
基于风格迁移的面部表情识别方法
2023-03-15 08:47肖世明章思远毛政翔
计算机应用与软件 2023年2期
肖世明 章思远 毛政翔 黄 伟,2
1(南昌大学信息工程学院 江西 南昌 330031) 2(南昌大学信息化办公室 江西 南昌 330031)
0 引 言
人脸面部表情是最直接、最有效的情感表达方式。Mehrabian等[1]做过研究表明,在人类日常交流的主要方式和途径中,传递信息最多的是人脸表情,其次是声音和语言,传递信息量分别占信息总量比重是55%、38%和7%。Ekman等[2]提出了人类共有的六类基本表情:生气、害怕、厌恶、开心、悲伤、惊讶,而其他复杂的表情都是在此基础上复合而成,例如惊喜就是惊讶加上开心,这也成为研究者研究人脸表情分类的共识。人脸表情识别可以应用于诸多领域,如人机交互实时表情识别、驾驶员疲劳检测、谎言检测等。
面部表情识别的方法一般步骤有:人脸图像信息获取、图像预处理、图像特征表示与提取、特征分类器的训练。其中表情图像特征的提取成为影响表情识别率的关键因素。面部表情特征的提取由手工提取特征[3-5,13]到浅层学习提取特征[6-7],再到如今运用广泛的深度学习提取特征[8-12]。不管是手工提取特征或者是使用深度神经网络提取特征,表情的识别率都受到身份、性别、年龄等属性的影响。Zhang等[11]提出的IACNN方法考虑了身份信息等因素对面部表情识别的影响。
研究表明,对于同一个人,可以通过比较他的当前表情和他的中性表情来判断他的表情[15]。也就是说一个人的面部表情可以分解为表情成分和中性成分[16]。根据这一研究,Kim等[17]和Lee等[18]利用需判断的表情图像和对应的中性表情图像的特征差异或者图像差异来识别面部表情。然而在这些工作中,识别面部表情的个体对应的中性表情都是可以直接获得的。而在现实情况下,并不是每个给定个体对应的中性表情都是可以直接获得的。为了解决这一问题,需要构建一个根据给定表情图像生成中性表情图像的生成器,并且该生成器不会改变个体的身份信息。随着生成对抗网络(Generative Adversarial Networks,GAN)[19]的提出,越来越多基于GAN的图像生成方法被提出。一个GAN模型包括生成器和判别器两部分,通过生成器和判别器之间的对抗训练生成逼真的图像。原始的GAN模型使用一个随机向量作为输入,缺少必要的约束,这使得生成的图像质量参差不齐。因此,在原始GAN模型的基础上,Zhu等[20]提出循环一致生成对抗网络(Cycle-consistent Generative Adversarial Networks,Cycle-GAN)。Cycle-GAN可以完成非成对图像的图像到图像的风格迁移。该网络使用源空间图像而非随机变量作为输入,通过结合循环一致损失和对抗损失共同训练模型,可以无监督地学习源空间到目标空间的映射。Cycle-GAN被广泛地应用于图像风格迁移。
