
基于k-means 的自然驾驶轨迹聚类研究
2023-03-30 07:02:56倪思齐江浩斌尹晨辉沈青原
时代汽车 2023年6期
倪思齐 江浩斌 尹晨辉 沈青原
江苏大学 汽车与交通工程学院 江苏省镇江市 212013
1 引言
inD 数据集包含了城市交叉口处大量的自然驾驶轨迹数据,为研究人类在交叉口处的驾驶特性提供了数据支撑。然而inD 数据集并没有标注出车辆轨迹的转向类型,例如左转、右转、直行等。为了进一步开展针对不同转向类型的车辆轨迹拟合与轨迹预测研究,需要对数据集中车辆轨迹进行聚类。本文首先对inD 数据集中车辆轨迹的转向类型进行了人工标注。其次,设置了不同的k-means参数进行轨迹聚类,并将聚类结果与人工标注结果做对比,通过聚类正确度指标分析了不同参数对聚类结果正确性的影响,并对参数进行了优化。最后采用优化后的参数对inD数据集中部分车辆轨迹进行了聚类。
2 车辆轨迹的人工标注
2.1 人工标注流程
为了评价车辆轨迹聚类结果的正确性,将数据集中车辆轨迹的类别进行了人工标注。inD 数据集共包括4 个城市交叉口场景,共32 个子数据集。本文选取了场景2(如图1所示)中的4 个子数据集进行人工标注及轨迹聚类研究。由于本文只研究乘用车(car)轨迹特征,因此仅保留数据集中乘用车的轨迹。具体流程如下:
(1)剔除数据集中行人(pedestrian)、自行车(bicycle)与商用车(truck_bus)的轨迹。
(2)剔除静止车辆与违章驾驶车辆的轨迹。
(3)将十字交叉口处的车道按逆时针顺序依次标记(A 至J),如图1 所示。根据车辆驶入、驶出车道,将转向类型分为共计12类,如表1 所示。表中字母的顺序表示车辆行驶方向,例如AB表示车辆从A车道驶入交叉口,并从B 车道驶出。
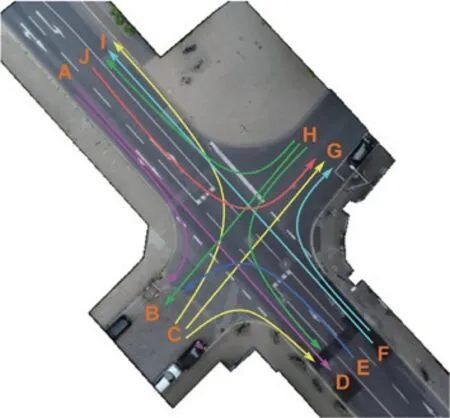
图1 车道标记
(4)根据车辆ID 的横、纵坐标,使用Matlab 画出所选部分数据集中的车辆轨迹,比对图1 中车辆驶入、驶出车道,在inD 子数据集文件中标入车辆轨迹的转向类型。
2.2 分类与统计结果
该十字路口处的车辆轨迹统计结果如表1所示。由统计结果得知,AD 与FI 两类直行轨迹占总轨迹数的59%,而CD、CG、CI、EB 与HB 的轨迹各自占比不足1%。

