
基于长句简化的中文开放关系抽取
2023-03-04 06:37熊建华韩永国寇露彦吴昌述
计算机技术与发展 2023年2期
熊建华,韩永国,廖 竞,寇露彦,吴昌述
(西南科技大学 计算机科学与技术学院,四川 绵阳 621010)
0 引 言
信息抽取(Information Extraction,IE)利用计算机技术来识别文档的有效信息,并将这些信息转换成适合计算机的存储、处理和检索的结构化形式。信息抽取开辟了更加丰富的知识使用方式,有助于高效、有效地分析海量文本数据。信息抽取任务依照抽取内容可以划分为:命名实体识别、事件抽取、关系抽取等。关系抽取是其中的重要子任务之一,主要目的是从文本中抽取实体之间的语义关系,通过三元组的形式对文本中包含的知识进行组织。开放关系抽取是指在不事先定义关系类型的情况下,直接对语料进行关系数据的抽取。相比于传统关系抽取,开放关系抽取能充分利用开放语料,扩展出更多的关系类型,为自然语言处理的下游任务提供更好的支持。
开放关系抽取最早是在英文领域提出的。在英文开放关系抽取研究中出现了TextRunner[1]、WOE[2]、Reverb[3]、ClauseIE[4]、OLLIE[5]等多种经典系统。其中,TextRunner与Reverb都是利用词性标记和正则表达式制定抽取规则进行抽取。ClauseIE通过英语语法知识将句子分解为子句进行抽取。WOE与OLLIE是基于自监督学习的抽取系统,利用已有的高质量关系数据标注数据,构建训练数据集,然后从训练数据集中学习关系抽取的模板。近年来,有学者尝试使用深度学习网络对开放关系进行端对端的抽取。文献[6]中利用编码器-解码器框架进行开放关系抽取。该方法可以不定义任何抽取模式,直接进行抽取。文献[7]利用BERT和多头注意注意力机制融合句子和谓语特征,通过序列标注的方法进行开放关系抽取。
相比于英文开放关系抽取,中文开放关系抽取研究仍然处于起步阶段,且中文开放关系抽取人工标记数据集较少,大部分研究仍然采用基于规则和模板的方式进行无监督的抽取。文献[8]中提出了一种无监督的中文开放关系抽取方法。该方法利用实体距离、关系词位置等特征抽取候选关系数据,随后利用信息增益、句式规则进行关系过滤。该方法在大规模网络文本语料中的准确率达到了80%。文献[9]首次提出多元组的中文开放关系抽取,首先,识别出语料中的基本名词短语作为实体词,将句子中的谓语动词作为候选关系词;然后,根据句法规则将与关系词相连的所有实体都添加到关系组中,可以同时抽取二元组和多元组。该方法在百度百科数据集上的抽取准确率达到了 81%。