
结合社区发现和局部恢复码的区块链扩容研究
2023-03-13 10:05:38姜承扬贾大宇于明鹤信俊昌
计算机工程与应用 2023年5期
姜承扬,庞 俊,2,贾大宇,于明鹤,信俊昌,刘 晨
1.武汉科技大学 计算机科学与技术学院,武汉 430070
2.智能信息处理与实时工业系统湖北省重点实验室,武汉 430070
3.东北大学 计算机科学与工程学院,沈阳 110169
4.东北大学 软件学院,沈阳 110169
近年来,区块链技术快速兴起,推动了诸多行业的发展。现有区块链系统全节点必须存储一份完整的区块链账本,虽然保障了数据安全,但不能满足数据快速增长的需求。区块链存储扩容成为当前区块链领域的研究热点之一。
目前已有许多研究提出了不同的区块链存储扩容方案,根据数据是否存储在区块链上可分为两类:链下方案[1-2]和链上方案[3-8]。链下方案将完整账本数据存储在第三方系统,区块链上只保存少量的非数据信息。虽然降低了存储开销,但提高了系统的中心化程度。因此许多研究工作采用链上方案[3-6]:利用分片技术,使区块链网络中每个节点只需存储完整账本的一部分,从而降低节点的存储压力。但存在部分节点出故障可能导致数据丢失的问题。因此文献[7-8]使用RS(Reed-Solomon)纠删码[9],在保证数据可恢复的前提下,降低系统存储开销。但该方案在恢复数据时需从其他节点获取较多的数据,带来较大的网络开销。并且未考虑节点之间的传输速度对数据请求效率的影响。若请求节点与目标节点之间的传输速度较慢,则会增加跨节点请求区块所花费的时间。
本文首先针对现有方案数据请求效率不够高的问题,改进文献[10]中提出的能够发现稳定非重叠社区的社区发现算法,并将其扩展到区块链,实现区块链节点分组,降低跨节点请求区块的响应时间。其大致流程如下:首先获取区块链网络中各节点间的传输速度作为连接边权重,然后对网络进行划分,使得各分组内部的平均连接速度尽可能大,从而降低组内节点间互相传输数据的时间开销。
其次,针对现有方案数据恢复网络开销较大的问题,本文采用局部恢复码[11(]local reconstruction codes,LRC)技术,减少了数据恢复时需要从其他节点获取的数据。其基本思想是:将原始数据分为若干个集合,并为每个集合构造局部编码块;对于单点故障,LRC码只需要同一集合的数据块和局部编码块即可实现数据恢复。
最后基于上述工作,提出了一种区块链存储扩容方案:首先基于改进的社区发现方法将区块链划分为组内平均连接速度较大的多个分组;然后在每个分组内使用LRC码对区块进行编码,获取编码块和数据块;最后将这些块存储到不同节点上(由一个分组的所有节点共同维护一份完整的账本)。本文的主要贡献如下:
(1)提出了一种基于改进社区发现的节点分组方法。
(2)采用局部恢复码技术,减少区块恢复时所需的外部数据,从而降低了网络开销。并提出了一种基于上述两项工作的区块链存储扩容方案。
(3)大量实验结果表明:与目前最佳方法相比,本文提出的存储扩容方案,在保持存储开销和容错能力的基础上,降低了区块链节点请求非本地区块的耗时。
1 相关工作
1.1 区块链存储扩容
区块链存储扩容方向已有大量研究成果,根据数据是否存储在区块链上可分为两大类:链下存储方案和链上存储方案。第一类方案将区块数据存储在链下存储系统,区块链上仅存储索引信息、验证信息及其他非数据信息。第二类方案只需要每个节点根据一定的规则存储一部分账本(多个节点共同维护一份账本)。
