
融合多特征图及实体影响力的领域实体消歧
2023-03-13 10:05:40单晓欢齐鑫傲宋宝燕张浩林
计算机工程与应用 2023年5期
单晓欢,齐鑫傲,宋宝燕,张浩林
辽宁大学 信息学院,沈阳 110036
随着信息技术的飞速发展以及互联网的普及应用,网络数据正以指数级的速度增长,网络已经成为最大的数据仓库之一,且大量数据在网络上以自然语言的形式呈现[1]。但是自然语言本身具有高度的歧义性和多样性,歧义性体现在相同的实体指称在不同上下文中可以指不同的实体,例如阿里巴巴可以表示阿里巴巴集团、阿里巴巴(阿拉伯小说人物)、阿里巴巴(歌曲名)、阿里巴巴(书名);而多样性是指同一实体在文本中会有不同的指称,如马爸爸、风清扬、Jack Ma都指阿里巴巴集团创始人马云。如果能够消除上述歧义,将网络数据与知识库连接起来,将更有助于人们理解网络数据的语义信息,有效利用网络数据进行数据分析,同时像Dbpedia、YAGO这样的实体知识库也可以不断扩充,使其知识更丰富,而实现这一步的关键便是实体消歧技术。
实体消歧指的是识别文本中的歧义实体指称(命名实体),并为这些实体指称在众多的候选实体中匹配出最终的目标实体[2],其在智能问答[3]、语义搜索[4]以及推荐系统[5]等诸多领域都有广泛应用。实体消歧可分为基于无监督聚类的实体消歧[6],其把所有实体指称按其指向的目标实体进行聚类;以及基于实体链接的实体消歧[7],此类方法利用知识库获取候选实体列表,并将实体指称链接到与之最相似的实体上。近年来,随着知识图谱的广泛应用,基于实体链接的消歧方法成为解决消歧任务的主流方法,因此本文采用此类方法实现实体消歧。
本文针对现有方法进行研究发现,普遍存在的问题包括:仅考虑单一实体指称与其候选之间的语义关系,而忽略了同一文本中不同实体指称候选之间的联系,因此只能实现局部消歧(单实体指称消歧);利用候选实体构建图时,忽略了实体影响力及候选实体间的相似度对实体消歧的影响;将无歧义实体指称及其候选实体亦作为图节点,增加了后续图计算的复杂性,进而对消歧的效率产生影响。
针对上述问题,本文提出一种融合多特征图及实体影响力的实体消歧方法(entity disambiguation method combining multi-feature graph and entity influence,ED_MG&EI),该方法综合局部消歧与协同消歧的优势,有效实现同一文本多实体指称的整体消歧,本文主要内容如下:
(1)基于候选实体的多特征图构建。本文以金融领域为特定领域,对现有知识库进行预处理,提取金融类别相关关键词三元组,构建金融领域知识库;针对金融活动类文本,提取待消歧实体指称,融合多种特征提取语义信息并通过相似度计算,筛选候选实体作为顶点集合,利用知识库三元组信息获取候选实体间2-hop内的关系作为边集合,同时计算候选实体间的相似度作为边权值,进而将多特征信息充分融合到图模型中,完成多特征图构建。
(2)提出基于实体影响力的消歧方法,该方法既考虑不同指称候选之间的关联性,又将局部消歧的消歧信息转化为实体影响力,作为消歧计算的衡量指标之一。在消歧过程中,采用动态决策策略,利用PageRank算法,并结合实体影响力计算多特征图中候选实体的综合评分,进而获得可信度较高的消歧结果。
1 相关工作
