
基于矢量地图的自主代客泊车定位算法研究
2023-03-03 07:09张天奇曹容川
汽车工程师 2023年1期
张天奇 曹容川
(中国第一汽车股份有限公司研发总院,长春 130013)
1 前言
自主代客泊车(Automated Valet Parking,AVP)技术近年来受到广大学者和研究人员的关注。由于AVP 系统工作场景大多为停车场内部,导致全球定位系统(Global Positoning System,GPS)无法正常工作,因此,稳定的、高精度的定位模块是其能够正常运行的关键。使用惯性测量单元(Intertial Measurement Unit,IMU)和轮速数据能够对自动驾驶车辆的惯性数据进行测量进而推算车辆的位置以及姿态信息。虽然通过上述传感器的测量值能够在短期内得到精准的位姿估计结果,但是由于缺少绝对的观测数据,使系统在长时间运行时其定位结果会因累积误差的存在而产生“漂移”现象。因此,使用额外的传感器实现对AVP 系统中定位数据的观测是非常必要的。传感器采集的实时数据与先验地图的匹配是解决该问题的有效手段,根据所采用传感器的不同,现阶段的研究方法可以分为基于激光雷达[1]和基于视觉2类。
通过发射激光束对目标进行探测,激光雷达能够实现厘米级测距精度[2-5]。虽然基于激光雷达的匹配定位算法[6-9]能够实现高精度的位姿输出,然而在应用时仍然存在问题:点云地图数据量较大,不利于车载存储;激光雷达的成本较高,在现阶段的量产车型中无法应用。因此,该类方法主要在科研中开展。
近年来,基于车载摄像头的视觉定位算法在AVP 定位系统中的应用得到研究人员的广泛关注,例如基于视觉的实时定位与建图(Simultaneously Localization and Mapping,SLAM)技术。在传统的SLAM 技术中,自动驾驶车辆能够在迭代更新局部特征地图的同时实现其自身定位,且定位结果精准度较高,其中具有代表性的方法有VINS-MONO[10]、ORB-SLAM[11-13]等。然而,因其使用视觉特征点的方式表达周围环境,该方法的鲁棒性不足且难以解决,这是由于视觉传感器的工作原理导致其对光照等因素的不稳定性所造成的。
为解决视觉定位系统不稳定的问题,本文提出一种基于矢量地图的AVP 场景定位算法,将视觉语义特征与矢量地图进行匹配,并融合IMU、轮速计等传感器的信号构建一种紧耦合的多传感融合定位算法。为减少外部因素对视觉传感器的影响,使用鲁棒性更强的语义检测结果作为特征对自动驾驶车辆周围的环境进行表达,增强定位的稳定性;使用矢量化表示的地图进行匹配,以极大程度地减少地图对存储资源的占用,同时实现稳定的元素匹配以及更快速的定位结果输出。最后,使用真实场景的数据对提出的方法进行验证并与现阶段主流算法进行对比,验证方法的稳定性和可行性。
2 视觉定位技术概述
