
基于精准通信建模的脉冲神经网络工作负载自动映射器
2023-03-24 13:25华夏朱铮皓徐聪张曦煌柴志雷陈闻杰
计算机应用 2023年3期
华夏,朱铮皓,徐聪,张曦煌*,柴志雷,2,陈闻杰
(1.江南大学 人工智能与计算机学院,江苏 无锡 214122;2.江苏省模式识别与计算智能工程实验室(江南大学),江苏 无锡 214122;3.软硬件协同设计技术与应用教育部工程研究中心(华东师范大学),上海 200062)
0 引言
以脉冲神经网络(Spiking Neural Network,SNN)[1]为代表的类脑计算在神经科学领域有着重要意义。目前针对SNN的很多研究采用软件模拟方式[2-3],比较成熟的类脑仿真器如NEST(NEural Simulation Tool)[4]、Brain2[5]、Brian2GeNN(links Brian to Gpu enhanced Neuronal Network)[6]和CARLsim[7]等精确度高、灵活性强,因此应用广泛。在实现平台方面,由于SNN 本身具有明显的分布式计算特点,且达到一定规模的SNN 才能展现出较强的智能水平,因此搭建大规模分布式平台是构成类脑计算平台的主流方式。
专用的类脑计算平台[8-10]理论上能够取得更高的性能与功耗指标,但是当专用计算平台和所运行的SNN 工作负载不匹配时,计算能效会大打折扣,甚至还不如通用计算机系统[11]。因此,针对特定的SNN 工作负载,如何找到它在对应分布式计算平台上的最佳映射是类脑计算领域的重要问题。
针对以上问题,刘俊秀等[12]提出一种动态优先级仲裁策略以解决SNN 硬件实现系统上的脉冲传输负载不均衡问题,有效提高了系统的稳定性。Balaji等[13]设计了一种将SNN 映射到神经形态芯片上的方法,通过合理映射有效减少了脉冲传递延迟和计算能耗。刘家华等[14]设计了一种将神经元映射到多核并行计算平台上的方法,提升了并行计算环境下SNN 的仿真效率。Qu等[15]采用了带时间戳的稀疏矩阵存储方法,有效优化了类脑计算平台的负载不平衡问题,提高了平台上的SNN 仿真速度。Titirsha等[16]对神经形态芯片进行了总能耗建模,并提出一种基于启发式的映射方法,能为神经元和突触分配合理的计算资源,降低了神经形态芯片的能耗。Song等[17]提出了一种基于同步数据流图(Synchronous DataFlow Graphs,SDFGs)的方法,将SNN 映射到多核硬件实现系统,并实现了系统吞吐量和资源消耗之间的平衡。这些工作提升了类脑计算平台和芯片的稳定性与运行性能,但是这些映射方法与优化设计尚未综合考虑多个方面的SNN 工作负载特性。
在众多类脑仿真器中,NEST 仿真器在SNN 研究应用广泛,它支持多种复杂程度各异的神经元和突触模型,在分布式计算平台上具有十分优秀的可扩展性[18]。在研究基于NEST 的SNN 工作负载方面,Kunkel等[19]在NEST 仿真器中设计了一种“NEST dry-run”模式,通过投入一个进程进行网络仿真即可有效预测多进程并行环境下的内存和计算时间负载消耗。Nguyen等[20]分析了NEST 仿真器运行SNN 的时间代价,提出了中央处理器(Central Processing Unit,CPU)和图形处理器(Graphic Processing Unit,GPU)协同工作时的SNN 仿真时间预测模型。上述工作虽然解决了类脑计算平台负载消耗预测的问题,但是没有从计算与通信负载平衡的角度考虑计算平台合理映射的问题。
2021 年,笔者所在小组对SNN 进行了工作负载分析,针对NEST 仿真器建立了内存、计算和通信负载模型,实现了一种基于NEST 的SNN 工作负载自动映射器(Workload Automatic Mapper for SNN,SWAM)[21]。SWAM 能够预测SNN的工作负载和在计算平台上的映射结果,并给出映射指导。然而SWAM 尚未深入研究通信的实现机制、缺乏有效的负载模型参数获取方法。在实际运行时,SWAM 存在针对通信工作负载的预测精度不高、对大规模网络适用性较差的问题。
