
基于卷积神经网络的全球海洋叶绿素a浓度反演方法
2023-02-22 06:27:00孙茜童韩春晓范宇华王天枢
光谱学与光谱分析 2023年2期
孙茜童, 付 芸, 韩春晓, 范宇华, 王天枢
长春理工大学光电工程学院, 吉林 长春 130012
引 言
叶绿素a(Chlorophyll-a, Chl-a)占浮游植物去除自由水后干重的1%~2%[1]。 当水体环境受到污染时, 浮游植物的数量将增多, 其中叶绿素a的含量也会迅速增加。 对叶绿素a浓度进行监测能够预防水质恶化、 浮游植物过多, 是一种非常有效的水体环境保护手段。 地球上广袤的海洋不仅蕴含着丰富的资源, 而且海洋环境严重影响着全球的气候。 叶绿素a浓度的传统检测方法是分光光度法, 该方法采样点有限, 限制了建模精度。 近些年, 采用卫星遥感影像进行环境监测已成为一种趋势, 它具有覆盖范围广、 分析耗时短等优势。 同时, 采集不同时间、 不同地点的数据建立数据库, 可以长期监测多种海洋环境参数。
随着定量遥感技术的发展, 叶绿素a浓度反演建模技术也逐渐发展起来。 目前比较成熟的方法有基于物理光学模型的分析算法[2]、 基于波段组合的经验算法[3-4]、 特征荧光峰算法[5], 以及支持向量机与神经网络等机器学习的方法[6-8]。 由于物理模型反演中一些输入参数较难获得, 且反演过程受许多不可控因素的影响, 导致该方法的反演精度受到限制[9]。 传统的机器学习方法在捕捉空间光谱与Chl-a浓度之间的复杂关系时建模能力有限, 而且计算效率较低, 无法实现对大批量和大尺寸的遥感影像数据的实时处理与分析, 因此采用传统的机器学习方法反演Chl-a浓度也是比较困难的[10]。 随着计算机硬件的研发和深度学习理论的发展[11], 卷积神经网络(convolutional neural networks, CNN)快速地发展起来, 已经广泛地应用于遥感影像处理领域。 遥感影像同时包含空间信息和光谱信息。 卷积神经网络在处理遥感影像时充分利用各种信息, 且在计算效率和分类准确度等方面具有极大的优势[12]。 谢婷婷等[13]根据高分一号宽幅相机的影像数据, 分别使用光谱响应函数和影像像元反射率, 采用不同方法构建Chl-a浓度反演模型。 