
单次神经网络结构搜索研究综述*
2023-02-20 02:48董佩杰魏自勉陈学晖
计算机工程与科学 2023年2期
董佩杰,牛 新,魏自勉,陈学晖
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
深度神经网络结构的不断创新是推动深度学习技术快速发展的重要因素。以图像识别任务为例,卷积网络的应用使得AlexNet[1]在大规模视觉识别挑战赛ImageNet[2]中远超传统的人工设计特征方法。此后,VGG[3]、GoogLeNet[4]分别采用小卷积核堆叠、卷积模块组合的方式,进一步提升了分类效果。ResNet[5]提出残差模块设计,使得构建上百层高精度分类网络成为可能。MobileNet[6]提出的深度可分离卷积推动了模型轻量化的发展。特征融合[7]、注意力机制[8]等主要以网络结构创新的形式引入,推动了模型结构的发展。但在传统人工模式下,神经网络结构设计依赖于专家知识和开发经验,开发流程复杂,迭代周期长。因此,研究人员开始关注并探索自动化设计网络结构的方法,期望采用智能算法自动地发掘高效网络结构,提出了神经网络结构搜索NAS(Neural Architecture Search)算法。相比人工设计网络,神经网络结构搜索算法可以一定程度上降低对先验知识的依赖,提高模型构建效率,并可进一步指导人工设计。
NAS算法通常采用迭代的搜索方式,在预先设定的搜索空间,通过某种搜索策略采样并评估候选网络,根据评估结果进行反馈,以优化搜索策略,如此迭代直到发现泛化性能最高的网络结构,如图1所示。当前主流的NAS算法,按搜索策略可划分为基于进化算法[9]的NAS算法、基于强化学习[10,11]的NAS算法和基于梯度优化[12 - 14]的NAS算法。无论何种搜索策略,在迭代搜索过程中都需要采样大量候选网络结构进行评估。早期的网络结构搜索算法[11]大多采用从头训练候选网络到收敛的评估方式,导致了过高的计算代价以及过长的搜索时间,难以在大规模数据集例如ImageNet[2]上搜索网络结构。例如,NASNet[15]在ImageNet上使用强化学习算法进行搜索,采用800块显卡训练了28天;AmoebaNet[9]在ImageNet上使用进化算法进行搜索,采用450块显卡训练了7天。

Figure 1 Searching phase of one-shot neural architecture search图1 单次神经网络结构搜索中的搜索阶段
为提升网络结构搜索效率,一系列评估技术相继被提出,例如低保真度[9]、早停机制[16]和代理模型[17]等。这些方法往往通过牺牲评估精度来缩短搜索时间,并且评估过程存在不确定性,无法完全反映在真实任务上的性能。另一方面,一些研究尝试将迁移学习思想引入NAS,由于搜索空间中的候选网络存在结构相似性,能够以相互协作的方式进行训练。通过基于权重共享的迁移学习,候选网络可以继承先前经过训练的、具有相似结构模型的权重参数,并在其基础上进行微调,从而加速候选模型的收敛。作为一种代表性的权重迁移方式,单次神经网络结构搜索(One-shot NAS)[12,18 - 21]算法被提出,因其灵活性和高效性,成为了当前网络结构搜索方向的一个热点。
One-shot NAS将所有网络架构视为超图(Super Graph)的不同子图(Sub Graph)。超图中包含了全部候选操作,因而包含了搜索空间内所有的网络结构。每个特定的候选网络对应超图中的一个子图,不同网络结构之间会继承共同部分的参数。如图1所示,右图对应的子图选择了左图中超图部分候选操作。子图通过重用已训练模型参数,加快了训练和评估过程的收敛速度,进而提高了模型搜索效率。在超图的训练过程结束后,将采样得到的子图进行权重初始化,从头开始训练。
在One-shot NAS中,超图可以视为一种特殊的性能评估器,即对给定网络结构进行性能评估。性能评估过程看重的是不同网络结构之间的相对性能排序,而不是评估结果的绝对值。根据排序相关性假设[22],在训练的某个时刻,如果网络A在某个数据集上的性能高于网络B的,那么当两者都训练收敛后,网络A的性能仍高于网络B的。排序相关性如图2所示,超图上子图模型的排序应与子图模型从头训练的真实性能排序尽可能一致,这样才能保证选择的子图是真实最优的。目前针对权重共享机制对排序相关性的影响还缺乏理论支撑,部分研究[20 - 22]发现,一些One-shot NAS算法的排序相关性较差,无法反映子图充分训练后的性能。Xie等人[23]从优化的角度对基于权重共享的结构搜索算法进行分析,指出排序相关性差是由于优化不足导致的,可以通过改进优化算法充分训练超图来缓解。
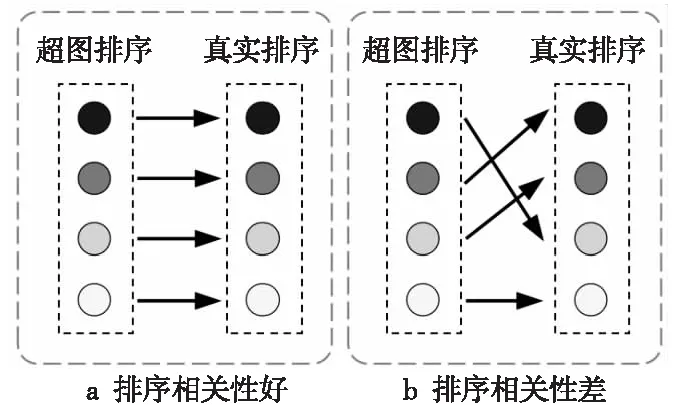
Figure 2 Ranking correlation in one-shot neural architecture search图2 单次神经网络结构搜索中的排序相关性
