
一种融合图结构的时空轨迹相似性查询算法
2023-03-29 12:31熊淑怡曹竞之高嘉媛
应用科学学报 2023年1期
熊 伟,熊淑怡,曹竞之,陈 浩,高嘉媛
国防科技大学电子科学学院,湖南 长沙 410073
随着带有全球定位系统(globe position system,GPS)传感器的移动设备的广泛普及和飞速发展,轨迹数据的生产、获取、共享越来越方便;同时随着时间的推移,轨迹数据的规模也越来越庞大。从本质上来看,轨迹数据是非结构化的数据,来源多样,关系复杂,主要包括人类活动轨迹数据、交通轨迹数据、动物活动轨迹数据和自然现象轨迹数据[1],其中前两类轨迹数据与人类生产生活关联最为紧密,因此涌现出了许多与这两类轨迹数据相关的研究成果[2]。以手机基站定位数据、社交网络签到数据为代表的人类活动轨迹数据,能够按时间顺序形成人员大致的移动情况,蕴含丰富的潜在信息。如移动运营商在疫情期间推出的个人行动轨迹查询,就是用手机基站定位数据,构成用户的移动轨迹,辅助疫情溯源工作;如Twitter、Facebook 等许多社交软件提供了轨迹查询和分享的功能,为用户提供兴趣点(point of interesting,POI)推荐、个性化旅游路线规划、相似用户查询等功能。以出租车轨迹数据、船舶轨迹数据为代表的交通轨迹数据,其覆盖区域广,时间跨度大,位置精度较高。这些数据不仅能反映所处区域的交通状况,而且有助于找出重点拥堵区域,提升交通运行效率。围绕时空轨迹数据,学术界和工业界开展了大量研究工作,包括如何解决轨迹聚类、轨迹分类、轨迹异常检测和轨迹预测等一系列问题[3],而这些问题的核心是度量轨迹之间的相似性[4]。
作为这些分析应用的基础,如何对不同类型的轨迹进行相似性度量是非常重要的。在人类活动轨迹和交通轨迹数据中,常常会出现不同的空间约束如道路、禁航区。针对这些轨迹数据的结构特征,可以将轨迹看成一个带有节点和边的图结构中的一条路径,使图中的节点与轨迹点对应,每个节点之间包含一段时间间隔,如图1所示。若两条轨迹在相同时间内通过相邻节点的数目越多,则认为这两条轨迹的相似性越高。引入图结构进行轨迹相似性度量,一方面可以更多地关注轨迹的拓扑相似性,另一方面可以减少用于相似性度量的轨迹点距离计算量。文献[5]对图结构下的轨迹相似性算法进行总结后发现:如果轨迹中节点的数量为n,那么现有研究中大部分算法的计算复杂度为O(n2),而只有少部分存在诸如两条轨迹长度相同等限制要求的算法,其计算复杂度为O(n),于是提出了一种计算复杂度也为O(n)、兼容不同长度轨迹的相似性度量方法。然而,该方法牺牲了准确性,只能近似评估相似性大小,并不适用于实际情况。针对以上问题,本文提出一种同步考虑空间维和时间维的轨迹相似性度量方法,能在保持计算复杂度为O(n) 的前提下,提高时间鲁棒性和度量准确性。
