
基于注意力机制和特征金字塔的孪生卷积神经网络目标跟踪算法
2023-03-15 08:47卞月楼陆振宇葛泉波白延中
计算机应用与软件 2023年2期
卞月楼 陆振宇 葛泉波 郑 成 白延中
1(南京信息工程大学电子与信息工程学院 江苏 南京 210044) 2(南京信息工程大学人工智能学院 江苏 南京 210044) 3(同济大学电子与信息工程学院 上海 200092)
0 引 言
目标跟踪是当下计算机视觉领域中的重要研究课题之一,它在诸如视频监控、自动驾驶、人机交互、防空预警等领域具有广泛的应用。目前,尽管目标跟踪已经取得了很多研究成果,但在一些复杂多变的场景中,由于受到目标部分遮挡、几何变形、快速运动、尺度变换等因素的影响,现有的算法跟踪目标的精度和鲁棒性不佳,因此,目标跟踪仍然是一个非常具有挑战性的任务。
相关滤波一直是目标追踪领域的主流方法。文献[1]首次提出了最小化输出平方误差和滤波(MOSSE)算法,较大地提高了算法跟踪速度。此后,一些基于核相关滤波改进的目标跟踪算法也随之产生[2-3]。在解决目标尺度变化问题上,文献[4]提出了区分尺度空间(DSST)算法,通过训练一个三维滤波器,对位置、尺度进行更新,实现了对目标尺度自适应跟踪并在文献[5-8]中进行了改进。在处理目标特征方面,文献[9]将3维的RGB特征映射到11维的颜色名(CN),使得滤波器具有处理丰富的颜色特征的能力。随后,文献[10]利用多特征融合的方法,提出了尺度自适应多特征跟踪器(SAMF),将CN和HOG特征进行特征融合,取得了较好的跟踪效果。
近年来,卷积神经网络发展十分迅速,凭借着强大的提取特征能力,在目标跟踪领域取得了很大成功。文献[11]首次训练了一个用于目标跟踪的多域通用模型,实现了端到端的跟踪。但是模型采用在线学习的方式,难以达到实时的要求。基于此,文献[12-13]都提出了采用离线学习的方式,运用孪生网络结构,大大提高了跟踪速度。随后,出现了很多基于文献[13]中全卷积孪生网络(SiameseFC)模型的改进算法,开辟了深度学习模型的新领域。SenseTime团队将Faster R-CNN的核心区域生成网络(RPN)用于SiameseFC,提出了SiamRPN[14],在精度和速度上,都达到了不错的效果。同年,SenseTime还提出了DaSiamRPN[15]模型,使算法更好地利用数据训练,并在模型跟踪失败的时候,模型采取一种“局部-全局”增大搜索框的策略去重新跟踪目标,可以很好地应对长时跟踪的问题。文献[16-17]都针对先前算法采用AlexNet这样的浅层主干网络进行分析,各自提出了使用深度神经网络进行特征提取的方法,提高了算法性能。此外,文献[18-21]通过将深度学习和相关滤波相结合的方式,也获得了比较有竞争力的性能。
