
基于YOLOv5的咖啡瑕疵豆检测方法
2023-03-21 13:08张成尧张艳诚张宇乾赵玉清
食品与机械 2023年2期
张成尧 张艳诚,2 张宇乾 赵玉清,2
(1. 云南农业大学机电工程学院,云南 昆明 650201;2. 云南省作物生产与智慧农业重点实验室,云南 昆明 650201)
咖啡瑕疵豆严重影响烘焙过程中咖啡的风味与品质,直接影响咖啡的出售价格。传统的咖啡瑕疵豆检测方法是通过人工目测筛选,劳动强度大、效率低、主观性大、评判标准不统一,难以保证咖啡品质[1-5]。随着图像技术的发展,将计算机视觉应用于咖啡瑕疵豆的检测成为了可能[6-7]。早期的计算机视觉研究大多基于机器学习方法,主要采用人工提取形状、颜色、纹理等特征,通过K近邻分类方法、支持向量机(SVM)和BP神经网络进行特征分类,实现咖啡瑕疵豆的检测[8]。Akbar等[9]利用随机森林和KNN方法,结合颜色和纹理视觉特征实现了阿拉比卡咖啡的品质分级。Pinto等[10]利用CNN模型对咖啡瑕疵豆进行分类,平均识别正确率为80%。目前深度学习已被应用于农业生产的各个方面[11-16]。宋怀波等[17]通过改进YOLOv5s中的卷积块并引入SE注意力机制模块实现了对重度黏连的小麦籽粒的检测。奉志强等[18]通过设计改进YOLOv5的特征提取模块并在主干网络中引入Transformer,提高了复杂背景下小目标的识别能力。胡根生等[19]基于改进YOLOv5网络实现了复杂背景图像中茶尺蠖的识别,识别准确率为92.89%。
综上,改进的YOLOv5算法在小目标检测、复杂背景等方面具有良好的表现,因此研究拟针对传统计算机视觉中,咖啡瑕疵豆检测网络模型深度不够导致精度不高,特征提取耗时耗力,以及咖啡瑕疵豆目标小、检测环境复杂等问题,结合深度学习在模型深度、小目标检测与复杂背景识别精度高等特点,提出一种以YOLOv5s为基线网络并嵌入CBAM注意力机制模块与Hardswish激活函数的咖啡瑕疵豆检测算法,旨在提高咖啡瑕疵豆识别准确率,以及在保证咖啡瑕疵豆检测准确率的基础上提高模型的检测速度,使模型更加轻量化,为后续基于深度学习的咖啡豆瑕疵检测算法部署到嵌入式设备提供依据。
1 材料与方法
1.1 试验数据制作