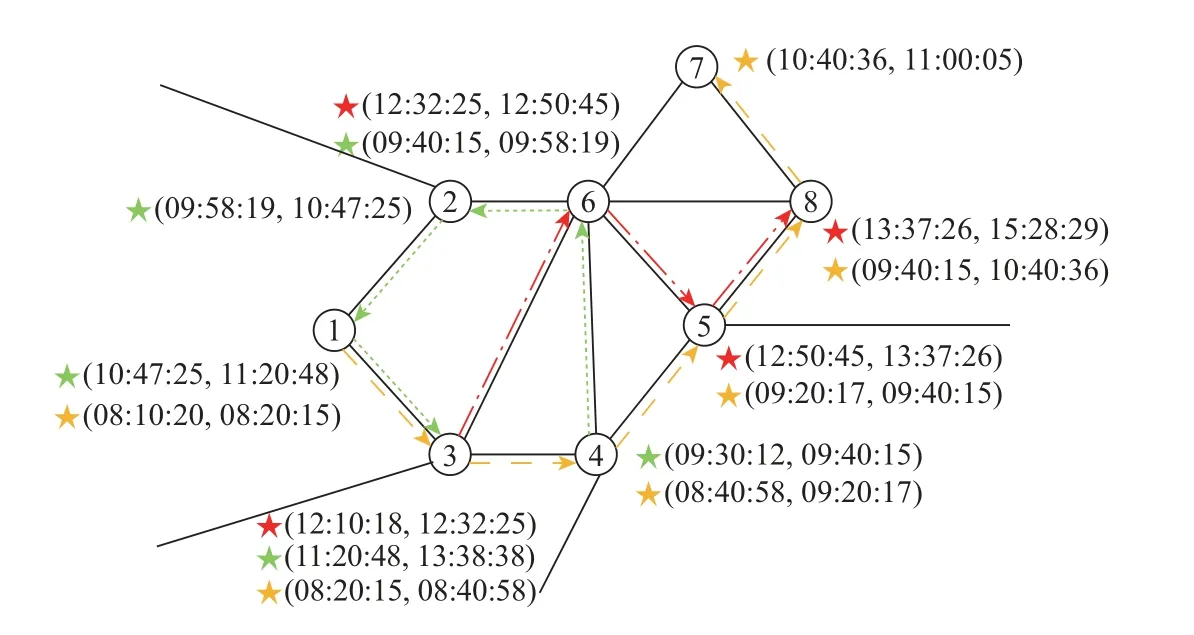
图1 图结构的时空轨迹示例Figure 1 Example of spatio-temporal trajectory with graph structure
较多研究[6-11]用基于R-tree[12]的方法在轨迹点或轨迹段上建立轨迹索引。若待查数据集中包含大量的轨迹,就会增加所占用的空间和搜索的时间。此外,典型的搜索策略以查询点为扩展中心来检索候选轨迹,直至满足某个停止条件。当给定查询轨迹较长且包含较多的轨迹点时,各查询点之间存在大量重叠的搜索空间。在这种情况下,相同的数据点可能被反复探测,直到在增量搜索的扩展过程中最终确定候选集为止。针对上述存在的问题,本文基于时空轨迹相似性度量方法设计了一套高效的相似查询框架,给定查询轨迹,并从轨迹集中返回相似性最高的前k条轨迹;然后提出了基于倒排索引和时间维过滤的索引结构,同时应用空间距离上界对候选轨迹进行剪枝,提高了查询效率。
1 基本原理
1.1 轨迹相似性度量
传统的轨迹相似性度量大多以距离为标准,分开考虑空间维或时间维特征的相似性。文献[13]将轨迹相似性度量方法分为基于空间维和基于时空维两种类型,对比分析了各自特征,并对这些相似性度量方法进行实验对比;文献[14]设计了一种改进的Jacard 距离,将单独计算空间维和时间维的距离相乘,得到最终的时空相似性大小;文献[5]提出了一种应用在图结构中的时空轨迹相似性度量方法,将节点间的最短路径视为轨迹点间的空间距离,在计算点与点之间的相似性时同时考虑了空间维和时间维。上述方法虽然能妥善解决相似性计算问题,但其中有的方法将空间维和时间维属性独立考虑,不能比较准确地反映时空相似性;有的方法则以提高计算效率为优化目标,牺牲了一定的准确性,因而不适用于许多与时间相关的应用场景,如出租车推荐等。
1.2 轨迹相似性查询
轨迹相似性查询是指给定查询轨迹,从轨迹集中找出与查询轨迹最相似的前k条轨迹。轨迹相似性查询主要包含两个步骤:
步骤1根据应用需求设计一个相似性度量函数。
步骤2设计一种有效的查询算法,查询相似性高的轨迹。
近年来,学界对轨迹相似性查询进行了大量的研究工作[7,9,15-16]。文献[17]定义了空间维和时间维的距离,并采用一种近似方法减少计算量,提升了查询效率。文献[5]提出了一种结合维诺图的近似搜索方法,也能提高查询效率。文献[18-19]在文献[5]的基础上提出了一种基于网格索引的查询方法,首先对网格单元进行聚类找出具有代表性的轨迹,从而将索引压缩;然后在查询阶段将轨迹分为不同的分区进行空间查询,缓解搜索空间重叠导致计算量增大的问题。上述方法虽然有效解决了相似查询的问题,但是不能同时兼顾效率和准确性。