文献[10]以句法分析结果的根节点为入口,递归查找所有动词的主语、宾语成分,再根据句法规则进行补充调整,最终有效地获取句子中复杂的多元实体关系。文献[11]从手工标注的少量地质领域数据学习关系抽取模板进行开放关系抽取,有效解决了地质领域关系复杂的问题。文献[12]首次将中文开放关系抽取视为序列生成任务,利用指针生成网络对文本进行端对端的抽取。然而该方法仍然是在基于模板抽取的数据集上进行训练的。
综上所述,目前中文开放关系抽取的主要方法都是基于规则和模板的,这些方法需要以自然语言处理工具的处理结果为基础进行抽取。然而自然语言处理工具在处理复杂长句时,分词、词性标注、句法分析的准确率都明显下降,严重影响关系抽取的质量。另一方面,在复杂长句中通常存在多个关系数据,现有的开放关系抽取模板很难做到全面覆盖。因此,该文借助序列到序列神经网络模型将复杂长句简化为多个结构简单的子句,然后,利用自然语言处理工具对每个子句分别进行处理,最后,通过词性、句法等约束实现开放关系抽取。
1 长句简化数据集构建
目前中文领域暂时没有长句简化相关的数据集。该文使用手工标注和回译策略两种方法构建了一个中文长句简化语料库。
首先,采用2019年中文维基百科的数据,进行长句简化数据集的手工标注。中文维基百科数据的内容丰富,词语、句法相对规范,数据量大是中文自然语言处理研究中常用的数据集,具有一定的权威性和可靠性。在进行手工标注前,需要先对中文维基百科数据进行预处理。如图1所示,首先,对数据按句号进行分句;然后,使用哈工大的LTP(Language Technology Platform)工具对句子进行分词,筛选出词数大于30的句子;最后,利用LTP对句子进行实体识别,筛选出包含两个以上实体的句子,确保选出的句子包含关系数据。
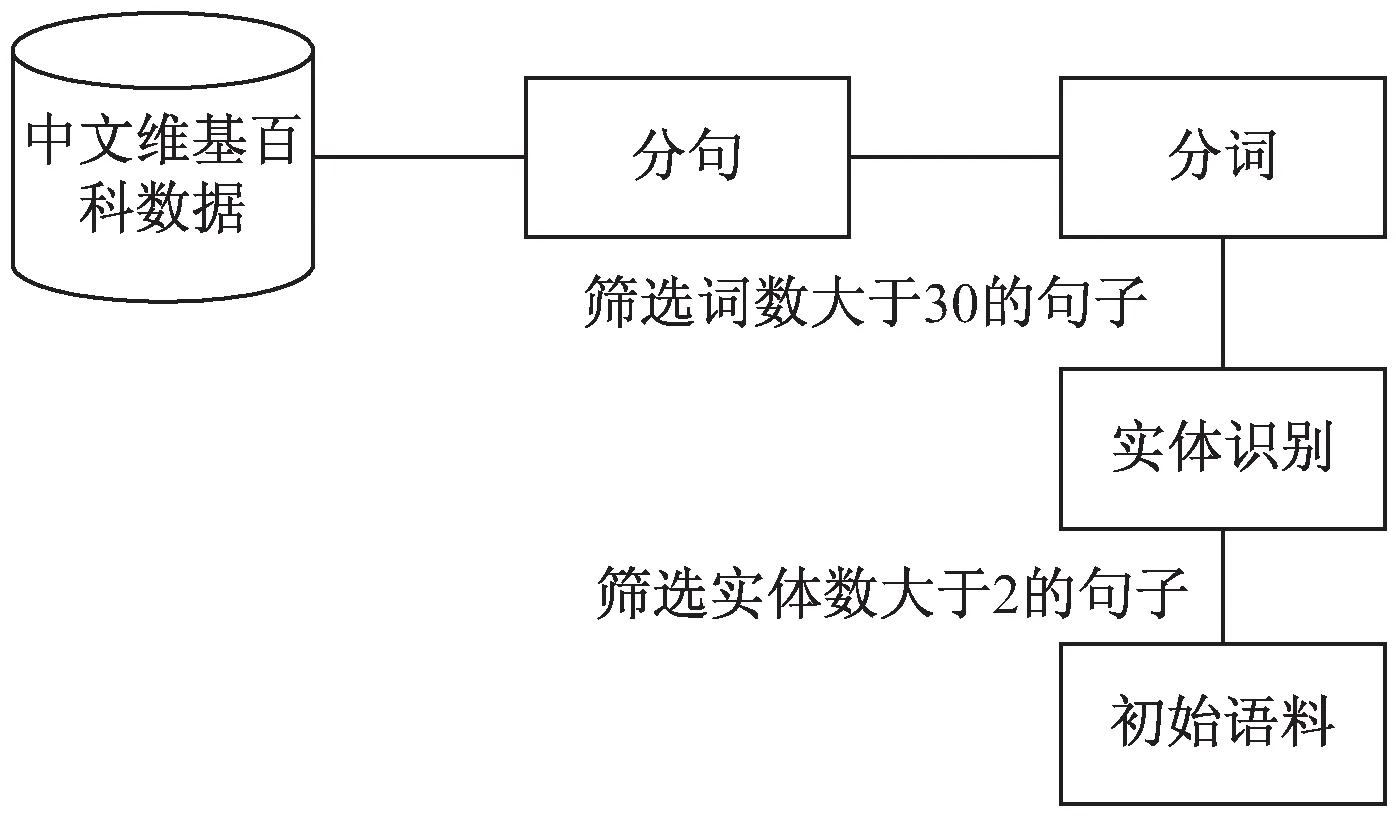
图1 维基百科数据预处理流程
通过对筛选后的复杂长句分析发现,大多数句子都可以采用分解法和指称法[13]进行手工简化。分解法是将长句中的复杂成分独立开来,与相应的成分构成若干短句。以语句“狐猴科是哺乳纲灵长目的一科,是树栖动物,主要分布于非洲的马达加斯加岛”为例。前方主语和后方的并列短语可以直接拆分为结构独立的子句:“狐猴科属于哺乳纲灵长目”“狐猴科是树栖动物”“狐猴科主要分布于非洲的马达加斯加岛”。指称法是指将长句中的复杂成分用一个词语来指代,与相应的成分构成“总说”的单句,再把复杂成分一一展开形成“分说”的单句,变成“总分句群”。以语句“龙卷风是在极不稳定天气下由空气强烈对流运动而产生的一种伴随着高速旋转的漏斗状云柱的强风涡旋”为例,先抽取出句子主干“龙卷风是一种强风涡旋”,再对句子中的复杂成分进行分说“龙卷风由空气强烈对流运动产生”“龙卷风伴随漏斗状云柱”。