尽管当下基于深度学习的目标跟踪算法凭借着卷积神经网络强大的特征学习和表征能力取得了不错的性能,但当跟踪目标所在场景复杂时,跟踪效果却一般。一方面一些挑战场景下,单纯使用深度网络提取特征还不足以得到更好的特征;另一方面深度网络导致提取到的特征感受野太大,更加关注目标的语义信息而缺少了物体的位置、纹理等底层信息。最后深度网络参数更大,需要更多计算资源,往往会导致跟踪速度降低。从本质而言,采用深度神经网络当作孪生网络的主干网络来提取特征,是用网络运行速度换取跟踪准确率的方式。然而,在实际应用中,考虑算法的性能时往往是综合各方面因素的,实时性也是不可忽视的问题。一个真正优秀的跟踪算法应同时具备较高的跟踪精度和满足实时应用要求。
为了克服以上问题,本文提出一种结合注意力机制和特征金字塔的全卷积孪生网络目标跟踪算法。注意力机制让跟踪器更专注于目标本身并抑制其余的无用背景信息,进而提高特征的表征能力。特征金字塔模型可以有效解决深度神经网络带来的感受野过大、小目标难以跟踪的问题。这些改进能够提高网络性能的同时,也不会带来巨大的资源开销。最后,针对在跟踪目标训练过程中正负样本不平衡、简单和困难样本问题,通过改进损失函数来优化网络训练。
综上所述,本文的主要贡献如下:
(1) 对网络进行改进并在一些卷积层间加入通道注意力机制,对卷积特征的各个通道赋予相应的权值,提高最终卷积特征的判别力。
(2) 在网络中加入特征金字塔网络(FPN)[22]结构,通过融合高低卷积层特征,使得提取到的特征具有更强的表观信息和语义信息。
(3) 针对网络训练过程中出现的正负样本不平衡、简单和困难样本问题,通过使用焦点损失(Focal Loss)[23]函数来进一步提高跟踪精度。
1 孪生神经网络的目标跟踪算法
1.1 孪生神经网络结构
孪生神经网络[24]是由两个或更多的神经网络分支构成的网络结构,并且每个子网共享权重,信息通过各自的子网络后,通过距离计算得出它们的相似性,从而可以在少量的样本情况下精准分类。孪生神经网络结构如图1所示,其中:Z为模板图像;X为候选图像。经过该结构后可得相似度函数为:
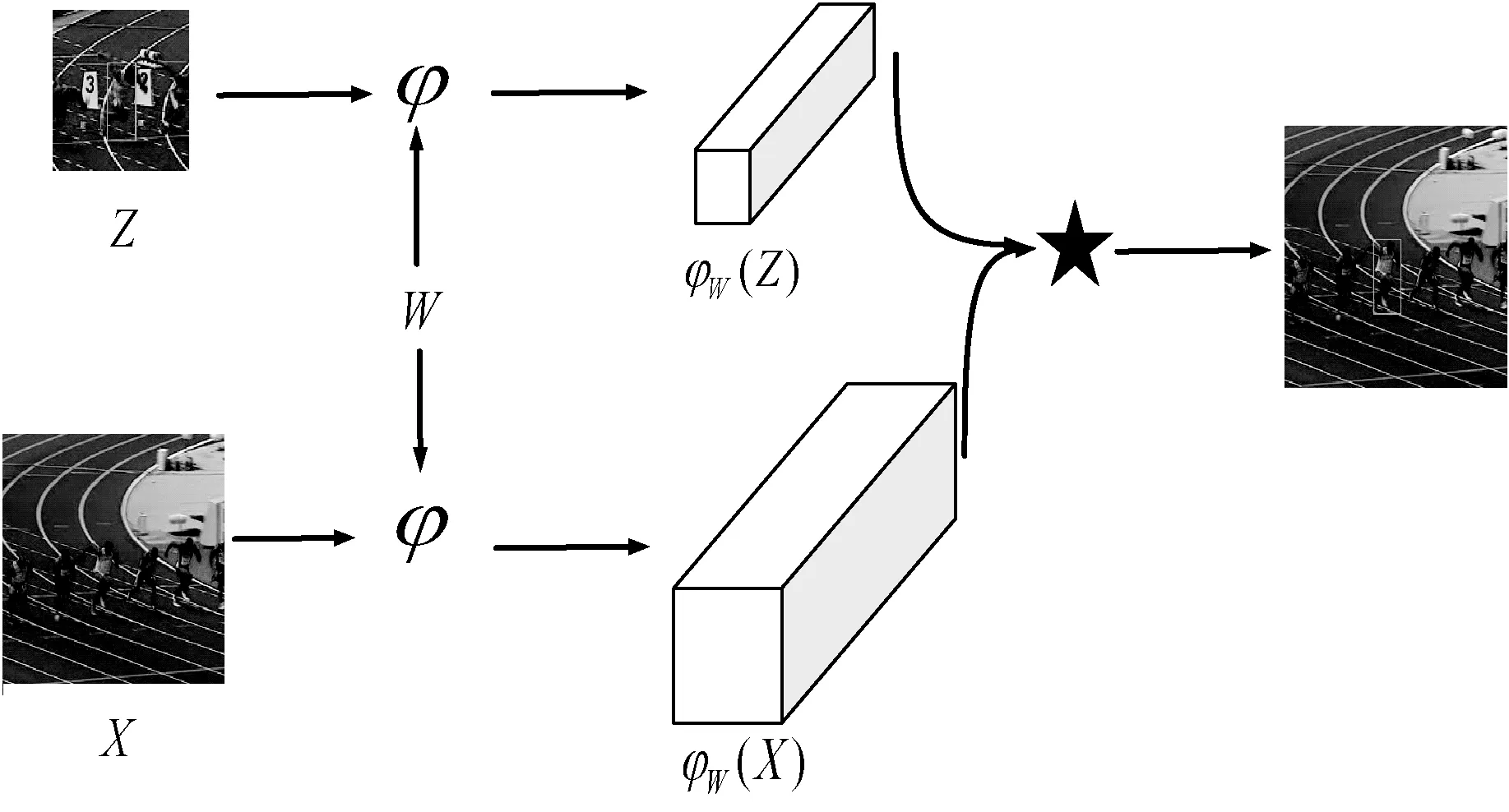
图1 孪生神经网络结构
fW(Z,X)=φW(Z)*φW(X)+b1
(1)
式中:φ为共享权重W的卷积操作;*代表卷积相关性操作;b1为偏移量。式(1)为二维的置信得分图,用来表示两个特征之间相似度,只要找到置信得分图中响应值最大的区域,并乘以相应的步长,通过计算就可以得到候选图像中的目标位置。
