
基于改进deeplabv3+的舌象分割算法
2023-04-13 11:39刘东华梁富娥吕珊珊
现代计算机 2023年3期
刘东华,张 伟,顾 旋,梁富娥,吕珊珊
(甘肃中医药大学信息工程学院,兰州 730000)
0 引言
舌诊作为中医特色诊断方法中望诊的重要组成部分,在中医智能诊断中扮演着重要的角色。舌头的大小、颜色、纹理等都能反映出人体对应的病症,因此舌诊在现代中医智能诊断和计算机辅助中医诊断中具有重要意义。当前计算机技术处理舌象图片都是先将舌体从图片中分割出来,然后再对舌象进行下一步的分类识别研究。舌体分割效果的好坏直接影响到后续研究的进程,舌体分割精度高可以大大提升后续研究的精度和简便性,能够减少许多不必要的麻烦。传统的图像处理方法如阈值法[1],通过设置一个像素值来将高于此像素值或低于此像素值的部分进行分割划分,利用单一的某个阈值来进行舌象分割的速度较快,但分割精度不高。边缘检测法[2],利用像素值在某一区域内发生剧烈的变化差值,来判断此区域为边缘区域,从而进行舌象分割,舌象图片复杂,色彩变换多,容易出现误判,分割精度低。主动轮廓算法[3],算法过度依赖轮廓线,稳定性低导致分割准确率不高。传统图像处理技术太过于依赖人工特征值的选择,利用的基本都是浅层的颜色和纹理的特征信息,这使得分割精度不高,分割出的图像效果不理想。
目前基于卷积神经网络的深度学习技术在图像处理领域大放异彩,卷积神经网络从R_CNN[4]发 展 到Faster R_CNN[5],从CNN 到FCN[6],在图像检测分类等领域得到了广泛的应用。本文提出了一种改进的deeplabv3+分割算法,采用注意力机制模块(convolutional block attention module, CBAM)和改进条带池化模块(strip pooling module, SPM)[7]及 混 合 池 化 模 块(mixed pooling module, MPM)来提取上下文信息,更好地进行舌象分割。
1 整体分割网络模型结构
本文采用编码器-解码器结构来对网络模型deeplabv3+进行语义分割,在编码器部分引入空间金字塔模块,对输入特征采用多采样率扩张卷积来获取多尺度上下文信息,然后通过编码器-解码器结构来恢复空间信息并获取目标边界,将其有效结合进行高效语义分割。过程如图1所示。
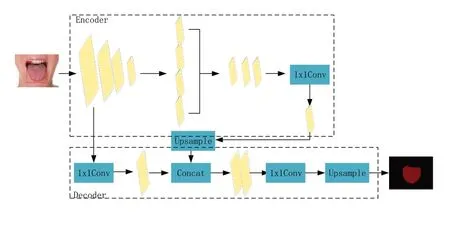
图1 分割网络流程
本文改进的deeplabv3+分割模型中采用了空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP),采用不同的上采样率进行多尺度特征提取。采用深度可分离卷积,降低参数数列,提高计算效率。同时加入了注意力机制来专注于舌体分割,抑制无关噪声干扰,提高分割精度。改进池化模块,加入条带池化和混合池化模块来提取上下文信息,更好地进行语义分割。
2 算法模型
2.1 深度可分离卷积
深度可分离卷积[8]实现起来与普通卷积一样,但其运行所需的参数量与普通卷积相比却大大减少,其一般应用于一些轻量级网络模型。深度可分离卷积主要由逐通道卷积和逐点卷积组成。逐通道卷积的每一个卷积核和通道都一一对应,这样特征图通道数就不会改变。逐点卷积的卷积核尺寸为1 × 1 ×M,M为上一层的通道数,所以卷积会在上一步特征图的深度方向上进行加权组合,从而输出新的特征图。