从预处理后的长句数据中随机抽取出4 000条长度大于30的句子,并按照上述方法对筛选出的句子进行手工简化。
第二,利用回译的方法,从英文的长句简化语料中获取原始数据,再从中筛选出2 000条数据。这一部分语料来源于WikiSpilt[14]。WikiSpilt数据集是从英文维基百科编辑历史数据中收集而来的,包含100万条句子简化实例。首先,利用谷歌翻译接口对原始数据集进行翻译,删除翻译后词语缺失、重复、翻译错误的噪声数据。然后,利用LTP工具对句子进行分词和实体识别,筛选出实体数目大于2且原始句子长度大于30的句子及其简化子句,再从中随机挑选出2 000条数据。最后,将两部分数据合并得到6 000条长句简化数据。
2 基于长句简化的中文开放关系抽取
关系抽取模型的大致工作流程如图2所示。以图中句子“斯坦福大学于1891年由时任加州参议员及州长的铁路大亨利兰·史丹福和他的妻子创办”为例。先通过长句简化模型将句子简化为“斯坦福大学于1891年创办”“斯坦福大学由亨利兰·史丹福创办”“亨利兰·史丹福时任加州州长”三条简单句。随后再利用关系抽取算法对每个子句进行抽取,得到关系三元组数组:(斯坦福大学,创办于,1891年);(亨利兰·史丹福,创办,斯坦福大学);(加州,州长,亨利兰·史丹福)。接下来将对长句简化模型、关系抽取两个部分内容分别进行介绍。
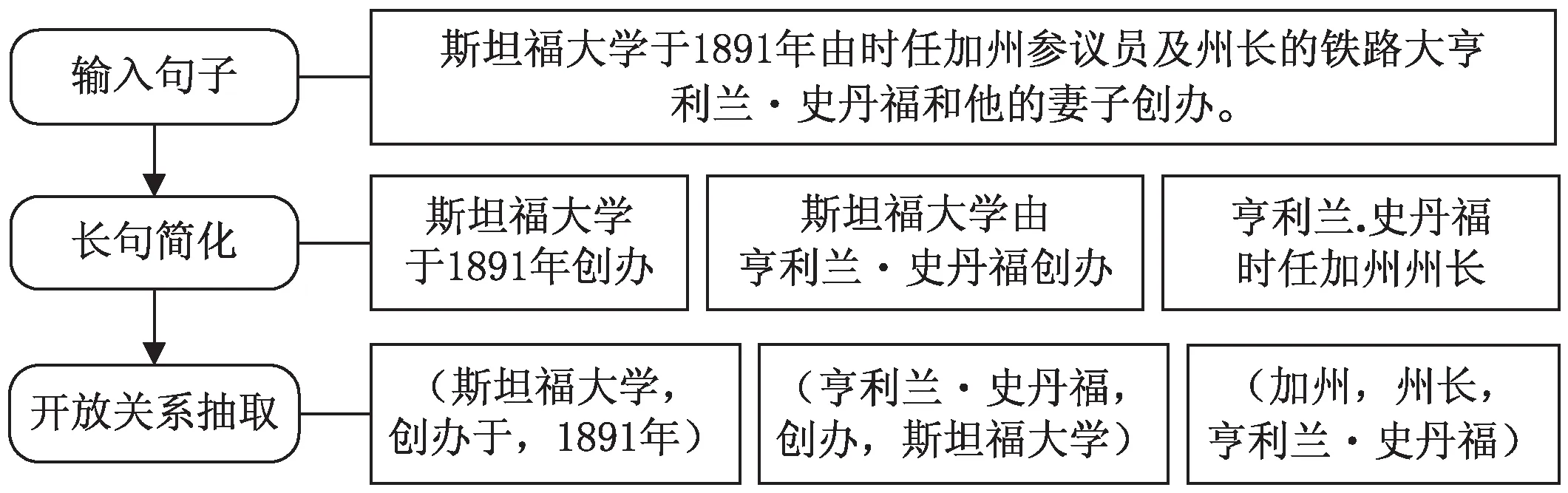
图2 基于长句简化的关系抽取流程
2.1 长句简化模型
目前关于中文复杂长句的简化主要是利用符号进行分割[15-17]。但基于符号分割的句子,仅能分割出原本结构独立的子句,部分结构不独立的子句中仍然包含有关系数据。并且根据对上文构建的复杂长句数据集的统计发现,在复杂长句中还存在许多没有逗号的句子。可见利用符号进行长句简化存在着较大的局限性。因此,该文借鉴英文长句简化的思想[18-20],直接利用机器翻译领域的序列到序列神经网络模型对长句简化任务进行建模,将其作为单语言的翻译任务。