1.2 基于深度神经网络的孪生网络目标跟踪算法
在深度学习领域中,目标跟踪算法大多是基于孪生网络结构实现的。尽管当下已经取得了不错的效果,然而诸如SiameseFC、SiamRPN等算法,无一例外都是采用类似AlexNet这样的浅层神经网络充当特征提取器。目标跟踪实质是一个验证的过程,浅层网络效果不错,同时跟踪需要实时进行,增加网络层数会增加计算负担,影响实时性。但是,随着深度学习的火热发展,通过简单地加深网络层数、优化网络结构,利用深度卷积神经网络强大的提取特征能力,许多领域的算法性能都得到较大的提升。因此,在目标跟踪领域网络深度化也应当是大势所趋。然而经过实验发现,在不考虑跟踪效率情况下,将深层基准网络ResNet[25]、Inception[26]应用到孪生网络结构中时,网络并没有像在其他视觉任务上表现得那么优秀。一方面深度网络导致提取到的特征感受野太大,更加关注目标的语义信息而缺少了物体的位置、纹理等底层信息;另一方面使用深度网络会存在很多的padding操作,会导致跟踪出现漂移现象;最后,一些网络的步长选择过大会导致小目标定位困难。所以,单单使用深度神经网络作为特征提取器并不能很好地提高算法精度。
为了提高跟踪器的判别能力,利用深度神经网络的特征提取能力,SiamDW[18]提出了新的残差网络结构,通过利用裁剪内部残差(Cropping-Inside Residual,CIR)单元,很大程度地减弱padding操作产生的偏差影响,在网络加深的同时也取得了较好的性能。但是,SiamDW在一些复杂场景判别能力不强,模型发生漂移,导致跟踪失败。本文基于此对算法进行改进,通过引入特征金字塔和通道注意力机制修改网络结构,并在训练中选取更加合适的损失函数,实验证明,该方法能够有效地减小跟踪器的跟踪误差。
2 算法设计
2.1 网络结构
本文所提出的网络结构如图2所示,以SiamDW网络为基础进行改进,加入了特征金字塔和空间注意力机制,并针对目标跟踪中正负样本失衡的问题,在训练中通过使用Focal Loss损失函数进行优化。
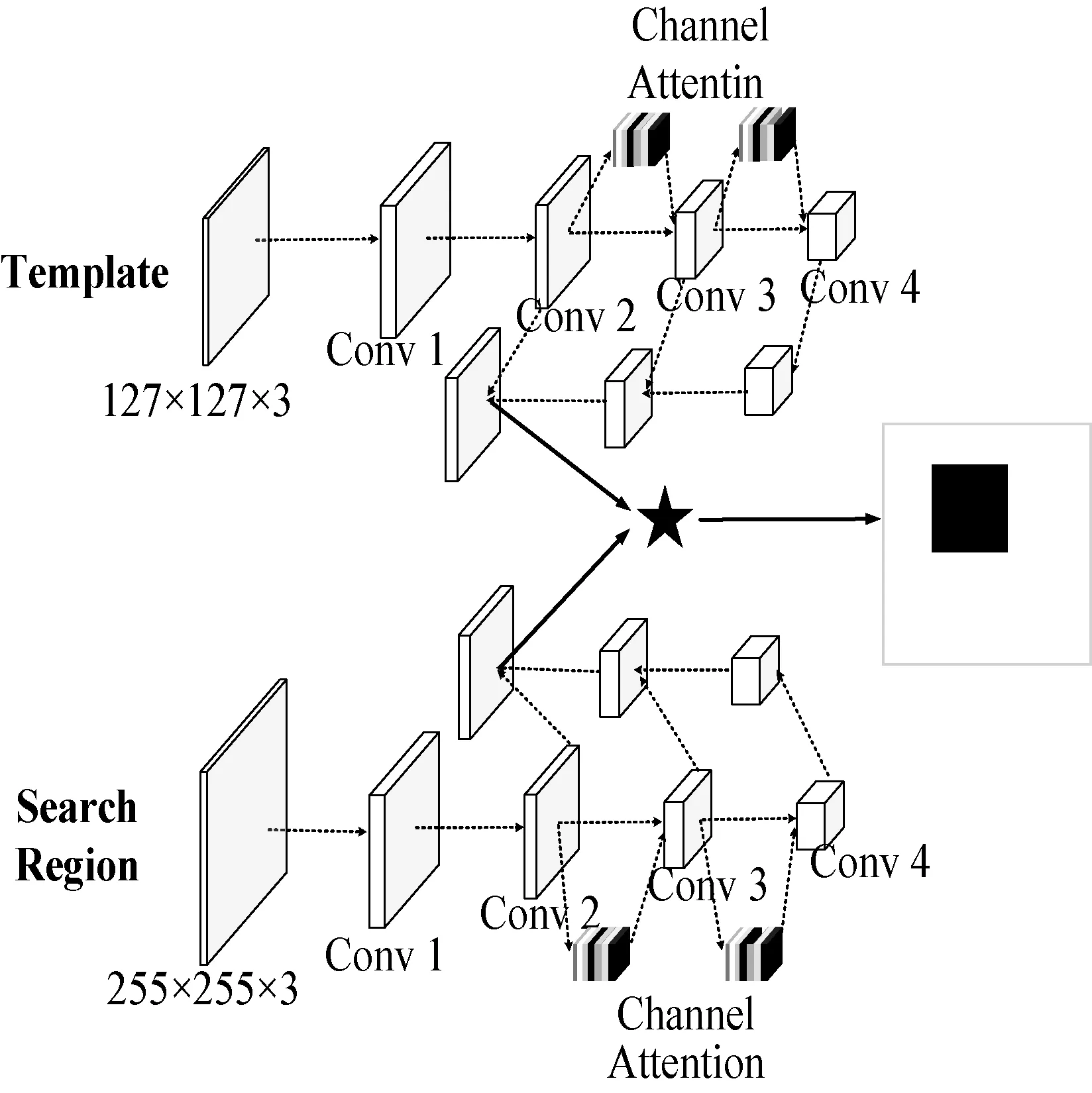
图2 网络总体结构
具体而言,在模型构建时,SiamDW选用的CIResNet-22作为原始主干网络并将其分为四个卷积阶段。我们首先在后两个卷积阶段所得的特征后加入收缩激励(Squeeze-and-Excitation,SE)模块[27],该模块能够充分利用特征图的通道信息,使得模型更加关注信息量大的通道特征,从而提高整个特征图的表达能力。随后,在第二和第三个卷积阶段后面加入最大池化操作,提高卷积的感受野。将各卷积阶段得到的特征图进行维度操作,并对高层特征进行上采样,使之与其上一层具有相同的尺寸,并将这两层网络特征进行融合。反复以上操作至最底层网络,就可以构造出特征金字塔。最后得到的特征融合了多层特征信息,不但具有高层的语义信息,还可以提供准确的位置、纹理等底层信息,增强了模型判别力的同时也提高了小目标物体跟踪的精度。
