
多跳式机器阅读理解研究进展综述
2023-03-04 06:37仇亚进奚雪峰崔志明盛胜利周悦尧
计算机技术与发展 2023年2期
仇亚进,奚雪峰,3*,崔志明,盛胜利,周悦尧
(1.苏州科技大学 电子与信息工程学院,江苏 苏州 215000;2.苏州市虚拟现实智能交互及应用重点实验室,江苏 苏州 215000;3.苏州智慧城市研究院,江苏 苏州 215000;4.德州理工大学,德克萨斯州 卢伯克市 79401)
0 引 言
机器阅读理解(Machine Reading Comprehension,MRC)任务主要是指通过利用现代人工智能等信息技术,使机器在阅读并掌握理解人类自然语言的基础上,从非结构化文档中寻找合适的答案,回答来自文本内容的相关问题,以此度量机器对自然文本的理解能力。近年来,MRC因其开放性和交互性在学术界和工业界受到越来越多的重视和研究,已经发展成为NLP领域重要的研究热点方向。
机器阅读理解有着悠久的历史,图灵早在20世纪50年代,就曾提出通过人机交互衡量机器的智能水平[1]。然后Terry Winograd提出构想,认为实现阅读理解的三大要素是:语法、语义和推理[2]。Hirschman等人于1999 年开始探索MRC技术的研究,设计出第一个以小学年级故事为语料库的自动阅读理解基线系统Deep Reed[3]。Riloff等人[4]根据人工制定规则,对问题与文章中候选语句的匹配度打分,然后选择最高分的候选语句当作答案。基于传统特征的MRC大都采用模式匹配来提取特征,其鲁棒性差、耗时长、早期发展比较慢。直到Hermann等人[5]于2015年提出使用神经网络模型,该领域才逐渐得到发展。Liu等人[6]于2019年发表一篇关于神经机器阅读理解方法的综述,重点归纳了基于深度学习的MRC方法。Zhang等人[7]于2019年列出并比较了各种MRC数据集的具体特征,并描述一些典型的MRC模型的主要思想。Dzendzik等人[8]于2021年发表一篇关于MRC英文数据集的综述,其详细介绍了数据集的数据收集以及创建过程,并对各个数据集从多维度进行分析对比。
在陈丹琦博士的学位论文中,根据答案形式将MRC任务分为完形填空式、多选式、片段抽取式、自由生成式四种类型,这四类见证了MRC技术的发展[9]。近年来,随着数据集的不断丰富,问题从简单的单询问问题转向更复杂的综合性问题,文本中的答案分布也随之变化,由单段落单片段答案到多片段多答案,从而对MRC的研究也面向更为复杂的多跳式阅读理解领域探索。
面对多种多样阅读理解任务的出现,近年国内学者包玥等人[10]对抽取式MRC任务作了总结;随着深度学习的较快发展,李舟军等人[11]对基于深度学习的MRC任务作了总结,认为高质量的词向量表示仍是MRC任务的研究重点;张超然等人[12]对基于预训练模型的MRC任务作了总结,总结了使用预训练模型的阅读理解模型在相关数据集上的表现;徐霄玲等人[13]对MRC任务的研究技术作了总结,比较了采用不同技术的MRC模型在不同类型数据集上的表现。但目前还没有学者对多跳式MRC任务进行系统地介绍,因此,该文对多跳式阅读理解的典型代表数据集进行介绍分析,对相关模型方法进行分类总结,希望能够对多跳式阅读理解任务的研究起到一定的推动作用。
1 多跳式机器阅读理解
