方法主要是利用灰度图可视化出不同token之间的注意力权重,这种方法存在的问题是每张图只能表示一个注意力头,难以获得全局的直接感受情况.在自注意力机制的可解释性研究上,有些学者主要对不同的注意力头进行理解,有些则侧重于关注注意力权重对特征提取的影响,还有部分学者认为注意力机制的分布是无法解释的.为了能够更好地设计和改进Transformer模型结构,需要对其运行机理和内部信息交互进行深入研究和深刻理解,因此Transformer模型的可解释性十分具有研究意义.
视觉Transformer作为一种新兴的架构,已然席卷了整个计算机视觉领域.与CNN相比,虽然视觉Transformer显示出了其独特的优势,但是视觉Transformer架构本身依然存在许多局限性,具有巨大的改进空间和发展潜力,因此大多数学者认为视觉Transformer并不能完全取代CNN,二者在未来的研究中可能会更多的融合,优势互补以发挥最佳性能.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
成都信息工程大学学报(2018年3期)2018-08-29
数学小灵通·3-4年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
电子设计工程(2017年20期)2017-02-10
第二课堂(课外活动版)(2016年2期)2016-10-21
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