表1 车辆轨迹统计结果

续表1
3 k-means 超参数优化
3.1 性能参数
本文使用Matlab 中 的k-means 工具箱对车辆轨迹进行聚类。研究过程中发现,k-means 算法的中心初始化次数(Replicates)、距离度量标准(Distance)和中心初始化方法[1](Start)对聚类结果有不同程度的影响。
在k-means 聚类过程中,多次选取初始中心点可以有效减少中心点位置选取的随机性对聚类结果的影响。其中,Cluster 方法是在聚类初始阶段,随机挑选总样本的10%作为子样本,使用层次法聚类后再挑选由聚类生成的k 个簇中心作为初始质心,并开始聚类。uniform 方法则在所有样本点中先任意挑选一个点,然后根据样本点的分布范围均匀生成k 个质心,再逐一选择离这些质心距离最远的点作为后继质心,直至选取完毕。较cluster 而言,uniform 在一定程度上能够降低样本空间密度不一致对聚类中心初始化的影响。
k-means 距离度量标准中的欧氏距离(sqeuclidean)衡量的是空间各点的绝对距离,与样本点所在位置的坐标直接相关;而余弦相似度(cosine)、衡量的是空间向量的夹角,更能体现样本点在方向上的差异[1,2]。
3.2 超参数优化
本文采用控制变量法,在保持一个参数不变的前提下,研究另一参数的变化对k-means聚类正确度及程序运行时间的影响。其中,轨迹聚类正确度采用聚类外部评价指标[3,4]PI(纯 度)、FI(F 值)、RI(Rand指数)与ARI(改进Rand 指数)来量化;其值越接近1,聚类正确度越高。
(1)控制距离度量使用sqeuclidean、中心初始化方法选择uniform 不变,将中心初始化次数分别设置为10、40、70 与100。轨迹聚类效果及其正确度如图2 和表2 所示,程序运行时间如图3 所示。由图2、图3 及表2 可知,随着中心初始化次数的增加,虽然程序运行时间有所增加,但是轨迹聚类正确度有一定提升。因此,选取100 作为中心初始化次数。
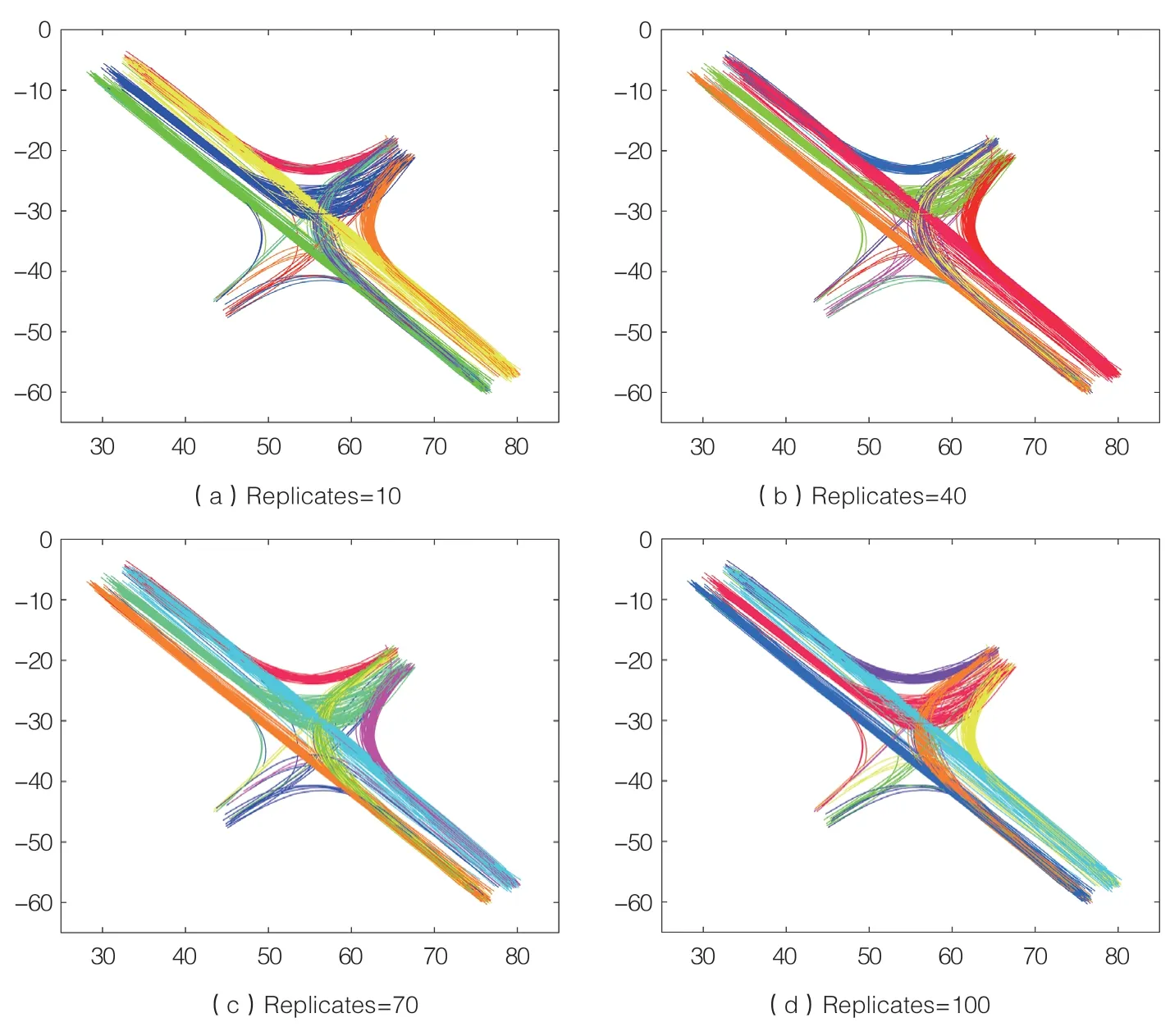
图2 不同中心初始化次数下的车辆轨迹聚类效果