得到的结果是随机森林模型的精度较高, 前者R2为0.895, 后者为0.709。 于博文等[10]首次将卷积神经网络应用于构建全球海洋Chl-a浓度反演模型。 仅使用遥感图像就可以获得接近Chl-a浓度真值的图像, 模型R2为0.901。 证明卷积神经网络在解决反演问题方面具有可行性。 王浩云等[14]提出采用迁移学习的方法反演绿萝叶片的叶绿素浓度。 研究表明, 结合了光谱信息和光学特性参数信息的模型预测效果更好,R2为0.931, 证明了光学参数反演叶绿素浓度方法的有效性。 本工作提出一种二维卷积神经网络建模方法, 应用于不同时间、 地点的海洋区域叶绿素a浓度反演, 使用叶绿素a浓度真值对反演模型进行了精度验证和影像对比。
1 实验部分
1.1 数据源
中分辨率成像光谱仪(moderate resolution imaging spectroradiometer, MODIS)由美国宇航局(National Aeronautics and Space Administration, NASA)研制, 是搭载在Terra和Aqua卫星上的重要仪器。 中分辨率成像光谱仪每48 h遍历整个地球表面一次, 数据涉及36个波段。 这些数据帮助科研人员了解全球遥感的动态, 被广泛地应用于空气质量监测、 土地沙漠化防护、 水质监测等方面。
选择NASA海洋生物加工小组(Ocean Biology Processing Group, OBPG)生产的中分辨率成像光谱仪Level3标准映射遥感影像数据, 包括遥感反射率影像(remote sensing reflectance, Rrs, 单位为sr-1)和叶绿素a浓度影像(单位为mg·m-3)来训练卷积神经网络。 卷积神经网络需要投入大量的数据进行训练, 而现场采集的数据一般数量有限, 因此选用NASA海洋生物加工小组生产的海量叶绿素a浓度数据作为真值来训练模型。 该数据可信度高, 保证构建的反演模型可以通过迁移学习应用到同类型的数据上。 使用的全部数据的时间分辨率均为每月, 空间分辨率均为4 km(赤道位置), 覆盖范围一致。