2.2 注意力机制
注意力机制是指从大量的信息中有选择性地关注重要的一部分,从而获取需要目标的特征,而不关注无关信息的技术。目前,注意力机制已经在各种深度学习领域都有应用,诸如计算机视觉、自然语言处理和语音识别等,也诞生了很多高效的算法[28-30]。SiamDW网络中的各层卷积操作,通过空间上的特征融合来增大感受野,提高特征的表征能力。而对于通道维度的特征,卷积并没有关注各个通道之间的关系,而是对所有通道进行直接融合。因此,本文在SiamDW网络中加入SE模块,这使得最终得到的特征不仅考虑了空间信息,而且还利用学习到的各通道之间的相关性来增强提取特征的效果。此外,加入SE模块并没有改变原有特征的空间维度,网络性能却有一定的提升。该模块结构如图3所示。
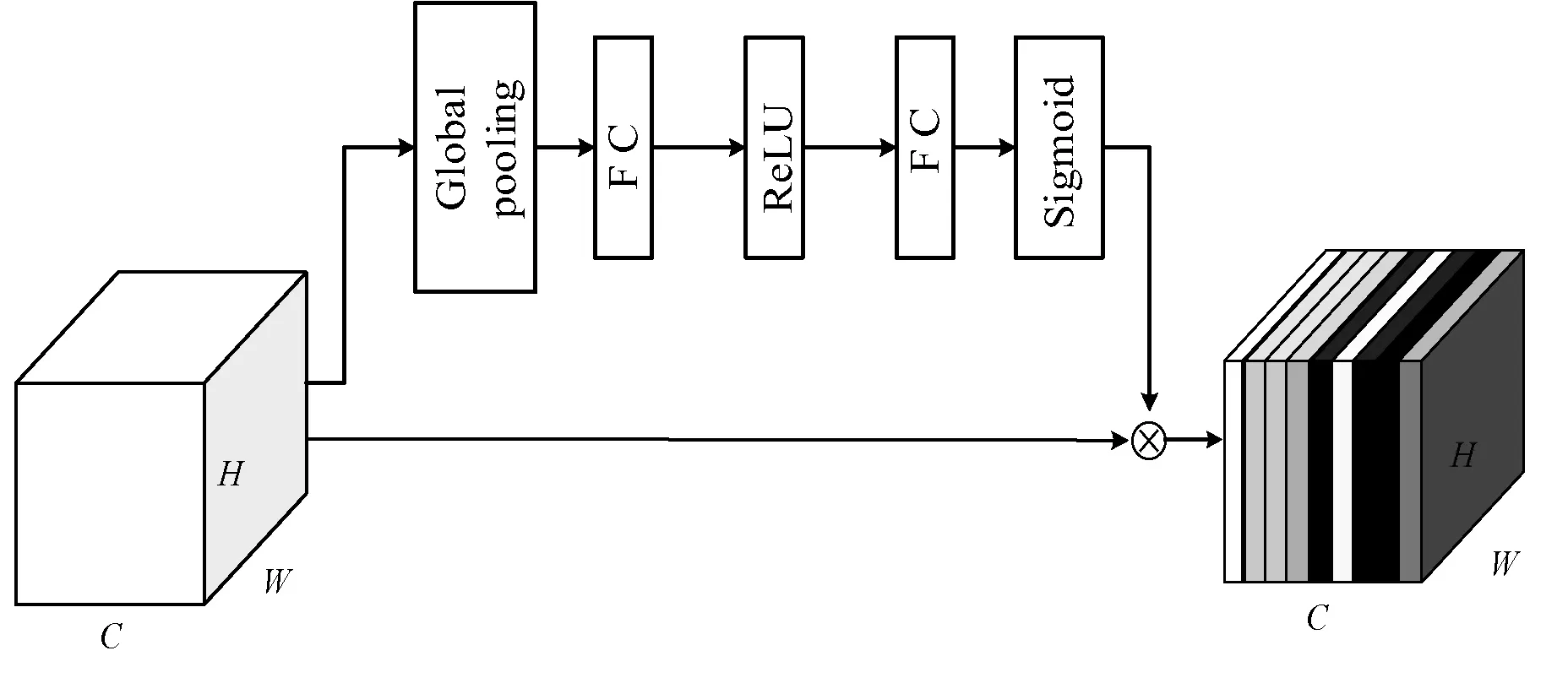
图3 通道注意力
模块中特征图的输入、输出维度均为H×W×C,FC为全连接网络,ReLU和Sigmoid为两种不同的激活函数,⊗为哈达玛积。H×W×C的特征图经过全局池化操作,将各个通道的特征转变成一个实数z,第c个通道的特征图对应的实数z为:
(2)
式中:uc(i,j)为输入特征图的第c个通道位置为(i,j)的图像像素值;Fsq为全局池化。随后将获取的通道信息经过全连接层、ReLU激活函数和全连接层操作。再利用Sigmoid激活函数进行处理,得到权重赋值:
s=σ2(W2σ1(W1z))
(3)
式中:z为式(2)操作的结果;W1和W2为第一层和第二层卷积权重;σ1和σ2为ReLU和Sigmoid激活函数。最后将输出的权重以加权的方式在原始特征图上进行重新标定,将每个通道特征图和对应权重值求哈达玛积,最终得到通过通道注意力机制的特征。
2.3 特征金字塔
网络提取的特征的好坏是影响跟踪器效果好坏的关键因素,在提取到通过通道注意力机制的特征后,本文使用特征金字塔模型对高低层卷积进行特征融合,从而获得更加丰富的特征信息。文中所使用的原始SiamDW的主干网络CIResNet-22由22个卷积层组成,并利用最高层的输出作为主干网络最终提取的特征,然而当跟踪目标是小目标时,该特征由于感受野过大就难以捕获目标的空间细节信息,最终导致模板漂移或者错误跟踪。在卷积神经网络中的所有的特征层中,浅层特征分辨率较高,具有更多的目标表观信息和空间特征。当随着网络加深以及感受野的扩大,深层特征则具有更多的目标语义信息。因此,通过特征金字塔网络将网络的高低层特征进行一定方式的融合,可以使得融合后的特征同时具有目标不错的表观信息和语义信息。
