
基于SIM-UNet++的眼底彩照视盘分割方法的研究
2023-04-13 11:39祝来李
现代计算机 2023年3期
祝来李
(西南民族大学电子信息学院,成都 610041)
0 引言
青光眼和病理性近视是常见的眼科疾病,其对视力造成的伤害是不可逆的。随着AI 医疗的不断发展,专家们对预防眼科疾病也有了更加科学的方法。例如,可以通过在眼底彩照中观察杯盘比大小是否存在扩大来诊断青光眼疾病,其中杯盘比是判断青光眼的重要指标。目前杯盘比通常是由眼科医生依靠多年的经验和观察眼底彩色照片获得。然而人工观测存在许多缺点,人工筛查不但耗时,而且对医生的专业程度要求很高,所以需要自动筛查方法。因此,视盘的定位和分割对于眼底疾病智能诊断是至关重要的。
本文基于UNet++模型提出了SimAM-UNet++,其是一种无参注意力机制的UNet++网络。本文的创新点如下:①在UNet++网络中融入无参注意力机制,在不增加参数量的基础上提升网络的性能。②采用直方图均衡化的方法对数据进行预处理,通过改变图片区域的颜色和插值结果来增强对比度,以此凸显视盘区域;采用数据增强的技术对数据进行了数据增量操作,降低模型训练过拟合的风险,提高分割性能。③采用DICE loss,可以减少过拟合。
1 相关工作
随着深度人工智能的发展,深度学习在医学领域的应用也越来越广泛,并且能够帮助人们解决一些实际的问题。在本节中,我们回顾了利用人工智能技术对眼底彩照视盘进行分割的研究结果。
Frage 等[1]介绍了一种多阶段的方法,基于传统算法完成对视盘的分割,首先检测出整体的亮斑区域,然后再通过霍夫变换细化亮斑区域,得到具体位置。Welfer 等[2]提出了一种基于血管结构模型的自适应方法。该方法第一步确定视盘的区域,然后通过血管的特征来判断绿色通道的前景和背景,在背景区域中检测视盘的具体位置。Aquino 等[3]提出了一种视神经盘分割算法,该方法采用投票法确定最终结果。首先利用形态学算法去除血管部分,然后通过边缘检测等处理得到视神经盘边界候选的二元掩膜,然后再通过霍夫变换计算视神经盘的圆形近似区域。
