
基于知识图谱的炒货食品抽检数据可视化系统研究
2023-03-03 13:12乔青青郝莉花马江涛罗莉仝莹莹
食品工业 2023年2期
乔青青,郝莉花*,马江涛,罗莉,仝莹莹
1. 河南省产品质量监督检验院(郑州 450000);2. 郑州轻工业大学(郑州 450000)
《食品安全法》明确提出我国对食品安全的管理由被动应对向主动预防转变,而预防机制基础就是食品安全大数据的应用[1]。
在我国,《关于“十三五”时期加强食品药品监管网络安全和信息化建设的指导意见》等多个文件[2-4]要求推进食品安全大数据建设。
《中共中央国务院关于深化改革加强食品安全工作的意见》[5]中指出“完善抽检监测信息通报机制,依法及时公开抽检信息”,这也为大数据在食品抽检领域分析提供了政策支持。
自食品安全抽检信息发布以来,目前已公布690万余批次的抽检结果[6],但传统的数据分析较为简单[7-8],无法满足智能监管的需求。
作为传统的休闲食品,近年来炒货制品的质量问题也受到广泛关注[9-11]。从公布的抽检结果看[12-14],炒货食品的不合格率较高,加强对炒货食品监管尤为重要。
网络爬虫技术可用于收集媒体网页中的数据,抓取有效信息并加以存储[15]。Neo4j数据库是一种以图的形式来存储信息的非关系存储数据库,相比传统数据格式,Neo4j数据库信息更加直观[16-17]。知识图谱(knowledge graph,KG)是以图的形式表现客观世界中的实体(概念、人、事物)及其之间关系的知识库[18-20]。
此次研究以已公布炒货食品抽检数据为基础,建立基于Neo4j及Django食品可视化分析系统,为智能化监管提供技术支持。
1 材料与方法
1.1 数据来源
数据来源主要从以下网站获取:国家市场监管管理局,http://www.samr.gov.cn/;国家市场监督管理总局食品安全抽检监测司,http://www.samr.gov.cn/jg/sjzz/201812/t20181218_278197.html;食品科学网,http://www.chnfood.cn/;中国食品安全网,https://www.cfsn.cn/;食安通,http://www.eshian.com/。
1.2 试验操作环境及技术
操作系统为Ubuntu 16.04;开发语言为Python 3.5.2;数据库为Neo4j和MySql;服务器为Django 1.11.8;前端相关API为Echarts,font-awesome,ChinaMap,dataTable和bootstrap等;Python相关API为pymsql,py2neo,PyTorch,jieba,spark,pytz和geoip等。
1.3 系统模块设计
系统主要包括的数据获取、数据清洗、数据质量控制、构建知识图谱、构建系统整体模块,见图1。系统结构见图2。
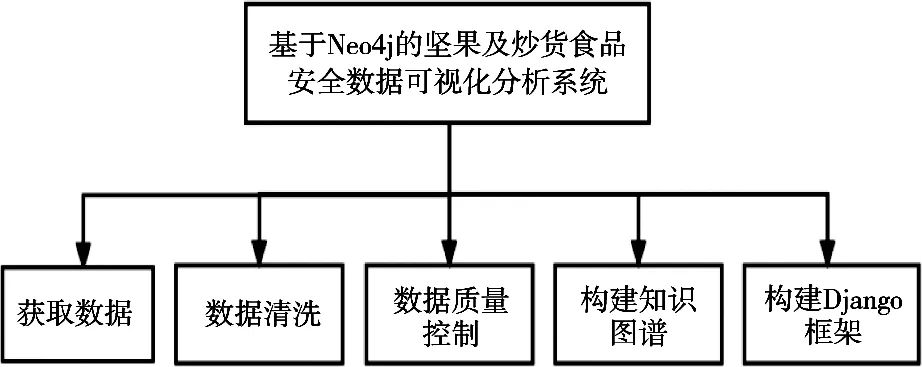
图1 系统整体模块结构图
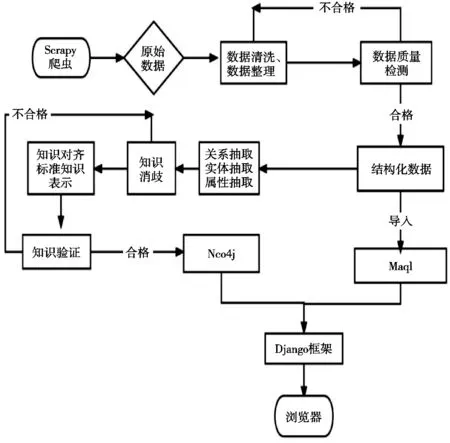
图2 系统整体结构图
1.3.1 获取数据模块
获取的数据模块主要使用Scrapy爬虫收集食品安全相关信息,收集食安通、国家市场监督管理总局、各省份市场监督管理局等网站上的各年食品抽检不合格信息登记表。
1.3.2 数据清洗模块
获取数据后,需要进行数据清洗。数据清洗模块包括删除无分析价值抽检数据(有些抽检数据缺失值过多,无分析价值)和清理与食品无关的脏值数据。在无分析价值的抽检数据处理时,抽检数据中不合格各项和检测结果缺失数据要进行删除,被抽检单位所在地缺失要进行填充,填充的方法为根据被抽检企业和发布单位数据条中进行地点抽取。与食品无关的脏值数据处理,直接删除即可。
1.3.3 数据质量控制模块
数据质量控制需要人工和程序共同完成,人工发现数据的质量出现问题,撰写程序进行再清洗。
1.3.4 构建知识图谱模块
知识图谱构建要对数据清洗完成后的数据进行实体抽取、关系抽取、属性抽取、知识消歧、知识对齐、标准知识表示、知识验证、导入Neo4j数据库。
1.3.5 构建Django模块
使用Python的第三方库django框架,构建django项目。从Mysql中调用构建好的数据集,并调用Neo4j中的数据接入项目接口。
2 结果与分析
2.1 Scrapy爬虫收集食品安全相关信息
在数据搜集阶段项目借助Scrapy框架对食安通(www.eshian.com)、国家市场监督管理总局、各省市场监督管理局官网进行收集,共收集2016—2020年坚果与炒货食品抽检不合格信息登记表1 932条。
2.2 数据清洗与整理
用scrapy框架收集到的坚果与炒货食品数据多为csv表格文件,其内容多包括标称生产企业名称、标称生产企业地址、被抽样单位名称、被抽样单位地址、食品名称、规格型号、商标、生产日期、不合格项目、检验结果、标准值、检验机构、备注等。
根据分析需求,序号、商标、备注列没有分析价值,因此利用pandas库读取所有收集到的csv文件并删除这3列。根据标称生产企业地址、被抽样单位地址这2列可以分析出产品的生产地址。根据不合格项目、检验结果、标准值可获得产品不合格项目的分类,因此增加2列,分别为不合格项目分类和产地。并对数据做进一步整理,得到包括产品名称、型号规格、不合格项目分类、不合格项、年份、产地的数据列。
2.3 数据导入数据库
2.3.1 数据导入Neo4j数据库
该模块借助Neo4j数据库,对食品抽检信息分析模块中的数据进行节点和关系的提取,将基础数据整合成年份、产品类别、不合格产品、不合格项目、不合格项目分类、省份6个节点,依照节点间的关系生成知识图谱json文件,通过Ajax技术在浏览器端生成知识图谱,可以借助图谱更加清晰地看到抽检不合格数据之间的联系。详见图3。

