
汉语V+V序列关系识别研究
2023-03-13 10:05:38李胜男曲维光魏庭新周俊生顾彦慧
计算机工程与应用 2023年5期
李胜男,曲维光,,魏庭新,周俊生,顾彦慧,李 斌
1.南京师范大学 计算机与电子信息学院/人工智能学院,南京 210023
2.南京师范大学 文学院,南京 210097
3.南京师范大学 国际文化教育学院,南京 210097
动词是理解句子的关键,在现代汉语里,句子中常常出现由多个动词形成的动词短语,多个动词一起可以表达丰富的语义内容,是现代汉语中的常见结构。本文将现代汉语句中出现两个及两个以上动词的结构概括为“V+V”结构。由于名词和动词可以承担多种语义角色,因此该结构能够形成多种完全不同的句法结构,如兼语结构、连动结构,以及兼语和连动组成的嵌套结构。这些结构在形式上完全相同,但各部分之间的语义关系却完全不同,如短语“回家吃饭”中“吃饭”和“回家”是并列关系,其施事主语为同一人,而在“请朋友吃饭”中,“请”和“吃饭”的施事主语则并非一个人,“朋友”是“请”的宾语,同时又是“吃饭”的主语。由此可见,动词V在不同的位置,发挥不同的作用,表达不同的含义,仅凭词性难以识别句法结构的不同,给句法解析造成很大的困扰,因此识别“V+V”结构的句法类型和语义角色,对于句法解析和语义解析都有着非常重要的作用。
抽象语义表示(abstract meaning representation,AMR)作为一种新的语义表示方法,使用图结构来表示语义,通过补充句子中的隐含或省略成分,更全面地描述句子的语义[1]。AMR在对语义标注时需要对兼语缺省的论元进行补充,而在连动句中存在着内部概念节点论元共享的现象,即在单句中多个谓词共享同一论元角色,AMR会将缺省的论元进行补全,得到完整语义表示。如图1所示,句子中的词被抽象为概念节点,比如“老师”“轮流”等都是概念节点,概念节点前的符号“arg0”“manner”等表示该概念节点与上层概念之间的关系,比如“老师”是“让”的施事“arg0”,“同学们”是“让”的受事“arg1”,“轮流”是“上讲台”的方式,所以“轮流”与“上讲台”之间的关系为“manner”。该句中的“同学们”既是“让”的受事宾语,又是“上讲台”的施事主语。但为了表达简洁方便,汉语会将后一个主谓结构中的主语“同学们”省略,AMR表示句子语义时会将省略的arg0“同学们”补全。对于其他动词“轮流”“讲”的缺省arg0,AMR同样进行补全,指示其概念节点同样为“同学们”。通过使用概念节点的标号,可以有效表达共享论元、补全省缺语义。

图1 AMR文本表示Fig.1 AMR text representation
根据文献[2]对小学1~6年级语文教材AMR语料库的统计,超过6%的句子含有兼语结构,超过10%的句子含有连动结构。正确识别V+V结构,识别出其中的兼语句、连动句及两者嵌套结构的内部成分,根据识别出的内部成分对缺省论元进行补全,能够帮助AMR中兼语句式和连动句式的标注与语料构建及解析,为解析V+V结构的其他序列关系提供思路。
本文的主要贡献如下:(1)将兼语连动这样的V+V结构全部纳入统一框架中,设计并标注了V+V语料库,包含5 381个兼语句子、7 987个连动句子以及1 212个兼语连动嵌套句子;(2)提出基于多头注意力和BiLSTMCRF的模型框架来识别V+V序列关系,并在测试集上取得较高的F1值;(3)相比于以往只单项识别兼语或连动句,本文将兼语和连动这样的V+V结构纳入统一框架进行学习,不仅可以同时识别兼语、连动结构,还可以解决兼语连动嵌套结构的识别问题。实验结果表明训练V+V语料的识别效果优于单独学习兼语或连动结构,证明了V+V序列关系识别方法的有效性。
