
Endogenous Security-Aware Resource Management for Digital Twin and 6G Edge Intelligence Integrated Smart Park
2023-03-12 12:01SunxuanZhangZijiaYaoHaijunLiaoZhenyuZhouYilongChenZhaoyangYou
China Communications 2023年2期
Sunxuan Zhang,Zijia Yao,Haijun Liao,Zhenyu Zhou,*,Yilong Chen,Zhaoyang You
1 State Key Laboratory of Alternate Electrical Power System with Renewable Energy Sources(North China Electric Power University),Beijing 102206,China
2 Power Dispatching and Control Center of State Grid Shanghai Municipal Electric Power Company,Shanghai 200122,China
Abstract: The integration of digital twin (DT) and 6G edge intelligence provides accurate forecasting for distributed resources control in smart park.However,the adverse impact of model poisoning attacks on DT model training cannot be ignored.To address this issue,we firstly construct the models of DT model training and model poisoning attacks.An optimization problem is formulated to minimize the weighted sum of the DT loss function and DT model training delay.Then,the problem is transformed and solved by the proposed Multi-timescAle endogenouS securiTyaware DQN-based rEsouRce management algorithm(MASTER) based on DT-assisted state information evaluation and attack detection.MASTER adopts multi-timescale deep Q-learning (DQN) networks to jointly schedule local training epochs and devices.It actively adjusts resource management strategies based on estimated attack probability to achieve endogenous security awareness.Simulation results demonstrate that MASTER has excellent performances in DT model training accuracy and delay.
Keywordst: smart park; digital twin (DT); 6G edge intelligence;resource management;endogenous security awareness
I.INTRODUCTION
Smart park is a fundamental unit of smart city and new power system.It covers a high proportion of distributed resources such as renewable energy,controllable loads,and energy storage[1].The core of smart park is to intelligently control and manage distributed resources for carbon emission reduction,renewable energy consumption,real-time electricity transaction,and other auxiliary services.Digital twin (DT) can provide accurate simulation and forecasting for the control and management of smart park by bridging the connectivity gap between physical entities and digital space[2,3].DT requires accurate mapping and realtime synchronization between the twin network and physical entity network.It imposes strict requirements on low-latency data transmission and accurate model training evaluated in terms of loss function[4,5].DT can be further integrated with 6G edge intelligence to support fast response and proximate data analysis by sinking massive computational resources at the network edges [6,7].In such a new paradigm,a large number of communication devices are deployed on distributed resources to collect real-time state data for local model training.Then,the local model parameters and state information are uploaded to edge servers for global model averaging through 6G[8].
To further improve DT model training accuracy and reduce model training delay,network resources including local training epochs and training devices should be managed intelligently and flexibly [9—12].However,different from network resource management in other systems,smart park operation has strict requirements on security and the adverse impact of malicious attackers on resource management cannot be ignored.For instance,model poisoning attack is a key threat to DT model training.Malicious attackers control vulnerable devices to upload error model parameters to adversely reduce global model averaging accuracy,resulting in biased energy control simulations and large demand-supply unbalance of smart park [13,14].Therefore,it is important to achieve endogenous security awareness by actively adjusting resource management in accordance with malicious attacks.How to optimize resource management for DT and 6G edge intelligence integrated smart park under model poisoning attacks faces several challenges,which are summarized as follows.
First,model accuracy and training delay are paradoxical metrics.Increasing the numbers of scheduled devices and local training epochs to improve model accuracy also increases the total DT model training delay.Second,considering the random behavior of malicious attackers and unpredictable model poisoning attacks based on the unpredictable attack,it is difficult to guarantee accuracy and delay requirements for DT model training.Last but not least,the management of various network resources is coupled across different timescales.For example,since the probability of model poisoning attacks varies much slower than channel conditions,local training epoch scheduling needs to be optimized in a large timescale,which also depends on the small-timescale device scheduling.Traditional resource management algorithms face slow convergence and poor optimization performances when solving multi-timescale resource management problem with large optimization space.
Many researchers have focused on the combination of DT and edge intelligence.In [15],Fanet al.proposed a DT-empowered edge artificial intelligence framework to realize ubiquitous control over heterogeneous vehicles mixing connected and automated vehicles (CAVs),connected vehicles (CVs),and humandriven vehicles (HVs).In [16],Fanet al.proposed a DT-empowered mobile edge computing (MEC) architecture to enhance the sensing,computing,and decision-making capabilities of CAVs.However,the above works neglect resource management optimization for DT construction.In [17],Sunet al.developed a deep reinforcement learning-based framework to manage local resources for DT-empowered industrial internet of things (IIoT) for loss function minimization.However,the aforementioned works neglect the impact of malicious attacks and cannot achieve endogenous security awareness.Moreover,the joint guarantee of low latency and high accuracy of DT model is not considered.In[14],Zhouet al.designed a weight-based detection scheme to defend against poisoning attacks in a federated learning(FL)system.However,this work neglects the scheduling of local training epochs and devices in model training,which cannot improve the training accuracy.
Motivated by the above challenges,we propose a Multi-timescAle endogenouS securiTy-aware DQNbased rEsouRce management algorithm (MASTER)for DT and 6G edge intelligence integrated smart park.First,the models of DT model training and model poisoning attacks are constructed.Then,we formulate a joint optimization problem to minimize the weighted sum of the DT loss function and average total DT model training delay through coordinated scheduling of local training epochs and devices.Afterwards,we transform the original problem into minimizing the weighted sum of the DT loss function convergence upper bound and average total DT model training delay.Finally,the transformed problem is addressed by the proposed MASTER with endogenous security awareness.The main contributions are summarized as follows.
・Low-Latency and High-Accuracy DT Model under Model Poisoning Attacks:MASTER jointly minimizes the DT loss function and average total DT model training delay.The tradeoff between accuracy and low latency is achieved by changing the weight of delay and learning the optimal resource management strategies accordingly.
・Endogenous Security-Aware Resource Management Coordination:We adopt a detection scheme to estimate the probability of model poisoning attack.The scheduling strategies of local training epochs and devices are actively adjusted based on estimated probability to guarantee accuracy and delay performances,thereby realizing the security of DT model training endogenously.
