
面向交通场景解析的局部和全局上下文注意力融合网络
2023-03-24 13:24王泽宇布树辉黄伟郑远攀吴庆岗张旭
计算机应用 2023年3期
王泽宇,布树辉,黄伟,郑远攀,吴庆岗,张旭
(1.郑州轻工业大学 计算机与通信工程学院,郑州 450002;2.西北工业大学 航空学院,西安 710072)
0 引言
场景解析[1]作为计算机视觉方向的基础工作,它的核心技术问题是如何准确地为图像中的每个像素分类。高精度的场景解析对于机器人任务规划[2]、自动驾驶[3]以及语义SLAM(Simultaneous Localization And Mapping)[4]等智能计算机视觉任务的实现至关重要。真实的场景复杂多变,特别是交通场景,图像中不仅包含多个不同类别的物体,而且物体的空间位置并不固定。因此,高精度的场景解析需要解决如下3 个问题:1)如何有效地提取图像中物体的视觉外观信息;2)如何准确地推理物体的全局上下文信息;3)如何自适应地完成上述两类特征的融合。
文献[5]首次基于卷积神经网络(Convolutional Neural Network,CNN)提出面向场景解析的全卷积网络(Fully Convolutional Network,FCN),并通过有效的视觉特征提取获得巨大成功。但是,CNN 卷积核的感知域较小,空间结构化学习能力较弱,提取的视觉特征一般缺少全局上下文信息。条件随机场(Conditional Random Field,CRF)作为CNN 的后端,通过优化图模型上定义的能量函数,使特征相近的相邻物体类别相同,相差较大的类别不同,从而实现场景解析的一致性和平滑性优化[6]。另外,由于具有门和存储结构的长短期记忆(Long Short-Term Memory,LSTM)网络可以模拟人脑的机制记忆和遗忘信息,因此将LSTM 加入CNN 的后端,从而通过逐像素地遍历图像视觉特征以获取物体间的空间依赖关系[7]。此外,PSPN(Pyramid Scene Parsing Network)[8]、DASPP(Densely connected Atrous Spatial Pyramid Pooling)[9]、DeepLab(Deep Labelling)[10]和多层 多尺度 注意力网络(Hierarchical Multi-scale Attention Network,HMAN)[11]等方法通过具有多尺度感受野的空洞空间金字塔池化单元提取物体所处场景的局部和全局上下文信息,避免了单一视觉特征可能导致的分类错误。但是,上述方法在上下文信息推理过程中没有充分考虑全局场景的空间结构化特征与局部对象自身的视觉外观特征间的相关性,导致全局噪声信息融入视觉特征当中,影响分类特征的鲁棒性。
为了解决此问题,基于注意力机制[12]的全局上下文信息推理方法[13-31]在场景解析研究中应用广泛。文献[13]中提出了基于空间和通道注意力模块的双注意力网络(Dual Attention Network,DAN),根据物体的视觉外观特点自适应地聚合全局上下文信息。门控金字塔网络(Gated Pyramid Network,GPN)[19]通过门控金字塔模块过滤全局噪声信息,保证了融合生成特征的质量。上下文先验网络(Context Prior Network,CPN)[16]内嵌基于亲和损失的上下文先验层,根据亲和损失监督学习的上下文先验知识有选择性地获取类别内和类别间的上下文依赖关系,从而提升特征表示的鲁棒性。语义约束的注意力细化网络(Semantic Constrained Attention Refinement Network,SCARN)[18]通过语义约束的注意力机制有效地学习类别内的上下文依赖关系,有效地增强了整个物体特征信息的一致性。另外,对象上下文表示网络(Object Contextual Representation Network,OCRN)[14]基于对象上下文表示实现像素上下文的有效聚合。