目前,基于实体链接的消歧方法主要有局部实体消歧和协同实体消歧两类。局部实体消歧通常只利用实体指称与候选实体的上下文信息的特征表示,计算两者之间的相似度,进而选出目标实体。由于传统特征方法[8]多为启发式算法,需手工设计有效特征,且难以调整,进而无法获取更深层次的语义和结构信息。近年来,采用神经网络进行局部消歧的思想逐渐兴起,Sun等人[9]提出了一种基于记忆网络的实体消歧方法,该方法通过注意机制从周围的语境中自动找到重要线索,并利用这些线索进行实体消歧,不依赖任何手动设计的特性。为了有效地学习模型参数,其需要大量的训练数据。Deeptype[10]是一种将符号信息集成到带有类型系统的神经网络推理过程中以实现实体消歧的方法,其能够将结构化数据和非结构数据进行整合,在英语、法语、德语以及西班牙语上具有较理想的消歧效果。Alokaili等人[11]提出了一种基于长短时记忆循环神经网络的神经网络结构,用于编码目标地理实体的上下文,进而实现地理实体消歧,其在英语和西班牙语两个注释语料库上对方法进行了评估。
协同实体消歧认为同一文本中不同实体指称存在语义关联性,进而推断其候选实体之间也具有依赖关系,在局部消歧基础上增加协同策略,结合这种关系进行综合计算,以提升实体消歧性能。文献[12]提出了一种结合语义表示学习的基于图的实体链接模型,基于RDF数据训练的语义向量构造了一个实体相关图,并在图上利用PageRank算法计算实体指称的正确候选实体。近年来,也有相关算法[13-14]将深度学习与图方法结合,将构建的实体图输入到图神经网络中学习,此类方法消歧效率较高,但文档较多训练起来工程很大。文献[15]为解决短文本稀疏性造成概念化困难的问题,通过度量术语之间的相关性、选择信息术语并对信息术语进行优先排序,以突出其辨别能力,减少噪声干扰。Jia等人[16]提出了一种层次语义相似模型,该模型基于实体指称上下文、实体描述和类别等多个信息源来寻找实体指称与目标实体的语义匹配。实体链接标注系统ABACO[17]假定标注的实体与文档的主题一致,以解决名称歧义问题。根据候选实体在知识图中的中心性和与文档主题的文本相似度对其进行评分,进而剔除最差的候选实体。
2 基于候选实体的多特征图构建
本文针对特定领域,从财经网、南方财富网、搜狐财经等网站爬取金融领域相关语料,获得经过人工标注、数据清洗、事件抽取而最终生成的待消歧实体指称集,并在此基础上进行研究,实现参与金融活动要素的实体消歧。因为金融相关文本表达的信息主要是金融交易或投资之间的关系,所以命名实体识别后的实体指称项(待消歧实体)为参与金融活动要素的企业及与企业相关的个人实体。
2.1 领域知识库构建
CN-DBpedia[18]是由复旦大学知识工场实验室研发并维护的大规模通用领域结构化百科,是国内最早推出的也是目前最大规模的开放百科中文知识图谱,涵盖数千万实体和数亿级的关系。CN-DBpedia主要从中文百科类网站(如百度百科、互动百科、中文维基百科等)的纯文本页面中提取信息,经过滤、融合、推断等操作后,最终形成高质量的结构化数据,即Dump数据集。
Dump数据集中有mention2entity信息110万+、摘要信息400万+、标签信息1 980万+、infobox信息4 100万+。Dump数据中的摘要信息、标签信息以及涵盖大量三元组关系、语义信息的infobox信息,适用于图节点及关系的挖掘;而mention2entity数据包含的信息则更注重表示实体对应的不同含义,即可能是具有相同字面表示的所有可能含义或者是现实中存在同一实体的不同别名的情况,因此这种数据对于候选实体生成具有一定的过滤作用。