1.1.1 链下方案
典型的链下存储方案主要包括GEM2-Tree[1]和vChain[2]。GEM2-Tree将账本存储在云服务器中,基于MB-Tree和SMB-Tree验证查询结果,并支持范围查询。vChain利用块内索引和块间索引进一步提高了验证计算的效率,并支持布尔范围查询。
这类方法不但能降低区块链的存储开销,一般还能支持较复杂的查询操作。但存在3个问题:(1)提高了系统中心化程度,降低了安全性;(2)账本数据存储于第三方服务器,存在隐私泄漏的隐患;(3)第三方服务器增大了经济成本[12]。因此本文并未采用链下方案。
1.1.2 链上方案
链上存储方案的基本思想是:若干个节点共同维护一份完整的区块链账本,每个节点只存储部分账本数据[13]。典型代表方案包括CUB[3]、PocketChain[6]和BFTstore[8]等。链上方案根据使用技术的不同,又可分为基于分片的链上方案和基于编码的链上方案两类。
基于分片的链上方案:数据库领域常采用分片技术将数据库分割成多个划分,分别存储到不同的服务器中。基于分片的链上存储方案使用了类似的原理。例如CUB方案[3]根据每个节点的存储容量分配一部分账本数据,保证账本在一个“共识单元”内被完整存储,并将经常访问的区块优先存储到对应节点的存储空间中。PocketChain[6]在公有链中运用分片和无状态客户端,降低节点存储需求的同时,有效地提升了系统的吞吐量。
虽然该类方法都能显著降低存储开销,但数据恢复能力较弱。若存储着某一区块的所有节点恰好都发生了故障,将导致数据永久丢失,降低了区块链的安全性[14]。而基于编码的链上方案拥有更好的容错能力,可以有效降低节点故障导致数据丢失的可能性。
基于编码的链上方案:针对分片存储的不足,有学者提出基于编码存储的方法,典型的编码如纠删码。纠删码是分布式系统常用的数据容错技术,与传统的多副本容错技术相比,具备更低的存储开销和更好的数据恢复能力。因此本文采用了基于编码的链上方案。
目前一些链上存储方案使用了(n,m)-RS(简称RS)纠删码[9]。Doriane等人[7]基于RS纠删码设计了一种LS(low storage)节点。LS节点将区块切分为片段后进行线性组合生成编码片段并存储。只需从其他节点获取一定量的编码片段,即可解码恢复出原始区块。Qi等人[8]提出了一种新的称为BFT-store的区块链存储引擎,通过结合RS纠删码和BFT共识来提高存储的可扩展性。上述采用RS码的链上存储方案能有效地提升系统整体存储性能,并拥有良好的数据恢复能力,但存在数据恢复网络开销较大的问题。使用RS码的系统必须从各节点获取至少n个块才能恢复出原始数据,导致网络开销较大[11]。(k,p,q)-LRC(简称LRC)码在单点故障时,仅需读取同集合的数据块和局部编码块即可实现恢复,比RS码所需的数据更少,网络开销也更小[11]。因此本文采用LRC码代替RS码。
此外,上述方案在分配数据时采用简单的随机策略,可能导致获取外部数据用时过长。因为节点向外部请求数据的效率会受节点间连接速度的影响。如果请求节点与存储数据的目标节点之间的连接速度更快,那么获取数据的耗时将较短。反之,用时较长。随机分组并不能保证连接速度较快的节点分到一组。因此本文提出了一种基于社区发现的方法将连接速度较快的节点分到一组,缩短了跨节点请求区块的响应时间。
1.2 社区发现
