
Quality-Aware Massive Content Delivery in Digital Twin-Enabled Edge Networks
2023-03-12 12:00YunGaoJunqiLiaoXinWeiLiangZhou
China Communications 2023年2期
Yun Gao,Junqi Liao,Xin Wei,Liang Zhou,*
1 School of Communications and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China
2 Key Laboratory of Broadband Wireless Communication and Sensor Network Technology,Ministry of Education,Nanjing University of Posts and Telecommunications,Nanjing 210003,China
Abstract: Massive content delivery will become one of the most prominent tasks of future B5G/6G communication.However,various multimedia applications possess huge differences in terms of object oriented(i.e.,machine or user)and corresponding quality evaluation metric,which will significantly impact the design of encoding or decoding within content delivery strategy.To get over this dilemma,we firstly integrate the digital twin into the edge networks to accurately and timely capture Quality-of-Decision(QoD) or Quality-of-Experience (QoE) for the guidance of content delivery.Then,in terms of machinecentric communication,a QoD-driven compression mechanism is designed for video analytics via temporally lightweight frame classification and spatially uneven quality assignment,which can achieve a balance among decision-making,delivered content,and encoding latency.Finally,in terms of user-centric communication,by fully leveraging haptic physical properties and semantic correlations of heterogeneous streams,we develop a QoE-driven video enhancement scheme to supply high data fidelity.Numerical results demonstrate the remarkable performance improvement of massive content delivery.
Keywordst: content delivery; digital twin; edge networks;QoD;QoE
I.INTRODUCTION
With the rapid advancements in wireless networks and multimedia communications,we have witnessed the substantial growth of various multimedia applications in recent years[1—3],which shift from traditional video services(e.g.video conferencing,video surveillance,etc.) to multi-modal services integrating audio,video,and haptic streams(e.g.remote industrial control,telesurgeryetc.) [4,5].Meanwhile,the development of smart city and Industrial Internet of Things(IIoT)inevitably results in the increasing data amount from these multimedia applications[6].As a result,in terms of massive multimedia contents with heterogeneous streams,how to design an efficient content delivery strategy has become one of the most challenging tasks[7].
Although the edge network is a promising paradigm to satisfy low-latency transmission requirements [8—10],however,diverse types of multimedia applications possess substantial differences in terms of quality evaluation metrics,which will significantly impact the design principle of content delivery strategy.Specifically,from the communication perspective,various multimedia applications can be broadly divided into two categories,i.e.,user-centric communication and machine-centric communication [11].In particular,figure 1 depicts two typical communication scenarios regarding massive content delivery,respectively.From these two sub-figures,we can clearly obtain the following observations.
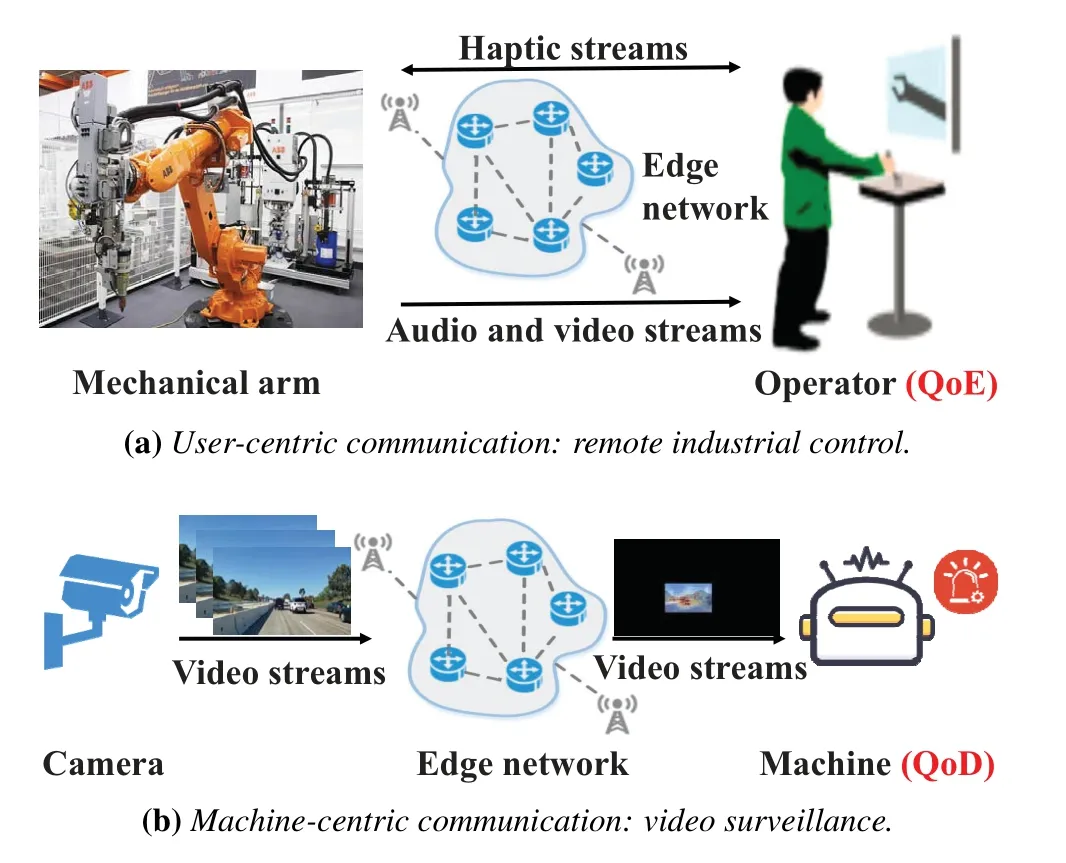
Figure 1.Two typical multimedia communication scenarios.