由于本文只针对金融领域的实体消歧进行研究,因此从P2P(网络借贷)、小额贷款、互联网支付等金融新业态角度研究,通过人工定义关键词知识体系,从CN-DBpedia数据中提取金融类别相关关键词三元组,构建金融特定领域知识库,分别生成mention2entity_finance数据和Dump_finance数据,并将抽取的三元组关系批量导入到Neo4j图数据库中进行存储及管理。同时,为了有效提高候选实体的挖掘效率,本文将mention2entity_finance数据进行预处理,遍历该数据集,将具有唯一含义的实体对三元组提取并生成mention2entity_finance_one-to-one数据集,用于验证实体指称是否只具有唯一候选实体;将剩余的三元组继续存储在mention2entity_finance数据集中,即该数据集中实体指称具有多个候选实体。
2.2 多特征图构建
研究发现,同一文本下不同实体指称的高相关性,导致对应的不同候选集合之间也具有一定的语义联系,且这种语义联系对消除实体歧义具有一定的作用[2],为此本文将候选实体及其之间的联系构建为有向加权图G=(V,E,LV,W)表示,其中V为节点集合,表示不同实体指称的候选实体及候选实体的1-hop邻居实体;E表示边集合,由不同实体指称的候选实体之间的语义关系组成;LV则为节点标签属性集合;W表示边权值集合,候选实体之间的关联度通过边权值表示,权值越大,则表明两候选实体之间越相似。
2.2.1 候选实体筛选
对于候选实体的生成,首先将文本中所有识别出的实体指称项组成集合M={m1,m2,…,mn},其中n表示文本中实体指称项的个数。然后针对每个实体指称项mi,在预处理的知识库三元组数据中搜索与之同名的头实体,将对应的尾实体集合作为该实体指称的候选集Ei={ei1,ei2,…},同理获得全部实体指称的候选集合H={E1,E2,…,Es},其中每个候选实体即为多特征图的节点。
如果知识库(mention2entity_finance_one-to-one及mention2entity_finance)中没有同名实体,则把相应的实体指称项归为空实体。如果从mention2entity_finance_one-to-one获得实体指称的候选实体,则表明该候选实体为唯一的无歧义候选,将这类候选实体直接作为实体消歧结果,不再构建于图中,进而降低了图的规模并简化了后续图计算的复杂度。其余实体则具有多个候选实体,为避免过多候选实体对实体消歧效率产生的影响,本文选取top-k个候选实体作为构建多特征图的节点,当候选实体个数小于等于k时,选取指称项所有的候选实体作为它最终的候选实体;当候选实体个数大于k时,定义指称项与候选实体的相似度为指称相似度,选取相似度最大的k个候选实体作为最终的候选实体。本文指称相似度由衡量字符串特征的编辑距离语法相似度以及表示语义特征的上下文语义相似度构成。
(1)表示字符串特征的编辑距离语法相似度
