
基于Boosting-Monodepth的管道病害深度估计与三维重建
2023-03-10 13:12方宏远王念念胡群芳雷建伟赵继成
同济大学学报(自然科学版) 2023年2期
方宏远,姜 雪,王念念,胡群芳,雷建伟,王 飞,赵继成,代 毅
(1.郑州大学 黄河实验室(郑州大学),河南 郑州 450001;2.上海防灾救灾研究所,上海 200092;3.城市安全风险监测预警应急管理部重点实验室,上海 200092;4.北京北排建设有限公司,北京 100071;5.深圳市博铭维技术股份有限公司,广东 深圳 518000)
城市地下管道作为城市建设中举足轻重的一部分,对城市发展起着至关重要的作用,主要承担公路纵横向排水、市政工程中供热、处理污水净水等任务。目前大部分地下管道设施的建设已经初具规模或已成型,城市发展中对管道的侧重点也逐渐从施工铺设转向养护保修。随着管道投入使用的年限逐步增长,初期施工的质量不一和地面沉降等问题引发了一系列管道病害[1-3],如管道整体结构的变形和破裂、管道内部的腐蚀与障碍物和异物插入等,这都会导致地下管道无法顺利有效地发挥功能,从而影响城市运行和交通管控[4-7]。因此,定期对管道进行病害检测和修复,保证安全性、提升管道的运行质量十分必要。当前管道病害的检测防治主要依赖人工检修和机器探测,人工检测病害的效率不一且需要从业人员有较高的水平,尤其是管道内部光线阴暗、狭窄潮湿,技术人员更加难以进入,完成整个检测过程往往费时费力[8-10]。相比之下使用影像设备采集管道图片或视频,再通过机器视觉技术处理数据会更加准确高效[11],这也是计算机图像分析研究领域的热点[12-15]。在实际应用中,无论是技术人员后期观看视频或图片来分辨病害种类还是管道机器人实时提取图片特征,都欠缺对物体三维立体信息的考虑,基于深度学习的单目图像深度估计可以从二维图像估计出三维空间一部分信息(即深度),对某些管道病害如破裂、障碍物等进行三维还原或重建,具有广泛的应用前景。
1 相关工作
目前已有的深度估计方法主要分为传统方法[16]和深度学习方法[17]2类,传统深度估计中基于线索的方法依赖于光影、纹理、遮挡或相机和场景的运动变化(structure from motion,SFM)[18-19],基于参数的方法如:刘芳等[20]加入语义信息的马尔可夫随机场(MRF),程婷婷等[21]提出的条件随机场(CRF),研究者们通过学习输入图像与输出深度之间的关系,分区域分层建立深度图的模型,在计算中引入纹理、模糊、消失点等特征,取得了突破性进步。
丰富的数据集也促进了深度学习的发展,MAKE 3D(2008 年)、NYU Depth(2012 年)、KITTI(2013年)的出现也促使人们由传统方法转向关注全监督、无监督和弱监督的深度学习方法。然而在管道方面,采集到的图像重复率比较高,实际可用的数据量并不庞大,国内相关研究还不充分。对于管道病害的三维重建方法主要有激光雷达扫描、机器视觉和传感器法,吴恩启[22]通过光影变化设计了一种检测微细管道内部的方法,对物体截面重建出立体轮廓。叶晶等[23]考虑傅里叶变换设计了一种基于三维成像重构小型管道内表面的技术,盛沙等[24]提出了一项基于超声波的管道内部病害检测方法也可达到同样的效果且更为高效,Chae等[25]提出一种新型数字管道扫描技术,采用移动检测设备进入管道内部,对采集到的图像数据进行失真调整并生成报告。与此类似,甘小明等[26]通过结合环形激光器和机器视觉设计出一款小型管道机器人,该设备针对管道内部细微缺陷进行检测,再引入相机运动估计可完成三维重建。Moraleda等[27]致力于排水管道内部故障检测,并提出一种测算三维空间中裂缝长度和直径的方法,Zhou等[28]利用相机和场景变化(SFM)原理对目标进行连续跟踪来估计单目相机的位姿,最终可以重建出管道的立体结构。
2 理论方法
2.1 网络结构
2.1.1 生成器
深度估计网络采用基于通用U-Net 的Pixel2 Pixel结构,相比于传统的自编码网络Auto-Encoder,U-Net增加了跳跃连接,如图1所示。在处理图像任务时,跳跃连接可以将低频信息包括图像的边缘、轮廓、形状、颜色和纹理直接传输到高层特征图上,很好地保留了一些低层信息。编码器采用尺寸为256×256 的图像作为Pixel2Pixel 的输入,网格维度为(256,256,1)、初始通道为64,图中下采样中的箭头表示4×4 的卷积核+ReLU+BN 的卷积操作。编码过程每次下采样通道数扩大2倍,一共进行3次下采样操作直至网格维度为(1,1,512)。上采样过程使用反卷积将网格维度(1,1,512)重新扩张到(256,256,1)再输出,编解码之间对应的特征图按通道相连接,用以共享一些具体的语义信息,提高网络的训练速度。

