
边坡稳定性自动机器学习预测方法研究*
2023-02-24 05:17张化进吴顺川张中信孙俊龙韩龙强
中国安全生产科学技术 2023年1期
张化进,吴顺川,2,张中信,孙俊龙,韩龙强
(1.昆明理工大学国土资源工程学院,云南 昆明 650093;2.自然资源部高原山地地质灾害预报预警与生态保护修复重点实验室,云南 昆明 650093)
0 引言
边坡灾害作为全球3 大地质灾害(地震、洪水、滑坡泥石流)之一,严重威胁人类生命财产安全。快速、准确、可靠的边坡稳定性评价是边坡工程设计与处治的先决条件,一直是边坡工程关注的焦点问题。目前评价边坡稳定性的主要方法有极限平衡法、数值分析法、稳定性图表法以及监测预警法等[1],但各类方法均存在一定局限性。譬如极限平衡法难以确定临界滑移面;数值分析法的可靠性极度依托于岩土体强度参数与本构模型的确定;图表法的主观性较强;监测预警法数据量庞大易导致分析结果缺乏时效性等。
随着大数据中心、人工智能等新型基础设施建设的提出与倡导,智能决策系统为解决多变量、非线性复杂问题提供方法,并获得广泛认可。人工智能方法如K-近邻(KNN)、支持向量机(SVM)、人工神经网络(ANN)、决策树(DT)等已在边坡稳定性研究领域广泛应用,结合遗传算法、粒子群算法等优化方法,形成一系列以数据为基础、算法为主导的边坡稳定性智能分析体系。张豪等[2]基于KNN模型,构建自适应人工免疫算法提高模型预测准确性;Rukhaiyar等[3]结合粒子群算法与ANN,构建出的优化模型较常规模型取得更好的预测效果;Hoang等[4]运用萤火虫算法对最小二乘支持向量分类算法进行超参数优化,构建的机器学习(ML)模型较元模型精度提高4%。截至目前,大多数学者致力于改进某类ML算法提升模型性能,但不同ML算法适用于不同的问题与数据集。针对某一具体任务,要构建高质量的ML模型,必须进行模型选择和超参数调优,这些工作耗费大量时间与精力,且其效果极度依托于丰富的数字科学经验,而这是多数岩土工作人员不具备的技能,因此目前需要1 种更简单有效的手段预测边坡稳定性。
选择不适合数据集的模型与超参数容易导致模型出现过拟合或欠拟合现象,但现有算法种类甚多,每种算法在泛化能力和复杂度等方面各有优缺点[5]。因此,如何选择合适的模型及其超参数一直是算法工程师迫切希望解决的关键科学与技术问题。为解决这一难题,自动机器学习[6](automatic machine learning,AutoML)方法应运而生,AutoML通过一些技术和方法使尽可能多的工作(如模型选择与超参数优化等)被自动化完成,不需要人工干预和过多的ML领域专业技能与知识,也能构建出比传统机器学习更优越的预测模型,有效提高ML的通用性和高效性。AutoML已成为人工智能领域最热门的研究课题之一,在医疗保健与目标检测等领域已做出一定贡献,但在边坡稳定性评价等岩土工程行业鲜有报道[7]。
截至目前,AutoML中仍没有1 种框架始终优于其它自动化框架,要么适用于某些结构,要么适用于某类任务或数据[8]。因此,针对边坡稳定性AutoML预测问题,亟需分析与评价各种AutoML框架在稳定性预测任务上的有效性及适用性。本文在探讨AutoML现状和特性的基础上,以收集的422 组边坡稳定性状态数据为例,采用5 种主流AutoML框架和6 种传统ML方法构建边坡稳定性预测模型,通过对比分析各模型的预测性能与速度等性质,检验基于AutoML的边坡稳定性预测模型的泛化能力和可行性,以期为边坡稳定性预测提供1种更为便捷有效的预测方法。
1 AutoML框架
AutoML[9]不像传统ML在数据集中拟合1 个模型那样简单,其利用数据集自身性质自动化实现特征工程、算法选择、超参数优化、模型评估及迭代建模等步骤,从而实现所有步骤的端到端过程。本文选择对MLBox、TPOT、H2O、Auto_ml及AutoKeras 5 种主流的开源AutoML框架进行分析,选择上述框架的原因包括以下2点:一是可提供Python API,可在Windows系统下免费使用;二是不需要先验数字科学知识和指定模型及超参数搜索空间,输入数据集可自动完成模型训练。AutoML里包含许多高级算法,不需要深入探索或编译,可自动搜索性能最好的预测模型及其超参数。一般工作流程为:根据训练数据特征,系统自动配置模型结构与超参数,并评估预测性能不断迭代优化,以选出预测效果最好的模型[8]。通用AutoML框架流程如图1所示。

