
智能网联汽车数字孪生测试关键场景提取和识别
2023-02-27 07:26韩庆文曾令秋张迪思
重庆理工大学学报(自然科学) 2023年1期
祖 晖,龙 洋,韩庆文,王 勇, 曾令秋,陈 旭,张迪思,卓 玺
(1.招商局检测车辆技术研究院有限公司, 重庆 401122; 2.重庆理工大学, 重庆 400054;3.重庆大学, 重庆 400044; 4.重庆高新区城市建设事务中心, 重庆 402365)
0 引言
随着V2X技术的发展,验证基于V2X的应用成为智能网联汽车(ICV)发展的重大挑战之一[1]。一些研究人员认为,使用虚拟仿真可以解决这一问题[2],虚拟仿真速度快,可以测试任何场景,其缺点是无法验证实际驾驶情况下的效果。相比于虚拟仿真,汽车行业更相信道路测试的结果。然而,真实的道路测试成本高、耗费时间长,并且某些极端场景无法在道路测试中测试[3-4],此外,目前V2X设备普及率很低,很大程度地影响测试效率。
数字孪生(DT)技术是将物理实体以数字化手段重建,以此实现对物理实体的分析和优化。目前,DT已广泛应用于制造和工业工程领域[5],并支撑ICV测试。
Zhao等[6]使用真实的驾驶数据构建自动驾驶汽车测试场景,将DT概念引入智能汽车测试。随后,项目组在2019年发布了基于DT的自动驾驶系统演示,该系统利用V2X通信技术实现车辆与云端服务器之间的信息交互,云端服务器根据车辆实时状态选择测试场景,并将场景下发至车辆进行应用测试[7]。
毫无疑问,DT是ICV测试的有效方案之一,但依旧面临典型测试场景的缺失问题。测试场景的典型性将直接决定测试结果的准确性,因此建立有效的测试场景典型性评价方法将是基于DT的ICV测试系统构建的关键。DT场景一般基于实际道路行驶数据构建,需要具备一定的典型性,即测试场景应“源于生活高于生活”。
传统的道路测试有效性评价大多基于实际行驶场景危险度指标建立,即需要在道路测试过程中遭遇最差条件[8],而最差条件基于事故事件设定,其标志一般为事故事件,此类事件发生概率较低,可能导致测试道路测试周期过长。因此Feng等[9]提出了一种基于场景典型性的评价方案,即综合考虑危险度和发生概率以评价场景。
目前DT场景的生成方法均基于场景有效性评价方法构建,文献[10]根据道路事故数据构建测试场景,其主要场景参数包括事故发生时间、位置、道路特征、环境特征、车辆行驶特征等。文献[9]则选取关键参数评价场景典型性,如车辆的碰撞时间等。在提取基础场景的前提下,还可进行场景重构,如文献[11]提出了基于现有测试场景构建自适应场景库,文献[12]则使用非线性算术约束来生成场景。
评价指标方面,Hallerbach等[13]选取典型参数,如碰撞时间、车辆减速能力和交通质量,来评估场景的风险等级。Batsch等[14]提出了一种使用高斯过程分类来评估场景风险的方法。Wagner等[15]使用Time-To-React(TTR)指标来计算场景的风险级别。Zhang等[16]不仅考虑了两车的碰撞时间和距离等因素,还通过分析车辆的动能来评估事故的严重程度;本项目组则提出了一种基于Ising模型的道路危险度评价方法[17]。基于以上,本文综合考虑风险等级和交通质量因素来评估道路交通状况,作为发生交通事故的评估参数。
Jenkins等[18]提出采用循环神经网络生成不同的事故场景,借鉴此思路,本文使用引入注意力机制的长短期记忆自动编码(LSTM-AE-Attention)神经网络模型来识别关键场景。
本文结构如下:第二节是测试系统介绍和数据预处理;第三节是场景评价参数定义;第四节是LSTM-AE-Attention模型;第五节是实验结果;第六节给出结论。
1 测试系统和数据预处理
1.1 测试系统
本文采用的DT测试系统由中国重庆永川自动驾驶示范区提供,由招商局检测车辆技术研究院(CMVR)、百度和重庆大学共同开发。测试系统的架构如图1所示,系统包括3个关键组成部分,即:数据采集平台、应用服务器和通信节点矩阵。

