
融合注意力机制和迁移学习的跨数据集微表情识别
2023-02-27 07:46肖家赋相虎生
重庆理工大学学报(自然科学) 2023年1期
王 越,王 峰,肖家赋,相虎生
(1.天津大学 电气自动化与信息工程学院, 天津 300072; 2.太原理工大学 信息与计算机学院, 山西 晋中 030600; 3.武警指挥学院, 天津 300352)
0 引言
微表情是一种自发产生、较为细微的面部表情动作信号。与宏观表情信号不同,微表情不会随主观意志而改变,持续时间大约在0.04~0.2 s[1],幅度较小,研究表明微表情可以反映出人们在压抑状态下的潜在真实情绪[1-2]。由于微表情表现形式与说谎时的心理状态存在极大相关性,微表情识别在国家安全、临床医学、案件侦破、司法审讯等领域具有良好的应用前景。
近年来,国内外对微表情特征提取与识别的研究方法分为三大类,包括光流法(optical flow,OF)、局部二值模式(local binary pattern,LBP)及其改进方法、卷积神经网络(convolutional neural network,CNN)。
在微表情特征提取方面,现有光流法主要是在亮度恒定、小幅度运动的假定条件下,利用像素在时空域的相关性,计算出光流场中图像运动信息。由于光流法结合感兴趣区域(region of interest,ROI)可以对应面部行为编码系统(facial action coding system,FACS)检测出表情动作变化[3],Liu等[4]提出主方向平均光流(main directional mean optical-flow,MDMO)方法用于微表情特征提取,对不同ROI方向平均电流进行归一化统计,将所得MDMO特征向量通过支持向量机(support vector machine,SVM)进行分类识别,可有效降低特征维数。Hua等[5]提出一种基于运动边界直方图融合的特征提取方法,分别在水平和垂直方向计算其微分光流矢量,特征融合后通过LOSO协议进行验证和评估。以上方法对应用场景要求较为苛刻,需要进行相应修改以提升其泛化能力;另外,传统方法对图像序列进行直接光流计算,计算成本较大。针对上述问题,首先利用深度学习网络模型对光流提取效果进行提升,结合残差网络思想,将光流速度矢量的近似估计转换为光流残差的策略求解问题,无需实现损失函数最小化,即可获得光流矢量自动更新,提升模型泛化能力;其次采用注意力机制构建基于关键帧的金字塔光流模型,赋予峰值帧更高权重,在提高计算精度的同时降低空间复杂度;由于所构建的光流模型仅对图像速度矢量进行计算,而忽略了图像序列的帧间运动信息,将三正交平面的局部二值模式(local binary patterns from three orthogonal planes,LBP-TOP)特征与光流特征融合得到最终特征表示,提取视频序列的时空纹理特征及光学应变信息,以弥补光流法缺少序列信息描述的不足,同时降低特征维数,减少计算成本。
在分类模型方面,卷积神经网络可挖掘视觉图像深层特征,在多种图像分类数据集上有非常出色的表现。Liong等[6]提出了一种双加权定向光流方法(Bi-WOOF法),仅使用视频中的峰值帧和起始帧进行特征提取,之后输入到二维CNN进行分类,取得了较好的结果。为了进一步提升模型准确率,建立面部关键区域与对应情感标签的紧密关联,同时缓解因微表情数据库样本数量不足等因素造成的模型过拟合问题,对CNN网络架构进行改进,构建基于CNN-GCN迁移学习网络的微表情跨数据集识别模型,利用图卷积网络GCN的独有优势对图像融合特征和标签向量隐藏联系进行分析,根据基于权重的迁移学习网络思想,将模型在宏表情数据集上进行预训练,利用宏表情数据优势缓解网络模型过拟合问题,同时引入SAMM微表情数据集,增强数据样本多样性,进一步提升网络识别性能。
1 特征提取
作为微表情识别流程中至关重要的一步,特征提取与选择直接影响最终识别性能。受到光照条件变化和图像畸变等因素影响,人脸图像中提取到的特征存在很大差异,影响识别性能。为了提升识别系统在干扰环境下的鲁棒性,构建了一种基于光流特征与LBP-TOP特征的微表情特征提取模型,根据残差网络思想,将光流法与注意力机制相融合,同时考虑了微表情关键帧及视频帧间的内在联系,构建基于关键帧的四层金字塔光流模型,与LBP-TOP 特征级联融合得到最终特征表示,有效提取视频序列的时空纹理特征及光学应变信息。
1.1 基于关键帧的金字塔光流模型
传统光流法是在亮度恒定、小幅度运动的假定条件下,对三维空间中目标物体的瞬时速度矢量在指定二维成像平面上的投影进行求解,用于描述运动物体位置变化及结构信息[7]。
当物体处于小幅度运动状态时,假设所得投影图像的像素点(x,y)在t时刻的光强度为I(x,y,t),其光流水平及垂直分量分别为u(x,y)和v(x,y),若在t+dt时刻,该点位移距离为(dx,dy) 时,光强度保持恒定,即:
I(x+dx,y+dy,t+dt)=I(x,y,t)
(1)