1.3 数据模型
定义1加权无向图
一个加权无向图是由顶点的有穷非空集合和顶点之间边的集合组成的,可以表示为G=(V,E,w);其中G表示一个图,V是图G中顶点的集合,e ∈E是图G中边的集合,每一条边就是一组顶点对(u,v),E ⊆{{u,v} ⊆V|u /=v},且每条边具有权值w。一条迹是由一个可重复的顶点序列组成,使得(ui,ui+1)∈E,1 ≤i≤N −1;一条路是没有重复节点的迹。一条迹或路的长度为其所包含的边的权值之和,可用d(u,v) 表示u,v两点之间的最短路径长度。
定义2时空轨迹
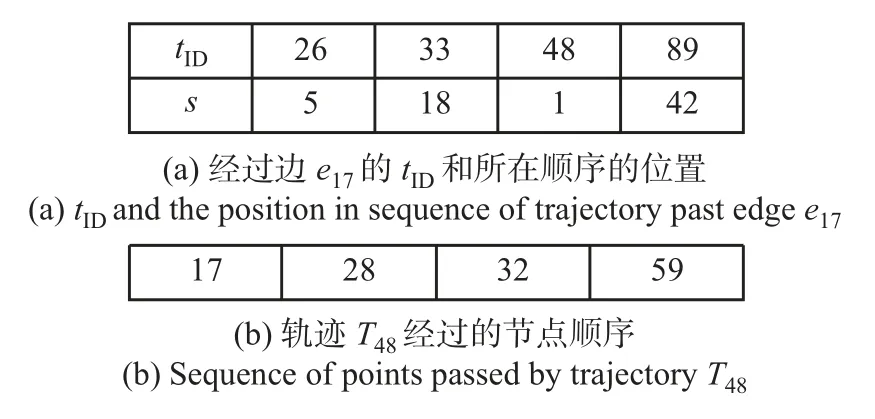
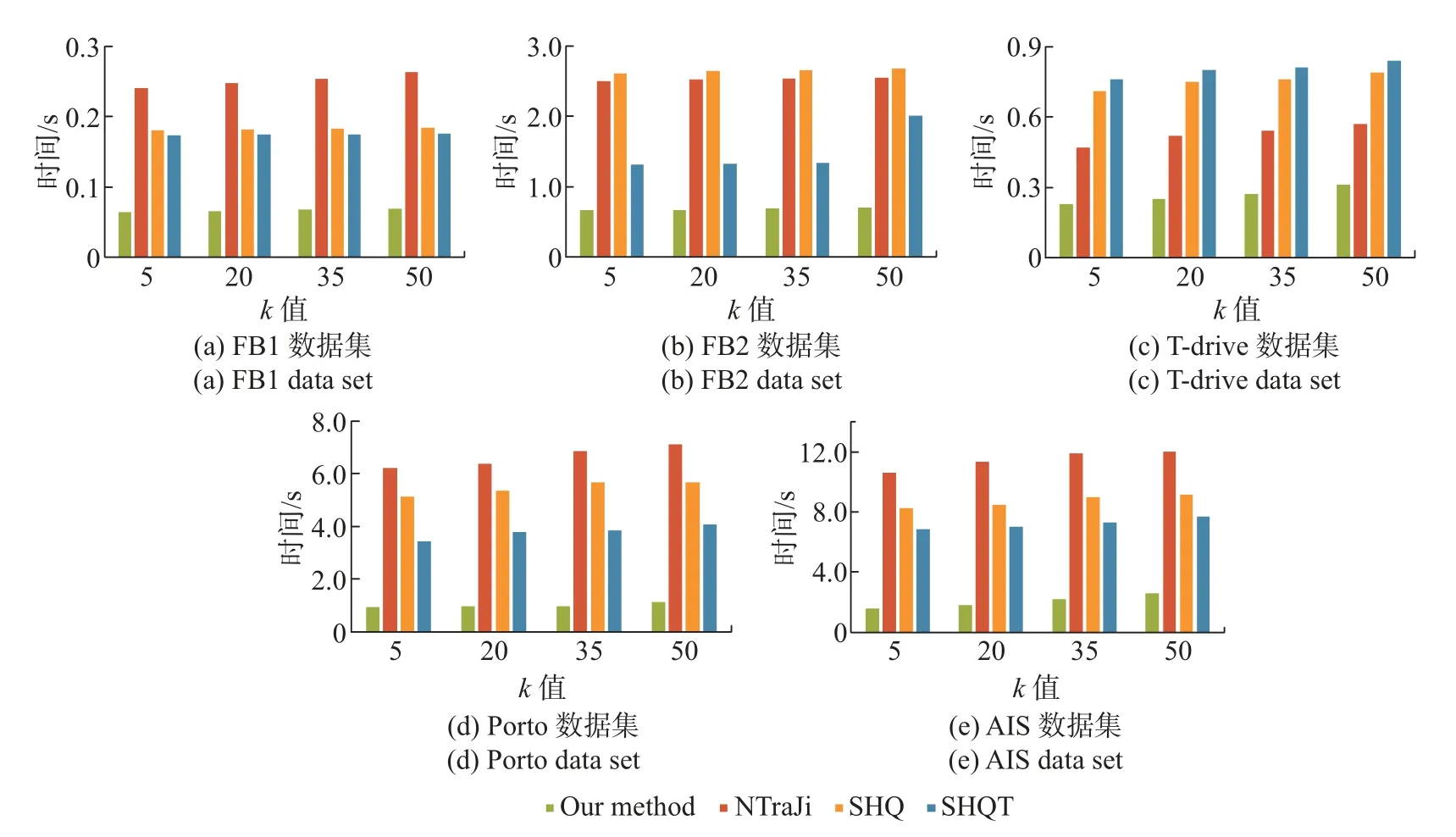
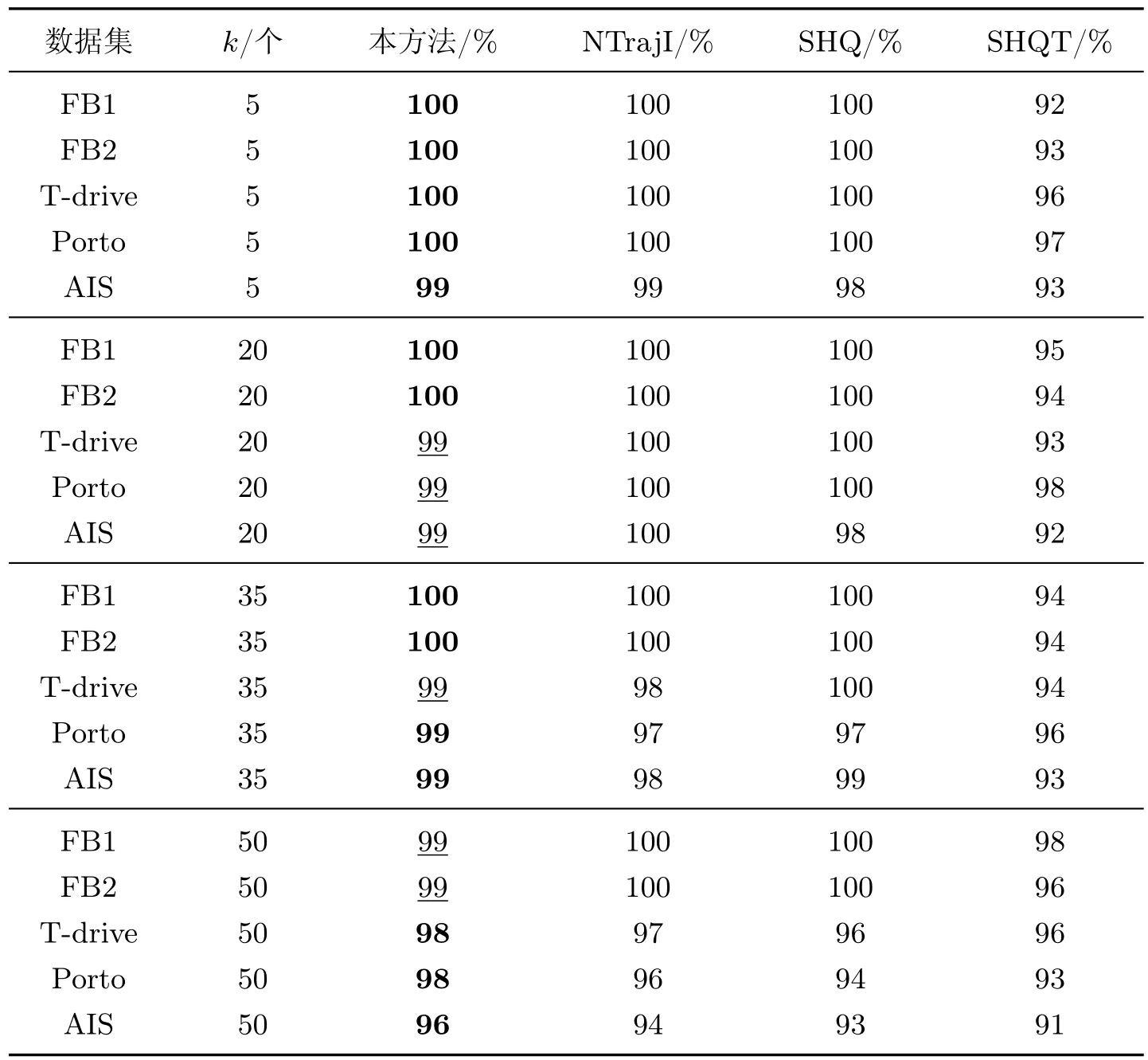
轨迹集Γ中的一条时空轨迹T是由移动对象在增量时间内的一系列轨迹点组成的,记为T=(v1,t1),(v2,t2),···,(vn,tn);其中vi ∈V表示轨迹点,即图G中的顶点;ti=[tis,tie]表示该点所包含的时间间隔,满足tis,tie ∈Z,tis 定义3时空轨迹相似性查询 给定一条查询轨迹Q和轨迹集Γ、相似性度量函数SIM 和参数k,时空轨迹Top-k相似查询就是要从轨迹集中找到与查询轨迹最为相似的前k条轨迹Γ′ ⊆Γ且|Γ′|=k,当S ∈Γ′、P ∈Γ −Γ′时,满足 空间距离是对两条轨迹之间空间位置关系的一种度量,可以反映两条轨迹的邻近或分离程度。然而,时空轨迹不仅是空间维中的空间目标,还是具有时间维的对象[20]。时空轨迹间的相似性程度既要度量其空间上的距离,也不可忽视时间上的同步性判别。对于时间区间不相交的两条轨迹,无论在空间上的位置多么接近,其时空距离都不可能相近。 时空轨迹相似性度量主要依赖于轨迹间的距离定义,而轨迹间的距离可用轨迹之间的匹配程度表示,但不同的轨迹匹配度量方法对轨迹之间的匹配程度有着不同的解释[21]。本文针对轨迹的拓扑结构特征,将轨迹用带有节点和边的加权无向的图结构表达,并为图结构添加空间和时间属性,进而提出了轨迹时空-拓扑结构相似性度量算法。 要设计轨迹相似度量,首先需要明确其含义。本文认为两条轨迹在相同时间段内经过相同顶点的数量越多,表明这两条轨迹的相似性越高。