现有的序列到序列模型通常采用RNN与LSTM神经网络,存在编码器结构过于简单以及编码阶段信息利用率低的问题,在语料资源较少的情况下,性能较差。BERT[21]模型通过结合多维语义特征获取词向量,可以得到更细粒度的文本上下文表示,极大地提升了模型的特征提取能力。如图3所示,该文以BERT的双向Transformer结构作为基础,构建序列到序列模型。由于本身结构限制,BERT模型通常只用于输入编码,并不能直接适用于文本生成任务。因此,采用UniLM[22]的seq2seq Mask机制对BERT的Transformer结构进行改造,仅对输入部分的第二段文本进行下三角遮掩。这样当Mask字段处在第一段文本时,模型可以利用文本中的所有token信息进行预测。当Mask字段处在第二段文本时,模型可以利用第一段文本的全部token信息,同时还可以利用Mask字段本身和它左侧的全部token信息。通过这种方式,可以实现序列到序列的效果。

图3 长句简化模型结构
为了减少不必要的计算,加快模型训练速度,对BERT模型的vocab.txt文件进行了精简,只保留语料中使用到的token。训练阶段,将复杂句S1和简单句子集S2连接成一个序列,以[SOS]s1[EOS]s2[EOS]的格式输入,S2中各个子句间使用“。”进行分割。根据词表获取序列的Token后,再对序列的词、位置、Segment(用于区分输入序列和目标序列)进行embedding计算,最后将三种embedding求和得到最终的文本向量。英文中各个单词本身带有分隔符,而中文词语通常由多个字词连接组成。原始的BERT模型在预训练过程中,采用的是以字粒度为基础的Mask方式,会分割原本完整的中文词语。因此,引入BERT-WWM[23]预训练模型参数,BERT-WWM利用全词Mask方式进行训练,将同一词语进行整体遮掩,能更好地保证中文句子的语义完整性。
在预测阶段,加载训练好的模型权重,输入待简化长句进行预测,在解码时利用beamSearch搜索算法优化预测序列得到简化句子集。
2.2 关系抽取
在关系抽取部分,仍然采用与主流开放关系抽取一致的思路,利用词性、句法规则进行抽取。然而与传统方法不同的是,该文抽取的句子是经过长句简化模型处理得到的,句子结构简单且类型大致相同。因此,不需要制定丰富、完备的范式,仅需要制定简洁规则进行抽取即可。关系抽取算法的具体步骤为:
(1)利用LTP工具处理简化后的句子,获取词性标注,依存句法分析的结果。
(2)获取句子的主语和宾语作为基础实体。将与句子核心词相连的实体词作为起点向前搜索,如果存在与实体词具有定中关系的名词、名词性动词等,则将其与起点的实体词组合成语义完整的实体。
(3)根据依存句法分析结果找到句子的核心词。
(4)以核心词为起点,对与之相连的词语进行判断。如果存在并列的动词或者动补结构的介词,则将其与核心词组合成新的关系词,如果不存在则直接将核心词作为关系词。
