
基于深度学习的医疗电子数据特征学习方法
2023-03-29 12:31崔运鹏
应用科学学报 2023年1期
王 婷,王 娜,崔运鹏,刘 娟
1.中国农业科学院农业信息研究所,北京 100081
2.农业农村部农业大数据重点实验室,北京 100081
3.96962 部队,北京 102206
物联网、可穿戴技术的快速普及,人工智能算法的不断优化和高性能计算存储环境的迅猛发展催生了医疗健康大数据的广阔前景。在国家政策、社会需求和技术创新等因素的影响下,对医疗健康大数据的分析和应用已经上升到国家战略高度。2016年,国务院发布的《关于促进和规范健康医疗大数据应用发展的指导意见》首次强调了健康医疗电子数据是医疗健康大数据中重要的组成部分,具有快速增长、多模态、复杂性等特点,同时包含患者的用药信息等时序动态数据和疾病名称、药物史、社会经历、家族史等丰富多样的静态数据[1]。如何运用人工智能技术从医疗电子数据中有效挖掘出有用的信息是当前医疗健康大数据环境下所面临的巨大挑战之一。
数据特征学习是一种有效的大数据挖掘分析方法,既能作为独立任务有效挖掘数据的内在模式,也能作为其他研究的基础。专家驱动的数据特征学习是传统的医疗数据分析方法,基于专家经验设计数据特征,但是过于依赖专家的先验知识,易受干扰且效率低下,无法充分发现医疗健康大数据中隐含的复杂特征。基于人工神经网络理论的深度学习是发展最快也最热门的人工智能方法,通过构建多层神经网络模型实现对大规模数据的深层次表达,无需领域知识便能实现对数据特征的有效学习,非常适用于高维复杂医疗大数据的挖掘分析。
在学术界和工业界,已出现一些基于深度学习的医疗大数据挖掘分析方法,分别应用于患者疾病诊断、临床治疗、医学图像处理、医学数据建模、蛋白质结构预测、测序数据处理等,如表1所示。其中有些应用在相关方向取得了突破。Gao 等[2]结合卷积神经网络(convolutional neural network,CNN)和循环神经网络模型(recurrent neural network,RNN),基于眼部检查图像对核性白内障进行严重程度分级,在准确率等性能方面打破了该领域诊断的记录。Ciresan 等[3]基于CNN 模型自动判别腺癌细胞图片中的有丝分裂现象,以高准确率赢得国际模式识别大会竞赛环节的冠军。
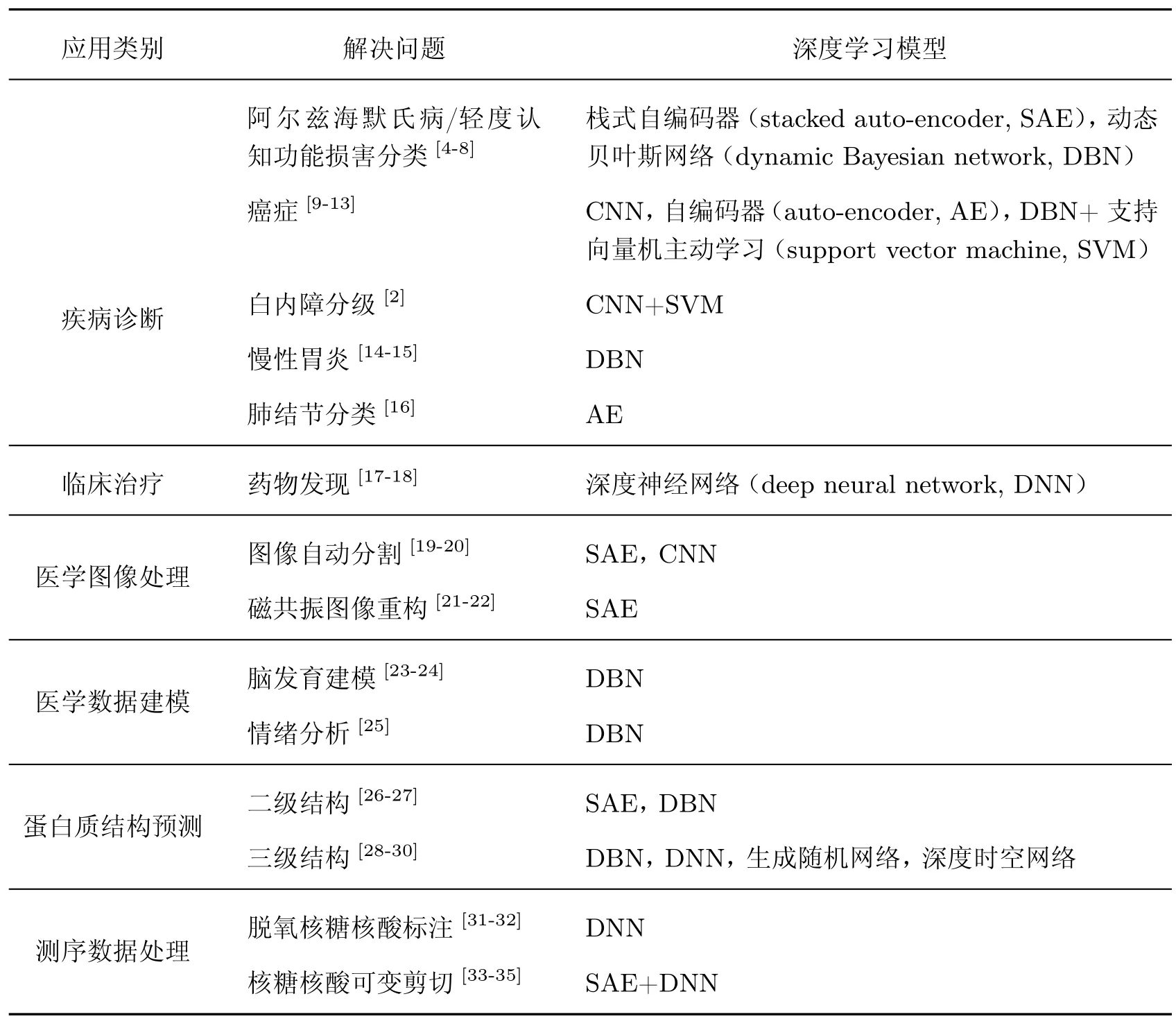
表1 基于深度学习的医疗领域应用Table 1 Medical applications based on deep learning