One-shot NAS中权重共享程度高,子图之间存在协同适应(Co-adaptation)的问题,在子图的优化过程中会存在冲突,降低了超图的收敛速度,也影响了算法的排序相关性。为了更好更快地优化超图,子图的采样策略、过程解耦及阶段性对One-shot NAS算法性能起到了关键作用。
当前已经有一些关于神经网络结构搜索的综述[24 - 26],但是缺少针对单次神经网络结构搜索的综述,许多新方法、新趋势在目前的综述中未能涉及。因此,本文针对当前神经网络结构搜索中的研究热点One-shot NAS及其关键技术进行详细分析。
2 基于权重迁移的单次神经网络结构搜索
在One-shot NAS的搜索过程中,耗时主要集中在评估阶段。由于搜索空间随着候选操作数量的增长呈指数级增长,早期网络结构搜索算法对每个候选网络从参数初始化开始进行充分训练,会带来巨大的计算开销。为加速性能评估,直观的思路是让待训练候选模型继承先前已训练模型知识,重用已训练模型的参数,从而加快收敛速度。在深度学习中,模型学习到的通用特征表达可以用于其他下游任务,迁移学习常用于加速模型的收敛,迁移已有知识来解决目标域中数据量不足的问题。单次学习(One-shot Learning)[27]作为迁移学习的极端形式,其本意是利用迁移学习提升初始模型的泛化能力,使其具备通用特征提取能力,从而可仅用少量样本学习新任务。类似地,One-shot NAS本质也是利用迁移学习提升候选网络特征表达能力,通过共享超图可以使候选网络获得良好的初始化权重,加速子图的收敛。

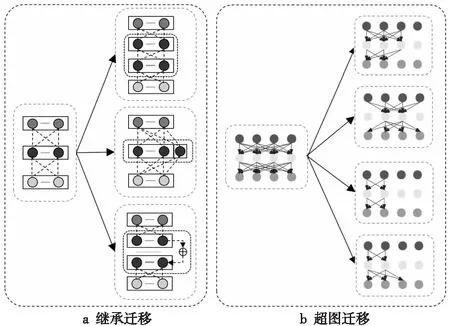
Figure 3 Weight transfer (inheritance transfer and super graph transfer)图3 权重迁移(继承迁移和超图迁移)

关于权重迁移的具体形式,One-shot NAS大多采用权重共享的方式,子网的权重来源为网络结构配置相同的模块或候选操作。例如,在ENAS[18]中,超图是一个有向无环图,被采样的子图会共享相同候选操作中的权重。
此外,也有部分研究通过网络结构编码来生成对应的权重,以实现权重迁移。典型算法SMASH(one-Shot Model Architecture Search through Hypernetworks)[30]引入了辅助超网络(Auxiliary Hypernetwork)[31],能够根据网络结构编码生成对应的权重。但是,这种权重生成的方式本身也需要优化,且迁移的方式缺乏直观解释,增加了迁移的复杂性。
近期一些工作显示,One-shot NAS的权重共享程度越来越高,不同的候选操作之间也能够进行权重共享。例如,Single Path NAS[32]中,较小卷积核会共享超级核居中位置的参数。类似地,OFA(Once For All)[33]也使用了可变形卷积核进行候选操作间卷积核的参数共享。Slimmable Network[34]、 US-Nets(Universally Slimmable Networks)[35]、AutoSlim[36]和FBNetv2(FeedBack Network v2)[37]等支持通道共享,通道数少的操作能够共享通道数多的卷积核的参数。共享程度的提高一方面加速了模型收敛,降低了搜索开销,另一方面也带来了子图间的深度耦合,提升了超图的优化难度[20]。
经典的单次神经网络搜索算法属于两阶段神经网络结构搜索算法(Two-stage NAS),包括搜索阶段和评估阶段。这种做法实际上是将超图作为性能评估器用来指示候选网络的真实性能,如图1所示。首先,将搜索空间设计为超图的形式,使超图包含所有候选操作及隐含的网络连接方式。在每个搜索迭代中,依次执行如下步骤:(1)使用某种策略,从搜索空间中采样子图并进行优化,更新超图对应子结构的参数。(2)从训练好的超图中找出泛化性能最好的架构。(3)初始化最好的架构,充分训练至收敛,得到最终模型。
在上述流程中,采样策略的选取至关重要。在One-shot NAS中,合适的采样策略能够降低子图之间的干扰,从而提升超图的整体性能。采样策略可以分为隐式采样和显式采样,这部分内容将在3.1节详细展开。
单次神经网络结构搜索算法需要同时优化候选网络结构和网络权重。优化方式可以分为解耦优化和耦合优化。解耦优化指的是在优化超图过程中,将对网络结构的优化过程和网络权重的优化过程解耦。耦合优化指的是交替优化网络权重和网络结构。这部分内容将在3.2节详细展开。
单阶段神经网络结构搜索(One-stage NAS)算法针对两阶段神经网络结构搜索训练不充分的问题,提出一些训练策略,有效提升了超图的综合性能,无需评估阶段,这部分内容将在3.3节详细展开。
3 单次神经网络结构搜索关键技术