图1 Pixel2Pixel生成器网络结构Fig.1 Network structure of Pixel2Pixel generator
2.1.2 判别器
传统的GAN(generative adversarial nets)方法通常使用整个图片作为网络输入,这样会使得生成的图片难以兼顾一些细节信息,整体较为模糊。可以注意到L1、L2此类的损失函数虽然会导致部分图片模糊,但是具有很好的提取和处理低频信息的能力,因此Pixel2Pixel 架构使用L1loss 重建来处理低频部分,高频信息部分使用一种“图像块”的patchGAN进行学习。patchGAN 判别器基于马尔科夫随机场设计,即把图像分成尺寸为n×n的图像块,将不同大小的patch依次输入判别器,逐一验证生成的图像块是否为真,而不需要输入整张图片再去判别全局是否为真。因为patchGAN 是马尔可夫性的,不同patch大小的像素之间相互独立,将N取不同值的判断结果取平均值再输出判别器,即为最终结果。已有的实验结果表明,N越大,模型处理图像细节纹理的效果就越好,输出图的整体效果也越好。当N取70 时,网络训练的参数量适中,patchGAN 判别器的处理速度最快,它只需要注重图像局部信息,运算速度有所提升。
2.1.3 损失函数
普通GAN 的目标函数LGAN(G,D)如式(1)所示,其仅表示为真实图像y经过生成器(Generator)和判别器(Discriminator)的处理结果(结果分别为G、D)。而此处Pixel2Pixel架构的输入图像改变了,其条件GAN(cGan,ConditionGAN)的损失函数LcGAN(G,D)也需要调整,如式(2)所示引入了条件变量x,式中D(x,y)表示判别器通过观察原始输入图像轮廓x和真实图像y的判断结果,D(x,G(x,z))表示图像轮廓x和生成器生成的G(x)的判别结果。
除了改善传统GAN函数,还添加了L1正则化即LL1(G)对网络进行优化,如式(3),L1损失函数计算的是单一的绝对差,生成的图缺乏多样性更趋于真值ground truth,但是鲁棒性强。相比于L2损失函数,L1可以更有效地减少模糊,有利于生成清晰的图像,提高输出图的质量。
最终的目标函数G*如式(4),其中λ为超参量。式(4)表示在L1正则约束下生成器和判别器的maximize &minimize 博弈,生成器不断尝试最小化目标函数以欺骗判别器,而判别器又为了输出最大化目标函数不断迭代,相互牵制抗衡以此输出最优结果。
2.2 Merge Net
2.2.1 双重估计
用来训练和测试的图片往往以固定分辨率输入网络,较小的分辨率可以保留图像的整体结构,场景一致性较好,但容易错失局部细节信息,相反较大的分辨率可以捕捉到局部细节轮廓,但场景的一致性又随着分辨率的增大而持续降低,同时还会产生一部分低频伪影。深度估计的模型和感受野都是固定的,如图2所示,改变输入图像的分辨率会不同程度地影响感受野(方框标注)所能“看到”的场景和线索。为了获得具备连续一致的场景和兼顾高频细节的深度估计图,boosting-monodepth设计了一个融合网络,将高分辨率深度估计图中的高频信息整合到低分辨率深度估计图中,形成一个两方面都能取得较好效果的基本估计(base estimation)。此方法适用需要百万像素级别深度图的情景,且无需太多的计算量和运行成本。