2002年,Newman等人提出社区概念,以反映复杂网络中数据的特征:社区内节点连接紧密,与外部节点连接稀疏。社区发现就是寻找网络中的固有社区划分。目前,相关研究非常多,根据网络是否加权,可分为在无权网络中根据节点属性来发现社区和在加权网络上根据边权重来发现社区两类。因为区块链网络是加权的,所以与本文相关的是后一类,该类典型算法包括WGN[15]、Strength[16]和Lu等人[10]提出基于传导性的社区发现算法等。与其他算法相比,Lu的算法能够发现稳定的非重叠社区,且性能更好,但其只用节点到社区的所有连接边权重之和来反映节点与社区的联系,而没有考虑最大权重边的影响。若直接应用在区块链中,无法获得内部平均连接速度较快的分组。因此本文对基于传导性的社区发现算法[10]进行改进和扩展,应用到区块链中,实现区块链节点的分组。
2 存储扩容方案
本章提出了一种基于社区发现和局部恢复码的区块链存储扩容方案。
2.1 方案目标
为解决区块链系统存储开销过高的问题,并弥补现有方案的不足,本文提出的方案需要实现下列目标:
(1)低冗余。单一节点无需在本地存储完整的账本,能通过网络获取账本中的任意区块。
(2)可恢复。在某些节点故障的情况下,可通过剩余节点的数据进行故障数据恢复。
(3)低时延。向外部节点获取区块的耗时要尽量短。
2.2 方案概述
方案概述如图1所示。首先使用改进的基于传导性的社区发现算法,将区块链网络划分为内部平均连接速度较快的多个组,每个组分别维护一份账本的副本;然后在每个组内用LRC码对区块进行编码,组内各节点分别存储编码后的部分账本。存储完成后,节点要获取区块数据,首先查询该区块是否存储在本地;若本地没有,则优先向存储了该区块的同组节点请求;若直接请求失败,则需使用LRC码解码恢复该区块。
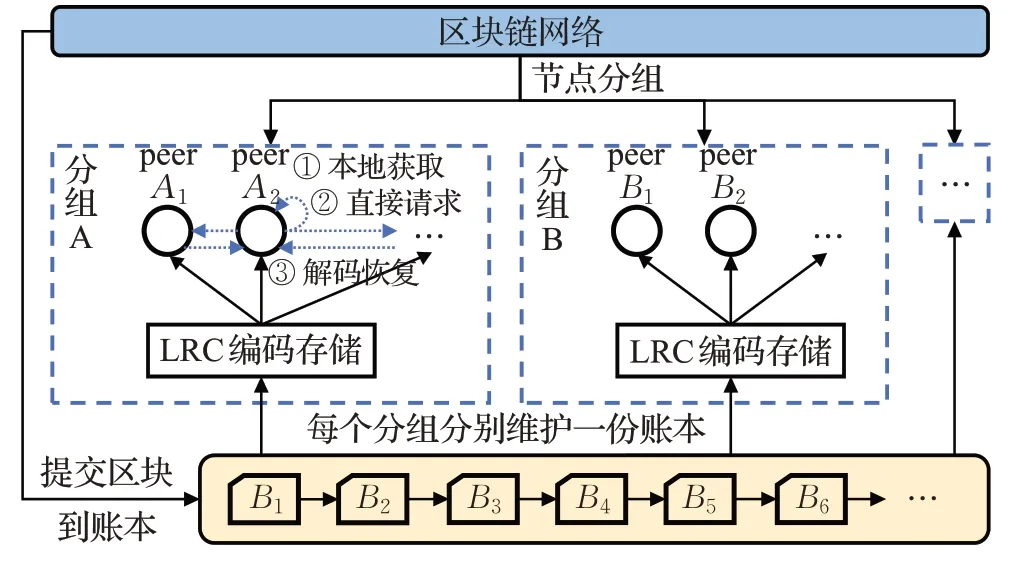
图1 扩容方案概述Fig.1 Overview of expansion scheme
各节点内部结构如图2所示。每个节点新增了4个功能模块:store模块、LRC模块、communication模块和分组模块。store模块负责存储和管理区块链数据,包括存储原始区块的账本存储域、存储编码块数据的编码块存储域和存储通过外部请求获得的区块的缓存域。LRC模块负责对区块数据进行编码和解码。communication模块负责跨节点请求数据和响应外部请求。分组模块负责对区块链网络进行节点分组。虽然每个节点都拥有分组模块,但系统只选择一个节点来调用该模块进行分组。

图2 节点内部结构示意图Fig.2 Diagram of node internal structure
下文分别介绍:基于社区发现的节点分组算法、基于局部恢复码的区块存储方案和请求区块的流程。
2.3 基于社区发现的节点分组算法
本节介绍改进的社区发现算法,以及将其扩展到区块链,实现区块链节点分组的具体过程。
现有的一些社区发现算法基于传导性[10]来发现加权网络中的社区,传导性越低,社区内部的联系越紧密。传导性的计算公式如公式(1)所示:
其中,cut(α,Gα)表示分组α所有切割边(与分组相连但不属于分组的边)的权重之和,wα表示分组α的切割边和其内部连接边的权重之和。
直接使用基于传导性的社区发现算法不能满足区块链节点分组的需求。例如图3中,若使用现有的算法,为使传导性下降,节点f将加入分组α,但显然节点f与分组β的连接速度更快。这是由于传导性用所有连接边权重之和来反映节点与分组的联系,而区块链所需的节点分组还应考虑最大权重的影响。为得到内部平均连接速度更快的分组,本文对基于传导性的社区发现算法做出如下改进:
(1)为了使最终的分组具有最小的传导性,将网络中所有相邻的两个节点分别组成临时分组,并选择其中传导性最小的分组作为初始种子,然后选取符合条件的节点来逐步扩展分组。
(2)将能否更大程度地降低分组的传导性和该节点到分组的准入系数是否小于1,作为是否允许节点加入分组的条件。准入系数的计算公式如公式(2)所示:
其中,WnTα表示节点n到分组α的所有连接边的权重,WnDTα表示节点n到分组α以外的所有连接边的权重。图3展示了分组的扩展过程,对于由节点g、h、i构成的分组β,其邻接节点f加入分组β得到的临时分组β″的传导性,比节点j加入β得到的临时分组β′的传导性更小,且f到β″的准入系数小于1,所以节点f加入分组构成新的β。

图3 分组扩展过程Fig.3 Process of expanding group
然后将改进的社区发现算法扩展应用到区块链中。对于给定网络,系统在启动后随机选择一个节点作为leader执行分组操作。leader节点首先收集各节点的连接情况构成网络图,并将它们之间的连接速度作为节点连接边的权重。然后使用改进的基于传导性的节点分组算法,划分网络得到节点分组。节点分组算法的伪代码如算法1所示。
算法1节点分组算法
1.leader ask other nodes for connectivity and transfer rate to makeNetGraph
2.whileNetGraphis not null
3.2-group={G′,G″,G‴,…}=findAll2-group(NetGraph)
4.Gi=MinConductance(2-group)
5.whileAdjacentGiis not null
6.n=findMaxReduceCon(Gi,AdjacentGi)
7.Gi′=Gi+n
8.if(Φ(Gi′)<Φ(Gi))&&∂(Gi′,n)<1
9.Gi=Gi′
10.updateAdjacentGi
11.else
12.deletenfromAdjacentGi
13.deleteGifromNetGraph
14.leader sentG1,G2,…to corresponding node
算法第1行leader节点获取区块链网络中各节点之间的连接,并将它们的数据传输速度作为连接边的权重,构造网络图NetGraph;第3、4行调用findAll2-group()函数获得NetGraph中所有由2个相邻节点构成的分组,然后调用MinConductance()函数找出其中传导性最小的,作为初始种子分组Gi;第6、7行遍历Gi的邻接节点,调用findMaxReduceCon()函数找到其中能使分组的传导性下降最多的节点n加入Gi,形成一个临时的分组Gi′;第8~12行比较分组Gi′和原分组Gi的传导性:如果Φ(Gi′)更小且n到Gi′的准入系数小于1,则分组Gi′取代原分组成为新的Gi;第14行leader节点将分组结果发送给各个节点。
当算法执行结束,获得的每个分组具有最小的传导性,即分组的任意邻接节点若加入分组,会降低该分组内节点的平均连接速度。
2.4 基于局部恢复码的区块存储