图1 AutoML框架流程Fig.1 AutoML framework flow
1.1 MLBox
MLBox是1 个基于Python 的分布式自动机器学习框架,主要包括数据预处理、模型优化与预测3 个子包[10]。MLBox框架运行速度快,代码量小,稳定性高,但仍处于开发阶段,随时可能发展变动,只能进行基本的特征工程,漂移识别存在移除有用变量的风险[11]。
1.2 TPOT
TPOT全称为树形传递优化技术,是Olson 等[12]开发的基于树的管道优化工具,其采用遗传算法构建特征预处理和建模管道比网格搜索方法更具优势,可最大程度提高ML模型的最终预测性能。TPOP是基于基因编程的框架,因此需要耗费较长计算时间分析数据集[13]。
1.3 H2O
H2O是1 个分布式、快速和线性可扩展的机器学习平台[14]。除实现传统机器学习的算法外,H2O可实现分布式随机森林、梯度提升与深度学习模型,并结合网格搜索与集成算法将性能最好的模型进行聚合。H2O的核心代码是基于Java开发的,使整个机器学习框架能够实现多线程。
1.4 Auto_ml
Auto_ml设计用于产业输出,包括自动化特征响应、数据分析、数据清理、独热编码、深度学习、分类集成等功能[15],并基于树模型从非线性模型中得到线性模型解释,Auto_ml可以处理稀疏数据,适合AutoML初学者进行研究与探索,易于分析和获取生产中的实时预测。
1.5 AutoKeras
AutoKeras是由DATALab 开发的用于创建具有有限数字科学或机器学习背景知识学者可轻易访问的神经结构搜索系统(NAS)[7]。与上述侧重于浅层模型的AutoML框架不同,AutoKeras侧重于深度学习任务,对神经网络支持较好,擅长解决图像与文本分类问题[8],因此对特征工程要求较低。
2 数据与实验
为研究AutoML在边坡稳定性预测领域的可行性与适用性,本文使用上述5 种AutoML框架进行纯自动化训练,在安装AutoML程序库后,输入训练数据,采用默认配置参数,系统自动实现数据预处理、模型选择与超参数优化等过程,直至训练出最优预测模型。结合模型性能度量指标,与6 种传统ML进行比较,评估AutoML的预测性能,以下实验过程均在Win10 CPU 3.2GHz系统的Python 3.7 软件中运行。
2.1 数据集
影响边坡稳定性的因素众多,一般只选择具有代表性的因素评价边坡稳定性。参考文献[16]的预测指标选择方案与结果,选取反映岩体强度、几何因素和地下水状况的岩土体重度γ、黏聚力c、内摩擦角φ、坡角α、坡高H及孔隙压力比γw6 个代表性特征对边坡稳定性进行评价。数据集的规模与质量直接影响构建模型的可靠性,通过文献查询与数据汇编[17],收集422 组边坡稳定性样本,其中处于稳定状态的有226 组样本,处于破坏状态的有196 组。受篇幅限制,本文仅列出其中10组样本,如表1所示。

表1 边坡稳定性预测数据集(部分)Table 1 Prediction data sets of slope stability (part)
考虑到数据集采集受地质条件和稳定性状态评价指标差异的影响,在划分数据集之前,先将样本顺序打乱,再按照4 :1 将数据集划分为训练数据与测试数据。
2.2 性能度量指标
将测试结果根据实际情况和预测结果的组合分为真稳定(TS)、假破坏(FF)、假稳定(FS)和真破坏(TF)4 种,总测试样本数N=TS +FF+FS +TF,分类结果的混淆矩阵如表2所示。为评价各种边坡稳定性预测模型的性能差异,采用准确率Acc、F1分数和受试者工作特征(ROC)曲线下的面积AUC作为客观评价模型综合性能的量化指标,3 个指标的取值范围均为[0,1],值越大表示模型性能越优越。其中Acc与F1的计算分别如式(1)和式(2)所示:

表2 分类结果的混淆矩阵Table 2 Confusion matrix of classification results
ROC曲线根据预测结果对样本进行排序,随后逐个将样本当作稳定状态进行预测,以假稳定率FSR(FSR=FS/(FS +TF))为横坐标、真稳定率TSR(TSR=TS/(TS+FF))为纵坐标作图,得到ROC曲线如图2所示,阴影表示ROC曲线下面积AUC,虚线表示45°对角线。曲线越靠拢(0,1)点,越偏离45°对角线,模型预测效果越好。

图2 ROC曲线与AUC示意Fig.2 Schematic diagram of ROC curve and AUC
2.3 传统机器学习模型
对比的6 种传统ML为逻辑斯蒂回归(LR)、朴素贝叶斯(NB)、KNN、DT、SVM 和ANN模型。不同于AutoML,传统ML目前只支持模型训练,因此为提升传统ML模型的预测性能,适当的数据预处理和模型超参数优化必不可少。
2.3.1 数据预处理
1)缺失值处理
由于数据集中孔隙压力比存在缺失值,因此需对缺失值进行处理。孔隙压力比属性的众数与中位数均为0.25,故以0.25 对缺失值进行填充,使数据完整。
2)标准化处理
由于数据集的数值属性具有较大的比例差异,如坡高与孔隙压力比属性不在同一数量级。因此,在模型训练之前对数据进行标准化处理,转化成无量纲的纯数值,即计算出数据属性的均值μ与标准差σ(σ≠0),按照式(3)将属性转换成μ为0、σ为1 的标准正态分布N(0,1)形式,统一属性量纲。
式中:X为转换后的数值;x为原始值。
2.3.2 超参数优化
6 种传统ML模型中,每种算法都包含1 个或多个重要的超参数,直接影响模型预测性能。本文采用网格搜索算法[17]进行超参数调优,嵌套5 折交叉验证法[18]评估模型性能,选出预测性能最佳的1 组超参数组合。5 折交叉验证法流程如图3所示,将训练数据均分为5个子集(D1~D5),依次留出1 个子集作为验证集,用来性能评估,剩余4 个子集的并集作为训练集训练模型,计算5 个训练模型在验证集上的平均准确率。将作为模型优化指标,搜索具有最高平均准确率的超参数组合,结果如表3所示。

图3 5 折交叉验证法Fig.3 5 fold cross-validation method

表3 网格搜索超参数优化Table 3 Hyper parameters optimization of grid search
2.4 实验结果
在获得各种ML模型的最优预测结果后,为评估模型的预测性能和泛化能力,计算各模型在边坡稳定性状态测试数据上的性能度量指标与运行耗时T,如表4所示。各模型ROC曲线与AUC如图4所示。
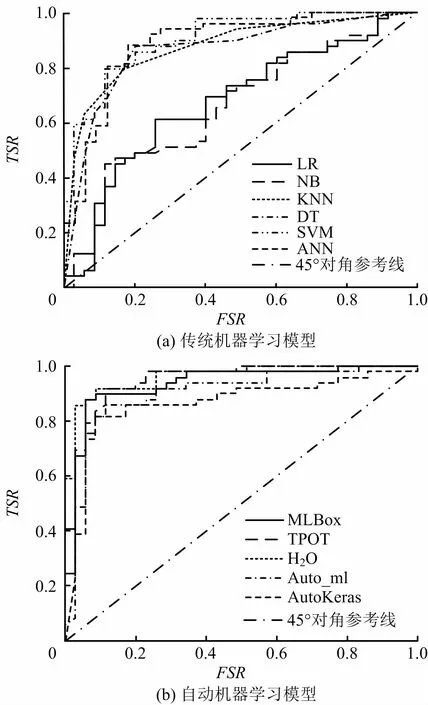
图4 各模型的ROC曲线与AUCFig.4 ROC curve and AUC of each model