编辑距离(edit distance,ED)是两个字符串之间,由一个字符串通过替换、插入和删除等一系列操作转换成另一个字符串所需的最少编辑操作代价。用EDm,ei(x,y)来表示字符串m和ei之间的编辑距离,其中x和y分别表示m和ei的长度。为统一量纲,本文对编辑距离进行归一化处理,如式(1)所示。当m和ei完全相同时,NED=0;反之,当m和ei完全不同时,NED=1,即NED(m,ei)∈[0,1]。
本文利用编辑距离对两字符串间的接近或相似程度进行衡量,将归一化的编辑距离转换为词语间的语法相似度,如式(2)所示,其值越大,表明两字符串的编辑距离越小,则越相似。
(2)表示语义特征的上下文语义相似度
编辑距离只反映了m和ei之间的字符串特征,未考虑任何语义特征,然而考虑到同一个实体所处的上下文环境相似,本文利用实体指称的上下文和候选实体在知识库中的上下文之间的文本特征计算实体指称与候选实体的相似性。对于m和ei之间的文本特征,采用经典的向量空间模型(vector space model,VSM)进行计算,通过空间上的相似性直观易懂地表达语义的相似度。
首先对实体指称和候选实体的上下文进行分词、停用词去除等预处理,再利用词袋模型将2个文本表示为向量,并计算2个向量之间的余弦值作为实体指称与候选实体的文本语义相似度,计算公式如式(3):
其中,X表示实体指称m上下文的词向量,Y表示候选实体ei的词向量,X·Y表示向量内积,||X||表示向量长度。
本文将上述两种相似度的线性组合作为实体指称与候选实体之间的指称相似度,如式(4)所示:
2.2.2 候选实体关系挖掘
实体关系属性是候选实体的重要属性之一,这种属性可以直接通过多特征图中的边表示。本文构建的领域知识库的Dump_finance数据中含有丰富的关系属性,本文通过检索头、尾实体为候选实体的三元组,获得候选实体间的关系属性,从而使候选实体相互连通形成网络图。具体过程为对每个实体指称的候选实体集合中的每个元素分别与其他候选实体集合中的所有元素进行关系查找,如果两者之间存在直接三元组或者具有2-hop的路径,则认为两候选实体之间存在关系,对应多特征图中两节点之间生成连接的边。为丰富消歧信息,提高实体消歧的准确性,在多特征图的构建过程中,既考虑了候选实体间的直接关系,又将2-hop内的间接关系体现在图中。
2.2.3 基于上下文语义相似度的权值计算
因为候选实体本身带有一定的描述信息,利用该语义信息可以计算不同实体指称的候选实体间的相似度,从而生成节点之间的边权值。本文将候选实体的描述文本表示为其上下文的文本向量,通过文本向量间的距离衡量不同指称的候选间的相似程度,其值由式(3)的余弦相似度计算所得。
综上,本文将构建的具有节点标签且能表示候选实体间语义关系及相似程度的有向加权图称之为多特征图。考虑某些实体指称只有唯一候选实体,这类无歧义候选实体即为消歧结果,无需构建于图中,简化了图的大小和后续图计算的复杂度。如图1所示,多特征图中节点由候选实体及候选实体之间的2-hop间接关系组成,边由不同实体指称的候选实体间的语义关系组成。图1中方形节点为实体指称,虚线表示实体指称与候选实体的对应关系,其上的权值为指称相似度,将作为候选实体节点的权值,因此本文构建的多特征图中不包含实体指称。
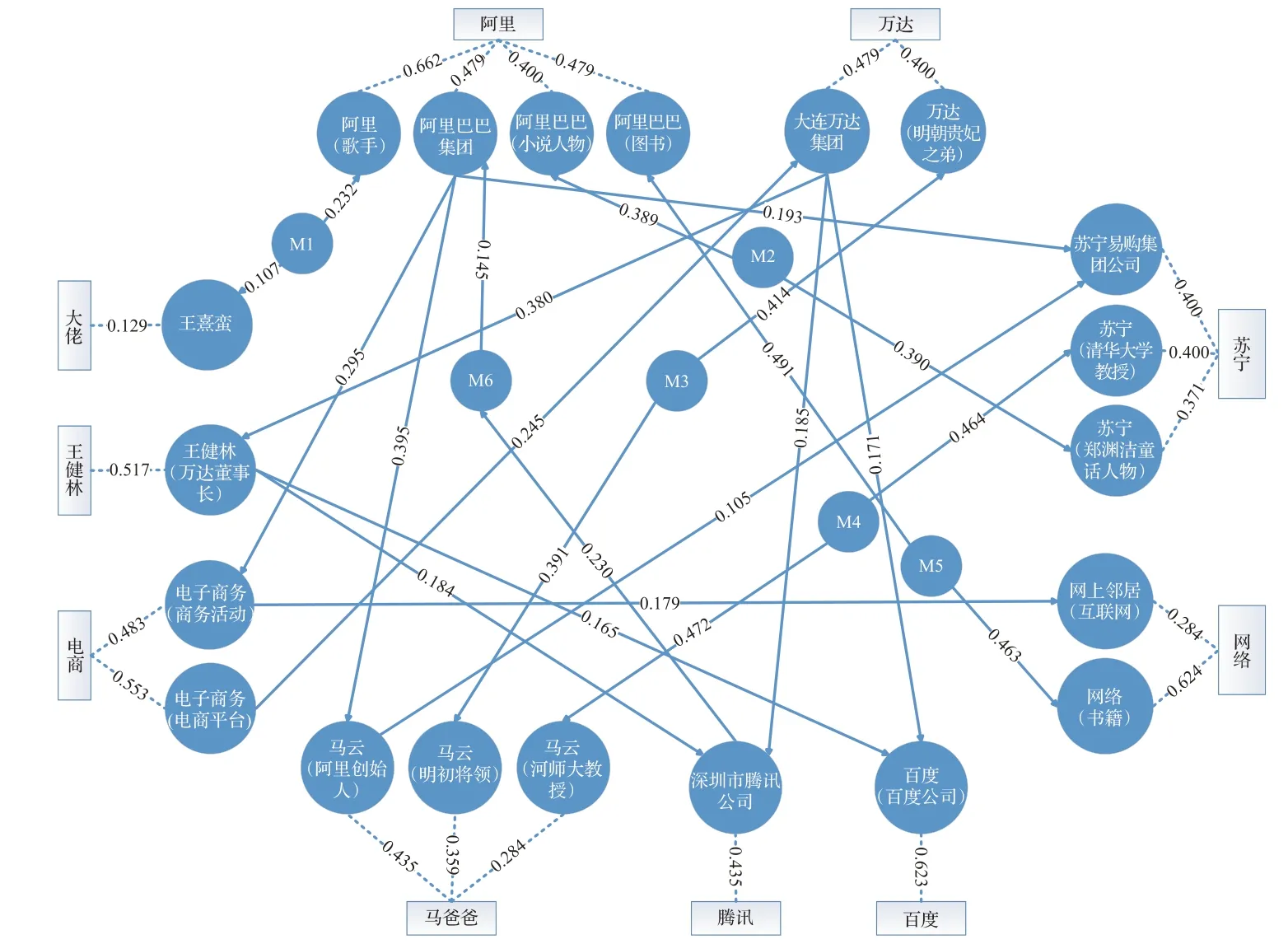
图1 多特征图示例Fig.1 Example of multi-feature graph
