
Edge-Coordinated Energy-Efficient Video Analytics for Digital Twin in 6G
2023-03-12 12:01PengYangJiaweiHouLiYuWenxiongChenYeWu
China Communications 2023年2期
Peng Yang,Jiawei Hou,Li Yu,Wenxiong Chen,Ye Wu
1 School of Electronic Information and Communications,Huazhong University of Science and Technology,Wuhan,Hubei 430074,China
2 College of Information Science and Engineering,Hunan Normal University,Changsha,Hunan 410081,China
3 School of Advanced Technology,Xi’an Jiaotong-Liverpool University,Suzhou,Jiangsu 215123,China
Abstract: Camera networks are essential to constructing fast and accurate mapping between virtual and physical space for digital twin.In this paper,with the aim of developing energy-efficient digital twin in 6G,we investigate real-time video analytics based on cameras mounted on mobile devices with edge coordination.This problem is challenging because 1)mobile devices are with limited battery life and lightweight computation capability,and 2) the captured video frames of mobile devices are continuous changing,which makes the corresponding tasks arrival uncertain.To achieve energy-efficient video analytics in digital twin,by taking energy consumption,analytics accuracy,and latency into consideration,we formulate a deep reinforcement learning based mobile device and edge coordination video analytics framework,which can utilized digital twin models to achieve joint offloading decision and configuration selection.The edge nodes help to collect the information on network topology and task arrival.Extensive simulation results demonstrate that our proposed framework outperforms the benchmarks on accuracy improvement and energy and latency reduction.
Keywordst: mobile edge computing; video analytics;digital twin;6G;deep reinforcement learning
I.INTRODUCTION
With the rapid development and deployment of 5G communication technologies,scholars have begun to focus on the concept of 6G and its applications[1].As one of the key enabling technology towards 6G,digital twin establishes an accurate mapping between the virtual and physical world.It is expected that in the era of 6G,various types of Internet of Things (IoT)devices will be deployed to capture environmental information and update to the digital twin in real-time[2—4].Among other,video cameras installed on mobile devices(MDs),such as augmented reality glasses,autonomous vehicles,etc.,prevail due to their ability of capturing rich environment information at low costs[5].Generally,cameras capture video frames and generate massive video data,which will be delivered and processed for various digital-twin enabled applications,such as remote surgery,autonomous driving,smart industry [6—8],etc.To serve these purposes,analyzing the video frames for accurate and fast construction and synchronization of digital twin in an efficient manner becomes vital.
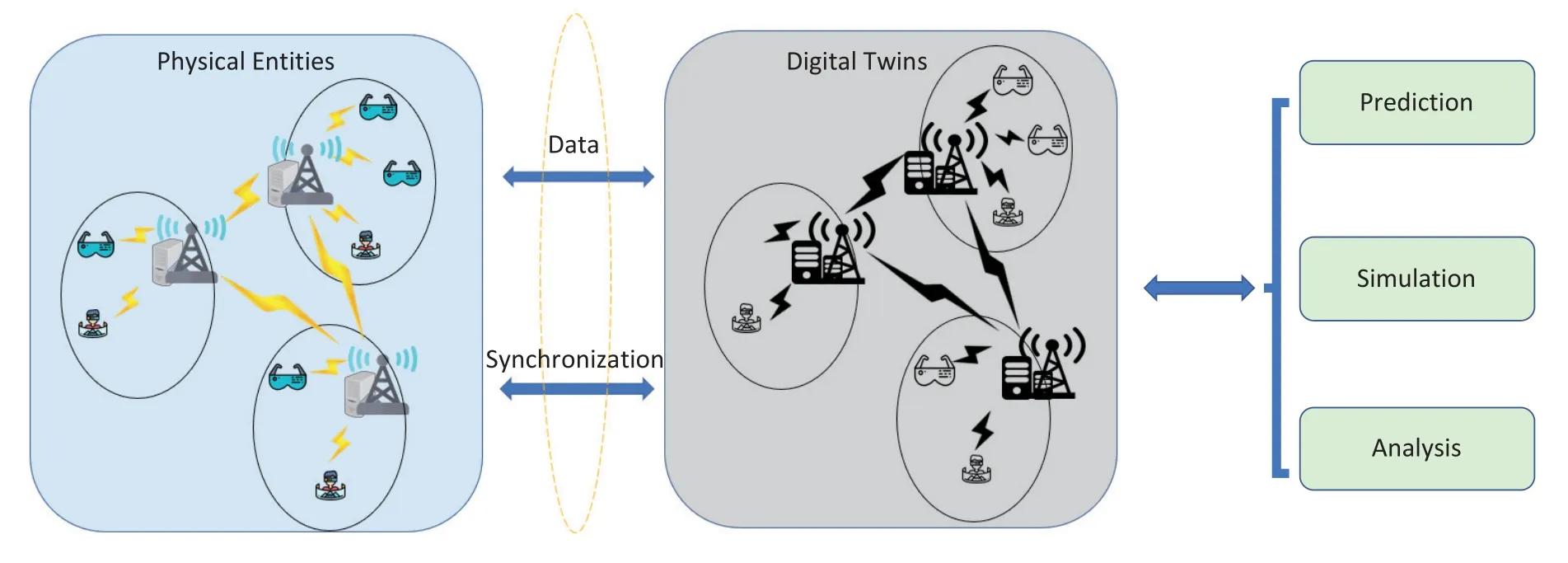
Figure 1.An illustration of digital twin in 6G networks.