相关研究工作虽然已经取得很多进展,却仍然存在局限性,尤其是在时序动态数据和静态数据共存的常见医疗领域场景中。目前,已有研究通常使用两种分析模式:动态数据和静态数据分别独立分析;把动态数据规约为具体统计指标,再关联静态数据进一步分析。然而,这两种分析模式在解决实际问题时既无法发挥时序动态数据的隐含模式,也不能充分发挥多维时序数据之间关联关系的作用。
根据以上分析和已有问题,本文面向患者联合用药不良预后风险预测,结合患者的联合用药数据和静态数据,提出一种基于深度学习的医疗电子数据特征学习方法,主要包含以下三方面的内容:
1)构建长短期记忆- 自动编码器(long short-term memory-auto encoder,LSTM-AE)模型对患者联合用药数据中的多维时序数据进行特征学习,结合神经网络模型中能够有效记忆时序关联特性的长短期记忆(long short-term memory,LSTM)模型和具有强大的自学习能力的自编码器(auto-encoder,AE)模型,有效保证了对多维复杂时序数据的特征学习效果。
2)针对高维医疗电子静态数据,采用DNN 模型进行数据特征学习,分别构建风险预测特征向量和风险相关特征向量,进行患者联合用药风险预测及其相关因素分析。
3)创新性地提出联合用药数据中的多变量时序数据在解决实际临床问题中的应用模式。在患者用药不良预后评估中,把用药数据转化为联合用药综合表达因子,充分利用了患者用药数据的时序特性和不同用药数据之间的关联关系,有效优化了多变量时序数据的深度应用。
1 分阶段神经网络模型
根据患者医疗电子数据的不同类型,分别构建LSTM-AE 模型和DNN 模型,用来实现联合用药数据和静态数据的特征学习。
1.1 时序数据特征学习模型LSTM-AE
LSTM-AE 模型以深度学习LSTM 模型结构作为AE 模型的隐藏层单元,如图1所示。其中:前者能够有效记忆数据的时序关联特性,后者具有强大的特征自学习能力。LSTM-AE模型能将两者结合起来,在保留序列特性的前提下实现数据降维,从而保证对患者用药数据的特征提取效果。
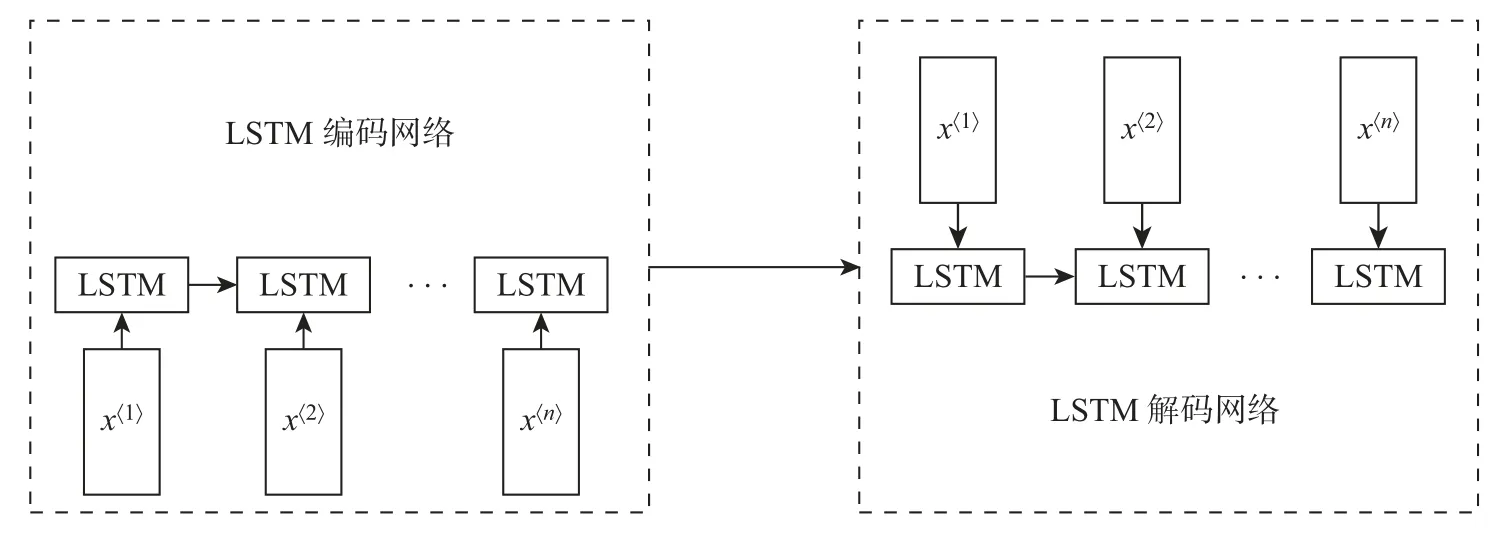
图1 LSTM-AEFigure 1 LSTM-AE model
1.1.1 LSTM 模型
LSTM 属于特殊的深度学习RNN 模型,相较于普通RNN 模型有更好的序列记忆性能,能有效解决长序列训练过程中梯度消失的问题。LSTM 的计算过程如式(1)~(6) 所示:
