
融合边特征与注意力的表格结构识别模型
2023-03-24 13:24吕学强张煜楠韩晶崔运鹏李欢
计算机应用 2023年3期
吕学强,张煜楠,韩晶*,崔运鹏,李欢
(1.网络文化与数字传播北京市重点实验室(北京信息科技大学),北京 100101;2.农业农村部农业大数据重点实验室(中国农业科学院农业信息研究所),北京 100081)
0 引言
表格数据因简洁规范、便于填写、易于阅读等特性而在生活中应用广泛。随着信息化的不断推进,人们对于表格信息自动提取的需求越发迫切。表格作为信息的载体,不仅包含文本信息,同时也包含逻辑结构信息。目前,已经可以通过光学字符识别(Optical Character Recognition,OCR)技术提取表格中的文本信息,而表格结构信息的识别仍然是表格信息提取领域的重点问题。
传统的表格结构识别方法利用图像处理技术从图像数据中获取特征,并使用启发式算法识别表格结构。对含有表格的图像进行处理,从中获取表格框线位置和表格文本投影信息,通过这些信息能够较好地识别规整的表格结构[1-2]。在此基础上,使用启发式算法对特殊情况进行处理,从全局角度优化输出,能够有效优化算法的性能[3-4]。基于传统方法的表格结构识别在特定场景下通常能够取得较好的效果,但这类方法往往受使用场景的限制,鲁棒性较差。
近年来,随着深度学习的快速发展,越来越多的研究开始将深度学习用于表格结构识别领域。基于图像特征的表格结构识别以表格图像为基础,利用目标检测、语义分割等深度学习方法对图像中表格的行和列进行检测分割,并通过后续算法还原表格结构信息。Paliwal等[5]提出一种基于语义分割的表格结构识别方法,首先通过语义分割得到表格中列的位置信息,并使用启发式方法得到行信息,实现表格结构识别。Tensmeyer等[6]提出了一种分割-合并模型,首先将表格图像进行细致分割,然后对分割结果进行同行、列的合并,由此得到表格结构信息。Siddiqui等[7]提出一种基于目标检测的表格结构识别方法,将表格的行、列视为被检测对象,使用语义分割网络进行检测。Qiao等[8]针对单元格位置信息与空白单元格进行优化,细化了单元格边界信息,并通过表格结构恢复算法解决了空白单元格的问题。基于图像特征的表格结构识别方法从表格图像的行、列结构入手,首先确认图像中的行、列结构,并以此为基础推导出单元格之间的关系。此类方法能够很好地获取图像中的全局信息,但较难处理表格结构中存在的复杂结构,泛化性较差。