・ User-centric communication focuses on delivering content as much as possible to ensure highfidelity signals for user’s Quality-of-Experience(QoE) improvement.As illustrated in figure 1a,the operator usually requires ultra high-resolution videos to accurately teleoperate the mechanical arm in IIoT scenarios.
・ Machine-centric communication emphasizes more on Quality-of-Decision (QoD) to only transmit necessary information critical to machine decision-making [12].For instance,if videos are consumed by machines for object detection/classification,there is no need to implement high-quality encoding at each pixel/region,which can effectively avoid redundant content delivery.
Given the above analysis,timely acquisition of QoE and QoD is expected to guide the design of encoding or decoding within content delivery in various applications.Although abundant data-driven approaches have been devoted to estimating or predicting these quality evaluation metrics[4,13,14],however,there is always a gap between the predicted value and true feedback in terms of accuracy and timeliness,especially under the complex and time-varying edge networks.
In order to get over the above dilemma,Digital Twin(DT),as an emerging digitalization technology in 6G era,offers a feasible solution by creating a virtual twin to simulate physical entities in real world(e.g.,device,model,system,etc.) [15—17].Specifically,merging DT with the edge networks (i.e.,DTEN) has the following two benefits:on the one hand,DT can comprehensively capture the dynamic status of the edge network environment,and accurately monitor QoE and QoD via simulated virtual twin.On the other hand,edge networks bring powerful communication,computation,and storage capabilities to DT,enabling realtime monitoring of QoE and QoD.Even if the DTEN has huge potential to supply precise and timely evaluation metrics,in particular,we still face the following two technical challenges when designing qualityaware content delivery strategies.
・Challenge 1: How to fully compress multimedia streams for machine decision-making based on QoD?
In terms of machine-centric communication,there exists a thorny problem regarding what contents need to be transmitted or discarded at the encoder under the premise of ensuring decision-making performance.Moreover,how to achieve low encoding latency is also important for delay-sensitive multimedia applications.
・Challenge 2: How to remarkably recover or even enhance multimedia streams for human perception based on QoE?
In terms of user-centric communication,packet loss inevitably happens during stream transmission due to channel noise[18].Basically,how to recover or even enhance signals at the decoder will benefit the further improvement of human-perception quality.
With the assistance of DTEN,this work aims at designing two content delivery strategies in terms of different types of multimedia applications by fundamentally resolving the above two technical challenges.In particular,we choose video analytics in smart city and remote material touching in IIoT as two typical cases to present the designed transmission strategies.The main contributions of this work can be summarized as follows.
・ We propose a DTEN framework for massive content delivery to acquire precise and timely quality evaluation metrics.In particular,with the support of real data from physical entities,the virtual twin can comprehensively simulate the QoD or QoE,and then return to the physical entities for the guidance of content delivery.
・ We design a QoD-driven encoding mechanism for video analytics to fulfill efficient compression.Specifically,by fully leveraging lightweight frame classification and uneven quality assignment for spatio-temporal compression,we are capable of achieving a balance among decisionmaking,delivered content,and encoding latency.
・ We develop a video enhancement scheme for QoE improvement to supply high data fidelity in IIoT.In order to further improve human visual perception quality,we make full use of physical properties of haptic streams and semantic correlations of heterogeneous streams for video enhancement at the decoder.
The reminder of this paper is organized as follows.Section II briefly reviews the related works on digital twin,video compression and enhancement.In Section III,we propose a DTEN-enabled multimedia content delivery framework.Section IV and V introduce QoD-driven video compression as well as video enhancement for QoE improvement,respectively.Section VI exhibits the numerical results,and we give the concluding remarks and future works in Section VII.
II.RELATED WORKS
2.1 Digital Twin
The concept of DT was first proposed in 2002 to describe product life-cycle management.With the development of 5G and upon 6G mobile networks in recent years,DT aims to provide real-time digital replicas of physical entities in the real world (e.g.,machine,human,system,etc.),which can monitor,simulate,optimize,and predict the status of these actual objects in several application scenarios including manufacturing,smart city,intelligent transportation,IIoT,etc.
