
基于故障关联度的数控系统可靠性建模*
2023-03-02 06:43张忠文车众元薛瑞娟王贺东
组合机床与自动化加工技术 2023年2期
张忠文,彭 翀,车众元,薛瑞娟,王贺东
(北京航空航天大学a.机械工程及自动化学院;b.自动化科学与电气工程学院,北京 100191)
0 引言
数控系统是数控机床的核心部件,被称为机床的大脑,在深入实施制造强国的战略发展规划中占据着重要的地位[1]。数控系统可靠性建模作为可靠性评估的重要方法,具有非常重要的研究价值[2]。数控系统故障数据由于采集方式直观、建模难度较小、研究成果较多,在数控系统的可靠性评估中经常被使用。许多学者在数控系统可靠性建模方面进行了相关研究。LIU等[3]提出了一种基于故障相关度的可靠性建模方法,并将故障相关因子引入参数估计部分,以充分反映可靠性建模中全生命周期中故障数据的可靠性信息。VERSHININ等[4]通过安装故障检测装置对数控系统的运行状态进行监测,研究数控机床及其控制单元的故障和失效原因,以提高机电系统可靠性分析的效率。但是这些方法所考虑的对数控系统故障影响的原因较为单一,当面对故障原因较为复杂的数控系统时,其适用范围受到严重的限制,因此亟需一种能满足数控系统可靠性分析的方法。
随着数控系统可靠性测试水平的提高与测试方法的完善,可靠性测试数据的内容日渐丰富,规模日益增长,充分利用数据信息可以很大程度地提高可靠性模型的准确性。此外,由于大数据技术的不断发展,数据挖掘[5]方法应用也趋于成熟。很多学者利用数据挖掘方法进行了研究。WANG等[6]改进SDT算法,相比原有算法更加适合和高效。BORCH等[7]在医学研究中提出了一种基于稀有模式的异常点检测方法(RPOD),经过比较性能评估后证实了RPOD方法优于现有的孤立点挖掘方法。鲍军鹏等[8]探讨了在多核CPU和GPU的典型异构计算节点中对时序数据挖掘过程进行并行优化的多种策略。结果表明,针对不同任务情况综合使用多种优化策略具有显著提升效果。
本文将数据挖掘技术应用于数控系统可靠性数据处理,结合Weibull分布建立了考虑故障关联因子的可靠性模型,充分融合了挖掘信息,使得模型具有更加精确的预测能力。
1 相关工作