3 领域实体消歧
3.1 候选实体影响力计算
本文利用协同消歧的思想,即同一段文本的实体指称语义相近,推断知识库中的候选实体语义也相近[12]。同时在众多实体指称的候选实体中,唯一候选实体作为无歧义候选,其与其他实体指称的候选实体的关联性对确定目标实体具有一定的影响,因此本文将唯一候选实体与其他候选实体的关联性作为节点的影响特征。
对无歧义候选实体集合Ei′中的元素分别与图中其他候选实体集合Ei中的每个元素进行关系查找,通过检索特定金融领域知识库的Dump_finance数据中的三元组,如果E′i中的元素与Ei中的元素之间存在直接三元组,说明该候选实体与唯一候选实体之间有关联,则增加图中相应候选实体的影响特征,每出现一个三元组则影响特征值加θ,其中θ∈(0,1)。
与此同时,实体指称与候选实体之间的指称相似度也作为衡量该候选实体影响力的因素之一,因此实体影响力的具体定义如下。
定义1(实体影响力)无歧义候选的影响特征值与指称相似度之和。
3.2 基于改进PageRank和影响力的实体消歧
本文利用多特征图的多属性特征,确定图中候选实体选择的两种因素,一种是候选实体影响力,包括无歧义候选的影响特征和指称相似度,反映候选实体在图中的影响力大小;另一种是利用PageRank算法计算节点的重要程度。
PageRank算法是基于实现网页重要性排序的一种算法。本文将图中的节点对应为实体概念,然后通过PageRank算法捕捉图模型中各个节点的重要程度。常规的PageRank算法只考虑了出入度的平均分配,即某个节点的PageRank值为它入度节点集中每个入度节点的PageRank值除以它们的出度边数之和。本文将PageRank计算公式进行修改,以适应本文的有向加权图,每个入度节点给出的值大小不再是平均分配,而是引入多特征图中代表候选实体间相似度的边权值,按权值占比大小分配,具体公式如下:
其中,N为节点数,M(ei)表示链入ei节点的集合,N(ej)表示链出ej节点的集合,W(ej,ei)是节点ej、ei之间边权值,d为阻尼因子,一般取0.85。达到平稳状态时的PR值表示了各节点的重要程度。
本文综合考虑实体影响力及节点的重要程度进行消歧。在消歧过程中,采用动态决策策略依次对每个实体指称进行消歧,计算所有节点的PageRank值,将各节点的影响力与PageRank值相加,作为候选实体的综合评分,分数越高的候选实体越优先消歧;若出现不同指称中多个候选的综合评分相同,则选择候选个数最多的实体指称优先消歧。每确定一个实体指称的目标实体,则对多特征图中节点进行修剪,将该实体指称的其他候选实体从多特征图中移除,以减少后续的计算量,具体算法如算法1所示。图1最终的消歧结果如图2所示。
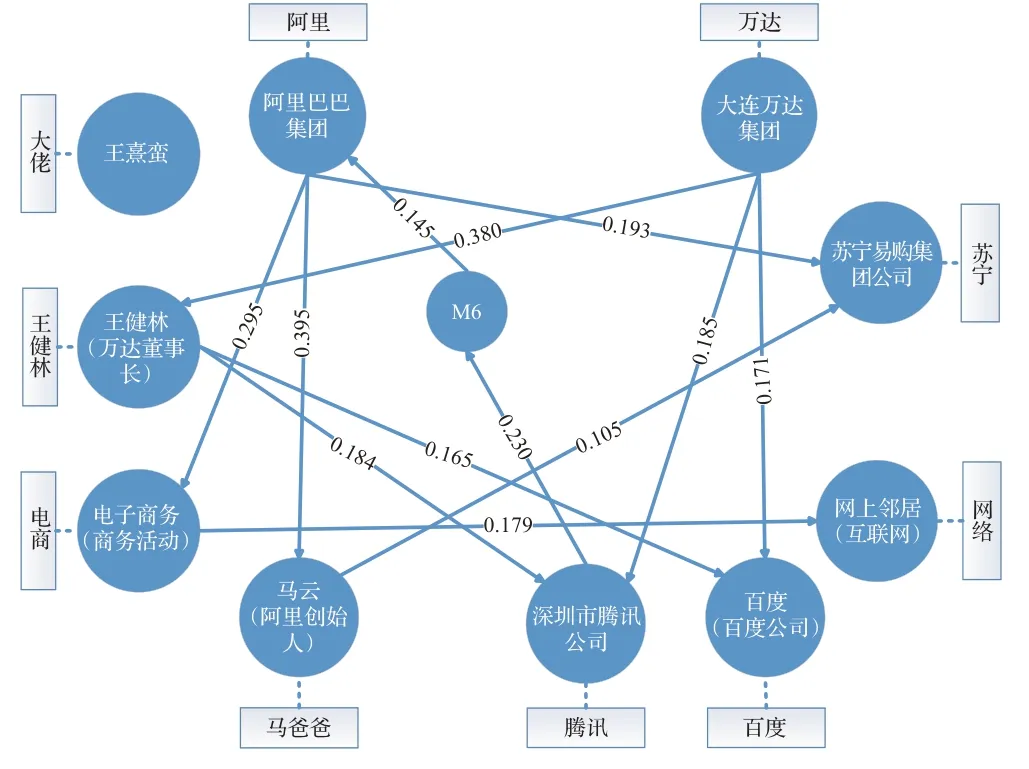
图2 消歧结果Fig.2 Disambiguation results
算法1ED_MG&EI Algorithm
Input:G,每个节点的影响力
Output:mention_entity_Dic(实体指称对应的目标实体)
Begin
1.对图G计算PageRank;
2.将每个节点的影响力加到其PageRank值上;
3.获取PageRank值+影响力最高的候选实体entity;