式中:σ(·) 表示tanh 函数;Gf、Gu、Go分别表示LSTM 单元中的遗忘门、更新门、输出门,分别控制已有内容的遗忘程度、输入更新、输出;Wf、Wu、Wo分别表示遗忘门、更新门、输出门的权重矩阵;bf、bu、bo分别表示遗忘门、更新门、输出门的偏置向量;t表示输入的不同时刻;x〈t〉、a〈t〉、c〈t〉分别表示输入值、隐藏状态值、输出值。
1.1.2 AE 模型
AE 模型以输入和输出相等为优化函数,可以对输入进行编码获取新特征表达,然后在此基础上进一步解码得到输出。AE 模型分别包括LSTM 编码网络和LSTM 解码网络,训练过程如下:
步骤1把单个药品的用药数据逐个输入编码网络,将最后一个x〈m〉输入后得到的a〈m〉作为整个时序数据的新特征表达,其中激活函数使用线性整流函数。
步骤2把a〈m〉输入解码网络,以均方差(mean squared error,MSE)为优化函数进行模型训练,可以用公式表示为
同时,本文使用KL 散度为自动编码器添加稀疏性限制,计算过程如式(8)~(10) 所示:
式中:β为控制稀疏限制的权重因子,为隐藏层的平均活跃度,vKL表示两个变量之间的相对熵。
1.2 高维数据特征学习模型DNN
深度神经网络DNN 是典型的深度学习基础模型,包含输入层、隐藏层和输出层三部分,且层与层之间属于全连接方式,即第i层的任一神经元一定与第i+1 层任一神经元相连。每一层的输出变量y为
式中:x、g、W、b分别表示输入数据、输入数据的激活函数、权重矩阵、偏置向量。模型的优化函数采用增加了正则化项的交叉熵损失函数J
式中:N、K、M分别表示训练样本数量、数据特征数量、神经单元数量,ynk和znk分别表示输出数据的期望值和观测值。
2 医疗电子数据特征学习方法
本文根据医疗电子数据多维异构的复杂特性,提出一种基于深度学习的特征学习方法,分别构建LSTM-AE 模型和DNN 模型对具有时序特性的联合用药数据和多维静态数据进行特征学习,并由此进行患者联合用药不良预后风险预测及其相关因素分析。本文方法的总框架如图2所示,主要包括四部分:1)形成患者联合用药综合表达因子;2)数据融合;3)构建患者医疗电子记录的特征表达向量;4)用药不良预后风险预测及其相关因素分析。
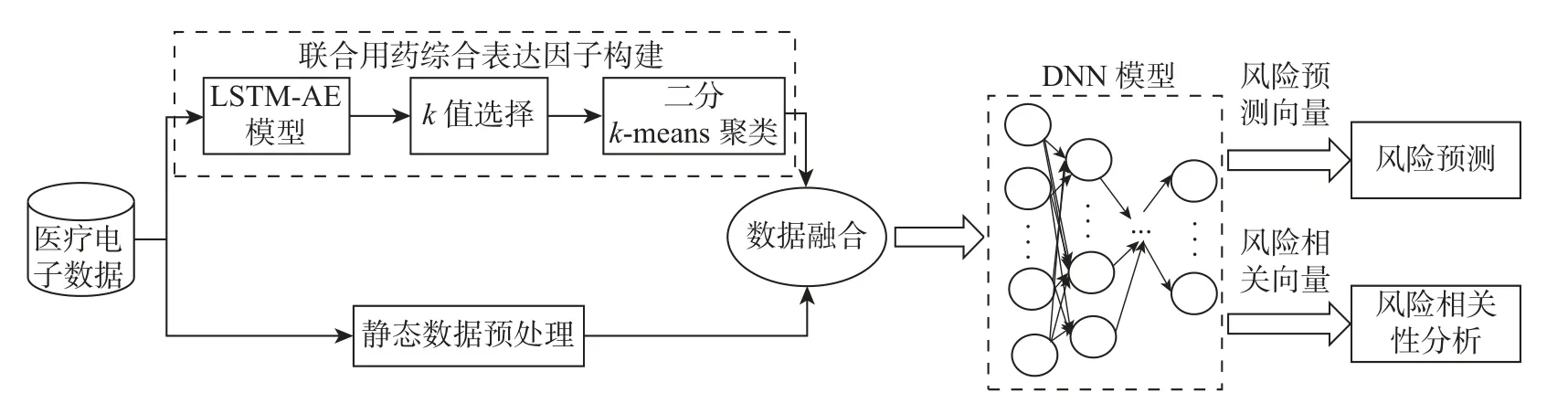
图2 医疗电子数据特征学习方法架构Figure 2 Architecture of feature learning method for medical electronic data
2.1 联合用药综合表达因子
在LSTM-AE 模型对患者联合用药数据进行特征学习的基础上,利用多变量二分k-均值(k-means)聚类方法形成联合用药综合表达因子,主要包括以下几个过程:1)联合用药数据距离度量值计算;2)聚类k值的选择;3)二分k-means 聚类;4)联合用药综合表达因子构建。