图1 测试系统结构示意图
数据采集平台:实时道路交通情况由7个激光雷达负责采集,激光雷达部署在一条300 m的测试路段两侧,部署情况如图2红点所示。
应用服务器:部署在路侧,负责从激光雷达采集的数据中提取关键场景,构建场景库。
通信节点矩阵:部署在路侧,由24个OBU组成,负责在车辆行驶过程中发送和接收BSM数据包。图2中的蓝点是OBU的位置,每个位置放置6个OBU。每个OBU的最大传输数据率是标准传输速率的3倍,24个OBU最多可以模拟72辆车,通信节点矩阵实景如图3所示。

图2 测试路段实景图

图3 路侧通信节点矩阵实景图
测试过程如下:
第一步:数据采集平台采集道路交通数据,主要为通过该路段的车辆行驶数据,包括车辆类型、车辆识别号、车辆经度、车辆纬度、车辆高度、车速、车辆航向角、车长、车宽、车高。
第二步:应用服务器从行车数据中提取典型场景,建立DT场景库。
第三步:将场景车辆行驶数据通过通信节点矩阵模拟重现,即将车辆特征属性转化为BSM数据包,再通过V2X发送,VUT接收数据包,并对其作出相关应用响应。
第四步:将VUT的应用响应数据上传到应用服务器,生成测试报告。
1.2 数据预处理
由于激光雷达采集的数据存在一定瑕疵,因此需要首先进行数据预处理,以替换无效数据,去除噪声点。
1.2.1无效数据替换
环境因素和系统误差可能导致激光雷达数据采集错误,具体反应为加速度和巡航速度异常,需要将这些异常点去除并替换。
本文采用离散小波变换(DWT)[19]寻找速度异常值,公式如下所示:
DWT(j,k)=〈x(t),ψj,k(t)〉
(1)

(2)
式中:x(t)为输入信号;ψ(t)为变换函数,这里选择Haar函数,高能量点被认为是速度异常值。
加速度异常点则基于正常加速度的取值范围为[-8 m/s2, 5 m/s2][20]判定。
发现异常点后,本文采用拉格朗日多项式插值法计算获得异常点替换值,公式如下所示:

(3)
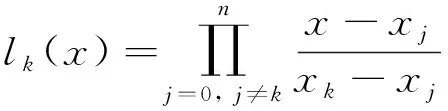
(4)
式中:y为输入数据;x为数据的帧数。
1.2.2噪声点去除
一般而言,激光雷达数据中的噪声表示出高斯白噪声特征,因此本文采用无迹卡尔曼滤波去除激光雷达数据中的噪声[21]。
假设测量噪声协方差为R,过程噪声协方差为Q。R值由激光雷达的物理特性决定,根据激光雷达说明设置为[36,36,1,0.01]。
Q是一个非零小常数,本文设计的Q值计算方法伪代码如算法1所示,对应的变量和函数如表1所示。

表1 算法中变量和函数的解释
Algorithm1Determine ParametersQ
Input:Q=Qnew=0.01
Output:Qnew
1:forQ<1do
2:ifCalRsigE(Q) > 0.95 and |CalAcc(Q)|<5 then
3:Qnew= CompareRsigE(Q)
4:Q=Q+0.01
5:endif
6 :endfor
7:returnQnew
1.3 总体流程图
本文提出的典型场景提取和识别方法的流程如图4所示。

图4 总体流程框图
2 场景评价参数
根据C-V2X day1测试要求,本文重点关注前向碰撞预警、变道预警、交叉路口碰撞预警3个典型场景,并基于场景特征提出了场景评价参数定义方法。
2.1 3种典型场景
如前所述,DT场景必须来自测试路段的真实交通数据。因此,应首先研究道路交通数据的有效性。
一般来说,碰撞风险可通过MTC(margin to collision)[22]反映。本文在MTC的基础上提出MMTC(modified margin to collision)参数来反映碰撞风险,该参数描述了前车突然刹车以避免碰撞的反应时间。
2.1.1前向碰撞预警(FCW)
假设前后车在一条直道上,在同一车道且沿同一方向行驶,其MMTC值由下公式计算:
(6)
式中:xr为两车相对距离;df和dp分别为前后车减速停车时的制动距离;vf和vp分别为前后车辆的速度;af和ap分别为前后车减速的加速度,路面干燥时设为0.75g,路面湿滑时设为0.5g,g为重力加速度,取9.8 m/s2。
2.1.2变道预警(LCW)
在变道过程中,本车应关注周围车辆的潜在碰撞风险,包括当前车道的前车、目标车道的前车和目标车道的后车。
综合考虑以上3种风险因素,并计算相应的MMTC值来表示LCW场景的典型性,分别表示为tMMTCc0,tMMTCt0和tMMTCt1。
2.1.3交叉路口碰撞预警(ICW)
假设两辆车沿着交叉路口的交叉路径行驶,并且在交叉路口发生碰撞,按照以下公式计算tTTCdiff值:
(7)
tTTCdiff=tTTCsafe-tTTC=t1+t2+t3+t4-tTTC=
(8)
式中:xh和xr为碰撞点与主车辆(HV)和另一车辆(RV)当前位置的距离;vh、vr为HV和RV的巡航速度;t1为驾驶员的响应时间,一般在0.4~1.0 s,本文设置为1 s;t2为液压制动响应时间,本文设置为0.2 s;t3为制动响应时间,一般在0.15~0.3 s,本文设定为0.2 s;g为重力加速度,取9.8 m/s2;μ为轮胎-路面附着系数,路面干燥时为0.75,路面湿滑时为0.5。
2.2 场景评价参数
道路交通数据的评价参数应考虑碰撞风险和交通质量。
3个典型场景的碰撞风险参数见2.1节。
采用宏观交通质量因子D、微观交通质量因子CVj、纳观交通质量因子DVj、车辆质量因子Degoj[13]和区域危险等级E{r}[17]5个因子描述交通质量,具体定义如下:
D=numveh/(s*t)
(9)
式中:numveh为在时间间隔t内经过观察车辆的车辆数;s为平均巡航速度。
(10)
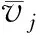