图3 不同Replicates 值下的聚类时间

表2 不同中心初始化次数下的聚类正确度
(2)控制uniform 作为聚类的中心初始化方法不变,分别使用欧氏距离与余弦相似度对轨迹聚类4 次。各自的聚类效果、程序运行时间如图4 与图5 所示,聚类正确度如表3 的第二行与第三行所示。由图4 及表3可知,采用欧氏距离时总体聚类效果较好,但余弦相似度对直行轨迹两侧的转弯轨迹聚类效果较好。由于inD 数据集中直行轨迹数量的占比大于50%,其聚类正确度对总体聚类正确度的影响较大。又由图5 得知,使用欧氏距离聚类的程序运行时间较短。综合考虑后,使用欧氏距离作为k-means 中的距离度量,对车辆轨迹进行聚类。

图4 不同距离度量标准下的车辆轨迹聚类效果

图5 不同距离度量标准下的聚类时间
(3)控制欧氏距离作为聚类的距离度量标准不变,分别使用uniform 与cluster 对轨迹聚类4 次。结果显示,使用uniform 聚类的程序运行平均时间为44.7s,小于使用cluster 聚类的程序运行平均时间47.1s。各自的程序运行时间、聚类效果与聚类正确度如图6、图7 与表3 的第三行与第四行所示。综合考虑程序运行时间与聚类正确度,在保持欧氏距离作为距离度量不变的前提下,使用uniform 作为中心初始化方法。
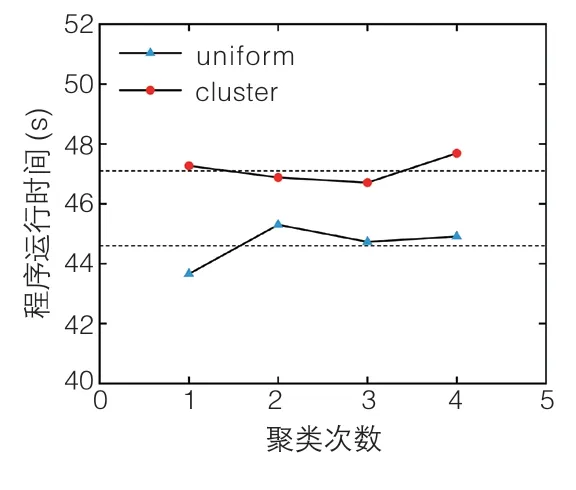
图6 不同中心初始化方法下的聚类时间

图7 不同中心初始化方法下的车辆轨迹聚类效果

表3 不同参数的聚类正确度
4 研究结果
使用k-means 对inD 数据集进行轨迹聚类,优化后的参数为:中心初始化方法选择uniform,距离度量方法选择sqeuclidean,中心初始化次数设置为100。其它参数为:聚类中心为12。该参数设置下的聚类效果如图8,结果显示车辆直行轨迹与大部分转弯轨迹的聚类正确度较高。聚类正确度分别为:PI=95.9%,FI=94.5%,RI=97.6%,ARI=93.8%。

图8 优化后的聚类效果
5 结论
本文使用了k-means 对inD 数据集中十字交叉口处的部分车辆轨迹进行了聚类。根据人工标注的车辆轨迹转向类型,使用控制变量法研究了k-means 在不同参数下的聚类正确度与程序运行效率,得出了较优的参数设置,并对车辆轨迹进行了聚类。该工作为后续进行基于转向类型的车辆轨迹拟合与轨迹预测提供了便捷。同时,inD 数据集中部分转向工况车辆轨迹数据量较少,聚类效果不是很理想,需要进一步改进k-means聚类方法以提高转向工况下车辆轨迹的聚类正确度。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
健康大视野(2020年6期)2020-04-10 06:47:58
法大研究生(2020年2期)2020-01-19 01:43:04
医学信息(2019年17期)2019-10-21 06:40:36
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
现代检验医学杂志(2016年5期)2016-08-20 03:17:18
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
中国医药指南(2015年10期)2015-10-22 06:22:58
黑龙江省政法管理干部学院学报(2015年4期)2015-03-26 20:34:09