由于dt无穷小,光流可近似为连续变化的三维矢量,将上述公式用泰勒级数展开为:
I(x,y,t)
(2)

Ixu+Iyv+It=0
(3)
上式也被称为光流约束方程。其中,Ix,Iy,It可直接由图像像素灰度计算得出。
在微表情识别过程中,光学特征侧重于描述不同时刻物体的运动变化,从而寻找序列视频帧间动态信息。人脸微表情的产生可分为3个关键阶段:起始、峰值及终止[8],其中,微表情峰值帧包含了绝大多数光学应变信息,在微表情识别过程中起着至关重要的作用[9]。由于传统光流法对应用场景具有较严格的限制,同时对整个图像序列进行光流计算增加了计算量,所得光流预测结果仅对真实值进行了粗糙近似,在一定程度上影响了光流提取质量。
基于以上分析,本文对光流法[10]进行改进,在每层金字塔级训练CNN,对光流矢量进行自动优化更新,逐级细化求解图像运动边界及细节,无需实现损失函数最小化,在实时提高计算精度的同时降低空间复杂度,节省模型所占空间。同时,考虑到微表情的峰值帧包含了绝大多数光学应变信息,在所构建光流模型基础上结合注意力机制,对峰值帧分配更多权重,获得更精准的光流矢量表达。
算法描述如下:
1) 对于尺寸为m*n的视频关键帧I,进行下采样操作,将I变换为m/2*n/2的新图像;
2) 利用扭曲算子(I,V)扭曲图像,进行双线性插值,采用独立且序列化的方式训练卷积网络;
3) 通过给定输入,在k层从下采样好的图片,即金字塔最顶层开始,初始化上一层光流场残差为0,与上一层光流场上采样结果相加,将计算所得光流场传递给注意力网络模型,对构建四层残差网络进行重复操作,计算残差,并最终计算出光流场。
每一层金字塔级的残差光流可表示为:
(4)