选用云南阿拉比卡小粒种咖啡生豆作为研究对象,使用佳能EOS 200DⅡ单反相机拍摄,拍摄时相机镜头距离咖啡豆60 cm,分别拍摄破损豆、霉菌豆、带壳豆(见图1)640像素×640像素尺寸各200张,采集的图片包含了单粒和多粒并记录各种豆子数量保证3种瑕疵豆总的数量相同,并对采集的数据集进行图像增强,扩充至2 400张图片,按照9∶1将各瑕疵豆随机分成训练集与验证集,同时检验训练集与验证集的瑕疵豆数量的比例是否接近9∶1,最后使用LabelLmg软件标注目标类别与目标位置,生成txt文件格式。

图1 缺陷豆种类Figure 1 Defective soybean species
1.2 数据增强
利用OpenCV相关库的图像处理操作对原始图像数据集进行处理,以提高训练模型的泛化能力。该过程通过图像镜像翻转、图像噪声增大、图像模糊等(图2),以达到提高网络的检测性能和鲁棒性。
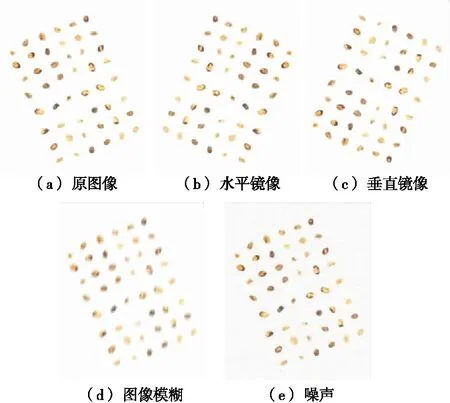
图2 图像增强Figure 2 Image enhancement
1.3 YOLOv5网络结构
YOLO系列[20-21]的检测网络是典型的one-stage网络,研究使用YOLOv5s检测模型。YOLOv5的主要网络结构包括输入端(input)、Backbone、Neck和输出端。
主干网络Backbone主要由Focus结构与CSP结构组成。Focus模块是将输入特征图像进行切片操作,使640×640×3的图像先变为320×320×12的特征图,再经过一次卷积操作变为320×320×32的特征图,该操作通过增加一点计算量来保证图像特征信息不会丢失,将 W、H的信息集中到通道上,使得特征提取得更加充分。CBL模块由Conv+BatchNormal+LeakyRelu组成。在YOLOV5中Backbone和Neck分别使用两种不同的CSP1_X和CSP2_X结构,在Backbone中使用带有残差结构CSP1_X源于Backbone网络结构较深,残差结构会加强梯度值在反向传播过程中,有效防止网络结构加深时所引起的梯度消失,得到更加丰富特征信息。通过设置不同的CSP模块中的宽度与深度,可以得到YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x不同的型号模型。SPP结构在Backbone的尾部,主要目的是增大感受野,增强网络的线性表达能力。
Neck网络是一系列混合图像特征的聚合层,采用FPN+PAN的结构。FPN 是通过上采样的方法传递和融合信息,从而获得预测的特征图。由于该网络的特征提取采用自上而下的特征金字塔网络,因此能够提高低层特征的传输,增强对不同尺度目标的检测,可以精确地识别不同尺寸和比例的目标对象。Neck中CSP2_X主干网络中的两个分支的输出进行拼接,加强网络特征融合能力。