因此,本文在SWAM 基础上进一步分析NEST 通信机制及通信操作算法,建立更精准的通信负载模型;针对负载模型中部分具有实时性的参数以及精准通信负载模型中的新增参数,设计了参数量化方法;设计了最大网络规模预测模块,提供了对不同计算平台的最大网络承载规模预测功能;在此基础上实现了包含精准通信模型和新增功能的工作负载自动映射器SWAM2。
1 研究背景
1.1 脉冲神经网络及其工作负载映射问题
SNN 是类脑计算的基础,被誉为第三代人工神经网络,具有低能耗和高效率的特点。SNN 的主要构成要素包括神经元、突触、连接拓扑、学习机制与可塑性等。SNN 运行过程可以分为神经元计算和突触传播两部分,它们的计算分别由SNN 案例选择的神经元模型和突触模型决定。
神经元模型定义了神经元内部状态更新和产生脉冲的过程,突触模型定义了突触前神经元产生的脉冲经突触处理后发送给突触后神经元的过程。在分布式平台中,神经元分布在不同节点上,因此突触的传播需要进行节点间通信。
目前业界针对大规模SNN 主要通过搭建大规模分布式集群的方式降低单个计算节点上的内存消耗与计算时间消耗。但计算平台的性能受节点规模影响,随着节点数增加,单节点的计算时间消耗减少,但是节点间的通信时间增加。因此特定的工作负载和分布式平台之间的映射都存在计算与通信平衡的问题。当投入节点数小于平衡点时,计算时间大于通信时间,未充分利用计算平台性能;反之,过量投入计算节点会造成平台的计算性能冗余。特定SNN 工作负载在分布式平台上的最佳映射指通过确定合适的投入节点规模(最佳映射节点数),平衡计算与通信时间,最大限度减少SNN 案例的仿真耗时,保证平台以最优的性能运行。
1.2 NEST仿真器
本文通过分析NEST 仿真器实现机制对SNN 工作负载进行研究。在NEST 上进行SNN 模拟主要分为创建、连接、仿真三个阶段。
NEST 支持分布式计算,使用消息传递接口(Message Passing Interface,MPI)实现计算节点间的数据通信。NEST的创建和连接阶段分别对应SNN 案例中神经元和突触的构建,进行分布式计算时,NEST 根据任务分配机制在每个计算节点上分布神经元和突触。
NEST 采用基于进程的轮询算法分配神经元,将神经元按各自的全局标识编号(Global IDentifier,GID)分配到不同的计算节点中。如图1(a)所示,由两个节点组成的分布式计算平台包含进程rank0 和rank1。NEST 根据神经元GID 以循环方式将总共4 个神经元均匀分布在两个进程上,括号内的数字表示神经元的GID。代理变量用于记录分布在其他进程上的神经元GID。

图1 NEST运行机制Fig.1 NEST operation mechanism
NEST 中的突触分配机制与该突触连接的神经元相关联,SNN 案例中的突触根据各自连接关系,会被分配到其突触后神经元所在的进程上。由于神经元的分配采用了轮询算法,突触也会近似均匀地分布到各个进程之中。
网络仿真阶段包括突触传递脉冲(Deliver)、神经元更新(Update)和脉冲收集(Gather)三部分。在分布式平台上,使用NEST 进行网络仿真的计算负载消耗主要包括Deliver 和Update 阶段中各进程上的神经元、突触模型的更新时间,通信负载消耗主要是Gather 阶段收集脉冲信息所需的进程间MPI 通信时间消耗。
如图1(b)所示,脉冲收集阶段负责收集所有进程上的脉冲信息。在该阶段中,每个进程都记录了本进程上产生脉冲的神经元,并且每个进程会把各自记录的神经元的GID(斜线、鱼鳞线表示)放入各自的通信缓冲区Sendbuffer,且要求所有进程的通信缓冲区大小相等。若有进程上的脉冲数量大于该进程的Sendbuffer 尺寸,则扩大该进程的Sendbuffer并且通过一次MPI_Allgather 通信将各个进程上的Sendbuffer同步到最新的尺寸,这可能导致缓冲区未填满,未填充的缓冲区内容为空(空白方块表示)。各进程Sendbuffer 大小确定后,通过MPI_Allgather 通信将所有进程的通信缓冲区依次汇总到全局通信缓冲区Globalbuffer,最后发送给每个进程。
1.3 SWAM自动化映射器
SWAM 是一个基于NEST 的工作负载自动映射器,能够预测SNN 工作负载与映射结果并完成映射。SWAM 包括工作负载建模和自动映射器设计两部分内容。
1.3.1 基于NEST的工作负载模型