基于文本框的表格结构识别以表格图像的OCR 结果为基础,对文本框进行图结构建模,通过图神经网络(Graph Neural Network,GNN)进行推理,还原表格结构信息。Qasim等[9]首先将GNN 引入表格结构识别领域,在对表格进行图建模的基础上,使用GNN 预测文本块之间的同行、同列、同单元格关系,以此得到表格结构。Li等[10]在OCR 的基础上建立图模型,然后使用图卷积神经网络(Graph Convolutional Network,GCN)预测文本块间的行、列位置关系。基于文本框的表格结构识别方法不依赖表格框线、图像特征等信息,具有更强的泛化能力;但受限于图网络结构,这类方法通常对于空间特征信息利用不够充分,在图网络推理过程中很容易损失局部空间信息,抗干扰能力较差。
针对现有方法在表格结构识别任务中存在的复杂表格结构识别率较低、局部空间信息损失的问题,本文提出一种新的用于表格结构识别的图网络主干网络——图边注意力网络(Graph Edge-Attention Network,GEAN),并在此基础上提出融合边特征与注意力的表格结构识别模型(Graph Edge-Attention Network based Table Structure Recognition model,GEAN-TSR)。GEAN-TSR 使用GEAN 作为主干网络对特征进行聚合、传递,然后引入边特征和文本特征,并与图网络提取的特征层相融合,最后通过图中边的分类实现表格结构预测。在公开数据集上的对比实验与消融实验验证了模型的有效性。
1 相关工作
1.1 空域图卷积神经网络
GCN 的主要发展方向分为空域图卷积与谱域图卷积两条路线:谱域图卷积神经网络从卷积定理出发,通过傅里叶变换等方法在谱空间实现图卷积。而空域图卷积神经网络则是在构建图模型的基础上,通过节点特征的聚合与传递进行更新、预测的网络。相较于谱域图卷积神经网络,空域图卷积神经网络更加灵活,能够更好地针对特定任务建模[11]。
在空域图卷积神经网络中,设图G=(V,E),其中:节点集合V={v1,v2,…,vn}表示图中包含n个图节点;边集合E⊆V×V;节点i与j之间的边表示为eij∈E;与节点i相邻的节点集合记为Ni={j∈V|eij∈E}。图神经网络每一层的输入为当前层图中所有节点特征的集合与图中所有边的集合E。更新前图节点特征记为hi,更新后图节点的新特征记为h′i。图节点更新公式如式(1)所示:
其中:f()表示特征提取函数;AGG()表示聚合函数。
1.2 边卷积
边卷积(Edge Convolution,EdgeConv)由Wang等[12]首先提出并使用。该方法针对空域图卷积神经网络在点云处理任务中缺乏拓扑信息而无法有效提取局部结构信息的问题,生成描述点与它的相邻节点的边缘特征,以取代传统图卷积神经网络直接从嵌入中生成点特征的方法,提升网络对于局部信息的学习能力,更新公式如下:
其中:θ与ϕ为参数矩阵;采用的激活函数为ReLU(Rectified Linear Unit)。
相较于其他空域图卷积网络结构,边卷积能够更好地学习节点与相邻节点的边缘特征,以解决局部图复杂的问题。边卷积更新如图1 所示。图1(a)中,待更新节点i及其相邻节点j之间的边特征eij由节点i的特征矩阵hi与节点j的特征矩阵hj经全连接层得到。图1(b)中,使用与待更新节点相邻的边特征进行图节点的特征聚合并更新节点hi为