该方法首先初步分割场景中的物体并聚合得到对象上下文表示;然后计算像素自身特征与场景中每个对象上下文表示的相关性;最后根据相关联程度自适应地聚合对象上下文信息,从而有效地增强每个像素的特征表示,并取得较优的场景解析准确率。但是,上述方法未充分考虑全局场景的空间结构化特性,如:骑手和行人的上方一般是天空,而骑手和行人的下方分别是自行车和道路,如何有效地聚合骑手和行人下方的上下文信息是区分骑手和行人的关键。而现有方法直接自适应聚合所有像素的上下文信息,从而由于依赖关系过度复杂而无法有效聚合有用上下文信息并屏蔽噪声上下文信息,进而影响聚合后特征表示的质量,甚至导致分类错误。
本文面向复杂交通场景提出局部和全局上下文注意力融合网络(Local and Global Context Attentive Fusion Network LGCAFN),LGCAFN 由特征提取模块、结构化学习模块和特征融合模块构成。主要工作如下:
1)基于串联空洞空间金字塔池化(Cascaded Atrous Spatial Pyramid Pooling,CASPP)单元改进了ResNet-101[32],通过增大感知域来提取物体不同尺度的局部上下文信息。
2)通过8 路LSTM 分支分别在8 个不同的方向上逐像素地遍历多尺度局部特征,从而显式地学习8 个不同场景区域的全局上下文信息,推理生成的空间结构化特征能够全面而准确地描述全局场景的结构化特性。
3)将物体邻近8 个不同场景区域的全局上下文信息与它自身局部视觉外观信息的相关性进行加权特征融合,自适应聚合生成的多模态融合特征能够高质量地表达物体的综合语义信息。
在Cityscapes 数据集[33]上进行对比实验,实验结果表明,LGCAFN 能够提升交通场景解析的准确率。
1 局部和全局上下文注意力融合网络
LGCAFN 共包含3 个部分:特征提取模块、结构化学习模块和特征融合模块。特征提取模块由ResNet-101 构成,在此基础上,修改ResNet-101 第2~5 层的结构为CASPP,从而通过级联改进ResNet-101 各层的输出特征,以提取物体的多尺度局部特征。结构化学习模块由8 路LSTM 分支组成,8 路LSTM 分支分别在8 个不同的方向上逐像素地遍历多尺度局部特征,从而学习物体邻近8 个不同场景区域的全局上下文信息,进而推理生成空间结构化特征。特征融合模块采用3阶段特征融合方式对物体的多尺度局部特征和空间结构化特征依次进行基于多层卷积操作的降维融合、基于注意力机制的加权融合以及基于反池化和反卷积操作的解码融合,最后利用Softmax 分类器根据自适应聚合的多模态融合特征逐像素地标注交通场景类别。LGCAFN 的框架如图1 所示。
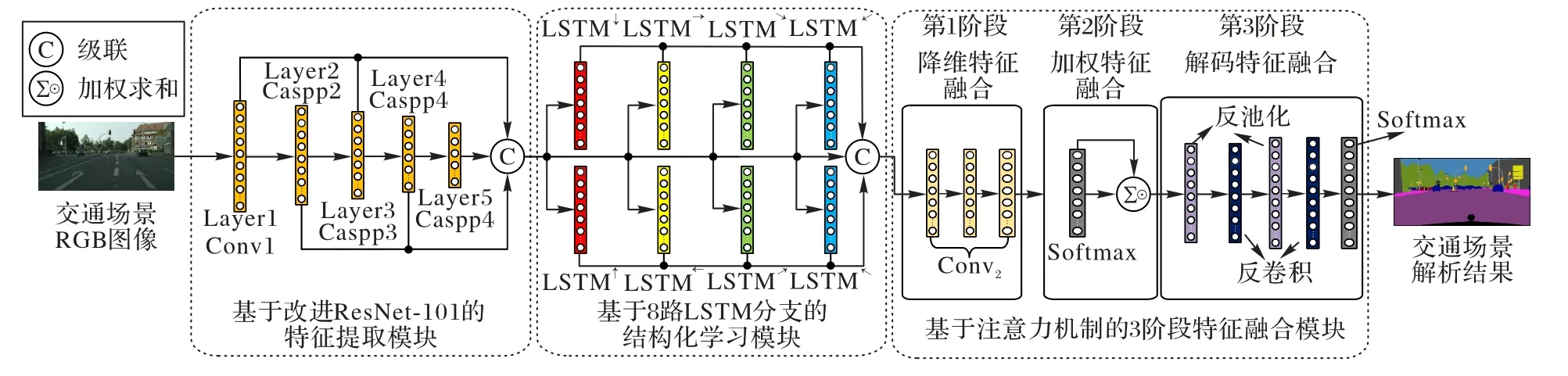
图1 局部和全局上下文注意力融合网络Fig.1 Local and global context attentive fusion network
1.1 基于串联空洞空间金字塔池化单元的特征提取模块
特征提取模块通过改进的ResNet-101 提取输入RGB 图像的多尺度局部特征(Multi-scale Local Features,MLF),图2为多尺度局部特征的提取过程。原始的ResNet-101 共包含5层:第1 层由7×7 卷积操作(Conv)和3×3 最大池化操作(maxpool)组成;第2~5 层分别由两类残差卷积单元(Residual Convolution Unit,RCU)构成,RCU1 和RCU2 均由1×1、3×3 和1×1 卷积操作堆叠而成[32]。为进一步增大特征提取模块的感知域,将ResNet-101 第1 层中7×7 卷积改为空洞卷积操作,并修改RCU1、RCU2 内的3×3 卷积操作为稀疏采样率可自设定的空洞卷积操作,从而改进ResNet-101 第2~5层为稀疏采样率顺序递增的CASPP。
