
中文科技政策文本分类:增强的TextCNN 视角
2023-03-08 02:57李牧南赖华鹏
科技管理研究 2023年2期
李牧南,王 良,赖华鹏
(1.华南理工大学工商管理学院,广东广州 510641;2.广东省创新方法与决策管理系统重点实验室,广东广州 510641)
1 研究背景
深度学习的理论和计算框架被提出以来,随着高性能计算硬件技术发展,越来越多普通实验室、中小型科研机构和团队开始参与深度学习理论和应用的研究,相关学术和应用成果也开始涌现,过去5 年出现了近乎指数级增长。与此同时,中国也逐渐成为深度学习相关理论、模型和算法应用研究最为活跃的地区之一。从图1 可以看出,2019—2021深度学习领域有关文献数量已经超过了过去10 年文献总数的74.6%,而仅仅2021 年所发表论文数量占比就达到了31.3%。从图2 可以看出,中国研究者在深度学习领域非常活跃,发表论文总数甚至超过了美国和英国的总和,表明中国在深度学习相关领域的科研投入相对较大,参与的研究机构和人员较多。

图1 深度学习领域文献数量的年度分布趋势

图2 2012—2021 年深度学习相关文献数量的国家分布
中国互联网络信息中心(CNNIC)发布的第48次《中国互联网络发展状况统计报告》显示,2021年中国网民规模达10.11 亿人,较2020 年12 月增长2 175 万人,互联网普及率达71.6%,形成了全球最为庞大和生机勃勃的数字社会[1]。中国早已成为全球最大规模的数字化服务应用地区,这也意味着各类中文文本数据呈现高速增长态势。如何针对这些不断增长的中文数据进行有效处理,及时发现蕴藏的各类知识,已经成为各类商务领域分析的重点,也成为新时代新形势下商务模式和治理模式创新的重要手段。
作为深度学习理论和计算框架/体系核心模型之一的卷积神经网络(convolutional neural networks,CNN)自从被Lawrence 等[2]提出以来,在图像识别、机器视觉、信号过滤和自然语言处理等多个不同领域得到广泛应用,如魏明珠等[3]、Zhang 等[4]、Rawat 等[5]和刘颖等[6]学者的研究。而且如Zhang等[4]、刘颖等[6]和Voulodimos 等[7]的研究均表明,深度学习与传统机器学习算法的一个显著区别在于非监督的特征提取,可以通过大样本的训练和学习完成特征提取工作,无须大量人工干预,在某种意义上真正实现了机器(计算机)的自我训练(selftraining)和自学习(self-learning)。因此,深度学习尽管依然是机器学习的一个分支,但其总体的计算思想可以认为是一个传统机器学习领域的阶段性标志,具有显著的里程碑意义。
Chen 等[8]、杨锐等[9]、Colin-Ruiz 等[10]、杨光等[11]众多研究均表明,尽管CNN 在图像识别和机器视觉等领域展现了较强的竞争优势,但是应用到自然语言处理领域,包括语义建模、情感分析和文本分类等,却是近5 年才逐步发展的一个研究分支。2014 年,纽约大学的 Kim[12]学者在arXiv 预印本网站发表了一篇应用CNN 进行语句分类(sentence classification)的论文,引起广泛关注;该方法此后被脸书公司在2019 年集成到PyTorch 工具包中,形成目前较为知名的文本卷积神经网络(TextCNN)。近两年来,国内外不少科研机构和团队也开始基于TextCNN 模型从事自然语言处理相关研究。随着这些长文本(long text)的数据量越来越大,如何对这些中文长文本进一步处理和挖掘,已经成为信息和档案管理以及基于大数据的公共治理体系建设的关键问题和挑战之一。