图1 边卷积更新过程示意图Fig.1 Schematic diagram of EdgeConv update process
1.3 图注意力模型
Veličković等[13]提出了 图注意 力网络(Graph Attention Network,GAT)模型,在图节点的特征聚合过程中引入注意力机制,使每个图节点都关注它所有的邻居,并给出查询表示重要程度,如图2 所示。图2(a)中,待更新节点与它相邻节点之间的注意力参数aij由节点i的特征矩阵hi与节点j的特征矩阵hj组合,并通过全连接层与激活层得到。图2(b)中,使用注意力参数为待更新节点的相邻节点特征进行加权,然后将加权后的相邻节点特征聚合并更新节点hi为引入注意力的模型能够更有效地聚合图节点特征,图注意力更新公式如下:
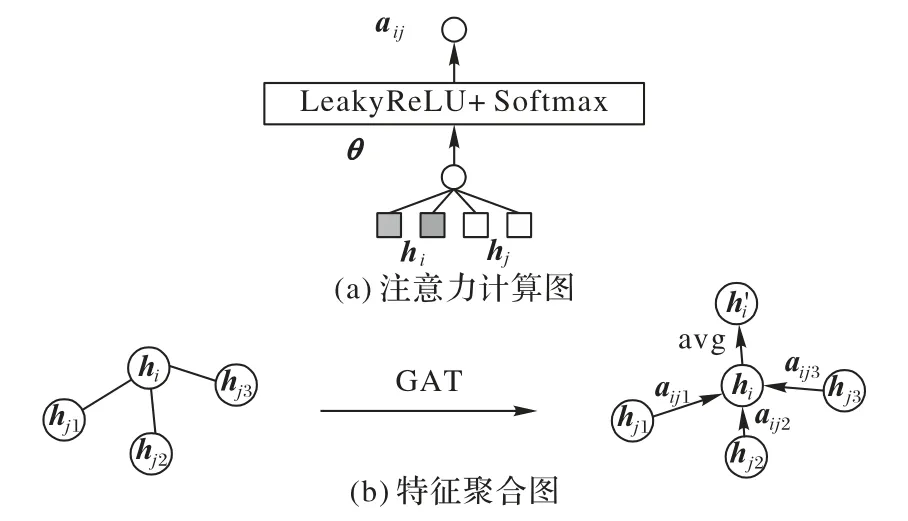
图2 GAT聚合过程图Fig.2 GAT aggregation process diagram
其中:aT、W为参数矩阵;LeakyReLU 为带泄露修正线性单元(Leaky Rectified Liner Unit);Softmax 为归一化指数函数。
此外,Brody等[14]指出GAT 模型本质上是一种静态注意力机制(static attention),并提出了改进的动态注意力机制(dynamic attention)。静态注意力机制存在一定的缺陷,无法准确表达应有的重要程度关系。设有查询矩阵Q与值矩阵V,若对于所有的Q都存在一个固定的V,使得所有Q对于这个V为所有查询中的最大值,则称这种注意力为静态注意力。在静态注意力中,注意力计算公式中的权重矩阵aT与W实际上处于连乘关系,因此,它的作用等效于一个线性层,无法准确表达应有的重要程度关系,使模块没能发挥应有的作用。动态注意力则通过改进eij的计算方式克服这个缺陷,有效提升了模型的表达能力。它拆分两个线性层,并分别在线性层后增加非线性激活函数,形成类似多层感知机的效果,以此提升注意力模型的效果。更新公式如下:
2 本文方法
本文在输入特征的基础上首先进行图结构建模,使用GEAN 提取特征,然后融合边、文本特征与图网络输出,最后由分类器输出结果,整体结构如图3 所示,其中多层感知器(MultiLayer Perceptron,MLP)是常用的特征提取方法。
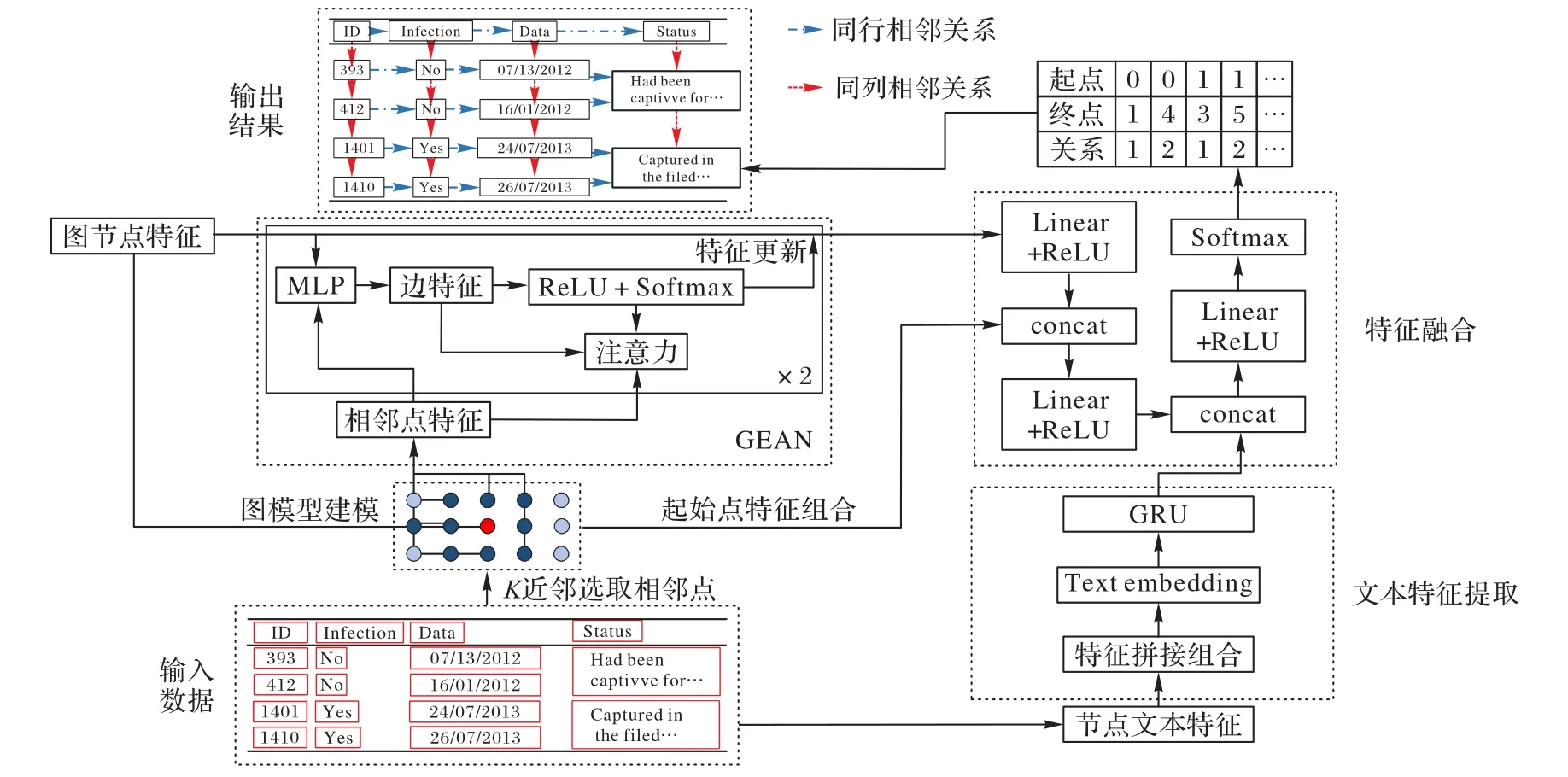
图3 GEAN-TSR结构Fig.3 Structure of GEAN-TSR
2.1 基于图模型的表格结构识别任务建模