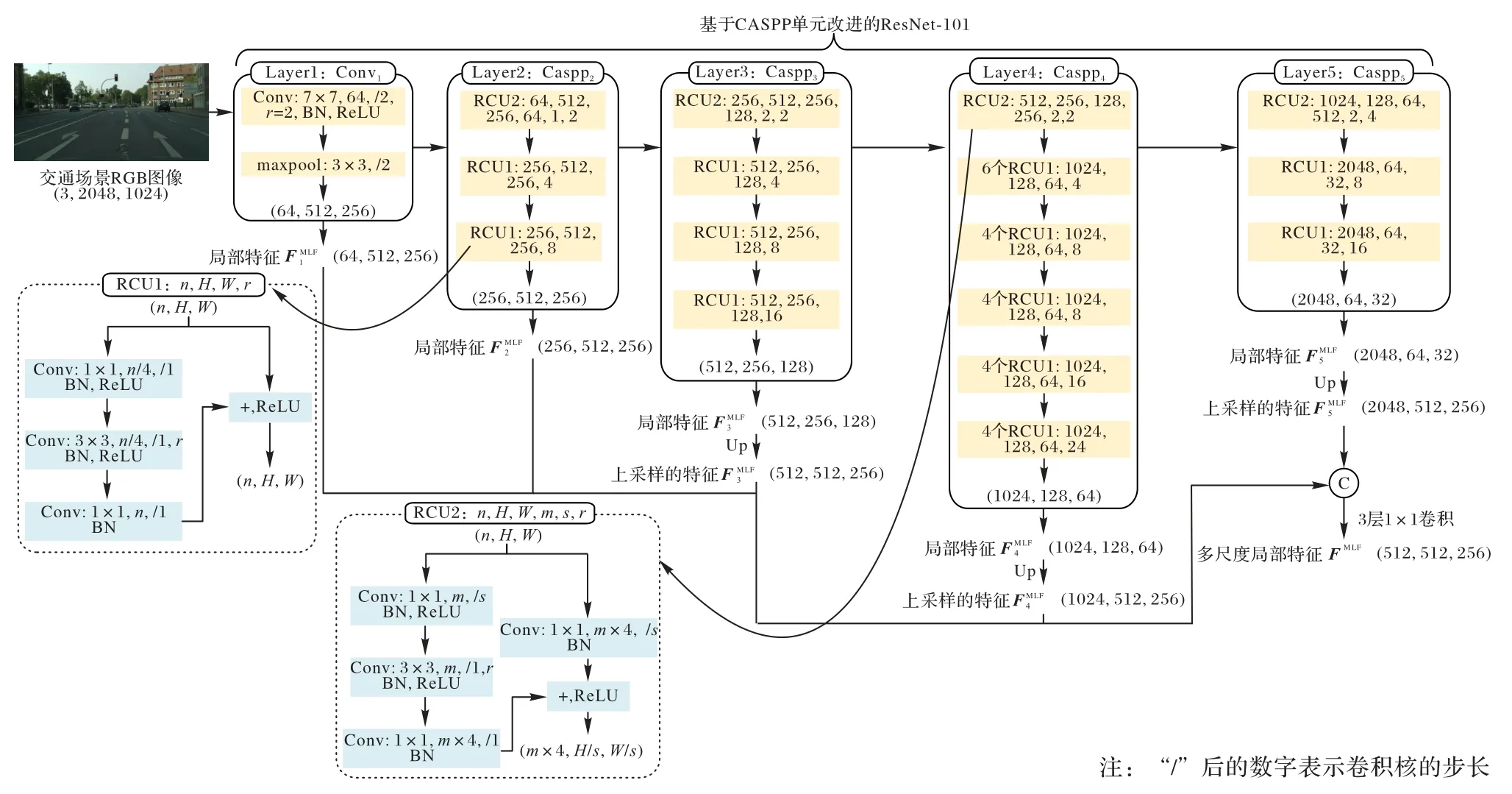
图2 基于CASPP单元的特征提取模块Fig.2 Feature extraction module based on CASPP unit
特征提取模块采用端到端的方式逐层提取特征,模块中第l层的输出特征可以定义为如下形式:
其中:I为输入RGB 图像;FlMLF为特征提取模块第l层的输出特征;Conv1和maxpool 为第1 层中的7×7 空洞卷积与3×3 最大池化;r1为Conv1的稀疏采样率;Casppl为第l层CASPP 单元对应的操作;rl为Casppl中3×3 卷积对应的稀疏采样率组。
为了提取RGB 图像的多尺度局部特征,首先通过上采样提取各层的输出特征,使新生特征尺寸为输入图像尺寸的1/4,然后级联各层上采样后的特征并送入多层卷积操作进行特征降维,从而生成RGB 图像的多尺度局部特征FMLF:
其中:Conv2表示3层1×1 卷积操作;n、H/4和W/4分别为多尺度局部特征的维数、高度和宽度;表示上采样操作,nl为特征提取模块第l层输出特征的维数。
多尺度局部特征中的像素(i,j)的特征可以表示为:
为了提取物体高质量的视觉特征表示,本文在特征提取模块各层采用稀疏采样率顺序递增的CASPP 单元,以显著地增大特征提取模块的感知域,从而使模块各层的输出特征包含更加丰富的局部上下文信息。通过级联各层输出特征得到的多尺度局部特征由物体不同抽象级别的局部上下文信息组成,能够更加准确地描述物体的视觉外观特点。
1.2 基于8路长短期记忆网络分支的结构化学习模块
为有效学习全局场景的空间结构化特性,将物体所处全局场景划分为上、下、左、右、左上、右下、右上和左下8 个不同区域,并采用8 路LSTM[7]分支显式地推理物体邻近8 个不同区域的全局上下文信息,进而通过级联不同区域的上下文信息获取物体的空间结构化特征(Spatial Structural Features,SSF)。图3 为SSF 的推理过程。8 路LSTM 分支均包含5 层单向的LSTM 单元,分别在8 个不同方向上逐像素遍历特征提取模块输出的多尺度局部特征:1)从上到下(↓);2)从下到上(↑);3)从左到右(→);4)从右到左(←);5)从左上到右下(↘);6)从右下到左上(↖);7)从右上到左下(↙);8)从左下到右上(↗)。结构化学习模块的处理流程可表示为如下形式,其中,b∈Z:
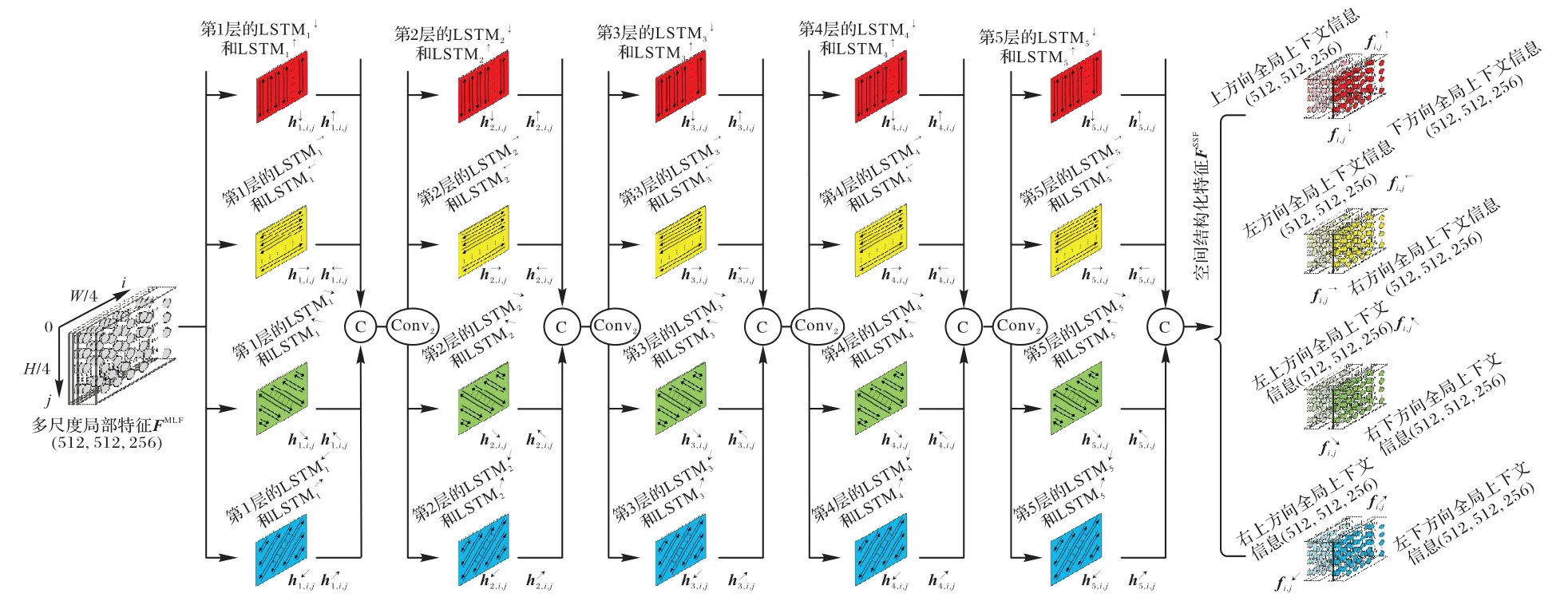
图3 基于8路LSTM分支的结构化学习模块Fig.3 Structural learning module based on eight LSTM branches
其中:LSTMl↓(LSTMl↑)为从上(下)到下(上)遍历分支中的第l层LSTM 单元的操作,对图像中每列i=b按j值递增(递减)的顺序逐像素遍历;LSTMl→(LSTMl←)为从左(右)到右(左)遍历分支中的第l层LSTM 单元的操作,对图像中每行j=b按i值递增(递减)的顺序逐像素遍历;LSTMl↘(LSTMl↖)为从左上(右下)到右下(左上)遍历分支中的第l层LSTM 单元的操作,对图像中每条斜线i=j-b按j值递增(递减)的顺序逐像素遍历;LSTMl↙(LSTMl↗)为从右上(左下)到左下(右上)遍历分支中的第l层LSTM 单元的操作,对图像中每条斜线j=-i+b按i值递减(递增)的顺序逐像素遍历;hl,i,j↓、hl,i,j↑、hl,i,j→、hl,i,j←、hl,i,j↘、hl,i,j↖、hl,i,j↙和hl,i,j↗分别表示第l层LSTMl↓、LSTMl↑、LSTMl→、LSTMl←、LSTMl↘、LSTMl↖、LSTMl↙和LSTMl↗的隐藏层状态;dl为第l层各LSTM单元隐藏层状态的维数;多尺度局部特征fi,jMLF表示第1 层各LSTM 单元的输入;hl-1,i,j表示第(l2≤l≤5)层各LSTM 单元的输入特征,它由第l-1 层各LSTM 单元隐藏层状态级联降维构成。