针对NEST 的工作负载包括内存、计算、通信三方面。在SWAM 中,已经针对这三方面的工作负载进行了建模。
在内存方面,每个进程的总内存消耗M由运行NEST 所需的基本内存消耗Mo,神经元内存消耗Mn和突触内存消耗Ms三部分组成。
在计算方面,每个进程的计算时间消耗timecalculate包括神经元计算时间消耗Tn和突触计算时间消耗Ts。
其中:tn_ref(i) 为处于不应期的神经元的单次更新时间;tn_unref(i)为非不应期且无脉冲产生的神经元的单次更新时间;tspike(i)为产生脉冲的神经元的单次更新时间;ts(z)为突触单次更新时间;Nspike(i)是脉冲产生次数;cn_ref(i)、cn_unref(i)为仿真过程中神经元更新处于不应期、非不应期且非脉冲激发状态的次数,cn_ref(i)、cn_unref(i)能够根据Nspike(i)计算得出;nkind为神经 元类型总数,i∈[ 1,nkind]为神经 元类型编号;Avgout(jpre)(z)为突触前神经元群落的出度;skind为突触类型总数;z为突触类型编号;numj为突触前神经元群落的个数;jpre为群落的编号;p为使用NEST 进行SNN 仿真时投入的进程数量。
在通信方面,每个进程通过MPI 通信收集脉冲信息的时间消耗如下:
其中:Td为通信操作的执行次数;tMPI(sendbuffer,p)是在p进程规模下的通信时间消耗;sendbuffer为单个进程上的通信数据量大小;tbandwidth表示平台带宽对通信时间的影响。
1.3.2 自动映射器流程
SWAM 流程包括量化和自动化映射模块,如图2 所示。
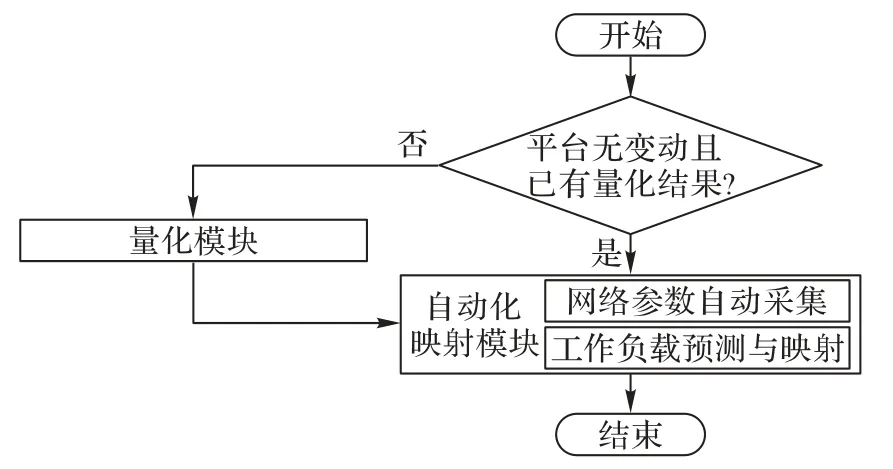
图2 SWAM流程Fig.2 SWAM flow
量化模块:模型中的稳定参数通过量化程序获取数值。稳定参数包括计算负载模型参数tn_ref(i)、tn_unref(i)、tspike(i)、ts(z)以及tMPI。
自动化映射模块包含两个部分:1)网络参数自动采集(Auto_Collect),即在SNN 的构建阶段自动采集模型中如Avgout(jpre)(z)、Td等网络参数;2)工作负载预测与映射(Auto_Forecast&Map),即将量化模块和Auto_Collect 获取的参数转化为工作负载消耗的预测值,并根据预测结果,按映射标准给出最佳映射节点数。
2 精准通信负载模型及自动映射方法
本章在SWAM 的基础上,优化了通信负载模型,提出了负载模型参数更为精准的量化方法,以提升SWAM 工作负载预测性能。同时,新增并设计了最大网络规模预测模块,提供针对不同计算平台最大网络承载规模的预测功能。在此基础上设计并实现了一种更为精准的工作负载自动映射器SWAM2。
2.1 精准通信负载模型设计
在通信工作负载方面,SWAM 缺乏对NEST 通信机制和通信操作算法的分析,导致负载模型准确性不高。本节基于SWAM 对建模过程中的通信负载模型进行了优化设计,以提高通信时间的预测准确率。
2.1.1 NEST通信模块算法建模
根据1.3 节的分析,使用NEST 进行SNN 仿真时,主要通过MPI_ALLgather 通信操作传递脉冲信息,因此针对MPI_ALLgather 的实现进行算法分析并建模。
MPI_ALLgather 是一种全局收集通信操作,每个进程都收集来自所有进程的发送数据Sendbuffer,并把收集的数据汇总为全局通信数据Globalbuffer。为了建立MPI_ALLgather操作的时间代价模型,将通信量大小为n的点对点通信成本tP2P建模为通信建立时间和网络传输时间,如式(6)所示:
其中:ta为通信建立时延;tb为网络时延。
MPI_Allgather 操作中每个进程都需要收集其他p-1 个进程上的发送数据,因此它需要的网络传输数据量为sendbuffer× (p-1),其中sendbuffer为单进程的通信数据量大小。此外,由于NEST 调用了MPICH(Message Passing Interface CHameleon)[22],根据实际情况选择递归倍增、Bruck 和环算法中的一种实现全局收集通信操作,三种算法在实现步骤上有所不同。参考文献[23]的工作,对MPI_ALLgather 操作的时间代价tcomm建模:
其中:cstep是执行MPI_Allgather 操作所需的操作步骤数。在不同进程数p和Globalbuffer 长度下cstep取值如下:
1)当p为2 的整数次幂,且Globalbuffer 长度小于512 KB时,采用递归倍增算法,cstep=lbp。
2)当p非2 的整数次幂,且Globalbuffer 长度小于80 KB时,采用Bruck 算法,cstep=l bp。
3)其他情况下采用环算法,cstep=p-1。
MPI_Allgather 操作中的通信建立时延ta包括在源节点上进行数据整合和目标节点上进行数据分解、校验等所需的时间,因此ta与计算平台的性能有关,与通信量大小无关。网络时延tb表示每字节通信数据在通信网络中的传输时间,tb的值与平台通信带宽B有关。
2.1.2 通信负载模型优化
基于上述分析,可对NEST 中每个进程进行MPI 通信的时间消耗建立更精准的工作负载模型:
其中:tcomm(sendbuffer,p)为通信带宽为B的计算平台在p个进程规模下,调用一次MPI_Allgather 通信操作所耗的时间;sendbuffer为每个进程的通信数据量大小。
相较于SWAM 的通信负载模型,精准通信负载模型更加重视通信时间代价随平台投入进程数变化的规律,同时更好地体现了平台网络带宽对每次通信操作的影响。
2.2 负载模型参数量化方法优化
本节对部分具有实时性的建模参数难以获取的问题进行分析,然后设计了一种参数量化方法。此外,针对精准通信负载模型中新增的参数设计了量化方法。
2.2.1 建模参数获取分析
如表1 所示,负载模型中的参数按照类型可分为时间参数和网络参数。精准通信负载模型中新增参数ta、tb为时间参数,sendbuffer为网络参数。根据对NEST 仿真架构的分析,网络参数中的进程间通信量sendbuffer和各神经元群落的脉冲产生次数Nspike在SNN 仿真过程中持续增加,且由于脉冲发射率具有实时性,难以对它的变化规律进行建模,一般情况下必须通过完整网络仿真获取。因此可以将sendbuffer和Nspike划分为实时网络参数。

表1 负载模型参数分类Tab.1 Classification of workload model parameters
实时网络参数均不受计算平台性能影响,但是与投入仿真进程数和具体SNN 的规模、连接拓扑有关。因此,实时网络参数sendbuffer和Nspike的获取必须针对不同情形进行多次完整网络仿真,它的代价无疑较大。针对此问题,SWAM 通过少量预仿真采集网络中神经元平均脉冲发射率,根据脉冲发射率和本地进程的神经元数量预测参数Nspike,同时根据Nspike推测平均通信发射任务量以框定sendbuffer。
2.2.2 Single_Mode实时网络参数量化方法设计
针对实时网络参数的获取问题,本节参考“NEST dryrun”[19]的设计思想提出了一种实时网络参数的低成本量化方法Single_Mode。Single_Mode 是一种经过修改的NEST 仿真器运行模式。在Single_Mode 下进行网络仿真只需投入一个进程rank0,它的特殊设计能够使rank0 的网络仿真行为类似于NEST 常规流程中投入p个进程进行网络仿真时rank0的仿真行为。因此,Single_Mode 下采集进程rank0 上的实时网络参数能够作为对参数真实数值的量化。Single_Mode 的具体实现包含对NEST 中网络构建流程和仿真流程的修改。
1)Single_Mode 网络构建流程。
运行Single_Mode 需要设定所需量化的条件下的网络参数(目标SNN 和投入网络仿真进程数p)。网络构建时只构建属于进程rank0 的神经元和突触数据结构。除rank0 外的p-1 个进程称为伪进程,伪进程未实例化。
Single_Mode 下的网络构建流程中,进程rank0 独立运行,不需要任何来自伪进程的信息。进程rank0 上仅实例化满足条件GID%p=0 的神经元。由于存储突触信息的数据结构与其目标神经元(突触后神经元)存储在同一进程上,因此进程rank0 仅需要检测突触的目标神经元是否分布在本地,以决定是否构建记录该突触的数据结构。
2)Single_Mode 网络仿真流程。