基于图模型的表格结构识别任务的输入为表格中每个单元格的特征,通过预测单元格之间水平或竖直方向的相邻关系完成表格结构识别任务。引入图模型后,将表格中的每个单元格视作图节点,单元格的相邻关系视作图中的边,由此将表格结构识别问题转化为已知图节点特征,预测图中边类别的任务。初始图中仅存在图节点及相关特征,并没有边存在,因此,首先需要根据图节点特征对图中的边进行初始化。为了不损失模型精度,图模型中的边需要尽可能将相邻的图节点(单元格)相连,最简单的办法是对所有图节点建立连通图。但是,连通图包含大量的冗余信息并且会带来极大的计算量。为了降低模型计算量,在图节点特征的基础上,使用K近邻(K-Nearest Neighbors,KNN)算法构建初始图中的边。其中,近邻值K的取值需要根据数据情况而定,本文选用K=20 构建邻域。在KNN 算法中,选用单元格中心点之间的欧氏距离度量单元格之间的距离:
随后,在邻域内的图节点与作为中心点的图节点之间建立边,完成图模型的构建。在完成建模后,以图节点特征矩阵、边矩阵作为图网络的输入进行推理。设图G中节点即表格中单元格数量为N,每个图节点有M个特征输入,则特征矩阵形状为N×M。本文选取图节点的绝对位置、相对位置等空间信息作为图节点的初始特征。边矩阵形状为2×L,代表图中共存在L条初始化的边,边矩阵记录了图中边的两端点。网络将通过模型推理判断K条边的类别,设图中节点i与j为同行相邻关系,则label(i,j)=1;若节点i与节点j为同列相邻关系,则label(i,j)=2;否则,节点i与节点j不构成关联关系,label(i,j)=0。
2.2 图边注意力网络
现有基于图卷积神经网络的表格结构识别方法大多采用边卷积作为主干网络[9-10]。然而,不同于边卷积应用的点云场景,表格结构识别任务中的图节点蕴含信息更为丰富密集,这导致边卷积使用的聚合方式很容易带来局部特征信息的损失。针对表格结构识别任务中图节点连接密集、对局部结构信息敏感等特点,本文提出GEAN 以完成表格结构识别任务中的特征提取、传递、聚合的任务,GEAN 的推理过程如图4 所示。图4(a)中,将待更新节点i的特征矩阵hi、待更新节点i相邻节点j的特征矩阵hj作为输入,通过全连接层计算得到节点i与节点j之间的边特征eij,然后将hj与eij组合并使用全连接层和激活层计算得到注意力权重aij。图4(b)中,将待更新节点的相邻节点特征hj与边特征eij组合传入全连接层,并使用注意力进行加权,更新节点特征hi。
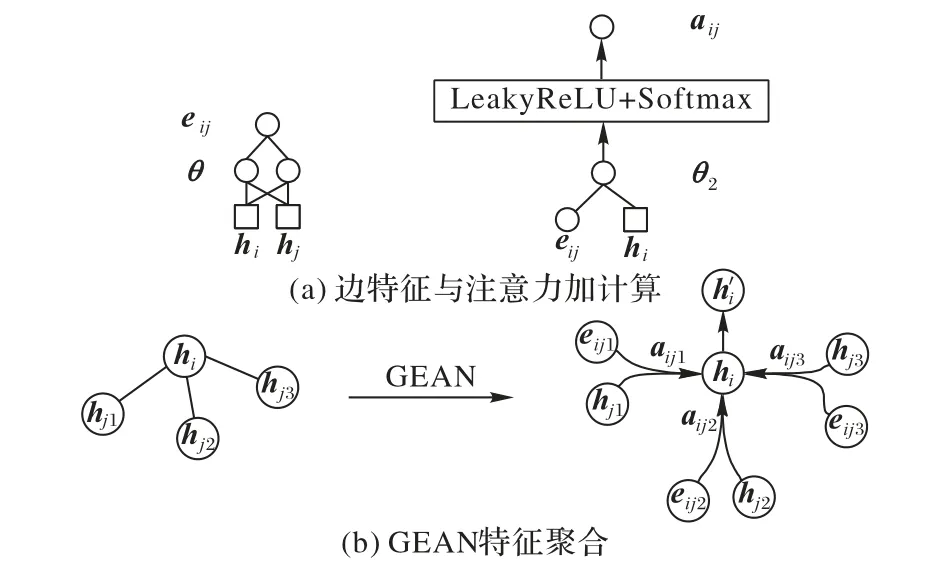
图4 GEAN推理过程Fig.4 Inference process of GEAN
GEAN 在边卷积结构的基础上,为了更好地提取局部空间信息,引入图注意力机制加强模型对局部空间信息的提取能力。同时,注意力查询能够更好地覆盖密集连接的边,更加充分地传递特征。在图边注意力中,本文将eij作为图边注意力的查询(Query),图节点i的特征hi作为键(Key),计算Ni中的每个图节点j与图节点i的注意力查询关系aij,并依据注意力权重更新图节点i的特征hi,图边注意力更新公式如式(11)~(13)。