1.1 FP-Growth算法
TELIKANI等[9]提出的FP-Growth算法是一种基于分治策略的频繁模式增长的经典关联规则挖掘算法。FP-Growth算法是通过将数据集存储在FP(frequent pattern)树上发现频繁项集,FP-Growth算法只需要对数据库进行两次扫描,该算法发现频繁项集的过程是:
(1)构建FP树;
(2)从FP树中挖掘频繁项集。
利用FP-Growth算法扫描数据集涉及到提升度(Lift),提升度定义为:“包含X的事务中同时包含Y的事务的比例”与“包含Y的事务的比例”的比值,表达式如下:
Lift=P(X∩Y)/P(X)/P(Y)
(1)
提升度反映了关联规则中的X与Y的相关性,提升度大于1且越高表明正相关性越高,提升度小于1且越低表明负相关性越高,提升度等于1表明没有相关性。
1.2 关联规则的建立
关联规则挖掘[10]是数据挖掘方法中重要的方法之一,由于其能有效发掘大规模数据中的隐含关系信息,已经成为数据挖掘领域中一个非常重要的手段[11-12]。该方法十分适合处理大量数控系统可靠性测试数据。如果两个或多个数据项重复且概率很高,则它们之间具有某种相关性,通过这些相关性可以生成相对应的关联规则:
设I={i1,i2,…,in}为整体项集,T={t1,t2,…,tm}为事件数据集,T≠∅,T⊆I,X⊆I,Y⊆I。
关联规则定义和其相关参数定义如下:
定义1:X≠∅,Y≠∅,X∩Y=∅,若有X⟹Y,则X⟹Y是一条关联规则;
定义2:关联规则X⟹Y在事件数据集T中存在置信度(confidence),则置信度为在事件数据集T中含有X也含有Y的可能性,表示为:
Confidence(X⟹Y)=P(X|Y)
(2)
定义3:支持度为描述关联规则X⟹Y在事件数据集T中同时存在X和Y的可能性,定义事件数据集T中存在支持度(support),支持度的公式为:
Support(X⟹Y)=P(X∪Y)
(3)
定义4:关联规则X⟹Y的置信度为:
(4)
为了简化了对事件数据集的扫描,提升频繁项集挖掘效率。本文利用FP-Growth算法建立关联规则。其过程如图1所示。
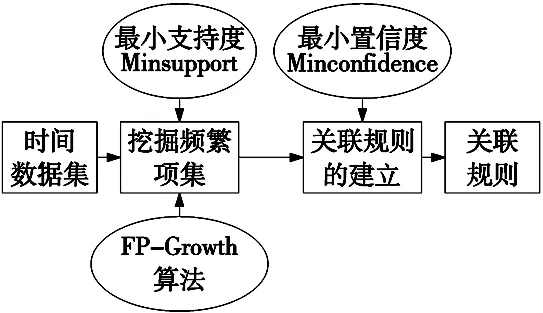