轨迹相似度函数SIM 将两条轨迹Q和T作为输入,经过距离计算输出其相似度结果,通常在0~1之间,即满足条件 这3 个要求分别对应非负性、对称性和自反性,也是线性空间中各种通用相似性度量的一般性要求。在此基础上,先分析点与点之间的相似性,再计算轨迹的持续时间和空间上的距离,最后综合时空距离计算结果来确定轨迹间的相似性。 定义4轨迹点-轨迹点的时空距离 给定两个轨迹点(u,tu)、(v,tv)和时间段s,tu=[tus,tue],tv=[tvs,tve],其时空距离D(u,v)可定义为 式中:distS(u,v) 表示为两点间在图G上的最短距离经过归一化后的结果,在这里假设已知所有节点间的最短距离;distT(u,v,s) 表示为两节点之间共同的时间长度,分别表示为 用ξ(x)=exp{−x}表示将距离函数度量转换为一个标准的近似值,也就是实现空间域和时间域上距离的转换,即ξ(distS(u,v))=exp{−distS(u,v)} ∈(0,1];时间维上的距离|tu ∩tv ∩s|表示轨迹点u、v和时间段s的共同时间长度。 定义5轨迹点-轨迹时空距离 给定点(u,tu)、一条轨迹T=(v1,t1),(v2,t2),···,(vn,tn) 和时间段s,其时空距离D(u,T) 可定义为 式中:distS(u,T) 和distT(u,T) 分别表示点u到轨迹T的最短空间维距离和最短时间维距离,具体表示为 式中:vi ∈T。同理给定两条轨迹Q和T,可以定义轨迹-轨迹时空距离为D(Q,T)。 定义6时空轨迹相似性 给定两条轨迹Q={(u1,t1),(u2,t2),···,(um,tm)}、T={(v1,t1),(v2,t2),···,(vn,tn)}以及时间段,其时空相似性可定义为 式中:|Q|和|T|分别表示两条迹的长度,即包含的节点数目;|s|表示时间段s的时间长度,目的是将时空轨迹距离进行归一化处理。同时根据式(5) 和(6) 进行归一化处理,能够得出时空轨迹相似性函数满足式(2) 提出的条件。 引理1定义6 的时空轨迹相似性满足条件(2),即 0 ≤SIM(Q,T,s)≤1 SIM(Q,T,s)=SIM(T,Q,s) SIM(Q,T,s)=1≡Q[s]=T[s] 证明 1)由定义4 可知:当两轨迹点(u,v) 和时间段s之间在时间维上的距离distT(u,v)=0时,其轨迹点-轨迹点距离D(u,v)=0。由此推广到定义6 可知:当两条轨迹Q、T和时间段s在时间维上没有交集时,其时空相似性SIM(Q,T,s)=0;当且仅当两条轨迹Q、T和时间段s上经过相同节点且在每个节点上的时间完全重合时,其时空距离D(Q,T)=1,又因为定义4 对空间维和时间维上的距离进行了归一化处理,因此满足条件 0 ≤SIM(Q,T,s)≤1 2)在图结构中,两节点之间的最短路径d(u,v)=d(v,u),(∀u,v ∈V),推广到定义6 中可得到 SIM(Q,T,s)=SIM(T,Q,s) 3)充分条件 假设SIM(Q,T,s)=1 且Q[s]/=T[s],则轨迹Q[s]和T[s]包含的节点不会完全相同。