2.1.1 计算联合用药数据距离度量值
药品数据的不同取值范围导致取值范围大的数据对联合用药数据距离的影响高于取值范围小的数据,因此在聚类之前对不同药品数据进行归一化,如式(13) 和(14) 所示:
基于欧氏距离构建多变量时序数据的距离度量如下:
2.1.2 聚类k 值选择
采用斯坦福大学Robert 教授提出的gap statistic 方法确定聚类k值,如式(18)~(23)所示:
式中:n表示聚类数,|Cl|表示簇Cl内的数目,d(q,r) 表示q和r之间的距离,Pn表示簇内分散度,B表示模拟数据集的数量。基于蒙特卡罗模拟法构建gap statistic 的步骤如下[36]:
步骤1设定k的取值范围(2,n)
步骤2对于取值范围内的每一个n值,按照均匀分布的原则随机产生与初始样本相同数量的随机样本进行二分k-means 聚类,得到Wn;重复此步骤m次得到sn值;本文中的m取值为100。
步骤3选取Gn −(Gn+1−sn+1) 取值最大的n值作为k的最优值。
2.1.3 二分k-means 聚类
二分k-means 是传统k-means 聚类方法的改进版本,解决了k-means 聚类的局部最优问题,具体步骤如下:
步骤1按照k-means 聚类方法将所有患者作为初始簇划分为两部分。
步骤2计算各个簇的误差平方和(sum of squared errors,SSE),并将值最小的簇继续划分为两部分
步骤3重复步骤2,直至满足聚类数目为k的要求。
2.1.4 联合用药综合表达因子构建
将4.1 节介绍的Medicare 数据集中阿片类药物(opioid,OPI)和苯二氮平类药物(benzodiazepine,BZD) 的联合用药数据进行聚类,根据最优聚类数目将k个组别分别用one-hot 形式表示。比如:如果k值为4,则组别分别为0001、0010、0100、1000。设定组别标识为联合用药综合表达因子,作为患者联合用药数据的综合表达方式。
2.2 数据融合
首先把患者静态数据中的字符串通过离散化映射为one-hot 形式,比如把性别属性中的male 和female 分别映射为01 和10;然后将患者联合用药综合表达因子和其他静态数据进行合并;最后将Medicare 数据集由初始的139 维转换为62 维。
2.3 医疗电子数据特征表达向量