图2 感受野与不同分辨率图像Fig.2 Receptive fields and images with different resolutions
图像边缘是影响深度估计网络性能的重要因素,它与上下文线索存在一定联系,将原始RGB 图像进行色彩梯度阈值处理得到粗略边缘图,再作为上下文线索估计整个图片的深度可取得比较不错的效果。如图2,感受野大小不变时,越大分辨率的图细粒度信息越容易捕捉,但也有一定像素缺少上下文线索,场景也开始变得不连续。当感受野都能覆盖到上下文线索时,此时的分辨率定义为R0,也是最适应图像场景内容的;当图中有20%的内容与上下文线索的距离超过感受野大小的一半时,此时的分辨率定义为R20,它也能同时保持场景的一致性和提取到丰富细节的分辨率。
提高分辨率的同时可搜索的深度线索也在变少,网络可以获得的像素信息也趋于匮乏,这样会导致网络估计的准确性降低,boosting-monodepth深度估计网络基于图像内容自适应输入的分辨率,低分辨率输入取感受野的大小(小于感受野并不会优化全景结构,反而会导致没有充分利用网络容量而削弱性能),高分辨输入取R20。再通过融合网络将2个深度估计结果进行合并,把R20的细粒度细节赋在低分辨率估计上,可以取得物体轮廓清晰且伪影较少的深度图。
2.2.2 补丁估计
当图像中某些场景比感受野的接受域更深更远时,深度估计网络难以获得这些像素和区域周围的信息,一味地提高输入分辨率反而会破坏输出深度图的细节,合适的输入分辨率随图像中内容的不同而有所差异。图像中某些内容丰富的地方也具备更高的上下文线索密度,因此再次利用融合网络对这些“块”进行单独估计有利于提高最终深度图的准确度,这种分块估计称为“patch estimation”。
patch的选择主要分为2个步骤。首先按感受野的大小平铺整个图像,平铺过程保证每个相邻的patch 之间有1/3 的重叠,如图3 所示。为了充分利用网络容量,让更多的patch搜索到足够的上下文信息,当patch框选到的上下文线索密度小于整张图的上下文线索密度时,此类patch可用性低,直接丢弃;当patch 框选到的内容具有更丰富高频的边缘信息时,保留此类patch并将它扩大到和原始图像尺寸相同(如图4),这样可以有效地提取到最具价值的像素。

图3 补丁选择第1步Fig.3 Step 1: Patch selection

图4 补丁扩张第2步Fig.4 Step 2: Patch expansion
一张图中会有多个patch,对这些patch 再依次进行双重估计以取得边缘清晰的局部深度图,然后将这些结果通过融合网络合并到之前的深度估计结果上,即先前由R0和R20生成的base estimation。至此已经获得了细节较为丰富的深度图(Mid-DepEst),为了发挥出网络的最大效能,最后能呈现出完整连续且像素过渡柔和的图像,再将Mid-DepEst 和base estimation 通过融合网络,整合出最终的深度估计图,全部过程一共进行了3次合并,整个技术路线流程如图5。