其中:θ、ϕ、W均为参数矩阵,激活函数为LeakyReLU。
GEAN 在网络中的更新细节如图5 所示。网络输入为图中所有节点的特征矩阵x,Nnum为图中节点数量,Cnum为多头注意力的头数。hi与hj宽度为节点特征数(128),Enum为图中边的数量。边矩阵e中的每一行代表图中一条边的特征,由矩阵hi与h(j起点与终点矩阵)中对应行经全连接层得到。之后,由矩阵e与hi计算得到注意力矩阵a。最后,由x与e在注意力加权下更新图节点特征矩阵x,完成一次网络更新。
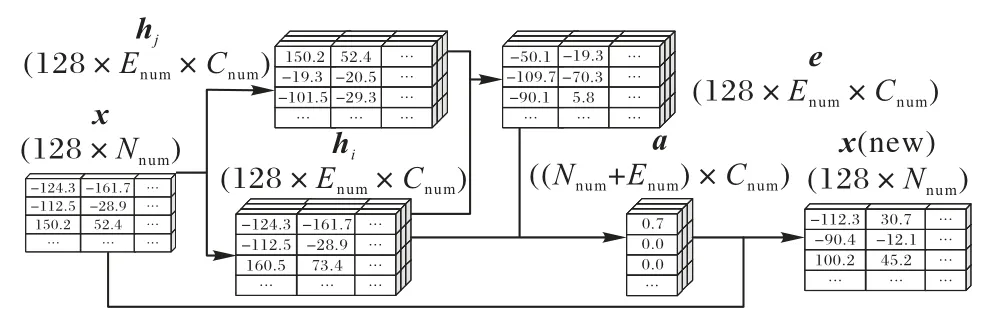
图5 GEAN更新过程仿真示例Fig.5 Simulation example of GEAN update process
2.3 边特征与文本特征融合
为了预测图中边的分类结果,边特征信息必不可少。每一条边特征都依赖于这条边的起点与终点。本文将边的两端点所对应的图节点特征进行特征层面的拼接,然后使用Linear+ReLU 得到边特征。通过图卷积更新图节点特征然后再拼接边特征的过程会造成特征的损失,影响模型的性能。为了加强用于边分类的特征,本文模型在生成边特征后,引入额外的边特征融合模块。该模块通过边矩阵获取边的起始点位置信息,并计算每条边的空间信息。本文模型选取了相对位置、绝对位置、相对角度等特征作为输入,在使用线性变换与激活函数进行简单的特征提取后,将新的边特征矩阵与先前计算得到的特征矩阵进行concat 融合,具体过程如图6 所示。
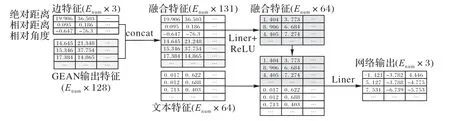
图6 边特征融合过程实例Fig.6 Example of edge feature fusion process
表格结构识别任务中除了单元格位置信息外,还存在单元格文本信息与单元格图像信息。Li等[10]指出单元格对应的图像信息并不能有效提升模型效果,而文本特征则有助于模型效果的提升。目前最常用的文本特征提取方法有门控循环单元(Gated Recurrent Unit,GRU)、长短期记忆(Long Short-Term Memory,LSTM)、BERT(Bidirectional Encoder Representations from Transformers)等,考虑到单元格中的文本特征上下文语义较弱,本文选用兼顾速度与性能的GRU 对每个单元格的文本分别进行特征提取:
其中:zt为更新门;rt为重置门;dt与dt-1分别为时间t与t-1的隐藏状态;xt为输入向量;σ为Sigmoid 函数。将得到的图节点文本特征拼接成边特征矩阵,并使用concat 操作将它与先前的特征矩阵组合;最后,在线性变换后使用Softmax 函数进行最终的网络预测输出,如图7 所示。