数据增强(data augmentation)是一种针对小样本学习问题而提出的训练样本强化方法,目前在图像识别、语音修复和计算机视觉等多媒体领域得到了一定程度应用,如He 等[13]、蒋芸等[14]、Salamon 等[15]的研究,但应用在自然语言处理和文本分类,尤其是中文自然语言处理方面依然存在较大的探索和拓展空间。因此,本研究从文本增强的角度出发,考虑进一步提升传统卷积神经网络模型在中文长文本分类中的实际效果。
2 研究设计
卷积神经网络提出之后,之所以很快就被应用到图像识别和分类领域,主要是卷积神经网络的多通道(channels)思想,能够将图像最基础的红色、绿色和蓝色(以下简称“RGB”)3 种颜色组合作为一种典型的三通道卷积神经网络,而基于RGB 的颜色标准也是目前工业界最广泛应用的颜色系统标准。对于任意一幅数字化图片而言,都是由一定像素(pixel)构成,而这些像素点实际上可以解构为RGB 三维空间的一个点,所谓像素也往往被称为“像素点”(pixel point)。卷积神经网络的思想认为,既然任何一幅图片其实都是点的集合(point set),那么理论上通过组合这些像素点就能提取图片特征,从而可以对图片进行分类和识别。
基于卷积神经网络处理图片数据的思路,文本也可以理解为由不同词语(字)组成,如果能够把这些词(字)映射到一个向量空间,就可以像处理图片识别的原理一样实现文本语义相似度的匹配和分类,这也是卷积神经网络逐渐进入自然语言处理领域的重要理论基础。但是,词向量空间依赖于基础语料库,而中文作为一种相对复杂的表意语言体系,通过机器来进行自然语言处理就比其他表音语言体系要困难得多[16],由此造成了针对中文长文本的分类、聚类、语义模式匹配和文本挖掘迄今依然面临较大挑战[17]。因此,近年来部分研究开始借鉴图像处理领域的数据增强方法改进文本分类效果,但目前国内外研究基本集中在以电影评论、商品评论和推特等短文本的处理领域,如Chen 等[18]、Hao 等[19]、Symeonidis 等[20]的研究,针对长文本尤其是中文长文本的自动分类研究还不多见。借鉴黄水清等[21]、Wei 等[22]、谷莹等[23]、明建华等[24]对当前有关数据增强、短文本分类和深度学习相关的理论和应用研究基础,本研究提出一种综合新时代人民日报分词语料库(NEPD)、简单数据增强(easy data augmentation,EDA)、词语向量化(word2vec)和TextCNN 的中文长文本分类框架(以下简称“NEWT”)。具体计算流程如图3 所示。
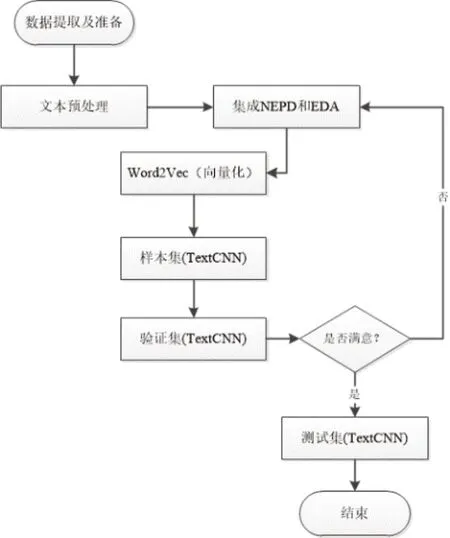
图3 NEWT 的计算执行流程
在图3 中,文本增强的EDA 方法包括同义词替换、随机交换、随机插入和随机删除,而中文自然语义处理的语料库为目前较为主流的NEPD。通过文本增强之后,原始的单个中文长文本可以被扩展为2×4 个样本,并且未丢失原始样本的核心语义信息,但是对于后续的卷积神经网络而言,训练样本得到了适当扩充。在深度神经网络训练结束后,随机选择的验证集会对训练效果进行验证,如果达到满足既定要求,则可以进入测试环节,并产生最终的长文本分类效果输出,其中包括准确率、召回率和加权后的F1值。应用NEWT 进行中文长文本分类流程如图4 所示,其中n表示样本数量,CL 表示卷积层神经元,PL 表示池化层神经元,k表示卷积层和池化层的神经元个数,FC 表示全连接层神经元,K表示全连接层神经元数,Z表示输出层神经元,m表示输出层的维度。