本文针对患者联合用药不良预后风险预测和风险相关因素分析,在数据融合的基础上通过DNN 模型的特征学习过程构建两种医疗电子数据特征表示向量:风险预测特征向量和风险相关特征向量。其中:前者以特征提取的方式形成新特征表达;后者以特征选择的方式构建,表示的是患者属性信息与用药不良预后风险的相关程度,具体描述如下:
1)风险预测特征向量由DNN 模型最后一层隐藏层中所有神经元构建的新特征值组成。DNN 模型基于风险预测特征向量获取对患者用药过量风险的预测结果。
2)风险相关特征向量由DNN 模型中所有神经单元表示的患者原始属性特征权重值求和构成,可用于患者用药过量风险相关性分析。DNN 网络的所有隐藏层的权重值形成一个患者属性特征权重网络,每个节点的权重值由上层节点权重值和边权重值的乘积求和计算所得,其结构如图3所示。
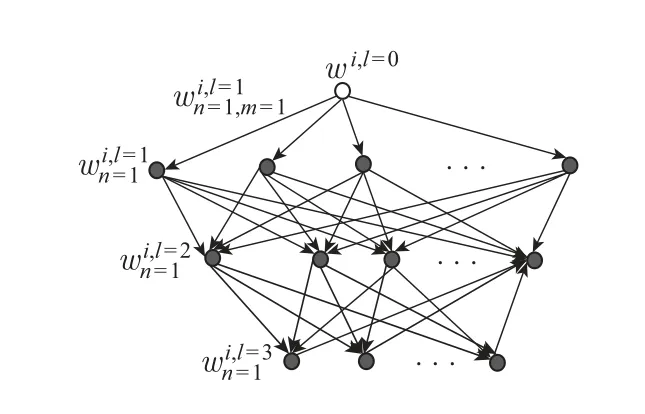
图3 患者属性特征权重网络结构Figure 3 Weight network structure of patient attribute characteristics
在图3中,l、n、m分别表示权重网络的层数、当前网络节点、上层网络节点的顺序号;wi,l=0表示患者属性特征i的初始权重值,所有初始权重值为1;表示第l层第n个节点对应的权重值;表示第l层第n个节点和第l −1 层第m个节点之间的边对应的权重值。具体计算过程如下:步骤1l=1,节点权重值是当下节点和初始节点之间的边所对应的权重值
步骤2l=2,节点权重值是每个上层节点对应的权重值和上层节点与本节点之间边的权重值的乘积和
步骤3l=3,依次类推,特征i在第n个神经单元的最终权重值所有神经单元的最终权重值构成预测相关特征向量。
3 实验与结果
3.1 数据集
本文以最少用过一次阿片类药剂OPI 和抗抑郁药剂BZD 为筛选条件,从美国医疗保险数据集Medicare 中选取10 000 个患者的医疗数据,包括2 708 个确诊为用药过量的患者和7 292 个没有出现用药过量的患者。每个患者具有139 维属性信息,包括两种类型:90 维时序数据类型的联合用药记录,即90 d(天)内对OPI 和BZD 的日用药量;49 维静态数据,包括年龄、性别、用药史等。患者医疗数据的筛选条件为OPI 或BZD 的缺失数值小于20%,缺失值通过患者前后5 d 的平均用药量填补。
选取Medicare 数据集的80% 作为训练集,20% 作为测试集。以训练集中患者的属性数据为输入,患者是否出现用药过度的不良反应为输出,训练网络结构为62:40:20:2 的深度学习DNN 模型,得到模型的权重值和偏置值等参数。
3.2 方法性能度量指标