1 相关工作
1.1 相关语料库构建现状
虽然“V+V”是汉语中非常常见的结构,但目前并没有专门的语料库。一些大型综合性语料库中会有句法类型的标注,其中包括了兼语、连动等的标注。文献[3]利用句法树标注体系构建了清华汉语树库,使用“JY”标记兼语结构,根据Chen对清华树库中兼语结构分布的统计,在3 093个出现兼语结构的句子中共有3 527项兼语结构,其中55项为兼语嵌套结构,占总频次1.6%[4]。清华树库还使用“LW”标注连谓结构,连谓结构中可以做谓语的不仅有动词和动词性结构,还有形容词和形容词结构[5],因此该语料库中的连动结构包含在连谓结构中,没有单独区分。
文献[6]构建的中文AMR语料库对汉语的特殊结构如兼语、连动的表示给予具体规定。但上述语料并不针对兼语和连动构建,且各语料对于兼语连动的定义、标注范围不统一且规模较小,无法直接用于兼语连动结构的识别工作。为了解决语料匮乏的问题,文献[7]针对兼语结构总结了一套兼语语料库标注规范,选取了来自文学、新闻、微博等不同领域的语料构建了一定数量面向中文AMR标注体系的兼语语料库,标注了兼语的中心词以及V1、V2,共包含4 760个兼语句、5 248个兼语结构,是目前最为完整系统的针对兼语结构的语料库。文献[8]针对连动句的研究,在人教版小学语文教材AMR语料以及清华汉语树库中,通过人工标注方法构建了包含7 200个连动句的语料库,为后续对连动句识别的研究提供了支持。
上述的语料库并未考虑到兼语连动嵌套的情况,因此没有包含兼语连动嵌套的标注,无法对嵌套结构的识别进行深入研究。关于嵌套结构的具体类型介绍将在后面2.1节标注规范中详细讲解。
1.2 兼语连动识别研究现状
目前关于兼语的研究主要集中在识别兼语结构的边界、兼语前的动词V1、兼语后的动词V2、兼语中心词等。连动句的研究集中在连动句识别。研究方法主要分为三类,分别是基于规则的方法、基于机器学习的方法和基于神经网络的方法。
文献[9]采用统计与规则结合的方法来识别兼语结构,构建了一个较为详尽的兼语动词词表,并且使用规则匹配的方法筛选兼语的候选特征,使用支持度计算的方法识别兼语结构中的兼语和V2的候选项。在《人民日报》语料上的识别结果达到了80%左右的正确率,但该方法无法识别未登录的兼语动词,而且该方法只适用于符合简单结构规则的兼语结构,无法处理复杂的嵌套结构,难以达到应用层面。文献[10]提出了一种基于规则和统计相结合的连动句识别方法,设计构建基于连动句形式特征和语义角色的基础规则库,然后使用互信息计算谓语动词与主语候选项的搭配强度,来识别连动句,实验结果F1值为70.83%。但是由于连动结构的复杂性,上述的基于规则的方法并不能涵盖所有情况,无法识别包含两个以上动词的连动句。