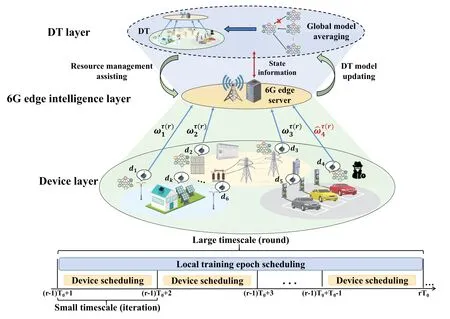
Figure 1.Scenario of DT and 6G edge intelligence integrated smart park.
・Intelligent Multi-timescale Scheduling of Network Resources with Fast Convergence:Based on DTassisted state information evaluation and model poisoning attack detection,MASTER adopts a large-timescale deep Q-learning (DQN) network to learn the large-timescale local training epoch scheduling strategy.Based on the optimized local training epoch scheduling strategy,a smalltimescale DQN network is adopted to learn the small-timescale device scheduling strategy.Moreover,we derive the minimum number of scheduled devices to reduce the optimization space and accelerate the convergence of multitimescale resource management optimization.
The rest of the paper is organized as follows.Section II introduces the models of DT model training and model poisoning attacks.Section III elaborates the problem formulation and transformation.The proposed MASTER is developed in Section IV.Section V presents the simulation results.Section VI concludes this paper.
II.SYSTEM MODEL
We considered a scenario of DT and 6G edge intelligence integrated smart park as shown in Figure 1.The objective is to set up a DT model for the smart park.We adopt FL to update the DT model since it can decouple the DT model updating from raw data uploading,thereby avoid the privacy disclosure of raw data[4,18].The considered scenario consists of three layers,i.e.,device layer,6G edge intelligence layer,and DT layer.
In the device layer,communication devices are deployed on electrical equipment such as photovoltaic and charging piles to perform local model training.There existKdevices,the set of which is donated asD={d1,···,dk,···,dK}.The devices perform local model training based on the scheduling of local training epochs by the 6G edge intelligence layer.Then,the devices upload their local model parameters to the 6G edge intelligence layer for global model averaging based on the device scheduling strategies.Some malicious attackers may launch model poisoning attacks,i.e.,reducing global model training accuracy by controlling devices to upload error model parameters.
In the 6G edge intelligence layer,there exist a base station (BS) and a colocated 6G edge server.Due to the existence of model poisoning attacks,the edge server schedules local training epochs for devices to guide the local model training,and makes device scheduling strategies for local parameter uploading.Moreover,the edge server provides detection for model poisoning attacks.
The DT layer is maintained by the edge server,which realizes real-time interaction with devices to keep the synchronization between DT and physical infrastructures.Besides,DT can assist resource management optimization by providing state estimation such as channel gain,electromagnetic interference,and the probability of model poisoning attacks.
Since the probability of model poisoning attacks varies much slower than channel gain,local training epoch scheduling needs to be optimized in a large timescale to guarantee training stability,while device scheduling needs to be optimized in a small timescale to adapt with rapidly changing link conditions.We divide the total optimization time intoRcommunication rounds,i.e.,large timescale.Each communication round is divided intoT0iterations,i.e.small timescale.The set of communication rounds is denoted asR={1,···,r,···,R} and ther-th round is denoted asT(r)={(r −1)T0+1,(r −1)T0+2,···,rT0}.Rrounds consist of a total ofTiterations,i.e.,T=RT0,and the set of iterations is denoted asT={1,···,t,···,T}.The edge server optimizes local training epoch scheduling in the large timescale and device scheduling in the small timescale.
2.1 DT Model
Denote the DT ofdkasDTk,which consists of local modelMk,local datasetCk,and local state informationsk(t).DTkis given by
2.2 Device Scheduling and Local Training Model
The edge server schedules devices to upload local model parameters for global model averaging in each iteration.A device is unavailable for local model training and parameter uploading if it has been detected as a malicious device by the edge server.Denote the set of available devices in thet-th iteration asDava(t)⊆D,the size of which is|Dava(t)|,i.e.,the number of elements inDava(t).Denote the device scheduling variable asak(t)∈ {0,1},whereak(t)=1 representsdkis scheduled in thet-th iteration,andak(t)=0 otherwise.The scheduled device,e.g.,dk,downloads the global model from the edge server to update its local model,which is expressed as
whereωkτ(r)(t −1) andωg(t −1) represent the local model parameter ofdkin the (t −1)-th iteration and the global model parameter in the(t −1)-th iteration,respectively.τ(r)represents the number of local training epochs in ther-th round.
In each iteration,dkutilizes its local datasetCkfor local model training[19,18,20].Denotexjandyjas the input and target output of thej-th sample inCk,the loss function ofdkis given by
where|Ck|is the sample size ofCk.fτ(r)(ωτ(r)k(t −1),xj,yj) represents the loss function of one sample,which is defined as the deviation of the real output from the target output.The loss function is used to updateωτk(r)through the gradient descent method[21,22],i.e.,
whereγis the learning step.
The local training delay ofdkis given by
whereζkis the CPU cycles required for processing one sample,andfk(t)is the available local computational resources.
2.3 Local Uploading Model
After local model training,each scheduled device uploads the local model parameter and local state information.The uploading rate is given by
whereBk(t) is the uploading bandwidth.pk(t) andgk(t) are the uploading power and channel gain,respectively.σ0andσkEMI(t) are the Gaussian white noise and the electromagnetic interference power,respectively.Sincesk(t)is very small,the uploading delay ofsk(t) can be ignored [23].Denoting|ωτk(r)(t)|as the size of local model parameter,the uploading delay of which is given by
2.4 Model Poisoning Attack Model
Malicious attackers in the smart park may control devices to upload error model parameters to launch model poisoning attacks,thereby destroying the global model averaging.The model poisoning attack is modeled as[24]
wherePa(r)is the probability of model poisoning attack in ther-th round.(t) represents the error model parameter,which is given by
whereχ ∈[−1,1]is the scale factor,andnk(t)is the additive noise with Gaussian distributionN(0,σ2).