For example,Huiet al.[19]develop a DT-enabled architecture for intelligent autonomous vehicles to simulate frequent information exchanges between vehicles,which can save lots of time and resources.Moreover,Luet al.[16] incorporate DT into IIoT to monitor the state information of the IoT system,which is able to overcome the obstacles of massive data and limited resources.Motivated by these works,applying DT in our work has huge potential to monitor the complex and dynamic status of machine or human,and then guide the massive content delivery.
2.2 Video Compression
Motivated by a variety of coding standards (e.g.,MPEG-4,H.264,etc.),existing compression methods for video analytics mainly attempt to remove temporal and spatial redundancies of video contents[20].In particular,some works are briefly reviewed as follows.
In terms of removing temporal redundancy,the most common and simple method is to extract key frames by decreasing frame rates(e.g.,from 60fps to 15 fps)and setting fixed frame sampling intervals [21,22].For example,Jianget al.[21]compress video contents via adaptive frame selection according to different application scenarios such as stationary parking lots or non-stationary streets.Moreover,recent advances in artificial intelligence technologies enable researchers to employ DNNs for key frame extraction[23,24].Typically,Moet al.[23] employ deep reinforcement learning to classify key frames from motion capture sequences.Briefly speaking,despite various efforts from these methods,there still exists a tradeoff between key frames missing and long encoding latency.
In terms of removing spatial redundancy,most of related works focus on lowering the resolution (e.g.,from 4K to 360P) and searching the region of interest (ROI) via region proposal,which are able to discard the irrelevant regions within each video frame[25,26].In particular,Sunet al.[25] propose a device-edge collaborative framework for live video analytics,which aims to locate and deliver the ROI contents to the edge for improving transmission efficiency.Although these methods achieve efficient video compression for human perception,they perform high-quality encoding for each macroblock of ROI,which is still redundant for machine decisionmaking.
In contrast to the existing works on temporal and spatial compression for video analytics,our work extends them along two significant aspects.In terms of temporal compression,by leveraging lightweight binary classification networks,we can avoid missing key frames in an efficient manner.In terms of spatial compression,under the premise of guaranteeing decisionmaking performance,we conduct the uneven quality assignment mechanism to further compress video contents.
2.3 Video Enhancement
The video enhancement has attracted extensive research in recent years,which can be broadly categorized as two classes,i.e.,intra-modal video enhancement and inter-modal video enhancement.
The core idea of the first one lies in taking full advantage of the correlations at the pixel level within the video for enhancement.In particular,DNNs-based approaches have been widely applied to such the task[27,28].For example,Donget al.[27] put forward the fast super-resolution CNN to map low-resolution visual signals to high-resolution ones.In spite of superior performance for these approaches based on video itself,they have the potential to further strengthen the visual quality with the aid of heterogeneous streams(e.g.,haptic stream).
The second one is to exploit the semantic correlations of heterogeneous streams for video enhancement [5,29].Typically,Weiet al.[29] propose a cross-modal video reconstruction proposal with the assistance of corresponding haptic streams,where its performance significantly outperforms other competing approaches in terms of Peak Signal-to-Noise Ratio(PSNR)and Mean Absolute Error(MAE).Despite achieving some progress,they still cannot figure out the fundamental mechanism of how haptic streams strengthen video streams,which is beneficial to realize further video enhancement.
Compared with the above relevant studies regarding video enhancement,we broaden them in the following aspect.In particular,besides video signals,we explore the correlation mechanism between heterogeneous signals,and then make full use of interpretable prior knowledge of haptic signals,e.g.,physical properties,to significantly improve video quality.
III.DTEN-ENABLED MASSIVE CONTENT DELIVERY FRAMEWORK
In this section,we introduce the DTEN-enabled massive content delivery framework.In particular,as depicted in figure 2,it is composed of three key components including physical entities,virtual twins,and bidirectional data transmission between physical entities and virtual twins[15].
3.1 Physical Entities
Here,physical entities represent various elements of the general content delivery framework in real world,which mainly covers source encoder/decoder,edge network,channel encoder/decoder,and wireless channel.Specifically,the source encoder is responsible to reduce the statistical redundancies of source signals for subsequent efficient transmission.Conversely,by introducing error correction information,the channel encoder is employed to increase its robustness to the noise from the wireless channel.It is noted that edge networks can offer powerful computation,communication,and storage capabilities to compress and recover multimedia contents at the source encoder and source decoder,respectively[30].
3.2 Virtual Twins
The DT accurately maps the above physical entities and their corresponding status in physical world to the virtual twins,which aim to simulate the quality evaluation metrics in this paper.In particular,we consider two categories of DTs in figure 2,i.e.,DT of the edge network and DT of the entire content delivery framework.On the one hand,the former category is a digital replica of the edge network,which continuously interacts with the physical edge network to update its status.Note that such a DT can provide computation capabilities to the encoder and the decoder,meanwhile,it can also store massive data from physical entities.On the other hand,the latter category is employed to simulate complex content delivery procedure,where such a DT can finally obtain real-time QoD or QoE at the decoder.As a result,in terms of machine-centric communication,the virtual twins will generate the QoD to guide the video encoding in physical entities,which is able to fully compress video streams for efficient delivery.Similarly,in terms of user-centric communication,QoE can be obtained from virtual twins for the guidance of video decoding,which devotes to enhancing video signals for high data fidelity.