根据上述分析,本文提出一种基于风格迁移的面部表情聚类识别方法。使用Cycle-GAN训练不同表情的生成器,将任意给定表情图像迁移到对应中性表情图像,生成器和表情一一对应。如图1所示,给定含有各种随机表情的人脸图像,通过中性表情生成器将含有表情的图像迁移到中性表情图像。在这一过程中,生成的中性表情图像不会改变原图像的身份信息,同时生成器会学习到不同表情的成分,即将不同表情的表情成分“存储”在对应的生成器中。
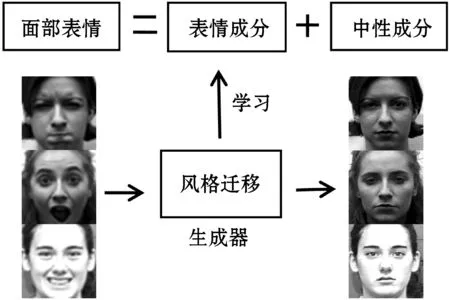
图1 表情风格迁移示意图
输入一幅表情图像到不同个数(取决于数据集表情类别数)的生成器中生成一组图像,由于不同的生成器学习到不同的表情成分,所以这组图像中,只有学习到输入图像的表情成分的生成器可以成功将该表情图像迁移为中性表情。而其他生成的图像则保留原表情信息,因为这些生成器中不具有该表情成分,故而不能将该表情图像迁移为中性表情图像。所以只要找到迁移为中性表情对应的含有该表情成分的生成器即可识别出该图像的表情类别。在生成的图像中,表情标签只有中性和输入图像的表情标签,这样将面部表情识别的多分类问题转化为二分类问题。本文使用支持向量机(Support Vector Machine,SVM)作为分类器。在做分类任务时,使用CNN卷积神经网络提取面部表情特征用于分类。
1 基于风格迁移的中性表情生成
1.1 Cycle-GAN
Cycle-GAN模型结构如图2所示,包含两个生成器和两个判别器,分别为GAB、GBA、DA、DB。Cycle-GAN可以通过学习源域(Source Domain)A与目标域(Target Domain)B之间的映射关系,从而完成图像到图像的风格迁移。生成器GAB学习从源域到目标域的映射f1:A→B,生成器GBA学习从目标域到源域的映射f2:B→A。判别器DA、DB分别用来判断各自输入的图像是否为源域A、目标域B的真实图像。
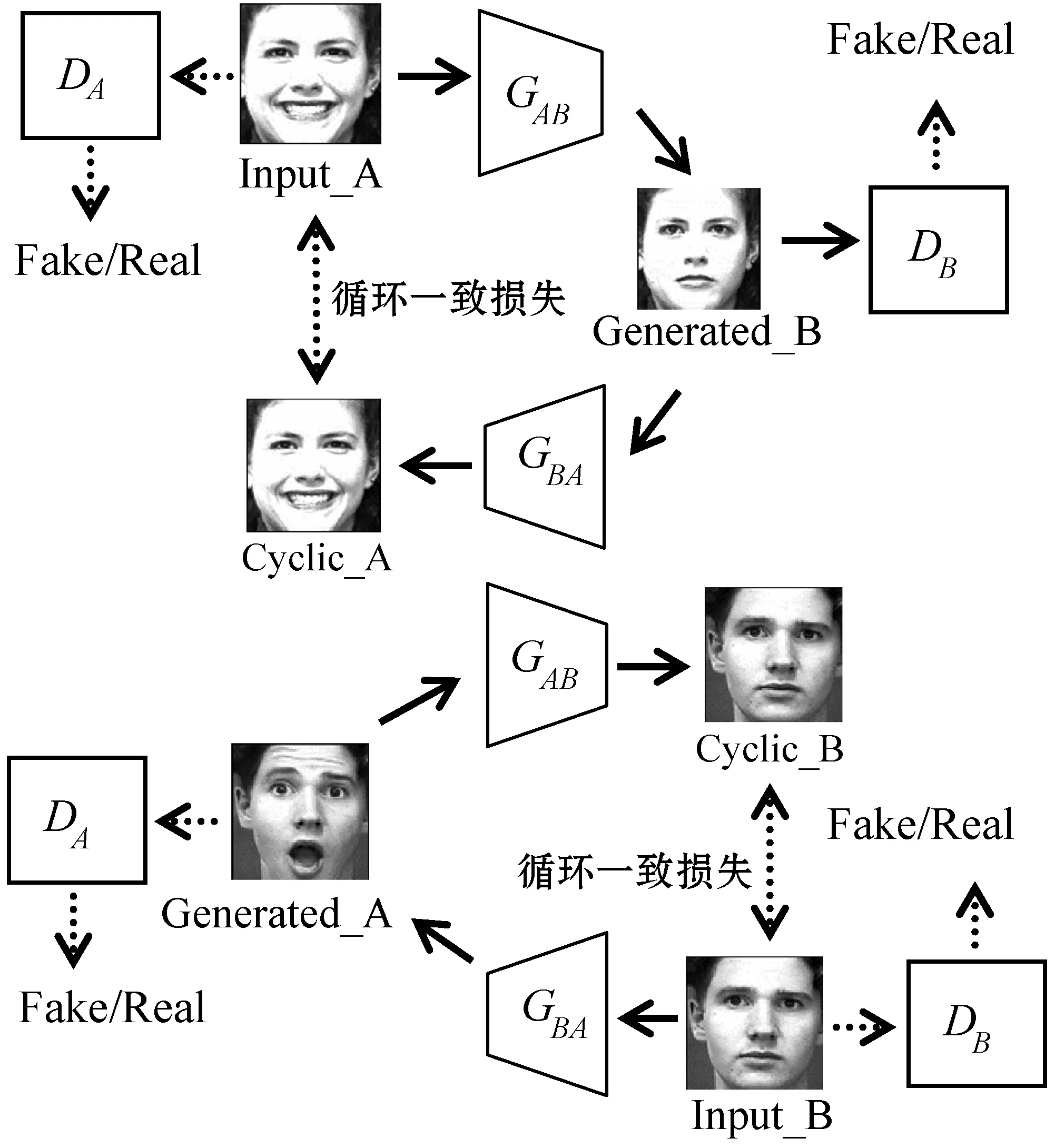
图2 Cycle-GAN的网络结构
Cycle-GAN的损失函数由两部分组成:
1) 生成对抗损失(Generative Adversarial Loss):
LGAN(GAB,DB,A,B)=Eb∈PB[logDB(b)]+
Ea∈PA[log(1-DB(GAB(a)))]
(1)
式(1)为A→B的生成对抗损失函数,a、b分别为来自源域A、目标域B的图像。生成器GAB尽可能生成与目标域B逼近的图像GAB(a),判别器DB则判断输入图像是否为真实的目标域B图像。
LGAN(GBA,DA,B,A)=Ea∈PA[logDA(a)]+
Eb∈PB[log(1-DA(GBA(b)))]
(2)
式(2)为B→A的生成对抗损失函数。生成器GBA尽可能生成与源域A逼近的图像GBA(b),判别器DA则判断输入图像是否为真实的源域A图像。
2) 循环一致损失(Cycle Consistency Loss)。
只有生成对抗损失是无法训练模型的,因为根据上述损失函数,生成器GAB可以将所有的源域A图像都映射为目标域B的同一幅图像。例如可以将所有高兴表情转换为中性表情,但是这些中性表情都是同一个人。同理,生成器GBA也有同样的问题。所以在Cycle-GAN中引入了循环一致损失函数Lcyc,公式如下:
(3)
生成器GAB和GBA分别学习f1和f2两个映射的同时,要求GAB(GBA(b))≈b以及GBA(GAB(a))≈a。即目标域B的图像b,经过f2映射得到图像GBA(b),再经过f1映射得到的图像GAB(GBA(b)),两者之间要尽可能相似。同样,对于源域A的图像a,经过f1映射得到图像GAB(a),再经过f2映射得到的图像GBA(GAB(a)),两者之间要尽可能相似。这样就保证了在两个域之间的图像转换不会映射为同一幅图像。
最终网络的所有损失加起来为:
L(GAB,GBA,DA,DB)=λ1LGAN(GAB,DB,A,B)+
λ2LGAN(GBA,DA,B,A)+λ3Lcyc(GAB,GBA)
(4)
式(4)中λ1、λ2、λ3分别为调节生成损失、对抗损失和循环一致损失所占权重的超参数。在所有的损失函数中,对于生成器来说需要最小化损失函数,对于判别器来说需要最大化损失函数。
1.2 中性表情生成方法
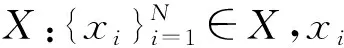
Cycle-GAN包含两个生成器和两个判别器,训练模型时,每次只将一类表情图像作为源域输入到生成器Gxiy中,中性表情图像作为目标域输入到生成器Gyxi中。将两个生成器生成的两幅图像输入到两个判别器中,得到两个表示图像真实度的数值。再通过模型定义的生成对抗损失和循环一致损失控制生成器生成更加真实且风格更加接近目标域的图像,最终完成图像的风格迁移。如此训练多次(次数由数据集表情类别数而定),每次用数据集中不同的表情作为源域,目标域则同为数据集中的中性表情,得到不同表情到中性表情的生成器Gxiy。