图1 关联规则
该过程的目的是找到一个关联规则,要求其既满足最小支持度(minsupport)又满足最小置信度(minconfidence)。其中,支持度和置信度越高,关联度越好。
关联规则建立过程如下:
(1)第一次扫描故障数据,得到所有频繁项集的计数。然后删除支持度低于阈值的项,将频繁项集放入项头表,并按照支持度降序排列;
(2)第二次扫描故障数据,将读到的原始数据剔除非频繁项集,并按照支持度降序排列。通过两次扫描数据建立项头表;
(3)构建FP树。读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是父节点,而靠后的是子节点。如果有共同的链表,则对应的公用父节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成;
(4)挖掘频繁项集。从项头表的底部项依次向上找到项头表项对应的条件模式基。从条件模式基递归挖掘得到项头表项的频繁项集,同时返回频繁项集对应的节点计数值;
(5)在满足要求的频繁项集的基础上,得到具有最小置信度的关联规则。
2 基于故障关联度的可靠性建模方法
2.1 数控系统可靠性数据的预处理
故障总时间法[13](total testing time,TTT)是一种用于数据变换的方法,可以较好的解决单个数控系统故障样本数目较少的问题。经过长时间使用后该方法在指数型检验、模型选择、维修策略等方面得到了应用。因此本文采用故障总时间法对其故障时间数据进行预处理,故障总时间的原理图如图2所示。
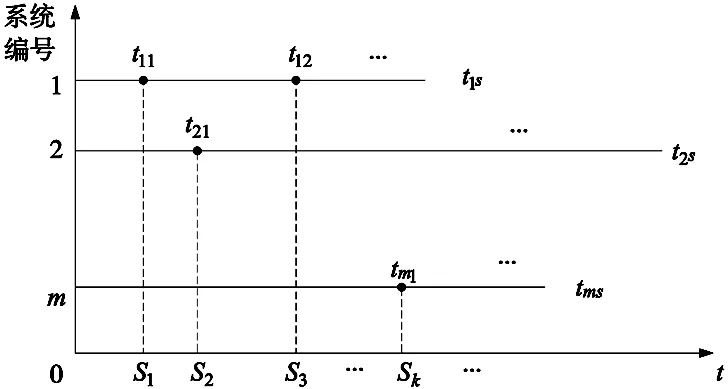
图2 故障总时间法原理
根据故障总时间法原理,假设采集的现场故障数据来自于m套数控系统,其中第i套数控系统采集的故障时间区间为(0,tis],i=1,2,…,m,共发生ni次故障,每次故障发生时间为tij(j=1,2,…,ni)。则各故障点所对应的故障总时间计算方法为:
T(tij)=tij×p(tij)+Ts
(5)
式中,p(tij)为tij时刻观察到的未截尾数控系统的数量;Ts为tij时刻观察到的所有已截尾数控系统截尾时间之和。