2.2 空洞空间金字塔池化
空洞空间金字塔池化对输入特征图以不同采样率的空洞卷积并行采样,然后将得到的结果堆叠到一起扩大通道数,最后通过1×1 的卷积将通道数降低到预期的数值,这样的操作相当于以多个比例捕捉图像的上下文,获取更多的上下文信息来进行后续的分割处理。空洞卷积[9]能够在扩大感受野的同时保证分辨率,其十分适用于检测、分割任务,感受野的增大可检测、分割大的目标,高分辨率则可精确定位目标。空洞卷积中参数dilation rate 设置不同,网络的感受野不同,从而能够获取多尺度信息。
2.3 注意力机制
2.3.1 通道注意力机制
通道注意力机制的工作原理,首先对输入进来的特征层分别进行全局平均池化和全局最大池化,获得初始通道注意力权重。初始权重仅代表各自通道特征信息,无法体现各通道特征的差异,所以将平均池化和最大池化的结果通过共享的全连接层进行处理,以便更好地进行分类。然后对处理后的两个结果进行相加,并取一个sigmoid,此时获得了输入特征层每一个通道的权值(介于0~1 之间),将权值乘上原输入特征层即可。
通道注意力机制表达式为
式中:Ic代表输入特征图I的第c个通道;Wc代表产生的第c个自适应权重;TC代表经过通道注意力机制后输出的特征图。
2.3.2 空间注意力机制
空间注意力机制详细原理:首先将通道本身进行降维处理,在输入进来的每一个特征点的通道上取最大值池化和平均值池化。然后将结果特征图进行堆叠拼接,调整通道数后取一个sigmoid,此时获得输入特征层每一个特征点的权值(介于0~1 之间),再将这个权值乘上原输入特征层即可。
空间注意力机制表达式为
式中:S(x,y)表示在空间位置(x,y)处的特征值,W(x,y)则是在(x,y)处的权重值,H(x,y)是经过空间注意力机制后的输出。
2.3.3 CBAM注意力机制
CBAM 注意力机制[10]如图2所示,可以看到CBAM 包含两个独立的子模块,通道注意力模块和空间注意力模块,分别进行通道与空间上的特征注意力处理。在CBAM 注意力机制中通道注意力模块和空间注意力模块进行串联处理,先进行通道注意力处理再进行空间注意力处理能使模型达到最佳注意力效果。这样不仅能够节约参数和计算力,并且能够使其方便地应用于其它网络模型。

图2 CBAM注意力机制
2.4 条带池化
条带池化,是将原本的池化核改进为水平垂直的条带状池化的方法,对池化核长条形区域所对应的特征图上位置的像素值求平均。实际应用中目标对象可能是长条状的信息,使用大方形窗口不能很好地处理,但条带池化就能有效地应对,更好地提取依赖特征。条带池化能够获取孤立区域的长距离关系,并且在其他空间维度上保持较窄的内核形状,有利于获得上下文信息。
2.4.1 条带池化模块
条带池化模块SPM 利用水平垂直方向上的池化核沿水平垂直空间两个维度捕获上下文信息。结构原理如图3所示,输入一个特征图(C×H×W),每一通道特征分别经过水平和垂直池化核后变成了H× 1 和1 ×W,对池化核内的元素值求平均,并以该值作为池化输出值。对两个输出特征图分别沿着左右和上下进行扩容,扩容后两个特征图尺寸相同,对扩容后的特征图对应相同位置求和得到H×W的特征图。最后通过1 × 1的卷积和sigmoid处理后与原输入图对应像素相乘得到输出结果。