Some of the high-end MDs are with highperformance central/graphics processing unit(CPU/GPU).They are capable of capturing highquality video frames and performing typical video analytics tasks using deep neural networks (DNNs),such as object detection,object classification,etc.The results of which are building blocks of the subsequent formation of digital twin.However,most of the off-the-shelf MDs are with constrained computing and storage capacity,which are insufficient to support computation-intensive DNNs.Most importantly,the battery capacity are not even comparable to the magnitude of the computation load and the data volume of video frames.For instance,Hololens 2,which is a popular mixed reality device released in 2019,can only support a maximum of two-hour standby time,which is far from meeting the requirement of constructing and maintaining digital twin.Consequently,it poses great challenges for performing video analytics tasks solely relying on the MDs system,in order to achieve accurate construction of digital twin,considering the limited capacity of most MDs and the high computation burden of processing the large-volume of video data.
Due to the large amount of MDs,their generated massive data places heavy burden on computation and communication resources [9].In this case,mobile edge computing (MEC) emerges as a new paradigm to augment the capacity of MDs.By deploying computing resource in the vicinity of MDs,the MEC can be promising to support the stringent delay and accuracy of large-scale video analytics [10].While MEC provides with a solution for large-scale video analytics,it fails to meet the requirement of delay-sensitive video analytics on MDs since the task arrival is uncertain and environment information is dynamic,which are difficult to predict.Consequently,it leads to the paradigm of digital twin,which enables the transformation from physical objects to virtual models.By this digital transformation,the virtual model can collect the state of its physical entities through sensing data.As shown in Figure 1,by collecting real-time information from its connected physical entities via camera sensors,the digital twin model can receive task arrival,interact with the environment and make decisions from a global perspective.Our main contributions in this paper are summarized as follows:
・ We investigate a 6G-enabled digital twin scenario,where MDs provide their virtual entities with state information via cameras mounted on mobile devices.
・ We discuss the relationship between video quality configuration and energy consumption,accuracy,respectively.Based on the relationship,we formulate an optimization problem that boils down to simultaneous configuring the video quality and offloading to the edge.
・ To solve this joint offloading and configuration selection problem,we propose a multi-agent deterministic policy gradient (MADDPG) learning approach,which regards each MD as an agent.The performance of the learning-based solution is evaluated via extensive experiments.
The remainder of this paper is organized as follows.Section II introduces the related work,followed by system model and problem analysis in Section III and Section IV.The simulation results are presented in Section V,followed by the conclusion and future work in Section VI.
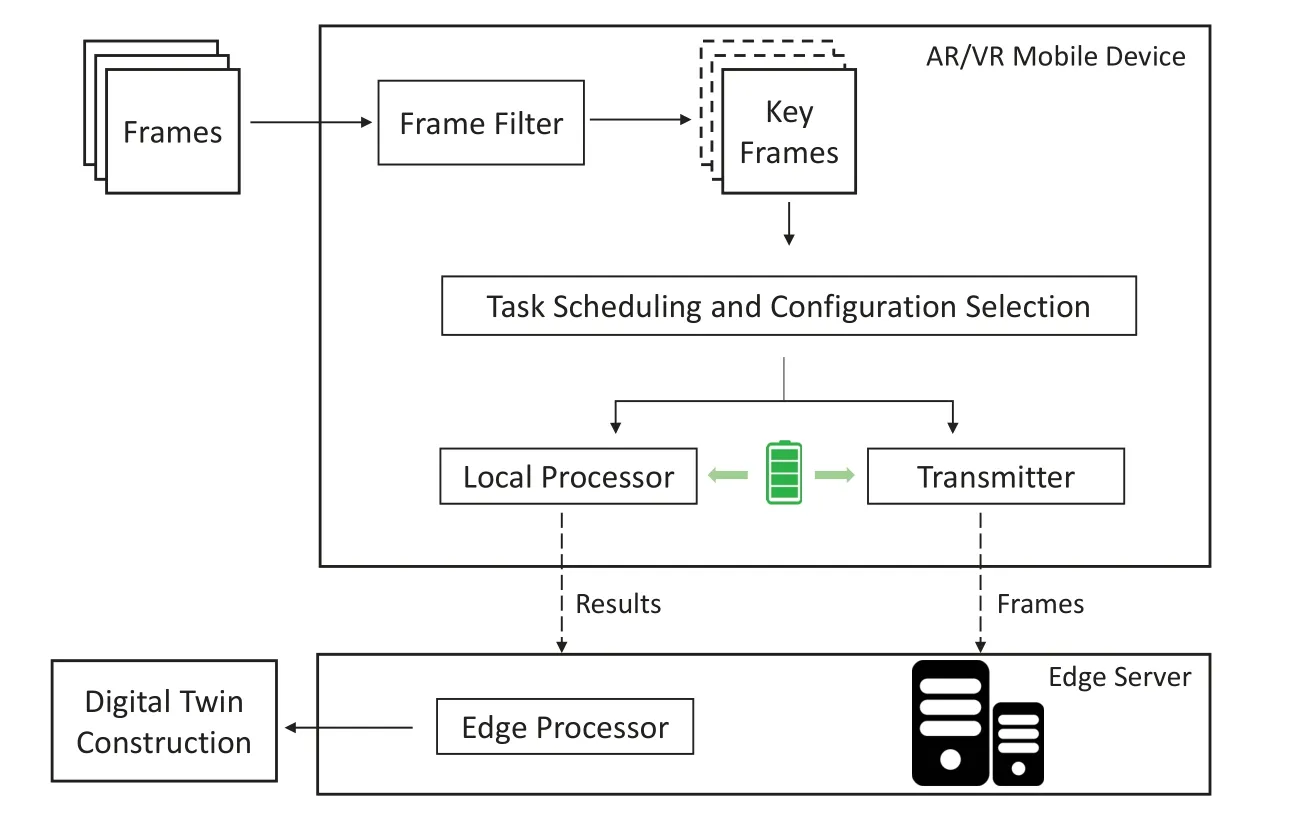
Figure 2.An overview of the proposed framework.