图5 技术路线Fig.5 Technical route
3 管道病害二维深度图生成和三维重建
3.1 数据集
以图形、纹理和颜色等信息为源数据的计算机视觉依赖大量的图片来训练网络,基于单目图像的深度估计分为无监督、有监督和自监督(弱监督)这几类。其中有监督学习的训练集是大量带有深度真值的RGB-D图像集,此类数据集获取难度较大且可采集到的数据量有限,网络计算难度也较高,相比之下自监督更灵活且使用的图像无需带有深度标签。深度估计方面目前应用最广泛的公共数据集有3种情形,室内场景如NYU Depth V2数据集;室外场景包括KITTI、NUScenes、MAKE 3D、CityScapes;合成数据集如Scene Flow。本文使用KITTI数据集来训练神经网络,该数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院共同开发,主要用于双目立体匹配、单目深度估计、光流、3D目标检测和跟踪等。采集数据的设备为一辆搭载彩色相机、灰度相机、激光扫描仪和GPS 导航系统等各类传感器的汽车,训练集包含39 810 张图片,验证集包括4 424 张图片。此外,排水管道内部的病害图片难以人工获取,为了得到比较好的识别和深度估计效果,选取变形、破裂、异物插入这3 类管道病害进行研究,并在这几类病害中再择优选取尺寸和分辨率都较大的图片来测试。
3.2 参数细节和深度图生成
训练的自监督单目深度估计模型基于Pytorch框架,选用Linux 系统、NVDIA RTX 3080Ti GPU计算模块,并用公共数据集KITTI进行预训练,训练批大小为12,迭代(epochs)为20,此外初始学习率过小会导致网络收敛缓慢,为了避免进入局部最优区域,初始学习率设置为10−4。在图像处理方面,输入网络前对图像采取随机旋转、翻转镜像、裁剪和缩放进行数据增强,部分由视频(采集帧数为30fps)分割出来的图片每隔50张抽取一个样本作为训练数据。
对于boosting-monodepth,输入图像尺寸最大采用1 920×1 080,而对于较小尺寸的图,Pixel2Pixel的10 层U-net 网络会将小尺寸图像上采样至1 024×1 024 的分辨率。monodepth2 的初始默认分辨率为640×192,对于管道图片将其修改为640×480(需为32 的倍数)。选取3 个具有代表性的管道病害进行研究,分别是变形、破裂和异物插入,这几类病害结构形变较为明显,更容易被观察,其中变形图片532 张,破裂589 张,异物插入456 张,通过在ImageNet 上的预训练模型初始化Resnet101 权重参数。
3.3 定性分析
在本次实验中,从管道3 类病害图片测试集中挑选了几张具有代表性的深度估计图与Zhou 等[28]的方法进行定性对比分析,并用boosting-monodepth作为最优深度估计效果展示。3 类管道病害用不同方法的深度估计结果如图6—8所示,为了更直观地观察到各类病害,在图中用框标注出深度估计效果显著的地方。由图6可见,深度估计效果较为突出,排水管道变形明显处可以有效识别。由图7 可见,排水管道破裂较大处可以估计,部分较深的裂缝可以清楚地估计出轮廓。

图6 变形Fig.6 Deformation

图7 破裂Fig.7 Rupture
除了识别出常规的支管插入,有些近景物体也能估计。从图6—8 可以看出,相比于其他方案,本文的boosting-monodepth 深度估计方法在管道病害图片测试集上显示出的效果更好,在管道发生明显塑性形变和裂缝处可以清晰地估计出轮廓形状。异物插入病害中除了远距离大体积的支管,画面中近景小物体也能感知估计,可见boosting-monodepth深度估计方法在场景中无论近远景物体都能估计出深度连续一致、像素过渡柔和的图像,并且因为此方法的融合网络对多尺度多分辨率的图像进行采样处理时场景中的低频伪影被有效降低,一些小物体的边界轮廓表现也不错。