3.1 隐式/显式采样策略
One-shot NAS中对超图的优化,本质上是按照一定的规则从超图中采样子图并训练子图的过程。采样策略的选择决定了超图的收敛速度、训练的稳定性以及最终收敛结果。根据能否得到明确的网络结构,采样策略可分为隐式采样策略和显式采样策略[38]。
基于隐式采样的One-shot NAS算法无法得到具体的网络结构配置,而是将候选网络结构的选择映射到可微连续参数空间,采样过程隐含于网络结构参数表示的混合概率分布。候选网络结构参数连续化可以将离散空间上的搜索问题转化为连续优化问题,优化结构权重组合及网络权重。例如,DARTS(Differentiable ARchiTecture Search)[12]引入了网络结构参数,将搜索空间松弛化,从而可以使用梯度优化进行网络结构搜索。基于显式采样的One-shot NAS算法能够明确得到具体的候选网络结构配置,典型的采样方法包括使用学习器采样或者从某概率分布中进行采样。例如,ENAS[18]使用递归神经网络学习器采样,并使用强化学习算法优化采样过程。虽然隐式采样可以用连续优化手段提高搜索效率,但在每一步优化过程中,计算及存储代价更高。
3.1.1 隐式采样策略
隐式采样策略可表述为一个可微分的搜索过程,将采样过程隐含于网络结构参数α={αi|αi∈R,1≤i≤m},其表示对应的候选操作O={o1,o2,…,om}的采样概率,其中m表示每层候选操作数量。通过将原来离散选择候选操作的问题进行松弛化,转化为连续空间中的优化问题进行求解。在基于隐式采样策略的结构搜索中,网络结构搜索被建模为双层优化(Bi-level Optimization)问题,即网络权重参数w和网络结构参数α相互影响。
图4展示了隐式采样策略的流程,超图的每条边上有m个候选操作O={o1,o2,o3,…,om},分别对应m个网络结构参数α={α1,α2,α3,…,αm},根据式(1)将离散的选择过程松弛化。
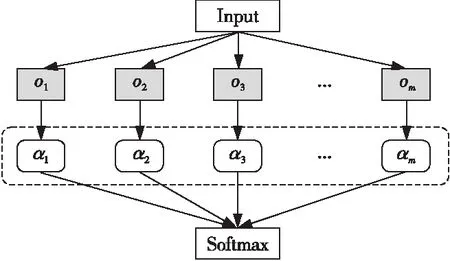
Figure 4 Process of implicit sampling strategy图4 隐式采样策略流程
(1)
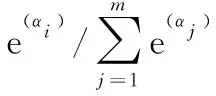
DARTS[12]是可微分结构搜索中的代表算法,是第1个端到端的可微分搜索算法,大幅降低了搜索开销,在单个GPU上训练一天即可完成搜索。DARTS创建了可微分神经网络结构搜索的新范式,但其存在一些亟需解决的问题,例如计算存储占用过高,大规模数据集训练困难,还有性能崩溃问题(Performance Collapse)等。
关于可微分结构搜索算法计算存储问题,梯度优化方法一般需要加载整幅超图,内存占用会随着搜索空间中候选操作数量的增加呈指数增大。反之,在内存受限情况下,搜索空间大小会受到限制。后续一些工作,如SNAS(Stocastic NAS)[39]、GDAS(Gradient-based search using Differentiable Architecture Sampler)[40]、FBNet(FeedBack Network)[41]和DATA(Differentiable ArchiTecture Approximation)[42]等,通过使用Gumbel-Max技巧[43]解决了从离散的候选操作中采样的不可微问题,每次进行前向传播的过程中只更新一幅子图,有效地降低了计算内存占用。PC-DARTS(Partial Channel DARTS)[44]提出了对原有通道数量的1/S进行结构搜索,而剩余通道使用残差连接,能够将内存占用量降低为原来的1/S,同时提出了边归一化技术,增加了训练过程的稳定性。
可微分结构搜索算法被认为是计算密集型网络结构搜索方法,直接应用于大规模任务所需要的计算代价极为昂贵。由于对计算内存要求高,在可微分结构搜索算法上也难以用大批量(Batch Size)进行梯度优化,这更增加了大规模数据集训练的难度。一种常见的处理策略是在代理任务(如CIFAR10数据集[45])上搜索网络的基本单元,再将最优单元迁移至目标任务(如ImageNet数据集[2])。然而,目标任务上的网络模型与在代理任务上搜索得到的网络模型存在深度差异(Depth Gap),借助代理任务进行搜索得到的模型是次优的。P-DARTS(Progressive DARTS)[46]通过渐进增加网络深度来解决深度差异问题,在网络层数增加的过程中逐渐减少候选操作数量以缓解深度差异。ProxylessNAS[47]提出了路径二值化的方法,降低训练过程中的计算存储占用,能够直接在目标任务上搜索。
