
基于跨度回归的中文事件触发词抽取
2023-03-29 12:31赵宇豪陈艳平黄瑞章秦永彬
应用科学学报 2023年1期
赵宇豪,陈艳平,黄瑞章,秦永彬
1.贵州大学公共大数据国家重点实验室,贵州 贵阳 550025
2.贵州大学计算机科学与技术学院,贵州 贵阳 550025
事件抽取从非结构化文本中抽取出用户感兴趣的事件信息,并以结构化呈现给用户,可以为自动文本摘要、事理图谱构建、智能问答等提供技术支撑,是信息抽取领域中的一个重要任务,具有重要的研究意义。2005年,自动内容抽取(automatic context extraction,ACE)约定了事件抽取任务。在该约定中,事件由事件触发词和描述事件结构的事件论元构成[1]。事件抽取包括事件触发词抽取和事件论元抽取两个任务。事件触发词抽取是指识别事件句中的触发词并对其所属事件类型进行分类,如在句子“浙江绿城集团日前已宣布正式‘收购’了这支上赛季刚刚降入甲B行列的球队”中,“收购”是事件的触发词,“交易”为触发的事件类型。目前,很多事件抽取的研究是以英文方式展开的。相对于英文,中文缺少自然分割符,且中文句子结构松散,缺少分词信息和词形变化,由此可见中文事件抽取是一项更具挑战的任务。
用于中文事件触发词抽取任务的主流模型是基于词或基于字符的模型,其中基于词的模型将事件检测视为逐词分类问题。文献[2]用分词工具将句子分词,然后使用基于卷积神经网络(convolutional neural network,CNN)的模型提取句子特征并对词进行分类。文献[3]提出了一种双向的循环神经网络(recurrent neural network,RNN)模型来提取句子特征,更好地保留了句子的语义信息。文献[4]基于CNN 提取重要特征,使用双向长短期记忆(bidirectional long short-term memory,Bi-LSTM)网络提取全局语义特征,再结合两种特征对词分类。然而,中文缺少天然的分隔符,采用分词工具实现分词会带来错误传播,可能引起事件触发词错误匹配的问题。如图1所示,“射杀”包含了两个触发词,“射”触发了类型为“受伤”的事件,“杀”触发了类型为“死亡”的事件;又如图2所示,“受了伤”触发了类型为“受伤”的事件,却被分词为3个单独的字,而在英文中不存在分词错误的问题。
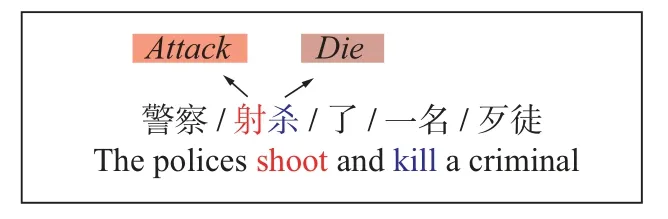
图1 触发词错误匹配例子1Figure 1 Trigger word mismatch example 1

图2 触发词错误匹配例子2Figure 2 Trigger word mismatch example 2