4.将entity对应实体指称mention的其他候选实体以及相关边从G中移除并在mention_entity_Dic中添加mention_entity_Dic[MENTION]=entity;
5.若mention_entity_Dic中的实体指称没有完全确定,返回1;
6.返回mention_entity_Dic;
End
4 实验与分析
4.1 实验设置
本文基于pycharm在Windows10环境下实现。实验采用从财经网、南方财富网、搜狐财经、新浪微博等网站爬取的金融活动文本为数据集。人工选取包含歧义实体较多的500篇文本,其中200篇作为训练数据,训练指称相似度中编辑距离语法相似度与上下文语义相似度的最优权值参数,300篇作为测试数据分析实验方法性能。语料预处理过程采用分词工具完成,包括分词、去停用词等过程。人工标记出与金融活动相关的公司实体和个人实体,通过命名实体识别可从文本中识别出共1 230个实体指称,通过人工方式标注了所有实体指称对应的正确实体(含NIL实体)。
本文采用准确率(Precision)、召回率(Recall)、F值三种评价指标,对提出方法的有效性进行验证。
4.2 实验分析
实验1特征参数的设置分析
将200篇文本构成的训练数据用于训练生成权值参数的最优解,在指称相似度中包含语法特征和语义特征两种,分别分配给两特征参数α和β,令α和β相加得1。测试实验使得两个特征同时发挥最大作用,通过对准确率Precise的分析,确定式(4)中α和β的最优值,如图3所示,当α=0.40、β=0.60时,准确率达到最大值。

图3 参数设置Fig.3 Parameter setting
实验2利用不分类候选生成图和去除无歧义候选的多特征图消歧的实验结果对比
实验2将所有实体指称生成的候选集都作为图节点,构建不分类候选生成图;按候选实体分类将包含多个候选实体的实体指称对应的候选集作为图节点,构建多特征图。表1为利用不分类候选生成图和去除无歧义候选的多特征图进行消歧的结果,由于本文多特征图中去除了无歧义候选,有效降低了图的规模,同时将节点影响力及节点的重要程度作为节点的综合评分,有效提高了消歧的准确性。

表1 不分类候选生成图和多特征图的实验结果对比Table 1 Comparison of results between unclassified candidate generating graph and multi-feature graph单位:%
实验3局部消歧、协同消歧和本文的集成消歧实验结果对比
为分析多种特征的有效性,本实验在基线系统的基础上分别叠加局部消歧、协同消歧和本文结合两种策略产生的集成实体消歧方法,三种方法与基线系统进行对比,实验结果如表2所示。

表2 消歧策略实验结果对比Table 2 Comparison of experimental results of disambiguation strategies 单位:%
实验4无向无权图与本文有向加权图方法实验结果对比
本文在现有图方法的基础上进行改进,将图变换成精度更高、信息更丰富的有向加权图,知识库三元组的头节点及尾节点提供有向边,图节点之间的相似性及语义关系为边提供权值,有向加权图使PageRank的计算结果更准确,实验进行有向加权图和无向无权图方法对比,实验结果如表3所示。