Vk=u(Vk-1)+vk
(5)
基于关键帧的金字塔残差光流特征计算过程如图1所示。其中,w、u和d分别表示对图像执行扭曲、上采样和下采样操作。

图1 基于关键帧的金字塔残差光流特征计算过程
所得光流图如图2所示。

图2 微表情数据集CASME Ⅱ图像序列样本EP13_03中起始帧和峰值帧的光流图
1.2 基于光流法与LBP-TOP的融合特征
上文构建的光流模型仅对关键帧的速度矢量进行近似光流估计,为了弥补由此带来的对微表情视频帧序列的帧间运动信息描述不足的问题,可结合其他特征提取算法提升识别性能[11]。Zhao等[12]提出的基于三正交平面的局部二值模式(LBP-TOP)同时考虑了图像序列的时间和空间信息,将均值 LBP 从二维扩展到三维空间,可有效提取微表情动态纹理,弥补了光流法缺乏序列纹理信息的不足。
算法特征提取过程如图3所示。在提取LBP-TOP特征的过程中,直接对图像序列进行运算会导致像素信息缺失,并不能很好地处理运动信息和图像细节,因此需要对微表情序列进行分块。采用均匀编码方式,将图像序列从水平方向x、垂直方向y及时间轴向t3个维度上分为若干个互不重叠的块状结构。分别对微表情图像序列的3个正交平面提取LBP特征,其中XY平面表示视频帧的空间信息,XT和YT平面分别表示沿时间轴扫描视频序列得到的水平和垂直方向的运动纹理信息,将3个维度上得到的归一化特征梯度直方图级联成LBP-TOP直方图向量,可以有效描述视频帧的时空纹理信息[13]。

图3 LBP-TOP分块特征提取及三正交平面示意图
将上文中得到的光流图转换为直方图,与图像序列的LBP-TOP特征进行级联融合,可得到最终直方图特征表示,算法模型如图4所示。

图4 基于光流运动特征与LBP-TOP特征的 微表情识别模型
2 深度学习识别模型
相比于其他神经网络结构,卷积神经网络所需参数较少,在图像分类数据集上有着非常出色的表现。在表情及微表情识别过程中,经常配合光流法使用。由于卷积神经网络仅对微表情图像序列中关键人脸动作单元(action unit,AU)进行分析,无法实现面部AU组合与对应情感标签的紧密关联[14]。因此本文在CNN模型的基础上进行改进,构建基于CNN-GCN迁移学习网络的微表情识别模型,利用GCN独有优势获取情感标签向量中节点属性及节点间的隐藏关联信息,帮助捕捉微表情序列中图像数据与对应情感标签的依赖关系[15],同时引入SAMM数据库,构建基于CNN-GCN迁移学习网络的跨数据集微表情识别模型,增强数据库的种族多样性,将所构建模型在宏表情数据集FER2013上进行预训练,利用宏表情定量优势辅助微表情识别,进一步提升网络模型识别精度。
2.1 基于残差模块的浅层CNN模型
将特征提取得到的特征数据集划分为训练集、测试集与验证集,以卷积层、池化层、全连接层和dropout层为核心搭建浅层CNN模型,考虑到后续会与GCN结合构建深层网络模型,随着层数增加,网络训练将会变得愈发困难,针对这一问题,对浅层CNN进一步改进,将总体CNN网络架构根据不同特征尺度分为若干个训练模块,假设在单个训练模块中,原始浅层网络模型的融合特征输入为x,通过网络中隐藏层级联的多层复杂映射计算后,其输出为微表情深层特征H(x),由于多个模块相互连接得到的网络模型复杂度较高,难以训练,因此采用残差结构思想,利用跳跃的捷径连接模块,直接将浅层特征x输入至该训练模块的输出,作为初始残差。该训练模块中的深层特征可表示为[16]:
H(x)=F(x)+x
(6)
令F(x)无限逼近于0,即可得到近似恒等映射,通过学习残差函数F(x),可进一步简化复杂模型,将深层特征训练网络分解为多个基于残差结构的浅层多尺度训练模块:
F(x)→0,H(x)≈x
(7)
改进后的模型如图5所示。