(5)将关系词与对应实体组成关系三元组输出。
(6)将各个子句中抽取出的关系数据进行合并成关系数组输出。
综上所述,关系抽取算法首先按照主谓宾的句法结构进行了抽取,然后在此基础上,对存在定中结构的实体词进行了补充,对关系词相连接的动词和介词进行了处理。
3 实验与分析
从构建的长句简化数据集中抽取出1 000条句子对作为长句简化的测试集,其余5 000条作为训练集。关系抽取部分,从长句简化的1 000条测试数据中抽取出2 479条关系数据,作为关系抽取的测试集。
长句简化部分,采用哈工大的BERT-WWM预训练参数,设置最大序列长度为70,Epochs设为55,初始学习率为1e-5,Beam_search解码时的Beam_size为5。选取SARI值、BLUE值和训练时间作为长句简化模型的评估指标。SARI值通过对比原句、参考子句、预测子句中的词语计算句子的简化性。BLUE值是字符串相似性度量,可以衡量简化子句与原句的相似性。
选用了如下三种基准模型进行长句简化对比实验:
(1)Seq2Seq+Attention:该模型将序列到序列框架与注意力机制结合,是目前研究文本生成任务的标准结构模型。
(2)Pointer-Generator:该模型在Seq2Seq模型的基础上,通过指针网络选择生成词,能有效解决生成过程中出现的未登录词的情况。
(3)BERT+LSTM:该模型采用Seq2Seq基础架构,将Encoder替换为双向Transformer编码,Decoder 采用LSTM。使用BERT模型对编码端参数进行初始化处理,解码端从初始状态训练。
如表1所示,提出的长句简化模型测试结果的SARI值和BLUE值分别为76.67%和60.65%,相比其他基准模型有较好的提升。此外,所提模型的训练时间相比其他模型也有所减少,这是因为BERT模型提供了更丰富的上下文信息,使模型能更快收敛。

表1 长句简化模型对比实验结果
关系抽取部分,将准确率(P)、召回率(R)和F1值作为关系抽取模型的评估指标,计算公式如下:
(1)
(2)
(3)
其中,C1表示抽取结果中正确的关系条数,C2表示抽取的总的关系条数,C3表示测试集中存在的关系总数,F1值是准确率和召回率的调和平均值。
选取了CORE[24]、DSNFS[25]系统进行开放关系抽取对比,CORE利上下文信息及句法结构信息进行开放关系抽取,取得了较好的效果。DSNFS对中文中存在的特殊语言现象进行了总结,提出了一种基于依存语义范式的抽取方法,可以对网络文本进行无监督的灵活的抽取。为了了解长句简化方法对开放关系抽取方法的改进效果,将两种模型分别在原始长句和简化后的句子上进行实验。将在简化句子的实验结果表示为CORE-SS和DSNFS-SS。