由于分词会导致触发词错误匹配问题,有的学者开始采用基于字符的模型进行事件触发词的检测。文献[5]先用RNN 提取句子的每一个字符特征,再以条件随机场(conditional random field,CRF)预测每一个字的标签。文献[6]提出一种动态多池化的CNN 模型,在CNN 得到的卷积特征上进行分段池化,可以获得句子不同部分的语义特征。文献[7]兼顾CNN 和长短期记忆(long short-term memory,LSTM)网络的优势,使用一种卷积的Bi-LSTM 网络提取字符级别的信息,可以让模型学习到更好的局部语义特征和全局语义特征,但难以捕获触发词的结构信息和上下文的语义信息。为了能更好地解决这一问题,文献[8]把字符特征、词特征、位置特征、预训练模型获取的特征结合在一起,通过CRF 预测每一个字的标签。文献[9]用动态多池化卷积神经网络(dynamic multi-pooling convolutional neural network,DMCNN)分别提取字符特征和词特征,再融合两种特征穷举可能的触发词进行分类。文献[10]通过Lattice LSTM 网络在字级别信息上融入外部词典的知识信息,在预测字的标签时可以用到词级别的特征信息。但是以上结合字词信息的混合表示缺乏用于触发词分类的语义信息。
中文事件触发词的结构有一定的规律,通常是“动词”、“动词+名词”、“方式副词+动词”、“动词+副词+名词”等[9]。传统的模型难以捕获到触发词的边界特征信息和结构特征信息。在信息抽取领域的实体识别任务中,文献[11-12]对候选实体边界的位置进行回归调整,在实体识别任务中取得了不错的结果,说明对目标的边界进行回归调整可以学习到更多语义信息。受以上工作的启发,本文提出一种基于跨度回归的方法。该方法用跨度表示候选的触发词,并对跨度的边界进行回归调整来学习触发词的边界特征信息和结构特征信息。首先通过基于Transformer 的双向编码器(bidirectional encoder representation from Transformer,BERT)[13]获取句子特征表示,进而生成触发词候选跨度;然后训练一个跨度分类器和一个跨度回归器,前者用来筛选候选的跨度,后者用来对候选跨度的边界进行回归调整以定位触发词;最后把已调整的候选跨度输入一个触发词分类器进行分类。
1 基于跨度回归的触发词抽取模型