图7 特征融合过程Fig.7 Process of feature fusion
3 实验与结果分析
3.1 数据集与评价指标
为了验证本文的GEAN-TSR 在表格结构识别任务上的有效性,选用表格结构识别领域常用的几个公开数据集进行性能测试,并与最新的表格结构识别模型进行对比。这些数据集包含表格图像、单元格文本位置标注、文本标注与单元格关系标注信息。
1)SciTSR(Scientific paper Table Structure Recognition)数据集:该数据集从LaTex 源文件中获取了15 000 个PDF 格式的表格以及对应的高质量表格结构标签。其中,共有12 000个表格及其结构标签用于训练,3 000 个用于测试。数据集中的表格平均有9 行、5 列、48 个单元格。为了对复杂表格结构进行评估,选取了716 张含有跨行跨列信息的表格图片构成了SciTSR-COMP(Scientific paper Table Structure Recognition-COMPlicated)的测试集。
2)ICDAR 2013(International Conference on Document Analysis and Recognition 2013)数据集:该数据集包括从美国、欧盟政府文件中摘录的156 张表格数据。
3)PubTabNet 数据集:该数据集包括500 777 张训练图像与9 115 张验证图像,包含大量的三行表,也含有跨行跨列单元格、空白单元格等复杂信息。
Göbel等[15]提出的表格结构识别指标是目前最通用的表格结构识别指标之一。该方法生成单元格与它在水平和垂直方向上最近邻的单元格之间的邻接关系表,而空白单元格则不与非空单元格产生邻接关系,通过计算精确率(Precision)与召回率(Recall)评估方法的性能。召回率反映了所有存在的邻接关系中被正确判别的比例,而精确率反映了检测到的邻接关系中判别正确的比例。评价指标如式(18)~(20)所示:
其中:cnum表示正确的邻接关系的数量;tnum表示全部邻接关系的数量;dnum表示检测到的邻接关系的数量。
图8(a)为真实标签,一共有31 个正确的邻接关系;图8(b)代表预测结果,预测出的正确邻接关系24 个,预测出的邻接关系29 个,错判标签4 个。根据图8 给出的示例进行评价指标的计算,得到召回率、精确率、F1 值为0.774、0.857与0.813。

图8 真实标签与预测标签Fig.8 True label and predicted label
3.2 实验环境与训练参数
本文实验环境为:Ubuntu 16.04、Tesla P4 GPU、CUDA 10.1、python 3.7、pytorch1.7.1。训练使用交叉熵损失函数,采用Adam 优化器,初始学习率设为5× 10-4,采用梯度衰减学习率的方法,每30 轮学习率衰减为原来的1/5。