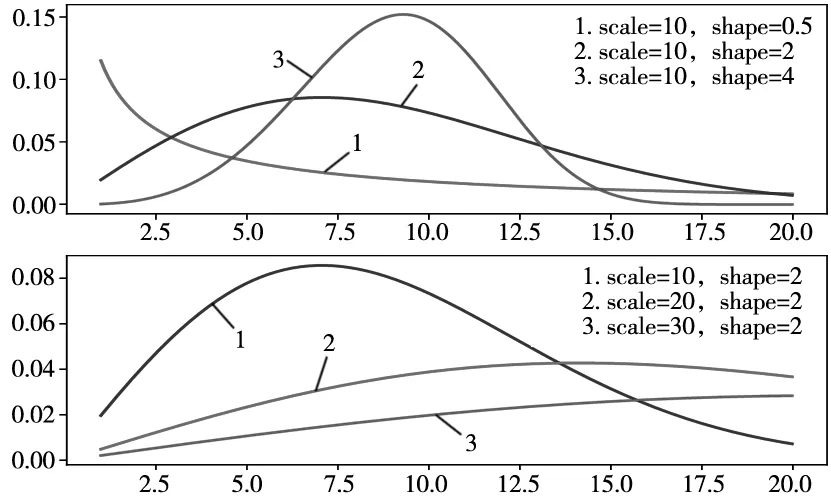
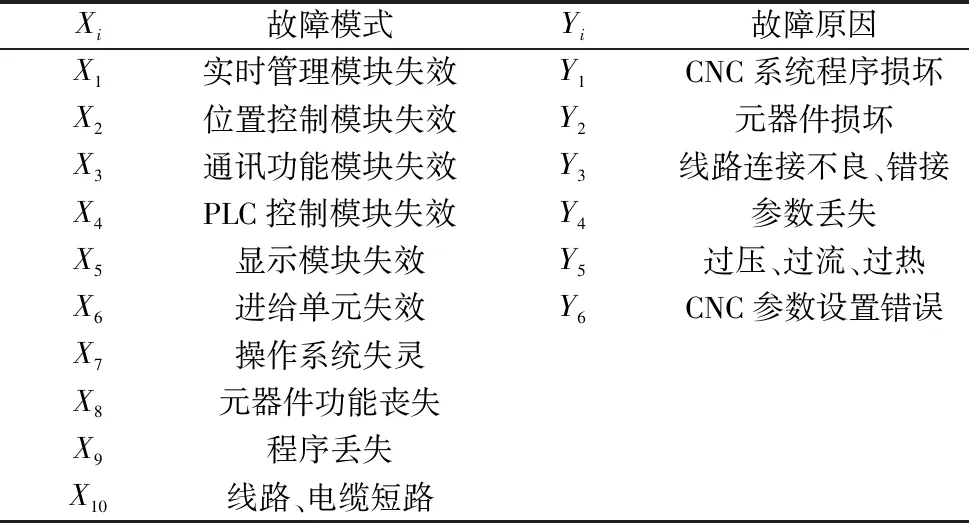
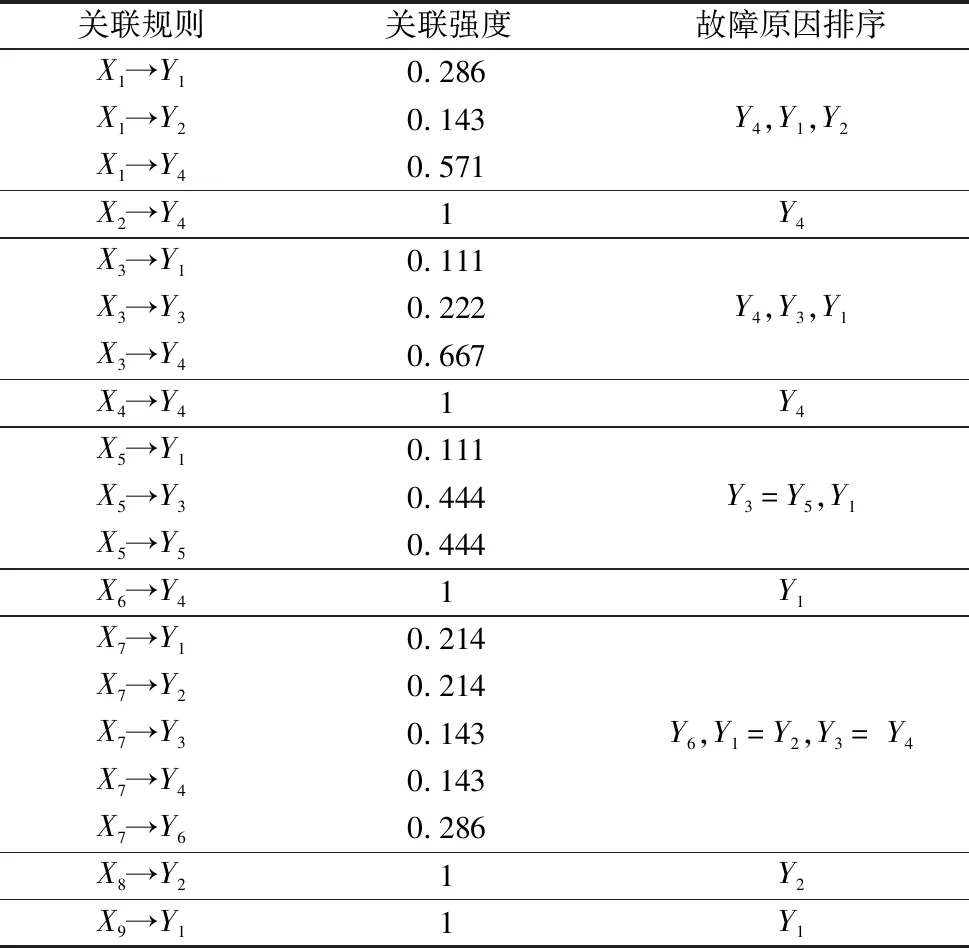
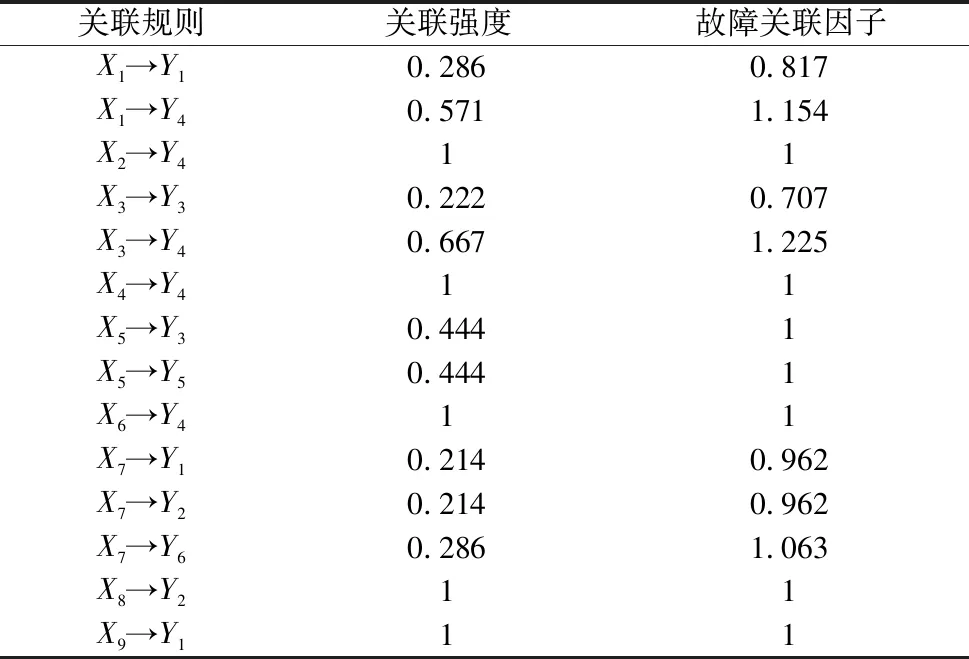
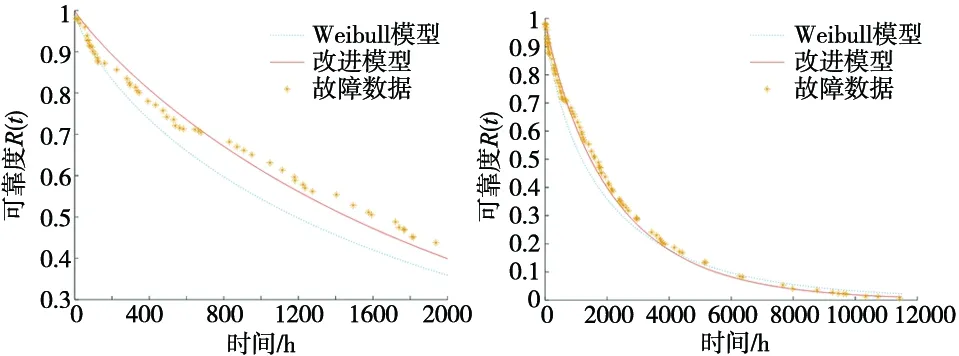
将得到数据从小到大排序得时间序列0 (6) 故障间隔时间的累积故障分布F(t)采用中位秩的方法进行计算,第i个故障数据的序号ri为: (7) 式中,N为故障总数(不含截尾数据);n′=N+1;j为采集的所有数据(包含截尾数据)的顺序号;i为故障数据的顺序号。 得故障间隔时间的累计故障分布F(t)为: (8) Weibull分布是一种传统可靠性模型,双参数Weibull分布可以用于分析具有小样本故障数据产品的可靠性。 采用Weibull分布对数控系统的可靠性进行建模: Weibull分布的故障率函数为: (9) Weibull分布的故障概率密度函数为: (10) Weibull分布的可靠度函数为: (11) 式中,β为形状参数(shape),表示函数的走势,β>1表示故障率随时间增加,β<1表示故障率随时间减小;θ为尺寸参数(scale),影响函数分布的平均值。 为分析β与θ对于分布的影响,通过取不同的值就Weibull分布的概率密度函数进行了绘制,如图3所示。 图3 Weibull分布的形状参数与尺寸参数关系 由图中可以看出随着尺寸参数θ与形状参数β的变化,所得到的失效概率密度函数曲线也会随之变化,可以表征整个产品全生命周期(浴盆曲线)的磨合阶段、稳定磨损阶段,以及剧烈磨损阶段。设置θ不变,当0<β<1时,概率密度曲线可模拟产品全生命周期的磨合阶段;当β=2时,可模拟产品全生命周期的稳定磨损阶段;当β>4的时候可模拟产品全生命周期的剧烈磨损阶段,可以看出形状参数β控制分布函数形状的变化。若设置β不变,随着θ的增大,可以看出曲线的幅值与期望均发生了变化,故尺度参数θ控制分布函数的幅度及期望。