II.RELATED WORKS
In this section,we provide an overview on relevant research background.
2.1 MEC-Assisted Video Analytics
MEC-assisted video analytics has been extensively studied by conventional wisdom [11].Intuitively,videos should be processed with low-latency and highaccuracy.To serve this purpose,Jianget al.proposed Chameleon,which adjusts several knobs for each video analytics task by sharing the best top-k configuration [12].The work of Chameleon is based on the assumption that videos have spacial correlations have overlapping in their best configurations.Ranet al.further formulate the video knob-tunning problem as a multiple-choice knapsack problem and solve it with a heuristic search method [13].To respond to video queries with low latency at the edge,a dynamic edge configuration algorithm is developed by Yanget al.[14].which adjusts the quality of generated video frames at the end cameras,as well as the allocated edge resources for each video query.
Although video analytics has attracted much attention recently,there are few works focus on video analytics on MDs with inherent properties of limitedenergy.Wanget al.designed an efficient online algorithm named JCAB[15],which can select appropriate configurations for multiple video streams according to video content.However,it does not consider that in practical,video analytics tasks arrive asynchronously and the heterogeneity of different task’s best configuration.
2.2 Digital Twin Enabled 6G
The concept of digital twin is first proposed by [16]and been applied in NASA flight maintenance and fault diagnosis.It can bridge the gap between physical entities and virtual world.As one of the most distinguished application of 6G,digital twin has been extensively studied for improving the performance of MEC systems [17—19].Daiet al.proposed a digital twin network architecture for industry internet of things,which uses digital twin to assist computation offloading and resource allocation[17].Sunet al.used digital twin to perceive the MEC environment and considered minimizing mobile offloading latency under the constraint of accumulated migration cost [18].Luet al.formulated the edge association problem with respect to the dynamic network states and network topology to construct and maintain digital twins in the wireless digital twin network[19].Different from those works,we focus on the video analytics of camera-mounted MDs,considering its advantage of providing sufficient physical information at low cost for the virtual entity.
III.SYSTEM MODEL AND PROBLEM FORMULATION
In this section,we first introduce the construction of digital twin via video analytics relying on cameras mounted on mobile devices.Then,we elaborate the energy model and latency model.Finally,we formulate optimization problems to address the jointly offloading and configuration selection problem.Important notations used in this paper are listed in Table 1.
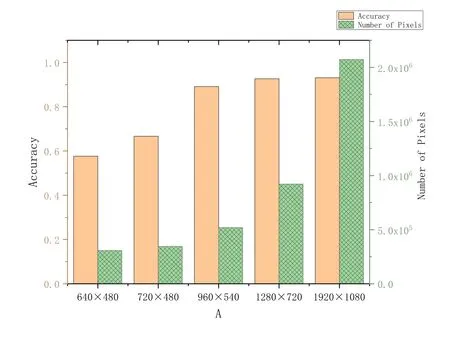
Figure 3.Impact of image quality on the accuracy of objection detection accuracy and energy consumption.
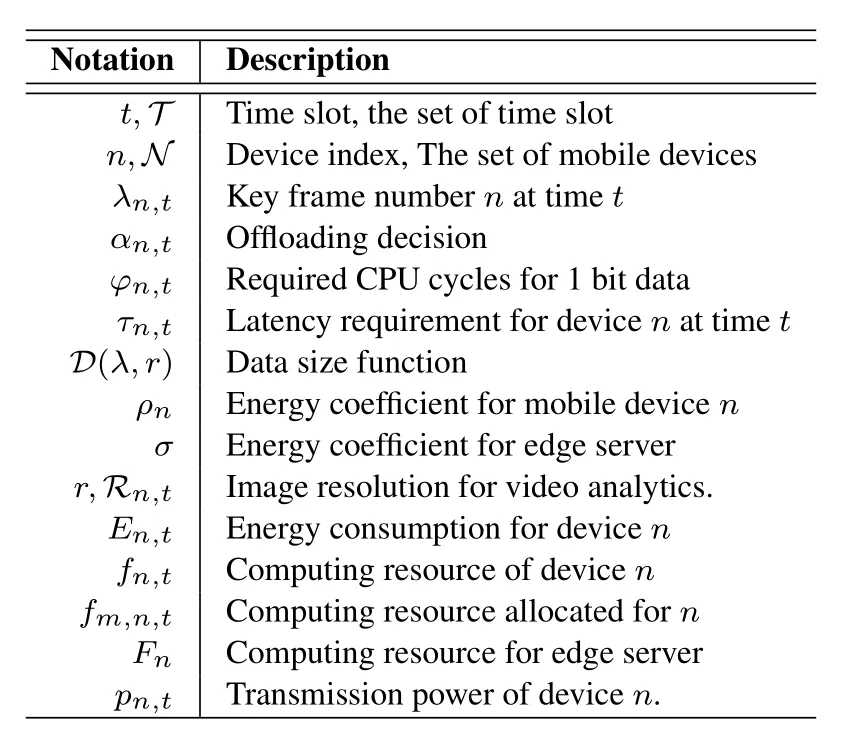
Table 1.Summary of notations.