Tjandrasa 等[4]通过分割活动轮廓的方法,首先对输入图片进行灰度处理,然后再通过霍夫变换定位视神经盘的位置。Lupascu 等[5]通过拟合与视神经盘边界相似度最高的圆来定位视神经盘的位置。Yin 等[6]则是通过建模的方法确定视神经盘的形状,然后通过近似圆来确定视神经盘的圆心和直径,确定视神经盘的边界,最后对视神经盘的边界进行回归。Cheng[7]等提出了一种基于消除视神经盘旁萎缩的视神经盘分割方法。
Zhang[8]等介绍了一种基于一维投影的方式,分别计算视神经盘的水平位置信息和垂直位置信息,从而确定视盘的最终位置。Youssif 等[9]提出了一种基于滤波器的视神经盘的分割方法,利用原图红色通道的信息得到mask,然后通过形态学处理方法对光照进行处理,分割出血管的部分,根据血管的方向进行滤波匹配,从而实现对视神经盘的分割。牛笛[10]提出了一种基于卷积网络的视盘定位及分割方法,将显著图和卷积网络相结合提高定位准确性,通过血管去除和卷积网络结合进行视盘的分割。Maninis 等[11]提出了一种基于卷积神经网络的视神经盘分割方法,并结合迁移学习,取得了不错的效果。
2 网络模型
2.1 SimAM
注意力机制是在机器学习模型中嵌入的一种特殊结构,用来自动学习和计算输入数据对输出结果的贡献的大小,注意力机制能够使模型更加关注有用的信息,对次要信息做一定程度的抑制。现有的注意力方法有很多,通道式注意力和空间式注意力,如图1 所示,分别是1-D 通道注意力,2-D 空间注意力和3-D 权重注意力的比较,1-D 和2-D 方法都是针对一个通道中的所有神经元或一个空间中的所有神经元位置相同,以至于他们不能有效地计算真正的3-D 权重。3-D 权重注意力就是赋予每一个像素不同的权重,使得模型能够更加高效地提取特征。

图1 不同注意力机制比较
本文引入了一种3-D 权重注意力,嵌入在UNet++网络中,在不增加参数量的情况下有效提高模型的特征提取能力。SimAM 是一种即插即用的无参注意力机制,与现有注意力机制不同的是,它可以为中间隐藏层推断出一个3-D的注意力权重,并且不需要向原始网络添加参数。SimAM 以一些著名的神经科学理论为基础,信息量最大的神经元通常是那些表现出与周围环境不同的放电模式的神经元,并且活跃的神经元也可能抑制周围神经元的活动,这种现象叫做空间抑制。视盘分割过程中,需要UNet++网络对眼底彩照图片进行特征提取,此时我们希望提取视盘的有效特征,对于与视盘无关的信息,希望网络给予更少的关注,这正符合SimAM 注意力机制的理论。SimAM 为每个神经元定义了一个能量函数:
2.2 SimAM-UNet++
UNet++网络是在UNet 网络上增加了跳层连接而成,跳层连接的特点就是能够将浅层特征和深层特征进行融合,因为浅层特征代表的是图片的具体信息,而深层特征代表的则是图像的抽象信息,融合后的特征能够较为全面地表示原图中的信息。
UNet++在UNet 直接连接的基础上增加了类似于Dense结构的卷积层,并融合了下一阶段卷积的特征,如图2 所示,X(0,0)、X(1,0)、X(2,0)、X(3,0)、X(4,0),每一个部分都代表了一个block,block 的结构依次是ReLU 层、Conv层、BN 层、Conv 层和BN 层。对各层block 的输出进行上采样,然后和对应的浅层特征融合。采用这种密集连接方法提取的特征既包含了有全局感受野的抽象特征,又融入了具体细节的局部特征。
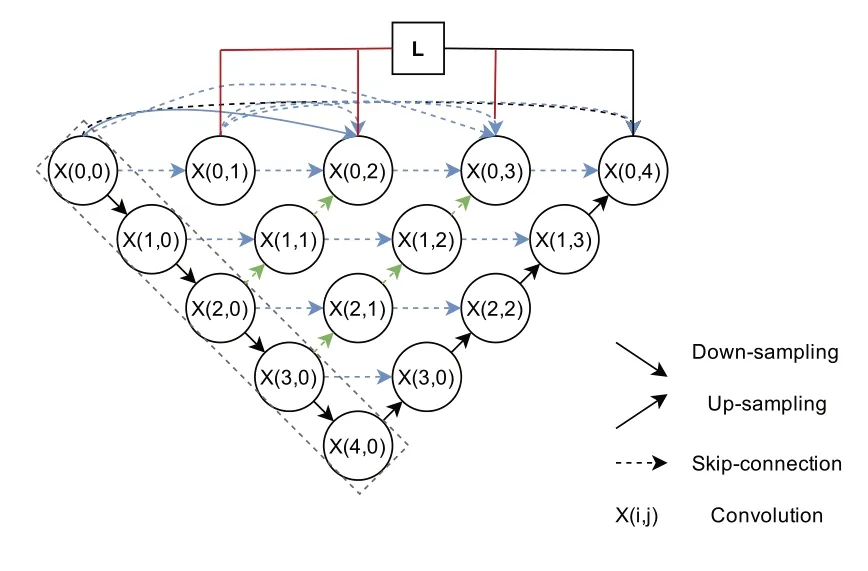
图2 Unet++网络结构
SimAM-UNet++网络是在UNet++中融入了SimAM 注意力机制。由于视盘分割任务要求网络的深度不宜过深,因为过深的网络会导致图像的细节特征丢失严重。为了进一步提高特征提取的有效性,我们在每一个下采样的block 中都添加了SimAM 注意力结构,如图3 所示,添加SimAM 之后block 的结构依次是ReLU 层、Conv 层、BN 层、Conv 层、BN 层 和SimAM 层。由于SimAM 注意力机制是基于求解能量函数来赋予每个神经元不同的重要性,所以添加SimAM注意力机制后的网络在不增加参数量的情况下能提高网络的学习能力。在视盘分割任务中,随着模型的训练轮次增加,网络能够学到更多和视盘相关的特征。
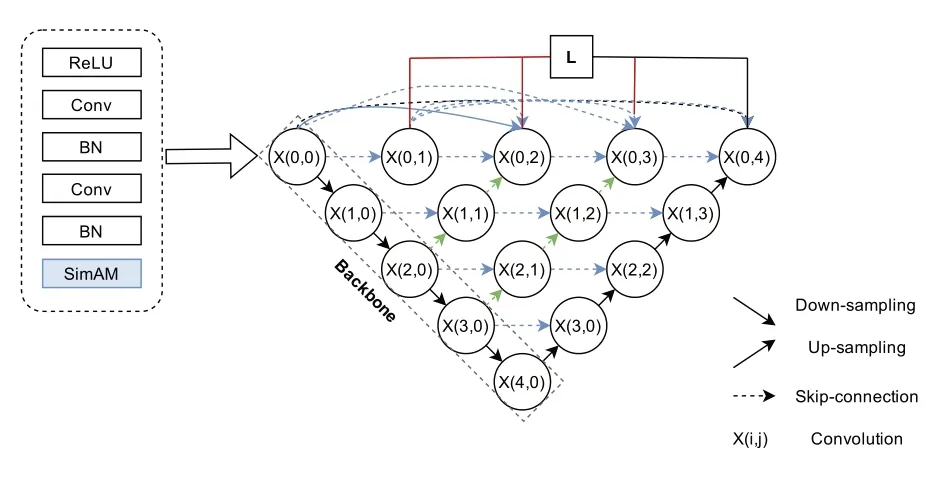
图3 SimAM-UNet++网络结构
3 实验设计
3.1 数据增强
本文使用的是iChallenge-PM 数据集,如图4所示,训练集为800 张彩色图,验证集为200 张彩色图,测试集为200张彩色图。由于训练的数据样本集较少可能会导致模型过拟合和模型的鲁棒性不够的问题。采用数据增强[12-13]技术在一定程度上解决了这个问题,有效提高模型的泛化能力。