在进行中性表情生成的时候,本文使用已经训练好的生成器Gxiy。如图3所示,输入一幅身份信息为A的表情图像到生成器Gxiy(此时xi为吃惊)中,生成对应的中性表情图像,且保留了原身份信息。将不同的表情图像输入到对应不同的生成器Gxiy中,便可得到不同表情图像对应的中性表情图像。
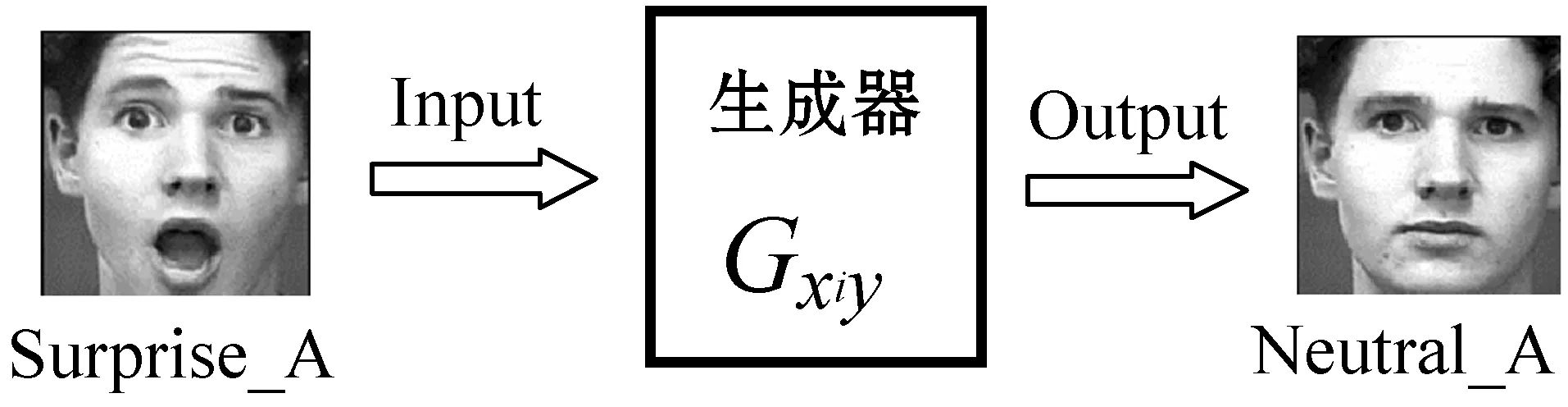
图3 中性表情生成方法
2 基于风格迁移的表情识别方法
2.1 基于CNN的面部表情特征提取
卷积神经网络(Convolutional Neural Networks,CNN)可以有效提取图像特征用于训练分类器做分类任务。传统的卷积神经网络由三部分组成:卷积层、池化层和全连接层。卷积层用于提取和保留图像特征。池化层对特征进行降维和抽象,可以有效减少网络参数,避免过拟合现象。全连接层连接前面提取到的特征,根据不同的任务输出不同的结果。
本文使用的CNN网络结构如图4所示。网络包含五个卷积层和一个全连接层。每个卷积层的卷积核大小均为3×3,步幅均为1,经过每层卷积之后通道数为原来的两倍。

图4 CNN网络结构及特征图
在训练CNN网络时,损失函数用来计算模型输出值与真实值之间的不一致程度,损失函数值越小,模型的鲁棒性越好。本文将使用L2 loss(均方误差)作为模型的损失函数。L2 loss的计算公式如下:
(5)
式中:N为样本数,x(p)与y(p)分别表示模型的输出值与目标值,P为维数。由于L2 loss取平方值的缘故,会放大较大误差和较小误差之间的差值,所以通过L2 loss训练网络可以使得提取的不同表情特征之间的距离加大,便于更好分类。
在训练阶段,输入数据集中的单通道表情图像,大小为128×128,经过五个卷积层之后输出的特征图为4×4×512。将该特征图输入到全连接层之后得到512维的输出值。通过最小化损失函数使模型输出值逼近真实值,以得到更加鲁棒的表情特征。将表情图像输入到训练好的CNN网络中,得到的512维输出值即为提取到的表情特征。
2.2 表情识别方法
本文提出一种基于风格迁移的表情识别方法。训练把面部表情图像迁移到中性表情图像的生成器,生成器中“存储”了该表情的表情成分。输入表情图像到所有表情生成器中,得到一组表情图像。在该组图像中,只有“存储”了输入图像的表情成分的生成器可以成功迁移为中性表情,而剩下的图像则保留原表情。将表情识别任务转换为二分类任务。