输出端采用CIOU函数作为边界框的损失函数,在目标检测后处理过程中,使用NMS、非极大值抑制来对多目标框进行筛选,增强多目标和遮挡目标的检测能力。具体网络结构如图3所示。
1.4 网络结构优化
1.4.1 嵌入CBAM注意力机制 注意力机制通过模仿人脑处理视觉信息的方式,模仿人类迅速观察图像的全局信息,找出需要重点关注的候选区域,并将主要注意力放在此区域,从而提取更多的细节信息。因此,在深度学习,尤其是在深层次高性能网络中得到了广泛应用。
为了获取咖啡瑕疵豆更加丰富的特征信息,减少背景与复杂环境的干扰,引入CBAM(Convolutional Blaock Attention Module)模块[22]。CBAM模块是由空间与通道的注意力机制模块组成,其中通道注意力模块与空间注意力模块可以并行排列和顺序排列,此处采取顺序排列。
输入的特征图为C×H×W∈F,其中C为特征图的通道数。F进入通道注意力模块,通过平均池化和最大池化得到每个通道的信息,并将得到的参数通过多层感知器进行叠加,再经过sigmoid函数激活,从而得到通道注意力特征:
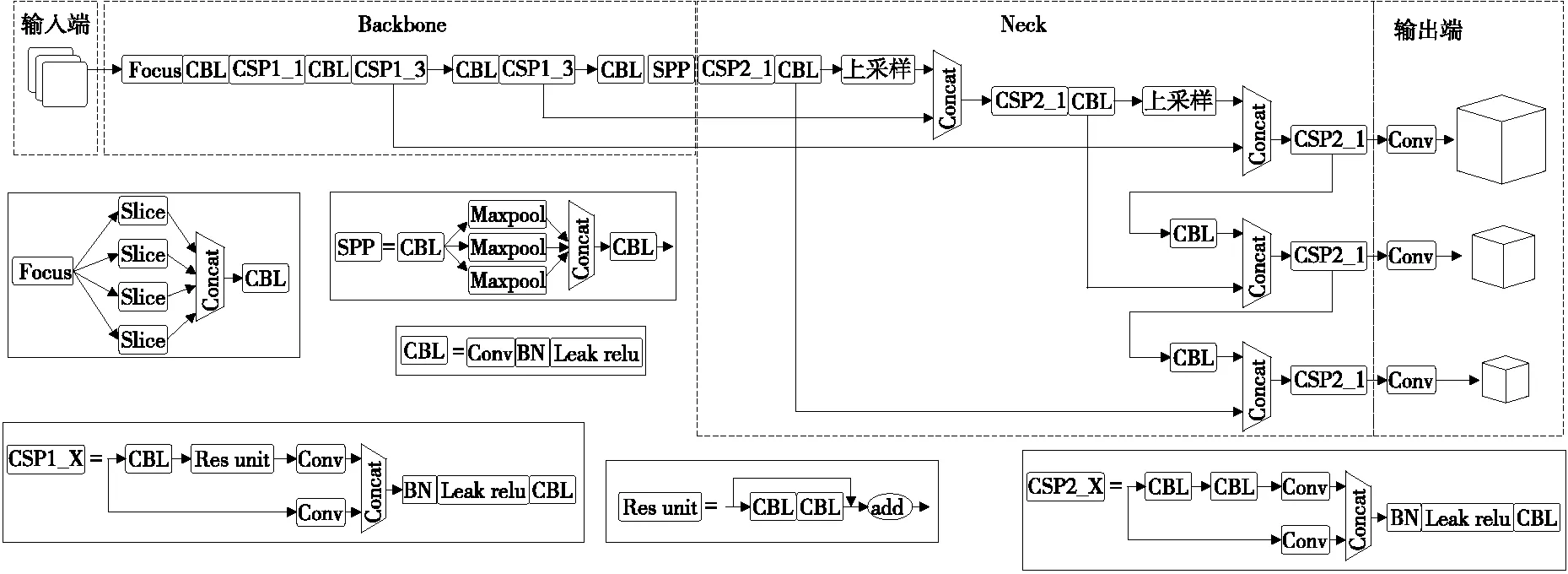
图3 YOLOv5网络结构Figure 3 YOLOv5 network structure
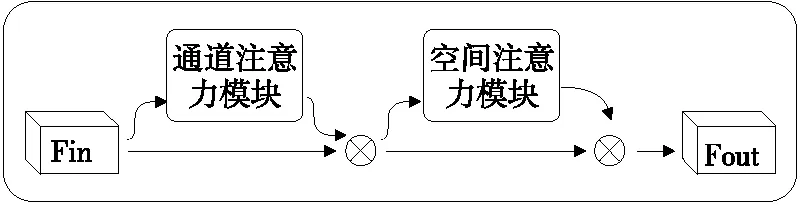
图4 CBAM模块结构Figure 4 CBAM module structure
(1)
式中:
Cm——通道注意力机制;
σ——sigmoid函数;
MLP——多层感知器;
AvgPool、MaxPool——对模块特征图空间信息进行平均池化和最大池化;
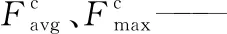
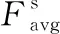
(2)
式中:
Sm——空间注意力机制。
1.4.2 激活函数 引入非线性函数作为激活函数,有利于加大深层神经网络表达能力,实现权值模型的轻量化,使模型具备捕获复杂的视觉布局能力,从而提高模型的综合性能,使咖啡瑕疵豆识别更加精确。选用Hardswish函数[23]作为激活函数,选择Hardswish将YOLOv5s特征提取网络骨干部分(Convolution、Batch normal、LeakReLU、CBL)模块中的激活函数进行替换:
(3)
1.4.3 损失函数 YOLOv5s的损失函数由3个部分组成,分别是定位损失、置信度损失和类别损失,其中置信度损失和类别损失采用二元交叉熵计算,在YOLOv5s原始网络中采用GIOU作为定位损失计算式。
(4)
(5)
式中:
C——两个框中的最小外接矩形;
B∪Bgt——预测框与真实框的并集。
虽然GIOU解决了IOU中两个框无交集时,导致梯度消失的情况,但并未改善预测框与真实框相互包含时损失函数退化成IOU,从而不能清楚描述预测框的回归问题,无法预测评估预测框和真实框的相对位置,影响定位精度的准确性,导致定位框失去收敛方向。选择CIOU[24]作为损失函数,其计算式为:
(6)
(7)
(8)
式中:
b、bgt——预测框与真实框的中心点;
ρ(·)——欧式距离;
C——两个框的最小外接矩的对角线距离;
ν——真实边框与预测边框的宽高比损失;
α——宽高比损失系数;
αν——CIOU宽高比惩罚项(防止当真实框与预测框中心点重合时CIOU损失退化成IOU,进而能在中心点重合时CIOU仍有宽高比损失惩罚,能进一步调整宽高比例)。
CIOU综合考虑了真实框与预测框之间的重叠率损失、中心点偏移损失和自身宽高比损失3种度量优点,使得在模型学习与训练中具有更好、更稳定的收敛精度与收敛效果。
2 结果与分析
2.1 模型及评价指标
为了评价模型性能,采用准确率(P)、召回率(R)、平均准确率(AP)、瑕疵豆平均准确率均值(mAP)以及检测速度FPS作为评价指标。
(9)
(10)
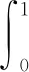
(11)
(12)
(13)
式中:
TP——判断为正类的正类;
FN——判断为负类的正类;
FP——判断为正类的负类。
2.2 训练结果
模型训练软件环境为Windows 10操作系统,使用pytorch深度学习框架,CUDA11.1。硬件环境为GeForce RTX2060显卡,AMD的R7-4800H处理器,16 GB运行内存。
模型训练以YOLOv5s初始参数设置为基础,迭代周期为200;Batchsize为16;动量因子为0.937;权重衰减系数0.000 5,采用余弦退火策略。