已有的相关研究大多将事件触发词的检测任务当作序列标注任务,输入一个句子,输出句子对应的序列标签,这种方式会受到数据标签稀疏的影响。本文考虑到句子中特定长度的字符子序列可能构成一个事件触发词,这样对于长度为n的句子,如果不限定候选跨度的长度,可能的触发词候选跨度就有n(n+1)/2 个。本文首先过滤掉大部分不可能为触发词的候选跨度,然后对可能为触发词的候选跨度进行回归调整以准确定位触发词。本文模型的结构如图3所示:
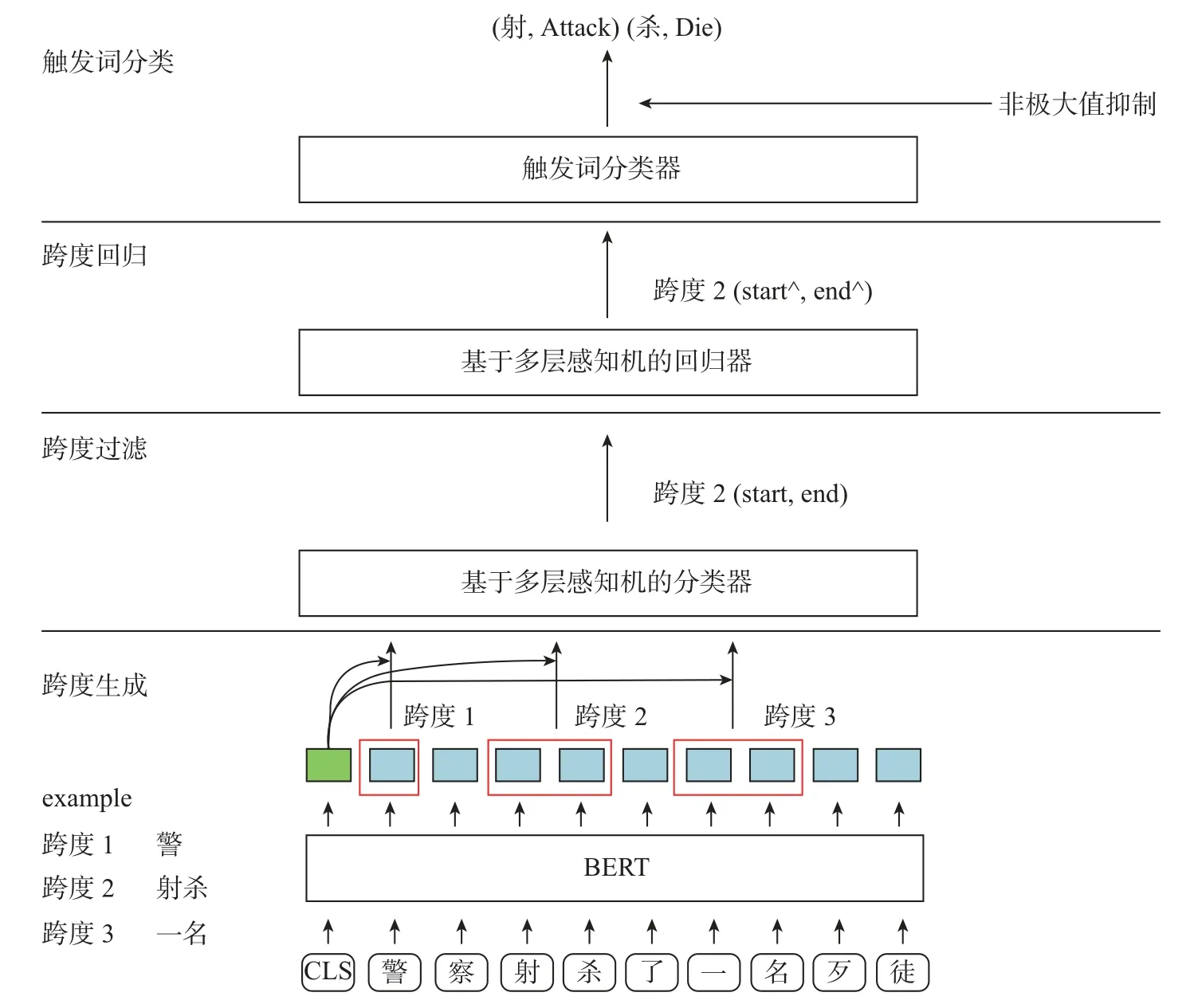
图3 基于跨度回归的事件触发词抽取模型Figure 3 Event trigger word extraction model based on span regression
本文模型的具体步骤如下:
步骤1采用预训练模型BERT 获取句子的特征表示,按照设定好的长度在句子特征表示上生成候选跨度,并以候选跨度在句子中的开始位置和结束位置表示候选跨度。
步骤2通过一个分类器过滤掉负样本跨度,因为在生成候选跨度时会得到大量的负样本跨度,所以需要该分类器妥善处理正负样本类别不均衡的问题。
步骤3使用一个跨度回归器来预测候选跨度的左右边界偏移量,再按照偏移量调整候选跨度的边界,以便准确地定位触发词。
步骤4将调整后的候选跨度分类,得到一系列固定大小的候选跨度及其对应类别的预测分数。
最后根据非极大值抑制算法(non-maximum suppression,NMS)[14]去除冗余的候选跨度,得到最终的抽取结果。
1.1 生成触发词候选跨度
本文把句子输入BERT,获取句子的特征表示序列e(s)=(ec,e1,···,en)。其中ei是句子中第i个字的嵌入,ec为字符CLS 的嵌入,带有句子的整体语义。由于中文事件触发词的长度一般在3 左右,本文设置了一个长度集合W={1,2,3,4,5,6}。本文遍历句子的特征表示序列,按照设置的长度生成候选跨度,最终得到一个候选跨度的集合L=(s0,s1,···,sk),si(li,ri)表示第i个跨度,li表示第i个跨度的开始,ri表示第i个跨度的结束。
本文用交并比(intersection over union,IOU)筛选正负样本。交并比可以计算两个跨度之间的重叠程度,于是本文设定一个阈值,计算每一个候选跨度与真实触发词跨度的交并比。如果交并比大于阈值则作为正样本跨度,否则作为负样本跨度。假设阈值α=0.7,则交并比的计算公式为
将HIOU大于α的候选跨度作为正样本跨度,给它分配对应的真实事件触发词的类别;将HIOU小于α的候选跨度作为负样本,给它分配一个none 事件类别。对于正样本,本文用来计算与真实事件触发词的左右边界位置偏移量。对于负样本,考虑到过多的负样本会影响模型的训练,本文设置了一个计数变量控制负样本的数量,先随机采样负样本,之后用正负样本训练跨度分类器和跨度回归器。