NEST 常规仿真流程中,每个进程独立进行神经元更新,突触传递脉冲的过程。但是脉冲收集阶段需要收集其他进程上的脉冲信息,为了模拟真实仿真流程,Single_Mode 实现中修改了NEST 仿真流程中的脉冲收集阶段。
如图3 所示,Single_Mode 下的脉冲收集阶段中rank0 会将神经元产生的脉冲信息放入通信缓冲区Sendbuffer(rank0)。然而伪进程都未实例化,不会产生脉冲信息,为了模拟p个进程下的真实仿真行为,使rank0 能够收集伪进程的脉冲信息,Single_Mode 为每个伪进程构造了伪脉冲信息。构造方法参考了“NEST dry-run”的设计,在NEST 中神经元群落均匀分布在所有进程上,每个进程都包含了神经元群落的一个子集。伪脉冲信息的构造假设在同一时间内,一个神经元群落的所有子集产生的脉冲数量几乎相等。因此Single_Mode 在仿真的每个时间片内构造了与rank0 上的脉冲数量相同的伪脉冲信息,以填充伪进程的通信缓冲区。
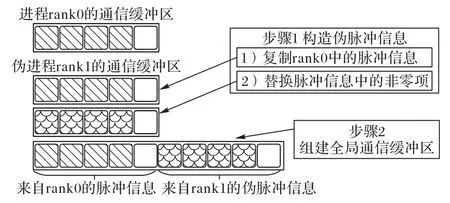
图3 Single_Mode脉冲收集阶段设计Fig.3 Design of spike gathering stage in Single_Mode
Single_Mode 下的脉冲收集阶段设计如图3 所示,以2 个进程为例,在每个仿真时间片内rank0 把产生的脉冲信息放入 Sendbuffer(rank0)。伪进程 rank1 的脉冲信息Sendbuffer(rank1)的构建方式是:首先将Sendbuffer(rank0)的内容直接复制给Sendbuffer(rank1);其次,将Sendbuffer(rank0)的非零项(斜线)替换为随机选择的神经元GID(鱼鳞线表示),但必须满足GID%p=1,即这些随机选择的神经元GID,即使在NEST 常规流程中也会被分配到进程rank1 上。完成伪进程构建后无需进行MPI 通信,而是把rank0 和所有伪进程的脉冲信息依次连接组建全局脉冲信息,rank0 根据全局脉冲信息更新突触和神经元然后继续进行下一轮仿真。
这种做法保证了所有进程的发送缓冲区尺寸相等且随rank0 的脉冲发射率而变化。尽可能模拟投入多进程进行仿真时的真实网络状态。按照Single_Mode 的设计进行网络构建和仿真后,通过在NEST 内核中的统计函数采集rank0 上的最终的通信缓冲区尺寸sendbuffer和各群落的脉冲激发次数Nspike以完成对实时网络参数的量化。
采用Single_Mode 量化实时网络参数只需投入一个进程,且无需进行MPI 通信,显然是一种低成本的方法。根据2.2.1节的分析,实时网络参数数值与计算平台算力无关,因此Single_Mode 的量化结果具有平台通用性。
2.2.3 通信模型时间参数量化方法设计
2.1 节优化的精准通信负载模型中新增的时间参数包括ta和tb,它们的数值与平台性能和通信带宽有关。
量化方法是:首先通过控制变量法获取不同进程规模p、通信量sendbuffer下的MPI_Allgather 运行时间tcomm以形成训练数据集。然后通过LM(Levenberg-Marquardt)最小二乘优化算法对式(7)中的MPI_Allgather 操作时间代价模型进行训练,最终得出ta和tb的值,如算法1 所示。

2.3 最大网络规模预测模块设计
本节在1.3.1 节提出的内存负载模型基础上,设计了针对分布式计算平台的最大网络规模预测模块。
当SNN 在每个进程上的内存消耗等于计算平台单个节点的最大可用内存Mh(排除系统运行等内存消耗)时,此时的网络规模即为平台所能承载的最大网络规模。在分布式平台上使用NEST 构建SNN 时,每个进程没有为非本地神经元、未与本地神经元建立连接的神经元提供基础设施,因此可对内存负载模型中的神经元内存负载Mn和突触内存负载Ms进行优化:
其中:N、Np为网络规模和单节点神经元数分别是进程为每个神经元提供的神经元、突触基础设施内存消耗以及本地神经元基础设施内存消耗;mn和ms为单个神经元模型和突触模型的内存消耗。
综上所述,对于神经元平均入度为Avgin的SNN,单个节点最大网络规模与平台投入进程数满足以下关系:
最大网络规模预测模块按照式(11)的模型,在确定计算平台最大可用内存Mh以及投入进程数p后,即可预测出平台单节点最大网络规模Nfull。