由图5可知,经过200轮次的训练,损失函数的最小值出现在155轮为0.03,召回率最大值出现在158轮为0.991,mAP(0.5)的最大值在154轮为98.8%,准确率与mAP(0.5∶0.95)的最大值均出现在196轮,分别为99.5% 和71.9%,选择196轮作为最终的测试权重文件。
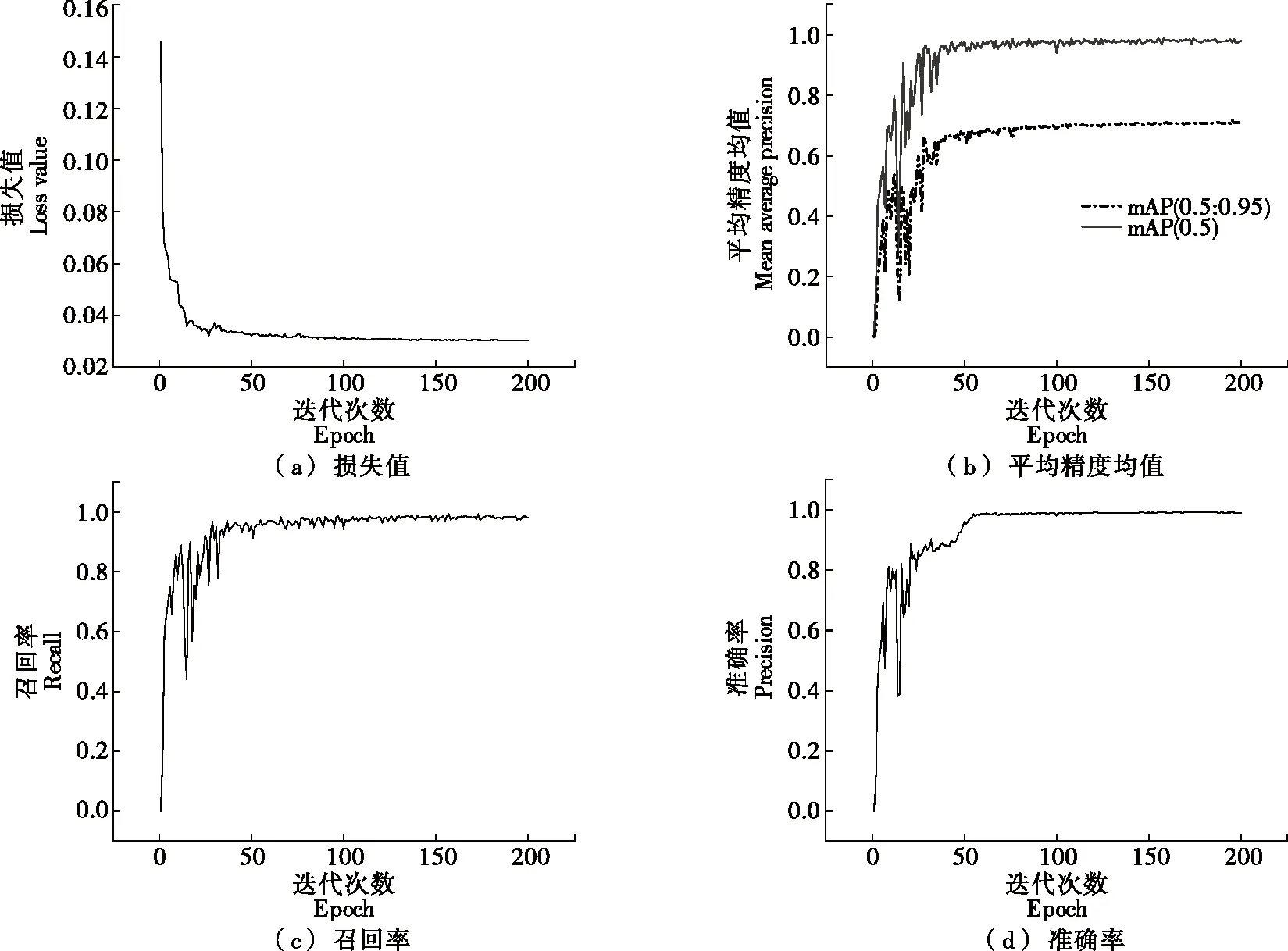
图5 各项指标变化曲线Figure 5 Change curves of various indicators
2.3 不同注意力机制分析
在主干网络Backbone中分别使用现有的注意力机制CBAM、SE、CA、ECA等模块[25-27]。分别加在表1序号2、4、6、9的4个BottleneckCSP模块后记作A;单独加在序号9的BottleneckCSP模块后记作B;单独增加一层加在序号8与序号9之间记作C,结果如图6所示。由图6 可知,CBAM加在B处的效果最好,相比基线网络,mAP (0.5∶0.95)提高了2.9%。
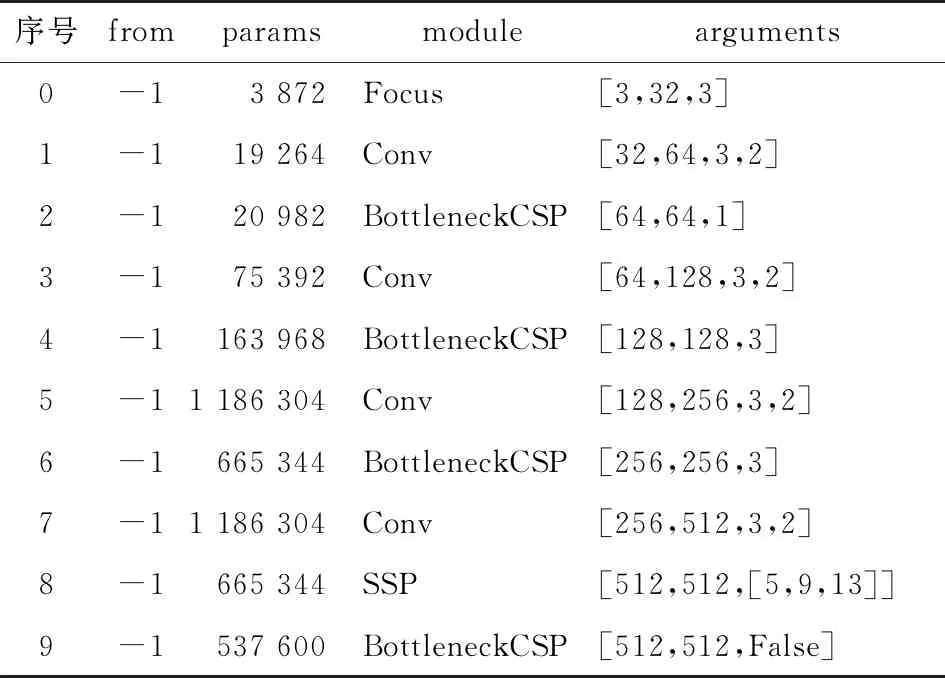
表1 YOLOv5s的Backbone部分网络结构图
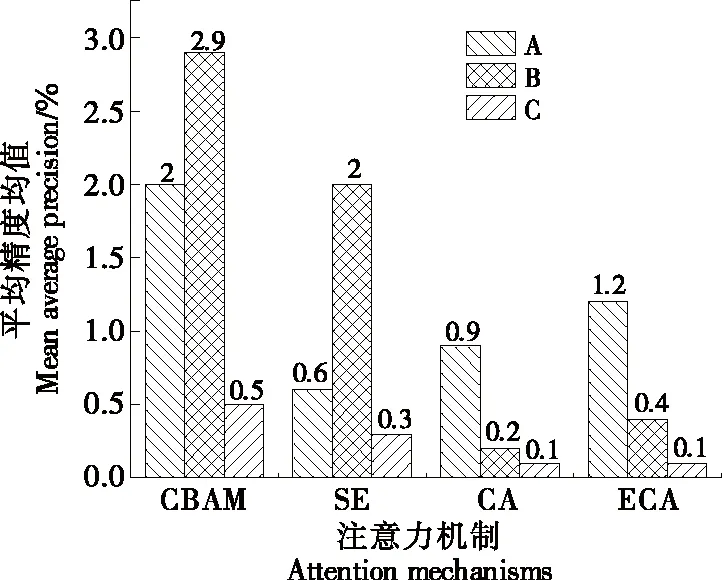
图6 不同注意力机制比较Figure 6 Comparison of different attention mechanisms
2.4 不同激活函数对比
通常,在线性捕获卷积层中的空间相关性后,激活层立即充当标量非线性变换。目前已提出了许多有效的激活函数,如SILU、Hardswish和FReLU[28]。以YOLOv5s网络为基线,模型默认的激活函数为LeakReLU,以模型在mAP(0.5∶0.95)为评价指标,选择一款在该数据集上模型的泛化性能更好的激活函数。由图7可知,Hardswish更有效,在咖啡瑕疵豆的检测任务上表现更好。
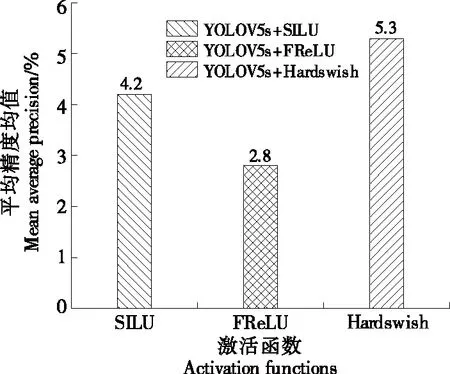
图7 不同激活函数比较Figure 7 Comparison of different activation functions
2.5 检测网络对咖啡瑕疵豆的识别