1.2 流程和数据预处理
卷积神经网络反演模型搭建流程如图1所示。
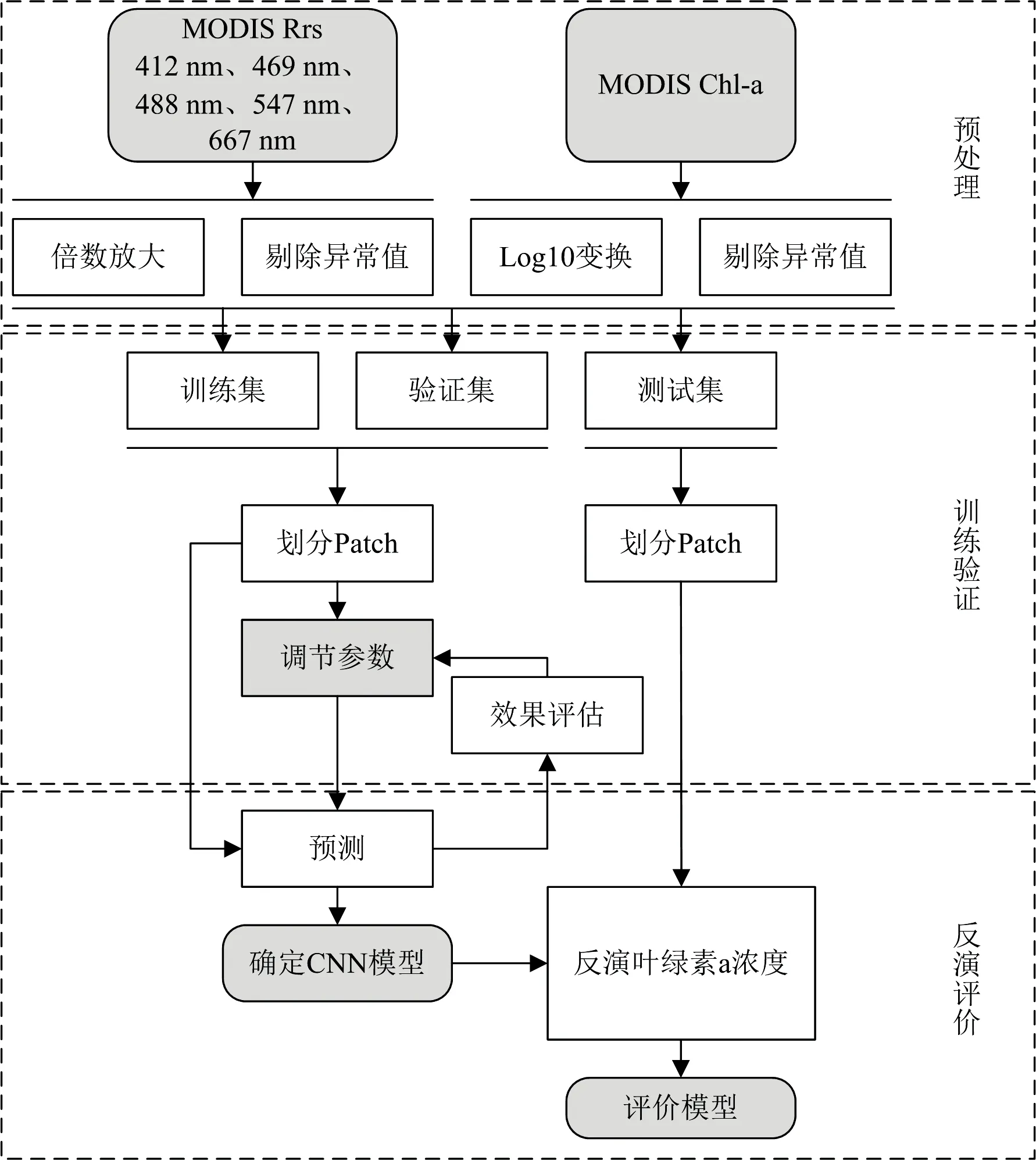
图1 卷积神经网络反演模型搭建流程Fig.1 Convolutional neural network inversion model building process
根据叶绿素a的光谱特征, 选取波段为412, 469, 488, 547和667 nm[15]的反射率数据, 共5个波段。 分别对反射率数据、 叶绿素a浓度数据进行100倍的放大处理, 再取log10对数转换。 反射率数据若有小于0的异常值, 则将其设为0。 反射率数据和叶绿素a浓度数据若是无效值NaN, 根据其不等于任何具体数的特点, 设置条件语句将其替换为0。 经过上述方式的预处理后, 两种数据均不含异常值、 无效值并都处在近似区间内, 有利于构建反演模型。 六幅遥感影像数据预处理前后的统计情况如表1所示。
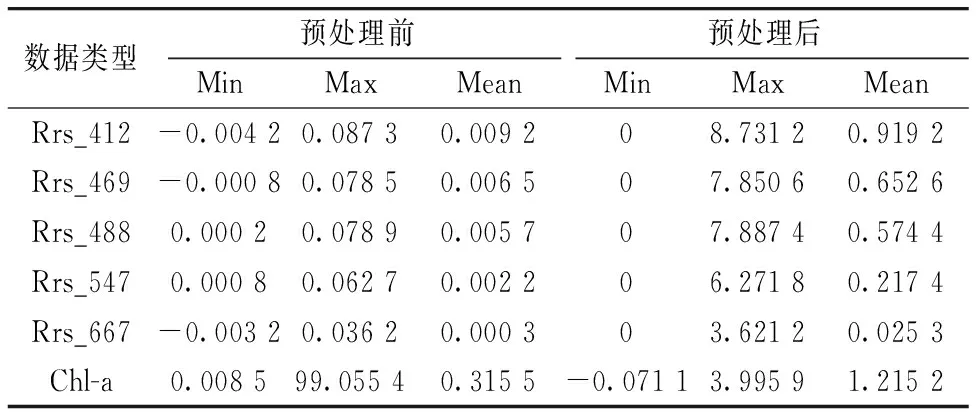
表1 六幅影像预处理前后统计情况Table 1 Details of six images before and after preprocessing
全年12个月反射率图像总共60幅, 每个月有5幅图像, 使用相同的图像尺寸, 4 320 pixel×8 640 pixel。 考虑到平台算力和训练效率, 裁剪大小为1 000 pixel×1 600 pixel的图像构建数据集, 并按照4∶1的比例划分为训练集和验证集。 测试集1和测试集2大小均为400 pixel×500 pixel, 裁剪影像位置如图2所示。 从可视化图像中可以看出, 裁剪位置处的叶绿素a浓度涵盖数据范围较广, 是整幅叶绿素a浓度数据中具有代表性的区域, 其中1为测试集1, 2为测试集2, 3为训练集和验证集。 在计算机算力允许的情况下, 应尽可能地选取较大的训练集, 增加样本数量能够提升模型反演的效果。 搭建环境为Ubuntu20.04, 建模语言是Python, 数据分析软件为ArcMap10.7和Origin 2019b。