2.5 Global Averaging Model
The edge server performs global model averaging to update the DT model after receiving the uploaded local model parameters and state information from the scheduled devices.The global model averaging is given by
The delay of global model averaging is expressed as
whereλ0denotes the CPU cycles per bit processing.fg(t)represents the available computational resources of the edge server.
The loss function ofωg(t)is utilized to measure the accuracy of the global model,which is given by
2.6 Model Poisoning Attack Detection
Model poisoning attack detection is proposed to detect error model parameters.The principle is to calculate the Euclidean norm between the parameter to be detected and the average parameter based on the other parameters,and compare this norm with the preset threshold[14].Takingωτk(r)(t)for example,the average parameters based on the other parameters withoutωτk(r)(t)is calculated as
The Euclidean norm betweenωτk(r)(t) andωSkT(t)is calculated as
Denote the scale reference value ofdk(t) and||ωSkT(t)||2asek(t),which is calculated as
Denote the attack detection variable asbk(t)∈{0,1},wherebk(t)=1 represents normal model parameter,andbk(t)=0 otherwise.The attack detection is given by
whereeThris the preset detection threshold.
When the proportion of the error model parameter uploaded bydkup to thet-th iteration exceeds a threshold,i.e.
dkis regarded as a malicious device and removed fromDava(t+1).
2.7 Total DT Model Training Delay
The total DT model training delay is the sum of the maximum local training delay and uploading delay among all the devices,and the global model averaging delay,which is given by
III.PROBLEMFORMULATIONAND TRANSFORMATION
3.1 Problem Formulation
To ensure the accurate and real-time simulation and forecast of smart park,the objective of the optimization problem is to minimize the weighted sum of the DT loss function and the total DT model training delay averaged overTiterations by jointly optimizing the scheduling of local training epochs and devices.The joint optimization problem is formulated as
where a(t)=(ak(t):∀dk ∈Dava(t),∀t ∈T),VLis a non-negative weight to trade off the DT loss function and average total DT model training delay.C1andC2are the device scheduling constraints.C3represents the discretized local training epoch scheduling constraint.Defineτ1andτHas the minimum and the maximum numbers of local training epochs.The interval of local training epochs [τ1,τH] is quantized intoHlevels,whereτh=
3.2 Problem Transformation
Since the short-term resource management optimization is coupled with the optimization objective,P1 is nontrivial to be solved directly.Therefore,based on[24],P1 is converted to minimize the weighted sum of the DT loss function convergence upper bound and the total DT model training delay per iteration.P1 can be rewritten as P2,which is given by(20).
In P2,ϕ(τ(r))=andδindicates the upper bound of the divergence between the gradient of the local loss function and the gradient of the DT loss function.ρandβrepresent the local loss function areρ −Lipschitz andβ −Smooth,respectively.Θ is the upper bound of the norm of all local model parameters,andvis the lower bound of the divergence between the current DT loss function and the converged DT loss functionF(ωgcon).is the estimated model poisoning attack probability in thet-th iteration,which is calculated by
According to P2,the following two remarks can be derived.
Remark 1.Since the DT loss function convergence upper bound is a convex function,there exists an optimal local training epoch τ∗(r)under model poisoning attack.τ∗(r)is associated with the probability of model poisoning attacks and the number of scheduled devices.A similar proof can be found in[24].
Remark 2.Increasing the number of scheduled devices under a fixed probability of model poisoning attacks will improve the DT loss function convergence upper bound but may also increase the average total DT model training delay.
Based on the Remark 2,we add a DT loss function convergence upper bound constraint to prevent the deterioration of DT model accuracy by at least scheduling a certain number of devices.The DT loss function convergence upper bound constraint can be further transformed into the constraint of the analytical part in the convergence upper bound related to the number of scheduled devices,i.e.
whereλ(t) is the threshold of the analytical part in the convergence upper bound related to the number of scheduled devices.Since the number of scheduled devices is an integer,(22)can be rewritten as
Therefore,P2 can be rewritten as
IV.MULTI-TIMESCALE ENDOGENOUS SECURITY-AWARE DQN-BASED RESOURCE MANAGEMENT
In this section,we propose MASTER to address P3 and realize coordinated resource management under unpredictable model poisoning attack for DT and 6G edge intelligence integrated smart park.
4.1 MDP Model
P3 can be modeled as a Markov decision process(MDP)as follows.
4.1.1 DT-Estimated State Space
The state space of local training epoch scheduling consists of all DT-estimated model poisoning attack probabilities during the previous communication round,i.e.
The state space of device scheduling consists of the local training epoch scheduling strategy and DTestimated model poisoning attack probability(t −1),channel gain(t),and electromagnetic interference(t).The state space of device scheduling is described as
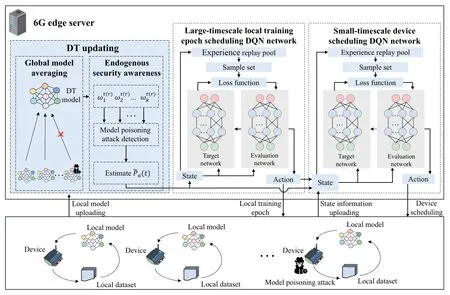
Figure 2.The framework of MASTER.
4.1.2 Action Space
The action space of local training epoch scheduling is given by
whereaTh(r)=1 denotesτ(r)=τh.
The action space of device scheduling is given by
4.1.3 Cost Function
Since P3 is a minimization problem,the cost function is adopted.For the small-timescale device scheduling,we utilize the one-iteration cost functionΩ(aT(r),a(t)),where aT(r)={aTh(r)}.For the large-timescale local training epoch scheduling,theT0-iteration cost function is utilized,which is calculated as
4.2 MASTER
MASTER is proposed to address the modeled MDP problem.The core idea is to adopt DQN to quantify and fit the state-action value in high-dimensional state space and achieve endogenous security awareness through the assistance of DT and model poisoning attack detection[25—29].