1.2 过滤触发词候选跨度
本文的候选跨度分类器是一个基于多层感知机(multilayer perceptron,MLP)[15]的分类器。MLP 包含两个线性层和一个采用随机正则的高斯误差线性单元(Gaussian error linear unit,GELU),具有较好的分类效果。本文对输入的候选跨度进行分类,过滤类别为none 的候选跨度。
从整体的句子特征中,取出跨度si对应的特征表示为e(si)=e(s)(li:ri),对跨度si的特征表示进行最大池化
把代表句子语义信息的ec和跨度的最大池化特征,以及跨度开始边界特征和结束边界特征拼接,用公式表示为
将得到的跨度最终特征表示F(si) 输入MLP 的分类器,得到类别预测分数为
在得到候选跨度的预测类别之后,过滤掉预测类别为none 的候选跨度。
1.3 回归调整候选跨度的边界
为了准确地定位真实的事件触发词跨度,需要通过回归调整候选跨度的左右边界。本文使用MLP 进行左右边界偏移量的回归预测,则拼接跨度的最大池化特征、跨度开始边界特征、跨度结束边界特征可以表示为
使用MLP 进行左右偏移量的回归预测,即ti=MLP(I(si))。根据左右边界偏移量调整候选跨度的边界,需要注意左右边界的位置必须在句子的范围内即(0,n),为调整后的候选跨度的左边界位置,为调整后的候选跨度的右边界位置,其计算公式如下:
1.4 触发词分类器
将调整后的候选跨度最终表示F(ˆsi) 输入触发词分类器,得到类别预测分数
得到候选跨度对应的类别预测分数后,需要使用NMS 算法去除冗余的候选跨度。本文将预测得到的候选跨度表示为di=(li,ri,yi,scorei),yi表示预测跨度的类别,scorei表示预测跨度的类别置信度。NMS 算法首先对预测的候选跨度按照score 大小进行排序,从score 分数最高的di开始执行算法,完成如下所示的算法过程。

2 触发词抽取模型训练实现
本文模型的训练过程包括3 个模块,分别为触发词候选跨度分类模块、触发词候选跨度回归模块、最终触发词分类模块。3 个模块同时训练,联合计算损失。
2.1 训练跨度分类器
本文用正负样本训练一个分类器作为本文的跨度分类器。考虑到采样过程中负样本的数量比较多,本文使用Focal Loss[16]解决正负样本失衡问题[16]。Focal Loss 通过更新不同类别样本损失的权重,加强模型对稀疏类别的学习。过滤的分类损失为
2.2 训练跨度回归器