文献[4]使用条件随机场模型,对兼语结构边界进行自动识别,F1值最高可达85.71%,但该工作依赖分词以及词性标注的效果,对于大量未加工的语料识别效果较差。文献[8]提出了一种基于神经网络的连动句识别方法。使用Bert编码,利用多层CNN与BiLSTM模型联合提取特征进行分类,在人工标注的语料上达到87.41%的F1值,证明了神经网络的方法对连动句识别的有效性。文献[7]设计了LA-BiLSTM-CRF模型,能够识别句子中的兼语结构边界,实验结果F1值为86.06%,证明BiLSTM模型更适合兼语结构边界识别任务。但该模型通常只捕捉兼语结构中的一个V2,对于包含连动以及宾语从句的兼语结构的后边界识别效果较差。
上述的相关工作都只针对单一的兼语结构或连动句进行识别,然而实际语料中既有兼语,又有连动,还有一个句子中同时出现兼语和连动的嵌套情况,现有研究并未对多种情况同时研究,也没有关注兼语连动嵌套的识别研究。
1.3 实体嵌套与多头注意力机制
在自然语言中嵌套实体普遍存在,文献[11]提出了一种新的神经框架MGNER,适用于处理嵌套实体和非重叠实体。文献[12]提出了解决嵌套命名实体识别的神经网络体系结构,使用多个标签对嵌套实体进行标记,这种方法简单易行,但也存在较为明显的问题,例如对于多层嵌套的情况,指数级增加了标签,导致分布过于稀疏,因此模型难以学习。文献[13]提出了将命名实体识别任务作为机器阅读理解任务来做的思路,即查询句子中是否存在指定问句的答案。上述的工作为解决嵌套识别问题提出了多种方法。
文献[14]提出了一种多头注意力机制的神经网络框架,可以使用多个单独的注意功能来捕捉不同的上下文,允许模型共同注意来自不同位置不同表征子空间的信息,更好地学习长句子的上下文依赖信息,目前被广泛应用到各个研究领域,例如文献[15]提出一种新颖的多模态多头注意力模型来预测关键短语,实验结果表明多头注意力能够从各个方面关注信息,并在不同场景中促进分类或生成;文献[16]提出基于多头注意力机制Tree-LSTM模型解决了句子语义相似度计算;文献[17]利用多头注意力机制生成多样性翻译。
受文献[12]启发,本文采用多个标签对嵌套结构进行标注,并利用多头注意力机制来帮助V+V结构中的语义关系进行建模,得到每个字应关注的全局语义,解决识别过程中的局部依赖性、位置信息获取不准确等问题。
2 V+V语料库构建
目前的一些大型语料库虽然综合地标注了各类句法,但类别分类不统一,对于特殊结构的标注不够详细,没有进一步进行更深层次的句法分析和词汇语义标注。本文利用语言规则在人教版小学语文教材AMR语料、清华树库、微博AMR语料以及哈工大语料库中初步筛选出具有V+V结构的句子,然后使用BIOES标注体系对这些句子进行内部成分的标注。V+V结构中最多的是连动结构,其次是兼语结构,此外,还包含少数的兼语和连动的嵌套结构。
2.1 标注规范
本文构建的V+V语料库主要对兼语结构中的V1、V2及兼语的中心词JY、连动结构中的连动词的施事主语n、连动词v,以及两种结构的嵌套形式进行标注。通过对语料的分析,本文制定以下标注规范:
(1)连动句标注方法
连动结构的完整语法格式可以表示为:“V1+NP1+V2+NP2”。
①在没有语音停顿的单句中,当V1和V2之间在语义上具有方式、顺承、目的、因果等关系,且连动词的施事主语为同一对象时,本文将之标注为连动结构,结构中的V1和V2是本文所要标注的连动词。例如,图2的例1“他们没有砍树造房子”中有两个动词“砍”和“造”,两个动词之间存在目的关系,即“造”表示“砍”的目的,所以这两个动词是连动词;“他们”是“砍”和“造”的动作发出者,所以“他们”是施事主语。在具体标注中,本文使用符号n对连动词施事主语进行标注,使用符号v对连动词进行标注。