图4 应用NEWT 进行中文长文本分类流程
图4 中,输入层所有样本是经过word2vec 转化后的词向量,而卷积层的卷积核宽度(列)需要与word2vec 输出的词向量维度保持一致,这里将卷积核的行数设定为3 行;输出层为softmax 多分类非线性映射,借鉴董洪伟[25]的方法,具体表达形式如下:
考虑到softmax 函数的特性,全连接层可以根据分类的数量输出同样数量的线性回归函数(单分类)作为softmax 模型的输入,此时softmax 函数的表达形式如下:
由此,softmax 函数可以将全连接层的输出转换为概率值。则输出可以理解为属于某个具体目标(类)的概率,表达形式如下:
为了衡量softmax 多分类函数的实际分类效果,就是使得对于任意一个样本,其属于目标(类)的概率最大,在所有样本分类准确的情况下即可实现。由于乘法会使得数值迅速趋于0,因此通常将概率的负对数平均值作为衡量的损失函数(loss function),也就是交叉熵损失函数,表达形式如下:
显然,若所有样本都趋于其真实类别,则损失函数趋于最小值,即概率的乘积和最大。中文长文本分类效果的评价通常采取准确率(P)和召回率(R)及加权平均F1值来衡量,表达形式如下:
式(5)中,F1是精确率与召回率的调和平均值,作为综合评价指标,取值范围为[0,1],越靠近1则表示文本分类的效果越好。
3 实证分析
从北大法宝网检索和下载了1949 年至2021 年中国地方政府发布的科技政策文本,共采集了3 万多条文本数据,剔除“授奖”“通报”和“表彰”等通知公告文本后,获得有效科技政策文本4 441 份(以下简称“样本”)。进行实证分析的硬件和软件环境情况如表1 所示。

表1 本文实证分析的软硬件主要配置
从样本文本长度看,最短的为612 字(含字符和空格),最长的超过7 万字,且文本长度呈现右偏长尾分布。其中:1 000 字至6 000 字的政策文本占比约63.8%,10 000 字以下的政策文本比重为85.6%,而15 000 字以下的文本占比则达到93.3%;32 000 字~73 000字的文本有39 篇,72 000字~73 000 字的文本有1 篇。笔者对每篇超过2 万字的文本都进行了较为仔细的校验,检查其中是否含有人员和机构名单、统计或年鉴数据、额外填充字符等附加字符。
根据张宝建等[26]的做法,基于政策体系性质将样本文本分为强制型、鼓励型和引导型3 类,分别共有1 540 篇、753 篇和2 148 篇。在应用EDA方法进行文本数据增强之后,原有样本文本被扩充为17 912 个样本数据。考虑到样本文本总体的长度分布以及深度神经网络的计算规模较大,在采取全文输入的情况下最长的文本字数超过7 万字,而word2vec 输出的是300 维词向量,因此,即使这份7万多字的样本文本采取中文分词后只剩下2 万字左右,但是20 000×300 的输入矩阵已经超过了普通深度学习机器的数据装载容量,即使通过加装更多的GPU,也会面临更高的“梯度爆炸”风险,且计算耗时过长。
基于以上考虑,取词长度分别设定为500 个词、750 个词和1 000 个词,尽管未能实现所有样本的全文加载,但是也比已有的短文本分类(如电影评论、消费评价等)的计算量大得多。交叉熵损失函数在不同取词长度下的变化趋势如图5 所示,可以看出,无论是否集成文本数据增强方法,TextCNN 模型的交叉熵损失函数在20个时期(epoch)之后都趋近于0,意味着深度神经网络的样本训练趋于稳定和收敛。但是,是否实现了集成数据增强对于中文长文本的分类效果影响显著需要进一步进行实验。