从表2可以看出,文中关系抽取方法准确率最高,召回率仅次于DSNFS-SS,这是因为DSNFS的抽取规则更加全面,可以覆盖更多的情况。而CORE-SS与DSNFS-SS相比直接在复杂长句上进行抽取的CORE与DSNFS效果有较大的提升。说明基于长句简化的关系抽取方法,能够有效地提升开放关系抽取系统对复杂长句的抽取效果。
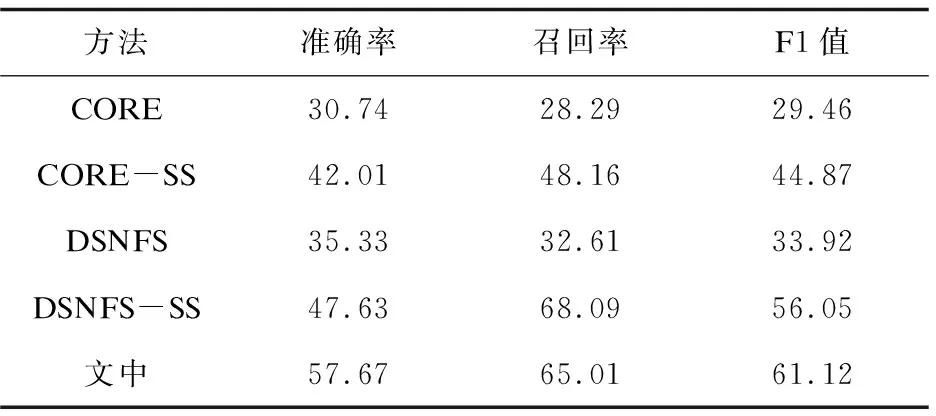
表2 开放关系抽取对比实验结果 %
最后,对抽取中的错误关系数据和未抽取出的关系数据进行了分析,分析结果如表3所示。其中35%的错误是由关系词识别错误产生的,由于该文仅选择了动词词性的词语作为关系词,而部分句子中的关系词是与动词相邻的名词作为关系指示词。其中28%的错误源于嵌套实体,由于在复杂长句中,除了句子本身结构复杂导致的句子长度增长外,还存在句子中实体词较长的情况。该文仅利用自然语言处理工具进行了简单的实体识别,没有处理实体由多个实体嵌套的情形。20%由词性标注导致的错误,由于中文中部分词既可以做动词又可以做名词,自然语言处理工具对这类词的识别容易出错。13%错误来自简化句子内容缺失,由于长句简化模型在句子生成过程中,遗失了部分内容,从而将错误传递给了关系抽取模块。4%由句法分析错误导致,经过长句简化后,大部分的句子都能够得到正确的句法分析结果,然而仍然存在少量句子句法分析错误。

表3 错误分析
4 结束语
该文提出了一种基于长句简化的中文开放关系抽取方法。首先,利用序列到序列模型对复杂长句进行化简,然后,针对化简后的句子进行开放关系抽取。实验结果表明,该方法能有效提高开放关系抽取对复杂长句抽取的准确率和召回率。此外,对实验结果中的错误进行了归纳总结,为之后的研究提供了参考。
猜你喜欢
四川师范大学学报(自然科学版)(2023年1期)2023-03-12
中等数学(2022年2期)2022-06-05
计算机集成制造系统(2020年8期)2020-09-11
小学生学习指导(低年级)(2020年6期)2020-07-25
小学生学习指导(低年级)(2018年9期)2018-09-26
疯狂英语·新读写(2018年2期)2018-09-07
西夏学(2018年2期)2018-05-15
现代语文(2016年21期)2016-05-25
智能系统学报(2015年5期)2015-12-03
——意群—动态对等法
长春大学学报(2012年9期)2012-09-19