本文计算正样本与真实触发词之间的左右边界偏移量t,训练一个基于MLP 的回归器。本文将Smooth L1 Loss[17]作为跨度回归器的损失函数,避免较大的错误偏移量主导回归的损失造成梯度爆炸。本文的跨度边界回归损失为
2.3 训练触发词分类器
本文最后对调整后的候选跨度进行分类,为了解决ACE2005 数据集中的事件触发词类别不均衡问题,设置了一个截断式的损失函数,加强模型对少数事件类别的关注。本文触发词分类的损失为
式中:xt为目标的预测值,K为设置的权重,可以通过调整损失函数中K的值来加强模型对稀疏事件类别的关注。本文模型最终的训练损失Lall为
式中:Lfl为跨度分类器的损失,Lloc为跨度回归器的损失,Lclass为触发词分类器的损失。
3 实验分析
3.1 数据集和实验环境
本文实验在ACE2005 中文数据集上进行,该数据集由ACE 项目发动。ACE2005 中文数据集包含来自新闻、广播、网络博客的633 份文档。该数据集对事件抽取任务进行了标注,包含8 个大的事件类型和33 个事件子类型。本文参考以前学者的工作[9],以8∶1∶1 的比例按文档数量划分成训练集、验证集、测试集。
本文实验基于Python 语言、PyTorch 深度学习框架,在NVIDIA Tesla A100 GPU 平台上进行实验。实验设置参数如表1所示:

表1 模型参数Table 1 Model parameters
3.2 实验结果与分析
为了证明本文模型的优点,将其与目前主流的模型进行性能比较。随后,为了证明回归调整的有效性,本文设置了基于跨度的消融实验。本文实验采用MUC 作为评价指标,即准确率P、召回率R、F1值。
3.2.1 基于跨度回归的方法与其他模型对比
如表2所示,将本文模型与以下模型在触发词识别任务和触发词分类任务上进行性能比较。
1)DMCNN[6]提出了一种动态多池化的卷积神经网络进行事件触发词检测,其中包括基于词的WDMCNN 和基于字的CDMCNN。
2)CBiLSTM[7]提出了一种卷积双向LSTM 的网络结构。
3)FBRNN[3]提出以双向循环神经网络进行事件触发词检测。
4)HNN[4]结合CNN 和Bi-LSTM,构造了一个用于事件触发词检测的神经网络结构。
5)NPN[9]提出了一种结合字和词特征表示的方法,并穷举可能的触发词进行检测。
6)TLNN[10]提出了一种触发词感知的Lattice LSTM 网络,并结合外部词典HowNet 补充词级别信息。
这些模型中的CDMCNN 和CBiLSTM 是基于字符的模型,FBRNN、WDMCNN、HNN是基于词的模型,NPN 和TLNN 是基于字词联合的模型。