多跳式机器阅读理解(Multi-Hop Machine Reading Comprehension,MHMRC)是指由机器阅读理解与多跳式推理回答交叉形成的新领域,即在传统MRC抽取答案的基础上引入多跳式问答,是MRC任务中重要的一类。多跳推理式阅读理解中的问题一般都是人工提出的复杂的综合问题,在文中不易直接找到答案。面对复杂问题,有可能需要从文本中多次推理才能对答案实现精准定位。具体来说,给定一个问题,系统只通过一个文档或段落是无法正确回答问题的,需要系统逐步结合多处信息来回答,所以需要多跳推理,如图1所示[14]。

图1 多跳阅读理解认知
对于上例问题,由于问题是复杂的组合问题,给出的信息都是一些间接的信息,因此没有办法直接抽取到答案。对于此类复杂问题,需要经历多次“跳转”才能找到答案,所以被称为MHMRC问题,可以看出,多跳问题比一般的单跳问题要复杂得多。
2 多跳式MRC相关数据集
数据集是支撑神经网络模型得以快速发展的基础,大规模MRC数据集的出现促进了神经机器阅读模型更好地发展。传统的单跳式阅读理解数据集中一直聚焦于“文章段落-问题-答案”三者之间的联系,从而忽略了真实情况中多跳问答具有的承前启后、逐步推理的性质。随着研究者不断深入探索多跳式MRC,各种具有挑战性的数据集被提出,其数据集规模不断增加并且答案类型不断丰富,越来越接近真实场景。多跳式数据集中的问题,系统需要根据多篇文档来回答,即需要多跳推理来锁定答案。目前,具有代表性的多跳式MRC数据集主要包括QAngaroo[15]、HotpotQA[16]等。QAngaroo与HotpotQA的发布,不仅推动了该类问题的研究,也推动了MRC的发展。
2.1 QAngaroo
QAngaroo是2017年伦敦大学学院推出的多文档推理阅读理解数据集。它由两个数据集组成:WikiHop和MedHop,它需要多个推理步骤,将来自多个文档的事实结合起来。
WikiHop是开放域,来源于维基百科文章,是一个多跳问答数据集。WikiHop的查询由来自WikiData[17]的实体和关系构成,而支持文档来自WikiReading[18]。与WikiHop格式相同,MedHop数据集基于医疗库PubMed的研究论文摘要,查询是关于药物对之间的相互作用。必须通过结合来自药物和蛋白质的一系列反应的信息来推断出正确的答案。
根据不同类型的任务以及所使用的数据集,对模型的推理能力要求各不一样。QAngaroo最大的特点是要从多篇文章中找相关文档,结合多个文档的多个推断步骤,联合文本多处进行综合推理,问题的答案不能从一个段落中单独得出。随着推理跳数的增加,统计距离逐渐变远,与问题的相关性逐渐变小,因此,QAngaroo对于算法设计和分析多段落的能力提出了很高的要求。
2.2 HotpotQA
2018年由卡耐基·梅隆大学、斯坦福大学、蒙特利尔大学和Google公司等联合推出多段落推理阅读理解数据集HotpotQA[16]。HotpotQA拥有11万个基于维基百科问答对段落,是一个以自然的、多跳的问题为特征的问答数据集。HotpotQA不仅要将模型需要读的文本范围从单段落扩展到多段落或多篇章段落,还要求模型可以对支持答案的证据之间的逻辑关系构建至少两步的推理链,这比单跳式MRC更有挑战性。