由于Weibull分布模型的上述特点,本研究选取该模型进行改进,并与改进后的模型进行对比。 以关联规则和关联强度为基础,计算数控系统故障关联因子,并将其引入到可靠性建模参数估计过程中,可以获取包含关联信息的数控系统可靠性修正模型。 故障关联因子α表示为: (12) 式中,η为关联规则对应的关联强度;n为同一故障模式对应关联规则个数。 考虑故障关联度之后,采用极大似然估计法估计参数,并将故障关联因子引入到似然函数并得到对数似然函数: (13) (14) 通过令式(13)的一阶导数为0来对形状参数β和尺寸参数θ进行估计。 获得了上述参数之后引入均方误差(RMSE)对模型的拟合度进行判断: (15) 通过中位秩法计算经验可靠度: (16) 式中, (17) 本文的研究内容使用的可靠性数据来源于实验室两期近十年可靠性测试研究。原始数据采集于实验室数十台数控系统中,涵盖了数控系统运行数据、指令数据、报警数据、故障记录、负载电流等上万条可靠性信息。对测试数据进行整理与筛选,剔除异常数据,合并重复数据,提取数控系统的故障时间、故障模式和故障原因,生成故障数据集。其中,X为故障模式,Y为故障原因。表1为故障模式及故障原因对照表。 表1 故障模式、故障原因对照表 针对故障数据集利用联规则挖掘计算,去除置信度小于0.1的结果,获取的故障模式与故障原因间的关联规则和置信度结果如表2所示。 表2 关联规则和置信度 通过带入式(12)可以得到各次故障对应的关联规则信息、故障关联因子,剔除置信度小于0.2的结果如表3所示。 表3 关联规则与故障关联因子 将统计好的可靠性数据代入到式(14)中计算未引入故障关联因子的Weibull模型相关模型参数。然后,引入故障关联因子,经过MATLAB数值计算即可获得经过改进模型的模型参数。应用故障样本数据进行拟合度验证,获得的改进模型和Weibull模型的RMSE,结果如表4所示。 表4 模型参数估计值与RMSE 利用表4中的参数估计值,绘制各个改进模型和Weibull模型的可靠度函数图,如图4所示。利用表数据绘制各模型可靠度函数图,可看出改进模型对数据的拟合程度更好,同时从均方根误差可以看出,引入故障关联因子的改进模型比一般Weibull模型均方根误差要小的多。 