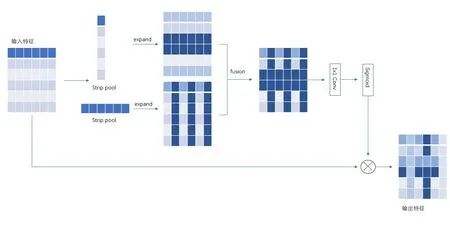
图3 SPM结构原理
2.4.2 混合池化模块
混合池化模块MPM 主要是通过利用不同内核形状的池化模型来探索复杂场景图像,从而收集有用的上下文信息。混合池化模块将金字塔池化模块和条带池化模型相结合,通过各类池化模块获取不同的上下文信息,使特征更有辨别力,可以连续使用它来扩展远程依赖关系。结构原理如图4所示,输入特征图分别进行金字塔池化和条带池化,金字塔池化生成多尺度特征,捕获局部上下文信息。条带池化模块能使孤立区域之间的连接和条纹状结构的编码区域成为可能,然后将输出结果进行有效融合。
将SPM 和MPM 两模块串联一起嵌入具有瓶颈的网络模型中,进行参数缩减和模块化设计,能够在一定程度上改善网络模型,提升模型效果。
3 实验研究与分析
3.1 数据集
数据主要来源于AI Studio 和Kaggle 云平台上的比赛数据集,数据有经过专业仪器采集得到的,也有智能手机拍摄的,来源不同,复杂度也不同,可以提高模型的泛化能力。总共选取舌象图片700 张,随机抽取70 张作为测试集,并将剩下的630 张按照10∶1 的比例随机划分为训练集和验证集进行训练。
3.2 实验环境
深度学习卷积神经网络模型对计算机硬件要求较高,租用云平台进行模型训练,GPU 型号NVIDIA RTX A2000 12GB 显 存,CPU 型 号Intel(R)Xeon(R)CPU E5-2680 v4 2.40GH,硬盘Samsung SSD 870,主板型号X10DRG-O+-CPU,模型框架平台TensorFlow,编程语言Python。
3.3 算法评价标准
对模型预测分割出来的结果图与舌象真实标签图进行比较分析,计算出各分割模型的好坏。评价指标主要有像素准确率PA,类别像素准确率CPA,类别平均像素准确率MPA,交并比IoU,平均交并比MIoU,频权交并比FWIoU。
其中:TP是把正标签预测为正的数量;FP是把负标签预测为正的数量;FN是把正标签预测为负的数量;TN是把负标签预测为负的数量。各评价指标值越接近于1则说明算法模型越好。
3.4 结果分析
将本文算法与传统分割算法,包括阈值算法、边缘检测算法、主动轮廓算法以及卷积神经网络模型算法SegNet 算法和PSPNet 算法进行比较分析。结果如表1和图5所示。
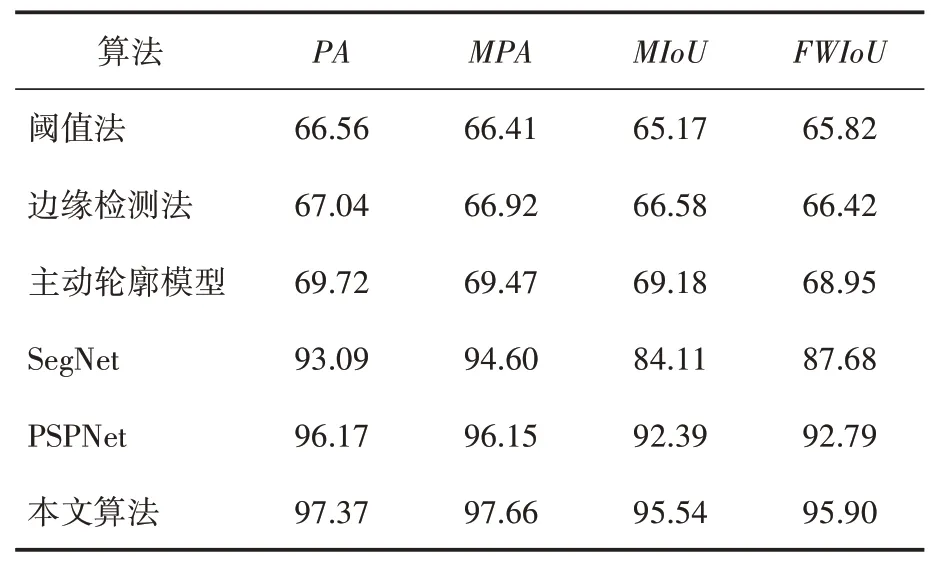
表1 算法各指标对比 单位:%

图5 算法结果对比
传统图像处理方法太过于依赖人工特征的选择,并且选择的分割特征都是浅层的颜色、形状和纹理等,当图像比较单调而且目标与环境有着较大的差异时,表现出的效果可能还不错。但当遇到像舌象这样比较复杂的图像时,仅仅依靠单一特征来进行分割是有点困难的,容易出现因错误划分导致分割结果精度不高的情况。基于卷积神经网络的SegNet 算法和PSPNet算法都是比较经典的语义分割算法模型,SegNet算法在编码和解码过程中使用same卷积,不会改变图片的原始大小,能使在池化时丢失的信息被重修获取。PSPNet 算法核心部件是金字塔池化模块,这和deeplabv3+算法有些相似,但deeplabv3+在金字塔池化的基础上进行了改进完善,使得效果得到进一步提升。