The detailed framework of MASTER is shown in Figure 2.MASTER is performed in the edge server with an online learning manner.Two sets of DQN networks are constructed for the scheduling of local training epochs and devices,respectively [30].For the large-timescale local training epoch scheduling,the edge server maintains an evaluation network and a target network,and the network parameters are respectively defined asψTeva(r)andψTtar(r).Similarly,the network parameters of the small-timescale device scheduling are respectively defined asψDeva(t) andψDtar(t).The principle of endogenous security awareness is to incorporate the estimated model poisoning attack probability into the modeling of DT-estimated state space and the calculation of cost function and Q value.MASTER can continuously fit and perceive the complex mapping relationship between the action value and the state and estimate the model poisoning attack probability with the assistance of DT and model poisoning attack detection to achieve endogenous security awareness.Therefore,the edge server can actively adjust the multi-timescale resource management strategy to reduce the DT loss function and average total DT model training delay.
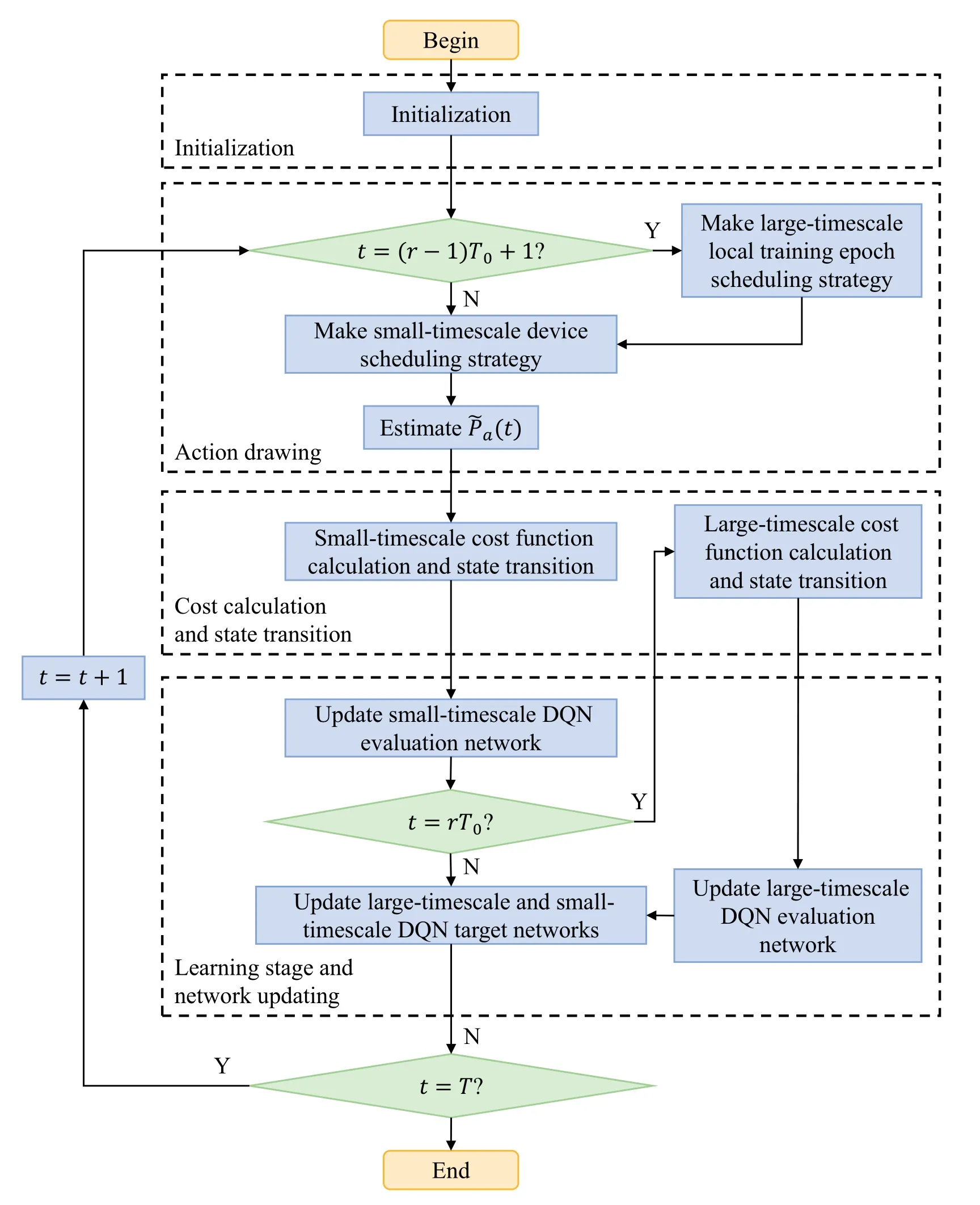
Figure 3.The flowchart of MASTER.
The flowchart of MASTER is shown in Figure 3.The implementation procedures of MASTER are summarized in Algorithm 1.

Algorithm 1.MASTER.1: Input: ST(r),SD(t),ϵ.2: Output:{aT(r),a(t)}.3: Initialize: Initialize ψTeva(r),ψTtar(r),ψDeva(t),ψDtar(t),ΩT0(aT(r)),and Ω(aT(r),a(t)).4: For t=1,···,T do 5:If t=(r −1)T0+1,r=1,···,R do 6:The edge server draws an action of largetimescale local training epoch scheduling aT(r)based on the ϵ-greedy method.7:end if 8:The edge server draws an action of smalltimescale device scheduling a(t) based on the ϵgreedy method.9:Each device executes aT(r)and a(t).10:The edge server estimatesimages/BZ_65_809_1245_823_1291.pngimages/BZ_65_823_1233_868_1279.pngPa(t)as(21).11:The edge server observes the DT loss function and average total DT model training delay performance,and calculates Ω(aT(r),a(t))as(24).12:Update the experience replay pool UD(t) and transfer SD(t)to SD(t+1).13:Randomly sample a set UDsamp,and calculate loss function ηD(t)as(33).14:Update ψDeva(t+1)as(34).15:If t=rT0,r=1,···,R do 16:The edge server calculates ΩT0(aT(r))as(29).17:Update the experience replay pool UT(r)and transfer ST(r)to ST(r+1).18:Randomly sample a set UTsamp,and calculate loss function ηT(r)as(30).19:Update ψTeva(r+1)as(32).20:end if 21:Update ψTtar(r)=ψTeva(r)every R0 rounds.22:Update ψDtar(t)=ψDeva(t)every T0 iterations.23: end for
1) Initialization:Initialize network parametersψTeva((r),)ψTtar(r),ψ(Deva(t),and)ψDtar(t).SetΩT0aT(r)=0,and ΩaT(r),a(t)=0.