图5 加入残差模块的CNN模型流程框图
2.2 基于CNN-GCN迁移学习网络跨数据集识别模型
由于AUs提取到的面部纹理特征不能直接反映情绪类别,因此需要将其作为中间特征映射至不同类别空间中,而面部不同区域的AU彼此独立又互相联系,因此可利用GCN对不同AUs存在的动态联系进行节点分析,获得深层时空特征,同时挖掘面部关键区域之间的依赖关系,实现更精准的微表情分类[17]。同时考虑到CASME Ⅱ数据集样本序列较少,缺乏种族多样性,在训练过程中极易出现过拟合,因此可利用与其具有类似情绪标签的SAMM数据集进行数据集扩充,拓展样本数据的多样性,构建跨数据集微表情识别模型[18]。另一方面,宏表情数据集和微表情数据集拥有类似情感属性,同时宏表情数据库中包含大量标记的训练数据,识别难度较低,能够为网络模型的训练及评估提供充足数据样本[19]。因此根据迁移学习主要思想,以CNN为主体,结合GCN对微表情数据集CASME Ⅱ和SAMM进行识别,将CASME Ⅱ特征数据集作为训练集,SAMM作为测试集,并在宏表情数据集FER2013上进行预训练,利用宏表情定量优势辅助微表情识别,构建了基于CNN-GCN迁移学习网络跨数据集微表情识别模型,增强识别系统在多干扰环境下的鲁棒性[20]。总体网络框架可分为两部分:基于CNN的图像特征训练模块及基于GCN的情感分类模块。原理图如图6所示。
图6中,C代表数据集中的情绪类别数,FCNN表示采用CNN对图片进行特征提取,提取得到的特征维数为D×h×w,经过全局最大池化后,维数被降为D,在基于GCN的情感分类模块中,首先根据各个关键区域的人脸动作单元AUs组合得到不同类别标签词嵌入向量,GC代表对各个标签向量进行图卷积操作,原始标签的词嵌入向量维数为d,经过特征映射后,标签向量维数变换为D,该维度由CNN中获取的图像特征表示维数决定。

图6 基于CNN-GCN的微表情识别网络框架
为便于迁移学习,采用微表情数据集CASME Ⅱ的4种情绪类别进行识别。对CNN学习到的图像特征进行最大池化,可得新的全局特征x:
x=G[fMP(FCNN(Ic,wCNN))]
(8)
式中:Ic代表输入图像的融合特征表示;wCNN表示CNN网络模型中的权值参数;FCNN为CNN模型隐含层迭代运算;fMP(·)代表最大池化函数;G(·)为池化特征的全局计算函数。
通过关联不同AUs及对应情绪类别,采用GCN训练目标分类器,可获得不同类别标签存在的隐藏关联信息。重复迭代当前网络的前置层节点特征作为该层输入,对节点特征进行更新,从而实现目标分类器对标签向量的策略建模,对微表情图像进行分类。
3 实验结果与分析
实验所用硬件配置为Intel 酷睿i7处理器,16 GB运行内存,2.3 GHz主频,GPU 显卡为 NVIDIA GeForce MX330;操作系统为64位Windows 10;实验平台为Python3.7,Keras+Tensorflow和Pytorch框架以及Matlab 2019b。
3.1 实验所用数据集
由于微表情难以捕捉、采集困难的特点,微表情建库水平较低,缺乏多样性,难以为识别系统地训练提供足够的数据。同时,宏表情与微表情具有相似情感标签,数据库中包含大量标记的训练样本,因此采用迁移学习方法,在微表情识别过程中充分利用宏表情数据库,根据其定量优势辅助微表情识别。实验中采用的数据集分别为微表情数据集CASME Ⅱ[21]和SAMM[22]以及宏表情数据集FER2013[23],3种数据集均采用4类样本数据进行识别,分别为开心、厌恶、惊讶及中性。
3.1.1CASME Ⅱ微表情数据集
CASME Ⅱ数据集由中科院傅小兰团队于2014年建立,该数据集包含247条在200 fps摄像机下拍摄的26位被测者的自发微表情视频片段,人脸图像面部分辨率约为280*340像素。该数据集将微表情分为7类进行标注,分别是快乐(happiness)、厌恶(disgust)、惊讶(surprise)、压抑(repression)、悲伤(sadness)、恐惧(fear)、中性(neutral)。图7为微表情数据库CASME Ⅱ 示例图。

图7 微表情数据集CASME Ⅱ样本示例
3.1.2SAMM微表情数据集
SAMM数据集包含159条在200 fps摄像机下拍摄的自发微表情视频片段,人脸图像面部分辨率约为400*400像素,SAMM数据库收录了13个不同种族、不同年龄的32位测试者的数据样本,包含8种基本情感诱发类别,分别为快乐、厌恶、惊讶、蔑视(contempt)、悲伤、恐惧、愤怒(angry)及中性,并利用FACS编码对相应AU进行标注。图8为SAMM数据库的微表情样例。