表3 无向无权图和本文有向加权图方法实验结果对比Table 3 Comparison of experimental results between undirected unweighted graph method and proposed directed weighted graph method 单位:%
实验5不同领域数据集对比
本文针对特定领域,在金融活动相关文本中提取实体,分析非法金融活动,在金融新业态角度研究非法金融活动的界定,构建金融领域知识库辅助消歧,因此相较于其他领域,金融领域文本的实体消歧效果更理想,实验结果如表4所示。

表4 不同领域实验结果对比Table 4 Comparison of experimental results in different fields单位:%
实验6不同方法实验结果对比
实验在金融领域数据集上复现了张涛等人[19]和高艳红等人[20]的方法,张涛等人[19]提出了一种基于图模型的维基概念相似度计算方法,有效地捕捉实体指称项文本与候选实体间的语义相似度。但图构建没有充分利用特征的表达,影响相似度计算。高艳红等人[20]提出了一种融合多特征的解决方案,将语义相似度融合到图模型中,但由于其构建的实体指称-候选实体图仅能对单一实体指称进行消歧,不适用于文本中多实体指称的集成消歧。本文针对上述问题,将无歧义候选实体去除,以降低图规模,同时综合考虑字符串特征、语义特征、实体影响力以及节点的重要程度等特征因素,以获得可信度较高的消歧结果,实验结果对比如表5所示。
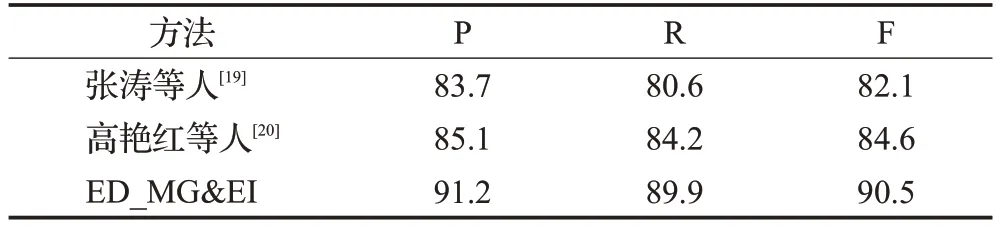
表5 本文方法与其他方法实验结果对比Table 5 Experimental results of this method compared with other methods 单位:%
5 结束语
本文对特定领域的实体消歧问题进行了研究,提出了一种融合多特征图及实体影响力的领域实体消歧方法。以金融领域为例,首先构建金融领域知识库,然后针对金融活动类文本,提取待消歧实体指称,利用构建的金融知识库,融合字符串及语义的相似特征,实体影响力及节点重要程度等特征属性构建多特征图;最后采用动态决策策略,利用PageRank算法,并结合实体影响力计算多特征图中候选实体的综合评分,进而获得可信度较高的消歧结果。实验结果验证了提出方法在特定领域实体消歧的精确度。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
计算机与数字工程(2021年12期)2022-01-15 06:24:02
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
中国外汇(2019年12期)2019-10-10 07:26:58
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
电脑与电信(2018年12期)2018-03-23 02:37:20
疯狂英语·新悦读(2017年2期)2017-04-08 01:31:27
海南师范大学学报(社会科学版)(2015年7期)2015-12-28 08:17:40
现代防御技术(2014年6期)2014-02-28 18:26:29