性能崩溃是DARTS等可微分结构搜索算法存在的特有问题,当搜索轮数过大的时候,搜索得到的结构会包含过多的跳跃连接,导致性能下降。在搜索的初期阶段,超图处于欠拟合的状态,网络结构参数α和网络权重参数w是合作关系。随着训练的进行,由于深层网络优化难度更大,算法会倾向于选择简单的跳跃连接,此时网络结构参数α和网络权重参数w变为竞争关系,导致性能崩溃。针对此问题,R-DARTS(Robust-DARTS)[22]根据海森矩阵特征值发现损失面中曲率高的部分对应的模型泛化性能更差,引入正则化项来降低海森矩阵特征值,能够让DARTS变得更加鲁棒。DARTS+[14]提出了正则化方法,在单元内部跳跃连接过多时停止搜索。DARTS-[48]发现性能崩溃的出现是由于跳跃连接相比其他操作在搜索过程中处于优势地位,于是通过引入辅助跳跃连接来确保所有操作的公平性。
3.1.2 显式采样策略
显式采样策略代表在网络结构搜索过程中可以显式得到网络结构配置,主要包括基于无偏分布的采样策略和基于学习器的采样策略。
基于无偏分布的采样策略发现隐式采样策略中使用的双层优化策略会在优化过程中带来偏差,并没有平等地对待每个子图。因此,优化初期性能较好的结构可能得到更多的训练机会,而某些子结构无法得到充分训练,一些潜在的高效网络结构在搜索过程中可能被忽略。从训练公平性出发,基于无偏分布的采样策略赋予每个候选操作相同的训练机会,最大限度发掘每个候选操作的潜能。Random NAS[49]从无偏概率分布中进行独立采样,使得每个候选操作被选择的概率相同。One-shot[29]在网络结构优化的过程中随机采样子图,同时配合路径丢弃法(Path of Drop out)在训练超图的同时降低子图间的干扰。之后,SPOS(Single Path One Shot)[19]简化了One-shot的搜索空间,构建了单路径的超图,训练超图过程中采用了均匀采样的策略,保证每个层内部的候选操作具有均等机会被采样,能够有效地提升排序相关性。FairNAS[50]指出SPOS中均匀采样策略中不同的采样顺序会对超图的优化产生影响,提出在超图的每次迭代中,每一层可选择运算模块的参数都需要参与训练,进一步提高了模型的排序相关性。
基于学习器的采样策略通过引入额外的学习器完成采样,并根据性能反馈更新学习器参数。基于学习器的采样策略将神经网络结构搜索视为黑盒优化,在无法求解梯度的情况下,通过观察输入和输出,预测黑盒函数的结构信息。强化学习(Reinforcement Learning)和蒙特卡罗树搜索MCTS(Monte Carlo Tree Search)可以用于神经网络结构搜索。强化学习对网络结构搜索问题进行重新建模,通过代理(学习器)与环境的交互过程学习策略,例如,ENAS[18]通过引入递归神经网络作为学习器,顺序地生成网络编码得到网络结构,然后使用REINFORCE(REINFORCEment learning)[15]方法来训练学习器。预算超级网络(Budgeted Super Network)[51]通过引入参数化分布,使用策略梯度算法[52]对网络权重和参数化分布进行优化,指导子网络的采样。然而,强化学习会同等对待所有的状态,不考虑每个状态过去的探索情况,难以很好地做到利用与探索权衡(Exploitation-exploration Tradeoff)。蒙特卡罗树搜索对每个状态建模,在大规模状态空间下效果更好。DeepArchitect[53]首次使用蒙特卡罗树进行神经网络结构搜索,使用蒙特卡罗树对搜索空间进行切割,完成采样过程。AlphaX[54]通过分布式蒙特卡罗树搜索引导迁移学习,利用深度神经网络提高预测网络的准确性,以加速搜索过程。LaNAS(Latent action NAS)[55]在蒙特卡罗树每个节点使用线性函数切分搜索空间,将搜索空间递归划分为包含相似性能网络的好区域或坏区域,显著地提高了搜索效率。LA-MCTS(Latent Action Monte Carlo Tree Search)[56]在LaNAS基础上进行改进,通过在线的方式,使用非线性决策边界划分搜索空间,并使用贝叶斯优化选择候选对象。
3.2 搜索阶段的耦合优化/解耦优化
One-shot NAS算法的搜索阶段由网络权重w优化和网络结构参数α优化组成,根据2个优化过程是否解耦,可以划分为耦合优化和解耦优化[24]。耦合优化一般通过交替优化网络权重参数w和网络结构参数α,在优化过程中两者会互相依赖于对方,相互影响。由于需要结构参数参与优化,目前主要针对可微分神经网络结构搜索算法[12,39,40,47]等隐式采样算法采用优化方法。解耦优化将网络权重参数w优化和网络结构参数α优化2个阶段解耦。第1个阶段优化网络权重参数w,通过优化采样得到的子图得到训练好的超图。第2个阶段优化网络结构参数α,将超图作为性能评估器选择最优网络结构,在优化α的过程中不会对网络权重参数w产生影响。一些结构搜索算法[19,50,57]通过解耦2个阶段有效地缓解了权重共享导致的协同适应问题。耦合优化会使得超图出现协同适应问题,影响了模型的泛化能力;解耦优化虽然避免了以上问题,但是需要解决由于权重共享导致的超图内不同的子网之间的权重耦合问题。