自主代客泊车技术中的高精定位模块是核心模块之一。考虑到实际应用中的成本问题,现阶段各大汽车厂商以及相关研究人员在该方向的研究中主要采用以视觉传感器为基础的定位方案。基于视觉的定位方案按照对周围环境描述方式的不同可以分为基于传统特征的定位方法和基于语义信息的定位方法。
传统的视觉特征由关键点和描述子2个部分组成,其中关键点主要用于确认特征所在的位置信息,描述子的功能是对其进行编码,从而实现对不同关键点的区分。基于传统视觉特征点的思想,R.MUR-ARTA 等人提出了ORB-SLAM 系列算法[11-13],以ORB 特征为基础实现快速、准确的SLAM 算法。该方法采用鲁棒性更强的关键帧和三维点的选择机制实现稳定的视觉特征匹配。M.SONS 等人[14]定义并使用特征描述子实现了基于环视摄像头的实时匹配定位算法的开发。为实现更高效率的实时定位与建图,J.ENGEL 等人[15]提出直接稀疏里程计(Direct Sparse Odometry,DSO)方法,基于直接法和稀疏法的视觉里程计能够实现传感器位姿的快速解算。HENRI 等人提出一种基于事件的视觉测距算法[16],该算法不受运动模糊的影响,并且在具有挑战性的高动态范围以及强烈的照明变化条件下都能很好地运行。此外,基于双目相机和能够采集深度信息的RGB-D 相机的SLAM 技术在理论与应用方面均取得了显著进展。
视觉摄像头特定的工作原理导致其在工作过程中会受到光线等因素的影响,进而影响传统方法的特征匹配精度。此外,由于停车场内环境不断变化,上述方法建立的特征地图无法在长时间内保持鲁棒性,进而影响最终的定位精度。
基于语义特征与矢量地图数据进行匹配的定位方法能够有效解决上述问题。首先,停车场内构建矢量地图的语义特征能够保持长时间的一致性。其次,通过将实时采集的图像数据进行语义特征的提取能够避免环境变化对特征元素的影响。例如,RANGANATHAN 等人[17]提出一种基于路面标志的匹配定位算法,该方法使用周围易于检测的标志对车辆所处的环境进行表达。SCHREIBER 等人[18]仅使用路沿石与地面的标线作为特征,实现了稳定的定位结果。FABIAN 提出一种模块化方法[19],将不同检测算法的检测数据与地图中的元素相关联,然后使用无迹卡尔曼滤波器融合得到绝对姿态。QIN 等人[20]提出一种SLAM方法,使用停车位作为主要特征实现实时定位、建图和地图匹配定位。
3 定位模块
本文提出的定位模块基于误差状态卡尔曼滤波器[21]实现,算法如图1 所示,主要包括基于视觉数据与矢量地图的匹配定位子模块和多传感器融合定位子模块。
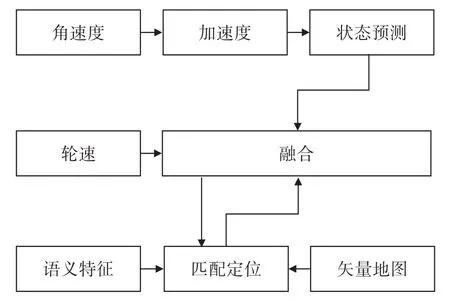
图1 定位算法
3.1 视觉匹配定位
