
基于多尺度注意力机制的道路场景语义分割模型
2023-02-20 09:39:34范润泽刘宇红张荣芬李景玉
计算机工程 2023年2期
范润泽,刘宇红,张荣芬,李景玉
(贵州大学 大数据与信息工程学院,贵阳 550025)
0 概述
对自动驾驶领域而言,语义分割可以对道路场景中的物体进行分割分类,给车辆避让行人等障碍提供辅助信息。文献[4]提出一种全卷积网络(Fully Convolutional Networks,FCN),实现了端到端的分割方法,也使卷积神经网络在图像分割中变为主流方法。文献[5]提出针对语义分割的编码器-解码器的网络结构,通过编码器提取特征,使用解码器恢复特征的结构并对像素进行分类。文献[6]提出U-Net 网络模型,通过编码器-解码器的网络结构、跳连连接等,将语义分割推向一个新的阶段,利用全卷积网络、压缩路径和扩展路径实现图像语义分割。文献[7]将编码器-解码器结构与金字塔结构相结合,收集多尺度信息,提高了分割精度。然而,对于无人驾驶而言,上述的图像语义分割网络在边缘细节上还存在一些问题,如边界分割不明显、小目标物体不易识别、相似物体与重叠物体误判等。
本文将注意力机制与小波变换相结合,设计一种基于多尺度注意力机制的道路场景语义分割模型,利用图像小波变换具有多尺度多频率信息分析的特点,使用小波多尺度变换的原理设计多尺度注意力机制,将原始图像的多尺度信息进行提取与融合。通过保留原始图像的高频特征,对图像边缘轮廓细节更加关注,并借助小波多尺度变换,改善卷积操作带来的高频特征损失问题。此外,在网络中增加残差注意力连接以及层级跳连模块,保留上下文特征信息并加以复用,并使用多级损失函数,在每一个解码器模块后将得到的特征进行输出,将不同分辨率的输出和最终结果进行融合得到损失函数,从而加速网络收敛。
1 相关工作
1.1 图像语义分割
近年来,基于深度学习的分割方法显著提高了分割的准确率和速度,多尺度特征的提取也得到了飞快发展,通过编码器-解码器结构进行图像语义分割的网络,如全卷积网络[4]、U-Net[6]、SegNet[8]等,其编码器通过下采样等操作,将图像压缩并提取特征,最后通过解码器将特征层还原成原始分辨率。金字塔网络能够利用多尺度信息的特点,PSPNet[9]等通过金字塔结构融合多尺度信息进行图像的语义分割,DeepLabV3+[7]则将编码器-解码器与金字塔结构融合,结合不同方法的优势,提高了分割精度。目前在提高模型精度这一问题上,大部分方法聚焦于注意力机制的设计与模块的选择。
1.2 注意力机制
注意力机制在深度学习领域被广泛应用,它可以理解为对于原本平均分配的资源根据注意力对象的重要程度重新分配资源,着重关注需要重点使用的地方,得到更多的特征信息。文献[10]提出一种Non-local 操作获取图像特征,随着通道注意力[11]和空间注意力[12]的提出,不同的注意力机制被运用到语义分割的网络中,如双注意力网络DANet[13]在FCN 结构中引入了注意力机制,特征金字塔注意力网络(Pyramid Feature Attention Network,PFANet)[14]对不同层级的特征添加注意力并结合全局池化与金字塔融合模块提高网络的分割精度。注意力机制的引入补充了网络中的语义信息,增加了特征提取的丰富程度,但伴随着注意力机制的添加,模型的参数量也随之增加。