图2 标注示例Fig.2 Annotation examples
②在施事主语的标注中,若主语部分为“量词+名词”“形容词+名词”“名词+名词”等,则只标注主语的中心词。例如,“两只老虎”“凶猛的老虎”“东北老虎”都只标注“老虎”。如果存在并列的施事主语,则标注每一个主语的中心词。若不存在主语则不做特殊标注。
③在连动词的标注中,只标注每个连动词的中心词。例如“砍树”和“造房子”只标注“砍”和“造”;“跳一跳”和“摇一摇”只标注第一个字“跳”和“摇”作为连动词。
(2)兼语句标注方法
兼语结构完整的语法格式可以表示为:“NP1+V1+NP2+V2”。
①在一个句子中,当V1是具有“使令”含义的动词,V1和V2的关系是递进式的,V1和V2共享NP2,NP2既是V1的受事宾语也是V2的施事主语时,本文将之标注为兼语结构。其中V1、NP2、V2是本文所要标注的兼语前动词、兼语、兼语后动词。NP1允许省略,NP2不能省略。本文使用符号V1对兼语前的动词进行标注,使用符号JY对兼语NP2进行标注,使用符号V2对兼语后的动词进行标注。
②在V1的标注中,V1需要满足兼语结构的语法格式,除此之外,V1的动词含义应具有“使令”“致使”的含义,例如“让”“使”“令”“请”“要求”等词。
③在兼语的标注中,兼语需要满足既是V1的受事宾语,又是V2的施事主语,例如图2例2句子“老师让大家跑起来”中的“大家”既充当前面“让”的宾语,又是后面“跑”的主语,因此“大家”是兼语,标注为JY。如果兼语为名词短语则只标注中心词,例如“东北老虎”只标注中心词“老虎”。如果兼语是由多个并列名词短语或名词组成,则标注每一个名词短语或名词的中心词。
④在V2的标注中,由于V2可以出现在各类复杂的其他结构中,例如动宾短语、状中短语、动补短语、连动短语等,因此对于V2的标注采取“就近原则”。如果兼语后出现情态动词加动词的结构,则将V2标注为离兼语较近的情态动词;如果兼语后出现补语的情况,则将V2标注为兼语后的第一个动词。例如“跑起来”中“起来”是“跑”的补语,所以V2只标注“跑”。
若兼语结构中出现与连动结构嵌套的形式,则按照本文制定的嵌套标注方法进行标注。
(3)嵌套句标注方法
对于句子中既含有兼语结构又含有连动结构但不存在嵌套现象的情况,标注如图2中例3所示。例如句子“如果大家都去看就会让款式外流”中连动结构“大家都去看”和兼语结构“让款式外流”虽然处在同一个小句中,但两个结构彼此之间相互独立,不存在干扰,因此不做特殊处理。对于存在嵌套情况的句子,本文做出如下标注规范:
①前兼语后连动情况,即兼语V2为连动结构。如图2中例4“请您坐在这儿看报纸”所示,“坐”和“看”既属于连动词又是兼语的V2部分,这种情况的嵌套是连动结构包含在兼语结构中,因此将连动结构全部标注为嵌套形式,即在原有的兼语标注后面使用符号“|”连接连动结构的相关标签。
②前连动后兼语情况,即连动句第二个动词短语为兼语结构。如图2中例5“把新娘领来让我看看”所示,这种情况是兼语与连动产生交集,动词“让”既是前面连动结构中的最后一个连动词v,又是后面兼语结构中的兼语动词V1,而其他成分都只有一种“身份”,因此只需将该动词标注为嵌套形式,使用符号“|”将它的两种“身份”进行拼接。