假设从上到下遍历分支中的第l层LSTMl↓,对于遍历到的像素(i,j),LSTMl↓计算它的全局上下文信息(隐藏层状态)hl,i,j↓的过程可以定义为如下形式:
物体的空间结构化特征由邻近8 个不同区域(上、下、左、右、左上、右下、右上和左下)的全局上下文信息组成,能够全面而准确地描述物体所处全局场景的空间结构化特性。当语义类别间的物体具有相似的视觉外观信息时(如行人和骑手),LGCAFN 就可以结合物体邻近场景区域的全局上下文信息准确地区分物体的类别;同时,当语义类别内的物体整体特征信息不一致时(如地面上有树影的马路),LGCAFN又能够依据物体所处全局场景的结构化特性避免分类错误。
1.3 基于注意力机制的3阶段特征融合模块
经过特征提取模块和结构化学习模块的学习,LGCAFN分别生成物体的多尺度局部特征MLF 和空间结构化特征SSF。为了实现上述2 类模态特征的自适应融合,本文首先采用多层卷积操作将物体的多尺度局部特征依次与8 个邻近场景区域推理的空间结构化特征进行第1 次降维融合,从而有效地挖掘2 类特征之间存在的复杂非线性关系;然后,根据2 类模态特征之间的相关性自适应地赋予8 个不同方向上的降维融合特征对应的权重,并基于注意力机制对8 个方向上的降维融合特征进行第2 次加权融合,从而有效地实现物体邻近8 个不同场景区域上下文信息的自适应聚合;最后,将加权融合特征和特征提取模块前2 层输出的低抽象级别局部特征级联,并通过多层反池化和反卷积操作进行第3次解码融合,从而准确地解码还原出每个像素的综合化语义信息。图4 展示了特征融合模块的原理。

图4 基于注意力机制的3阶段特征融合模块Fig.4 Three-stage feature fusion module based on attention mechanism
首先,将每个像素(i,j)的多尺度局部特征依次与8 个方向上推理的空间结构化特征级联,并采用共享参数的3 层1×1 卷积操作对8 个方向上级联的混合特征作第1 次降维融合,可以表示为如下形式:
然后,利用Softmax 函数分别计算不同方向上的降维融合特征对应的注意力权重
其中:e2为注意力权重的维数;[0,1]为权重的取值范围。
对8 个不同方向上的降维融合特征进行加权求和,从而生成以下特征:
最后,本文级联加权融合特征和特征提取模块前2 层输出的低抽象级别局部特征,并通过反池化和反卷积操作解码还原出物体的多模态融合特征(Multi-modal Fusion Features,MFF),进而利用Softmax 函数对RGB 图像逐像素地标注语义类别。上述解码融合过程可以表示为如下的形式:
其中:unpool 表示反池化操作;deconv 表示反卷积操作;FMFF表示RGB 图像的多模态融合特征;e3表示多模态融合特征的维数;F1MLF和F2MLF分别表示特征提取模块第1 和2 层的输出特征;P表示语义分类概率;K表示语义类别个数。
本文的特征融合模块不仅能够准确地聚合有用的上下文信息,而且可以有效地避免全局噪声信息的引入,聚合生成的多模态融合特征不仅含有物体自身的视觉外观信息,而且包含与它相关性较高的邻近场景区域的全局上下文信息,从而较为准确地表示物体的综合语义。
2 实验与结果分析
2.1 训练数据集和性能评价标准
为了评价LGCAFN,在标准交通场景RGB 数据集Cityscapes[33]上进行性能测试。Cityscapes 数据集共包含5 000 张高分辨率(1 024×2 048)的交通场景图像,训练、验证与测试图像分别有2 975、500、1 525 张。该数据集共包含9.43×109个细粒度标注的像素,被标记为19 个交通场景语义类别。为进一步提升网络性能,使用Cityscapes 扩展数据集[11]进行训练,扩展集包含20 000 张自动标注的图像,从而确保各语义类别分布的均衡性。另外,使用平均交并比(mean Intersection over Union,mIoU)评价场景解析[5]。