本文采用轮廓系数(silhouette coefficient,SC)作为MDFL 方法中联合用药模式的聚类性能评价指标,预测准确率(precision rate,PR)、召回率(recall rate,RR)、误判率(false rate,FR)、F1作为患者不良预后和风险预测的性能评价指标。
1)轮廓系数
式中:a(i) 表示簇内不相似度,即样本i到同簇其他样本的平均距离;b(i) 表示簇间不相似度,即样本i到其他簇中所有样本的平均距离。
2)精确率表示准确预测具有用药过量风险的患者数量和预测有风险的患者总量的比值,可以表示为
3)误判率表示被错误预测为有用药过量风险的患者数量和预测为有风险的患者总量的比值,可以表示为
4)召回率表示准确预测为用药过量风险的患者数量占患者总量的比值,可以表示为
5)F1指数综合考量了准确率和召回率,可以表示为
式中:nTP表示准确预测为用药过量风险的患者数量,nTN表示预测为无用药过量风险的患者数量,nFN表示把用药过量风险的患者错误预测为无风险患者的数量,nFP表示把无用药过量风险的患者错误预测为风险患者的数量。
3.3 联合用药模式分析
3.3.1 联合用药模式
本文以患者的联合用药综合表示因子为组别,把每组患者的初始用药数据按照时间点加和求平均,结果如图4~7 所示,其中横轴为x轴,表示以d 为单位的时间点;y轴的上半部分表示不同组别对OPI 的每天平均剂量dOPI,y轴的下半部分表示不同组别对BZD 的每天平均剂量dBZD。由图可得患者的联合用药综合表达因子所对应的具体用药模式如下:
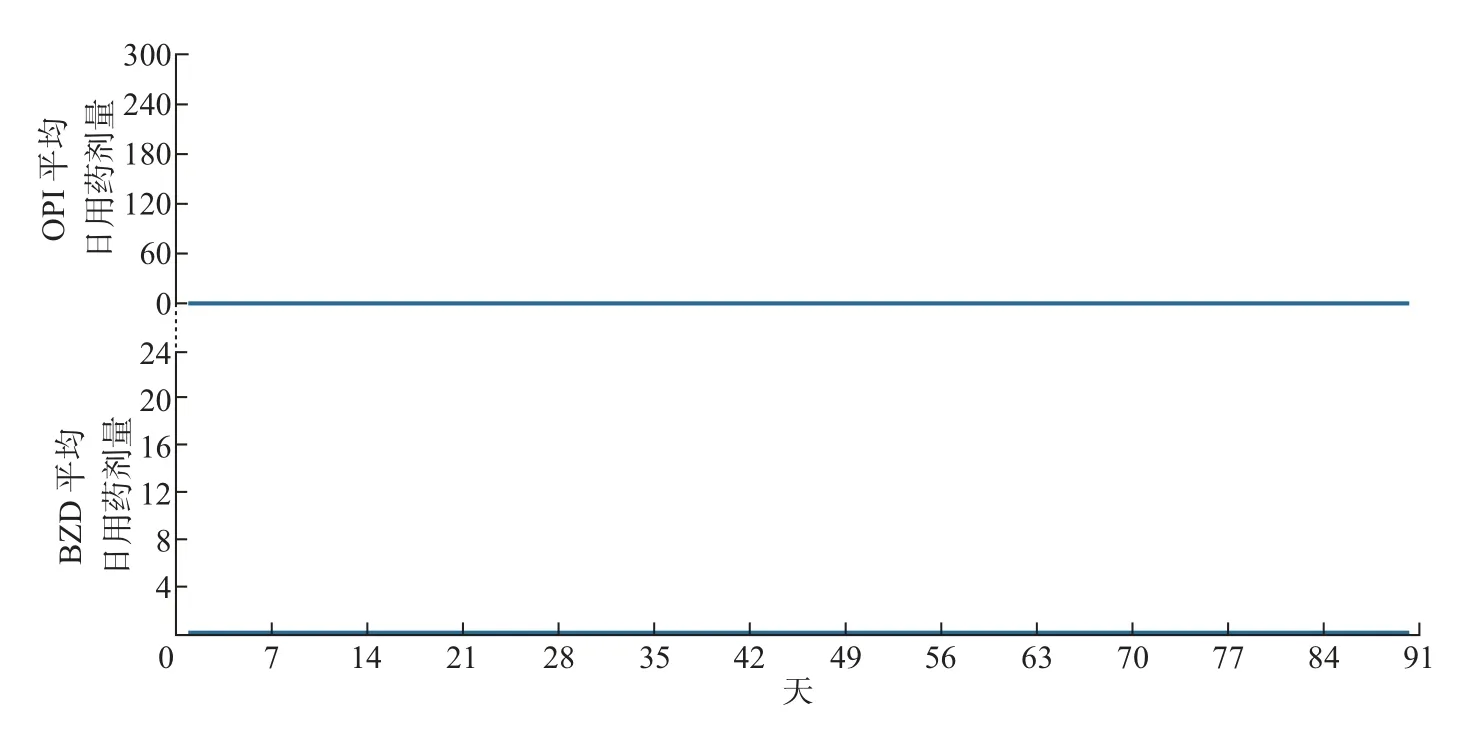
图4 联合用药模式0001Figure 4 Concurrent medical use pattern of 0001
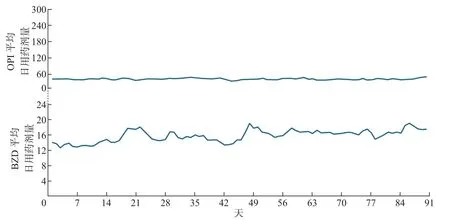
图5 联合用药模式0010Figure 5 Concurrent medical use pattern of 0010
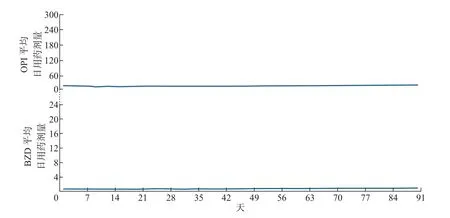
图6 联合用药模式0100Figure 6 Concurrent medical use pattern of 0100

图7 联合用药模式1000Figure 7 Concurrent medical use pattern of 1000
1)联合用药模式为0001,OPI(dOPI~0)和BZD(dBZD~0)的平均日用药剂量持续较低,此组别人数占总数的71.9%。
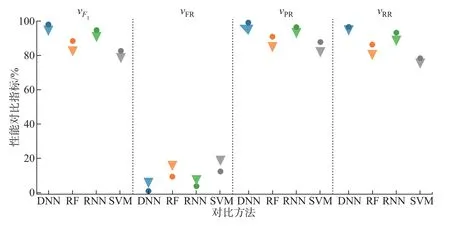