图3 坚果及炒货食品知识图谱图
2.4 可视化展示
在这个模块中对数据按照地区、名称、年份、超标项目等维度进行统计处理,并且借助ChinaMap,Echarts等前端接口将统计结果以图表的形式返回给用户。从收集的坚果与炒货的数据看,不合格指标分为微生物、污染物、理化指标、食品添加剂4个类别。可视化展示分为7个模块,模块数据可动态更新。
2.4.1 不合格省份展示
各省抽检不合格情况采用3种方式展示,分别为柱状图、地图、扇形图展示,详见图4和图5。从图4和图5中可以直观看出:坚果与炒货食品中不合格样品批次较多的省份为广东,其次为浙江、江苏;不合格样品较多的省份主要集中于南部地区。

图4 生产省份抽检不合格柱形图
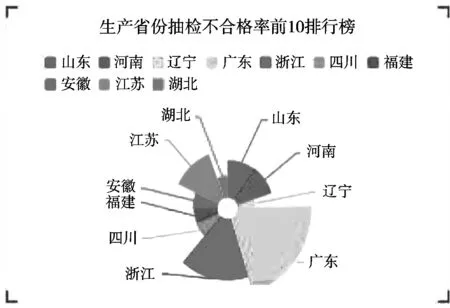
图5 生产省份抽检不合格扇形图
2.4.2 各年度不合格情况表
该部分展示的为每年度的抽检情况及不合格占比。2016—2020年,不合格批次较多的为2018年度,其次为2016年度。详见图6。
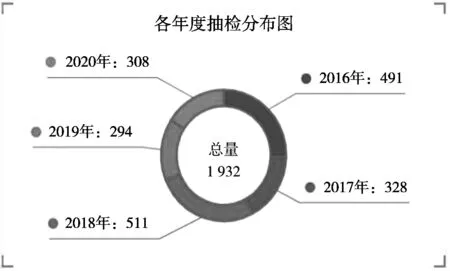
图6 抽检不合格批次年度分布表
2.4.3 不合格产品排名展示
该部分展示的为不合格批次较多的食品类别。从收集数据看,坚果与炒货食品不合格批次较多的为鱼皮花生、开心果、花生米等,详见图7。

图7 抽检不合格食品品种图
2.4.4 超标项目类别排名展示
通过此模块,可展示出不合格的主要指标分类,从目前收集数据看,坚果与炒货食品中不合格率最高为理化指标,其次为微生物项目。详见图8。

图8 抽检不合格项目分类图
3 结论与讨论
通过系统的可视化展示,坚果与炒货食品不合格批次较多的省份主要为广东、浙江、江苏等南部省份,主要是由于南部省份气温较高,坚果与炒货食品作为高蛋白、高油脂的食品,在生产、运输、贮藏及销售过程中,若环境温度或保存不当,易造成酸价、过氧化值超标及微生物超标。从不合格样品看,不合格批次较多的为鱼皮花生。鱼皮花生是以花生、白糖、面粉为原料加工的食品,花生包裹在以面粉和白糖制作的外壳内。鱼皮花生不合格批次较多,有可能是由于该类产品在保存中易造成花生的品质下降,也有可能是生产者在加工时选用品质较差的花生,造成该类产品不合格批次较多。
猜你喜欢
儿童时代·快乐苗苗(2022年10期)2022-12-09
数学大王·低年级(2022年5期)2022-05-21
肝博士(2021年1期)2021-03-29
当代水产(2019年11期)2019-12-23
启蒙(3-7岁)(2018年10期)2018-10-13
儿童时代·快乐苗苗(2016年4期)2016-11-07
学苑创造·A版(2016年7期)2016-07-06
中国土地科学(2014年4期)2014-03-01