为了提高区块链系统的整体存储能力,本文采用LRC码实现区块存储。其编码过程如下所示:区块链每个编码周期开始时,节点首先将本周期提交的新区块按常规方式存储到本地。当新区块的数量达到编码所需的数量,则用LRC码对新区块进行编码,得到编码块和数据块。然后各节点根据周期号和自身的节点号存储相应的块,并删除多余的块,结束这一周期。图4展示了一个编码存储过程的示例:对于含有7个节点的给定分组,使用(4,2,1)-LRC码编码区块数据,然后存储到不同节点。例如在周期2中,新生成了4个区块B5~B8,用LRC码编码得到两个局部编码块lc2-1(由B5和B6得到)、lc2-2(由B7和B8得到)和一个全局编码块gc2-1(由B5~B8得到)。然后节点a~g分别存储不同的块,周期2结束。具体算法伪代码如算法2所示。
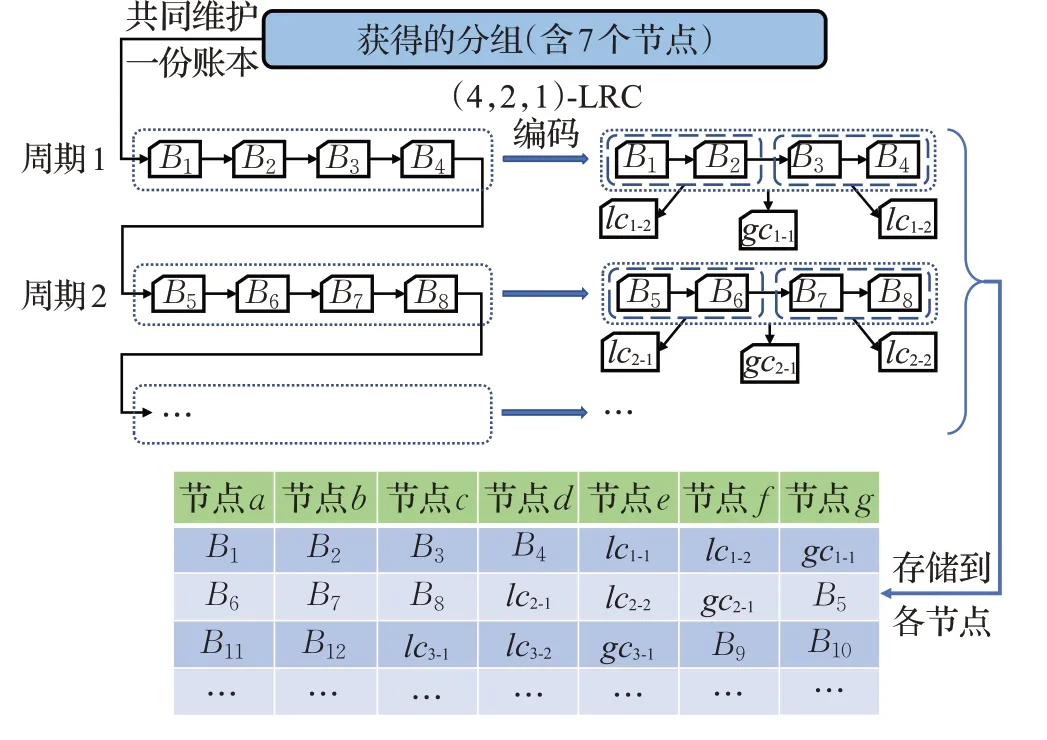
图4 编码存储示例Fig.4 Example of encoding storage
算法2区块存储算法
输入:当前节点号n,新区块号Bi,当前周期号e,(k,p,q)-LRC码
1.when get an ewblockBido
2.saveBiinto local ledger
3.ifBi==k×edo
4.usenandeto getSBNthrough calculation
5.ifSBNis block do
6.delete other block in{Bi-k,…,Bi}from ledger exceptSBN
7.else ifSBNis coding chunk do
8.{lci-1,…,lci-p,gci-1,…,gci-q}=use(k,p,q)-LRC to encode{Bi-k,…,Bi}
9.save SBN from{lci-1,…,lci-p;gci-1,…,gci-q}
10.delete block in{Bi-k,…,Bi}from ledger
11.e++
算法第2~4行将新区块存入本地账本,并判断这一周期存储的新区块数量是否满足编码数量,若满足则计算当前节点在这一周期应存储的块号SBN;第5、6行如果SBN对应的是普通区块,那么将这一周期存储的其他新区块从账本中删去,只保留SBN对应的区块;第7~10行如果SBN对应编码块,那么使用(k,p,q)-LRC码对这一周期存储的新区块进行编码,得到SBN对应的编码块并存储到本地,然后将本轮周期存储的新区块从本地账本中删除。
为了让每个节点的存储开销总体上相等,节点不固定存储原始区块或编码块。因为编码块的大小与编码时所使用的最大原始区块的大小相同,如果节点总是存储编码块,其所需的空间一定比总存储原始区块的节点多。此外,为避免节点编码压力过大和分发编码块时可能导致的网络阻塞,leader节点不负责编码。
2.5 区块请求
本节阐述扩容方案中节点如何请求获取区块。由于本地没有存储完整账本,因此节点有三种方式获取区块数据:从本地获取、直接请求其他节点获取和解码恢复该区块。节点请求某一区块时,需要依次尝试上述三种方式。请求区块的具体流程如图5所示。
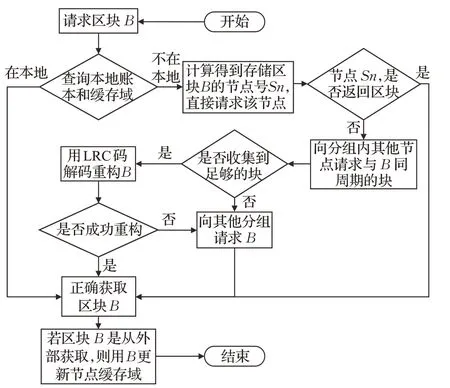
图5 区块请求流程图Fig.5 Flowchart of requesting blocks
流程图中的各步骤均省略了对区块的验证过程,在实际过程中节点会在获取区块后,用存储在本地的区块头来验证区块是否正确,从而过滤错误区块。