HotpotQA包含比较问题和是/否问题,涵盖了围绕实体、位置、事件、日期和数值的各种问题。HotpotQA作者从数据集中抽取了100个例子,发现HotpotQA涵盖了广泛的答案类型,这与笔者对问题类型的初步分析相匹配,其中大多数问题都是关于文章中的实体(68%)和包括各种属性(如日期(9%))以及其他描述性属性(如数字(8%)和形容词(4%))的不可忽略的问题。
与QAngaroo数据集相比,HotpotQA数据集无论是在训练集还是在测试集的数据量上都有成倍的增加,且增加了带干扰设置的数据集,更为复杂,如表1所示。
另外,为了证明模型的确有利用原文中的相关证据进行推理并提升模型的可解释性,HotpotQA不仅要求模型给出最终答案,还要给出推理所用到的支持性事实。
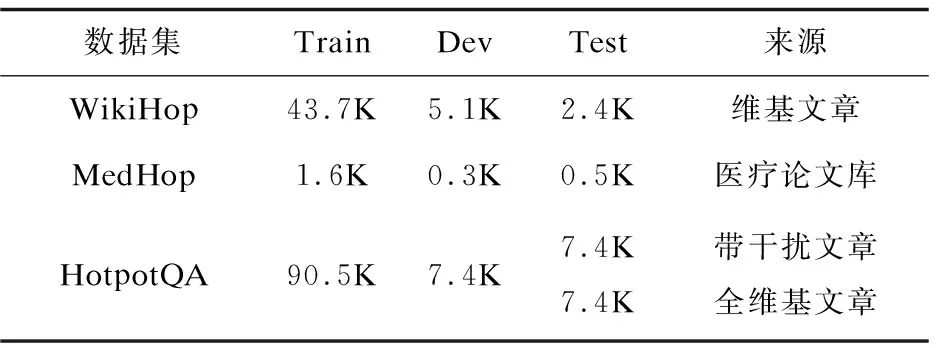
表1 数据集对比
2.3 数据集评估标准
不同的MRC任务有不同的评估指标,可信的评估标准是衡量模型理解自然语言能力的关键参考指标。对于MHMRC任务,需要模型对比预测所得答案和真实答案。通常使用精确匹配(EM值)和模糊匹配(F1值)进行评价。
EM值指的是模型的预测答案和给出的正确答案完全相同的比例。F1值指的是模型的预测答案和正确答案的覆盖率,通过计算准确率(Precision)与召回率(Recall)得到,即使模型的预测答案和正确答案不完全相同也可得分,是一种模糊匹配计算。其计算公式如下:
(1)EM值。
(1)
其中,Npa表示模型的预测答案和真实答案完全匹配的数量,Nta表示真实答案的总数量。
(2)F1值。
(2)
(3)
(4)
其中,Nptw表示预测正确的单词/字符数目,Npaw表示所预测答案的所有单词/字符数目,Ntaw表示真实答案的所有单词/字符数目。
3 多跳式MRC相关模型方法
传统的基于机器学习的MRC模型采用模式匹配进行特征提取,性能提升有限,已不能满足多文档多答案以及复杂问题的需求。随着深度学习的研究发展,基于神经网络的MRC模型发展很快。循环神经网络(RNN)、卷积神经网络(CNN)、长短时记忆网络(LSTM)、门控循环单元(GRU)、注意力机制等深度学习方法和图神经网络的出现大大推动了MRC的发展。近年来有很多学者基于注意力机制来研究MHMRC,与此同时,随着图神经网络技术的不断发展,也有学者就此展开对MHMRC的研究,考虑到有些复杂的问题其实可以拆分成简单子问题,而问题的答案就在这些子问题中,也有学者提出将复杂问题分解成若干子问题来解决MHMRC问题。
因此,目前对于MHMRC任务的解决方案根据方法主要分为基于注意力机制方法、基于图神经网络方法以及基于问题分解方法三种。
3.1 基于注意力机制方法
由于受到人类视觉神经系统可以快速发现较远处视野中的重点关注区域的启发,计算机视觉领域早在2000年就提出注意力机制概念[19]。自然语言处理模型在读取文本时也可以效仿图像处理,重点关注和任务相关的文本内容。基于此,Bahdanau等人[20]于2014年在机器翻译(NMT)任务上应用注意力机制,同时进行翻译和对齐工作,显著提升了译文质量,这是首次在NLP领域中使用注意力机制。Hermann等人[5]将注意力机制应用于MRC模型中,大大的提升了模型准确率。自此,注意力机制很快被推广应用到各种自然语言处理任务中。