本文使用SVM作为二分类器,训练SVM时,将数据集中所有非中性表情图像统一标记为正类,中性表情图像标记为负类。将所有图像输入到训练好的CNN模型中提取表情特征,再将提取到的表情特征用于训练SVM做分类。
测试阶段,将通过生成器生成的一组图像输入CNN网络提取表情特征,提取到的表情特征用于SVM分类,最终得到识别结果。
方法的具体步骤如下:
Step1输入面部表情图像到不同的表情生成器Gxiy得到一组图像。每幅图像用image_xi表示,xi标记生成该图像的生成器对应的表情标签。
Step2将这一组图像输入到CNN网络,提取到一组表情特征。每幅图像对应的特征用Feat_xi表示。
Step3将提取到的表情特征输入到SVM中做二分类,得到分类结果。取分类结果为负类(中性表情)的特征Feat_xi对应的xi为最终表情识别的结果。
3 实 验
3.1 实验设置与环境
Cycle-GAN同时对生成器和判别器进行训练。训练使用的优化器为Adam,学习率为0.000 2,动量为0.5。对于Cycle-GAN损失函数中的三个超参数:对抗损失超参数λ1,生成损失超参数λ2,循环一致损失超参数λ3,本文使用的是Zhu等[20]在实验中设定的值,分别设为1、5、10。训练时BatchSize为1,迭代次数为150。
在CNN网络中,在每层卷积层之后都使用了批标准化(Batch Normalization,BN)[21]处理。批标准化之后使用的激活函数为ReLU。并且为了防止在训练时出现过拟合,在全连接层之后,使用了舍弃概率为0.5的Dropout。
实验使用的深度学习框架为PyTorch,GPU为NVIDIA TITAN V,显存为12 GB。编程语言为Python 3.5,操作系统为Ubuntu 16.04。
3.2 数据集
本文实验使用了三个面部表情识别数据集:CK+[22]、MMI[23]、RAF-DB[24]。其中CK+和MMI为实验室环境下的表情数据集,RAF-DB为自然环境下的表情数据集,数据集图像样本如图5所示。在做数据集预处理时,使用OpenCV人脸检测算法定位人脸区域,自动裁剪出面部表情图像。然后统一转化为大小128×128的单通道灰度图像。

图5 CK+、MMI、RAF-DB数据集的图像样本