由定义4 可知总会存在distS(u,v)=d(u,v)>0;同时在假设中有Q[s]/=T[s],即有两条轨迹在时间段s内总会存在经过相同节点而时间不重合的情况,因此由定义6 可知两条轨迹间距离SIM(Q,T,s)<1。 4)必要条件 假设Q[s]=T[s],则在时间段s内,轨迹Q、T经过相同的节点,于是有distS(u,v)=1;同时,在时间段s内,所有轨迹点之间的距离经过求和后再归一化,最终得到 SIM(Q,T,s)=1 引理1 的证明可以验证所提时空轨迹相似性满足设计条件,下面分别给出引理2~4 作为相似性查询优化的基础。 引理2给定两条轨迹Q、T以及时间段s、t,且timeT=s ⊆t,则有 |t|SIM(Q,T,t)=|s|SIM(Q,T,s) 证明由定义6 可以得到 引理3给定3 条轨迹Q、T、P和时间段q,且有q ⊆TimeQ,则有 SIM(Q,P,q)+SIM(T,P,q)≤1+SIM(Q,T,q) 证明将定义6 代入引理3 可得 经进一步推导可得 已知|q|−|q ∩t|≥0,以上不等式可以化简为不等式两端分别去掉|q|和|q ∩t|后不等式是否成立。由定义6 可知不等式两端之间大小的比较最终归结于3 条轨迹之间在时间维上是否有交集,下面将分成4 种情况来讨论: 1)当|q ∩t|=∅和|q ∩p|=∅时,不等式两端均为0,不等式成立。 2)当|q ∩t|/=∅和|q ∩p|/=∅时,满足条件 1+distS(u,v)≥distS(x,v)+distS(u,x),不等式成立。 3)当|q ∩t|=∅和|q ∩p|/=∅时,化简可得D(ui,xh)≤|q|,不等式成立。 4)当|q ∩t| /=∅和|q ∩p|=∅时,化简可得|q ∩t| < |q|+(1+D(ui,vj)),不等式成立。 引理4给定两条轨迹Q、T和时间段s,则定义5 关于D(Q,T) 的计算复杂度为O(|Q||T|)。 证明 根据引理1 的证明,可知两轨迹点之间的距离D(u,v)=D(v,u),因此在定义6 时空轨迹距离的计算中,两轨迹点之间的距离只需计算一次即可,最终可得计算复杂度为O(|Q||T|)。 在Top-k相似查询中,一是要考虑时间属性,导致算法的空间剪枝能力较弱;二是要处理海量轨迹数据,使得算法存在计算效率低的问题。