在原始的CIResNet-22中,作者根据目标跟踪的特点构建的卷积后三个阶段特征图的维度并没有变化,保证了一个合理的网络步长。本文为了进一步提高卷积特征的表征能力,在卷积的第三和第四阶段加入最大池化,提高感受野的同时便于后续金字塔的构建。图4为本文中的特征金字塔网络结构。首先对提取到的三个阶段卷积特征进行降维操作,即使用1×1的卷积使不同维度的输出特征图具有相同的通道数。其次自上而下地进行特征融合,由于上层特征图尺度比较小,通过对其进行上采样再与下一层的特征图进行对应元素相加,得到融合高低层特征的卷积特征。最终在得到的三个特征图上分别进行预测。在本文构建的网络结构中,实验表明融合后下层特征具有更好的表征能力,跟踪器的性能也更加优异。
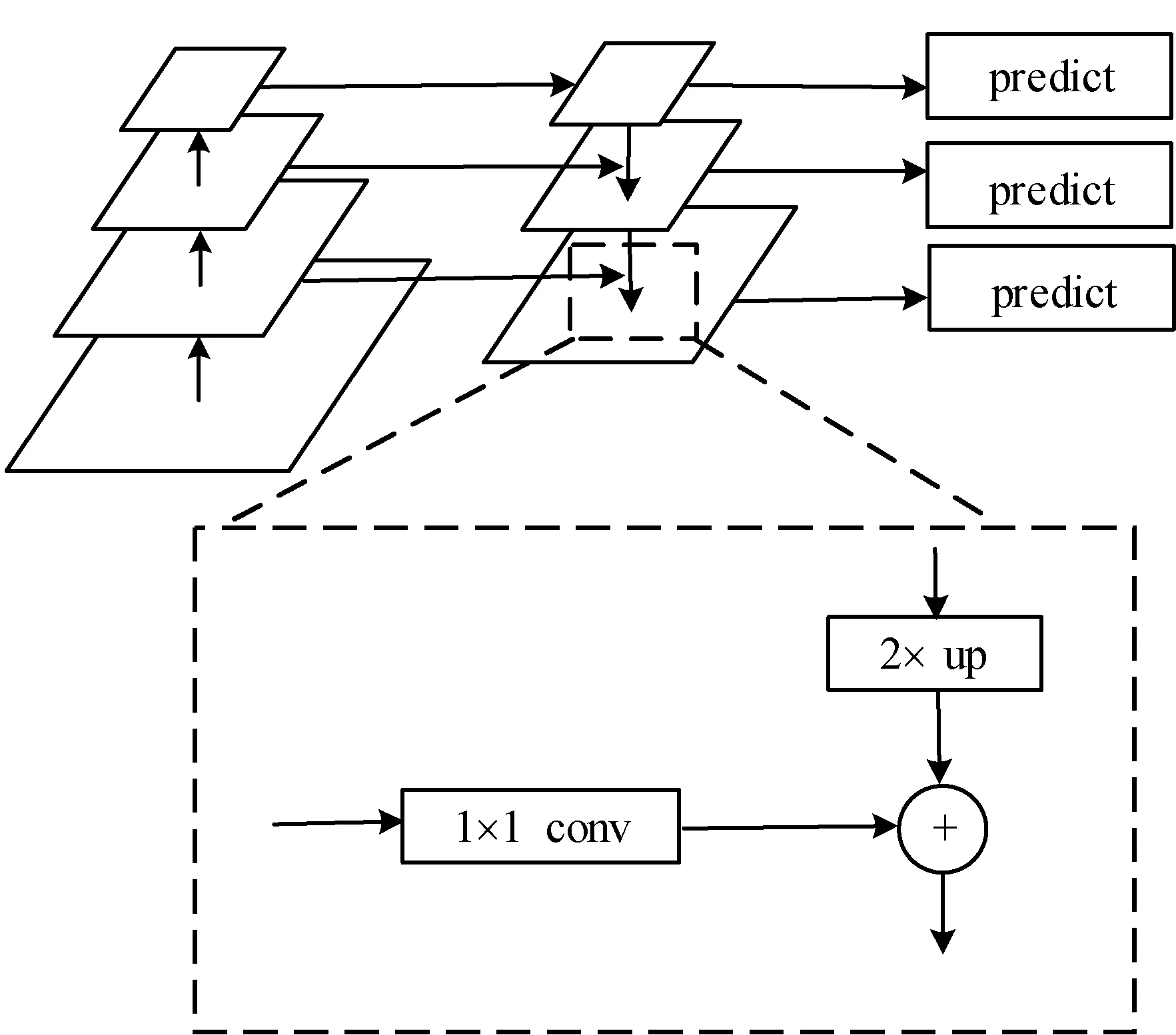
图4 特征金字塔模型
2.4 损失函数
由于物体的尺度变化,在跟踪过程中网络需要对搜索区域大小进行尺度放缩来确定目标大小,提高跟踪性能。然而,生成大量的候选框中正负样本数存在着不平衡,负样本数远远大于正样本数,这也导致了网络训练困难进而影响着模型的精度。为了解决这一问题,本文将目标检测中的Focal Loss函数应用到跟踪领域。Focal Loss函数是基于传统交叉熵(CE)的改进函数,可以一定程度克服训练正负样本不平衡,使模型更加关注难分类的样本。传统的CE公式如下:
CE(p,y)=CE(pt)=-log(pt)
(4)
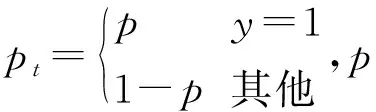
FL(p,y)=FL(pt)=-(1-pt)γlog(pt)
(5)
式中:(1-pt)γ(γ≥0)为调制系数,当γ=0时,Foca Loss即为传统交叉熵函数。针对训练时正负样本不平衡的问题,Focal Loss又引入平衡因子αt,得到最终得Focal Loss函数为:
FL(p,y)=FL(pt)=-αt(1-pt)γlog(pt)
(6)
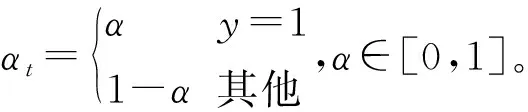
3 实验结果与分析
3.1 实验环境和设置
本文算法在Ubuntu16.04系统下PyTorch 0.3.1框架上实现,并使用GPU进行加速。实验平台中,CPU配置为:Inter core i5-8600k,计算机内存为16 GB。GPU配置为:NVIDIA GTX 1080Ti,显存大小为12 GB。