图8 异物插入Fig.8 Foreign body penetration
同时,boosting-monodepth深度估计方法也存在一些不足,有些清晰度不高的原始图像所估计出来的深度图效果不算太理想,非常细小的裂痕深度图细节还原度不高,管道内部表面腐蚀的此类病害因没有突出的明暗或距离变化而难以估计,但总体效果相比其他深度估计方案具有更好的效果。
3.4 定量分析
对于深度估计任务,利用2种数据源(公共数据集KITTI 和自采管道病害数据)来对不同的深度估计方法(monodepth2、midas、本文所使用的boostingmonodepth)进行训练测试,并对比分析在相同的评价指标下,本文方法和目前已有的深度估计网络之间的差异和优劣。表1给出了不同深度估计方法的定量分析结果,其中monodepth2 和boostingmonodepth 均是自监督学习,采用广泛使用的Abs-Rel(绝对相对误差)、RMSE(均方根误差)、SqRel(平方相对误差)、D³R 和ORD(内置函数)评价指标来评估深度估计网络在预测KITTI和管道病害图片方面的性能,以上5个指标数值越低越好,同时也纳入了深度信息预测值与真实值对比的精确度指标δ,在阈值为1.25范围内,δ数值越高越好,表示具有更高的准确性。
从表1可以看出,在相同的定量评估指标下,与近段时间现有的经典方法相比,本文所采用的双重估计方法取得了更好的效果,尤其是RMSE 值明显降低,boosting-monodepth通过融合网络对低分辨率的深度图上采样得到较大的尺寸,再和高分辨率的深度估计图中的高频细节信息进行3 次合并,在阈值为1.25时,本文提出的方法深度信息预测精确度指标δ比另外2种方法提高了约18%,进一步验证了boosting-monodepth深度估计方法的有效性。

表1 不同深度估计方法评估结果Tab.1 Evaluation results of different depth estimation methods
3.5 基于二维转三维的管道病害重建
3.5.1 坐标系转换
从深度信息转化到三维点云是以不同的坐标系之间相互转换完成的,由二维深度图重建出三维模型是一个信息扩增过程,这个过程涉及4个坐标系,分别是世界坐标系、相机坐标系、图像坐标系和像素坐标系,它们之间一一对应,可以通过各种矩阵变换或者量化模型完成,其中三维重建主要是从图像坐标系到世界坐标系的变换。位于三维世界中的任意一点P,它在三维空间中的坐标是P(x,y,z),这个世界坐标系也是我们日常生活的客观世界,以此为基准可以描述相机的摆放位置以及物体的具体位点,即Pw(xw,yw,zw),以相机坐标系的坐标原点为相机的光心,在此坐标系下P点坐标为Pc(xc,yc,zc),由世界坐标转换到相机坐标的变换为式(5):
其为刚体变换,各坐标系对应点的具体变换为式(6):
式中:R为旋转矩阵;T为平移矩阵。它们是相机的外参,和相机内参共同组成了坐标系变换的约束条件。式(6)反映了三维立体世界中的物体投影到二维平面的过程,由此反推可以得到二维的像素点一一映射到三维空间的转换关系,即图像坐标系转换为世界坐标系,如式(8),其中D为深度,(x,y,z)为点云坐标,x′、y′为图像坐标,有
3.5.2 三维点云重建和可视化
通过深度估计方法已获得高质量的深度图,从中选取3 种具有代表性的管道病害来重建三维结构,Matlab 软件可以较好地访问提取图像的深度信息,通过式(8)的转换关系使用Matlab软件作为二维深度图像转化三维点云的平台。
为了更直观地观察三维重建效果和测算深度,管道病害立体图用CloudCompare 进行展示,图9—11即为效果图,为了更容易看出病害破损程度,三维效果图选取最优管道截面视角并用框标识。