基于LRC码的区块恢复:当节点必须通过解码恢复区块时,其向外部请求同周期区块的策略会影响数据恢复的耗时和网络开销。本文采用的LRC码只需要局部块,就可以实现单点故障的恢复。例如图6中,节点a需要区块B2,但无法从本地或节点b获取该块,所以必须通过解码恢复B2。由于节点a自身存储了B1,所以其在恢复B2时,只需向节点e请求局部编码块lc1-1,再使用LRC码解码即可恢复出B2。如果示例中使用的是(4,3)-RS码,则节点a必须从其他节点获取至少3个块才能恢复B2,网络开销更高。具体算法伪代码如算法3所示。
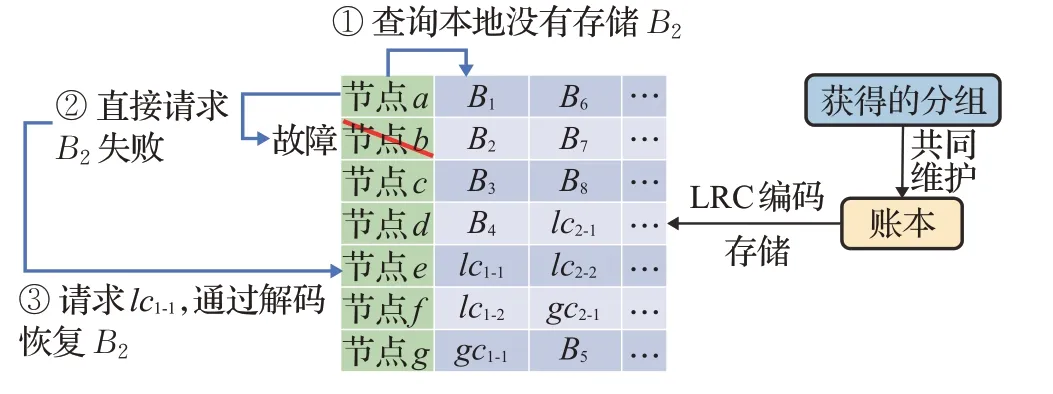
图6 解码恢复示例Fig.6 Example of decoding for recovery
算法3区块恢复算法
输入:当前节点号n,请求区块号B,(k,p,q)-LRC码
1.getepochofBthrough calculation
2.{local data chunks}and{local coding chunks}=ask other nodes for local chunks in the sameepochwithB
3.if number of local chunks==(k/p)+1
4.B=use(k,p,q)-LRC to decode{local data chunks}and{local coding chunks}
5.else
6.ask other nodes for{k chunks}in sameepochwithB
7.B=use(k,p,q)-LRC to decode{k chunks}
8.useBto update cache
算法第1、2行计算出区块B所在的周期号epoch,并向同组的节点请求区块B对应的局部编码块和数据块;第3~7行如果获取到足够的局部块,那么使用(k,p,q)-LRC码解码局部块得到区块B,否则需要向其他节点请求k个与B同周期的块来解码出区块B;第8行用区块B更新缓存。
缓存替换策略:一些链上存储方案采用了缓存来存储频繁使用的区块。由于节点存储容量有限,缓存需要经常更新。现有方案常用“最近最少使用”策略作为缓存替换策略。本文在每个节点上建立了缓存域,来降低请求区块的时间,并综合考虑区块的使用频繁度、获取耗时制定了策略:每当节点向外部请求获取区块后,若节点缓存域未满,则将直接其加入;若缓存域已满,则需要找到缓存域中所有比新区块价值小的区块,然后用新区块替换其中价值最小的块。缓存价值的计算公式如公式(3)所示:
其中,Ti表示获取区块i所需的时间;Fi表示节点对区块i访问的频繁程度值,即访问次数;D的初始值为0,每当发生缓存替换后,更新D的值为被替换区块的Vi值,每当该区块被访问后,D重置为0。
3 性能分析
本章在模拟数据集上进行了大量实验,对比了本文提出的方案和baseline方法的存储开销、区块请求时延、区块恢复的网络开销和容错能力,验证了其保持了与最优方案近似的存储开销和相同的容错能力,还有效降低了跨节点请求区块的时间。
3.1 实验环境和数据集
本文在开源区块链平台HyperledgerFabricv1.1上实现了提出的方案。所有实验都在一台配备2.10 GHz 8核CPU,64 GB RAM和2 TB磁盘空间的机器上完成。利用VMware虚拟机建立24个节点,每个节点分配2 GB内存和20 GB硬盘,并安装ubuntu18.04系统。