本文算法的类别平均像素准确率MPA和平均交并比MIoU值比SegNet算法和PSPNet算法的对应值都要高,并且MIoU达到了95.54%,可以很好地满足舌象分割需求。
为了验证本文改进算法的有效性,将其与未改进的算法进行比较分析,通过结果来验证改进思路和算法的正确性和有效性。表2所示为加入注意力机制与未加入注意力机制的对比结果。
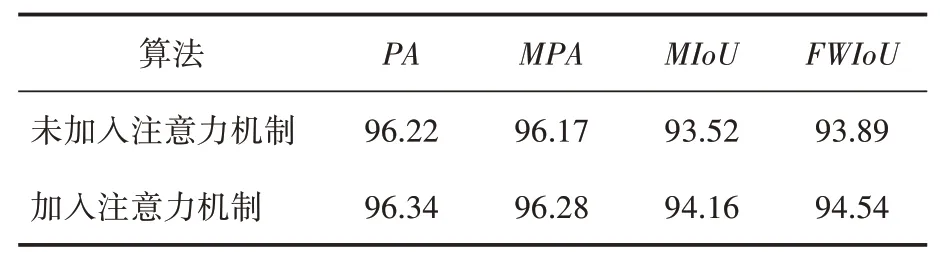
表2 注意力机制结果对比 单位:%
本研究在网络模型中加入CBAM 注意力机制,它结合了通道注意力机制和空间注意力机制,能够结合通道和空间的注意力特征信息,然后将其与原输入特征图进行融合并进行特征修正,产生最后的特征图。加入注意力机制能够使网络更加专注于分割目标对象,抑制无关噪声信号的干扰,更好地提升模型效果,模型的MPA和MIoU分别提升了0.11和0.64个百分点。
将条带池化模块SPM 和混合池化模块MPM串联加入网络模型中,与CBAM注意力机制进行对比,将注意力机制模型与改进池化模型有效结合,融入网络模型中进一步提升模型舌象分割效果。表3为改进池化模块的对比分析结果。
条带池化模块和混合池化模块通过转换池化核的方式来改进池化模型,更好地获取上下文信息,其本质也可以看作注意力机制。分别将CBAM 注意力机制和改进池化模型SPM、MPM 加入到deeplabv3+网络模型中,可以看出单独加入改进模块对模型的提升都比较小,没有达到预期的效果。当将CBAM 模块和改进池化模块SPM、MPM 一同融入deeplabv3+网络中时,效果比单独使用时有了不错的提升。改进分割网络模型相比于未改进网络模型的MPA和MIoU分别提升了1.49 和2.02 个百分点。本文改进方法的整体效果尚可,分割准确率也可以满足舌象分割的需求。
4 结语
本文采用deeplabv3+网络模型对舌象进行分割处理,采用CBAM 注意力机制模块和改进条带池化模块SPM 和MPM 来对网络模型进行改进提升。将各改进模块有效地融合加入分割网络模型当中,相比于未改进之前有了不错的提升,分割精度也能满足舌象分割的需求,从而验证本文改进算法对模型分割效果提升的有效性。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
世界科学技术-中医药现代化(2022年3期)2022-08-22
世界科学技术-中医药现代化(2022年2期)2022-05-25
软件导刊(2022年3期)2022-03-25
世界科学技术-中医药现代化(2021年9期)2021-12-31
新一代信息技术(2021年22期)2021-12-29
世界科学技术-中医药现代化(2020年2期)2020-07-25
计算机技术与发展(2019年1期)2019-01-21
系统工程与电子技术(2016年2期)2016-04-16
中国光学(2015年1期)2015-06-06