在训练阶段,我们使用GOT-10K数据集对网络进行预训练,该数据集总共包含了10 000个视频图像序列,563个不同目标种类,87种常见的运动模式,具有更加丰富的现实场景。我们设置初始学习率为0.001,随着网络训练次数的增加,学习率会逐渐递减,最终降为0.000 000 1。此外,还设置α=0.25和γ=2来克服训练时候正负样本不平衡的问题。在测试阶段,用目标跟踪基准数据集OTB100对训练好的网络进行鲁棒性和准确性的检验。
3.2 OTB基准
(1) 评估标准。为了有效地评估本文算法的性能,本文利用OTB100数据集进行测试,采用中心位置误差(CLE)和重叠率(OP)作为基本度量方式,并使用精确度(Precision)和成功率(Success Rate)作为指标对算法性能进行评估。精确度衡量的是目标预测中心位置和标注目标中心位置的像素差值小于设定阈值的帧数占所有帧数的比例。公式为:
(7)
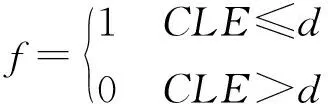
(8)
(9)
式中:N表示视频序列的帧数;f表示某一帧是否跟踪成功;d表示设定阈值;(xp,yp)和(xg,yg)表示预测框和标注框的中心位置坐标。成功率则计算预测框和标注框的重叠率(Overlap Rate)大于设定阈值的帧数占所有帧数的比例。公式为:
(10)
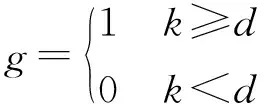
(11)
(12)
式中:g表示某一帧是否跟踪成功;d表示设定阈值;k表示重叠率;rp和rg表示预测区域和标注区域。
(2) 消融实验。为了验证不同模块对实验最终结果的影响,本文在OTB100数据集上进行大量对比实验,使用精确度和成功率作为指标对算法性能进行评估。在CIResNet-22主干网络中组合加入空间注意力机制、特征金字塔和Focal Loss损失函数构建新的网络。如表1所示,当仅加入其中一个模块时,修改原网络损失函数为Focal Loss取得了最好的结果,比原本的精确度和成功率分别提高了0.035和0.015;当同时使用空间注意力机制和特征金字塔构建网络,并修改原损失函数为Focal Loss时,算法取得了最高的精确度和成功率,比原本算法分别提高了0.052和0.030,因此,我们将该情况下的最终精度用于和以下主流算法实验对比来验证本文算法的有效性。
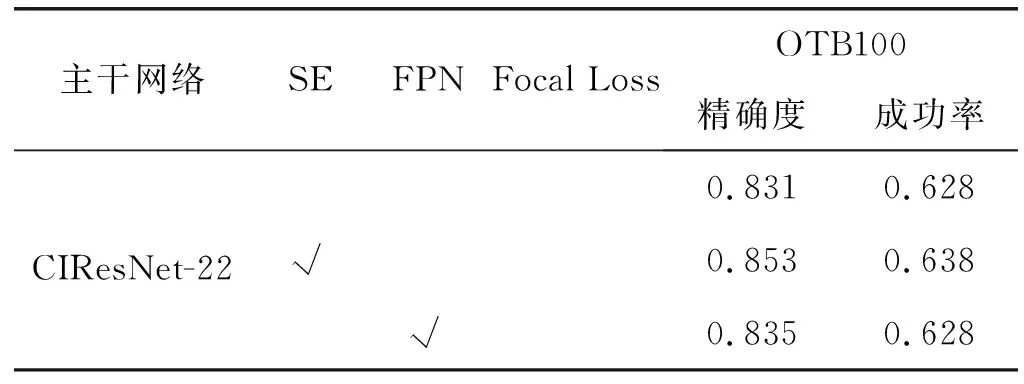
表1 OTB100数据集上各模块实验结果
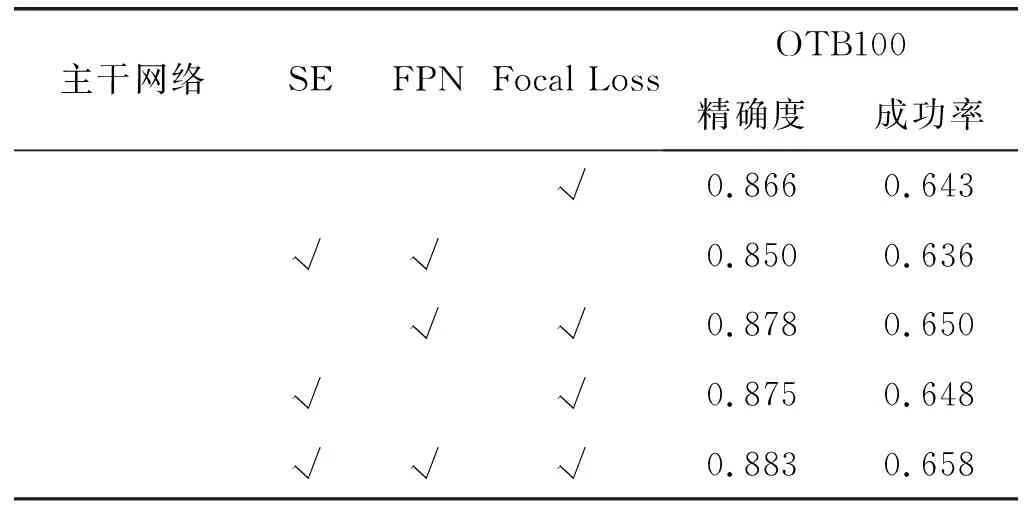
续表1