实验在模拟网络环境下进行,首先使用文献[17]中提出的著名基准测试框架生成加权网络图,然后根据网络图中的各连接边的权重来设置区块链网络中各节点间的传输速度,从而模拟实际网络情况。实验数据集为使用fabricSDK循环生成的模拟数据集,通过建立200个账户,让它们随机互相转账,产生100 000条交易,共2 000个区块。
baseline方法:(1)fabric的存储方案(简称方案1)。(2)结合分片[3-6]和多副本的存储方案(简称方案2)。首先根据节点数量划分完整账本,然后为每一个分片构造三个副本并随机存储于不同节点。(3)结合RS码[7-8]和分组的区块链存储方案(简称方案3)。将文献[7-8]采用的降低存储开销的RS码扩展后应用于fabric平台,并使用与本文提出方案一致的节点分组方法。
本文共提出了两种存储扩容方案:第一种采用原始的基于社区发现[10]的节点分组方法和LRC码的存储方案(简称方案4);第二种采用本文改进的基于社区发现的节点分组方法和LRC码的存储方案(简称方案5)。其中LRC码和RS码的编码块数量设为相同。
3.2 存储开销
本节主要评估区块链的存储开销,分别测试了方案5和三种对比方法存储每个区块的空间开销。没有与方案4进行比较,因为其与方案5都采用LRC码进行存储。实验时不设置故障节点,将数据集提交到区块链,当节点总数从6增加到24时,区块的平均存储开销如图7所示。图7可见:方案5每存储一个区块平均所需的存储空间并不随着节点数量的增加而明显增长,与方案2、3的结果类似。因为方案3和5都采用了纠删码来降低区块链存储开销,所以具有近似的变化趋势,验证了本文提出的存储扩容方案保持了与目前最佳方案3近似的存储开销。此外,因为系统中节点分组数量增加,且每个分组需要共同存储一份账本,所以方案3和5在节点数量为12时存储开销增大。
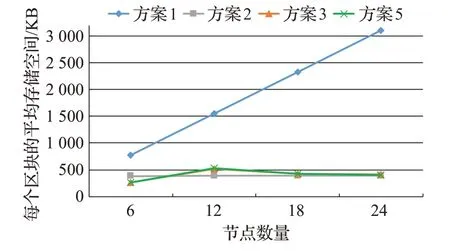
图7 区块的平均存储开销对比Fig.7 Comparison of average storage overhead perblock
3.3 区块请求时延
本节主要评估本文方案和方案2和3从发起区块请求到获取目标区块所需的时间。没有与方案1比较是因为fabric的每个节点都有完整账本,不需要向外部请求区块。
首先从区块链网络中随机选取1/6的节点作为实验节点,然后从剩余节点存储的数据中随机选取50个区块作为测试数据。接着让系统正常运行,然后在各个实验节点上请求测试数据并记录花费的时间。不同方案跨节点请求区块的平均时延如图8所示。

图8 跨节点请求区块时间对比Fig.8 Comparison of requesting blocks time across node
图8可见:方案3~5获取测试数据的耗时较短。因为对区块链网络进行了划分,得到了内部连接速度更快的节点分组,所以节点可以从组内获取区块。方案3和5比方案4的时延要更短,因为方案3和5使用了改进的节点分组方法,获得的分组连接速度更快。此外,方案2中各节点存储的区块是随机分配的,当前节点所需的区块可能存储在网络距离很远的节点上,所以平均响应时间较长。实验结果表明本文方案提出的基于社区发现的节点分组方法可有效减小跨节点请求区块的时延。
3.4 区块恢复的网络开销
本节主要评估本文采用的LRC码和现有最佳方案所使用的RS码在区块恢复时的网络开销。由于区块恢复时,向外部请求的数据越多,网络开销就越大,区块恢复时间也就越长。因此分别测试了方案3和方案5恢复缺失区块所需的平均时间。