3.1 Video Analytics Assisted Digital Twin Construction
In this work,we consider a discrete system which equally divides time into a sequence of slotsT={1,...,T}.In each time slott ∈T,the edge server utilizes cameras mounted on mobile devices to perceive the environment.As shown in Figure 2,video analytic tasks(such as object detection and semantic segmentation)are conducted on key frames to provide the edge server with digital twin construction information.Specifically,the task scheduling and configuration selection will have an influence on latency and accuracy,which will be discussed later.
3.1.1 Mobile Devices
Consider a scenario with a set,N={1,...,N},ofNmobile devices,such as augmented reality (AR)glasses,mobile phones.In each time slott ∈T,those MDs keep capturing and identifying key video frames for further video analytics.Without loss of generality,we assume the computing capabilityfnof each devicen ∈Nis known in advance and may vary with devices.
3.1.2 Edge Nodes
Suppose there is a set,M={1,...,M},ofMedge nodes (ENs),each of which is with computing resourceFm,tin time slott.Typical deployment of ENs can be mobile base stations and WiFi access points,which enable the process of offloaded services from MDs.The MDs are assumed to be moving slowly,the distance between them and the ENs are assumed to be constant within one time slot.Consequently,task migration is not taken into consideration.
3.1.3 Video Analytic Task Model
Due to the mobility of MDs,in each time slott,there is a video analytic task tupleWn,t≜(λn,t,φn,t,τn,t)arrives at MDn ∈N.Here,λtnis the number of arrived key frames which can be obtained by cheap calculations.Inspired by previous work[20],φn,tdenotes the number of CPU/GPU cycles required for computing one-bit video data,which varies with tasks.τn,tdenotes the maximum end to end latency for this task,which is set in advance by the MD.It should be noted that,this task model is tailored for video analytics due to the following two-fold reasons.On one hand,frame filtering is the key to reduce video redundancy and has been extensively studied,such as Reducto[21]and FilterForward[22].On the other hand,changing image configuration not only influences storage and computation resource consumption,but also influences video analytic accuracy.
Intuitively,the accuracy of video analytics tasks are closely related to video quality,which is indicated by image resolutionrin this work.A higher resolution leads to higher video analytic accuracy,but also consumes higher energy and causes higher latency.Take YOLO [23],an object detection deep neural network(DNN)as example,we plot the breakdown of F1 score(accuracy),required computing pixel number (analogous to energy consumption)and resolution in Figure 3.We useϕn,t(r) to denote the accuracy function in terms of resolutionr,which is offline-trained in advance.
Given the maximum allowable end to end latencyτn,t,each MDn ∈Nmakes task offloading scheduling and configuration selection decision to achieve energy-efficient video analytics while maintaining accuracy performance.
3.2 Energy and Latency Model
In this work,we consider that video analytics tasks generated by MDs are processed either locally or on ENs.In each time slott ∈T,given taskwn,t,we use integerxn,m,t ∈{0,1},(m ∈0,...,M)to denote the processed location andrn,t ∈{r0,...,rk}to denote the selected video resolution.
3.2.1 Local Processing
Specifically,xn,t=0 indicates that the task is processed locally.Hence,the locally computing latency and energy consumption is given as follows.
It should be noted that theρnis a constant which measures the energy consumption for 1 unit of CPU/GPU cycles and only depends on the chip architecture.
3.2.2 Edge Processing
In the era of 6G,the multiplexing technology will potentially use smart OFDMA plus index modulation.On this bias,we assume that each EN can allocate multiple specific channels to corresponding MDs,hence we consider the inter-channel interference as wireless interference between a MD and its connected EN.Given the transmission powerPtnand channel gainHtnof all MDs,the wireless interference can be expressed as:
wheren′andm′denotes MDs and ENs exceptnandm.Whenxn,t=1,MDntransmits its task data to the chosen EN,where the task will be processed by allocated computing resourcefm,n,t ≤Ftm.There will be additional latency and energy consumption used for task up-link transmission and computing.Since the video analytics results are usually small in size,the down-link transmission latency and energy consumption is assumed to be negligible.In this case,the data up-link latency depends on the transmission rateCn,tbetween MDs and ENs.According to Shannon capacity,Cn,tcan be obtained by:
whereBn,tandN0denotes the bandwidth and noise power respectively.It should be noted that due to the network environment uncertainty and user mobility,btnandHtnis dynamic.The data up-link latency is express as follows:
Correspondingly,the transmission energy consumption is calculated by:
whereEtailis tail energy which is introduced due to the fact that MDs will hold the active work state for a while after transmission.This practice is widely adopted by wireless transmission industry for energy thrifty[24,25].Once transmitted to ENs,taskwwill be processed with computing latency:
Correspondingly,the energy consumption of edge server for assisting devicento process video analytics task at timetis expressed as:
Similar toρn,µedenotes energy consumption for processing 1 unit CPU/GPU cycles.Generally speaking,for MDn ∈Nat time slott ∈T,the video analytics inference time and local energy consumption can be expressed respectively as:
3.3 Problem Formulation
We aim to find the optimal policy to achieve high efficiency video analytics,where users make task offloading and video configuration selection decisions.For each devicen,this can be described as:
whereweandwaare weights of local energy consumption and video analytics accuracy,respectively.Constraint(11a)and(11b)say that at timet,the video analytics task can only be processed at one place.Constraint(11c)indicates the chosen resolution should be inR,which is set in advance.Constraint(11d)implies that the latency cannot exceed the maximum latency.