③前连动中兼语后连动情况,即连动句第二个动词为兼语结构、同时兼语结构的V2又由连动结构组成。如图2例6“又掏出20元钱让他打的回家”所示,“掏出20元钱让”按照前连动后兼语情况标注,“他打的回家”按照前兼语后连动情况标注,这里不再赘述。
④前兼语后兼语情况,即前一个兼语结构中的V2同时又是后一个兼语结构的V1。如图2中例7“她央求父母约请同学到山上野营”所示,该句可以拆分为两个兼语结构,分别是“央求父母约请”和“约请同学到山上野营”。第一个兼语“父母”的V2“约请”充当第二个兼语“同学”的V1。对于该情况,本文将出现在第一个兼语结构中的V2(约请)忽略,将其标注为第二个兼语结构的V1。
⑤前兼语中连动后兼语情况,如图2例8“列宁常常派人去请他来谈天”,该句可以拆分为两个兼语结构,分别是“派人去”和“请他来谈天”,其中“去”和“请”分别充当前一个兼语的V2和后一个兼语的V1,同时,“去”和“请”还是一组连动词,施事主语是“人”。对于这种情况,本文使用符号“|”将前一个连动词和前一个兼语的V2进行拼接,将后一个连动词与后一个兼语的V1进行拼接。
2.2 语料库统计
根据以上规范,选取了小学AMR语料、微博AMR语料、哈工大语料、清华树库语料对兼语句和连动句进行标注。总共标注了11 647个句子作为本文实验的V+V原始数据集,其中各类句子的数量统计情况如表1所示。表中只含有兼语或只含有连动结构的句子是指句子中只出现同一类别的结构,也称其为只含有单一结构句子。含两种结构但不嵌套是指该句子同时出现了兼语结构和连动结构,但是这两个结构分别位于句子的不同部分,因此没有产生嵌套关系。表2展示了V+V语料中标注的标签数量统计情况。

表1 语料句子类别统计Table 1 Statistics of sentence categories in Corpus
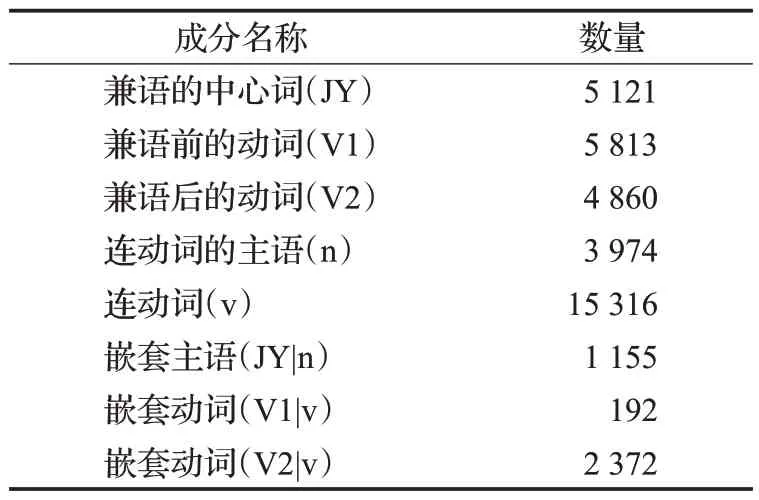
表2 语料标签统计Table 2 Corpus label statistics
3 模型设计
本文将中文V+V序列关系识别建模成一个序列标注问题,采用基于BiLSTM-CRF和多头注意力机制相结合的方法进行V+V结构识别。模型架构图如图3所示。
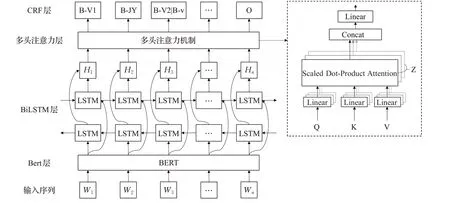
图3 模型架构图Fig.3 Model architecture
本文引入了一种基于多层双向Transformer结构的语言模型Bert,它能够根据上下文的语义动态调整词向量来缓解多义词问题,同时增强了对文本特征的抽取能力。为了防止训练过程出现过拟合,在最终的词向量进入BiLSTM之前,经过一个丢弃概率为0.5的dropout层。
LSTM-CRF作为序列标注任务的主流框架,虽然取得了很好的性能并被广泛使用,但经过LSTM编码获得的是基于全局的特征,忽略了对于局部特征的提取,存在局部依赖性以及受限于序列化特征学习的缺点。目前也有很多方法基于BiLSTM-CRF框架与注意力机制的简单结合的模型,仍然存在局部依赖性、位置信息获取不准确等缺陷。为了同步建模句子中每个词的局部上下文语义与全局语义,有效弥补BiLSTM对局部特征获取不足的问题,本文使用基于多头注意力机制的BiLSTM-CRF序列标注模型。