由表2可以看出:本文方法在触发词识别任务上的F1值与TLNN 相比提升了2.38%,召回率也相对较高,说明本文提出的通过回归调整候选跨度边界来准确定位触发词是可行的;基于字符的模型性能是最差的。从表2中还可以看出:若以F1值来考量,则基于词的WDMCNN 比基于字符的CDMCNN 提升了4.20%。基于字符的模型虽然避免了分词带来的错误,但缺少了词义信息,难以捕获触发词的结构信息。基于字词联合的模型结合了基于字符的模型和基于词的模型的优点,但是不便衡量字符信息和词信息的重要性,因为在触发词的识别阶段,字符信息相对于词信息更为重要。本文的跨度回归模型则对跨度边界进行调整,能更好地学习到触发词的结构信息和边界信息,更利于触发词的识别。
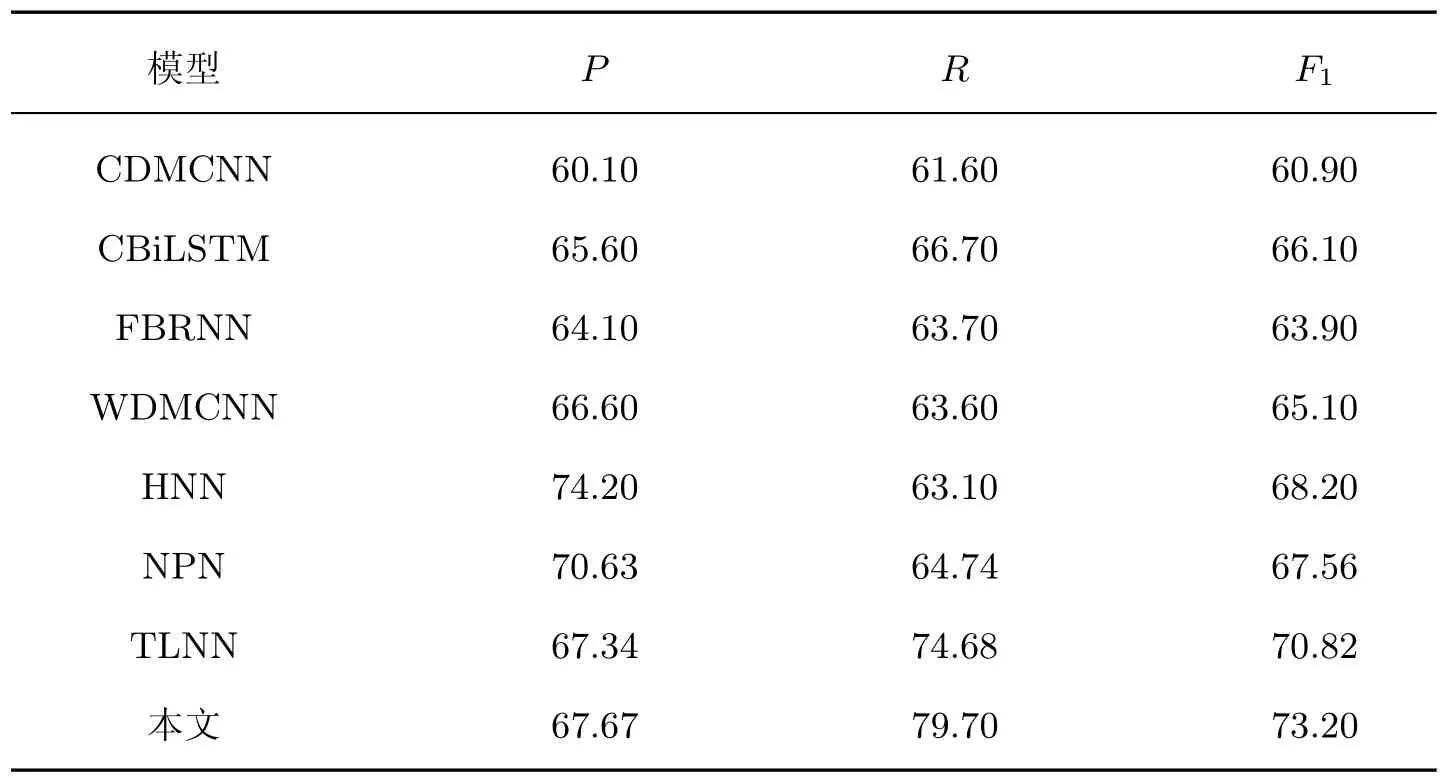
表2 触发词识别任务性能比较Table 2 Performance comparison of trigger word recognition task%
在触发词分类任务上的实验结果如表3所示,可以看出:本文方法在触发词分类任务上的F1值与TLNN 相比提升了3.82%,准确率和召回率都相对较高,说明本文模型使用跨度表示候选触发词可以充分利用有助于触发词分类的语义信息,且通过跨度分类过滤和跨度回归调整也让触发词的分类更为准确。从表3中还可以看出:基于字符的模型和基于词的模型在触发词分类任务上的性能都比较差,因为这两种模型都不能较好地捕获触发词的结构信息和语义信息。基于字词联合的模型可以将字符信息和词信息结合起来,但缺少用于触发词分类的语义信息,而且对触发词进行分类时不能突出更重要的词信息。本文的跨度回归模型在生成跨度表示的时候加上了句子的整体语义信息,并且通过回归调整更好地学习到了触发词的结构信息和语义信息。
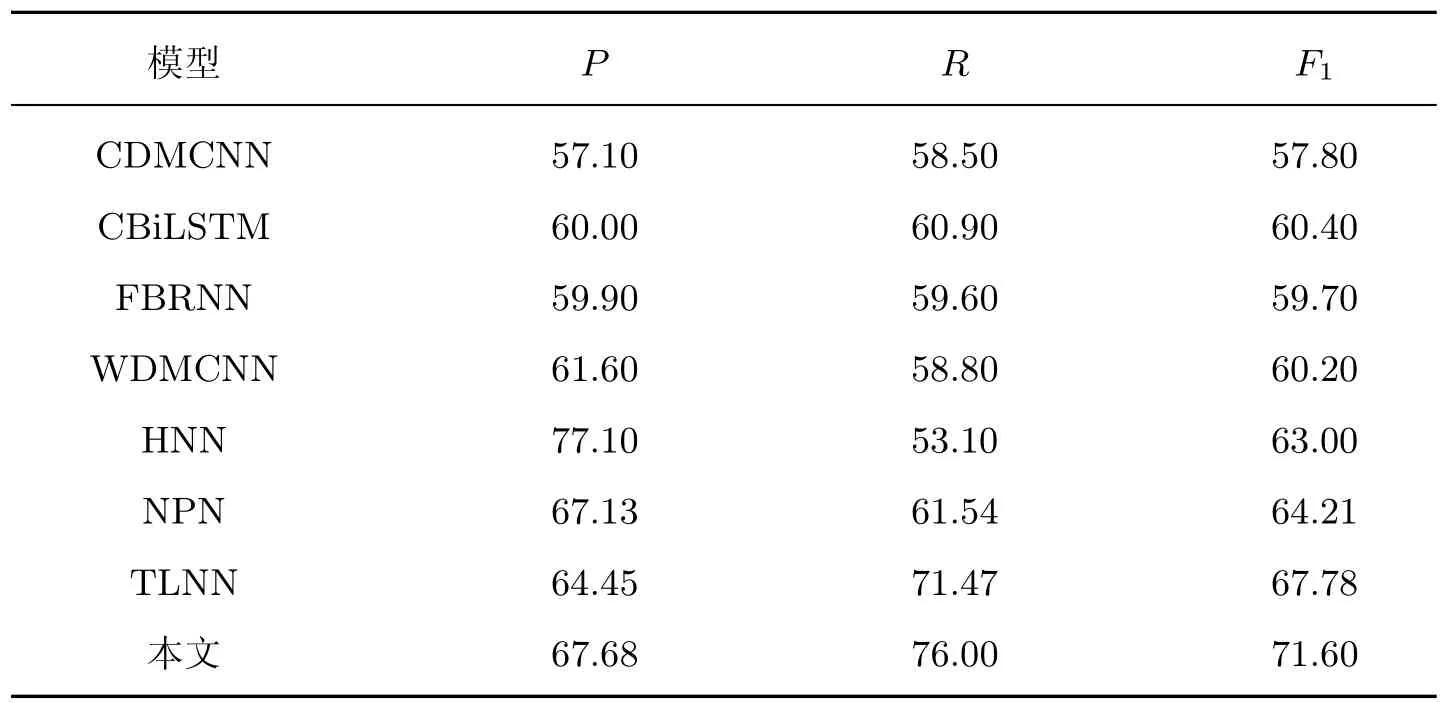
表3 触发词分类任务性能比较Table 3 Performance comparison of trigger word classification tasks%
综上所述,本文模型在触发词识别和触发词分类两个任务上均优于目前主流的模型。在这些模型中,与本文工作比较相似的是NPN 模型。NPN 模型以句子中的每一个字符为中心,左右滑动一定的位置作为触发词的左右边界,穷举可能的候选触发词进行检测。此类方法通常面临计算复杂度较大的问题,本文则在训练时随机动态采样一定数量的负样本,而在预测时过滤掉大量的负样本,优化了模型的计算复杂度,从而在一定程度上缓解了负例过多带来的不平衡问题。