3.4 Problem Analysis and Transformation
The optimization problem ofP1is thorny due to the following reasons.
1.P1is a mixed integer nonlinear programming(MINLP)problem,which is NP-hard;
2.The optimal policy of each agent not only depends on its own strategy,but also depends on other agents’ behavior,the complexity arises from the greedy of each agent;
3.Offloading management and latency requirement are coupled,while offloading tasks to edge servers can reduce local energy consumption,it may incurs long latency due to the dynamic frame number and channel quality;
4.Configuration selection is coupled with video analytic accuracy,choosing a low video resolution reduces end to end latency but also decreases video analytic accuracy.
To overcome aforementioned difficulties,we transformP1 as a partially observable Markov game,which is a multi-agent Markov decision process.Each MDn ∈ Nis considered as an agent.At each time slot,the game can be described in the following steps: (1) By observing their own environmentO1,...,ON,agents make actionsa1,...,aNaccording to stochastic policyπθn.(2)Agents produce the next states according to the state transition function.(3)Agents obtain rewardsu1,...,uN.(4) According to next states,each agent receives their own next observationO′1,...,O′N.Intuitively,each agent aims to maximize its own rewardtherefore we turn to DRL to find optimal solutions for sequential decision making problems.To evaluate the performance of each MD’s action,we define the reward function as follows:
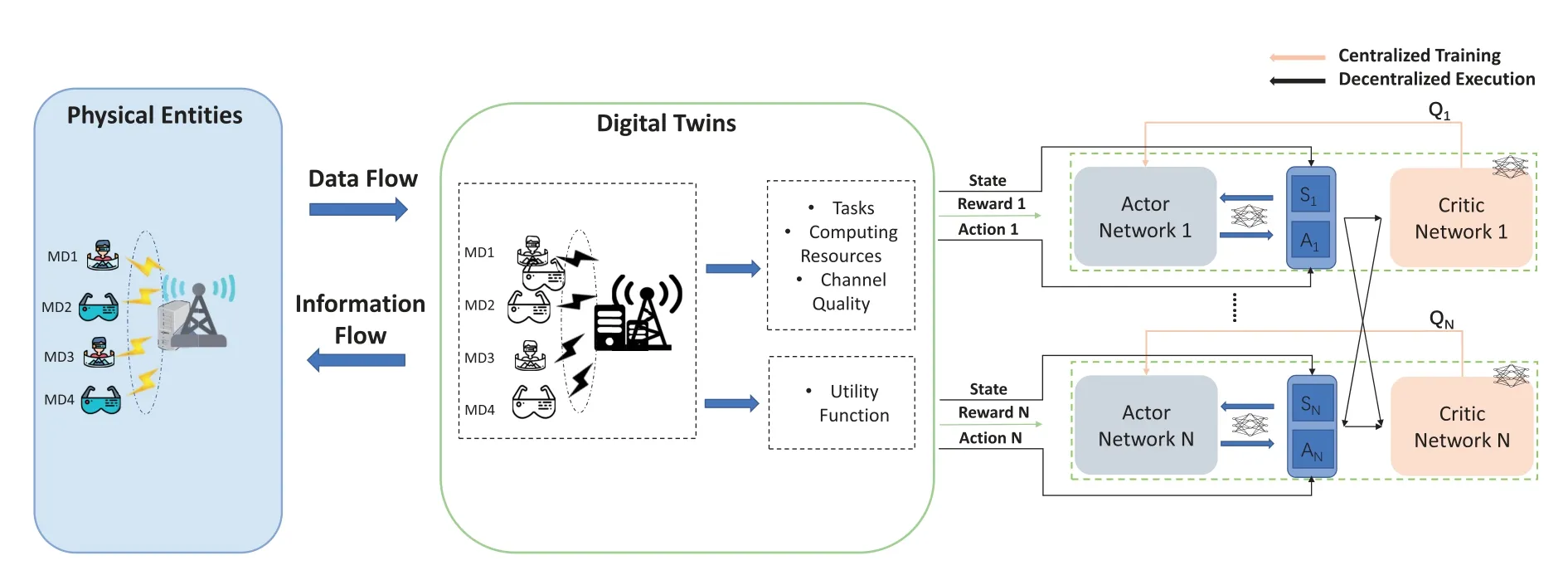
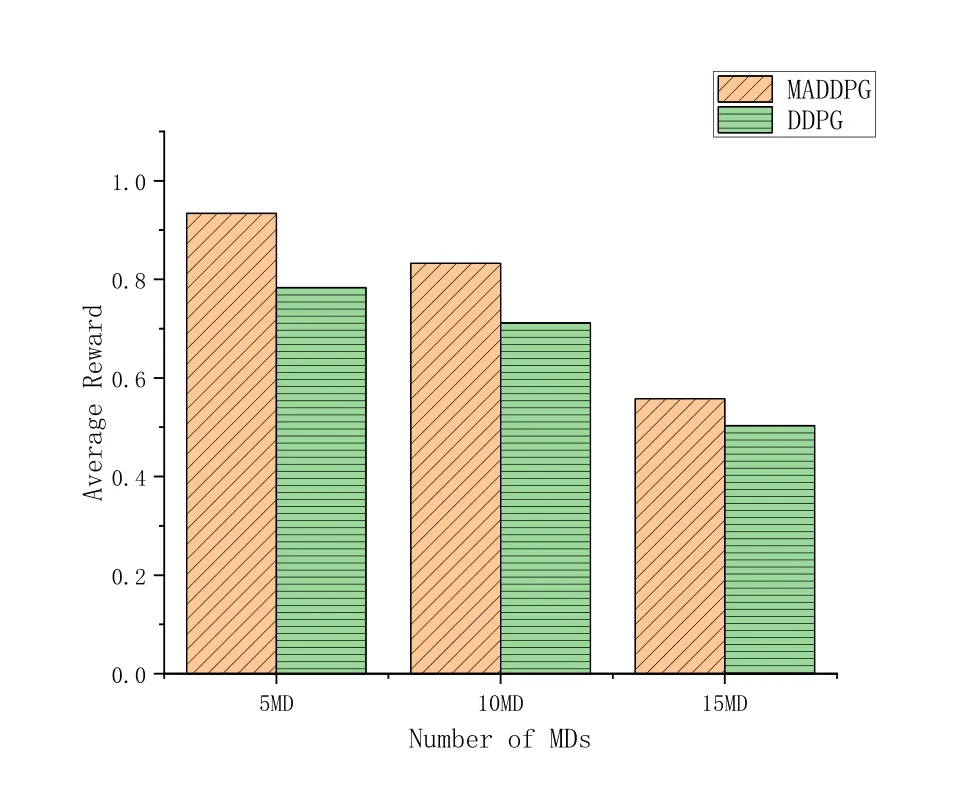
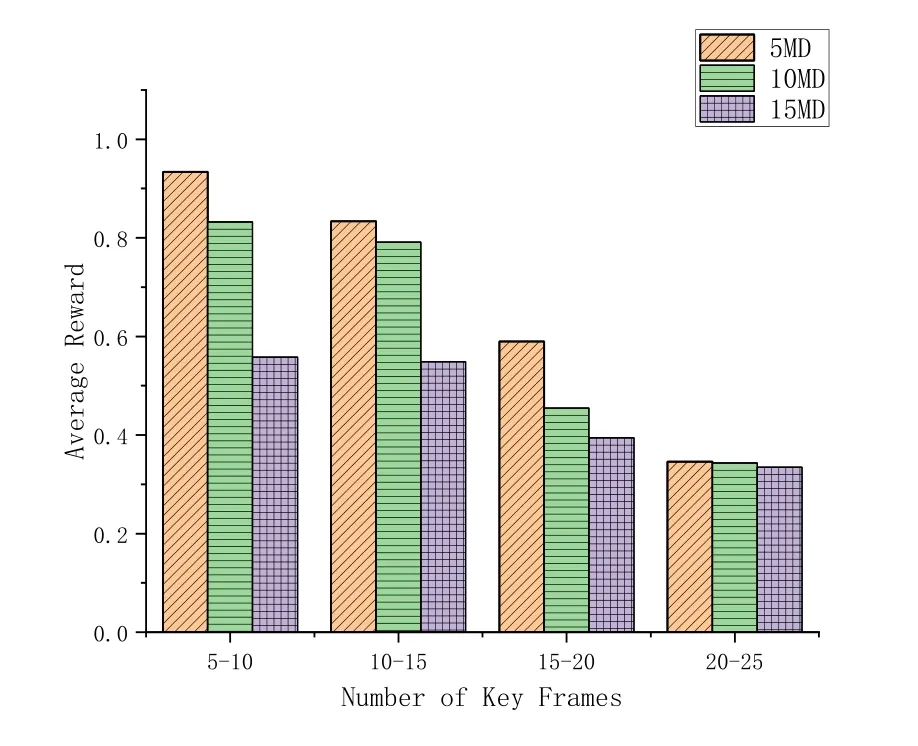
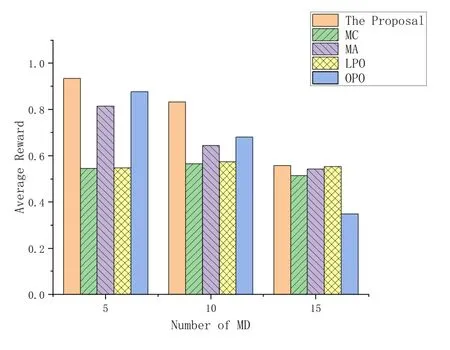
where 1a Therefore,this problemP1can be transformed into: In problemP2,the latency constraint is incorporated into reward function of each agent,which will punish decisions that make the latency of video analytics tasks exceedτn,t.As a result,the video analytics assisted digital twin construction algorithm is shown in Algorithm 1. In this section,we first introduce the preliminaries of multi-agent deep deterministic policy gradient(MADDPG) algorithm [26],then we elaborate the energyefficient video analytics framework. Algorithm 1.Video analytics assisted digital twin construction.1: At the beginning of time slot t ∈T,each MD,EN transmits status information to corresponding virtual entity.2: Each virtual entity makes task scheduling xn,t and configuration selection rn,t by solving P2 and transmit decisions to MDs.3: Video analytic tasks are processed on CPU/GPU processor,the results are transmitted to the edge server for digital twin construction.4: The digital twins on edge server synchronize with physical world.5: t=t+1. As an extension of DDPG,MADDPG provides with a centralized training and decentralized execution framework,which means that we can use global information to ease training,so long as this information is not used at test time.This process is illustrated in the right half of Figure 4.Basically speaking,a MADDPG model is composed of four elements. (1)Agents:Nvirtual entities of users in digital twin network. (2)State: The state of an agent can be described by