2.2 实验环境和参数设置
本文基于开源的深度学习开发框架TensorFlow[34]编码实现LGCAFN,并在一台2 颗2.4 GHz Intel Xeon Silver 4214R CPU(2×12 Cores),24 GB NVIDIA GeForce GTX 3090 GPU 以及128 GB 内存的计算机上进行训练和测试。在训练阶段,本文定义目标函数为多类别交叉熵损失[5],并利用反向传播算法[35]实现LGCAFN 各层的联合优化。
在特征提取模块通过CASPP 单元改进的ResNet-101[32]提取物体的多尺度局部特征。首先,设定网络第1 层内7×7卷积操作的稀疏采样率为2;并设定第2~5 层中3×3 卷积操作组对应的稀疏采样率组分别为(2,4,8),(2,4,8,16),(2,4_6,8_4,8_4,16_4,24_4)和(4,8,16)。随后使用ImageNet数据集训练的公用参数模型resnet_v1_101_2016_08_28[32]初始化特征提取模块的参数,同时设置该模块的学习率为5×10-4;上采样改进ResNet-101 各层的输出特征,各层输出特征的维数分别为64、256、512、1024 和2 048;最后,级联各层上采样后的特征,并将级联后的特征送入3 层1×1 卷积进行降维,各卷积层输出特征的维数分别为2 048、1 024 和512。
在结构化学习模块,本文通过8 路LSTM 分支学习物体邻近8 个不同场景区域的全局上下文信息,从而生成空间结构化特征。每路LSTM 分支均由5 个单向的LSTM 单元堆叠而成,各单向LSTM 单元输出的隐藏层状态的维数分别为512、256、128、256 和512。本文在[-0.05,0.05]的均匀分布下随机地初始化8 路LSTM 分支的网络参数,并设定结构化学习模块的学习率为10-3。
在特征融合模块,本文首先通过级联的3 层1×1 卷积操作将多尺度局部特征依次与8 个邻近场景区域内学习的空间结构化特征进行第1 次降维融合,各卷积层输出特征的维数分别为512、256 和256;然后,利用Softmax 分别计算8 个方向上降维融合特征对应的注意力权重,并基于注意力机制对8 个方向上的降维融合特征加权求和,从而完成第2 次加权融合;接着,级联加权融合特征和特征提取模块第1、2 层输出的低抽象级别局部特征,并通过2 层2×2 反池化和3×3 反卷积操作对级联后的特征进行第3 次解码融合,解码生成的多模态融合特征的维数为128;最后,利用Softmax 分类器并根据多模态融合特征逐像素地标注RGB 图像的语义标签。本文在均值为0、标准差为0.05 的正态分布下初始化各卷积层的网络参数,同时设置特征融合模块的学习率为5×10-4。
在完成LGCAFN 的网络参数和学习率配置后,设置LGCAFN 的训练 参数为:batch_size=8,momentum=0.9,weight_decay=10-4,epoch=500,并采用随机梯度下降算法[36]优化LGCAFN 的网络参数。
在测试阶段,本文将测试图像依次输入LGCAFN,并在LGCAFN 的网络参数指导下依次输出图像的场景解析结果。
2.3 实验结果与分析
2.3.1 与当前先进方法的对比实验结果