2.4 SWAM2实现
SWAM2 整体流程如图4 所示,2.1 和2.2 节的工作分别是对网络自动化映射和量化模块的优化。
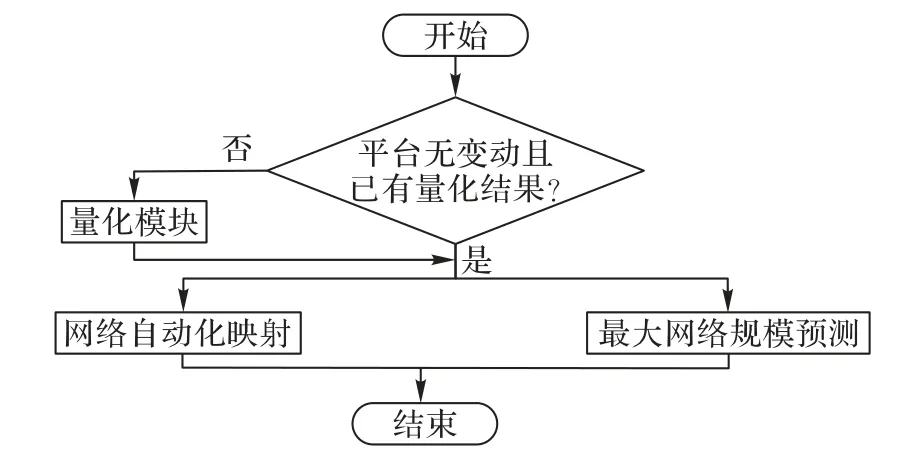
图4 SWAM2流程Fig.4 SWAM2 flow
2.4.1 量化模块
SWAM2 的量化模块在保留了SWAM 原有的稳定参数量化功能的基础上,使用优化量化方法获取了实时网络参数和通信模型中的时间参数。在目标类脑计算平台上,使用Single_Mode 运行目标SNN 案例即可完成实时网络参数的量化。通过在Single_Mode 中设置不同的网络仿真进程数,可以量化不同进程规模下的实时网络参数。
对于通信模型中的时间参数ta和tb,首先在目标类脑计算平台上多次运行MPI_Allgather 通信操作,每次运行时改变进程规模和通信量,采集通信操作运行时间形成训练数据集,然后调用通信时间参数量化算法获取参数ta和tb。此外,式(11)中的建模参数和ms在同一个计算平台上都是固定值,属于稳定参数,通过手动分析量化获取。
量化模块获得的所有实时网络参数、时间参数和稳定参数放入参数记录表中进行存储,后续流程可以直接读取表中数据进行工作负载预测和分析。
2.4.2 网络自动化映射与最大网络规模预测
网络自动化映射模块保留了网络参数自动采集功能(Auto_Collect)。在工作负载预测与映射(Auto_Forecast&Map)中采用了精准通信负载模型,将量化模块、Auto_Collect获取的所有参数转化为不同进程规模下的计算时间timecalculate、通信时间timeMPI等负载预测结果。
SWAM2 将SNN 案例在计算平台上的仿真时间消耗作为衡量平台运行性能的标准,SNN 的仿真时间消耗即是timecalculate和timeMPI之和。SWAM2 按照这一标准,给出平台取得最优性能(SNN 的仿真时间消耗最少)时投入的进程数量Pbest。由于NEST 在分布式计算平台的每个节点上运行一个进程,因此Pbest的数值是SNN 在计算平台上的最佳映射节点数。
最大网络规模预测模块首先从参数记录表中读取式(11)所需参数,然后通过函数接口接收描述计算平台信息的参数Mh和p,最后即可完成对最大网络规模的预测。
3 实验与结果分析
3.1 实验平台
本文采用的实验平台为由PYNQ Z1/Z2(PYthon productivity for zyNQ Z1/Z2)[24]组成的大规模分布式类脑计算平台。如图5 所示,类脑计算平台的每个节点都包含一个ARM(Acorn Risc Machine)架构的Cortex-A9 处理器及现场可编程逻辑门阵列(Field Programmable Gate Array,FPGA)。计算节点通过1 000 Mb/s 网络带宽的以太网连接到网络交换机,将计算节点分成2 组连接在2 个网络交换机上,交换机互相桥接构成一个完整平台,以实现SNN 并行计算。

图5 PYNQ类脑计算平台Fig.5 PYNQ brain-like computing platform
在之前的工作中已针对STDP(Spike Timing Dependent Plasticity)突触和IAF(Integrate-And-Fire)神经元设计了加速模块[25-26],选择调用或不调用加速模块可获得两种不同性能的类脑计算平台(ARM+FPGA 和ARM)。
3.2 工作负载
为验证SWAM2 针对不同类型SNN 模型的有效性,本文对两种不同类型的典型案例进行测试。
1)Example1:高性能计算机基准测试[27]。该测试能够衡量整个系统的性能,侧重于神经形态特性验证。包含两个神经元群落in 和ex,神经元均为iaf_psc_alpha 类型,两个群落中神经元数量之间的比例为1∶4,网络规模可以成倍调节。该网络包含静态、STDP 两种类型的突触。
网络以11 250 个神经元为基准,选取的缩放倍率为1.0。ex 包含9 000 个神经元,in 包含2 250 个神经元,网络模拟运行250 ms,运行过程中每个神经元更新2 500 次。ex 中的神经元通过STDP 突触与in 中神经元连接,in 中的神经元通过静态突触与ex 中神经元连接,网络包含约8 100 万条STDP 突触和4 556 万条静态突触。