CK+数据集是在Cohn-Kanada Dataset基础上扩展得到的,被广泛地用于面部表情识别。数据集是在实验室条件下获取,包含了从123个人中得到的593个图像序列,每个表情序列都为从中性表情过渡到峰值表情。数据集包括七类表情:生气(Anger)、蔑视(Contempt)、厌恶(Disgust)、恐惧(Fear)、高兴(Happy)、悲伤(Sad)、惊讶(Surprise)。实验使用的是带有表情标签的327个序列,取每个序列的最后三幅图像为该表情图像,表情标签和序列标签一致。得到981幅表情图像,不同的表情数量分布如表1所示。

表1 CK+数据集表情数量分布
MMI数据集包含236个图像序列,从31个人中获得。每个序列数据集包括六类基本表情:生气(Anger)、厌恶(Disgust)、恐惧(Fear)、高兴(Happy)、悲伤(Sad)、惊讶(Surprise),相比CK+数据集,少了蔑视表情。每个图像序列从中性表情过渡到峰值表情,再从峰值表情过渡回到中性表情,峰值表情处在序列中段。实验选取208个正脸角度的序列,取每个序列中段的3幅图像作为表情图像,标签为该序列标签。得到624幅表情图像,不同的表情数量分布如表2所示。

表2 MMI数据集表情数量分布
RAF-DB是从网页上抓取的大量人脸图像,采用众包的方式标记表情标签的自然条件下的表情数据集。RAF-DB包含15 339幅标记了七类基本表情(愤怒(Anger)、厌恶(Disgust)、恐惧(Fear)、高兴(Happy)、悲伤(Sad)、惊讶(Surprise))的图片,和3 954幅标记了12类复合表情的图片,实验只用标记为基本表情的图片。由于RAF-DB数据集存在严重的样本比例失衡问题,例如高兴的表情图片有5 957幅,而恐惧的表情图片只有355幅。所以每个表情图片选取数量以最少的恐惧表情为标准,都为355幅。
3.3 实验结果与分析
本文实验在三个数据集上均采用10折交叉验证,实验结果取10次交叉验证结果的平均值。为了评价本文提出的方法的有效性,每个数据集的实验结果中均设有Baseline。Baseline的结果为本文提取表情特征的CNN网络直接用于表情分类的结果。在使用CNN网络进行表情分类时,在CNN网络最后加一层输出为6维或7维(由数据集表情类别数而定)数值的全连接层,使用交叉熵(Cross Entropy Loss)作为损失函数进行表情分类。
3.3.1CK+数据集
根据2.2节表情识别方法可知,不同表情输入到生成器生成的中性表情的图像质量对最终的识别结果有很大影响。图6为在CK+数据集上的迁移效果,单数行是输入的表情图像,偶数行是对应表情生成的中性表情图像。

图6 CK+数据集上的表情迁移效果