the set of arrived task,local and edge computation resource,channel information: (3)Action: At each timet,according to the observed environment,each agent makes decision on video analytic processing locationotn,mand video resolutionrtn. (4)Reward:In DRL,the reward of agent,which usually designed to leads agents to right direction,is a function of the state and action.To this end,we define the reward of agentnby equation(12). For each agentn ∈Nin digital twin,it is composed of two actor-critic pairs: one pair named evaluation network and another named target network.More concretely,Qs,aandQ′s,aare the action-state value functions for the evaluation network and target network,respectively.Consider the continuous policy set ofNagents (virtual entities) isµ=µθ1,...,µθnw.r.t.parametersθn(abbreviated asµn).The actor of evaluation network is updated by maximizing the following function: where x=(o1,...,oN) denotes the observation of all agents anda1,...,aNdenotes actions made by all agents.The gradient of(15)is expressed by: Figure 4.The MADDPG framework in digital twin enabled virtual environment. The tuple (xt,at,ut,x′t) is stored in the replay buffer to record experiences of all agents.Each agent wants to maximize its expected reward by making independent decision according to their own observationan,t=µn,t(on,t).Consequently,parameters of evaluation networks’critic,θn,Q,are updated in real-time according to: whereun,tis the reward anda′1,...,a′Nare the set of target actions.Here the idea of centralized training is shown in the action-value functionQn(x,a1,...,aN). According to[26],for each agentn,with the update of evaluate networks’ parametersθn,Qandθn,µ,the target networks can be updated as follows: In what follows,we evaluate the performance of the proposed learning based video quality and task offloading optimization. In this section,we provide extensive simulation results to demonstrate the performance of proposed MADDPG-based task scheduling and configuration selection algorithm and compare it with different benchmarks.All experiments are performed using Python and on Pytorch. Consider a scenario with multiple users and multiple ENs.The duration of each time slot,t=0.5 s.One MD generates one video analytics task,such as object detection and classification.The number of key frames follows a Poisson distribution with parameter of 10.The computing capacity of MDs are set as 109cycles/s,while the ENs have computing capacity of[5.0,10.0]×109cycles/s.A task may be locally processed with energy coefficientρ=10−27or offloaded to nearby ENs with energy coefficientσ=8.2 nJ per unit [27].The transmission power of each MD,pn,t=100 mW[28],and noiseN0=10−9.Following[29],the channel gains are set to be exponentially distributed with unit mean. For each frame,we offer 4 configuration choices:[1920*1080,1280*720,960*540,640*360].The accuracy model is offline-trained in advance,which can be fitted as the function ofω1logf+ω2[14].Besides,the MADDPG algorithm is trained for 200 episode and the learning rate is 0.01 by default.The DRL related parameters are summarized in Table 2. The following benchmarks are considered as baselines in this work: Algorithm 