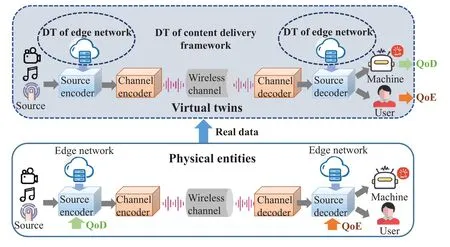
Figure 2.DTEN-enabled massive content delivery framework.

Table 1.QoE vs.QoD.
3.3 Bidirectional Data Transmission
This component is responsible for exchanging data and information between physical entities and virtual twins.As mentioned before,the real data of physical entities is sent to the virtual twins for simulation,and quality evaluation metrics are returned to physical entities.Note that in this part,we also put emphasis on differentiating QoE and QoD (Please see Table 1)[12,31].
IV.CASE 1: QOD-DRIVEN VIDEO COMPRESSION FOR VIDEO ANALYTICS
In recent years,with the advances in artificial intelligence (AI) and IoT,machine-centric applications(e.g.,intelligent transport,smart manufacturing) will no longer need humans to monitor and operate.In terms of such a type of application scenario,we take video analytics as a use case to study the content delivery strategy.
4.1 Design Principle
Recall that the key point of video compression for video analytics lies in reducing its spatio-temporal statistical redundancies.Compared with the existing video compression methods reviewed in Section 2.2,our designed encoding mechanism has the following two highlights.
On the one hand,instead of setting fixed frame sampling intervals for temporal compression,our goal is to avoid missing any key frame containing objects to ensure the performance of machine decision-making.To this end,one natural idea lies in adopting computationintensive DNNs to perform object detection for each frame [32].However,if applying such an idea,the core difficulty becomes how to achieve low processing latency under the limited computation resources of local devices[33].To get over this dilemma,we transform the complex object detection to the simple binary classification(i.e.,with/without the object in each frame),which can be implemented via lightweight and cheap DNNs.
On the other hand,although ROI high-quality encoding can filter out useless spatial regions for human perception,this approach still has huge compression space for machine decision-making.Specifically,the goal of this part is to preserve and stream necessary regions of each key frame to guarantee decision-making performance.In other words,we only need to assign high encoding quality to regions in ROI that have significant influences on the decision-making performance [34].From the technical perspective,the key challenge lies in how to measure the influence degrees of each region.Benefiting from real-time QoD feedback from virtual twins,one feasible solution is to compute the similarity between QoD of the encoded frame after quality assignment and that of the same frame encoded with high quality.Note that the higher similarity denotes the better compression performance.
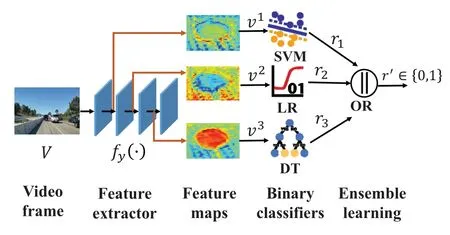
Figure 3.Architecture for lightweight frame classification.
4.2 Lightweight Frame Classification for Temporal Compression
In this part,we devote to accurately and efficiently extracting key frames containing objects based on DNNs for video temporal compression.In particular,the architecture for lightweight frame classification is depicted in figure 3.Technically,we firstly employ cheap DNNs for feature extraction of each frame,and then choose intermediate features generated from some layers of these DNNs.Subsequently,various intermediate features are inputted to the lightweight binary classifiers (e.g.,SVM,Decision Tree,etc.) to independently test if containing the object.Finally,in order to avoid missing key frames,we process the result of each base learner in parallel via the bagging of the ensemble learning,where this frame is judged without objects only if all classifiers output the results without objects.Overall,the detailed steps are shown in the following.
Step 1:We choose YOLOv5 as the cheap DNNs for feature extraction,and its backbone neural networks are shown in[35].LetVdenote the video frame,and the feature extraction process can be expressed as
wherefy(·) denotes YOLOv5,θydenotes the corresponding model parameters,andvrepresents the video features.
Step 2:In terms of the YOLOv5 network structure,diverse activations among them are widely considered as appropriate splits to produce intermediate features[36].To this end,we select the outputs of three SiLU as the feature maps [37],which are denoted byvc={v1,v2,v3},respectively.
Step 3:The extracted intermediate features are sent to various lightweight binary classifiers (i.e.,SVM,Decision Tree,and Logistic Regression) for frame classification,respectively.That is,
wherefc(·)denotes various classifiers,θcdenotes their corresponding model parameters,rc ∈{0,1} is the classification result.In particular,0 denotes that there contains no object in this frame and vice versa.