2)Action Drawing:At the beginning of each round,i.e.,t=(r −1)T0+1,the edge server leveragesϵgreedy method to draw the action of large-timescale local training epoch scheduling.Similarly,at the beginning of each iteration,the edge server draws the action of small-timescale device scheduling.Each device executes the drawn action.The edge server estimates the model poisoning attack probability as(21).
3)Cost Calculation and State Transition:At the end of each iteration,the edge server observes the DT loss function and average total DT model training delay performance,and calculates Ω(aT(r),a(t))based on(24).At the end of each round,i.e.,t=rT0,the edge server calculatesbased on(29).
For the large-timescale local training epoch scheduling,the edge server generates experience datauT(r)={ST(r),AT(r),,ST(r+1)}to update a experience replay poolUT(r),and transforms the current state ST(r) to the next state ST(r+1).Similarly,for the small-timescale device scheduling,the edge server generates experience datauD(t)={SD(t),AD(t),Ω(aT(r),a(t)),SD(t+1)}to update a experience replay poolUD(t),and transforms the current state SD(t)to the next state SD(t+1).
4) Learning Stage and Network Updating:At the end of each round,the edge server randomly samples a setUfromUT(r),and updates the loss function of large-timescale local training epoch scheduling as
whereQTtar(r) denotes the Q value of the target network,which is calculated by
whereιrepresents the discount factor.
Gradient descent method is adopted to update evaluation network parameterψTtar(r),i.e.
whereκrepresents the learning step.
Similarly,at the end of each iteration,the edge server randomly samples a setUDsampfromUD(t).The loss function and the evaluation network parameterψDeva(t+1)of the small-timescale device scheduling are updated as
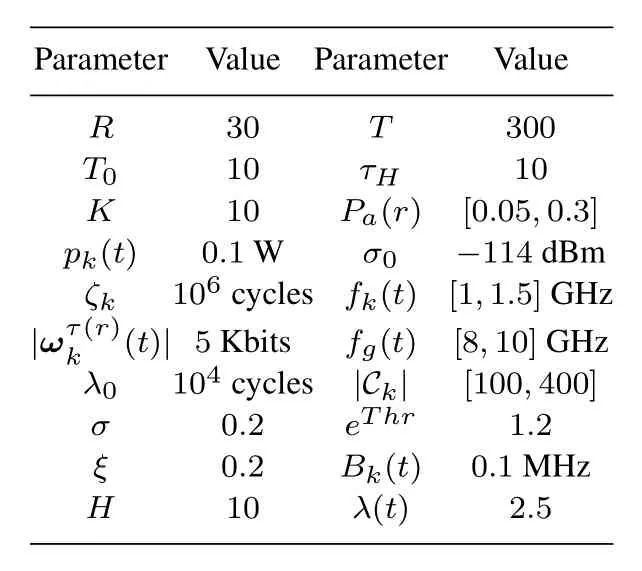
Table 1.Simulation parameters.
UpdateψTtar(r)=ψTeva(r) everyR0rounds,and updateψDtar(t)=ψDeva(t)everyT0iterations.
The optimization ends whent=T.
MASTER can achieve endogenous security-aware resource management for DT and 6G edge intelligence integrated smart park.It actively adjusts the largetimescale local training epoch scheduling and smalltimescale device scheduling strategies based on the estimated probability of model poisoning attack.Specifically,for the small-timescale device scheduling,when the estimated probability of model poisoning attack in thet-th iteration is larger than that in the (t −1)-th iteration,the cost function Ω(aT(r),a(t))may increase.Hence,the edge server can actively adjust the device scheduling strategy to reduce Ω(aT(r),a(t))and ensure the DT training accuracy and average total DT model training delay performances.For the large-timescale local training epoch scheduling,MASTER can perceive the variation of the cost functionand estimated model poisoning attack probability distribution.Therefore,the edge server can actively adjust the local training epoch scheduling strategy to adapt to the changing model poisoning attacks,ensuring the security of DT model training endogenously.
V.PERFORMANCE ANALYSIS AND SIMULATIONS
We consider a 400 m×400 m area in the smart park,which contains 10 devices.The devices are randomly distributed,and the BS and the edge server are located at the center.The classic data set MNIST is adopted to train the DT model[18,31].Each device is randomly allocated with several training samples from MINST.The probability of model poisoning attack is randomly distributed in [0.05,0.3].The simulation parameters are summarized in Table 1 [14,18,24,32].Two resource management algorithms are adopted for comparison.The first one is the DRL-based device orchestration algorithm (DRL-DO) [33],the optimization objective of which is to minimize the weighted sum of the DT loss function and average total DT model training delay.The other one is the upper confidence bound policy-based client scheduling algorithm(UCB-CS)[34],the optimization objective of which is to minimize the average total DT model training delay.Both algorithms neglect the large-timescale local training epoch scheduling and randomly setτ(r)in[1,10].Moreover,endogenous security awareness is not considered as well.
Figure 4 shows the weighted sum of DT loss function and average total DT model training delay versus iterations.MASTER outperforms DRL-DO and UCB-CS by 13.47% and 17.10%.Moreover,MASTER achieves better convergence and lower volatility.The reason is that MASTER jointly optimizes the DT loss function and average total DT model training delay by perceiving endogenous security.The related results will be further provided in Figure 5 and Figure 6.