具体来说,给定句子S={W1,W2,…,Wn},其中Wi表示句中的一个字,该句子首先经过Bert进行编码,然后传入LSTM层计算第t时刻对应的LSTM的状态值。由于单向的LSTM无法同时获取上下文两个方向的信息,为了更好地获得前项和后项的上下文信息,本文使用双向LSTM模型,将经过前向LSTM得到的隐藏变量和经过后向LSTM得到的隐藏变量进行拼接,得到整体的隐藏变量作为输出Ht,计算公式为:
然后根据文献[14]的多头注意力机制建模句子中任意两个字之间的语义关系,计算来自上一层的第i个单词的隐状态Hi的单头注意力权重,得到每个字应关注的全局语义。具体计算过程如下:
其中,WiQ、Wik和WiV分别是需要训练的权重参数,表示平滑项,d为Hi的维度数。然后将单头注意力单元进行拼接,再进行1次线性变换,将得到的值作为多头注意力的结果,计算公式为:
其中,Wout为权重参数,Z为拼接数量,即头的个数,这里设置为8。对于每一次计算,单头注意力输出之间的参数不进行共享。考虑到序列标注任务中标签之间一般存在依赖关系,尤其是对于兼语和连动的识别问题,兼语动词V1一定出现在兼语中心词JY之前,V2一定出现在兼语中心词JY之后,连动词之间一定是连续出现的,这种依赖关系无法直接使用分类器进行建模。由于条件随机场模型能够对标签之间的关系进行建模,得到全局最优的标注序列,而不是单独地预测每一个标签,因此在模型最后一层利用CRF进行标签序列的预测。
4 实验
4.1 数据集以及实验设置
本文的实验语料是按照8∶1∶1的比例将数据集进行切分,得到训练集、开发集和测试集。实验数据统计如表3所示,其中V+V原始数据集是由本文所标注的含有兼语、连动结构,以及嵌套结构的11 647个句子构成。兼语语料库是由文献[7]所构建的针对兼语结构边界识别的语料库。单一结构数据集是在V+V原始数据集的基础上,抽取只含有单一结构的句子构成,其中有3 655个兼语句子和6 266个连动句子,不包括含有不同类别结构的句子和含有嵌套结构的句子。
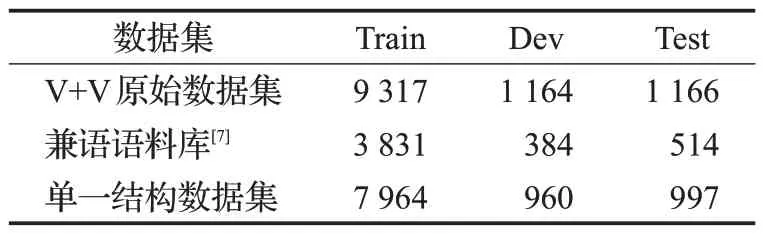
表3 实验数据统计Table 3 Experimental data statistics
本文实验使用基于Python3.8编程语言开发,采用tensorflow-gpu1.14.0进行模型的实现。在训练过程中,模型均使用Adam算法进行优化。主要超参数设置如表4所示。

表4 参数设置Table 4 Parameter setting
本文采用的评价指标分别为精确率(用P表示)、召回率(用R表示)以及F1值,保留在开发集上预测结果最佳的模型进行预测。
4.2 V+V序列识别对比实验
本节在V+V原始数据集上进行实验。为了评估本文提出的基于多头注意力的Bert-BiLSTM-CRF模型在V+V序列关系识别中的效果,分别与BiLSTM-CRF、BiLSTM-MultiHead Attention-CRF、Bert-BiLSTM-CRF
进行实验对比,实验结果如表5所示。本文模型在测试集中的标签识别结果如表6所示。
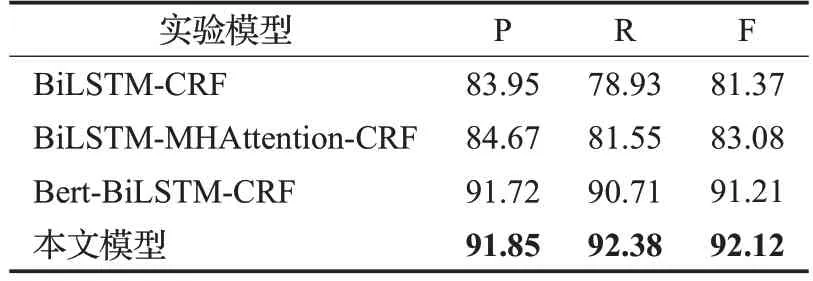
表5 V+V序列识别实验结果Table 5 V+V recognition experimental results单位:%
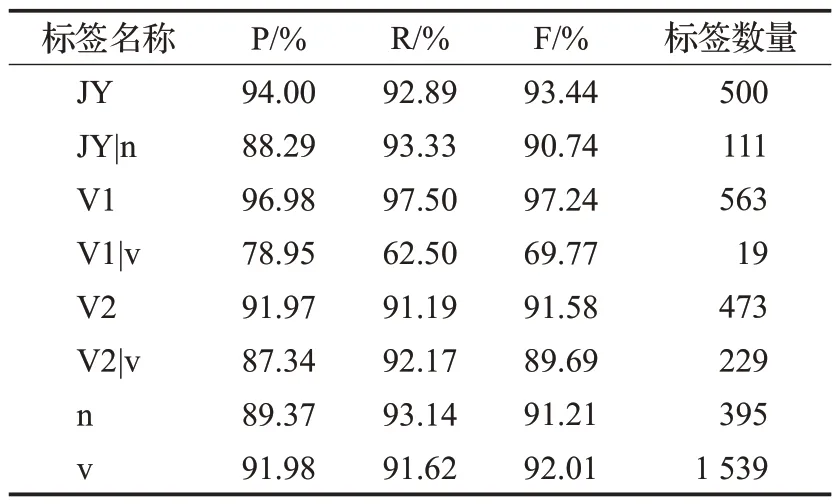
表6 各类标签识别效果Table 6 Recognition effect of various labels