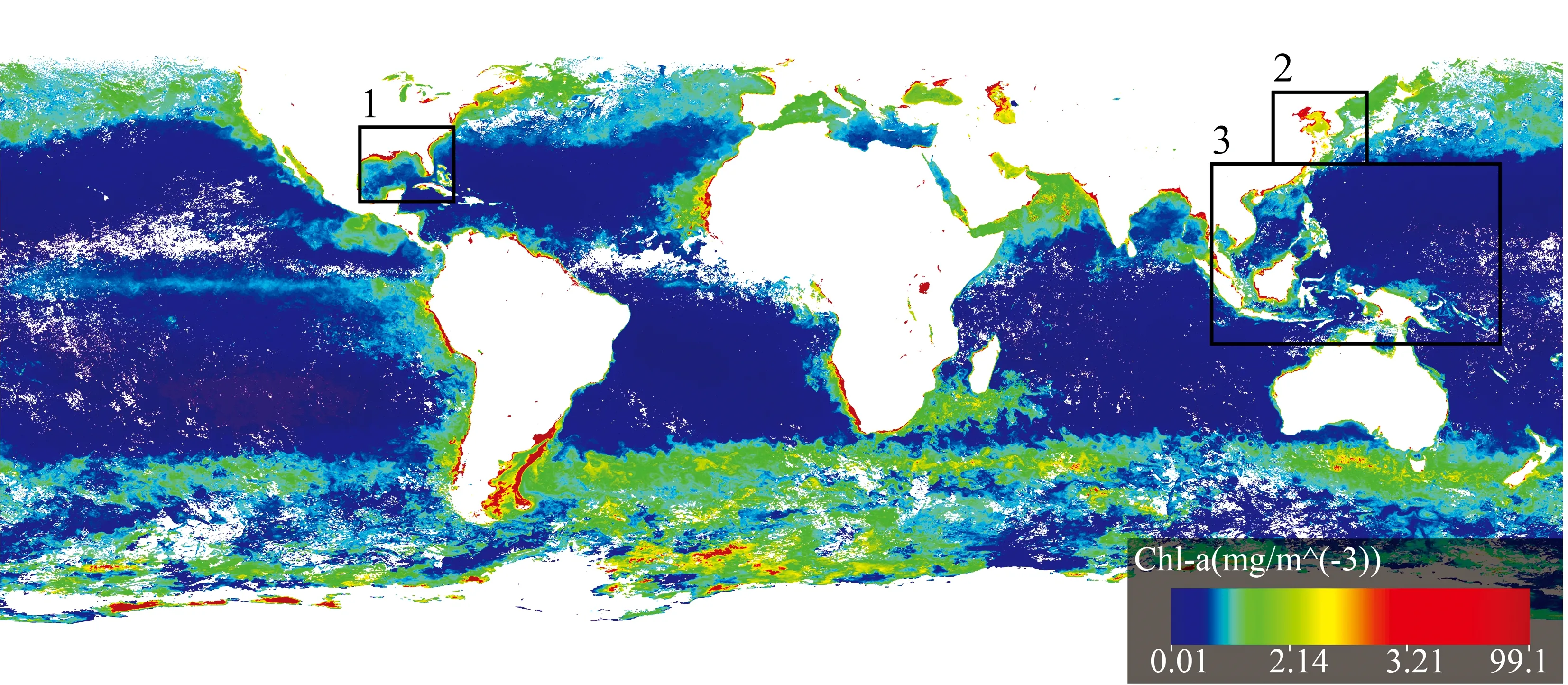
图2 裁剪遥感影像感兴趣区域Fig.2 Cropping the area of interest of remote sensing images
2 结果与讨论
2.1 卷积神经网络
卷积神经网络的建模能力较强, 计算效率高, 适合解决具有复杂性和不确定性的反演问题。 在处理计算机视觉任务中, 卷积神经网络的指标优于机器学习, 根本原因是它能综合利用遥感数据的空间信息和光谱信息。 如今航空卫星图像数据与日俱增[16], 卫星遥感数据量大的特点要求叶绿素a浓度的反演算法能够高效地处理大批量的遥感数据, 因此设计一种提取特征能力强的深度学习算法来解决反演问题是一个重要的研究课题。
2.2 卷积神经网络反演模型结构
增加特征图数目和网络深度都能够提高网络从训练集中提取有用信息的学习能力。 然而, 随着结构复杂度和计算量的提升, 网络容易出现过拟合现象。 因此, 建模时要选取合适的网络深度、 patch大小、 卷积核大小等参数。
填充(padding)操作可以防止丢掉图像边缘位置的信息。 如果不对图像进行填充, 会削弱图像边缘位置的数据提供信息的作用, 而仅突出图像中间位置的数据对训练结果的影响。 此外, 随着卷积层数增加, 图像尺寸逐渐缩小, 不填充也会使最终的图像过小。 选择的填充方式为same卷积, 能够起到填充边缘、 扩大边缘的作用。 反演时patch尺寸会影响中心像素的周边海域范围, 根据实验效果最终使用13 pixel×13 pixel(52 km×52 km)的patch图像块扫描测试集, 即5个波段组合而成的反射率图像, 生成卷积神经网络建模时使用的样本块。
反演模型结构如图3所示, 主体由四个卷积层、 两个池化层、 两个全连接层组成, 最后一层输出Chl-a反演值。 在第一个pooling层、 第二个conv层之后都添加了dropout操作, 防止模型过拟合。 模型加深的同时也应适当地变宽。 遥感图像的空间分辨率有限, 选取3×3大小的卷积核既能充分利用邻域的空间信息, 又能避免大尺寸的卷积核会包含太多与中心像素差距过大的反射率值。