Step 4:We utilize the bagging of the ensemble learning to comprehensively evaluate the classification results,that is,
wherer′denotes the final classification result for this video frame,andORis the logic or.
4.3 Quality Assignment for Spatial Compression
Intuitively,the regions/macroblocks at each key frame,which have significant influences on the performance of machine decision-making,should be encoded with high quality.Following this guideline,the spatial compression workflow is illustrated in figure 4.Briefly speaking,when the key frame extracted from the above subsection arrives,the designed quality assignment mechanism decides that each region in this frame should be encoded with high quality or low quality,to obtain the spatially compressed frame.Then,a video codec(e.g.,HEVC,H.264)is implemented before streaming content.The detailed procedure and analysis are given in the following.
First,the fundamental problem to be resolved is how to optimally assign encoding quality to each key frame.Recall that we plan to employ QoD similarity as the criteria to quantitatively measure the influence degrees of each region on machine decision-making.Mathematically,this optimization problem is defined as follows,
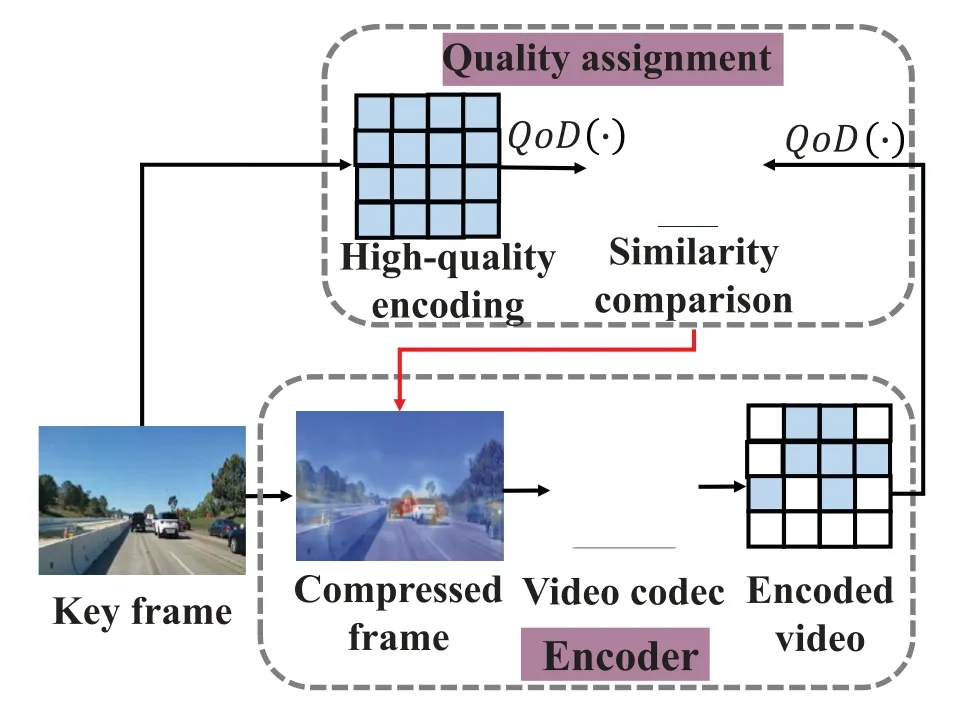
Figure 4.Workflow of spatial compression at the encoder.
whereSim(·)denotes the similarity of QoD between two different encoding contexts,Q(·) denotes QoD,andHdenotes the key frame with high-quality encoding.In particular,C=W×H+(1−W)×Ldenotes the same key frame encoded by the designed quality assignment mechanism,wherewi=1 denotes highquality encoding for regioni,Lis the key frame with low-quality encoding,and×denotes the element-wise product.
Next,motivated by[34],we further derive the optimal solution to the quality assignment.Specifically,maximizingSim(Q(C);Q(H)) is equivalent to the following derivation,
where∂(·) denotes the derivative, ||· || denotes the norm,(a) and (b) are based on Lagrange Theorem,C ≤C′ ≤H,and(c)is based on the definition ofC.Letinfluencei=denotes the influence degrees of regionion machine decision-making.Consequently,the optimal solution to quality assignment is wheninfluencei > ξ,we encode the regioniwith high quality and vice versa,whereξis a threshold constant.
Finally,we discuss the offline training procedure of the quality assignment mechanism.Note that this mechanism is deployed and trained at the edge network,which can offer powerful computation resources for DNNs-based feature extractors.Moreover,benefiting from the DT,QoD can be accurately simulated from virtual twins,which also contributes to computing the influence degrees in real time.
V.CASE 2: SEMANTIC-AIDED VIDEO ENHANCEMENT FOR QOE IMPROVEMENT
The above section has introduced a content delivery strategy in terms of machine-centric multimedia applications,which take video surveillance as a case study.Besides,it is well known that the human-perception quality is also critical to some user-centric multimedia applications.Thus,as another typical case study,we develop a QoE-driven video enhancement scheme for remote material touching in this section.