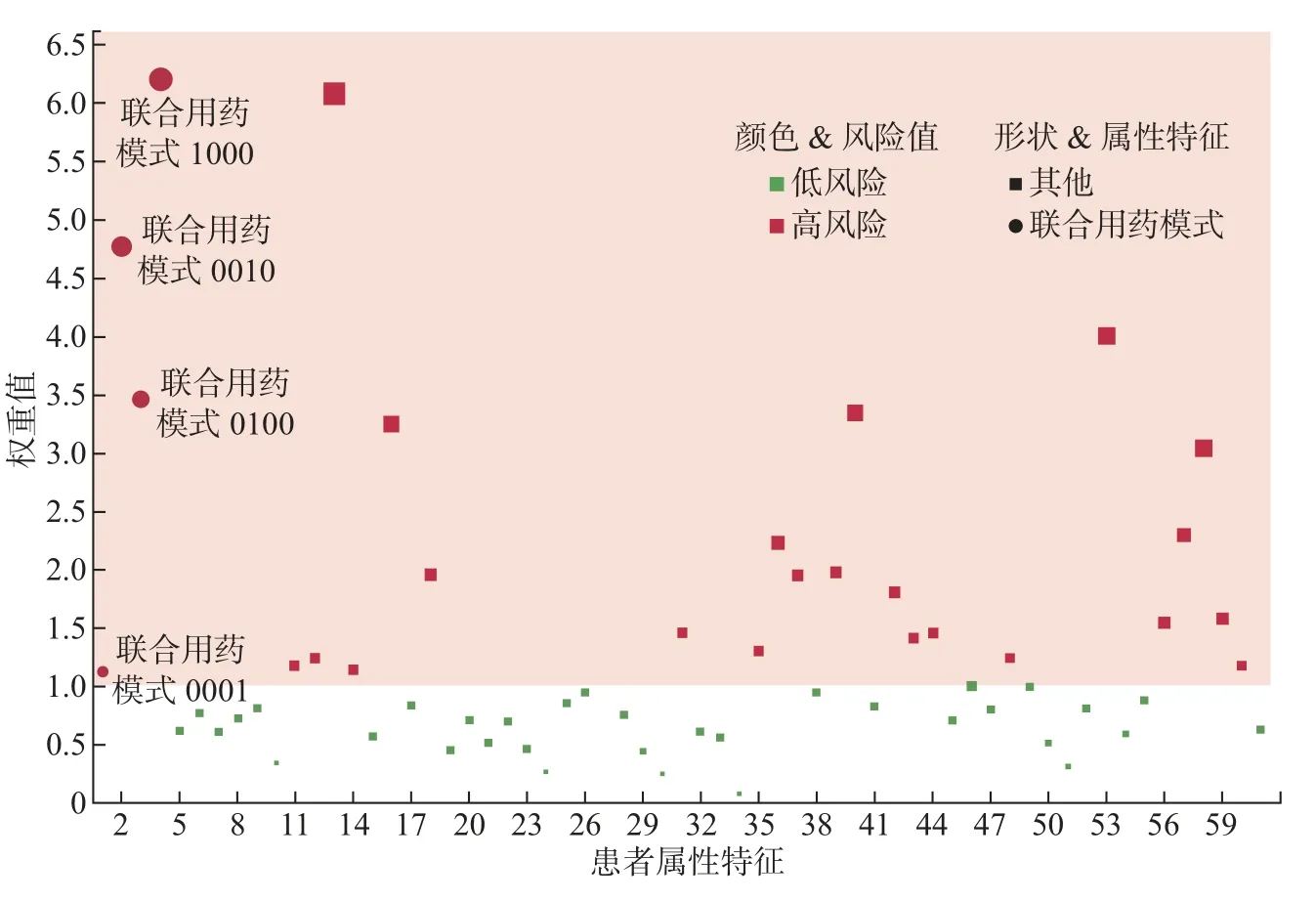
2)联合用药模式为0010,OPI(dOPI<60)的平均日用药剂量较低且BZD(12 3)联合用药模式为0100,OPI(dOPI<1)的平均日用药剂量中等且BZD(dBZD<30)的平均日用药剂量较低,此组别人数占总数的9.8%。 4)联合用药模式为1000,OPI(dOPI>210)和BZD(4 3.3.2 聚类性能分析 本节对MDFL 方法中联合用药模式的聚类性能进行了分析,如表2所示。对比算法包括:自上而下层次聚类法(方法1)、k-means(方法2)、二分k-means(方法3)、k-medoids(方法4)、没有进行归一化的MDFL 方法(方法5),本文提出的方法(方法6)。其中用到的距离度量包括欧氏距离(Euclidean)、泊松距离(Pearson)、最长公共子序列(the longest common subsequence,LCSS)、动态时间规整(dynamic time wrapping,DTW)、实序列编辑距离(edit distance on real sequence,EDR)。 表2 聚类性能结果Table 2 Results of clustering performance 由表2可知:MDFL 方法的vSC明显高于其他方法,至少提高了15%;MDFL 方法的vSC高于没有归一化的MDFL 方法;与其他距离度量相比,基于欧氏距离的MDFL 方法的vSC最高。 基于3.3 节构建的患者风险预测特征向量和风险相关特征向量对患者用药过量的不良预后风险进行了预测,并探究了患者的不同属性特征和用药过量风险的相关性。 3.4.1 不良预后风险预测 用不同方法对Medicare 测试集中患者是否出现用药过量风险进行预测,结果如图8所示。对比方法分别包括:本文方法中使用的DNN、随机森林(random forest,RF)、RNN、SVM。不同颜色表示不同预测方法,圆形和三角形分别表示使用和未使用联合用药综合表达因子应用模式的预测结果。由图8可知:这4 种方法在使用联合用药综合表达因子应用模式后的F1、vPR、vRR都高于一般应用模式的预测结果,提高的幅度为5%~10%,其中DNN 的预测指标最高;vFR低于一般应用模式,降低的幅度为3%~5%,其中DNN 的结果最低。由此可见:联合用药综合表达因子应用模式把复杂多维的联合用药数据转换为综合表达因子,有效提高了对患者用药过量的预测准确率,优化了患者联合用药的不良预后风险预测。