3.3 实验结果
3.3.1 对比实验
为验证GEAN 作为主干网时的模型效率,在其他条件不变的情况下,将GEAN 替换为其他几个常用的图网络模型进行对比,结果如表1 所示。其中,图卷积网络(GCN)与动态图卷积神经网络(Dynamic Graph Convolutional Neural Network,DGCNN)均为常用的图网络模型。结果显示,在相同的实验条件下,以GEAN 作为主干网与其他模型相比,模型大小、参数量和预测平均用时比较接近,说明了GEAN 具备良好的效果。
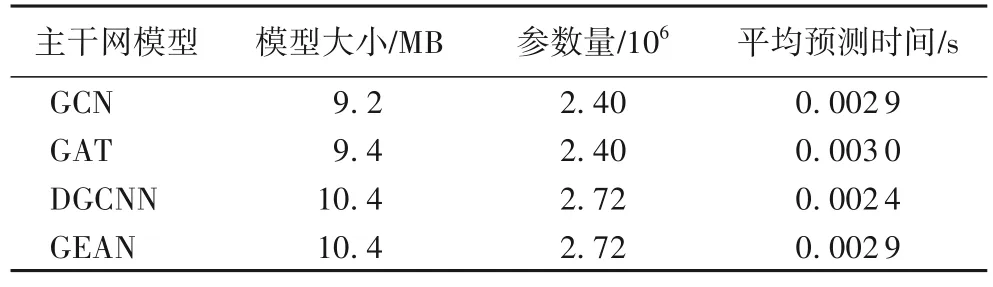
表1 不同主干网模型效率对比Tab.1 Model efficiency comparison with different backbone networks
为验证GEAN-TSR 的有效性,与其他表格结构识别模型进行对比,实验结果如表2 所示。其中:Tabby[4]是基于启发式算法的表格结构识别模型;DeepDeSRT(Deep learning for Detection and Structure Recognition of Tables)[16]、GraphTSR(Graph neural network for Table Structure Recognizes)[17]、SEM(Split,Embed and Merge)[18]、TabStruct-Net(Table Structure Network)[19]则是基于深度学习方法的表格结构识别模型。对比实验表明,GEAN-TSR 在召回率与F1 指标上均有明显提升。SciTSR-COMP 是从SciTSR 数据集中筛选出的复杂数据集,该数据集更能体现模型面对复杂表格结构时的表达能力,在SciTSR-COMP 数据集上,相较于目前最优的SEM 模型,GEAN-TSR 的召回率与F1 值分别提高了2.5 和1.4 个百分点,验证了GEAN-TSR 在复杂结构上的有效性。
为了验证本文模型的泛化能力,将所有模型在SciTSR数据集上训练,然后在ICDAR 2013 数据集进行测试。ICDAR 2013 数据集中的数据出自政府文件,与SciTSR 数据集具有较大差异性,因此该实验的结果能够从一定程度上反映模型的泛化能力。从表2 可以看出,与其他模型相比,GEAN-TSR 拥有更好的泛化能力,在训练集均为SciTSR 数据集时,在ICDAR 2013 数据集上大部分指标都取得了最优值。

表2 训练集为SciTSR时,不同模型在不同测试集上的评价指标对比Tab.2 Comparison of evaluation indicators of different models on different test sets when training set is SciTSR