2.MADDPG algorithm.1: Initialization: initialize each agent’s evaluation network and target network,initialize the replay memory buffer of each agent,the weights of actor and critic networks.2: for each episode do 3: Reset the environment x and set the reward of each agent as 0.4: for each step do 5:Each agent n selects an action an,t=µn(on,t)6:digital twin executes actions at=a1,t,...,aN,t in the environment,receives reward ut= u1,t,...,uN,t,obtains new observation x′t.7:Store the transition (xt,at,ut,x′t) in replay buffer.8:Set xt=x′t 9:for each agent do 10:Select a mini-batch of samples(xt,j,at,j,ut,j,x′t,j) from replay buffer randomly.11:Set yj according to(17).12:Update the critic of evaluation network according to(17).13:Update the actor of evaluation network according to(16).14:end for 15:Update the target networks according to(18).16: end for 17: U′=U′+Nimages/BZ_32_551_2092_599_2137.png un 18: end for n=0 Table 2.Simulation parameters. ・ Min-Cost (MC): Each video frame is processed on the lowest resolution,intuitively,this will consume the least energy and time. ・ Max-Accuracy (MA): Each video frame is processed on the highest resolution to maximize video analytics accuracy. Figure 5.The impact of learning rate on performance of the proposal. ・ Local-Process-Only (LPO): Without the assistance of ENs,each MD processes video analytics tasks by themselves. ・ Offloading-Process-Only(OPO):Whenever there are tasks arrive to MDs,they will be transmitted to the ES for further processing. The convergence and the impact of learning rate on performance of the proposal is firstly illustrated in Figure 5.While relative higher learning rate usually results to failure to converge,there is a risk for low learning rate of getting trapped in local optimal.It is of vital importance to choose a proper learning rate.It can be observed that the learning rate of 10−2is superior to others and it is set as the default learning rate in the following experiments. The impact of the number of MDs on average reward is reflected in Figure 6.Generally speaking,the algorithm converges around 40th epochs and the convergence speed is slow when there are more MDs.This is consistent with our perceptions since when there are more MDs,the computing and communication resource on ENs will be scarce. Figure 7 illustrates the system average reward respect to the number of MDs (ranging from 5 to 15)under different DRL methods.Specifically,we use DDPG as baseline: each agent acts as an independent DDPG model and only receives its own observation during training process.As the system average reward decreases with the number of MDs increase,the proposed MADDPG-based algorithm outperforms DDPG.It indicates that the centralized training and decentralized execution helps agents to cooperate to maximize their rewards. Figure 6.The convergence of the proposed algorithm. Figure 7.System average reward respect to the number of MDs under different DRL methods. The video contents generated from cameras are nonstationary,which means the number of key frames in one time slot is dynamic.This nature has been discussed in conventional wisdom [12,30] and will be highlighted on MDs