为了提升Top-k相似查询效率,支持时空轨迹相似性度量方法的轨迹相似性查询,本文首先在空间维对轨迹建立基于边的倒排索引,用Delta 编码[22]对排序后的结果进行压缩;其次在时间维进行过滤,减少计算量;最后定义空间距离上界对候选集进行剪枝。 定义7基于边的倒排索引(edge based inverted index,EII) 给定图G中一条边e ∈E,其倒排索引存储轨迹集Γ中所有轨迹编号及其顺序{tID,s}。其中,tID代表轨迹编号,s代表轨迹经过的节点顺序。 除了在索引中存储轨迹数据外,还要在计算轨迹间相似度时确定轨迹节点(边)的位置,于是采用两个列表分别存储tID和s中的信息。如图2所示,假设轨迹T26、T33、T48、T89都经过了一条边e17,并且在其轨迹中的顺序分别为第5、18、26、42 位,则边e17的倒排列表按照tID的顺序可表示为{{26,5},{33,18},{48,1},{89,42}}。 图2 索引和轨迹的存储结构Figure 2 Storage structures of index and trajectory 由于倒排索引和轨迹编号都由整数表示,因此可以参考Delta 编码[22]将排序后的列表压缩,把图2(b) 中的轨迹排序和编码后转化为{17,28-17,32-28,59-32}={17,11,4,27}。 根据轨迹相似性的定义,在时间域内不相交的两条轨迹相似性定义为0,其时空相似度最高不超过0.5,因此这些轨迹就不需要考虑到候选集中。对于查询轨迹Q ∈Γ和待查轨迹T ∈Γ,分别获取两条轨迹的起点和终点的时间间隔,生成整条轨迹的时间间隔tQ和tT。若tQ ∩tT=∅,则可以对轨迹T进行剪枝处理;同理,根据这一处理能够对倒排列表中的轨迹按照时间属性如起始时间进行排序。根据时间过滤可以生成候选轨迹数据的倒排列表,有效降低计算时间。 传统的相似查询算法会计算查询轨迹与数据集中每一条轨迹之间的相似性,返回前k个结果,这就会造成高计算量和高I/O。因此,提出一种有效的剪枝方法来减少计算量。 通过轨迹索引EII,可以快速得到查询轨迹Q、T之间的公共节点和公共边,并将距离上界定义为其公共节点的数量之和 经归一化处理得到 由式(5) 可以得知:由于引入了归一化处理,当点在该轨迹上时,其空间距离为0,而空间相似性为1。计算轨迹集中的轨迹与查询轨迹之间的距离上界,以距离值排序得到候选列表;然后根据排序后的候选列表按时间维过滤,得到最终的相似性结果并更新Top-k结果列表。相似性查询算法如下。 本文同时采用合成轨迹数据和真实轨迹数据进行实验。 