图8 微表情数据集SAMM样本示例
3.1.3FER2013宏表情数据集
FER2013包含10名专业演员的34 034张人脸表情灰度图像,其面部分辨率为48*48,共有7种情绪类别,分别为愤怒、厌恶、恐惧、快乐、悲伤、惊讶及中性。该数据集在人脸图像的基础上增加了测试者头部及手部的运动姿态信息,图9为FER2013数据集的某些图像样本。

图9 FER2013数据集样例
3.2 网络结构与参数配置
将CNN模型、基于残差模块(RSB)的CNN模型作为对比模型,与本文中提出的基于CNN-GCN迁移学习网络的微表情跨数据集识别模型进行对比。
CNN-GCN模型中的网络结构主要由图卷积单元和基于残差模块的CNN构成,将图卷积单元与残差模块级联,使用基于残差模块的CNN获取微表情特征的内在联系,形成新的特征向量;利用图卷积单元将标签图数据转换到CNN的特征学习空间中,捕捉微表情人脸特征与对应情感标签的隐藏联系。
表1是3个对比模型的主要参数配置。在CNN模型和REB-CNN模型中,卷积单元由初始卷积核数目为32,核尺寸为3×3的2层卷积层构成。CNN-GCN将卷积核数目改为64,将m的初始值设置为1,每经过1个卷积单元,m的值乘以2,卷积核数目翻倍。