由表2可知,YOLO系列算法在召回率、准确率、mAP上均大于Faster-RCNN和SSD;试验算法的mAP比Faster-RCNN、SSD、YOLOv3、YOLOv4、YOLOv5分别高20.4%,13.2%,7.3%,4.1%,3.1%。在模型检测速度方面,试验算法识别速率为64幅/s,相比上述模型差值为+48,+9,+18,+24,-2。在模型大小方面,试验算法、SSD、YOLOv5s明显优于Fast-R-RCNN、YOLOv3和YOLOv4。综上,改进后的算法在识别准确率与召回率上明显提升,可大幅提高咖啡豆的品质检测。在工程应用中,将检测速率与模型可移植性作为评价指标,轻量级模型在模型的可移植性方面更好,鉴于试验改进算法在检测时间与模型大小的优势,改进后的YOLOv5算法更加适用咖啡豆检测系统的部署应用。
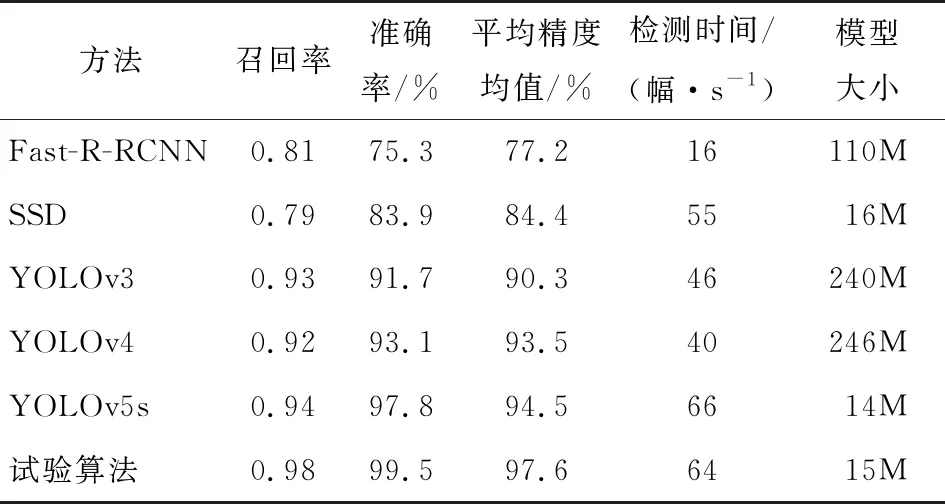
表2 算法对咖啡瑕疵豆的识别结果
2.6 咖啡瑕疵豆的识别效果
2.6.1 单粒识别效果 测试了3种瑕疵豆各30张,其中破损豆与霉菌豆各出现一个错误识别,整体的检测置信度均在90%以上,识别准确率为98%(见图8)。

图8 单粒识别效果Figure 8 Effects of single particle recognition effect
2.6.2 多粒识别效果 由图9可知,试验算法在粒数为8的图像中全部识别正确,整体置信度在92%以上;在粒数为30的图像中,有一个将破损豆识别为霉菌豆,识别正确率为96.7%,其中霉菌豆目标检测置信度最小为82%,最大为88%,均值为84.7%,破损豆目标检测置信度最小为74%,最大为87%,均值为81.7%,带壳豆目标检测置信度最小为84%,最大为90%,平均值为87.6%;单幅60粒的图像中识别错误有7个豆,分别是2个破损豆、2个带壳豆和3个霉菌豆,其中有4个识别错误豆是检测框出现类别重复。破损豆、带壳豆和霉菌豆正确率分别为90%,90%,85%。破损豆目标检测置信度最小值、最大值、平均值分别为76%,88%,83%;带壳豆目标检测置信度最小值、最大值、平均值分别为83%,90%,87.1%;霉菌豆目标检测置信度最小值、最大值、平均值分别为74%,87%,83.7%。综上,试验算法的总体识别正确率在85%以上,目标检测置信度在74%以上。随着粒数的上升,模型精度会有所下滑,总体来说模型在多粒识别方面均有不错的效果。

图9 多粒识别效果Figure 9 Effects of multiple grains recognition
2.6.3 黏连识别效果 采用单幅30粒的图片分别设置3种黏连程度,由图10可知,3种黏连程度的准确率分别为100%,100%,86%,其中重度黏连中出现2个破损豆识别错误,2个带壳豆识别错误。轻度、中度、重度黏连的目标检测置信度均值分别为88.1%,81.5%,85.3%。综上,模型精度受黏连程度的影响,但模型总体识别效果较好。