表4 各模型的性能指标与耗时Table 4 Performance indexes and time consumption of each model
在测试数据上,传统ML模型中的ANN模型预测性能较好(Acc=85.71%,F1分数 =88.68%,AUC=89.01%);DT与SVM 模型性能次之;LR和NB模型表现较差,性能度量指标均未超过70%。AutoML模型预测性能总体上优于传统ML模型,H2O、MLBox框架在边坡稳定性预测中表现较好,尤其是H2O模型的准确率、F1分数和AUC 3 项指标均大于90%,预测性能显著优于传统ML模型,TPOT和AutoKeras训练的模型性能相对较差,但也能获得与ANN模型相匹配的效果。上述结果表明AutoML能够有效地应用于边坡稳定性预测任务,提高预测准确率与鲁棒性。
相对传统机器学习,由于AutoML框架需要训练大量模型,因此运行时间相对更长。本文边坡稳定性预测任务中,除TPOT模型运行约2 h 外,其余AutoML模型收敛较快,均未超过3 min,运行耗时较短。另外,由于AutoML框架能够实现全过程自动化数据预处理、模型选择、超参数优化等一系列工作,仅需导入相应程序库及训练数据即可轻易运行程序,基本不需要数字科学经验和人为干预,便可获得高性能的预测模型,充分验证AutoML更易于被岩土工程领域的技术人员掌握,极大程度上减轻岩土工程师的工作量,具有广泛适用性。
3 讨论
尽管大多数AutoML在许多数据集上能够取得较理想的预测结果,但针对不同的任务类型,目前仍没有1个AutoML框架可以明显超越其它框架[8]。因此根据目前AutoML的研究成果,从特征工程、算法支持、超参数优化、特性和运行速度等方面对上述5 种AutoML框架进行综合比较,结果如表5所示,可为解决类似岩土工程问题提供一定参考。

表5 不同AutoML框架的综合对比Table 5 Comprehensive comparison of differ ent AutoML frameworks
结合表4~5 可知,针对边坡稳定性状态等二分类问题,AutoML是1 种很好的选择,具有较好的鲁棒性和广泛的适用性。对于预测时间要求不高的领域,推荐使用H2O框架,该框架训练模型的预测性能优于其它方法,并提供Web GUI交互式界面,对用户十分友好。如果对预测时间要求较高,则优选MLBox或Auto_ml框架,这2 种方法可快速收敛并获得较准确的结果。AutoKeras不支持特征工程,适用于图像处理与文本分类等深度学习任务。TPOT相较其它框架运行时间花费更多,尽管提供模板选项功能可加快收敛速度,但需要具有一定知识储备的人为干预,不太适用于快速初步的边坡稳定性评价。目前,AutoML正处于早期研发阶段,相信随着工具的发展与完善,在不久的将来预测质量与速度等方面将取得更好的成绩。
4 结论
1)AutoML方法可避免模型选择与超参数优化等挑战性问题,不需要先验数字科学知识,能直接基于边坡稳定性数据集快速自动构建预测模型,为准确、可靠的边坡稳定性状态评价提供1 种简便方法,适合岩土工程领域工作人员研究与应用。
2)基于422 组边坡稳定性数据集训练结果发现,AutoML模型预测性能总体上优于传统ML模型,能够显著提高预测准确率和稳健性,证实AutoML在边坡稳定性预测任务上的适用性和可靠性,对正确评价边坡稳定性具有重要意义。
3)通过综合比较与分析典型AutoML框架的预测性能、速度等方面性质,结果表明H2O和MLBox框架可以快速收敛并获得泛化能力较强的预测模型,更适合于解决边坡稳定性预测等类似的非线性二分类问题。
4)本文仅针对二分类(稳定与破坏)任务,而不同类型(建筑、土木、露天矿等边坡)、不同安全等级的边坡稳定性评判标准不同。因此,下一步应开展AutoML回归分析研究,精确确定边坡安全系数,对稳定性状态进行更精细地量化表达。
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2021年5期)2021-11-19
石油沥青(2021年4期)2021-10-14
有色金属(矿山部分)(2021年4期)2021-08-30
科学与财富(2021年36期)2021-05-10
数学物理学报(2020年3期)2020-07-27
水电站设计(2020年4期)2020-07-16
厦门理工学院学报(2016年1期)2016-12-01
现代工业经济和信息化(2016年22期)2016-08-23
燕山大学学报(2015年4期)2015-12-25