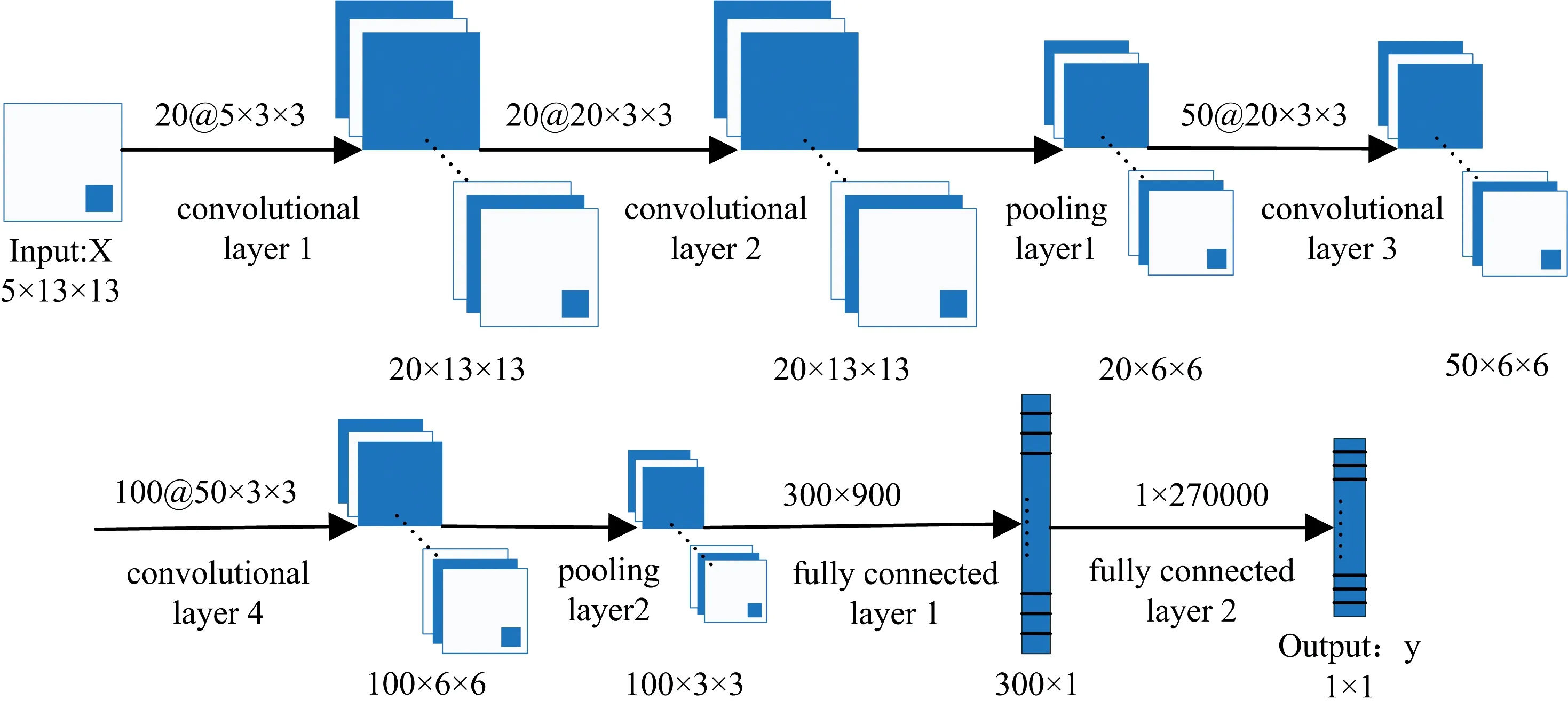
图3 卷积神经网络反演模型结构Fig.3 Convolutional neural network inversion model structure
2.3 卷积神经网络模型反演结果
反演模型评价指标为决定系数(R2)、 均方根误差(root mean squared error, RMSE)以及平均绝对误差(mean absolute error, MAE), 见式(1)—式(3)。R2反映模型的拟合程度, 取值范围是[0, 1], 拟合程度越高, 取值越接近1。 误差说明模型的准确性, 其中RMSE是对误差的平方累加后再开方, 放大了较大误差之间的差距, 受异常值的影响更大, MAE反映的是反演结果的真实误差。
(1)
(2)
(3)
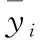
截取2020年全年12个月份的影像, 得到测试集1与测试集2的反演评价指标如表2所示。 其中1, 2, 3, 4, 5, 10, 11和12月份的R2均在0.9以上, 而年中附近月份的R2略低于0.9。 由于建模水域在冬季与夏季所处的温度、 湿度、 光照等其他环境因素都不同, 所以靠近建模月份(即1月份)的数据反演效果会略优于夏季。

表2 2020年全年叶绿素a浓度反演Table 2 Inversion results of chlorophyll-a concentrations for 2020
对两个测试集在12个月份的各项平均值再取均值, 得到本卷积神经网络反演模型R2为0.930, RMSE为0.132, MAE为0.103。
图4(a)和(b)分别是测试集1与测试集2的叶绿素浓度真值与反演预测值拟合情况, 大部分的散点都分布在拟合直线的两侧或线上; (c)是测试集1与测试集2的叶绿素浓度真值与反演预测值分布情况。 分布情况近似, 表明通过训练, 卷积神经网络从Rrs图像和Chl-a图像中提取到了二者之间的非线性关系。