图10 黏连识别效果Figure 10 Effects of adhesion recognition
2.6.4 不同光照背景 测试了3种光照条件下的单幅9粒图片,由图11可知,在过度曝光情况下识别准确率为100%,目标检测置信度均值为82.7%,在弱光环境下识别准确率为100%,目标检测置信度均值为84.4%,在昏暗环境下准确率为66.7%,其中带壳豆与霉菌豆识别准确率为100%,由于昏暗环境导致破损豆与霉菌豆显示无差别,导致模型将破损豆全部识别为霉菌豆,目标检测置信度均值为83.6%。综上,模型在相对稳定的环境下识别效果较好,当环境影响较大时,在带壳豆与霉菌豆检测方面也具有较高的准确率。

图11 不同光照识别效果Figure 11 Effects of recognition in different illumination
3 结论
针对瑕疵豆引起咖啡生豆的品质问题,提出了一种改进的YOLOv5s咖啡瑕疵豆的检测算法。结果表明,试验算法比YOLOv5s基线网络模型的准确率、平均精度均值和召回率分别提高了1.7%,3.1%和4%,同时也优于SSD、Fast-R-RCNN、YOLOv3、YOLOv4等模型;模型对单粒识别效果最好,识别准确率为99%,在多粒与黏连环境下识别效果下降,但整体识别准确率>85%;过度曝光与弱光环境下模型识别正常,但在昏暗条件下,模型易将破损豆识别为霉菌豆,导致破损豆识别准确率下降。针对破损豆的识别率不高,如何利用在计算能力有限的嵌入式设备上,实现高性能的实时咖啡瑕疵豆检测任务等问题,后续可以从数据集制作,在主干特征提取网络中增加小目标检测层,进一步提高破损豆在昏暗环境的检测效果,以及对改进后的算法进行轻量化研究。
猜你喜欢
好日子(2022年3期)2022-06-01
核科学与工程(2021年4期)2022-01-12
法律方法(2021年4期)2021-03-16
扬子江诗刊(2019年3期)2019-11-12
扬子江(2019年3期)2019-05-24
计算机应用(2018年5期)2018-07-25
Coco薇(2015年12期)2015-12-10
轴承(2015年2期)2015-07-25
科普童话·百科探秘(2015年5期)2015-05-26
电讯技术(2011年11期)2011-04-02