本文使用的视觉语义特征通过深度学习网络实现,检测的语义元素包括停车位、箭头、道路标线、斑马线共4 个类别。虽然停车场内部的语义种类更多,但上述4 种类别是停车场内最常见的标志,能够实现对自动驾驶车辆周围环境的有效表达,同时,上述特征的选取也有利于深度学习网络的收敛,提升特征提取的精度。视觉匹配定位问题可以描述为如下形式:给定车辆附近的矢量地图以及根据实时采集到的图像数据提取的语义特征,计算车辆当前时刻在地图坐标系下的位置和姿态,数学上可以描述为如下优化问题:
式中,h为误差函数;P为语义特征元素的集合;M为矢量地图中元素的集合;T为待优化的变量;SE(3)为特殊欧氏群。
本文使用三维空间下变换矩阵的形式描述车辆的位姿。
3.1.1 语义特征匹配
语义特征与矢量地图中元素的匹配是构建误差函数h的重要步骤和前提。为实现语义特征匹配,首先需要解决检测数据与地图数据表达形式不一致的问题。深度学习网络提取的语义特征的可视化结果如图2 所示,主要以结构化数据中像素点的集合形式表示,矢量地图中的数据则以关键点的形式存在。语义特征匹配的目的是实现上述2种数据元素的关联。
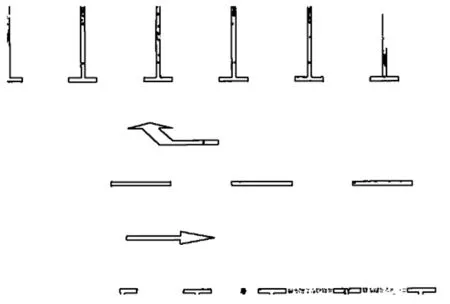
图2 语义特征可视化
本文采用最近邻搜索的方式实现待匹配数据的选取,其中目标数据由提取的语义特征数据采样得到,搜索空间由局部地图内的元素构成。不同类型的特征使用的采样方法不同。其中车位和标线特征数据的提取通过均匀采样的方式实现,同时保留数据的角点(位于语义特征数据中折线位置的点和端点)信息。为实现箭头和斑马线的语义特征数据与地图数据一致,在对其数据采样之前额外执行了轮廓的提取,且在轮廓数据上实现后续的采样。为提升上述方式中搜索过程的执行效率,采用KDTree存储地图元素,该方法能够将时间复杂度由O(n2)提升至O(nlog(n))。
3.1.2 目标函数构建
构建目标函数的过程即是构建函数h的过程,也是根据上一节中匹配到的元素计算误差约束的过程。本文针对角点和一般点提出2种不同的误差计算方法,其中角点的约束根据点与点之间的欧式距离计算:
式中,Pc、Mc分别为特征数据和地图元素中角点的集合。
在计算一般点的约束时,采用点到直线的欧式距离构建误差,其中直线通过地图元素中最近的2个角点确定:
式中,pj∈Pg;mj,mk∈Mg。
由此可推算出函数h的形式为:
3.2 融合定位
本文采用误差状态卡尔曼滤波器实现视觉匹配定位、IMU 以及轮速计的数据融合,融合模块中描述系统状态、输入输出的符号及其物理意义如表1、表2 所示。本文使用四元数表示车辆的姿态,使用IMU 执行模型的预测部分。其中系统状态定义为积分状态和误差状态的组合,预测阶段通过运动学模型对积分状态和误差状态分别进行推算,更新阶段仅在误差状态下进行,即通过观测值修正系统的误差,并将误差嵌入积分状态以实现最优的状态估计。
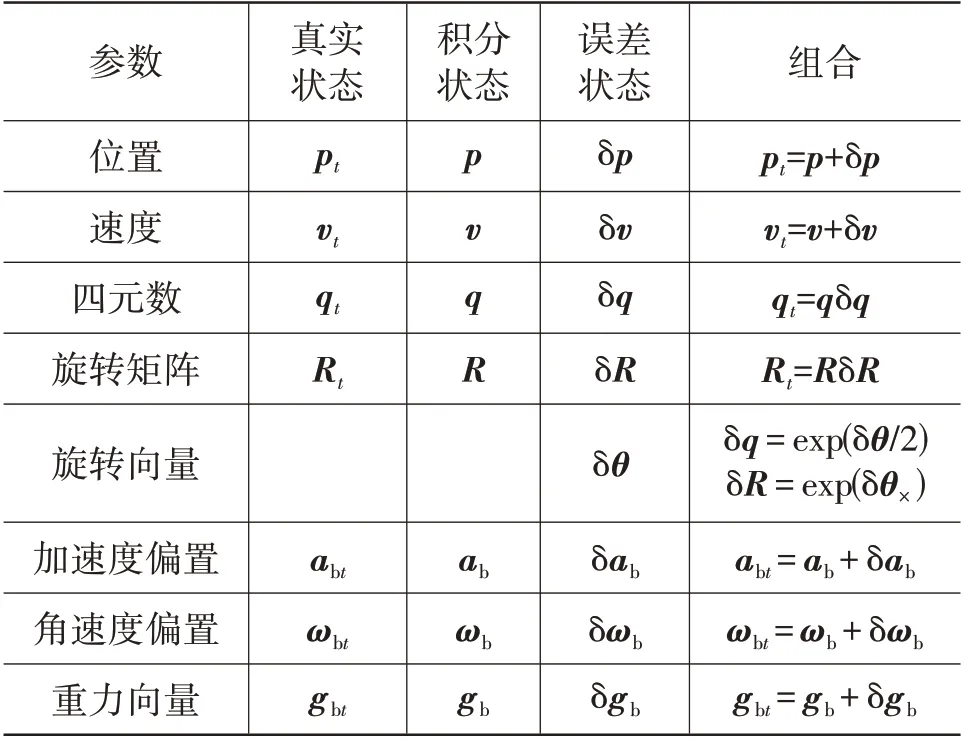