在Cityscapes 原始数据集上,将LGCAFN 与OCRN[14]、基于空间金字塔的图推理网络(Spatial Pyramid Based Graph Reasoning Network,SPBGRN)[15]、CPN[16]、语义边界增强和定位网络(Semantic Boundary Enhancement and Position Network,SBEPN)[17]、SCARN[18]、GPN[19]、通道化轴向注意力网络(Channelized Axial Attention Network,CAAN)[20]、行列注意力网络(Row-Column Attention Network,RCAN)[21]、上下文集成网络(Contextual Ensemble Network,CEN)[22]和统计纹理学习网络(Statistical Texture Learning Network,STLN)[29]等方法进行比较;添加了Cityscapes 扩展数据集后,将LGCAFN 与HMAN[11]、扩展残 差网络(Scaling Wide Residual Network,SWRN)[30]和逆变 换网络(Inverse Transformation Network,ITN)[31]等进行比较。HMAN、OCRN、RCAN 和ITN 等采用HRNet-W48(48-Width High Resolution Network)[37]作为主干网 络,SWRN采用SWideRNet-(1,1,4.5)(Scaling Wide Residual Network with factors(1,1,4.5))[30]作为主干网络,其他方法采用ResNet-101 作为主干网络。对比结果如表1所示。
在仅使用Cityscapes 原始数据集进行训练时,LGCAFN的平均mIoU 为84.0%,相较于次优的OCRN 提升了0.7 个百分点,而且在12 种语义类别上的mIoU 取得了最优。使用Cityscapes 扩展数据集后,LGCAFN 的平均mIoU 为86.3%,取得了最优;同时在14 种类别的mIoU 取得了最优。值得注意的是:1)LGCAFN 在围栏、杆、信号灯和交通标识等尺寸较小的语义类别上均取得了最优的mIoU,一方面说明基于CASPP 单元的特征提取模块能够有效地保留尺寸较小物体的视觉细节信息;另一方面说明基于注意力机制和解码结构的特征融合模块不仅能准确聚合有用的局部和全局上下文信息,而且能有效避免引入全局噪声信息,确保聚合生成的多模态融合特征的鲁棒性。2)LGCAFN 在较易混淆的语义类别(如行人和骑手、摩托车和自行车)上也取得了最优的分割结果,一方面说明基于8 路LSTM 分支的结构化学习模块能准确学习物体邻近8 个不同场景区域的全局上下文信息;另一方面也说明基于注意力机制的特征融合模块可以根据物体自身局部特征和所处场景全局特征的相关性自适应地聚合有用上下文信息。相较于先进方法,LGCAFN 能够更加有效地自适应聚合物体所处全局场景的上下文信息,生成的特征表示可以更加全面准确地表达物体的综合语义信息。
本文以浮点数参数量和解析1 024×2 048 分辨率图像所需浮点运算量作为网络模型复杂度的评价标准,不同方法的对比结果如表2 所示。可以看出,LGCAFN 不仅具有最小的参数量,而且具有较低的单帧图像预测运算量,说明LGCAFN 模型尺寸较小且预测延迟较低。另外,LGCAFN 具有最优的mIoU,从而证明LGCAFN 可以较好地平衡准确性和复杂度。
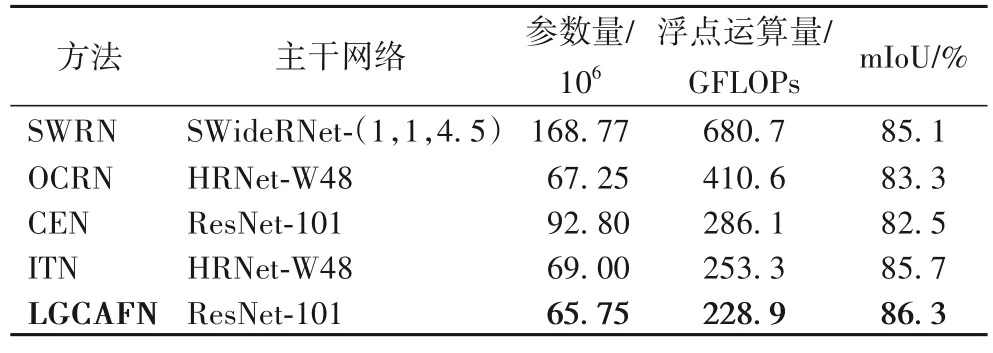
表2 在Cityscapes数据集的模型复杂度对比Tab.2 Model complexity comparison on Cityscapes dataset
2.3.2 消融学习
在表3 中,Baseline 为原始ResNet-101,Baseline+CASPP表示加入CASPP 单元模型,Baseline+CASPP+LSTM 表示添加基于8 路LSTM 分支的结构化学习模块后的模型,Baseline+CASPP+LSTM+Attention 为添加基于注意力机制的模型。

表3 Cityscapes数据集上的消融学习 单位:%Tab.3 Ablation study on Cityscapes dataset unit:%