MRC中最核心的任务就是上下文的语义推理,一般是将单层网络模型经过多次迭代计算语义从而包含更多相关语义信息,在每一层的更新词语计算中加入注意力机制,注意力机制应用在MRC模型中读取文本时重点关注与问题相关的文本部分。面对使用注意力机制的MRC模型无法充分利用上下文与问题之间的关联信息,只是单向的应用以及只应用于文本中部分内容,Seo等人[21]提出双向注意力流网络结构BiDAF,这是一个根据不同粒度分成多阶段来获得问题感知的上下文表示结构。在此基础上,Liu等人[22]提出一种新的基于注意力的机器理解任务神经网络模型—双重交互模型(DIM Reader),用于研究文本的理解能力,该模型构建了多跳的双重迭代交替注意力机制。Li等人[23]提出一种基于双向注意流(BiDAF)模型和词向量结合的方法,该模型使用双向注意流机制来捕捉上下文和问题之间的注意力。Xu等人[24]提出一个由粗到细的注意力网络,设计了一个多阶段分层模型BiDMF,其上下文和问题由双向LSTM RNN编码;然后通过注意力机制的多次迭代,得到更准确的交互信息。
自注意力(Self-Attention)[25]是注意力机制的一种改进,即查询来自源文本序列自身,用于建模源文本序列内部元素间的依赖关系,以加强对源文本语义的理解。Wang等人[26]提出了门控自匹配网络R-Net,首次将自注意力机制应用于MRC模型。MHMRC需要结合多篇文章的信息和推理来推断答案的能力。Zhuang等人[27]引入动态自注意力网络DynSAN来完成多篇文章的阅读理解任务,它在标记级处理跨篇文章的信息,同时避免大量的计算开销。针对现实生活中很多问题的答案往往由多个片段组成,苏立新等人[28]提出面向多片段答案抽取的阅读理解模型BertBoundary,该模型采用预训练Bert作为底层结构来理解问题和文本,再利用序列标注建模多个答案片段。面对具有挑战性的多跳生成任务(叙事任务),Bauer等人[29]提出多跳指针生成器模型MHPGM,如图2所示。

图2 多跳指针生成器模型框架
MHPGM编码器使用双向注意力结合自注意力的混合注意力机制来执行多跳推理,并使用指针生成解码器来有效地读取和推理长文章,合成与问题一致的答案。MHPGM模型框架由Embedding Layer、Reasoning Layer、Self-Attention Layer、Pointer-Generator Decoding Layer四部分组成。各部分功能结构列举如下:
•嵌入层:用一个学习过的d维嵌入空间嵌入上下文和问题中的每个单词,通过来自语言模型(ELMo)的预嵌入获得每个单词的上下文感知嵌入。
•推理层:推理层由k个推理单元组成,使嵌入的上下文通过k个推理单元传递,使用BiDAF模拟多跳推理过程中的单个推理步骤。
•自注意力层:作为答案生成之前的最后一层,利用剩余静态自我注意机制来帮助模型处理具有长期依赖性的长上下文。
•指针生成器解码层:使用一个注意力指针生成解码器并从上下文中复制来创建答案。