Figure 5 shows the DT loss function versus iterations.Figure 6 shows the average total DT model training delay versus iterations.Compared with DRLDO and UCB-CS,MASTER improves the DT loss function by 57.09%and 72.01%.MASTER improves the average total DT model training delay by 6.06%compared with DRL-DO.The reason is that MASTER can quantify and fit the complex relationship between high-dimensional state spaces and multi-timescale resource management actions,and achieve endogenous security awareness through the assistance of DT and model poisoning attack detection.Therefore,MASTER can learn and actively adjust the multi-timescale resource management strategies to reduce the DT loss function and average total DT model training delay jointly.UCB-CS achieves the best average total DT model training delay but the worst DT loss function since it only considers the optimization of the average total DT model training delay.
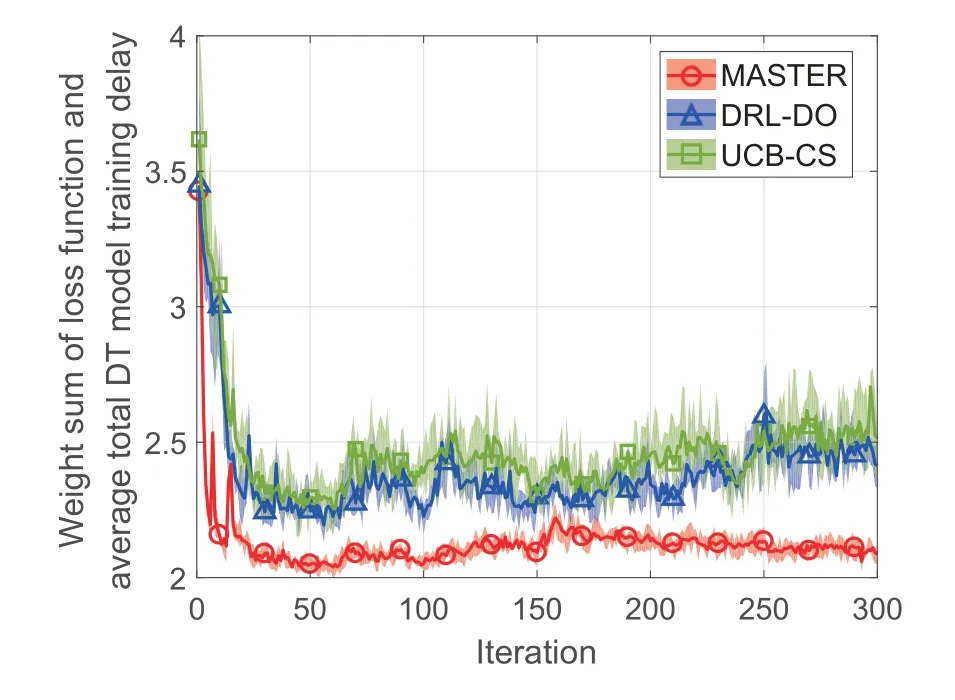
Figure 4.The weighted sum of the DT loss function and average total DT model training delay versus iterations.
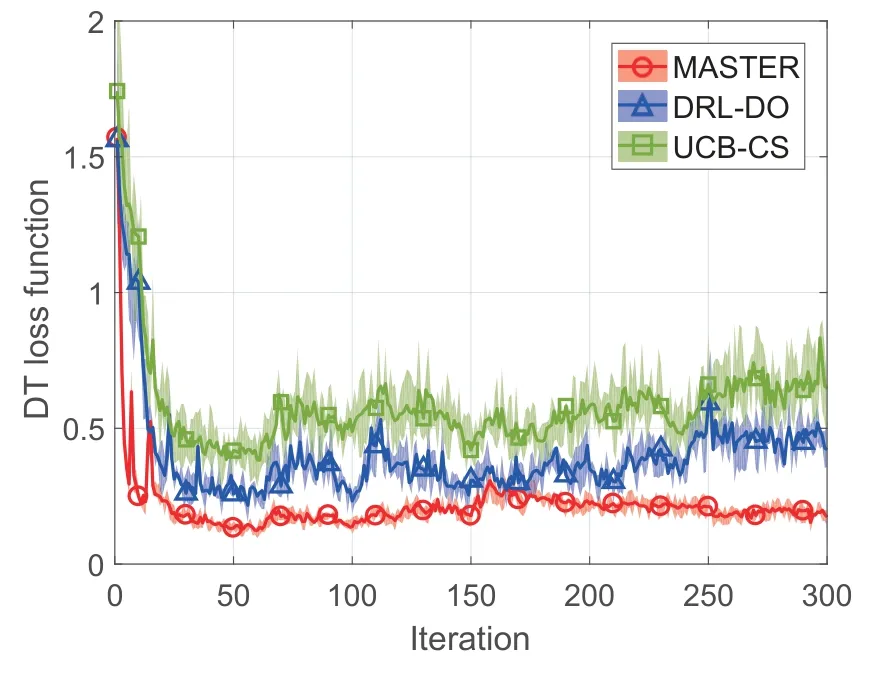
Figure 5.The DT loss function versus iterations.
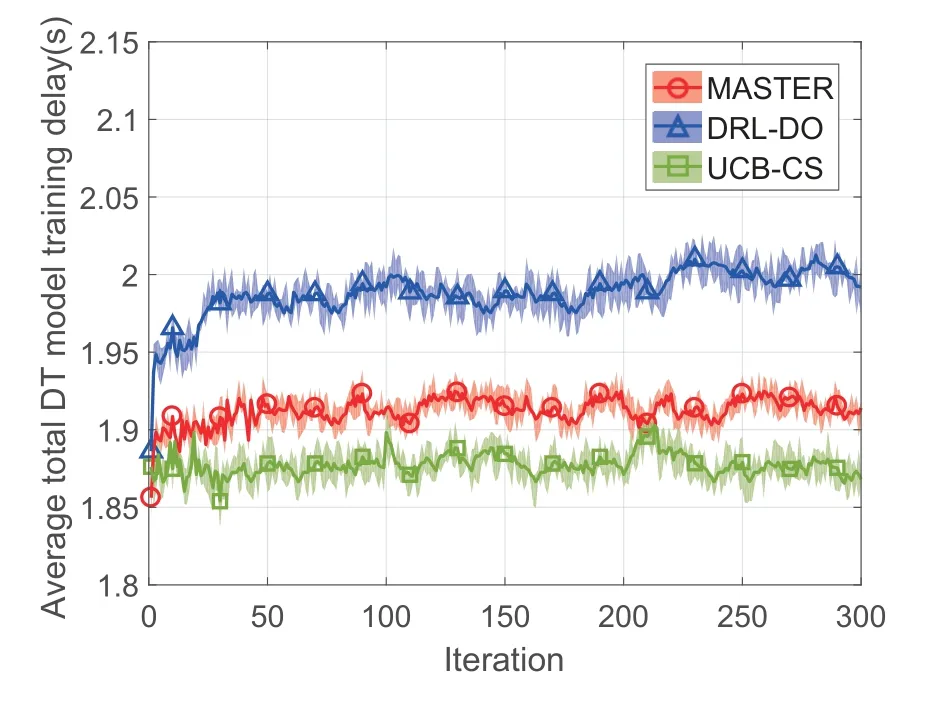
Figure 6.The average total DT model training delay versus iterations.