使用本文提出的方法,在CK+数据集上的表情识别准确率达到98.47%,如表3所示。为了评估本文提出的方法在CK+数据集上的表现,将实验结果与近几年提出的六种表情识别方法(LBVCNN[9]、DTAGN[10]、IACNN[11]、RN+LAF+ADA[25]、ppfSVM[26]、DCMA-CNNs[12])进行对比。LBVCNN、DTAGN和ppfSVM三种方法输入的为表情序列,训练数据的规模远大于本文方法使用的数据规模。可以看出,本文方法较比其他几种方法在准确率上都有提高。
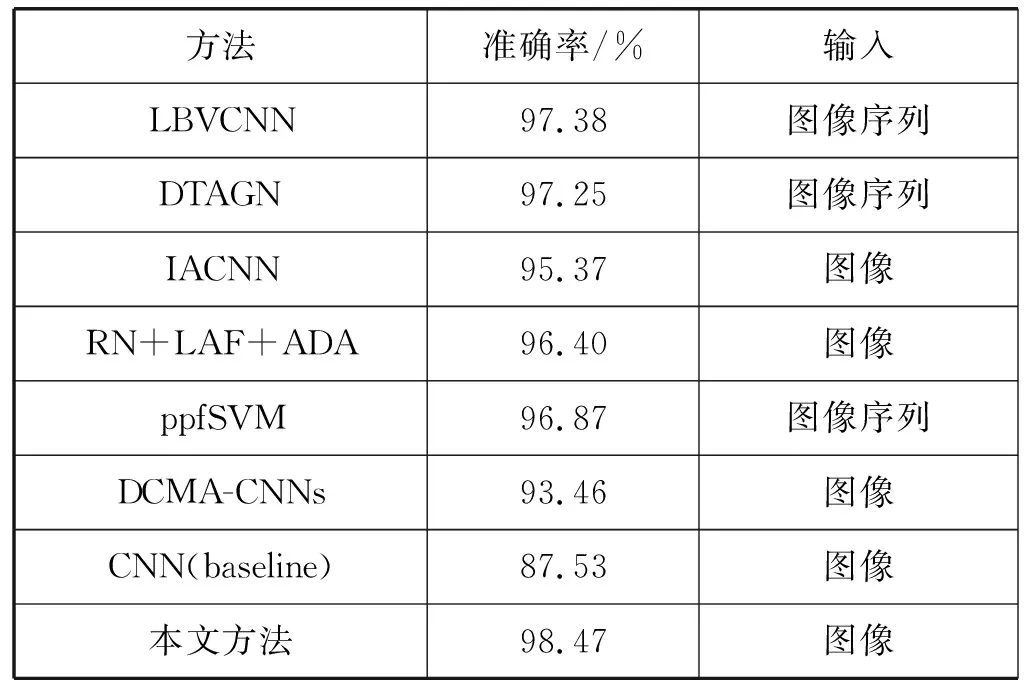
表3 不同方法在CK+数据集上的准确率对比
表4为本文方法在CK+数据集上各类表情识别的混淆矩阵,表格斜对角线的值对应各表情识别准确率,其他数值为表情识别错误率。通过混淆矩阵看出,蔑视表情的识别率最低,为96.39%。原因是蔑视表情在数据集中的数量较少,将该表情迁移至中性表情的生成器学习到的特征较少,生成的图像质量偏差,从而影响准确率。
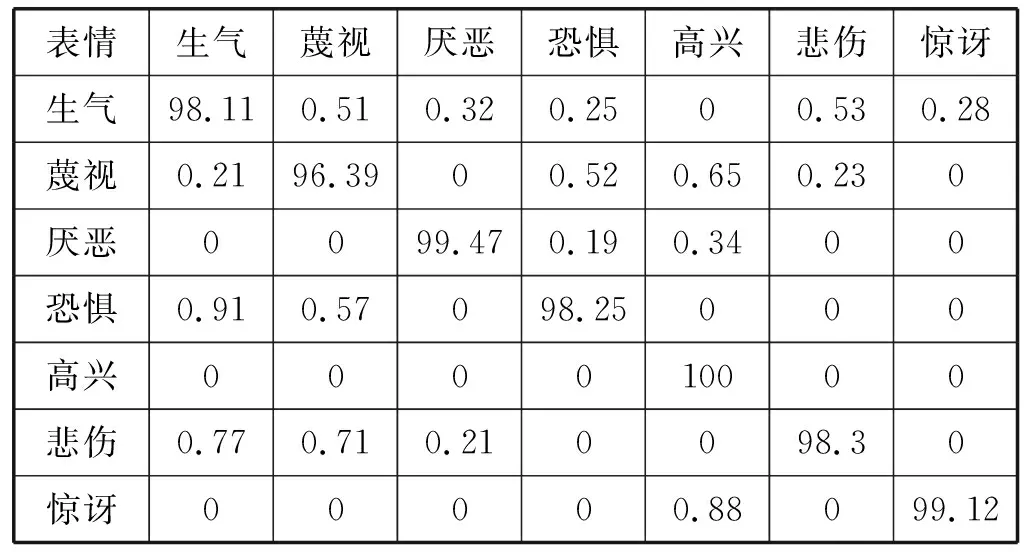
表4 CK+数据集上的混淆矩阵
3.3.2MMI数据集
使用本文提出的方法,在MMI数据集上的表情识别准确率为85.27%,如表5所示。同样,为了评估本文方法在MMI数据集上的表现,将实验结果同近几年提出的表情识别方法(IACNN[11]、STM-Explet[14]、DTAGN[10]、HOG-3D[13])进行了比较。其中STM-Explet、DTAGN-Joint、HOG-3D均使用图像序列作为输入,以此得到表情变化的时序信息,本文方法相比于这三个方法,准确率都有显著的提高。而对于同样使用图像输入的IACNN方法,本文方法更是提升了近14百分点的准确率。

表5 不同方法在MMI数据集上的准确率对比
MMI数据集上各类表情识别的混淆矩阵如表6所示。可以看出,恐惧表情的识别率比较低,容易与厌恶表情和惊讶表情混淆。导致该现象的原因为,MMI数据集中这三种表情图像在特征上比较相似,使得生成器学习到的表情特征也较为相似,从而影响准确率。另一方面,高兴表情极易识别,准确率达到96.13%。
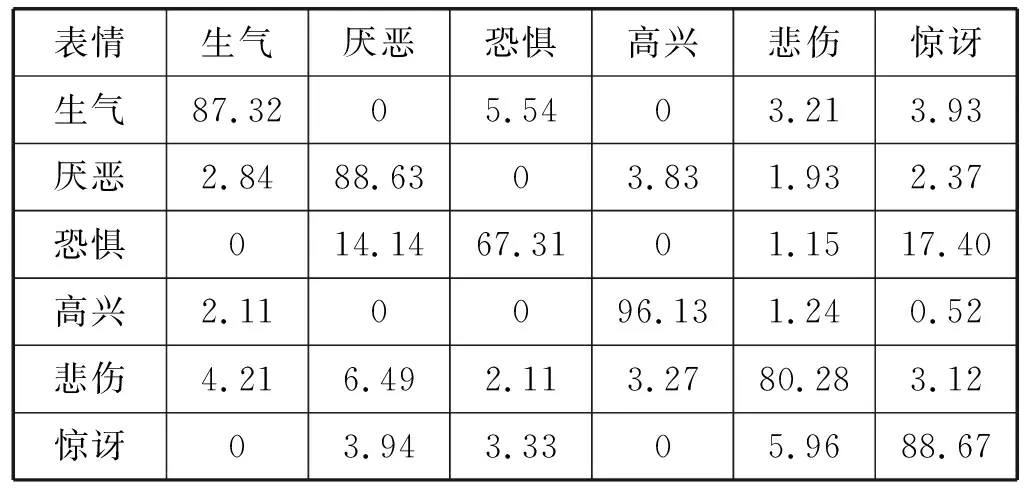
表6 MMI数据集上的混淆矩阵
3.3.3RAF-DB数据集