(3) 实验对比。将本文算法与主流的9种目标跟踪算法(fDSST[5]、Staple[31]、SiamFC[13]、CFNet[32]、SRDCF[33]、SiamDW[18]、DeepSRDCF[34]、SiamRPN[14]、GradNet[35])在OTB100数据集进行一次性通过评估(One-Pass Evaluation,OPE)比较。图5和图6展示了所有算法在不同阈值下精确度和成功率的曲线。其中,将成功率曲线的曲线下面积(Area Under Curve,AUC)用于跟踪算法的排名。表2显示了各个算法的对比结果。可以看出,本文算法在OTB100数据集上,精确度和成功率均在所有比较算法中排名第一,算法精确度和成功率比第二GradNet提高了0.019和0.018。结果表明本文改进的跟踪算法取得了比较有竞争力的效果。

图5 10种算法在OTB100数据集上的成功率曲线
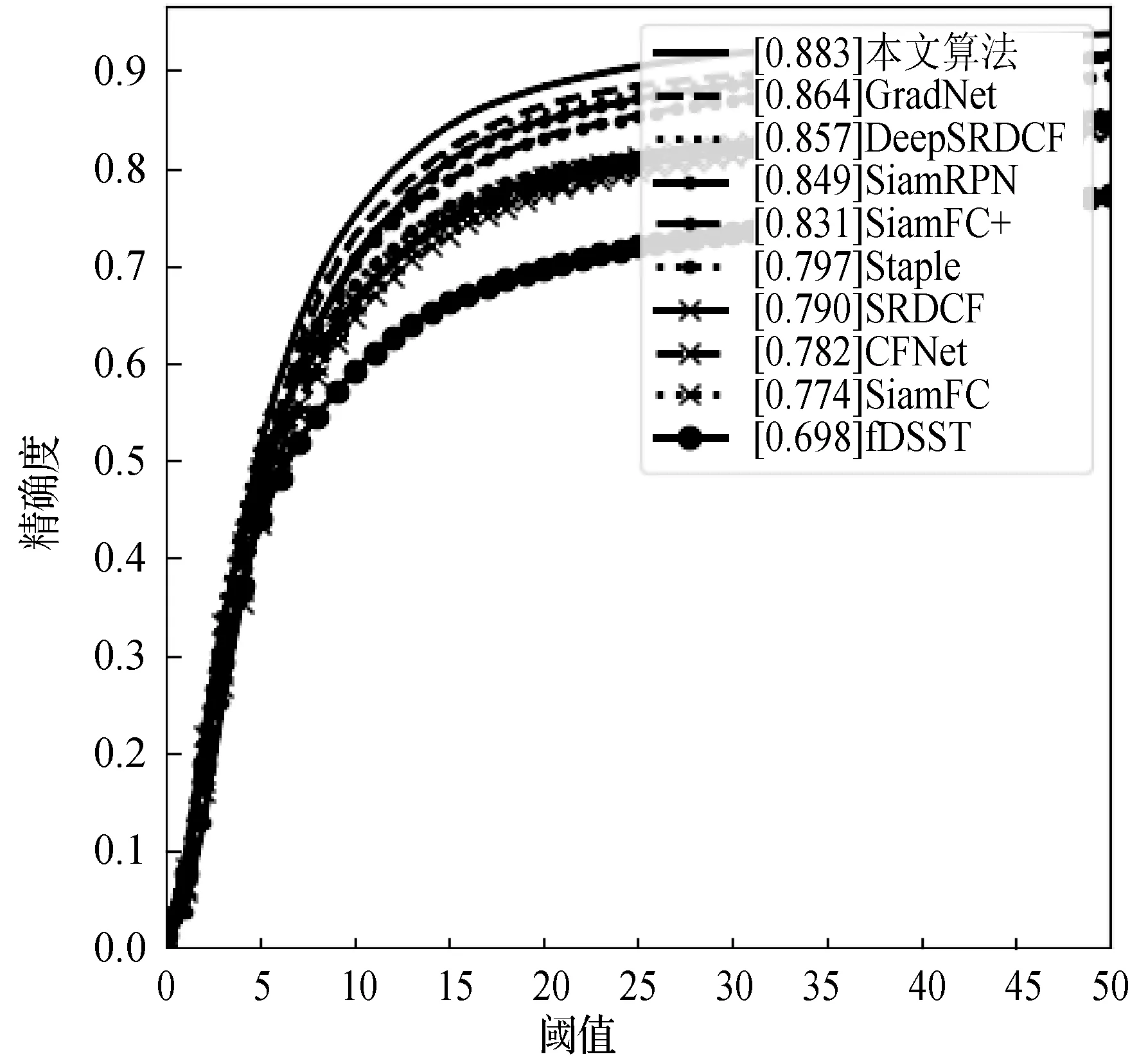
图6 10种算法在OTB100数据集上的精确度曲线
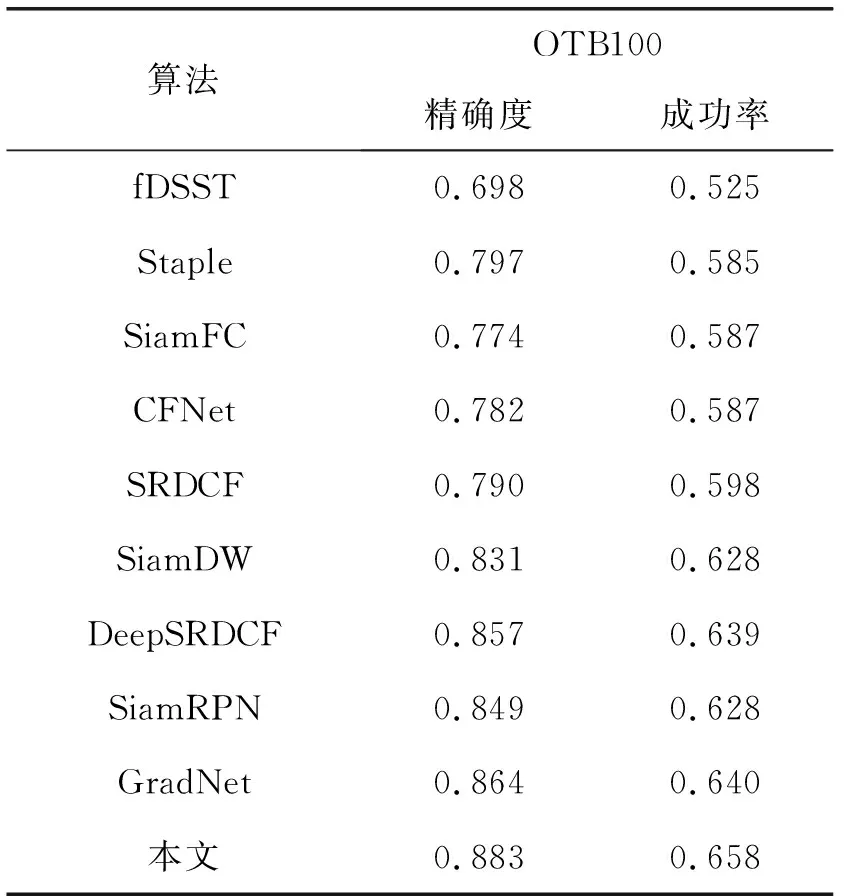
表2 10种算法在OTB100数据集上实验结果
为了更好地说明本文算法对目标跟踪中常见问题的有效性,我们对OTB100数据集的11个标注属性目标进行独立实验。11种属性分别是背景干扰(Background Clutter,BC)、非刚性形变( Deformation,DF)、快速移动(Fast Motion, FM)、平面内旋转(In-plane Rotation,IR)、超出视野(Out-of-view,OV)、光照变化(Illumination Variation,IV)、低分辨率(Low Resolution,LR)、运动模糊(Motion Blur,MB)、遮挡(Occlusion,OC)、尺度变化(Scale Variation,SV)和平面外旋转(Out-of-plane Rotation,OR)。表3和表4分别为本文算法和4种表现较好的对比算法在11种挑战属性下的成功率和精确度实验结果。可以看出,本文算法在背景干扰、非刚性变化、平面内旋转、光照变化、平面外旋转和尺度变化这6种属性中均取得了最好的效果。
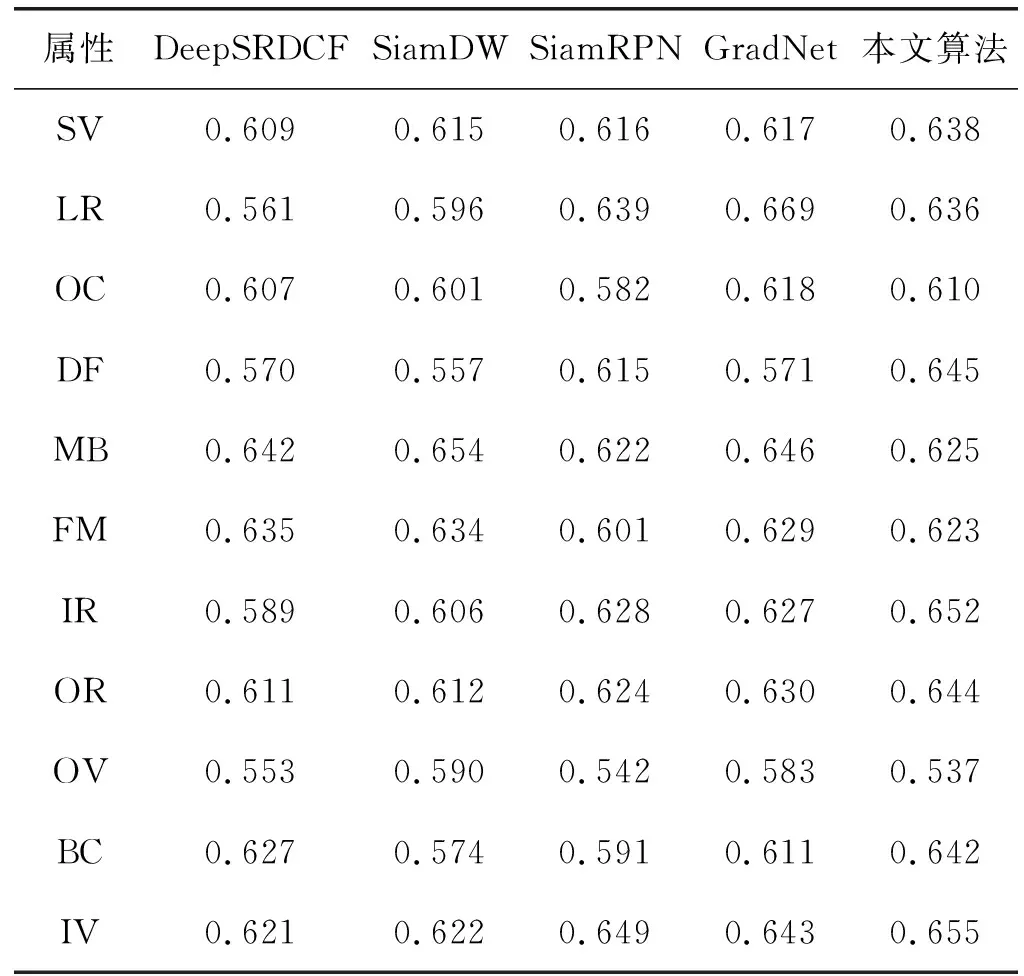
表3 OTB100数据集上11种属性的成功率
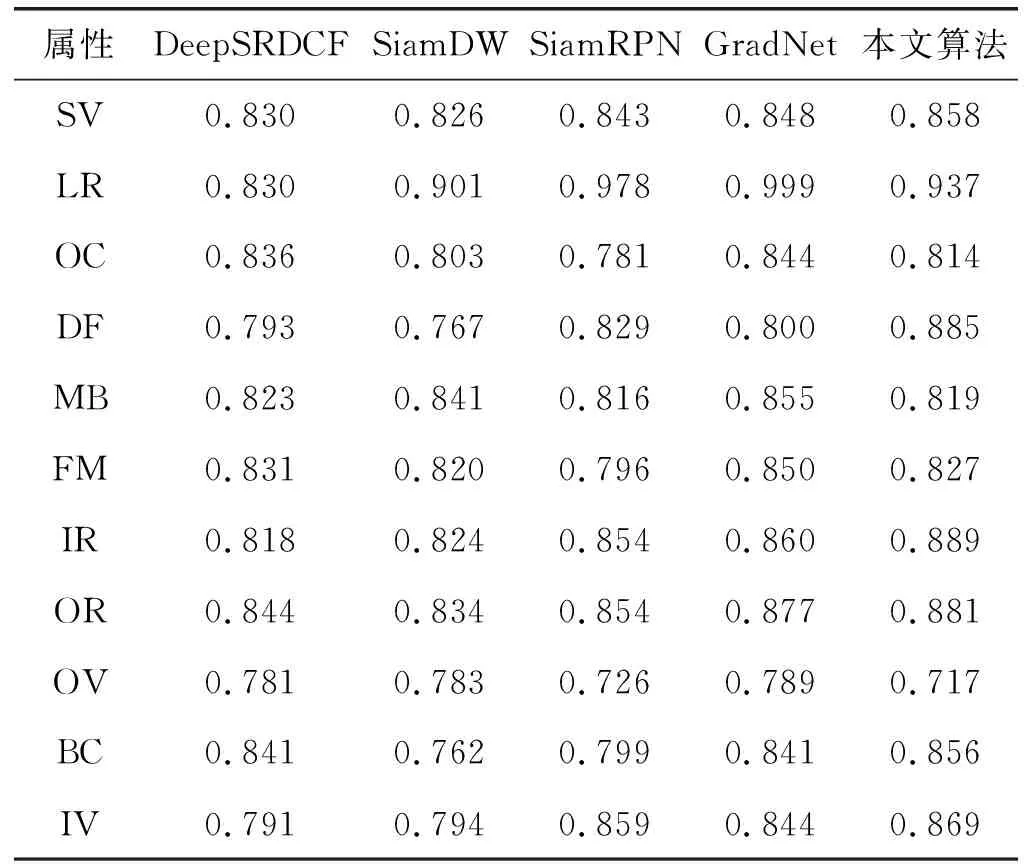
表4 OTB100数据集上11种属性的精确度
3.3 VOT基准