3.2.1 网络权重与网络结构的耦合优化
可微分神经网络结构搜索算法[12,39,41,47]是网络权重与网络结构耦合优化的代表性方法,通过引入网络结构参数θ将离散的搜索空间A松弛为连续搜索空间A(θ),其中松弛后的空间包含了原搜索空间(A⊆A(θ))。通常采用双层优化(Bi- level Optimization)交替优化网络权重参数w和网络结构参数θ,将优化网络权重参数和网络结构参数2个过程以耦合的方式进行优化,如式(2)所示:
(2)
其中,双层优化的复杂度通常由2个变量所决定,求解以上优化问题的复杂度为O(|w||θ|),主要受搜索空间中候选操作个数以及候选操作本身的参数量影响。在网络训练过程中,参数量较少的候选操作可以在短时间内收敛并表达出其相应的功能,而参数量较大的候选操作则需要更长时间收敛。这样会导致出现马太效应(Matthew Effect)[58],即算法会减少在早期表现较差的候选操作对应的结构参数,而结构参数的减少会导致其反向传播的梯度更小,需要更长的训练时间。而由于训练不充分,会导致结构参数进一步减少。马太效应导致算法将过多的计算资源集中于早期表现较好的候选操作,无法充分发挥各个候选操作的作用。R-DARTS[22]发现原来的搜索方式不够稳定,泛化能力较差,通过追踪验证集损失对结构参数二阶导的特征值,发现结构参数在数据集上发生了过拟合。通过使用正则化方法,如早停法、增大正则项及数据增强等,增加了训练过程的稳定性。DropNAS(grouped operation Dropout for DARTS)[58]针对可微分神经网络结构搜索算法中协同适应问题和马太效应,提出根据候选操作的参数量划分小组,每组设置不同的丢弃率(Dropout Rate)参数,缓解了协同适应问题。StacNAS(Stable and consistant DARTS)[59]指出相似候选操作之间相互适应是导致DARTS崩溃的核心原因,提出候选操作聚类(Operator Clustering)方法,使用两级搜索缓解了协同适应问题,提升了算法鲁棒性。BNAO(Balanced one-shot Neural Architecture Optimization)[60]指出参数量小的操作相比参数量大的操作更容易优化,提出了平衡训练策略,使得每个网络结构被采样的概率与其参数量成正比,解决了原来训练方法中存在的优化不足的问题。
3.2.2 网络权重与网络结构的解耦优化
在One-shot NAS中,解耦优化表示将网络结构优化和权重优化解耦为2个阶段,依次优化。第1个阶段,对超图权重wA进行优化:
(3)
其中,优化目标为降低训练集上的损失函数Ltrain。
第2个阶段,对超图权重wA对应的结构参数α进行优化:
(4)
其中,wA(α)代表继承了超图权重的子图,ACCval(wA(α))代表候选结构参数α在验证集上的准确率。以上优化过程是解耦的,求解该问题的复杂度为O(|w|+|α|),其中超图的复杂度受搜索空间影响,而第2个阶段与具体搜索算法设计相关。
超图反映了其所能代表的搜索空间。复杂的超图对应的搜索空间自由度更高,但搜索时优化的难度更大,找到泛化能力最强的网络结构耗时也越久。因此,近期的一些工作借鉴了人工设计网络的经验,在超图每一层提供了多个模块,构成了单路径的超图范式,降低了超图的复杂度。用单路径超图表示搜索空间最早是由SPOS[19]提出的,如图5所示,单路径超图在网络的每一层提供了5个候选模块{o1,o2,o3,o4,o5},每一层可以选择其中1个候选模块。在训练阶段,随机选取单路径子图并使用随机梯度下降算法优化。在评估阶段,使用进化算法从超图中找到最优网络。在单路径超图设计下,虽然复杂度降低,但是其搜索空间依然比较大,需要一定的手段提升优化效率。GreedyNAS(one-shot NAS with Greedy supernet)[57]发现由于搜索空间非常大,期望超图正确预测所有路径的要求过高,不同路径的耦合会导致训练坏的路径对好的路径产生干扰,因此提出了贪婪路径过滤(Greedy Path Filtering)策略,一次性采样一个批次路径,根据在验证集上计算得到的损失进行排序,然后训练损失值比较小的路径,抛弃损失值比较大的路径。BNNAS(NAS with Batch Norm)[61]观察到批归一化中的γ参数起到了指示通道重要性的作用,将γ参数作为衡量子图性能的指标。BNNAS在训练过程中固定卷积参数,只训练批归一化层的参数,进一步缩短了搜索所用时间。知识蒸馏是一个模型压缩的过程,能够将知识从较大的教师网络迁移到较小的学生网络。OFA[33]提出了渐进收缩训练策略,将规模最大的超图作为教师网络,引导规模小的子图的学习,缓解了搜索空间过大带来的优化问题。
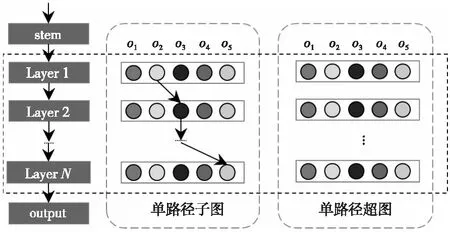