从对比实验结果可以发现,本文提出的模型在识别V+V序列关系的效果上要优于其他模型,精确率为91.85%,召回率为92.38%,F1值为92.12%,能够有效对V+V结构进行建模。
自主学习是学生在学习活动中自我决定、自我选择、自我调控、自我评价反思,发展自身主体性的过程。自主学习具有能动性,独立性和异步性三个基本特点。中职学生自主合作学习能力的培养具有重要意义。通过学生自主地分析、探索、实践等实现学习目标,从中不断提升自主学习能力成为一名真正社会所需的技能型人才。
本文模型相比于Bert-BiLSTM-CRF模型提高了0.91个百分点的分数,BiLSTM-MHAttention-CRF模型相比于BiLSTM-CRF模型提高了1.71个百分点,都表明了多头注意力机制的作用,能够捕获远距离的依赖信息,并抓取最相关的信息,给重要的信息词分配更高的权重。BiLSTM-CRF模型相比于Bert-BiLSTM-CRF模型,效果低了9.84个百分点,本文分析是因为Bert中的Transformer机制采用注意力机制提取文本特征,这样虽然解决了文本的长距离依赖问题,但它难以捕捉句子中字词的位置方向信息,因此Bert-BiLSTM-CRF模型对于连动结构以及宾语从句这种与位置方向有关的结构学习能力较差。本文模型获得了最优的性能,是因为更好地发挥了Bert、BiLSTM、多头注意力机制之间的互补作用。
同时,表6展示了本文的最佳模型在测试集中的具体结果,包括V+V结构内部成分的标签识别效果以及相应标签的数量统计情况。可以看出兼语结构中的V1识别效果最好,其F1值为97.24%,其次是兼语JY,其识别的F1值为93.44%,兼语结构中的V2相比于V1识别效果较差,F1值为91.58%。根据对语料库的分析发现,兼语中的V2多存在于连动结构或其他复杂结构中,因此模型对V2的识别能力较弱。连动结构中的主语n和连动词v识别效果差距不大,分别达到了91.21%和92.01%,但连动主语n的P值较低,只有89.37%,可能原因是标签数量相对于连动词差距较大,数量较少,容易产生过拟合现象。对于兼语连动嵌套标签,由于出现的频率较少,模型难以学到其特征,所以识别效果会因标签数量的降低而变差。
4.3 方法性能对比实验
为了进一步验证本文模型的性能,本文和现有的相关工作的识别结果进行了对比。侯文惠等[7]面向中文AMR标注体系构建了一个兼语语料库,设计了添加词典信息的LA-BiLSTM-CRF模型,并在该语料库上进行兼语结构边界的识别研究,实验结果F1值为86.06%。分别在文献[7]构建的兼语语料库和本文所构建的V+V语料库上进行对比实验。实验结果如表7所示。

表7 相关工作实验结果比较Table 7 Comparison of experimental results单位:%
通过在兼语语料库上的实验结果比较可以发现,本文的模型在兼语结构边界识别任务上的F1值达到91.95%,相较于文献[7]的F1值高出了5.89个百分点。
通过在V+V数据集上的实验结果比较发现,本文模型在V+V序列关系识别的实验结果比文献[7]的模型高出了13.54个百分点,结果表明了文献[7]的方法仅适用于单一类别的兼语结构识别,不适用于标签类别数量较多、结构之间类似的“V+V”数据集,因此具有局限性,而本文提出的模型可以同时识别出兼语结构、连动结构及其嵌套结构,完成更为复杂的任务,并且可以取得更高的性能。