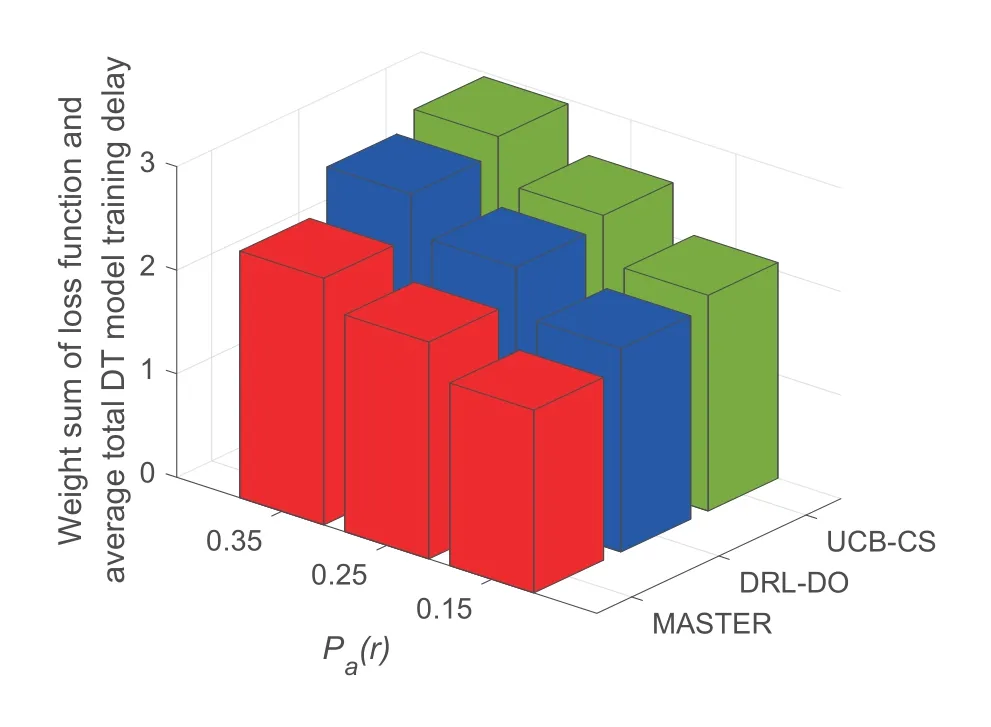
Figure 7.The weighted sum of the DT loss function and average total DT model training delay versus the model poisoning attack probability.
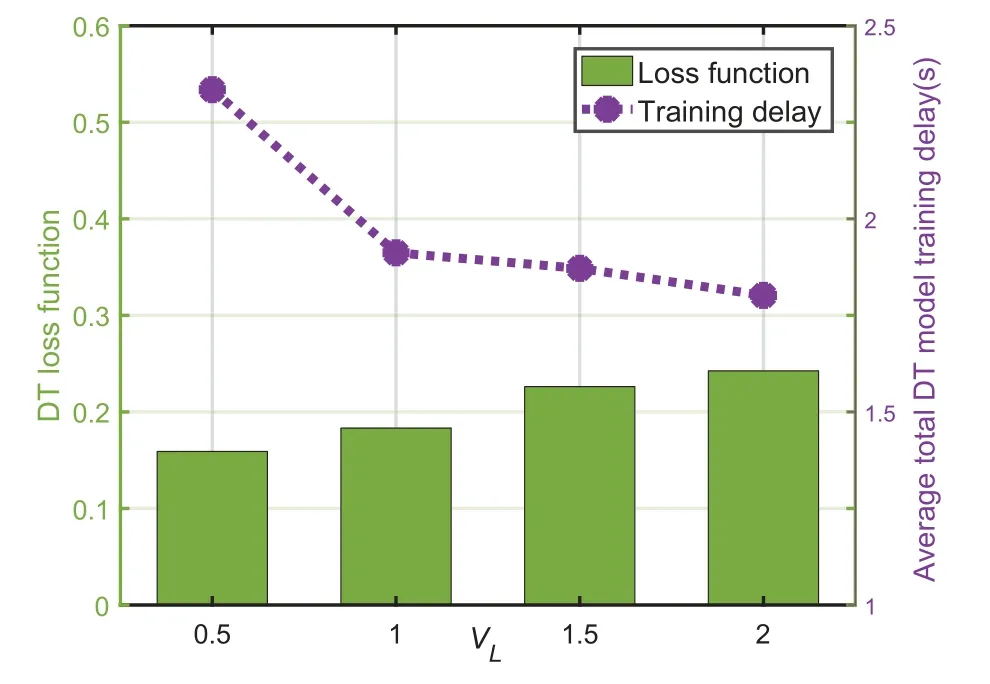
Figure 8.The DT loss function and average total DT model training delay versus VL.