3.1.1 合成轨迹数据 FB[23]数据1&2 是根据Stanford Network Analyses Project 提供的社交网络数据生成的合成轨迹数据,由文献[18]提供。 3.1.2 真实轨迹数据 真实轨迹数据包含以下3 种数据: 1)T-drive[24]数据 微软亚洲研究院公开的北京地区2008-02-02 到2008-02-08 内10 357辆出租车的轨迹数据。 2)Porto[25]数据 包含Porto 地区一年内422 辆出租车生成的170 多万条轨迹数据。 3)AIS[26]数据 采用美国海事局自动识别系统记录的船舶轨迹数据,选取了2019年UTM Zone 10 区域中连续一个月的数据,包含了4 653 条船舶的轨迹数据。 对于真实轨迹数据,首先进行数据预处理,将每个GPS 定位点解释为一个顶点;然后用k-means 算法对这些顶点进行聚类,使每个聚类中心点生成图中的一个顶点。如果在连续的时间间隔内至少有一条轨迹经过两个顶点,那么将两个顶点用一条边连接起来,其间的距离表示边的权值。数据集详细信息如表1所示。 表1 实验数据集Table 1 Experiment datasets 实验环境为Ubuntu20.04 LTS 操作系统,Intel®Xeon®E5-2620 v4 CPU 2.10 GHz,512 G内存,编程语言采用C++11,GCC 9.30。 为评估本文方法的各项性能,选取一些最新方法作为基准进行比较:1)文献[5]提出的基准方法NTrajI,采用区间树对轨迹数据建立索引;2)文献[5]提出的近似查询方案SHQ/SHQT,基于维诺图和轨迹的启发式算法缩小图的规模和轨迹长度。 实验验证部分将主要从索引建立时间、查询效率和查询有效性三方面评估本文提出的算法。 3.3.1 索引建立时间 表2展示了不同索引方法的构建时间,可以发现本文方法与NTrajI 方法相比,其索引建立时间仅为2%~25%,且在大规模数据集上的优势更为明显;同SHQ 和SHQT 两种方法相比,也有一定的优势。在FB1 数据集上,本文方法的索引构建时间比SHQ、SHQT 方法的索引构建时间略长,在其他数据集上均比SHQ 方法短,在FB2、AIS 数据集上则略长于SHQT方法。由于这些数据集轨迹数量较少,本文方法的优势还不太明显;但在更大规模轨迹数据集上,本方法的优势就比较明显了。 表2 索引构建时间Table 2 Time cost for building indexs 3.3.2 查询时间 本文从FB1,FB2 数据集中随机挑选100 条轨迹作为查询数据集,从T-drive、Porto、AIS数据集中随机挑选1 000 条轨迹作为查询数据集,设定不同的查询数量值,如k为5、20、35、50,并与对比方法进行比较来衡量本文方法的查询效率,计算其查询时间如图3所示。 