Figure 5 Single path super graph图5 单路径超图
在单路径的超图中,其对应的搜索空间自由度较低,相同层会共享相同的模块,模块间会协同适应。在超图中不同的候选操作之间的优化有着高度相关的行为,并且在训练超图的过程中,子图之间的参数以强关联的方式进行更新,在优化的过程中共享参数会互相影响,不同的子图之间存在一定程度耦合。共享权重一方面有助于彼此训练,但权重共享程度过高则会导致子图之间互相干扰。降低子图之间的耦合度有利于提升One-shot NAS算法的排序相关性。
目前子图间解耦有2种常见的方法。第1种是使用正则化方法进行子图间解耦,路径丢弃法是一种通用的路径解耦方法。One-shot[29]发现使用常规优化方法会导致各部件之间相互耦合,移除任一操作会导致准确率较大幅度下降。为了让算法更加鲁棒,提出了路径丢弃法(Path Dropout)来解耦子网络并使用一种变体的批归一化操作进一步稳定训练。第2种是引入额外权重降低超图的共享程度,从而实现子图间解耦。这类工作的动机来自于文献[21],发现在One-shot NAS中,权重共享度越高,算法的排序相关性越差。为了降低子图之间权重共享度,有些研究通过引入独立于超图的参数来降低子图间的耦合度。文献[62]为了降低单路径搜索空间中的耦合程度,为当前层和前一层的操作引入偏差权重,对输入值进行动态调整,可以在搜索代价不明显增加的情况下提升模型性能。Scarlet-NAS[63]为了解决单路径超图中跳跃连接带来的训练震荡问题,使用线性等价变换来稳定训练过程。Few-Shot NAS[64]针对超图中不同候选操作之间的耦合问题,提出了使用多个超图共同协作覆盖整个搜索空间的方法。在划分搜索空间的过程中,引入了多个不重叠的超图,以互补的方式覆盖完整的搜索空间。类似地,K-Shot NAS(learnable weight-sharing for NAS withK-shot supernets)[65]通过引入K个超图为每个候选操作提供了K个独立的权重,对于每个子图的每个操作,提出使用额外的网络SimpleX生成K个超图组成的凸组合进行耦合优化。
3.3 单阶段/两阶段One-shot NAS
One-shot NAS根据流程可以划分为2类[24]:单阶段神经网络结构搜索和两阶段神经网络结构搜索。Two-stage NAS(如图6所示)包括搜索阶段和评估阶段。在搜索阶段通过优化网络结构和网络权重,得到一些有潜力的模型;在评估阶段从头开始训练,以获得最终模型。典型的算法有ENAS[18]、DARTS[12]和SPOS[19]等。
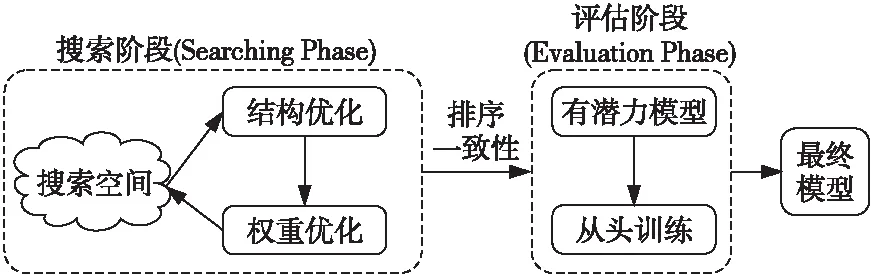
Figure 6 Process of Two-stage neural architecture search图6 两阶段神经网络结构搜索的基本流程
单阶段神经网络结构搜索方法(如图7所示)是近期发展的方法,相比两阶段方法,无需评估阶段,可以直接从超图中得到最终模型。典型的算法有OFA[33]、BigNAS(scaling up NAS with Big single-stage models)[66]和AtomNAS[67]等。
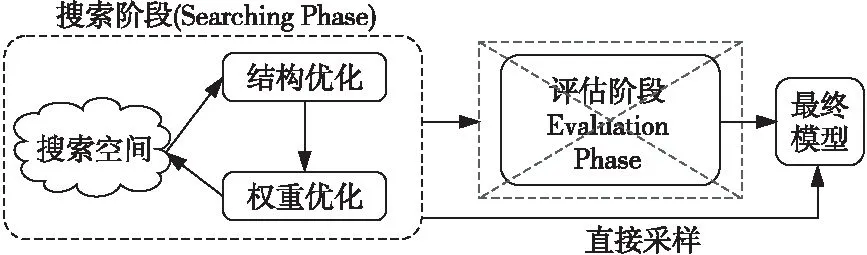
Figure 7 Process of One-stage neural architecture search图7 单阶段神经网络结构搜索的基本流程
3.3.1 两阶段神经网络结构搜索
Two-stage NAS算法[18,19,4]将网络结构搜索问题分为2个阶段。在搜索阶段对超图进行结构优化和权重优化,然后将超图作为性能评估器测试子图的性能,得到有潜力的模型;在评估阶段从头训练有潜力模型,挑选出泛化能力最好的网络作为最终模型。由于Two-stage NAS中超图训练不够充分,在完成搜索阶段后从超图中采样得到的子图的性能较差,因而需要在评估阶段从头训练以达到更高性能。而评估阶段能选择到最优子图的前提是超图的精度排序和子图真实的精度相对排序有较强的相关性。Yu等人[21]对典型的One-shot NAS算法[12,18]进行了评估,发现基于权重共享的算法排序相关性比较差,难以反映模型真实性能排序。为了衡量排序相关性,在Two-stage NAS中需要引入新的指标来衡量超图反映真实排序的能力,一般用肯德尔相关性系数(Kendall Correlation Coefficient)或者皮尔逊相关性系数(Person Correlation Coefficient)来评估超图得到的网络结构排序与网络真实排序之间的相关性。