3.2.2 验证对跨度进行回归调整的有效性
为了证明回归调整的有效性,本文调整了模型结构,实现了基于跨度的触发词检测模型。本文完成了两组对比实验。在触发词识别任务上的结果如表4所示,可以看出:基于跨度回归的方法相比基于跨度的方法,在触发词识别任务上的F1值提升了2.08%。在准确率上提升了3.94%,说明加入回归调整能够让候选跨度更准确地定位真实触发词的位置。

表4 触发词识别对比实验Table 4 Comparison experiment of trigger word recognition%
在触发词分类任务上的结果如表5所示,可以看出:基于跨度回归的方法相比基于跨度的方法,在触发词分类任务上的F1值提升了2.43%,且准确率和召回率也更高,说明基于跨度回归的方法更具优势。

表5 触发词分类对比实验Table 5 Comparison experiment of trigger word classification%
综上所述,基于跨度回归的方法相比基于跨度的方法,在触发词识别和分类任务上的性能都有了提升。基于跨度的模型将与事件触发词有交集但不完全匹配的跨度都当成了负例,便不能充分利用这些跨度信息。本文的跨度回归模型则把这部分跨度当成正样本并在回归时进行调整,这样就能更好地学习触发词的边界信息和结构特征,并通过调整跨度的边界去定位真实的触发词。
3.2.3 NMS 算法的影响
NMS 是目标检测领域的一种常用算法,用于模型预测阶段去除冗余的候选结果。本文将建立一组实验来探索NMS 算法对模型的影响。在事件触发词抽取标准中,事件触发词的正确抽取意味着必须同时正确识别事件触发词的开始边界和结束边界,并且对识别出的事件触发词正确分类。本文的NMS 算法在模型的预测阶段有效,但不参与模型的训练。本文将NMS阈值从0.3 设置为1.0,实验结果如表6所示。
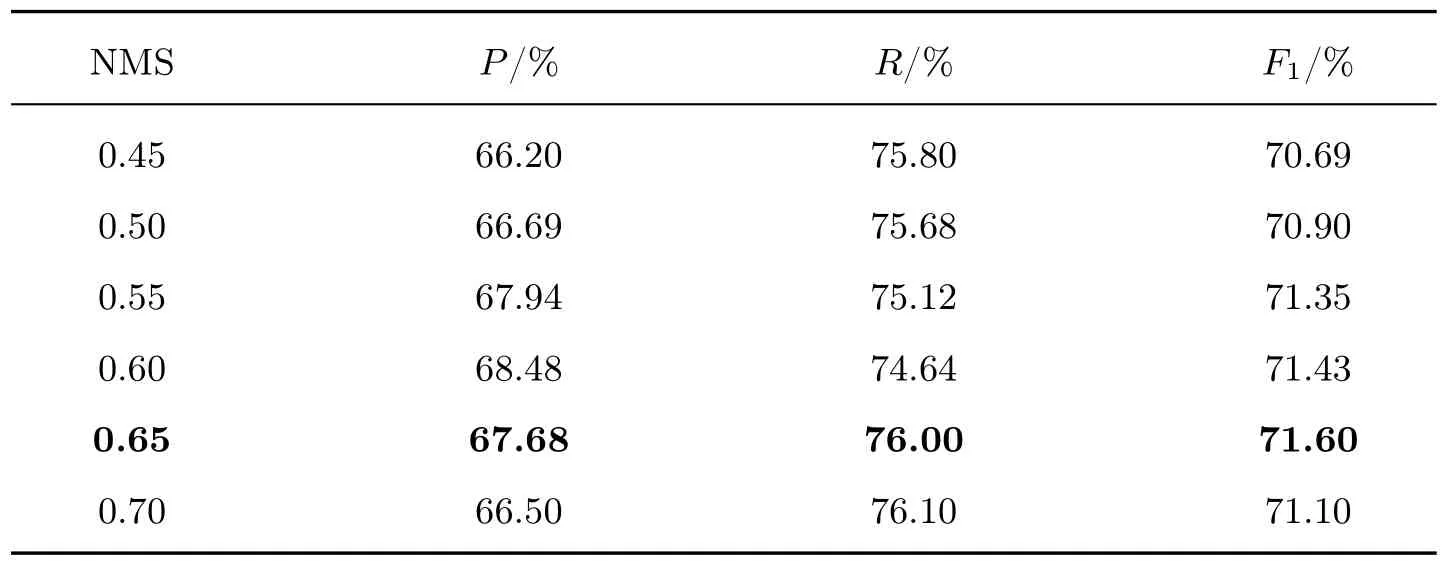
表6 NMS 阈值对模型的影响Table 6 Effect of NMS threshold on model
由表6可以看出:NMS 算法的阈值对模型的性能是有影响的,且随着NMS 阈值的增加,模型的性能有所上升,并在NMS 阈值为0.65 时取得最好的性能。NMS 算法是用来筛选最终结果的,因为在触发词分类阶段之后得到的是一系列候选跨度及其类别预测分数,而这些候选跨度之间存在冗余,所以利用NMS 算法能妥善解决冗余问题,并提取最终结果。