图9 变形(三维)Fig.9 Deformation(3D)
本文研究的管道均为排水管道,管道半径均为5.0~6.5m,在具体深度值方面,本文采用随机采样一致算法模拟管道表面,选定管道病害损伤点到管道面的距离然后测算其深度,同时在CloudCompare软件中测距并与现场实测数据做对比。从表2可以看出,对大型管道测量的数据的单位有效位数在毫米级不容易展现,随物体体积变大或管径长度的增加误差也在一定程度上变大,但在实际研究范围内仍具有一定的准确性和参考价值。
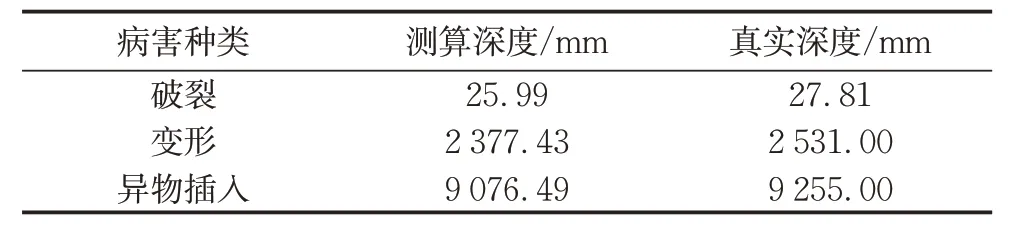
表2 深度对比Tab.2 Contrast of depth

图10 破裂(三维)Fig.10 Rupture (3D)

图11 异物插入(三维)Fig.11 Foreign body penetration (3D)
4 结论
城市地下管道是城市能量传输的重要载体,关乎整个城市的正常运作,管道的大量投入使用也导致了其内部结构的改变和表面的腐蚀破损,而以往对于管道病害的拍摄采集和后期人为分辨病害种类都是从二维角度出发,缺乏对三维空间信息(深度)的考量,针对此问题选取3 类病害,即破裂、变形和异物插入,进行二维转三维的研究,具体工作如下:
提出了一种基于boosting-monodepth 的提升图像深度估计效果的方法,相比于传统的自监督深度学习,该深度估计方法采用双重估计策略,通过融合合并网络将不同分辨率大小的管道病害图像多次整合,生成了画面场景一致、像素过渡柔和的深度图,尤其在一些管道发生明显结构变形和较大较深裂缝处,可以得到轮廓边界清晰的高质量深度图。同时本文在不同的测试集上验证了boosting-monodepth的有效性,并与经典的monodepth2 和midas 深度估计效果进行定量比较,结果表明相比于另2种方法,boosting-monodepth 方法的均方根误差RMSE 降低了约30%,δ<1.25 时,模型精确度指标δ提高了约18%。得到了较好的深度图之后通过具有较好的深度信息访问功能的Matlab 软件进行三维点云重建,以小孔成像理论为基础完成二维图像坐标系到三维点云世界坐标系的转换,同时在CloudCompare软件上可视化显示,同时运用随机采样一致算法测算深度并和真实现场实测数据进行比较,可知其具有不错的准确率和实际参考价值。
作者贡献声明:
方宏远:论文思路指导、论文撰写、实验规划。
姜 雪:论文撰写、数据分析、实验结果可视化。
王念念:论文审阅及修订、论文思路指导。
胡群芳:总体技术方案及实验方法设计与数据分析。
雷建伟:现场管道实验部署与数据采集。
王 飞:论文指导与数据分析。
赵继成:实验数据提供及结果验证。
代 毅:提供实验设备、数据采集。
猜你喜欢
导航定位学报(2022年2期)2022-04-11
上海师范大学学报·自然科学版(2021年4期)2021-09-23
计算机应用(2019年3期)2019-07-31
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
中学生数理化·七年级数学人教版(2018年4期)2018-06-28
数学大世界(2018年1期)2018-04-12
制造技术与机床(2017年7期)2018-01-19
自动化学报(2017年5期)2017-05-14
软件导刊(2016年9期)2016-11-07