在实际临床应用中,医生可以基于患者的历史用药数据进行不良预后风险预测,并根据预测值调整不同药品的用药量,从而避免患者用药过量的问题。 图8 患者联合用药的风险预测结果Figure 8 Risk prediction in patients with concurrent medical use 3.4.2 不良预后风险相关因素分析 本文基于3.3 节中患者属性特征权重网络获取患者不同初始属性特征的权重值,绝对值越大则表示与患者不良预后风险的相关程度越大,患者联合用药综合表达因子的权重值越大则表示此种联合用药模式下的患者出现用药过量的风险就越大。患者不同属性特征的权重值分布如图9所示,正方形代表联合用药综合表达因子,圆形代表其他属性特征;绿色代表低风险,红色代表高风险。由图9可知:联合用药模式为D 的患者出现用药过量的风险最高,其次为B 和C,A 的风险最低。医生可以根据此分析结果调整患者的用药策略,有效降低用药过量的风险。 图9 患者风险预测的重要因素分析Figure 9 Important factors analysis for patients’ risk prediction 本文提出一种基于深度学习的医疗电子数据特征学习方法,并对患者联合用药的不良预后进行预测和相关性分析。本文提出的方法采用深度学习模型,相比已有研究方法,能够更有效地提取患者医疗数据的数据特征,从而得到更优的患者联合用药模式分析结果和更高的患者联合用药风险预测准确率。同时,本文方法在患者联合用药风险预测中以联合用药综合表达因子的形式表征患者的联合用药使用情况,充分利用了患者的联合用药数据。在医学领域的实际应用中,本文方法可以准确评估患者联合用药的风险程度,并有效辅助医生对患者的临床联合用药处方进行优化。目前,本文只针对两种用药的联合用药数据进行了分析,在以后的研究中会增加联合用药的数量,覆盖更多的临床用药应用场景。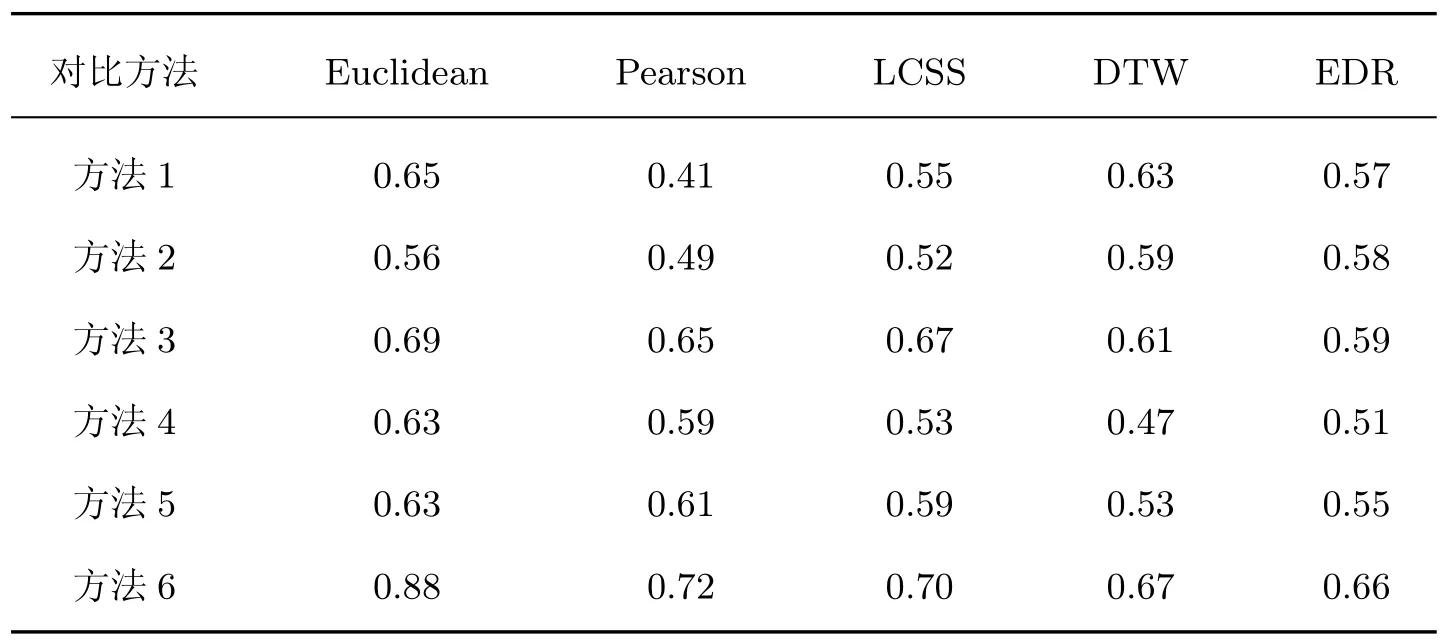
3.4 不良预后风险预测及其相关因素分析
4 结 语
猜你喜欢
中老年保健(2022年4期)2022-08-22中老年保健(2021年5期)2021-08-24当代陕西(2020年17期)2020-10-28铁道通信信号(2019年6期)2019-10-08人大建设(2018年5期)2018-08-16基层中医药(2018年3期)2018-05-31基层中医药(2018年3期)2018-05-31雷达学报(2017年6期)2017-03-26应用科技(2015年5期)2015-12-09电子设计工程(2015年6期)2015-02-27