可以看出:1)相较于Baseline,Baseline+CASPP 的mIoU提高2.8 个百分点,说明CASPP 单元能够显著增大特征提取模块的感知域,使提取的多尺度局部特征能够更加准确地描述物体的视觉外观特点;2)相较于Baseline+CASPP,Baseline+CASPP+LSTM 的mIoU 提高了2.4 个百分点,说明结构化学习模块能通过8 路LSTM 分支显式地学习物体邻近8个不同场景区域的全局上下文信息,推理生成的空间结构化特征能更加准确地描述物体所处全局场景的结构化特性;3)Baseline+CASPP+LSTM+Attention 取得了最优的mIoU,说明基于注意力机制的3 阶段特征融合模块不仅能自适应地聚合物体邻近8 个场景区域的有效上下文信息,而且能避免引入相关性较弱的全局噪声信息,聚合生成的多模态融合特 征能更加准地表达物体的综合语义信息。
2.3.3 特征提取模块的稀疏采样率设置学习
假设特征提取模块(基于CASPP 单元改进的ResNet-101)中第1 层的7× 7 大小的空洞卷积的稀疏采样率为r1,第2 到5 层中的3× 3 大小的空洞卷积组对应的稀疏采样率组依次为r2、r3、r4和r5。本文在Cityscapes 原始数据集(不包含扩展数据集)上学习不同的稀疏采样率设置ResNet-101(r1,r2,r3,r4,r5)对特征提取模块的性能影响,如表4 所示。由于ResNet-101 第4 层中共包含多达23 个3× 3 空洞卷积,因此本文将它们分为6 组,每组的空洞卷积个数分别为1、6、4、4、4 和4(用下划线后的数字表示),并为每组空洞卷积设置相同的稀疏采样率(用下划线前的数字表示)。
从表4 可以看出:1)如果为所有空洞卷积均设置相同的稀疏采样率(方法1),随着稀疏采样率由1 逐步增大到8,模块的mIoU 由77.6%逐步提升到78.9%,说明增大采样率能够显著地增大卷积核的感知域,从而获取更丰富的局部上下文信息;但是,如果稀疏采样率设置为更大的16 或24,虽然卷积核的感知域进一步增大,但是模块的性能却开始下降,说明在较低层次的ResNet-101 中,如果稀疏采样率过大,即卷积核的感知域过大,会无法有效地学习物体的视觉细节信息,从而影响特征表示的质量。2)仅为ResNet-101 每层中的空洞卷积组设置相同的稀疏采样率(方法2),而对于不同层中的空洞卷积,在较低层次则设置较小的采样率,反之设置较大的采样率。相较于方法1 的ResNet-101(2,(4,4,4),(8,8,8,8),(8,8_6,8_4,8_4,8_4,8_4),(16,16,16)),方法2 的mIoU 提升了0.6 个百分点,说明该设置下的模块不仅能利用低层次网络中感知域较小的空洞卷积提取物体的视觉细节信息,而且可以通过高层次网络中感知域较大的空洞卷积获取物体的局部上下文信息。3)为ResNet-101 每层中的空洞卷积组设置顺序递增的稀疏采样率(方法3),即将各层的结构修改为CASPP 单元。相较于前2 种方法,方法3 取得了最优的性能,说明基于CASPP 单元的特征提取模块能有效地避免特征提取过程中有用视觉信息的丢失,从而更加全面地表达物体的视觉特点。
2.3.4 结构化学习模块的消融学习
在Cityscapes 数据集(不包含扩展数据集)上通过消融学习验证3 种不同的LSTM 遍历方式对LGCAFN 的性能影响,结果如表5 所示。可以看出:相较于前2 种遍历方式,第3 种遍历方式取得了最优的mIoU,说明基于8 路LSTM 分支的结构化学习模块可以显式地学习物体邻近8 个不同场景区域的全局上下文信息,推理生成的空间结构化特征能够更加准确地表达物体所处全局场景的结构化特性。
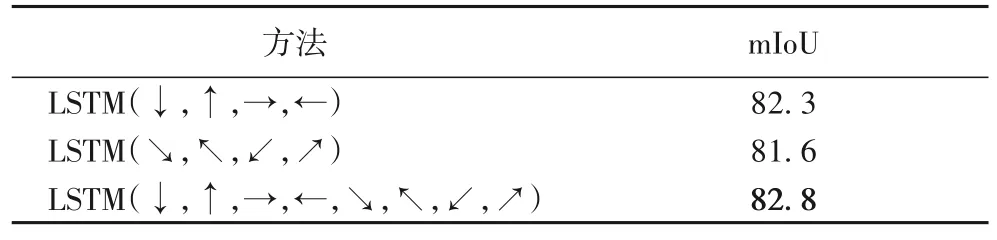
表5 不同LSTM遍历方式对性能的影响 单位:%Tab.5 Effect of different LSTM traversal methods on performance unit:%