随着注意力机制的快速发展,Song等人[30]提出一种新的全局注意力推理(GAI)神经网络结构,它通过动态终止的多跳推理机制从结构知识中学习有用的线索来回答完形填空式的问题。Duan等人[31]提出一种端到端的深度学习模型来回答多选题。该模型采用双GRU对文章和问题进行上下文编码,并通过六种注意力函数对给定文章和问题之间的复杂交互进行建模,然后利用多层次的注意力转移推理机制,进一步获得更准确的综合语义。针对现实生活中的问题多样性,谭红叶等人[32]对此展开研究,提出一种基于Bert的多任务阅读理解模型,该模型先对问题分类预测,然后利用双向注意力机制来捕获问题和篇章的关系,从而回答多样性问题。Zhong等人[33]提出一种新的问答模型—粗粒度细粒度知识网络(CFC),CFC应用协同注意力和自我注意力来学习候选、文档和实体的查询感知节点表示。由于RNN的顺序性,基于注意力机制的循环神经网络阅读理解模型在训练和推理方面较慢,Zheng等人[34]提出一个新的多粒度MRC模型,该模型利用图注意网络来获得不同层次的表示,对两个粒度答案之间的依赖关系进行建模,从而为彼此提供证据。最近,Wu等人[35]利用选择引导策略(S2G)以由粗到细的方式精确检索证据段落,并结合两种新颖的注意机制,设计出符合多跳推理本质的MRC模型。
综上所述,可知在MRC任务中结合注意力机制的模型层出不穷,表2以时间顺序梳理了近五年来不同注意力机制应用在MRC中的典型模型方法及主要贡献。

表2 基于注意力机制方法的典型MRC模型及主要贡献
3.2 基于图神经网络方法
图神经网络的概念最初由Gori等人[36]于2005年提出,并在Scarselli[37]等人的文章中进一步阐述。最近几年,深度学习方法在图上得到了广泛的探索与研究。在CNN、RNN和深度自动编码器的基础上,衍生出很多处理图数据的神经网络结构,即图神经网络(GNN)。按照其建模方式的不同,将图神经网络划分为图卷积网络(GCN)、图注意力网络(GAN)、图自编码器(Graph Auto-encoders)、图生成网络(GGN)和图时空网络五大类别。
目前,图的深度学习和NLP的交叉研究浪潮影响着很多NLP任务,人们应用和开发不同的GNNs变体并在诸多NLP任务中取得相当大的成功。陈雨龙等人[38]对图神经网络在自然语言处理中的不同应用进行系统论述,认为如何用图来建模不同任务中的关键信息是未来工作中的重点。Song等人[39]探索过基于图结构的MRC任务,主要解决MRC中的多跳语义关联问题。Su等人[40]提出用于问题生成的多跳编码融合网络(MulQG),MulQG使用图卷积网络在多跳中进行上下文编码,并通过编码器推理门进行编码融合。受人类推理过程的启发,Tang等人[41]从支持文档中构建了基于路径的推理图,该图结合基于图的方法和基于路径的方法,更适合多跳推理。
对于需要通过多次跳转一组文档才能得到正确答案的问题,模型需要:(1)选出和问题相关的段落;(2)找出段落中有力的支持证据;(3)根据收集到的证据推理出正确答案。基于图神经网络其固有的消息传递机制,可以通过图传播多跳信息,Fang等人[42]提出一种用于多跳问题回答的层次图网络(HGN),该模型通过层次框架中的多级细粒度图来支持联合回答/证据预测,对每个问题,HGN不是只使用实体作为节点,而是构建一个层次图来从不同粒度级别(问题、段落、句子、实体)中获取线索,HGN模型各部分如图3所示。

图3 HGN模型架构