首先让系统正常启动,接着随机关闭1/6的节点,来模拟故障的发生。然后从剩余节点中随机选取一个节点,在该节点上请求故障节点所存储的区块,并记录恢复区块所花费的时间。两方案恢复缺失区块的平均时间如图9所示。
图9可见:本文方案的平均恢复时间更短,这是因为LRC码最少只需要相应的局部编码块和数据块就可以恢复出所请求的区块。实验结果表明,本文方案采用的LRC码能降低数据恢复时的网络开销。
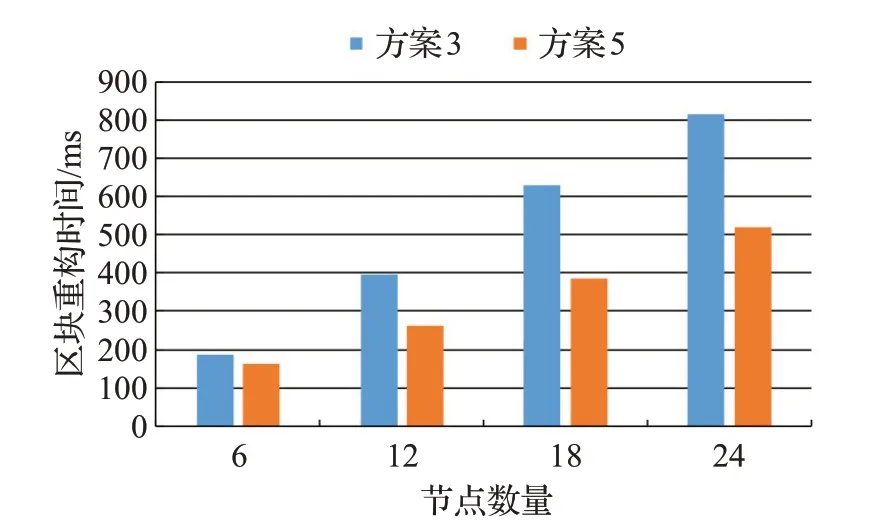
图9 区块恢复时间对比Fig.9 Comparison of blocks reconstructing time
3.5 容错能力
在实际环境中,区块链部分节点故障的情况是很常见的。因此本节分别计算了不同方案在部分节点故障时的数据完整性。当网络中1/5、1/4、1/3的节点故障时,不同方案能恢复出完整数据的可能性如表1所示。表中没有比较方案1,因为节点故障不会影响fabric的数据完整性;也没有比较方案4,因为其与方案5都基于LRC码实现,它们具有相同的容错能力。
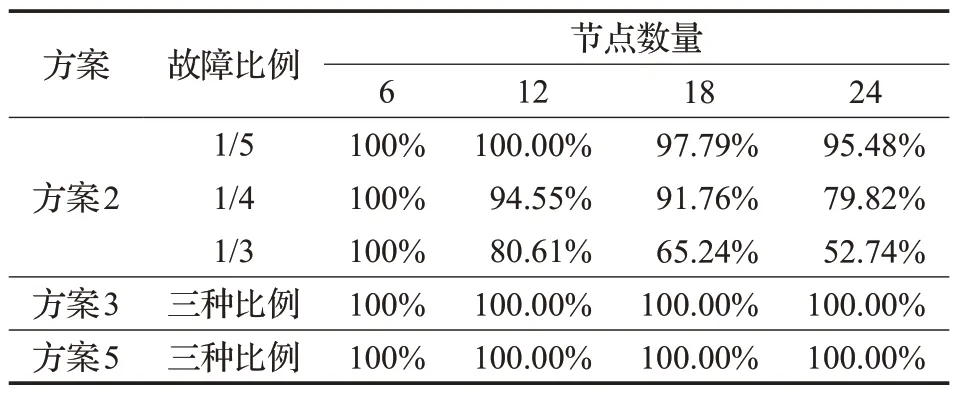
表1 容错能力对比Table 1 Comparison of fault tolerance
从表中可看出,方案3和方案5在设置的实验条件下均能够恢复出所有的数据,而方案2在故障节点较多时,很容易发生数据丢失。因为对于三副本技术,若存储了某一区块所有副本的节点恰好都发生了故障,这些数据将不再可达。而纠删码可以在一定限度内利用剩余的数据恢复出原始的数据。因此,使用本文方案的区块链系统具有较好的故障容错能力。
4 总结
本文首先对现有基于传导性的社区发现算法进行改进,提出一种基于社区发现的区块链节点分组方法,将连接速度较快的节点分为一组,降低了跨节点区块请求的响应时间。然后在上述工作基础上,结合LRC码技术,提出了一种新的区块链存储扩容方案,使得每个节点只存储部分编码后的账本,保证系统在降低存储开销和网络开销的同时拥有较好的数据恢复能力。大量实验结果表明,本文提出的扩容方案与目前最优方法相比,不仅保持了近似的存储开销和相同的容错能力,还能提高跨节点区块请求效率。未来可改进基于LRC码的存储策略,提出开销更低、容错能力更好的编码方案,进一步减少节点的存储空间。
猜你喜欢
中小企业管理与科技·下旬刊(2020年2期)2020-06-08 09:48:24
当代党员(2019年19期)2019-11-13 01:43:29
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:48
学生天地·小学中高年级(2018年10期)2018-12-13 02:45:34
小学生导刊(2018年31期)2018-12-06 08:36:42
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:42
小学科学(学生版)(2018年1期)2018-01-31 01:51:45
小学生导刊(低年级)(2017年1期)2017-06-12 12:07:42
纺织检测与标准(2016年2期)2016-06-18 03:41:16
中国市场(2015年16期)2015-05-30 20:31:44