排序相关性是Two-stage NAS中重要的研究内容,一些研究[21]发现,算法的排序相关性与搜索空间的复杂度有一定关联。复杂搜索空间,如NAS-Bench-101[68]和DARTS类搜索空间[12],排序相关性趋于零;简单搜索空间,如SPOS[19]和FairNAS[50]等使用了精心设计的采样策略,平等地训练所有候选操作,排序相关性较好。Landmark Regularization[38]显式地引入用于衡量排序相关性的正则项,将关键候选网络的性能信息引入超图的优化过程,最大化超图的性能排名与独立网络的性能排名的相关性。还有一些工作通过引入一些新的指标来判断网络的相对性能,例如,AngleNAS(Angle-based search space shrinking for NAS)[69]、RLNAS(NAS with Random Labels)[70]中使用了层旋转(Layer Rotation)来衡量子模型的泛化能力,层旋转越大,其泛化能力越强,模型性能相对排序就越高,有效地提升了算法的排序相关性。NASWOT(NAS WithOut Training)[71]通过对初始化神经网络进行简单的观察,使用汉明距离衡量网络的线性映射情况衡量子图的性能,能够免去训练过程,大幅降低了计算代价。TE-NAS(Training freE NAS)[72]引入神经正切核的频谱和输入空间线性区域数量来衡量子图的相对性能,能够在无需训练的情况下选择最佳网络结构。
3.3.2 单阶段神经网络结构搜索
Two-stage NAS算法中对超图的训练不够充分,将训练好的超图作为性能评估器,用于衡量子图的相对性能。直接继承超图权重的子图在验证集上的性能较差,无法直接作为最终模型。One-stage NAS通过提出一系列有针对性的优化策略,能够让超图中所有子图的性能得到显著提升,甚至超过人工设计的网络结构的性能。因此,One-stage NAS无需通过评估阶段从头开始训练,从超图中直接采样得到的网络模型就能够直接用于部署。这种特性有利于NAS算法从通用硬件到专用加速器的模型部署,提高了算法的应用场景和使用价值。
最早的单阶段神经网络结构搜索算法是OFA[33],提出渐进收缩(Progressive Shrinking)的训练策略,先训练最大深度、宽度和卷积核的最大超图,然后微调超图以支持更小深度、宽度和卷积核对应的子图。这种策略可以为较小的子图提供更好的初始化权重,防止训练过程中多个子图之间互相干扰,提高了训练的效率。在这种方法限制下,所有子图的性能得到了一致性提升。BigNAS[66]遵从了单阶段神经网络结构搜索算法的范式,使用由粗到细的架构选择策略(Coarse-to-fine Architecture Selection)采样子图,并配合三明治法则(Sandwich Rule)和原地蒸馏(Inplace Distillation)对超图进行优化,无需额外的训练或者后处理步骤。这些有针对性的策略能够更充分地训练超图,使得所有子图模型都经过训练,在搜索结束时可以同时取得优秀性能,整体性能得到了一致的提升。CompOFA[89]针对OFA搜索阶段代价过高的问题,认为网络的宽度和深度不是相互独立的,存在复合关系,基于此提出了复合采样策略,使网络的宽度和深度成对缩放,缩小了OFA的搜索空间,使采样得到的模型能够更好地权衡精度和复杂度,将训练时间缩短为原来的一半。AtomNAS[67]从模型剪枝的视角来建模One-shot NAS,通过引入硬件感知的缩放因子来控制搜索空间,在训练超图的过程中,逐步剪枝影响因子非常小的分支,从而得到最终的模型,实现了端到端的搜索和训练,无需从头开始训练。
在可微分神经网络结构搜索中,一些研究工作[39,74]通过降低训练过程中的偏差,维持了整个流程的完整性和可微性,实现了单阶段可微分神经网络结构搜索。SNAS[39]和DSNAS[74]指出大部分可微分网络结构搜索方法无法实现单阶段神经网络结构搜索的主要问题在于搜索的目标函数的近似中引入了过多的偏差。SNAS通过更严格的近似,在每次反向传播过程中同时训练网络结构参数和网络权重参数,使得SNAS中的子图在搜索阶段可以维持较高的验证准确率。但是,SNAS的优化过程需要把整幅超图都存入显存中,导致无法直接在ImageNet等大型数据集上优化。DSNAS进一步解决了SNAS的效率问题,利用Gumbel Softmax替换了SNAS中的结构分布参数,能够直接在ImageNet数据集上进行训练,并且DSNAS派生的网络结构可以直接部署。
4 典型单次神经网络结构搜索算法比较
本节主要关注One-shot NAS算法的3个评价指标,即准确率、参数量和训练耗时。准确率是评估模型性能的重要定量指标,能够反映模型正确分类的能力。参数量反映了模型所有带参数层的权重参数总量,可以用于衡量模型的复杂度。一般来说,参数量越大的模型复杂度越高,模型容量越大,能够拟合的数据规模也越大;训练耗时也是NAS中比较关心的指标,通常使用GPU天来衡量,即搜索算法需要在多个GPU上运行的天数。