图4 2020年01月Chl-a浓度值(a): 测试集1拟合; (b): 测试集2拟合; (c): 分布情况Fig.4 Chl-a concentration values for January, 2020(a): Test set 1 fit; (b): Test set 2 fit; (c): Distribution
2020年1月的Chl-a浓度反演效果如图5所示。 可以看出, CNN模型获得的预测图像与真值图像具有很强的空间一致性。 对于Chl-a浓度较高的地方(即红橙色区域), 反演颜色要比真值浅, 对于Chl-a浓度较低的地方(即蓝紫色区域), 反演颜色也比真值浅。 真值与反演值的差值如图5(c)和(f)所示, 能够看出CNN反演出来的Chl-a浓度呈现出一种集中趋势, 海洋中部的反演效果要比陆地沿岸处效果好。
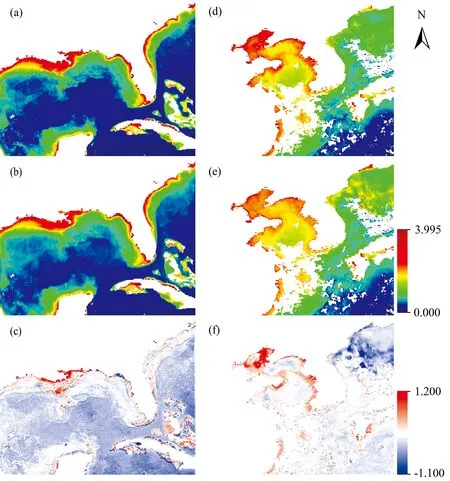
图5 2020年01月Chl-a浓度反演效果(a): 测试集1真值; (b): 测试集1反演值; (c): 测试集1真值与反演值之间差值; (d): 测试集2真值; (e): 测试集2反演值; (f): 测试集2真值与反演值之间差值Fig.5 Chl-a concentration inversion effect for January, 2020(a): Test set 1 true values; (b): Test set 1 inversion values; (c): Difference between true and inversion values of test set 1; (d): Test set 2 true values; (e): Test set 2 inversion values; (f): Difference between true and inversion values of test set 2
在水色遥感领域, 根据光学性质变化的主要影响因素将水体分为Ⅰ类和Ⅱ类[17]。 前者的主要影响因素是浮游植物, 后者的主要影响因素是有色可溶有机物。 通常情况下, 海洋水体受浮游植物影响较多, 沿岸水体由于自我净化能力较弱, 受有色可溶有机物影响较多。 