In particular,the highlights of this scheme lie in two significant aspects.On the one hand,besides the video feature itself,it makes full use of haptic features to assist video signal reconstruction.On the other hand,we analyze and extract physical properties of massive haptic signals stored in the edge,which can supplement the prior knowledge to further enhance video signals at the decoder.Figure 5 depicts the video enhancement framework that is composed of three modules,including haptic physical properties extraction in the edge,video feature enhancement via fusion network,and feature-signal mapping via generation network.
5.1 Haptic Physical Properties Extraction
Compared with existing black-box models on extracting haptic features,we attempt to explore interpretable prior knowledge of haptic signals to assist video enhancement.For example,surface texture information from robotic grasping can benefit fine-grained video signal reconstruction [29].Generally speaking,the sense of touch is equipped with five primary physical properties,i.e.,friction,compliance,adhesion,texture,and thermal conductances[38].
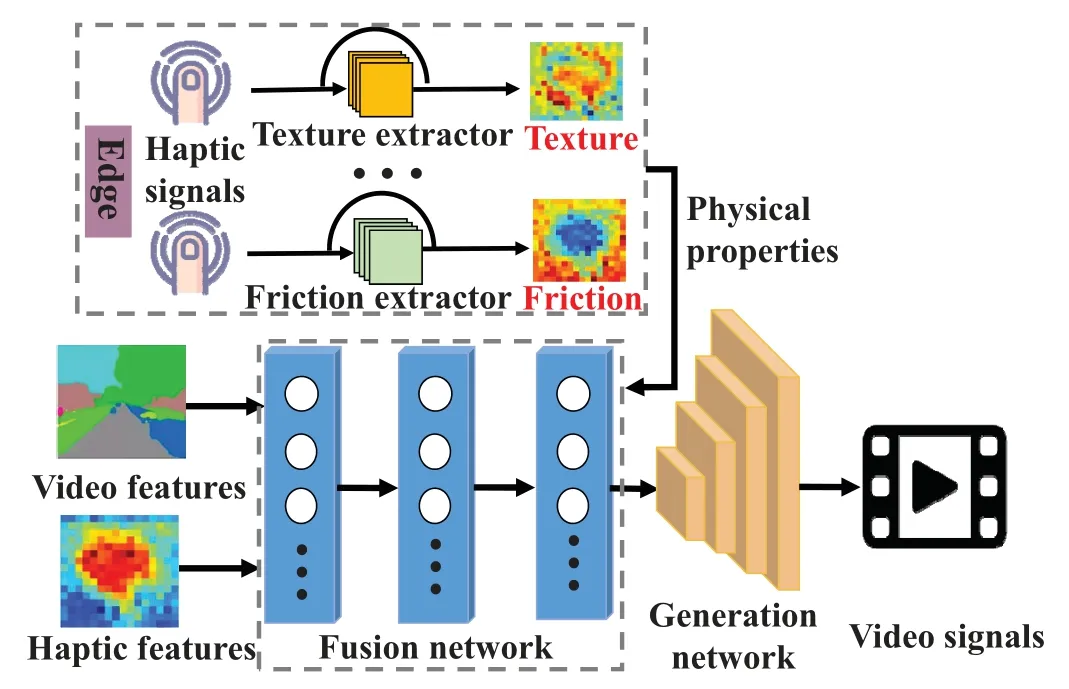
Figure 5.Semantic-aided video enhancement framework.
Based on the above analysis,we aim to extract physical properties from massive haptic signals stored at the edge.On the technical side,we exploit an efficient auto-encoder,which consists of an encoder and a decoder,to accomplish such a goal.For simplicity,we take the design of texture extractor as an example to introduce the technical details.Specifically,according to the label of transmitted video and haptic streams,we firstly retrieval the haptic signals with the same label in the edge.Then,we extract the texture features of these haptic signals via the encoder,i.e.,
In terms ofLseman,that is,
wherefsoft(·) denotes the softmax function,θsoftis the model parameter,andltdenotes the corresponding labeled category.In particular,fsoft(·)can be denoted as,
where I{·} denotes the indicator function,and the(x,l;θ)is the softmax probability distribution.
TheLreconcan be denoted as,
where||·||22denotes theL2-norm,θa=[θe,θd]consist of model parameters of encoder and decoder,anddenotes the recovered haptic signal via the decoder.In particular,can be obtained in the following,
wherefd(·)denotes the decoder.
In summary,the loss functionsLaof auto-encoder for texture extraction can be denoted as follows to optimize a series of model parameters via the popular gradient descent method,i.e.,
whereβdenotes the hyper-parameter to balance two different loss functions.