表1 不同网络模型的主要参数配置
在训练过程中采用Adam(adaptive moment estimation) 作为模型的优化器,相较于其他优化器,Adam可自动调整各个参数的学习率,具有较快的网络收敛速度。设置批处理尺寸(batch_size)为64;初始学习率(base_lr)为0.001;学习衰减率(learn rate decay)为le-5;动量(momentum)为0.9;循环周期(epoch)为70,采用自适应监督方式调整学习率。每层卷积层添加BN正则化,采用Early stopping回调函数在模型性能不再提升时中断训练,缓解过拟合,增强模型泛化能力。
3.3 实验步骤
具体实验步骤如下:
1) 首先对CASME Ⅱ和SAMM数据集进行预处理,将微表情数据集进行分帧处理,并采用图像翻转等6种图像增强方式扩充数据集,使各个类别的样本数量基本持平。之后对图像序列进行帧数归一化,将微表情图像序列插帧为16帧,便于后续特征提取。由于不同测试者人脸特征和姿态变化各有不同,对其进行人脸检测及配准以获得归一化人脸微表情图像[24]。
2) 对CASME Ⅱ和SAMM微表情数据集进行特征提取,提取关键帧的光流特征,采用均匀编码方式,将图像序列从3个维度上分为若干个互不重叠的块状结构,对分块后微表情图像序列的3个正交平面进行计算得到其LBP-TOP直方图,与所在图像序列的光流特征级联融合得到最终直方图特征表示。
3) 为了验证提出的微表情特征提取方法和网络分类模型的有效性,将特征数据集分别输入至支持向量机及上文中提到的不同网络分类模型中进行分类对比。
3.4 结果分析
首先采用传统机器学习算法支持向量机SVM对提出的LBP-TOP结合改进光流法的特征与传统特征分别进行分类识别,图10为不同分块数下微表情LBP-TOP特征的识别率。
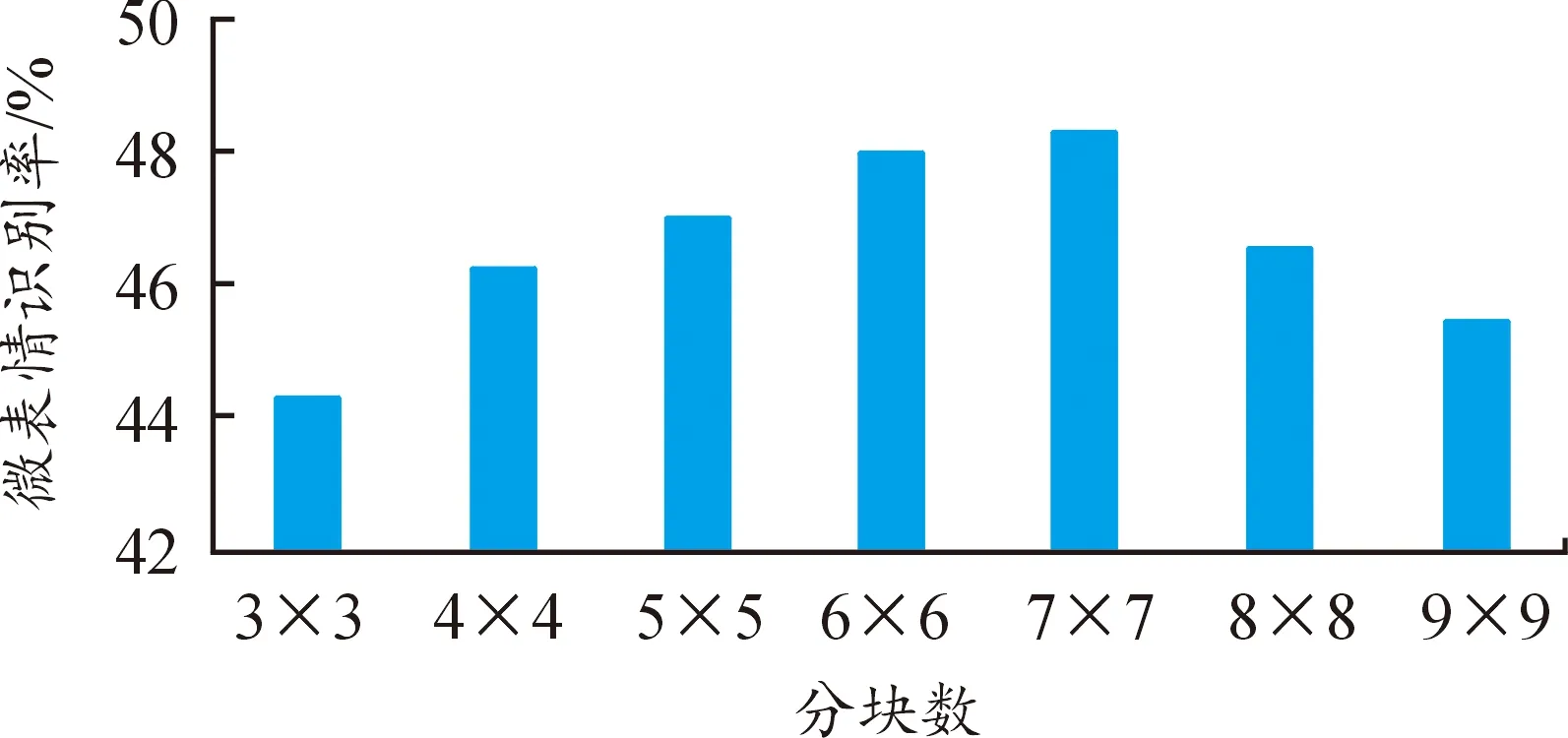
图10 不同分块数下微表情LBP-TOP特征识别率
从图10中可以看出,图像序列的不同分块方式直接影响了最终分类性能。随着分块数的增多,微表情识别率呈现先上升后下降的趋势。分块数过少时,图像序列中关键信息描述不足,分类及预测效果较差,而当分块数过多时,块状区域中所含像素点较少,特征维数呈平方级增长,训练复杂度有所提高,识别效果反而呈现下降趋势,当分块数为7*7时,识别效果最佳。因此,后续的实验操作中均采用7*7的分块方式进行微表情特征提取。
为了验证改进光流算法和特征融合模型的有效性,将改进光流法提取得到的光流图片转换为直方图,与图像序列的LBP-TOP特征进行融合,得到最终的级联直方图,输入到SVM中进行分类,并与传统光流法TVL1[25]进行多次实验对比,实验结果如图11所示。