本研究通过patch扫描遥感影像生成训练样本时, 由于I类水体面积远远大于Ⅱ类水体面积, 二者训练样本数量差异过大, 造成了高值Chl-a浓度与低值Chl-a浓度样本不充足的问题, 所以水域中部的反演效果稍好于水域边缘。 如果未来有更多的沿岸水体数据, 可以提升反演精度。 从整体水域来看, 本文提出的CNN模型能有效地反演出海洋Chl-a浓度。
3 结 论
由于采集水体样本受天气和周围环境等实验条件限制, 目前针对内陆湖泊、 河流叶绿素a浓度反演方法主要应用在叶绿素a浓度较高、 面积较小的区域。 面对广袤的海洋, 遥感影像数据量显著增多, 建模工作量也大幅度提升, 因此经典方法的适用性下降。 针对这个问题, 采用CNN方法建立反演模型, 以海洋Chl-a浓度为研究对象, 通过对遥感影像进行组合、 数学变换及剔除异常值等处理后, 输入到CNN中。 结果表明, 叶绿素a浓度反演结果与真值数据具有较好的一致性(R2=0.930)和较低的误差(RMSE=0.132, MAE=0.103)。 本文搭建的网络采用1月份数据训练出的反演模型能够有效地迁移到2月—12月上, 表明其存在更长时间序列反演的能力, 而不需要引入新的观测数据。 同时也能将其应用在不同经纬度的海洋区域上, 具有较好的泛化能力。
猜你喜欢
中等数学(2022年5期)2022-08-29 06:07:38
阅读(科学探秘)(2020年8期)2020-11-06 06:22:48
中国果业信息(2019年1期)2019-01-05 17:41:42
石油地球物理勘探(2017年4期)2017-12-18 07:14:55
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
生物学教学(2017年9期)2017-08-20 13:22:32
电子制作(2017年1期)2017-05-17 03:54:35
智能系统学报(2015年5期)2015-12-03 05:18:20
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
食品工业科技(2014年6期)2014-05-10 06:04:50