表1 系统状态符号及定义
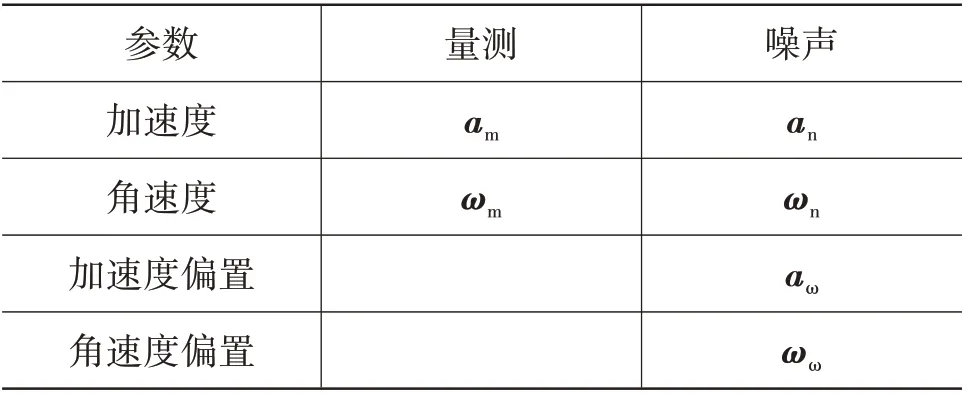
表2 系统测量及噪声
3.2.1 系统模型
根据运动学方程,系统的真实状态可以为:
根据表1分别推导积分状态和误差状态的系统模型,结果为:
对比式(6)和式(5)可以看出,积分状态的系统模型为真实状态的系统模型去除误差项的形式。误差状态的模型根据表1 中的组合方式近似得到,由于系统的误差通常处于较小的量级,因此可以根据一阶泰勒展开得到的线性化形式进行建模,同时该模型具有较小的线性化误差,具体形式见式(7)。
3.2.2 状态预测
在本文提出的基于误差卡尔曼滤波的融合框架中,系统状态的预测基于IMU 的测量实现。其中积分状态根据式(6)中的运动方程推算。为方便书写,本文使用向量化的形式描述误差状态:
同时,该状态满足高斯分布假设:
增值税由于税基广阔、征管手段高效的特点,已经成为我国最大的税种,2017年我国税收收入144360亿元,其中,国内增值税收入达到56378亿元,占比接近40%。在试点工作不断推进的过程中,结合征管实践经验逐步完善相关法规显得愈发重要,本文旨在为完善增值税会计,促进增值税会计准则的制定提供参考建议。
式中,δx̂为误差状态的预测值。
根据式(7),可以推导出误差状态的推算服从:
其中,变换矩阵Fx和Fi为式(7)中稀疏的矩阵化表达,即
式中,Δt为积分时间。
式中,I为单位矩阵。
um和i分别为IMU的读数和系统中的扰动项:
式中,vi、θi分别为速度、角度的噪声;ai、ωi分别为加速度、角速度高斯白噪声中的方差。
根据式(10)~式(16)可得误差状态的参数服从:
3.2.3 融合定位
本质上,融合定位的过程就是使用语义匹配定位的结果和轮速数据更新误差状态的过程,且该过程服从卡尔曼滤波的更新规则,可以描述为:
式中,K为卡尔曼增益;V为观测值的协方差矩阵;H为函数h1关于δx的雅可比矩阵;h1为函数h的简化形式;y为优化后的特征匹配位姿带入式(4)得到的误差值;δx̂t为[pt vt qt Rt abt ωbt gbt]的预测值。
值得注意的是,由于更新过程针对误差状态,因此矩阵H为观测误差对误差状态的雅克比矩阵,可以通过链式法则计算:
4 试验验证
为验证本文提出方法的可行性以及在实际自主代客泊车场景下的性能,分别在仿真环境下和真实场景下测试,并将测试结果与目前主流方法做了对比。其中试验平台为Nuvo-6108GC 工控机,搭载英特尔至强E3v5 CPU、英伟达GTX1080 GPU;操作系统为Ubuntu16.04,搭载ROS-kinetic子系统;摄像头采用MV-CA013-21UM 海康工业摄像头,系统输出图像大小为640×480。
为了能够量化方法的性能,使用平均旋转角度误差和平均位移误差作为评价算法性能的指标,计算方法为:
式中,Θ为模型输出结果的集合;T̂i为i时刻模型的输出位姿;Ti为i时刻的真实位姿。
本文方法与主流方法的平均误差对比结果如表3 所示。对比结果表明,本文提出的方法的平均旋转角度误差和平均位移误差均处于较小的量级,证明了方法的有效性。本文方法与AVP-SLAM 算法均使用视觉语义特征,其中AVP-SLAM 仅使用停车位的语义信息表达周围环境,本文使用的特征更丰富,试验结果也表明本文提出的语义特征能够实现更好的定位效果。ORB-SLAM3 和VINS-MONO是基于传统视觉特征点的方法,该类算法能够获得较高的结果精度,但是长期鲁棒性较弱。本文提出的方法能够与ORB-SLAM3保持相似的误差,实现了高精度的定位结果。与ICP 及其改进算法进行对比可以看出,本文提出的方法优于传统的基于最邻近搜索的方法。
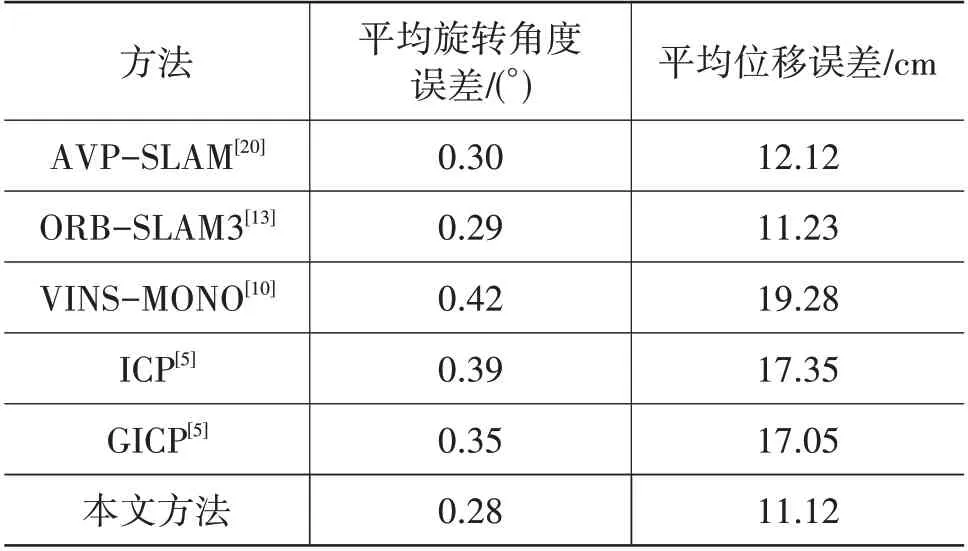
表3 算法指标对比
同时,算法执行效率的优劣是其能否在实际环境中应用的前提,因此本文也针对模型的平均计算时间进行对比试验。
算法运算时间的试验结果如图3 所示。值得注意的是,该部分试验内容中算法的计算时间是指视觉匹配定位的时间。理论上,特征数据的表达方式越复杂,其算法的执行效率就越差,因此基于特征点的方法能够实现高效的计算。同时,本文使用的语义特征(AVP-SLAM)是最简洁的特征描述方式,因此理论上比基于关键点和描述子的方法(AVPSLAM、ORB-SLAM3)具备更快的计算速度。试验结果验证了前文论述的内容,其中基于语义特征的算法能够实现快速的结果输出,节省了计算资源。

图3 计算时间对比
5 结束语
本文提出了一种基于矢量地图的多传感器融合定位方法,并应用于自主代客泊车场景,实现高精定位功能。同时将提出的方法基于真实数据进行测试,与主流算法的结果进行对比分析可知,该算法在结果精度和执行效率上均处于领先水平,能够实现快速稳定的实时定位功能。然而,由于停车场一般属于封闭室内场景,验证阶段真值数据的获取比较复杂,未来,该方法仍需要在更复杂的场景中进行验证,并根据测试结果提升算法的性能。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
导航定位与授时(2020年5期)2020-09-23
今日中国·法文版(2020年7期)2020-07-04
开放教育研究(2020年2期)2020-03-31
铁道通信信号(2020年9期)2020-02-06
中国特种设备安全(2019年1期)2019-03-13
知识经济·中国直销(2018年3期)2018-04-12
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
长江学术(2016年4期)2016-03-11