图11 对不同特征采用SVM分类的识别率
根据图11可知,传统光流法TVL1结合LBP-TOP进行特征提取获取了2种方法的优势,识别效果较单一方法来说有所提升。同时,改进光流法利用关键帧计算求得了连续光流场的绝大多数有效信息,进一步优化了所选特征,因此获得了更佳的识别性能,识别率从51.2%升至54.4%。
在深度学习网络分类方面,本文以卷积层、池化层、全连接层为核心构建了浅层CNN模型,在此基础上加入残差模块,提出基于CNN-GCN迁移学习网络的微表情识别模型,将改进光流法与LBP-TOP融合得到的CASME Ⅱ特征数据集分别输入至CNN模型、RES-CNN模型以及CNN-GCN模型中,得到的识别准确率如图12所示,其中,蓝色曲线代表训练集曲线,橘色曲线代表验证集曲线,横轴为训练周期数,纵轴为四类表情的识别准确率。

图12 不同网络模型得到的准确率结果曲线
从图12(a)中可以看出,与传统机器学习算法相比,深度学习模型在识别性能上有了较大提升,准确率由54.4%升至57.56%。在此基础上,对浅层CNN模型不断优化改进,首先加入浅层残差模块以提升特征学习效果,结果如图12(b)所示,改进后的网络结合了捷径连接中得到的浅层特征和经过隐含层复杂映射的网络深层特征,多尺度特征的结合在一定程度上提高了网络的识别性能,训练过程中的最大准确率从57.56%升至65.42%。GCN利用标签图数据的节点关系挖掘面部不同关键区域隐藏的关联信息,对CNN中提取到的图像全局特征进行优化,利用节点的内在联系增强了AU和标签类数据的相关性,因此基于CNN-GCN的网络明显优于基于残差模块的CNN网络模型,准确率从65.42%升至71.29%,如图12(c)所示。
针对微表情数据样本不足的问题,本文基于CNN-GCN迁移学习网络的跨数据集微表情识别模型,将CASME Ⅱ和SAMM得到的特征图片分别作为训练集和测试集,对训练集及测试集进行扩充,比例为4∶1,并在宏表情数据集FER2013上进行预训练,采用基于权重的迁移学习方式对微表情进行识别,结果如图13所示。