4.4 语料对模型性能影响对比实验
为了探究单独学习一种结构与同时学习多种结构的优劣,使用本文提出的模型在单一结构数据集上进行实验。本节共设置了3个实验,虽然均使用相同的训练集、开发集、测试集,但是在实验的过程中针对语料标签做出了以下区分:
实验Ⅰ:探究只学习连动结构的模型性能,因此在实验过程中,将单一结构数据集中的关于兼语结构的相关标签全部设置为Other。在测试集中评价连动结构识别效果。
实验Ⅱ:探究只学习兼语结构的模型性能,因此在实验过程中,将单一结构数据集中的关于连动结构的相关标签全部设置为Other。在测试集中评价兼语结构识别效果。
实验Ⅲ:探究在单一结构数据集上同时学习兼语结构和连动结构的模型性能,在测试集中评价连动结构和兼语结构的识别效果。
实验结果如表8所示,可以看出实验Ⅰ和实验Ⅱ中对连动识别和兼语识别的效果比实验Ⅲ的结果分别低了1.41和1.47个百分点。对于只学习了连动结构的模型,无法很好地区分兼语结构的干扰,同样只学习兼语结构的模型也不能很好地区分连动结构的干扰。例如句子“王聚生集合全团干部开现场会。”,由于句法结构类似,只学习了兼语结构的模型,会很容易地将该句的“集合”“干部”“开”分别标注成兼语结构中的兼语动词V1、兼语JY以及兼语动词V2,但其实“集合”和“开”是由施事主语“王聚生”发出的连续动作,属于连动词。而同时学习了两种结构的模型便能够较好地解决因为结构类似而识别错误的情况。由于本节实验语料抽取的是单一结构句子,没有包含嵌套结构的复杂句子,因此整体实验结果比在V+V原始数据集上的实验结果有所提高。

表8 语料类型对实验效果的影响对比Table 8 Experimental results of different corpus types单位:%
5 结束语
本文的主要工作包括3个方面:(1)提出包含嵌套结构的V+V句子标注规范;(2)根据设计的嵌套结构标注规范构建了V+V语料库;(3)提出基于BiLSTM-CRF和多头注意力机制的模型来对V+V序列关系进行识别。具体来说,区别于以往的对单一结构的识别工作,本文可以同时识别兼语结构中的兼语动词V1、V2,以及兼语的中心词、连动结构中的施事主语和连动词,并且解决了V+V序列中的嵌套结构识别问题。在测试集语料上实验结果的F1值达到92.12%。
神经网络和注意力机制在结构识别中仍然具有很大的提升空间,本文的工作在词嵌入层仅使用Bert表示词向量,没有添加其他的外部知识,后续工作可以尝试在神经网络中加入动词论元框架的知识,辅助模型的学习。除此之外尝试对兼语结构类别进行分类,并对连动词之间的语义关系进行分类,从而提升汉语语义解析及AMR解析的性能。
猜你喜欢
语数外学习·高中版中旬(2023年7期)2023-08-25 09:04:58
疯狂英语·新阅版(2023年7期)2023-08-17 14:49:58
系统工程学报(2021年4期)2021-12-21 06:21:24
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
青苹果(2014年2期)2014-04-29 20:31:27
渭南师范学院学报(2014年12期)2014-03-20 15:31:14
计算机工程(2014年6期)2014-02-28 01:25:29