图4 故障数据和拟合模型对比图 由表4可知,考虑故障关联因子的改进模型RMSE为0.068 2,远小于Weibull模型的0.112,拟合优度更高。通过图4可得,虽然Weibull模型在试验早期(小于200 h)具有更加优秀的拟合能力,但是在完整的试验周期中,整体拟合效果远差于改进模型。这是由于在实验早期,故障数据样本小,相关的关联规则不明确,改进模型的特性不能明显体现。随着测试时间的增长,故障样本数据逐渐增加,关联规则逐渐明确,故障关联因子对模型的修正作用逐渐加强,使得修正模型能够更加符合理论故障数据的变化趋势,局部偏离度小,拟合优度更高。而且随着试验时间的增长,考虑故障关联因子的修正模型的预测能力会明显提高。 本研究通过考虑故障模式与故障原因的关联程度,采用数据挖掘技术,以在故障数据对应的故障时间、故障模式与故障原因构成数据集,利用FP-Growth算法搜索得到频繁项集,结合最小置信度得到关联规则,计算得到故障关联因子,并引入到数控系统可靠性模型参数估计过程中,从而获得了修正的可靠性模型。结论如下: 引入故障关联因子修正的可靠性模型,具有更加为突出的拟合优度,对理论故障数据的变化趋势具有一定的适应性,能够更加准确的对数控系统全生命周期的可靠性进行预测。并且随样本数据的增长,预测能力会逐渐增强。2.2 数控系统可靠性建模
2.3 考虑故障关联因子的可靠性模型参数评估
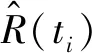
3 实例验证

4 结论
猜你喜欢
核科学与工程(2021年4期)2022-01-12
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
制造技术与机床(2017年5期)2018-01-19
制造技术与机床(2017年6期)2018-01-19
制造技术与机床(2017年7期)2018-01-19
制造技术与机床(2017年9期)2017-11-27
轴承(2015年2期)2015-07-25
电讯技术(2011年11期)2011-04-02
网络安全与数据管理(2010年1期)2010-05-18