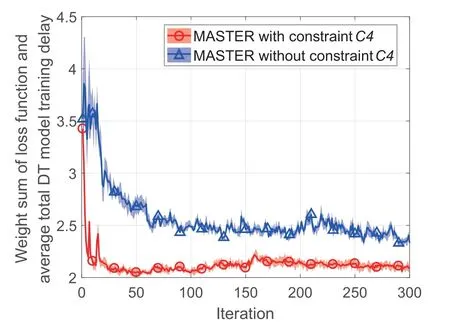
Figure 9.The convergence performance.
Figure 7 shows the weighted sum of the DT loss function and average total DT model training delay versus average model poisoning attack probability.As the probability increases,the weighted sums of three algorithms increase,and MASTER has the lowest increase.MASTER outperforms DRL-DO and UCBCS by 14.91%and 19.51%whenPa(r)=0.35.The reason is that MASTER adopts the model poisoning attack detection to estimate the model poisoning attack probability.Hence,MASTER can actively adjust the multi-timescale resource management strategies by perceiving the estimated attack probability to realize the endogenous security of the DT model training.
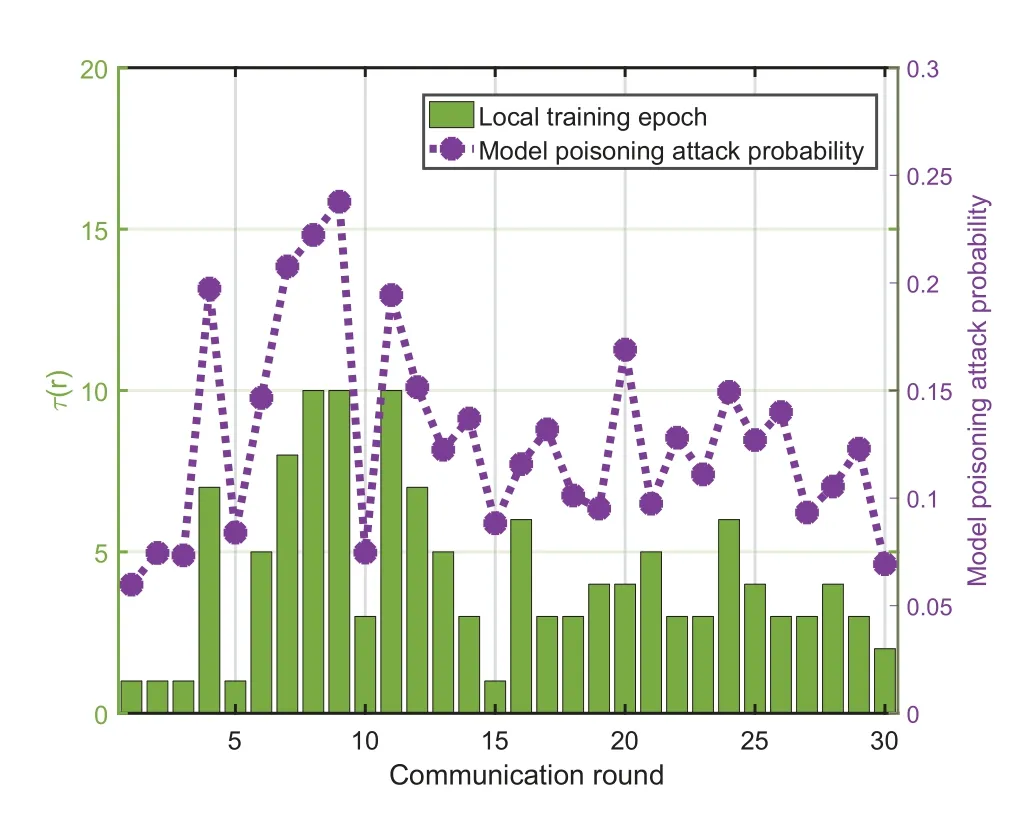
Figure 10.τ(r) and model poisoning attack probability versus communication rounds.
Figure 8 shows the performances of the DT loss function and average total DT model training delay versusVL.With the increase ofVL,the DT loss function increases while the average total DT model training delay decreases.The reason is that with the increase ofVL,the average total DT model training delay performance has a more significant impact on the change of the cost function.MASTER will dynamically adjust the multi-timescale resource management strategies to achieve a better average total DT model training delay performance to reduce the cost function.
Figure 9 shows the convergence performance of MASTER with and without constraintC4.MASTER with constraintC4converges at the 30-th iteration while MASTER withoutC4converges at the 90-th iteration.The reason is thatC4limits the minimum number of scheduled devices to reduce the size of the action space of MASTER and achieve faster convergence.
Figure 10 showsτ(r) and model poisoning attack probability versus communication rounds.The simulation result demonstrates that from 1-st to 15-th round,MASTER can perceive the large fluctuation of model poisoning attack probability to frequently adjust the local training epoch scheduling decision.From 16-th to 30-th round,MASTER can slightly adjust the local training epoch scheduling decision to adapt to the small fluctuation of model poisoning attack probability.
VI.CONCLUSION
In this paper,we investigated the multi-timescale resource management problem for DT and 6G edge intelligence integrated smart park under unpredictable model poisoning attacks.We proposed MASTER to dynamically optimize the scheduling of largetimescale local training epochs and small-timescale devices with endogenous security awareness.MASTER reduces the DT loss function by 57.09%and the average total DT model training delay by 6.06%compared with DRL-DO,and reduces the DT loss function by 72.01%compared with UCB-CS.In the future,we will focus on the model data leakage caused by inference attacks in DT and 6G edge intelligence integrated smart park.
ACKNOWLEDGEMENT
This work was supported by the Science and Technology Project of State Grid Corporation of China under Grant Number 52094021N010(5400-202199534A-0-5-ZN).

- China Communications的其它文章
- Quality-Aware Massive Content Delivery in Digital Twin-Enabled Edge Networks
- Edge-Coordinated Energy-Efficient Video Analytics for Digital Twin in 6G
- Unpredictability of Digital Twin for Connected Vehicles
- Digital Twin-Assisted Knowledge Distillation Framework for Heterogeneous Federated Learning
- Design and Implementation of Secure and Reliable Information Interaction Architecture for Digital Twins
- A Golden Decade of Polar Codes: From Basic Principle to 5G Applications