图5 不同取词长度下的NEWT 和TextCNN 的损失函数变化趋势
从图6可以看出,经过整合NEPD和文本增强后,NEWT针对中文科技政策文本的分类效果显著提升,F1值比使用传统TextCNN 方法提升超过10%。通过对每个不同取词长度都运行20 次实验(训练集—验证集—测试集),然后计算F1值的平均值;每个实验的样本训练次数为40 个epoch,且验证数据集(validation set)和测试数据集(test set)的样本规模均为200 个。结果如表2 所示,可见取词长短对样本文本分类效果不甚显著,500 个词长度下大致只实现了大约10%样本文本的全文输入(中文分词之后会去除空格和标点符号等),而1 000 个词的长度大致可以实现大约50%的样本数据全文本输入。从理论上看,取词长度并不是越长越好。取词长度过长,一方面导致计算耗时呈现几何级增长,甚至出现样本矩阵过大无法加载的困难;另一方面,对于一些本来就不太长的政策文本而言,则需要填充太多的冗余字符,也可能会影响最终的分类效果。

图6 基于NEWT 和TextCNN 的中文长文本分类效果对比

表2 取词长度对中文长文本分类效果对比
为进一步验证NEWT 计算框架,选择当前较为流行的几个用于文本分类的深度学习模型进行对比,包括余传明[27]、马晓雯等[28]、Kim 等[29]、冯国民等[30]提出的循环神经网络(RCNN)、双向长短期记忆网络(Bi-LSTM)和胶囊网络(CapsNet)。对比分析结果如表3 所示,与上述各深度学习相关文本分类模型相比,本研究提出的NEWT 框架在3种取词长度下对中国地方政府科技政策文本的分类效果均较优,且F1值的平均提升比例超过13%,较为显著。

表3 NEWT 与其他相关模型的文本分类效果对比
4 结论与讨论
从目前国内外基于深度学习算法的文本分类研究看,绝大部分都是针对短文内容,例如在线评论、知识问答、推特和微博等,而针对长文本,尤其是中文长文本分类的研究就更少。尽管卷积神经网络在深度学习理论和应用研究中占据相当比例,但卷积深度神经网络在文本分类、自然语义处理、专利分析和不平衡情感分析等相关研究领域依然存在应用研究的拓展空间,如Li 等[31]、张志武等[32]的研究,针对长文本的分类、聚类、语义识别和内容挖掘已经成为当前深度学习研究领域的前沿和热点主题之一。针对中文长文本分类,本研究提出了集成计算框 架NEWT(NEPD+EDA+Word2Vec+TextCNN),借鉴和拓展了传统的数据增强方法,并应用到中文科技政策文本挖掘领域,与传统深度学习相关文本分类模型相比,F1 值平均提升比例超过10%,分类效果更好;此外,NEWT 在相对较短取词长度下实现与全文输入的近似效果,可以部分改善传统深度学习模型的计算效率,节省大量运算时间,有助于提高计算效率、节省运算时间,补充和完善长文本分类领域的研究盲点,并为中文长文本自动分类走向应用提供参考。
本研究也存在一些局限性:首先,对于文本增强的探讨还有待于进一步深入,如何更好适应中文文本语言表述和语义特征,还需要在未来研究中继续探索;其次,尽管NEWT 的长文本分类效果也基本达到了目前中文文本分类的平均效果,但依然存在一定的优化和改进空间,如杨春霞等[33]、杨锐等[9]的研究指出,传统文本分类模型在不同应用场合也有一些改进版本,与这些改进版本,以及与刘宇飞等[34]提出的迁移学习和杨波等[35]、王雪等[36]提出的BERT 及其相关改进模型等之间的比较还有待于进一步检验;第三,针对取词长短对实际分类效果影响不显著的问题还需要在后续研究中进一步从理论层面予以探讨;最后,NEWT 算法的普适性和泛化能力还有待于进一步检验,在其他类型的政策文本(例如:能源、环境和金融政策等)是否也能取得类似或更好的效果,还需要在后续研究中进一步论证。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
小学生学习指导(低年级)(2020年10期)2020-11-26
数学小灵通(1-2年级)(2020年9期)2020-10-27
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
作文大王·低年级(2017年11期)2017-12-05
小学生学习指导(低年级)(2017年12期)2017-11-22