(11)


(12)

(13)
式中:V为道路目标区域内所有车辆的平均速度;Ji, j为车辆i和车辆j之间的关联强度;H(i)和H(j)分别为车辆i和车辆j的健康等级。
2.3 关键场景聚类打标
根据以上场景评价参数,本文采用k-means聚类方法对3种典型场景数据进行分类。考虑到场景差异,使用评价参数方差作为聚类参数选择的依据,最终选取的聚类参数如下所示:
1) FCW:Feafcw={tMMTC、D、CVj、Degoj、E{r}}
2) LCW:Fealcw={tMMTCc0、tMMTCt0、tMMTCt1、
D、CVj、Degoj、E{r}}
3) ICW:Feaicw={tMMTCdiff、D、CVj、DVj、
Degoj、E{r}}
前期聚类结果表明,聚类类别数K范围为2~13,根据不同K值聚类的Calinski-Habasz(CH)评分[23]来选择聚类效果最好的K值。聚类过程伪代码见算法2,对应的变量和函数列在表2中。
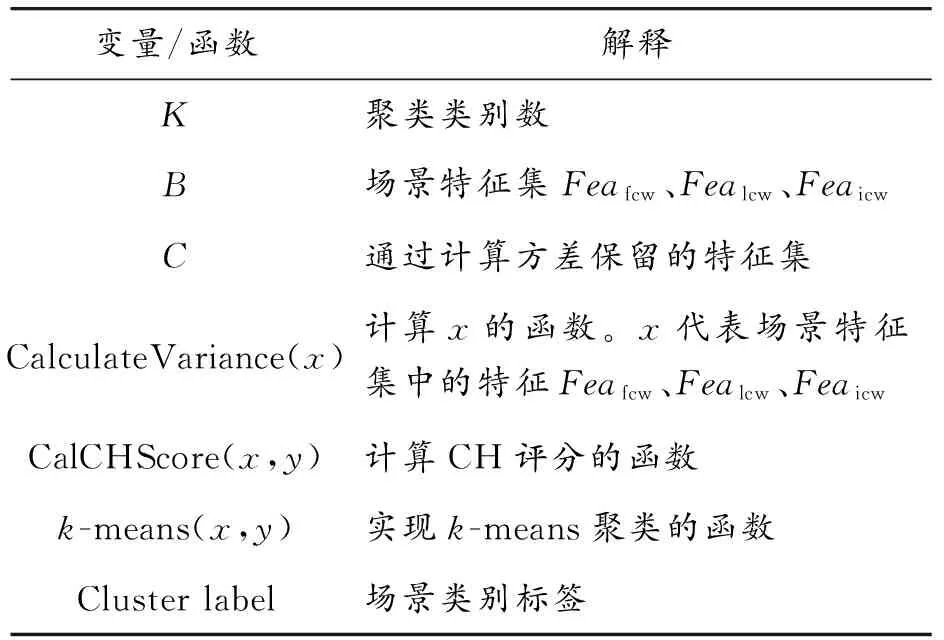
表2 算法2中变量和函数的解释
Algorithm2Criticality scenario clustering algorithm
Input:
Cluster numberK,Scenario evaluation factors setB, Final scenario evaluation factors setC
Output: Cluster label
1:foreachb∈Bdo
2:ifCalculateVariance(b) > 0.05then
3: C.pushback(b);
4:endif
5:endfor
6:forj←2 to 13do
7:ifCalCHScore(j) is maximum in this loop then
8:K=j;
9:endif
10:endfor
11: Cluster label ←k-means(K,C);
12:returnCluster label
3 典型场景识别模型
本文提出了一种LSTM-AE-Attention模型以识别典型场景。本节中将首先定义3个典型应用场景的特征矩阵,然后详细分析典型场景识别模型。
3.1 构建特征样本
典型场景的特征选择有3种。
3.1.1FCW
FCW在时间t上的特征矩阵定义为:
Pfcw(t)=[vl,al,lenl,widl,vf,
式中:vl、al、lenl、widl分别为前车的巡航速度、加速度、车辆长度和车辆宽度;vf、af、lenf、widf分别为后车的巡航速度、加速度、车长和车宽。