NMS 算法广泛应用于目标检测。在目标检测中,根据置信水平将矩形检测框排序,进行交并比计算过滤冗余检测框,选取最终检测结果。本文使用NMS 算法选择置信度最高的触发词候选跨度,算法过程详见1.4 节。
3.2.4 负样本采样数量对模型的影响
本文研究了负样本采样数量对模型的影响,在候选跨度分类阶段需要过滤掉大部分不可能为触发词的负样本,使模型充分学习这些负样本的特征。这些负样本数量是比较多的,如果在训练过程中完全枚举一个句子中的负样本,不仅会增大计算量,而且会带来正负样本不均衡的问题。因此,本文随机动态采样一定数量的负样本参与模型训练,让模型在训练阶段能每次从句子中随机采样10 个、20 个、50 个、100 个、150 个、200 个负样本。图4显示了本文模型的F1值与每个句子中负样本数量之间的关系。
在图4中,开始时随着负样本数量的增加,模型的性能也随之提升,这说明模型的训练需要足够数量的负样本;当负样本达到一定数量后,模型的性能开始变得稳定;之后再增加负样本的数量,模型的性能就开始下降,这说明太多的负样本会影响模型的效果。分析实验结果可以得出:当负样本采样数量为50 时,模型的性能最好;当负样本数量大于150 时,模型的性能开始下降。
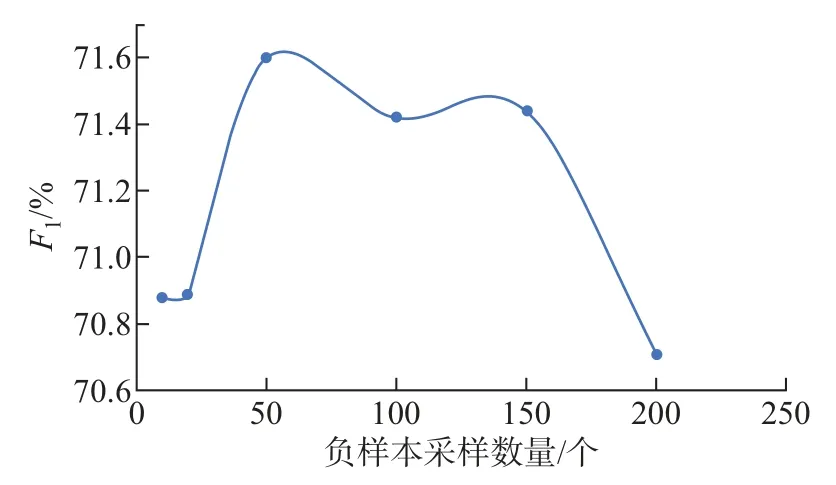
图4 负样本数量对模型性能的影响Figure 4 Effect of negative sample number on model performance
4 结 语
本文提出了一种基于跨度回归的中文事件触发词抽取方法。相比于传统的基于词或基于字符的模型,可以避免分词带来的错误,更好地学习触发词的结构信息和上下文语义信息。该方法在生成候选跨度表示时结合了句子的语义信息,更利于触发词的分类;可以用到更多的跨度信息对跨度边界进行回归调整,让事件触发词的检测更准确。下一步工作将研究使用基于跨度回归的方法抽取事件论元,联合建模事件触发词抽取任务和事件论元抽取任务进行多目标学习,让两个任务相互促进,以提高中文事件抽取的效果。
猜你喜欢
建材发展导向(2022年14期)2022-08-19
儿童时代·幸福宝宝(2021年11期)2021-12-21
西部交通科技(2021年9期)2021-01-11
现代装饰(2020年4期)2020-05-20
上海建材(2018年4期)2018-11-13
证券法律评论(2018年0期)2018-08-31
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
铁道科学与工程学报(2015年4期)2015-12-24
外语学刊(2014年6期)2014-04-18