2.3.5 特征融合模块的消融学习
在Cityscapes 数据集(不包含扩展数据集)上通过消融学习验证3 种不同融合方式对LGCAFN 的性能影响,如表6 所示。Concatenation 为直接级联多尺度局部特征和空间结构化特征后送入6 层1×1 卷积操作进行融合的方式;Elementwise addition 为替换特征融合模块中第2 次加权融合为点加融合的方式,即令各方向上的注意力权重相同;Attention mechanism 表示本文的基于注意力机制的3 阶段融合方式。
从消融学习中可以发现:基于注意力机制的3 阶段特征融合方式使LGCAFN 取得最优的mIoU,说明本文的特征融合方式不仅能够有效地挖掘多尺度局部特征和空间结构化特征之间存在的复杂非线性关系,而且可以根据2 类模态特征之间的相关性自适应地聚合有用信息和屏蔽噪声信息,进而基于低抽象级别的视觉细节信息确保解码还原的综合语义信息的质量。
2.3.6 Cityscapes数据集上的场景解析视觉效果
LGCAFN 在Cityscapes 数据集上的场景解析视觉效果如图5 所示,图5(d)为LGCAFN 的预测结果与真值之间的误差。可以看出:1)相较于ResNet-101,LGCAFN 的场景解析结果更接近Ground Truth,LGCAFN 不仅能更加清晰地分割物体轮廓,而且可以更加准确地标记语义类别,从而再次证明了LGCAFN 的优势;2)LGCAFN 不仅能够有效地解析尺寸较小的物体(如杆、信号灯和交通标识,实线框标记),而且可以准确地区分易混淆的语义类别(如行人和骑手、摩托车和自行车、汽车和卡车,虚线框标记),从而再次证明特征提取模块有效提取尺寸较小的物体的视觉细节信息的能力、结构化学习模块显式推理全局上下文信息的能力以及特征融合模块自适应聚合上下文信息的能力。

图5 Cityscapes数据集上LGCAFN的场景解析视觉效果Fig.5 Scene parsing visual effects of LGCAFN on Cityscapes dataset
综上所述,LGCAFN 在交通场景解析上获取的成功可以归纳为如下3 点:1)基于CASPP 单元的特征提取模块不仅可以有效地学习更加丰富的局部上下文信息,而且能够避免局部细节信息的丢失,提取的多尺度局部特征能更准确地描述物体的视觉外观特点;2)基于8 路LSTM 分支的结构化学习模块能显式地学习物体邻近8 个不同场景区域的全局上下文信息,推理生成的空间结构化特征可以更加准确地描述物体所处全局场景的结构化特性;3)基于注意力机制的3 阶段特征融合模块能够有效地根据2 类模态特征间的相关性自适应地聚合有用上下文信息和屏蔽噪声上下文信息,聚合生成的多模态融合特征能够更加准确地表达物体的综合语义。
3 结语
本文提出了面向交通场景解析的LGCAFN,不仅能有效学习物体自身的视觉外观信息和所处场景的全局上下文信息,而且可以基于注意力机制自适应地聚合上述2 类信息,聚合生成的多模态融合特征能够更加全面且准确地表达物体的综合语义信息。实验结果表明,LGCAFN 在Cityscapes数据集上能准确地解析场景,有助于实现车辆自动驾驶、语义SLAM 等智能计算机视觉任务。但像素级标签的制作成本昂贵,因此后续将研究无监督领域自适应学习方法,使LGCAFN 能自适应更加复杂的现实交通场景解析任务。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
河北理科教学研究(2021年4期)2021-04-19
计算机教育(2020年5期)2020-07-24
电子制作(2018年19期)2018-11-14
金桥(2018年4期)2018-09-26
自动化学报(2017年11期)2017-04-04
计算机工程(2015年8期)2015-07-03
噪声与振动控制(2015年4期)2015-01-01
中国卫生(2014年5期)2014-11-10