since their mobility.As a result,we discuss the impact of key frames number on the performance of average reward,which is shown in Figure 8.As we can see,the average reward is with negative correlation with key frame numbers.When key frame numbers ranges in[20,25],the average reward does not change much with the number of MD. Figure 8.Average reward on different number of key frames in one time slot. Figure 9.Comparison between different algorithms. Finally,we manifest the superiority of our methods on other benchmarks while the number of MD ranges from 5 to 15.It can be observed from Figure 9 that the performance of the proposal,MA and OPO decrease as the MD number increase,which is corresponding to Figure 6.Specifically,MC and LFO does not change much with the number of MD since there is no competition on computing/communication resources.It is worth noting that the performance of OPO changes intensely,this indicates that task scheduling is more sensitive to the number of MDs. In this paper,we have developed an energy-efficient video analytics framework for digital twin construction in 6G,which utilizes camera-mounted mobile devices for collecting,processing and updating information.With the information cameras,the task scheduling and configuration selection of video analytics are formulated to maximizing the reward of each MD,which is considered as an agent in a partially observable Markov game.While traditional optimization methods encounters dilemma when confronting large action space,an MADDPG-based method has been proposed to solve this problem.Finally,the performance of the proposal is validated by extensive simulation results.Our proposal is applicable in large scale mobile video analytics,which will be key technology to build 6G edge intelligent network.For the future work,we will investigate performance enhancement with coordination among MDs. ACKNOWLEDGEMENT This work is supported in part by the Natural Science Foundation of China under Grants 62001180,in part by the Natural Science Foundation of Hubei Province of China under Grant 2021CFB338,in part by the Fundamental Research Funds for the Central Universities,HUST,under Grant 2021XXJS014,in part by the Research Project on Teaching Reform of Ordinary Colleges and Universities in Hunan Province under Grant HNJG-2020-0156,and in part by the “double firstclass”discipline youth project training plan of Hunan Normal University.IV.MULTI-AGENT DDPG-BASED VIDEO ANALYSIS

V.SIMULATION RESULTS
5.1 Simulation Setup

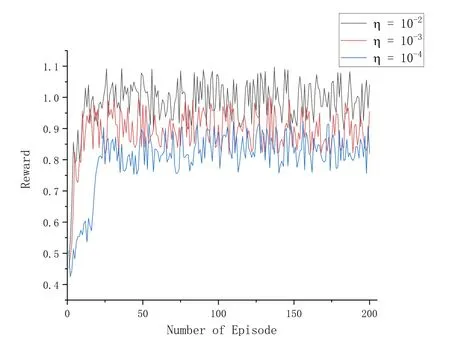
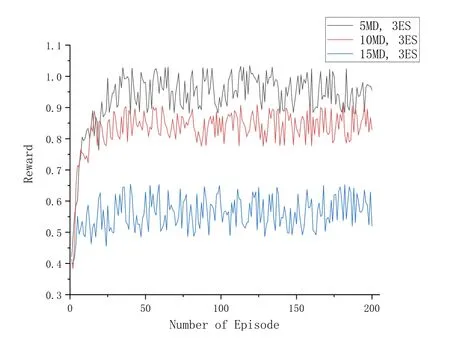
5.2 Performance Evaluation
VI.CONCLUSION

- China Communications的其它文章
- Quality-Aware Massive Content Delivery in Digital Twin-Enabled Edge Networks
- Unpredictability of Digital Twin for Connected Vehicles
- Endogenous Security-Aware Resource Management for Digital Twin and 6G Edge Intelligence Integrated Smart Park
- Digital Twin-Assisted Knowledge Distillation Framework for Heterogeneous Federated Learning
- Design and Implementation of Secure and Reliable Information Interaction Architecture for Digital Twins
- A Golden Decade of Polar Codes: From Basic Principle to 5G Applications