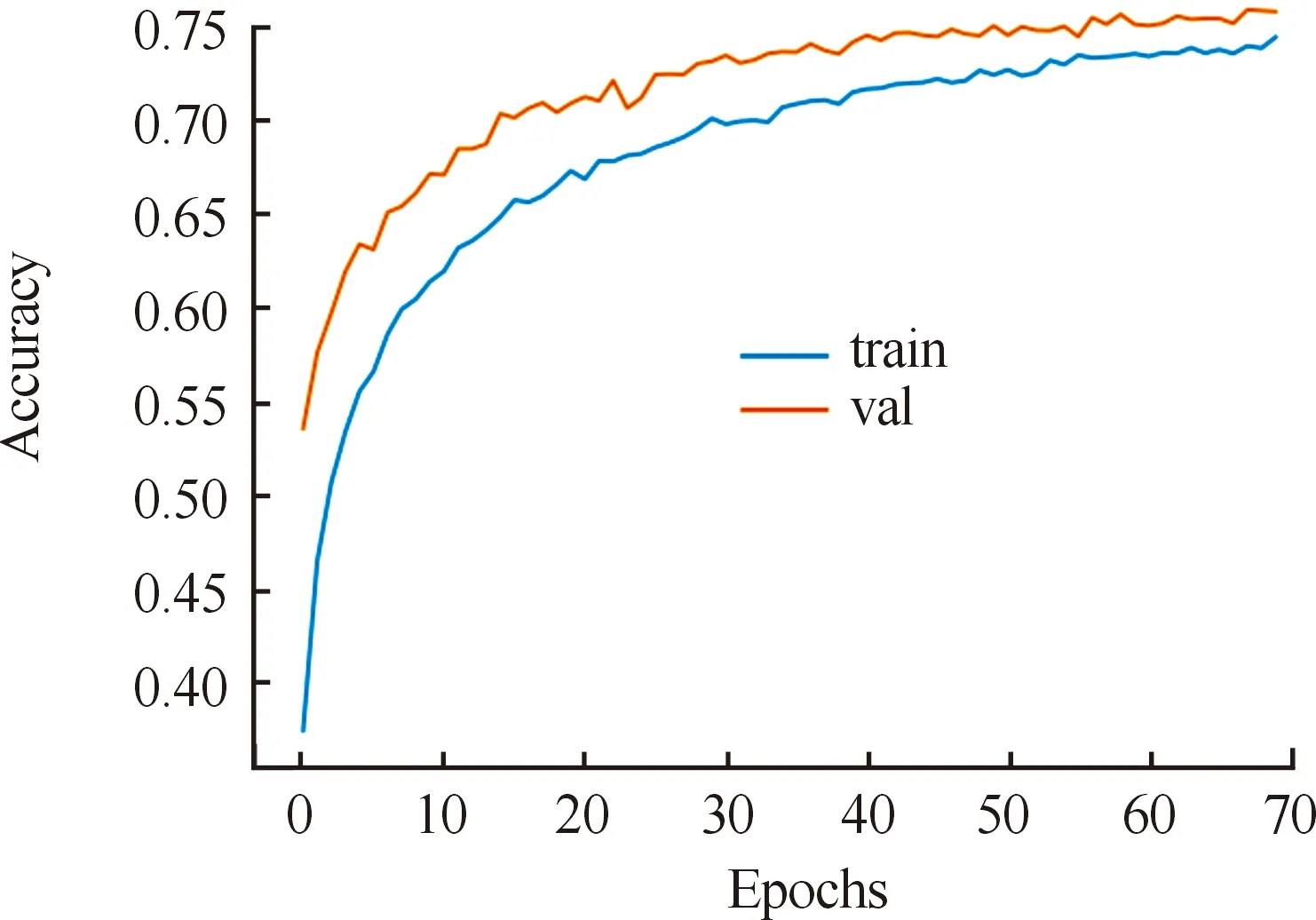
图13 CNN-GCN迁移学习网络跨数据集微表情识别模型准确率曲线
由图13可以得出,利用CNN-GCN模型对CASME Ⅱ融合特征进行识别,其最大识别率为71.29%,将CASME Ⅱ和SAMM微表情数据集结合构建的跨数据集迁移学习网络模型结合了二者优势,实现了2种数据集的互补,利用宏表情数据优势提升了模型识别性能,缓解了微表情样本序列数量较少和缺乏种族多样性对网络训练的影响,在网络的不断训练优化过程中,模型最大识别率由起初的57.56%升至最终的75.93%。
4 结论
对微表情识别采用的特征提取算法和深度学习网络展开了研究,提出了基于关键帧的金字塔光流提取改进算法,优化了特征选择。在网络训练方面,构建了基于CNN-GCN迁移学习网络的微表情识别模型,借助GCN自动更新节点信息的独有优势,捕捉微表情序列中图像数据与对应情感标签的依赖关系,将搭建好的网络模型在FER2013数据集上进行预训练,利用宏表情的定量优势辅助微表情识别,通过多次实验对比可得,所构建的模型提高了微表情的识别精度。在实验过程中,由于微表情数据集样本数量较少,因此极易出现过拟合情况,在未来的工作中,考虑采用生成对抗网络进一步扩充数据库,缓解过拟合问题。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年15期)2019-08-27
自动化学报(2019年6期)2019-07-23
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
中国惯性技术学报(2015年1期)2015-12-19
噪声与振动控制(2015年4期)2015-01-01
中北大学学报(自然科学版)(2014年3期)2014-11-22