与OTB基准一样,VOT基准也是视觉跟踪领域使用较广泛的数据集。本文选用VOT2015数据集对算法进行实验对比验证。VOT2015包含了60个视频图像序列。在评价指标方面,我们选取3个常用的VOT基准评价指标来评价跟踪器的性能,分别是准确率(Accuracy,A)、鲁棒性(Robustness,R)和常用来对跟踪器进行排名的评价指标平均重叠期望(Expected Average Overlap,EAO)。其中,跟踪器准确率和平均重叠期望得分越高代表着算法表现更好,而鲁棒性得分越低则反映跟踪器跟踪性能更优秀。
在VOT2015基准下,本文选用DSST[5]、SAMF[10]、SRDCF[33]、DeepSRDCF[34]、SiamFC[13]和SiamDW[18]六种主流算法和本文算法进行比较。从表5中可见,本文算法鲁棒性为1.08,在7个算法中排名第三,但准确率和平均重叠期望都取得了最好的效果。在准确率中,本文算法比第二名算法SiamDW提高了0.01。在平均重叠期望中,本文算法和DeepSRDCF取得了同样的结果,比DSST提高了0.15,但DeepSRDCF只有不到1帧/秒的跟踪速度远远达不到实时性,而本文算法取得的65帧/秒达到了实时的跟踪速度。此外,图7展示了各算法在VOT2015数据集上平均数学期望的排名。

表5 7种算法在VOT2015数据集上实验结果
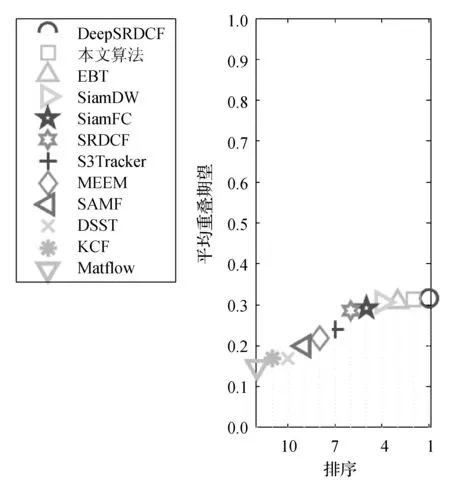
图7 VOT2015数据集上的平均重叠期望
4 结 语
本文在深度学习目标跟踪算法的框架下,针对深度卷积网络在复杂场景的不足,提出一种结合注意力机制和特征金字塔的目标跟踪算法。通过对网络的重新构建,将通道注意力机制和特征金字塔模型融入孪生卷积神经网络并在训练中利用Focal Loss函数解决样本训练的问题。实验表明,本文算法能够较好地解决一些复杂场景难以跟踪的问题,有效地提高了目标跟踪的成功率。但同时实验也发现,引入特征金字塔模型来提高特征表征能力会增加计算量,降低了算法跟踪的速度。因此,如何改进本文算法的跟踪速度,将是下一步研究的工作重点。
猜你喜欢
环球时报(2022-09-19)2022-09-19
Contemporary Social Sciences(2021年5期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
少儿美术(快乐历史地理)(2019年2期)2019-06-12
北京航空航天大学学报(2018年1期)2018-04-20
童话世界(2017年11期)2017-05-17
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