RAF-DB数据集的迁移效果如图7所示,单数行是输入的表情图像,偶数行是迁移至中性的表情图像。使用本文提出的方法,在RAF-DB数据集上的表情识别准确率为78.13%。同样为了评估本文方法在RAF-DB数据集上的表现,将实验结果与相关方法进行比较,实验结果如表7所示。其中VGG、AlexNet、baseCNN、DLP-CNN[24]是RAF-DB数据集作者给出的基准方法。FsNet+TcNet[27]、Boosting-POOF[28]为当前较为先进的方法。通过表7可知,本文方法相比于数据集给出的基准方法中准确率最高的DLP-CNN方法,准确率有4%左右的提升。并且实验结果的准确率接近于当前最好方法,证明了本文方法在自然条件下的面部表情识别效果的可靠性。

图7 RAF-DB数据集上的表情迁移效果
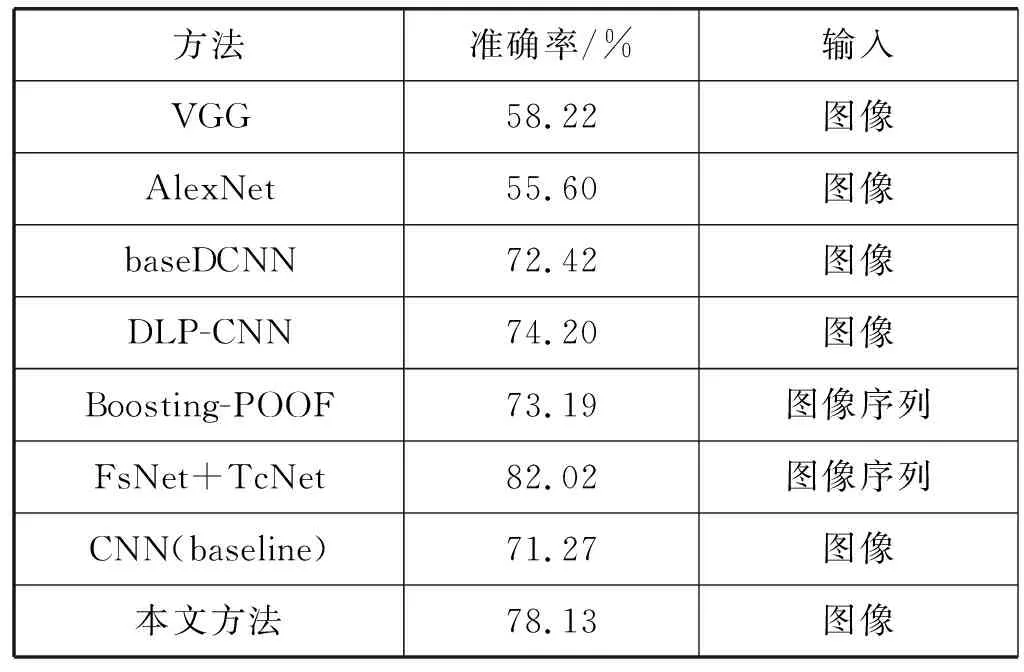
表7 不同方法在RAF-DB数据集上的准确率对比
表8为RAF-DB数据集上各类表情识别的混淆矩阵。可以发现,“惊讶”“高兴”和“生气”这三类表情具有更高的识别率,而“厌恶”“恐惧”和“悲伤”这三类表情的识别率较低,容易产生混淆。
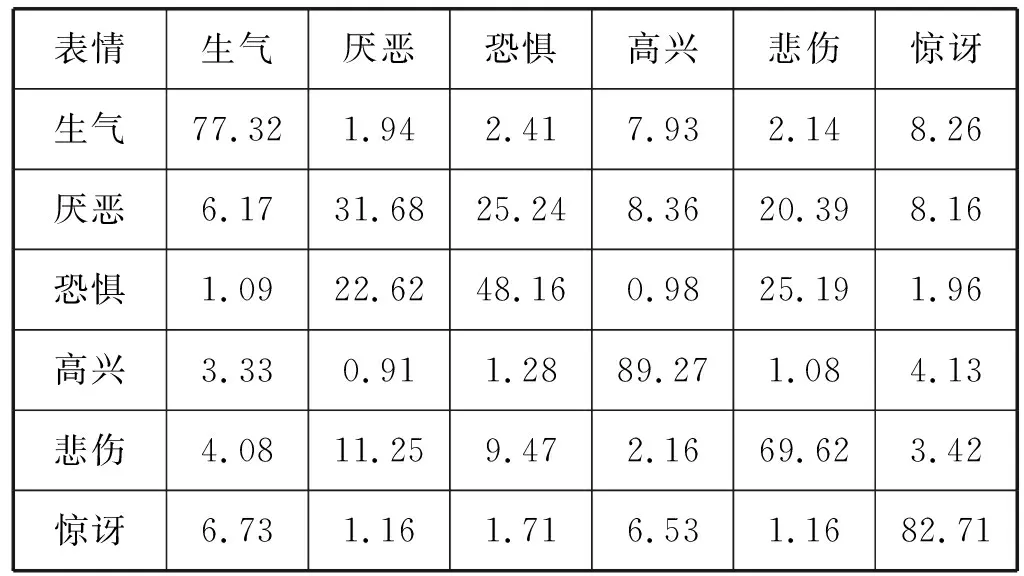
表8 RAF-DB数据集上的混淆矩阵
4 结 语
本文提出了一种基于风格迁移的面部表情识别方法。通过训练Cycle-GAN得到将不同表情图像迁移到中性表情图像的生成器,即生成器学习了不同表情的表情成分。将表情图像输入到训练好的生成器中得到一组图像,该组图像只具备中性表情和输入图像的表情。通过CNN网络提取该组图像特征用于SVM做二分类任务,得到中性表情图像,生成该图像对应的表情生成器即为表情识别结果。实验结果表明该方法不仅在实验室条件下的获得的数据集中表现良好,在自然条件下获得的数据集中也有较高识别率。在CK+数据、MMI数据集和RAF-DB数据集上的表情识别率分别为98.47%、85.27%和78.13%。在今后的任务中,将进一步提升表情迁移后的图像质量和迁移效果,以便提高在更加复杂环境下的面部表情识别率。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
英语学习(上半月)(2019年9期)2019-10-10
今日农业(2019年15期)2019-01-03
数学物理学报(2017年5期)2017-11-23
米娜·女性大世界(2016年8期)2016-08-17
工业设计(2016年11期)2016-04-16
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