那么场景的数据集表示为:
Sfcw={Pfcw0,Pfcw1,…,Pfcwi}
3.1.2LCW
LCW在时间t上的特征矩阵定义为:
Plcw(t)=[νego,aego,ωego,lenego,widedo,νol,
aol,ωol,lenol,widol,νtl,atl,ωtl,lentl,
widtl,νtf,atf,ωtf,lentf,widtf,disego_ol,
式中:νego、aego、ωego、lenego、widego分别为主车的巡航速度、加速度、角速度、车长和车宽;νol、aol、ωol、lenol、widol分别为当前车道上前车的巡航速度、加速度、角速度、车长和车宽;νtl、atl、ωtl、lentl、widtl分别为目标车道上前车的巡航速度、加速度、角速度、车长和车宽;νtf、atf、ωtf、lentf、widtf分别为目标车道上后车的巡航速度、加速度、角速度、车辆长度和车辆宽度;disego_ol为当前车道上本车与前车的相对距离;disego_tl为目标车道上本车与前车的相对距离;disego_tf为目标车道上本车与后车的相对距离。
场景的数据集表示为:
Slcw={Plcw0,Plcw1,…,Plcwi}
3.1.3ICW
ICW在时间t上的特征矩阵定义为:
Picw=[vego,aego,ωego,lenego,widego,voth,
aoth,ωoth,lenoth,widoth,disego,
式中:νego、aego、ωego、lenego、widego分别为主车的巡航速度、加速度、角速度、车长和车宽;νoth、aoth、ωoth、lenoth、widoth分别为另一车辆的巡航速度、加速度、角速度、车长和车宽;disego为本车与碰撞点之间的距离;disoth为另一车辆与碰撞点之间的距离。
场景的数据集表示为:
Sicw={Picw0,Picw1,…,Picwi}
3.2 LSTM-AE-Attention模型
本文提出的LATM-AE-Attention模型如图5所示。

图5 LSTM-AE-Attention神经网络模型结构框图
如图5所示,LSTM-AE-Attention模型包括自动编码神经网络和典型场景识别神经网络两部分。
3.2.1自动编码器神经网络
自动编码(AE)网络用于预训练模型并提取重要特征。编码器Q1将场景数据S映射为隐式特征向量c=[c1,c2,…,cd],然后解码器Q2将向量c映射成与S维数相同的序列。AE旨在减少Q1的输入和Q2的输出之间的差异,使c能够用于表示S。
3.2.2典型场景识别网络
典型场景识别网络由编码器Q1、单层LSTM和注意力层组成。注意力层扫描特征向量c得到注意特征,并根据注意特征的注意等级设置权重因子,相关定义如下:

(14)
R(cν)=tanh(Wνcν+bν)
(15)

(16)
式中:qrci是场景典型因子,是合并层计算的隐式特征向量c的加权和。密集层以权重Wν和神经元的偏置bν完成从cν到R(cν)的非线性映射,然后通过softmax函数h计算权重因子αν。Wν、bν和softmax函数h的平滑因子在训练过程中不断更新。
4 实验和结果分析
4.1 典型场景聚类和打标
以LCW为例说明实验过程。如上所述,根据场景评价参数方差来选择聚类参数。LCW场景评价参数的方差为表3所示。

表3 LCW场景评价参数的方差
根据表3,选择方差较大的5个参数进行聚类,包括tMMTCc0、tMMTCt0、tMMTCt1、D、E{r},不同聚类类别数k对应的CH评分如图6所示。