2)Example2:皮质层视觉模型[28]。该模型是无监督的图像分类算法,可以模仿生物学机制进行图像分类任务。该SNN 有5 层,前4 层网络为训练部分,第5 层为推理部分。神经元模型均是iaf_psc_exp,无设备类型神经元,突触模型包括静态突触和STDP 突触。
在网络训练和验证过程中均使用了Caltech 101 数据集,模型的网络规模与数据集图片尺寸成正比,本文采用尺寸为300× 300 的数据集进行测试,大约产生70 万个神经元、3 万条STDP 突触和570 万条静态突触。网络模拟运行50 ms,运行过程中每个神经元更新500 次。
3.3 优化设计结果对比与分析
为了验证SWAM2 中优化的通信模型及参数量化方法的有效性,将SWAM2 和SWAM 针对两种案例预测的实时网络参数、工作负载数据分别与实测数据进行对比;同时根据SWAM2 和SWAM 预测的计算、通信工作负载,推导出最佳映射节点数并与实测的最佳映射节点数进行对比。
3.3.1 负载数据预测结果对比与分析
在预测实时网络参数方面,对比表2 和表3 中数据可知,SWAM2 针对案例Example1 和Example2 预测的通信数据量sendbuffer在不同进程规模下都十分接近实测数据,通过计算预测值之和与实测值之和的比值,得到SAWM2 针对这两个案例的sendbuffer的平均准确率为95.80%,而SWAM 的预测平均准确率为81.46%。

表2 Example1中的sendbuffer 单位:B Tab.2 Comparison of sendbuffer in Example1 unit:B
在工作负载预测方面,表4 对比了SWAM2 和SWAM 对实时网络参数的预测准确率以及在两种计算平台(ARM+FPGA 和ARM)上的平均工作负载数据预测准确率。此外,以ARM 平台为例,图6 展示了不同进程数下SWAM2 和SWAM 对计算、通信负载的预测结果,以及实测的负载数据。实验结果表明,随着进程数增加,通信时间逐渐增长,计算时间被稀释,说明SNN 工作负载映射的问题真实存在,寻找最佳映射节点数能够平衡计算与通信负载,减少SNN 的仿真耗时。SWAM2、SWAM 的预测结果均能够反映负载数据变化趋势,而SWAM2 的负载预测结果明显更加接近真实数据。
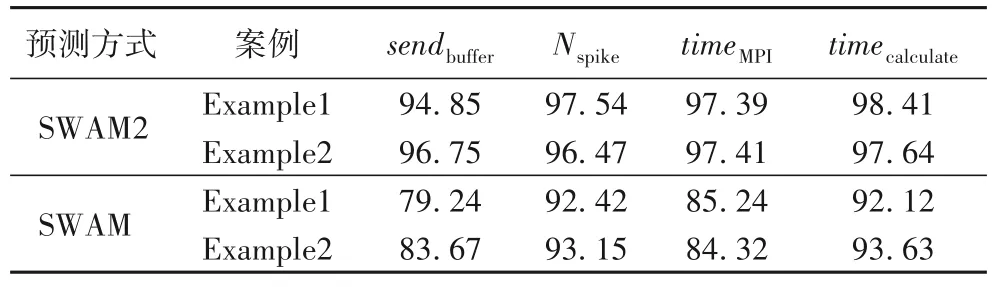
表4 预测准确率对比 单位:%Tab.4 Comparison of predicted accuracy unit:%
在通信负载预测方面,从表4 可知,SWAM2 通过建立精准通信负载模型与准确预测参数sendbuffer,有效提升了对通信负载预测的准确率。SWAM2 针对2 个案例预测的timeMPI与实测数据间的平均误差只有2.60 个百分点,相较于SWAM,减少了12.62 个百分点。
在计算负载预测方面,由于优化了建模参数Nspike的量化方法,相较于实测数据,SWAM2 对两种案例预测的timecalculate的预测误差只有1.59 和2.36 个百分点,相较于SWAM,预测误差减少了5.15 个百分点。
3.3.2 映射结果对比与分析
为了验证SWAM2 在预测最佳映射结果方面的有效性,针对两种案例分别在ARM 和ARM+FPGA 两个平台上进行仿真时间和映射结果预测对比。如图7 所示,对通信和计算负载预测准确率的提高使仿真时间的预测更加准确,进而提高了最佳映射结果的准确率。

图7 SWAM2和SWAM仿真时间预测与实测数据比较Fig.7 Comparison of SWAM2 and SWAM predicted simulation time with measured data
SWAM2 与SWAM 输出的最佳映射结果Pbest如表5 所示。在ARM 和ARM+FPGA 两个平台上,SWAM2 针对Example1预测Pbest的预测误差分别为2 和0 个节点;针对Example2 预测Pbest的误差分别为1 和0 个节点。计算预测误差之和与实测数据之和的比值,得到的预测误差率为2.45%。与实测数据相比,SWAM2 预测Pbest的平均准确率达到了97.55%,相较于SWAM 准确率提升13.13 个百分点。再次验证了SWAM2 对通信负载模型和建模参数获取进行的优化设计的有效性。