图3 查询时间比较Figure 3 Comparison of query time 从图3中可以发现:本文方法在所有数据集中的查询性能均优于其他3 种对比方法,并且随着查询数量k值的增加,查询性能的提升趋势更加明显,表明本文方法的索引机制提高了查询处理效率。从实验数据来看,当k值增加时,其他方法的查询耗时均会增加,而本文方法仅在T-drive 和AIS 数据集上略有增加,基本保持了稳定的查询性能。 3.3.3 有效性 为验证本文方法的有效性,基于文献[5]采用相似性系数(similarity sore ratio,SSR)和F1-measure 进行评价。 定义8相似性系数 τ1为传统未建立索引优化的计算方法得到的Top-k查询准确结果集,τ2为本文方法和其他对比方法得到的结果集,则这两个结果集的相似性系数为 表3展示了实验结果,可以看出随着k值的增加,本文方法依然能够保持较高的相似性,特别是在大规模数据集上表现出了较强的鲁棒性。 表3 不同数据集下的SSR 值Table 3 SSR under different datasets 时空轨迹相似性查询是时空轨迹数据挖掘的关键问题之一。本文面向受限时空轨迹,提出了基于图结构的时空轨迹相似度量方法;以相似查询为目标,提出了融合时间维过滤+距离上界的倒排索引框架,提高查询性能。在合成轨迹数据和真实轨迹数据上进行验证,得到了较好的效果。以后将考虑融合位置语义信息,结合POI 数据进行轨迹预测,并进一步优化相似查询算法。1.4 轨迹度量模型
2 轨迹索引与查询
2.1 基本思想
2.2 轨迹索引框架
2.3 时间维过滤
2.4 距离上界

3 实验
3.1 实验数据与环境设置
3.2 对比方法
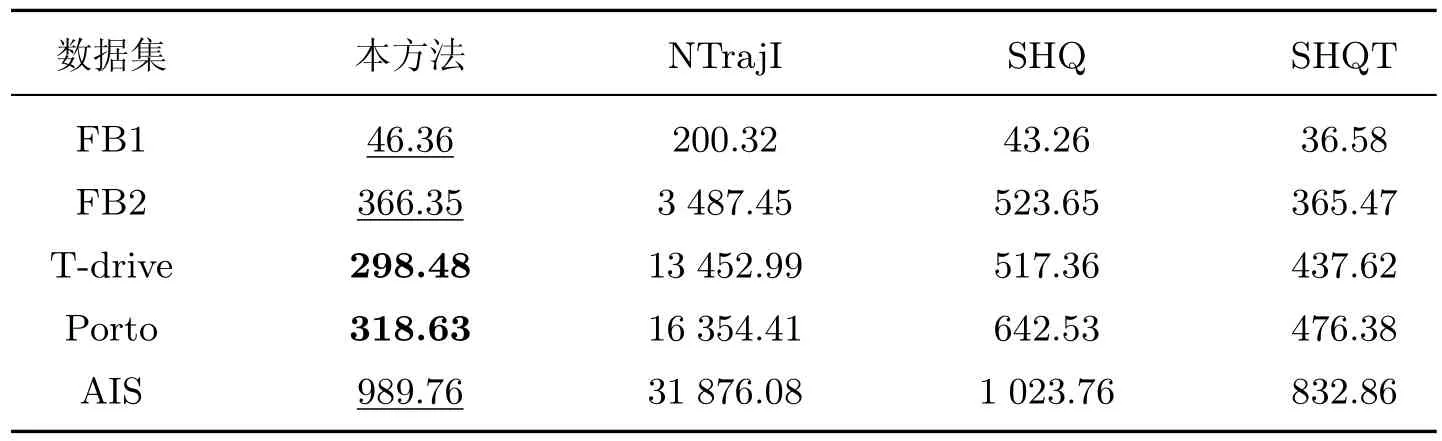
3.3 评估指标与结果
4 结 语
猜你喜欢
数学物理学报(2022年5期)2022-10-09
上海文化(文化研究)(2022年3期)2022-06-28
四川党的建设(2022年8期)2022-04-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
小学生学习指导(低年级)(2020年11期)2020-12-14
河北画报(2020年8期)2020-10-27
数学年刊A辑(中文版)(2019年3期)2019-10-08
作文大王·低年级(2018年10期)2018-12-06
浙江大学学报(工学版)(2016年2期)2016-06-05
小猕猴智力画刊(2016年5期)2016-05-14