5.2 Video Feature Enhancement
After extracting physical properties from massive haptic signals in the edge,this part is responsible to enhance the video feature,which is supported by semantic correlations of heterogeneous signals.Specifically,enhanced video features are generated by the comprehensive fusion of transmitted video and haptic features,as well as haptic physical properties from the edge.Technically,these three types of features are inputted to the fusion network,i.e.,
wherev′denotes the enhanced video feature,fg(·)denotes the fusion network with the model parameterθg,denote five physical propert ies,vandhdenote the transmitted video features and haptic features,respectively.
Similar to haptic physical properties extraction,we employ the semantic discriminative loss functionLfto optimizeθg.Specifically,the label ofv′should be consistent with that ofvandh.In particular,we defineLfin the following,
wherelvdenotes the common label of transmitted video and haptic features.
5.3 Feature-Signal Mapping
Finally,we utilize the generation network to map the enhanced video features to video signals.In particular,due to the robust generative and discriminative performances,we choose Generative Adversarial Nets(GANs)as the generation network.
Specifically,GANs consist of a generatorGand discriminatorD,where the former one converts the feature to the signal and the latter one distinguishes the real signal from the generated signal.Therefore,the above loss functionLDcan be defined as follows,
Moreover,we also consider theL2-norm loss between generated video signals and real video signals,i.e.,
Overall,the loss functions can be expressed in the following,
whereγis the hyper-parameter to balance various loss functions.
VI.NUMERICAL RESULTS AND ANALYSIS
In this section,we present the numerical results and analysis to comprehensively examine the performance of various content delivery strategies.Specifically,we firstly introduce the experimental setup of two typical cases,i.e.,video analytics in smart city and remote material touching in IIoT.Then,we exhibit and analyze the corresponding results of designed encoding and decoding strategies,respectively.
6.1 Experimental Setup
On the one hand,we perform object detection to test the spatio-temporal compression performance of the designed encoding mechanism.In particular,the dataset contains 956 video frames (including 496 key frames with objects),which was collected from YouTube via searching keywords such as highway,dashcam.Specifically,this encoding mechanism is deployed at the local cheap laptop (with 8GB memory)while the object detection is performed based on YOLO at the remote server(with 12GB VRAM).The batch size of the YOLO is set as 16,and its optimizer is Adam.In terms of compared approaches,we choose two lightweight DNNs (i.e.,MobileNet-SSD and YOLO) as baselines to evaluate temporal compression performance.Besides,two baselines are employed to verify the superior performance of spatial compression: i)ROI encoding(ROIE),and ii)deviceedge collaboration (DEC) [39].In particular,ROIE assigns uniform quality to the regions whereas DEC communicates the feature data via lossy compression between device and edge to reduce spatial redundancy.On the other hand,we adopt the established Vis-Touch surface material database as the dataset to show the performance of the proposed decoding scheme.In particular,it contains various common categories of surface materials (e.g.,slate,wood,linen,etc.) with their audio,video,and haptic signals,which were collected from our constructed cross-modal communication platform for remote material touching1.Moreover,to draw a comprehensive observation in this context,the proposed decoding scheme is compared with two classical signal reconstruction schemes: i) intramodal reconstruction (INTRA) [40],and ii) intermodal reconstruction (INTER) [29].It is noted that the difference between INTER and the proposed decoding scheme in this work lies in if considering the haptic physical properties extracted from the database.
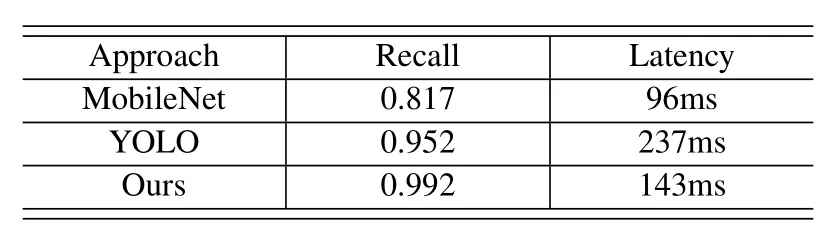
Table 2.Performance comparison for temporal compression.
6.2 Performance of QoD-Driven Encoding Mechanism
First,we investigate the effectiveness and efficiency of frame filtering for temporal compression in terms of Recall and processing latency.In particular,Recall is employed to measure the classification accuracy of the key frame that contains objects,where higher Recall denotes better classification performance.Given the numerical results from multiple times of experiments,Table 2 demonstrates that the proposed frame classification is expected to effectively avoid missing key frame,which will ensure the performance of machine decision-making.Meanwhile,due to the adoption of cheap machine learning models,our approach can also achieve higher encoding efficiency than YOLO.Note that although MobileNet may outperform the other two approaches in terms of encoding efficiency,it is very likely to miss the key video frames,which is intolerable for machine decision-making[12,21].