HGN主要由四部分组成,图构造模块:用于构造分层图以连接不同粒度信息,其中分层图需要分两步构建,首先要识别出和问题相关联的各段落,然后再添加所选段落中各级实体(句子/实体)之间联系的边;上下文编码模块:也就是通过基于RoBERTa的模型编码器得到图中各个图节点的初始表示;图推理模块:在上下文编码完成后,HGN对分成图推理,通过图神经网络将上下文表示的图节点转换成更高级的特征,并利用基于图注意力的方法完成节点的表示更新;多任务预测模块:图推理完成后,更新的节点表示被用于不同的子任务(选择段落+寻找支持证据+实体预测+提取答案),完成这些子任务后才得到答案。
由于层次图可以应用于不同的多跳问答数据集,为了推广到其他需要使用较长文档的数据集,可使用基于滑动窗口的方法将长序列分成短序列,或者用能够处理长序列的其他基于变压器的模型代替基于Bert的主干。Song等人[39]基于共同参考全局信息或滑动窗口构建实体图,提出一种新的模型MHQA-GRN来更好地连接全局证据,形成了更复杂的图。Tu等人[43]通过添加文档节点以及在文档、实体和候选答案之间创建交互来丰富实体图中的信息,引入一种具有不同类型节点和边的异构图,称为异构文档实体图(HDE),HDE使用基于图神经网络(GNN)的消息传递算法来积累证据。
可解释的多跳问题回答需要对多个文档进行逐步推理,并找到分散的支持事实来回答问题。已有工作提出用实体图方法来聚合实体信息,提高推理能力。然而,实体图有时也会丢失一些对理解语义也很重要的非实体信息。此外,分布在噪声句子中的实体可能会误导推理过程。为此,Zhang等人[44]提出一种粗粒度和细粒度图网络(CFGGN),CFGGN是一种结合句子信息和实体信息来回答多跳问题的新的可解释模型,由执行句子级推理的粗粒度模块和进行实体级引用的细粒度模块组成。为解决多跳问答模型在没有正确推理的情况下反而得到正确答案的偏差问题,Lee等人[45]提出一种学习证据的新方法,决定答案预测是否得到正确证据的支持。为处理动态和复杂的问题,Xu等人[46]提出一种新的方法,通过动态地构建语义图并对其进行推理,在为多跳问答提供可解释性证据的同时,发掘更多的有效事实。
通过上述分析可知,近年来基于图神经网络方法来研究MRC任务逐渐兴起,其相关典型模型方法及主要贡献如表3所示。

3.3 基于问题分解方法
MHMRC具有挑战性,因为它需要跨多个段落收集证据来回答一个问题,并且需要对两个证据如何相互关联进行更复杂的推理。多跳问题大都为复杂的问题,然而复杂问题可以分解为若干单跳问题。在单跳MRC中,系统可以使用单个句子获得良好的性能。基于此,Min等人[47]于2019年提出一个用于多跳RC的系统DECOMPRC,其学会使用原始问题的跨度将组合多跳问题分解成简单的单跳子问题。此外,他们还提出一种重排序方法,从不同的可能分解中获得答案,并用答案重排序每个分解,以决定最终答案,而不是一开始就决定分解。同年,Min等人[48]认为问题组合性不是多跳推理的充分条件,即使是高度复合的问题,如果这些问题针对的是特定实体类型,或者回答这些问题所需的事实是多余的,也可以用一跳来回答。为此,他们提出一个基于单跳Bert的阅读理解模型,如图4所示。
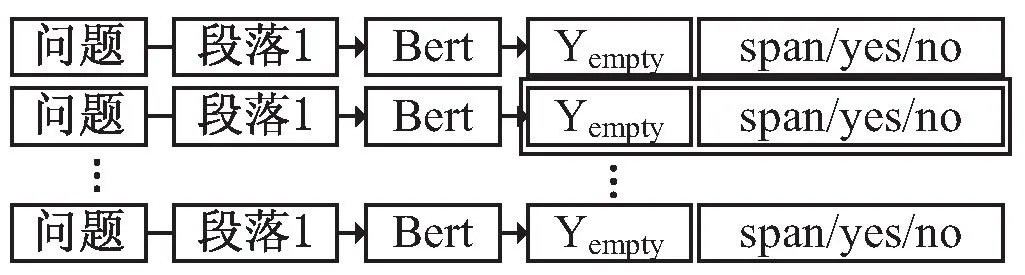