NAS中常用的分类数据集有CIFAR10[45]、CIFAR100[75]和ImageNet[2]等。由于ImageNet数据集规模更大,贴合实际应用场景的要求,因此主要关注各算法在ImageNet数据集上的性能表现。典型的One-shot NAS算法在ImageNet数据集上的搜索效果如表1所示,表中汇总了各个算法在文献中给出的结果,其中‘-’代表文献中未公布结果。ENAS[18]和RobustDARTS[22]等仅在小规模数据集(如CIFAR10)上给出了结果,没有提供在ImageNet数据集上训练结果的算法,没有纳入此表。另外,表1中的一些算法,如DARTS[12]、GDAS[40]和SNAS[39]等并没有在ImageNet上直接搜索,而是将CIFAR10作为ImageNet数据集的代理任务,将在代理任务上的最优网络结构通过迁移学习的方法迁移到ImageNet目标任务。

Table 1 Experimental results of one-shot neural architecture search algorithms on ImageNet表1 单次神经网络结构搜索算法在 ImageNet 数据集上的实验结果
从表1可知,One-stage NAS算法,如BigNAS和OFA,准确率整体上都要比Two-stage NAS算法的高,能够更好地权衡精度和参数量。但是,其消耗的计算资源更高,以OFA为例,整个训练过程需要在NVIDIA Tesla V100显卡上运行50天。基于可微分神经网络结构搜索的算法在耗时方面远低于One-stage NAS的,以DARTS为代表,整个训练过程仅需在1080Ti显卡上运行1天。
与早期的神经网络结构搜索算法[10,11]相比,One-shot NAS的搜索时间要少很多。具体来说,One-stage NAS算法适用于数据规模大,并且需要多平台部署的场景,因为其无需重新训练子图。而可微分神经网络结构搜索算法则适用于需要快速迭代模型的场景,比如数据集增量更新的情景。由于其计算代价低,能够快速得到目标网络。
5 问题及展望
神经网络结构搜索是自动机器学习领域的研究热点,也是计算机视觉领域的重要研究方向。针对传统神经网络结构搜索算法搜索效率低的问题,One-shot NAS通过超图进行权重共享,有效地降低了训练开销和资源占用。虽然One-shot NAS取得了一定的成果,但是仍存在很多值得研究的问题,主要体现在以下几个方面:
(1)超参数与网络结构搜索的协同优化。不同结构的网络所使用的最佳超参数是不同的,而现有算法在搜索阶段会使用一组固定的超参数进行搜索,在评估阶段则会调整超参数。2个阶段使用不同的超参数带来的差异会导致搜索得到的模型是次优的。近期有些研究工作开始探索这个方向,联合搜索训练超参数和网络结构,取得了不错的效果。
(2)One-stage NAS算法开始崭露头角。早期的基于超图的工作大多属于Two-stage NAS,训练技术不够成熟。单阶段神经网络结构搜索,通过对超图中各个子图进行充分训练,使所有的子图性能得到一致的提升,无需评估阶段,降低了评估阶段带来的开销。One-stage NAS具有广泛的应用场景,适用于在专用加速器上的模型部署,具有较高的应用价值。
(3)搜索空间的设计与探索。早期的工作中搜索空间主要由卷积层、池化层等构成。近期一些工作如GLIT(Global and Local Image Transformer)[77]、BossNAS(Block-wisely self-supervised NAS)[78]将Transformer[76]模块引入搜索空间,探索卷积与Transformer的组合方式,并将其应用在计算机视觉领域,取得了超越卷积神经网络的结果。
(4)无监督网络结构搜索。以对比学习为代表的无监督学习取得了惊人的效果,并且有些研究工作[78]开始结合NAS提出新的训练方案,在排序一致性以及准确率方面取得了新的进展。
6 结束语
本文针对单次神经网络结构搜索算法研究方向,主要从采样策略、过程解耦和阶段性3个方面对关键技术进行综述,有助于研究人员快速了解One-shot NAS领域。神经网络结构搜索算法也存在着一些难题亟待解决,仍需要研究人员共同努力,以推动其真正落地进入产业,推动人工智能领域的进步。
猜你喜欢
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
同济大学学报(自然科学版)(2019年2期)2019-04-02
电子科技大学学报(2016年2期)2016-08-31
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
电测与仪表(2015年15期)2015-04-12
河北科技大学学报(2015年5期)2015-03-11
中央民族大学学报(自然科学版)(2014年1期)2014-06-11