Next,we evaluate the performance of spatial compression in terms of decision-making(i.e.,confidence score),delivered content (i.e.,data amount),and encoding latency.On the one hand,figure 6 depicts the conflicting performance metrics of confidence score and data amount on four key frames by three encoding schemes.The caption of each sub-figure gives the original data amount.From this figure,we clearly observe that compared with the other two schemes,the proposed scheme can achieve a balance between these two core metrics.Specifically,in contrast to ROIE with uniform quality,ours can further reduce data amount via uneven quality assignment under the premise of ensuring machine decision-making.Moreover,since DEC performs lossy compression for feature data,it inevitably impacts the decision quality.On the other hand,we also measure the encoding latency for these schemes.Given the experimental results in Table 3,the proposed scheme integrating DT can obtain the best encoding efficiency among them.This is because the DT technology is able to provide realtime QoD feedback,which is beneficial to save more encoding time.
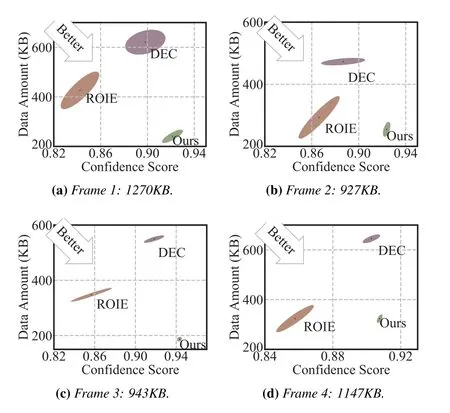
Figure 6.Confidence score vs.data amount among different spatial compression methods.

Table 3.Average encoding latency for different spatial compression methods.
6.3 Performance of QoE-Driven Decoding Scheme
Subsequently,we conduct qualitative analysis to compare the decoding performance of the proposed scheme with the other competing schemes.Intuitively,figure 7 exhibits four material categories of reconstructed/enhanced signals at the decoder.From these results,it can be found that the reconstructed material signals via INTER and ours,which are based on semantic correlations,are more similar to the original signals than those of INTRA.More importantly,some material details (e.g.,texture,light) of the proposed scheme can be clearly observed due to the incorporation of various haptic physical properties.

Figure 7.Qualitative analysis of various decoding schemes.
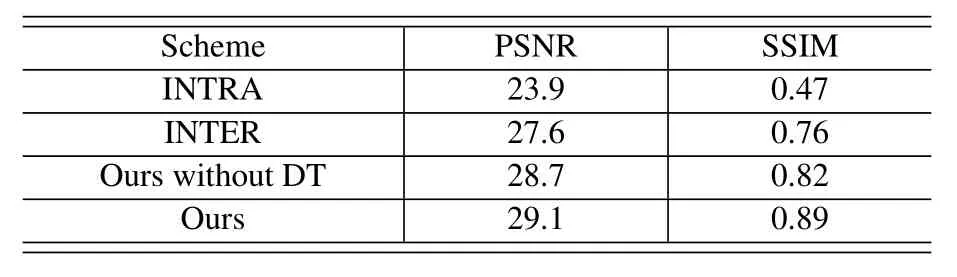
Table 4.Quantitative comparison among various decoding schemes.
Finally,we also perform a quantitative comparison in terms of PSNR and Structural Similarity (SSIM),where the higher values mean better performance.Since DT is capable of obtaining precise QoE,the numerical results in Table 4 demonstrate that the proposed scheme outperforms the others on these two metrics,which are consistent with the above qualitative analysis.
VII.CONCLUSION
In this paper,we study quality-aware massive content delivery with the assistance of DTEN.Specifically,we firstly propose a DTEN-enabled content delivery framework to acquire precise and real-time QoD or QoE,which is capable of guiding the design of transmission strategies for various multimedia applications.Next,we design a QoD-driven encoding mechanism for machine-centric communication (e.g.,video analytics)through frame classification and quality assignment,which can effectively reduce spatio-temporal redundancies under the premise of ensuring machine decision-making performance.Finally,in terms of user-centric communication,by taking full advantage of haptic physical properties and semantic correlations of heterogeneous streams,a video enhancement scheme is developed for human-perception quality improvement.
For future works,we plan to further consider the potential deviation between physical entities and virtual twins of the proposed framework from the technical perspective.On the application side,this framework is expected to be applied to some practical scenarios (e.g.,traffic management,industrial manufacturing,etc.).
ACKNOWLEDGEMENT
This work is partly supported by the National Natural Science Foundation of China (Grants No.62231017 and No.62071254) and the Priority Academic Program Development of Jiangsu Higher Education Institutions.
NOTES
1http://8.133.175.194

- China Communications的其它文章
- Edge-Coordinated Energy-Efficient Video Analytics for Digital Twin in 6G
- Unpredictability of Digital Twin for Connected Vehicles
- Endogenous Security-Aware Resource Management for Digital Twin and 6G Edge Intelligence Integrated Smart Park
- Digital Twin-Assisted Knowledge Distillation Framework for Heterogeneous Federated Learning
- Design and Implementation of Secure and Reliable Information Interaction Architecture for Digital Twins
- A Golden Decade of Polar Codes: From Basic Principle to 5G Applications