3.3.2 消融实验
为了验证不同模块的有效性,设计了针对不同模块的消融实验。消融实验将模型分解为特征提取主干网络GEAN、文本特征融合、边特征融合三个模块。GEAN-TSR 在SciTSR、PubtabNet 数据集下的消融实验结果如表3 所示。由消融实验可知,相较于DGCNN 作为主干网络,GEAN 作为主干网时模型在各个指标上均有一定提升,这说明融合注意力的GEAN 优于DGCNN。在GEAN 作为主干网的基础上,分别融合文本与位置信息模块,融合后的网络相较于基础的GEAN 在三个指标上均有提升,验证了文本特征与边特征两个模块的有效性。而融合文本特征与边特征的GEAN 在各个指标上表现最佳,说明文本与边特征模块的融合互不冲突,能够共同作用使模型达到最佳性能。

表3 消融实验结果Tab.3 Ablation experiment results
4 结语
基于图网络的表格结构识别模型能够在对表格进行图模型建模的同时输出表格的结构信息。但目前用于表格结构识别的图网络模型仍存在两个问题:1)图网络模型面对复杂表格结构表达能力不足;2)图网络在推理过程中会造成局部结构信息丢失。针对上述问题,本文提出图边注意力网络(GEAN)作为主干网络提取特征,并提出一种融合边特征与注意力的表格结构识别模型(GEAN-TSR)。GEAN 在边卷积图网络模型的基础上引入注意力机制,有效增强了图网络在表格结构识别任务中的表达能力。此后,引入边特征与文本特征融合模块,补足了图网络推理过程中损失的局部结构信息,有效提升了模型性能。
对比实验表明,GEAN-TSR 相较于其他模型,能够有效提升表格结构识别任务的效果,同时具有一定的泛化能力,在面对复杂表格结构时,也能达到较好的效果。消融实验验证了GEAN 的性能以及特征融合模块的必要性。
目前数据集的位置信息标签局限于文本框,而不是单元格的位置信息,这样的监督信息很可能对模型的学习造成负面影响,因此,在未来的实验中可以尝试使用图像处理或深度学习的方法增强位置信息以覆盖整个单元格,由此提高模型在表格结构识别任务上的性能。
猜你喜欢
现代临床医学(2022年5期)2022-09-28
小雪花·成长指南(2022年1期)2022-04-09
现代临床医学(2022年1期)2022-02-12
电脑爱好者(2021年8期)2021-04-21
数学大王·趣味逻辑(2020年6期)2020-06-22
数学大王·趣味逻辑(2020年5期)2020-06-19
文化创新比较研究(2020年13期)2020-01-01
西部皮革(2018年6期)2018-05-07
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