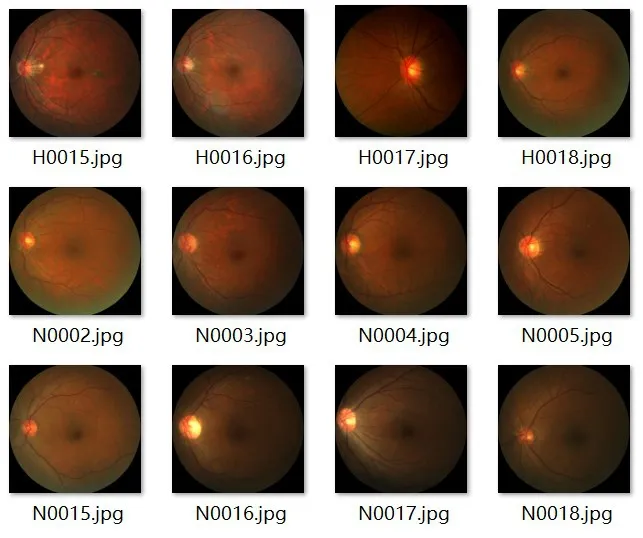
图4 眼底彩照数据集
3.2 直方图均衡化
直方图均衡化是一种增强图像对比度的方法,其主要方法是将一幅图像的直方图分布变成近似均匀分布,从而增强图像的对比度。如图4 所示,在iChallenge-PM 数据集中,可以观察到图像的对比度不是很强,某些图中视盘的肉眼可见性不明显,这是由于视盘的像素值和视盘周围的像素值比较接近,都集中在某一范围内,这样会导致网络在学习视盘特征时比较困难。为了解决这个问题,本文使用直方图均衡化的方法,通过增强图像的对比度使得图像中的像素值分布更加广泛,从而使得视盘的特征更加明显,如图5所示,这样有利于网络学习到与视盘相关的特征。
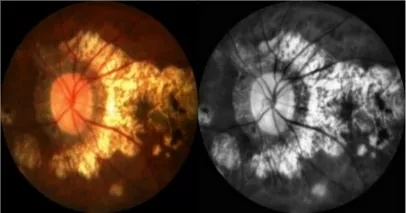
图5 直方图均衡化
3.3 实验结果与分析
为了评价分割结果,本文采用医学图像分割常用的评价指标Dice 系数,Dice 系数是表示两幅大小相同的图像相似程度的一种度量,Dice 系数越大,说明两幅图像的相似程度就越高,其公式如下:
其中:A表示输入图像通过模型分割之后的结果;B表示输入图像对应的掩膜;|A∩B|表示分割图与掩膜重叠的部分;|A|+ |B|表示分割图与其掩膜的总量。表1所示为各网络模型的Dice系数。
实验主要分为训练和测试两个阶段,首先在训练集上进行训练,通过训练集的损失、验证集的损失和验证集的准确率来保存最优权重,然后利用训练好的最优权重在测试集中进行模型测试,得到分割结果。图6所示为视盘分割的二值图,图7为分割的三通道图。
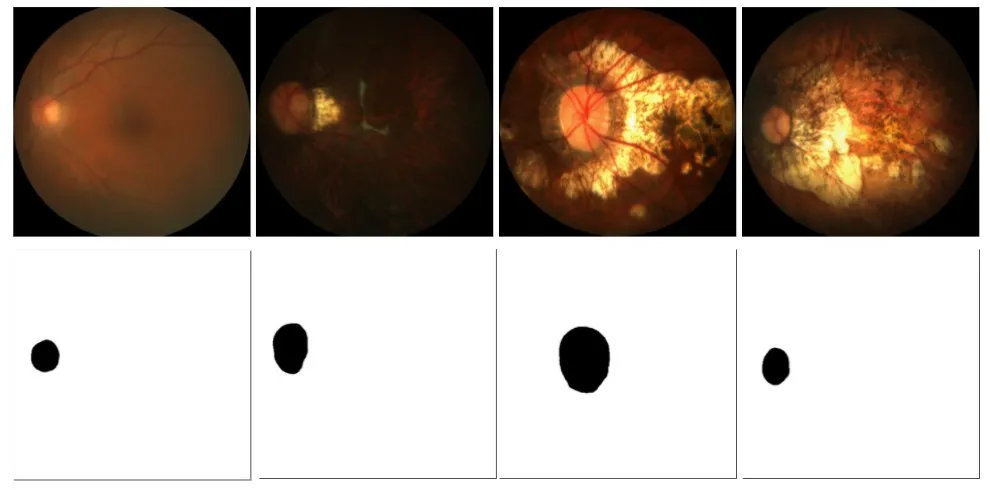
图6 视盘分割二值图
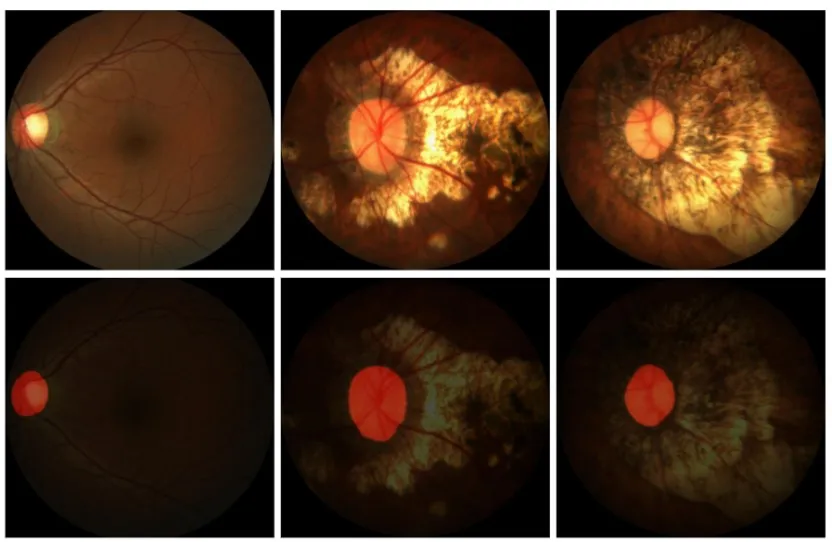
图7 视盘分割三通道图
为了证明模型的有效性,本文先后做了多组对比试验,主要包括以下内容:①利用Unet网络做视盘的分割;②利用SimAM-Unet 网络做视盘的分割;③利用UNet++做视盘的分割;④利用SimAM-UNet++做视盘的分割。每组实验分别从不同的指标来对分割结果进行比较。