图4 单段落Bert模型
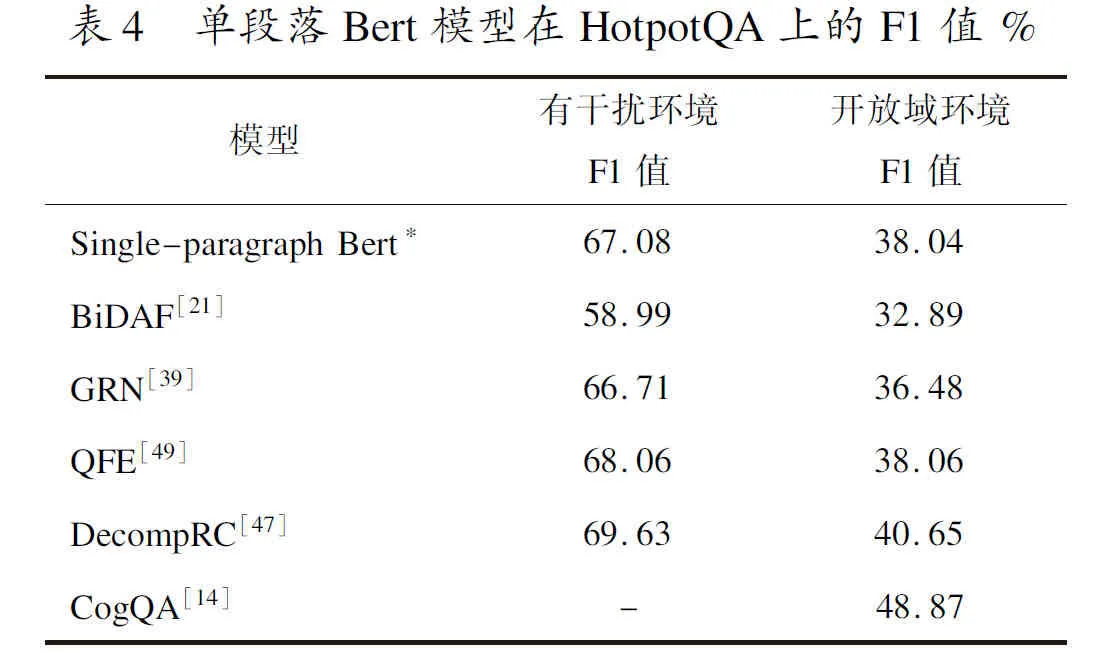
单段落Bert模型分别对每段进行评分和回答,然后从yempty得分最低的段落中得到答案。其中yspan、yyes、yno和yempty分别表示答案是有跨度区间、是类型、非类型或没有答案类型。如表4所示,与代表性模型相比单段落Bert模型在多跳数据集HotpotQA上F1值达到67.08%。这表明大多数HotpotQA问题都可以使用单跳模型加干扰物设置来回答。最后,他们还设计一个评估环境,在这个环境中,人类没有看到预期的多跳推理所需的所有段落,但仍然可以回答80%以上的问题,同样表明大多数组合问题都可以分解成单跳问题。
通过研究多跳问题的最佳表现模型是否像人类一样理解潜在的子问题。2020年,Tang等人[50]采用神经分解模型为多跳复杂问题生成子问题,然后提取相应的子答案。此外还提出一个新的模型来提高回答子问题的性能,这项工作朝着构建一个更易于解释的多跳质量保证系统迈出了重要一步。2021年,Cao等人[51]引入粗粒度复杂问题分解(CGDe)策略,在没有任何附加注释的情况下将复杂问题分解为简单问题,并结合细粒度交互(FGIn)策略,以更好地表示文档中的每个单词,提取与推理路径相关的更全面准确的句子。
4 结束语
该文归纳总结了目前多跳式机器阅读理解的概念和多跳领域的数据集,以及常用的模型方法,即基于注意力机制、图神经网络、问题分解的三种多跳式MRC模型。
针对当前多跳式MRC任务发展中存在的难点和挑战,提出以下几点未来研究方向:
(1)目前针对多跳式MRC中文数据集很少,中文数据集与英文数据集在语法结构、语义分析、语序等多方面存在较大差异,如何构建一个好的面向多跳领域的中文数据集仍然是一个巨大的挑战。另外,面向各专业领域数据集相对较少,各行各业如何结合行业发展趋势,推出各自领域的相关数据集,这也是NLP各任务未来必不可少的研究。
(2)从上述研究方法中,不难发现能否设计出高效准确的推理方法至关重要,如何结合注意力机制以及图神经网络设计出合理高效的推理方法仍是研究热点之一。
(3)在实际情况下MRC模型的输入是很复杂的,对于一些夹杂着噪声的输入常常影响模型的泛化性能,因此如何增强模型鲁棒性的研究也是一个巨大的挑战。
(4)人类在解答问题时通常会联想到问题的相关背景以及有关联的信息等,而阅读理解模型在寻找答案时所考虑的信息都来自于给定文档,没有融合外部知识来理解文章,可想而知,效率以及准确度大大下降。因此,如何引入外部知识并与MRC模型相结合来提升模型准确率,也需要深入探讨研究。
猜你喜欢
客联(2022年3期)2022-05-31
小雪花·成长指南(2022年1期)2022-04-09
中国新闻周刊(2021年26期)2021-07-27
小学阅读指南·低年级版(2020年9期)2020-10-12
阅读(快乐英语高年级)(2020年9期)2020-01-08
散文诗(2017年17期)2018-01-31
传媒评论(2017年3期)2017-06-13
信息安全研究(2016年4期)2016-12-01
第二课堂(课外活动版)(2016年2期)2016-10-21
读写算(下)(2016年11期)2016-05-04