图6 CH评分曲线
根据CH值,聚类类别数k应设置为6,聚类结果如图7所示。

图7 聚类结果直方图
tMMTC越低,场景危险度越高,此外,D和E{r}越高,交通质量越差。根据上述标准,类别5被认为是典型场景。
4.2 典型场景识别
数据集包括25 406个FCW场景,其中4 827个是典型场景;13 308个LCW场景,其中2 661个是典型场景;4 006个ICW场景,其中841个是典型场景。
本文将数据集的80%作为训练集,20%作为测试集。根据实验结果,学习率选择为0.006。以LCW场景为例,训练结果如图8所示。

图8 训练结果曲线
为了验证模型的有效性,将LSTM-AE-Attention模型与其他模型进行了对比。
使用精度、召回率和F1值3个评价指标来评价模型性能,公式如下所示:
(17)
(18)
(19)
式中,STP,SFP和SFN分别表示真阳性样本、假阳性样本和假阴性样本的数量。
由于LSTM-AE-Attention是复合模型,将模型各个模块拆分评价各模块贡献,首先对比不采用自编码网络、自编码网络采用门循环单元(gate recurrent unit,GRU)和自编码网络采用LSTM网络来对比效果,实验结果如表4所示,然后分别采用支持向量机(support vector machine,SVM)、随机森林(random forest,RF)、极限梯度提升算法(extreme gradient boosting,XGBoost)、LSTM和添加注意力模块的LSTM(attention)进行分类。
从表4可知,采用AE的模型在这3种指标上的表现普遍优于其他没采用AE的模型。AE对模型的典型场景识别精度进行了有效提升。不同预测模型的实验结果如表5所示。

表4 模型组件的实验结果
从表5可以看出LSTM-AE-Attention优于其他预测模型,加入注意力模块能够提升模型性能,实验结果证明了所提方法的可行性和准确性。

表5 不同预测模型的实验结果
4.3 DT测试系统场景注入
数据采集平台采集道路上真实车辆行驶数据,经过数据预处理和本文的典型场景提取识别后,可得到真实驾驶数据种典型测试场景孪生体,以之为基础可构建智能网联孪生测试基础场景库。
当执行孪生测试时,测试系统将根据待测车辆VUT(vehicle under test)的测试项目需求和车辆所处的真实道路环境从场景库中选择匹配场景,并将场景中的背景因素,如道路环境、车辆密度、多普勒频移、信道衰落、雨雾衰减等映射为测试系统各个通信节点的发送功率、发送速率等配置参数,将行车轨迹映射为BSM数据包,并通过节点阵列发送BSM数据模拟测试场景中虚拟车辆,实现孪生测试场景的下发;VUT生成BSM数据包,节点阵列根据接收的VUT数据包跟踪VUT轨迹,并以之为参考进行场景微调,更新BSM数据包内容,VUT则根据接收的BSM数据包触发应用响应,应用响应信息通过4G/5G网络上传至中心服务器,与此同时,节点阵列也将VUT数据包接收数据通过以太网上传至中心服务器,中心服务器则以之为依据生成测试报告,包括应用响应测试结果分析和通信性能测试结果分析。
5 结论
在V2X产业化过程中,道路测试的有效性受到质疑,目前成熟的ADAS测试方案无法评估通信性能对V2X典型应用的影响。基于DT的ICV测试方案旨在通过通信节点阵列构建虚拟交通场景,是一种有效的解决方案。
为了促进基于DT的ICV测试方案的成熟,本文致力于解决基于DT的ICV测试方案设计的挑战之一——关键场景选择。
基于CMVR提供的激光雷达数据集和路边DT系统,从实车驾驶数据中提取了3个典型的V2X应用场景,在综合考虑碰撞风险和交通因素的前提下,提出了一种场景典型性评估方法,同时训练了一个LSTM-AE-Attention神经网络模型识别典型场景。实验结果表明,所提出的方案可以有效地提取典型场景。
考虑的3类典型应用场景是车辆之间的交互产生的部分场景,在未来的工作中,课题组将进一步研究行人、交通信号灯等其他交通参与者以及更复杂的场景;考虑的场景评估因素未来需要考虑通信条件的影响;所建立的数据集采集于单一的道路区域,需要进一步获取其他可用数据集,提升模型的泛化能力。
猜你喜欢
小学生作文(低年级适用)(2022年10期)2022-10-31
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
现代临床医学(2021年1期)2021-01-26
铁道通信信号(2019年6期)2019-10-08
小太阳画报(2018年3期)2018-05-14
雷达学报(2017年6期)2017-03-26
阅读与作文(小学低年级版)(2016年12期)2016-12-22
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
汽车文摘(2015年11期)2015-12-02