从表1 可以看出,添加SimAM 注意力之后的UNet和UNet++网络均比不添加的网络效果更好,并且SimAM-UNet++网络的眼底彩照视盘分割效果在一定程度上优于其他三种模型,这进一步验证了SimAM-UNet++模型的有效性。
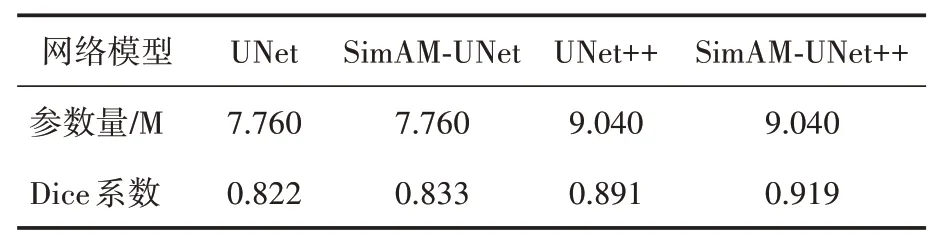
表1 参数量
为了进一步观察分割的结果,本文从损失的角度记录了验证集上100 个epoch 对应的损失值,绘制成曲线,如图8 所示。从图8 可以看出,添加注意力机制的SimAM-UNet++网络比UNet++网络收敛更快,并且SimAM-UNet++的损失能够收敛到更小。
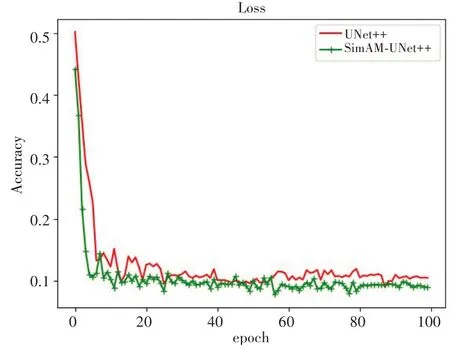
图8 损失函数
SimAM-UNet++在不增加模型参数量的基础上加速模型的收敛,如表1 所示,SimAM 是基于求解能量函数来得到每个神经元的权重,而不是通过深度学习的方式,这样有效避免了网络冗余的情况,增加了模型的效率。
4 结语
本文提出了一种新型的眼底视盘分割模型SimAM-UNet++网络,在不增加参数量的情况下,有效提高模型的效率和鲁棒性。对于一些较为复杂的眼底彩照图片,一方面使用SimAM注意力机制后,特征提取网络提取的特征更加精确,为上采样得到准确的分割图提供了保障;另一方面参数量的大小也会限制算法最终的落地效率,SimAM 无参注意力机制能够为UNet++网络提供更强的性能。通过数据增强技术对眼底彩照图片执行预处理操作,在推理过程中有明显提升视盘分割的效果。
猜你喜欢
国际眼科杂志(2023年3期)2023-04-15
基层中医药(2021年8期)2021-11-02
临床眼科杂志(2021年2期)2021-05-26
老友(2021年1期)2021-02-21
科学(2020年3期)2020-11-26
中医眼耳鼻喉杂志(2019年3期)2019-04-13
阅读与作文(小学高年级版)(2019年2期)2019-03-27
中医眼耳鼻喉杂志(2018年1期)2018-04-10
初中生天地(2016年17期)2016-06-29
初中生学习·低(2016年11期)2016-05-30