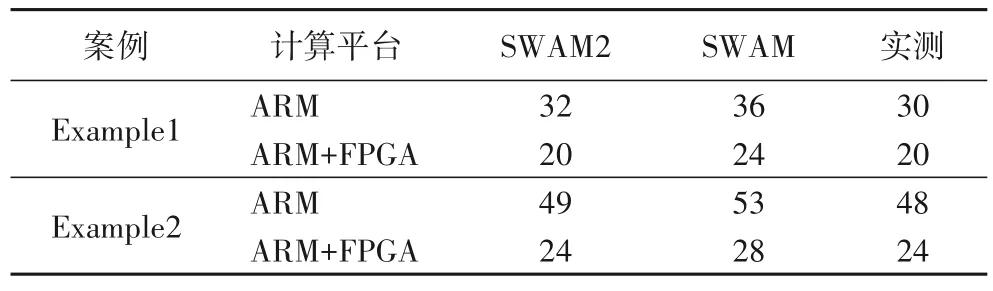
表5 最佳映射结果对比Tab.5 Comparison of best mapping results
3.4 最大网络规模预测结果分析
为了验证SWAM2 最大网络规模预测模块的有效性,将预测结果与通过实测得出的单节点最大网络规模进行对比。相较于ARM 平台,ARM+FPGA 平台的每个节点需要消耗额外64 MB 内存以支持加速,因此它的单节点最大网络规模小于ARM 平台。对比结果如表6 所示。
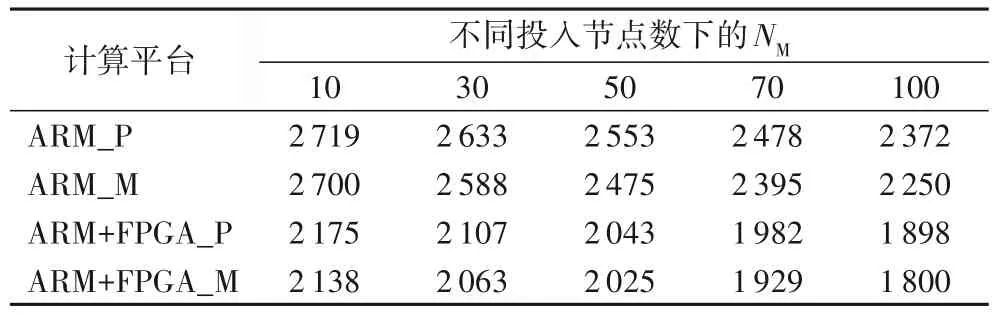
表6 平台NM与实测数据对比Tab.6 Comparison between platform’s NM and measured data
对实测数据(ARM_M 和ARM+FPGA_M)分析可知,随着投入节点数增加,单节点最大网络规模数(NM)减少,原因在于每个节点提供给非本进程神经元的基础设施内存消耗增大,因此预测分布式计算平台的最大网络规模时,考虑基础设施的内存消耗十分重要。SWAM2 预测的NM十分接近实测结果。以ARM 平台为例,投入100 节点的NM的预测结果和实测结果(ARM_P 和ARM_M)分别为2 372 和2 250 个神经元。采用与3.3.2 节相同的计算方式,根据预测数据和实测数据得到预测误差,计算预测误差之和与实测数据之和的比值得到误差率,最后得到预测准确率。针对两种平台的NM的预测准确率为97.33%。证明了考虑基础设施内存消耗的模型的准确性。
3.5 SWAM2资源消耗评估
SWAM2 的内存资源消耗主要包括参数记录表(V_static)和自动化映射模块记录SNN 信息所需的数据结构(V_collect)。上述内存资源消耗与网络模型规模有关,如表7所示,针 对Example1 和Example2,SWAM2 分别消耗了181.1 KB 和9 678.3 KB,因此SWAM2 的内存消耗处于较低水平。

表7 SWAM2内存消耗 单位:KB Tab.7 SWAM2 memory consumption unit:KB
在时间资源消耗方面,SWAM2 的时间代价较为稳定,针对Example1 和Example2 的时间消耗分别为0.9 s 和2.5 s,与通过真实网络仿真的方式进行映射试探相比,SWAM2 拥有绝对的时间优势。
综上所述,采用了精准通信负载模型与优化的参数量化方法后,SWAM2 在预测平台通信、计算负载数据方面相较于SWAM 更为精准,对最佳节点映射的预测更为准确。同时SWAM2 新增了最大网络规模预测功能以帮助使用者针对不同计算平台有效预测出最大承载网络规模。此外,针对SWAM2 的资源消耗评估可知,SWAM2 所需的内存和时间代价较小,具备轻量级的优势。
4 结语
针对如何在类脑计算平台上实现工作负载和计算资源的合理映射问题,本文在SWAM 工作负载自动映射器的基础上加以改进,通过建立精准通信负载模型以及优化建模参数量化方法的方式,提升了对工作负载中的计算、通信时间以及最佳映射节点数的预测准确率;同时设计了最大网络规模预测模块,准确预测了不同计算平台所能承载的最大网络规模。在此基础上实现了一种准确度更高、功能更全面的SNN工作负载自动映射器SWAM2。
下一步工作将从以下两方面展开:1)深入分析工作负载参数的影响因素,优化负载模型参数获取方法,以实现更加便捷、准确的参数获取。2)考虑输入数据特性、模型计算精度等更多因素对SNN 工作负载的影响,从更广阔的层面探究SNN 工作负载的合理映射问题。
猜你喜欢
意林(2023年7期)2023-06-13
昆钢科技(2022年4期)2022-12-30
自然杂志(2021年6期)2021-12-23
昆钢科技(2021年6期)2021-03-09
中国外汇(2019年20期)2019-11-25
小学科学(学生版)(2019年4期)2019-05-11
现代装饰(2018年5期)2018-05-26
电源技术(2015年5期)2015-08-22
弹箭与制导学报(2015年1期)2015-03-11
民主与科学(2014年3期)2014-02-28