1.3 深度学习与小波变换
小波变换通过多级分解得到不同频率特征下的不同子带,使之具有多分辨率多尺度分析的特点,通过逆变换更能无损失地恢复原信号,因此常被用于信号处理和图像分析领域。此外,小波变换的多尺度特性也更符合人类的视觉机制。神经网络中不论是卷积操作还是池化操作(最大池化、平均池化),在处理不同频率信息时均有一定程度的丢失,而通过与小波变换相结合的操作可以保留不同频率的信息特征,且不增加额外的参数量。目前小波与深度学习结合方向也有一些探索,文献[15]结合小波变换与残差网络,发现小波变换的更多子带可以提高网络的学习效果。文献[16]提出深度小波超分辨率恢复,通过处理子带恢复卷积提取特征的过程中缺失的细节信息。文献[17]提出将小波变换代替神经网络中的池化操作,保留原始图像的高频信息以及边缘细节。文献[18]则将小波变换集成到编码器-解码器的过程中,提高了网络的运算速度,降低了参数量,但目前还没有将小波变换与多尺度特征融合这两种方式与注意力机制进行结合的处理方法。
2 本文算法
本文采用“编码器-解码器”结构搭建道路场景语义分割模型,其中设计了多尺度小波注意力模块,通过注意力模块加强特征提取的同时保留高频边缘特征信息。编码器网络采用ResNet-34,并移除了全连接层,在编码器与解码器的连接处通过改进的金字塔池化模块将原始图像特征进行多尺度融合,最后通过解码器网络对上述特征进行多次上采样。解码器的每个模块对特征进行2 倍的上采样,并通过卷积和编码器的跳连连接更好地进行特征映射与边缘信息补充,逐步恢复带有语义信息的原始分辨率图像,输出语义分割结果。本文模型结构如图1 所示,图中C为输出通道数,BN 为批归一化处理(Batch Normalization)。

图1 本文模型结构Fig.1 Structure of model in this paper
2.1 多尺度小波注意力机制
采用2D Haar小波变换的离散小波变换(Discrete Wavelet Transform,DWT)[19]可以将原始图像x分解成4 个子带图像,图像大小(即图像分辨率)变为原始图像的1/4。上述操作可同等于使用4 个滤波器(fLL、fLH、fHL、fHH)对原始图像x进行分解,获得xLL、xLH、xHL、xHH4 个子带图像,其中A为低频图像、V为竖直细节图像、H为水平细节图像、D为对角细节图像,滤波器的参数固定,即不随网络训练的反向传播进行梯度下降操作更新参数,步幅设置为2。Haar小波滤波器的表达式如式(1)所示:
使用具有潜在肾毒性药物时应遵循以下原则:⑴严格按照药物适应证用药,尽量选用无毒或肾毒性较小的药物。⑵根据患者的病理生理情况,确定合适的给药剂量、途径、速度和疗程。⑶在用药过程中应密切观察尿量,监测血肌酐、血清胱抑肽C等肾损伤标记物的变化情况。⑷对于已发生急性肾损伤患者应及时停药,促进药物排泄,保护肾功能,维持血压,纠正电解质和酸碱失衡[2]。因此,建议临床在使用膦甲酸钠注射液治疗期间,应当密切监测患者肾功能;避免与肾毒性药物联用;用药前及用药期间应给予充足的水化治疗;发生肾损伤后应及时停药,水化利尿促进药物排泄[3]。
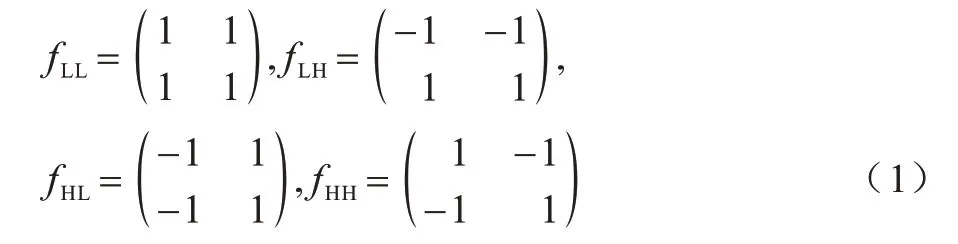
输入图像为x(i,j),其中i为行,j为列,则2D Haar 小波变换的离散小波变换可表示为式(2)所示:
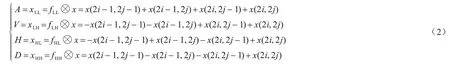
其中:⊗表示卷积操作;输入x可通过与不同滤波器进行卷积操作来表示。
根据上述原理,本文基于小波多尺度变换提出一种多尺度小波注意力(Multi-Scale Wavelet Attention,MWA)机制。不同于通道注意力[11]通过对每个通道进行计算来获取权重,空间注意力[12]通过池化操作反映图像特征,而全局平均池化(Global Average Pooling,GAP)和最大池化得益于其易用性与高效性一般会作为首选。但由于池化操作的特性,不论是最大池化还是平均池化,都不能完整地反映整个图像的特征信息,缺乏对输入信息的多样性处理。文献[20]认为均值信息不足以代表其特点,而平均池化等价于图像变换中的低频分量,因此如果仅使用平均池化,会忽略其他有用的频率分量。受此启发,本文选择结合小波变换的特征与多尺度输入,设计多尺度小波注意力模块,加强对不同频率分量的特征注意力。多尺度小波注意力模块如图2所示。

图2 多尺度小波注意力模块Fig.2 Multi-scale wavelet attention module
2.2 改进的金字塔池化模块
在道路景观分割的过程中,需要充分考虑不同尺度物体的影响,在上下文信息的处理上需要引入不同尺度、感受野的全局信息。在图像语义分割的过程中不仅需要提炼特征图中深层语义信息,并对像素进行分类,也需要浅层特征图中的轮廓边缘信息帮助定位。通过金字塔池化模块可以在编码器与解码器的过渡阶段将网络深层语义与网络浅层轮廓细节相结合,从而充分利用不同尺度的特征信息。
与原始的金字塔池化模块相比,本文替换了3 个不同比例的空洞卷积,并通过小波变换分解得到3 个高频子带,将得到的多尺度特征进行拼接融合。改进的金字塔池化模块如图3 所示。
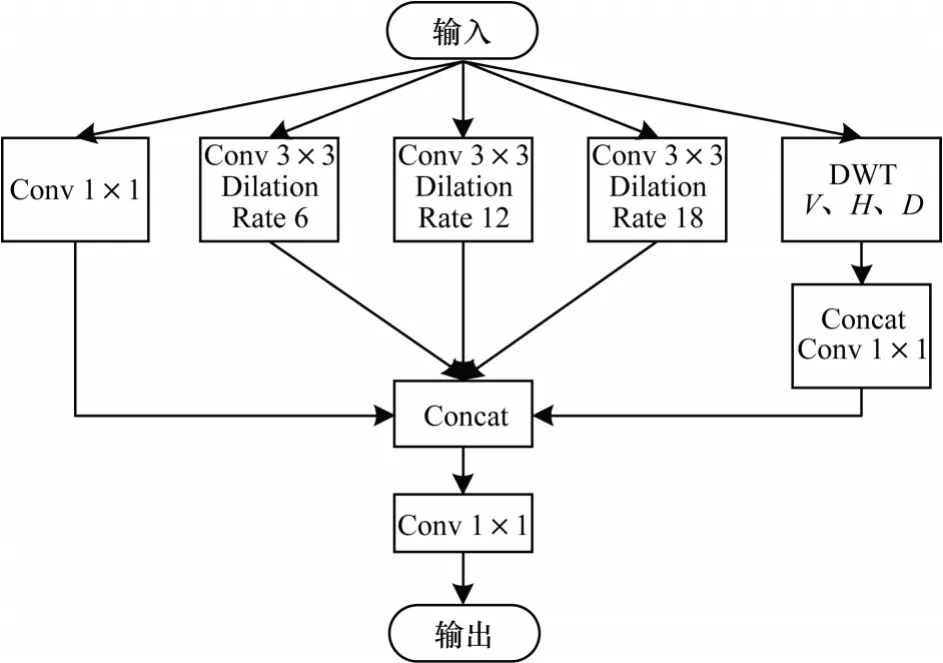
图3 改进的金字塔池化模块Fig.3 Improved pyramid pool module
2.3 编码器与解码器
本文在编码器部分采用ResNet-34 作为骨干网络,同时将本文设计的多尺度小波注意力模块嵌入到骨干网络中,添加注意力机制的同时保留原始输入的高频轮廓信息,通过提取不同频率信息、不同尺度上的特征来提高训练的准确度。解码器由3 个解码器模块组成,其中解码器模块通道数随着分辨率上升而减少。此外,本文还整合了深度可分离卷积[21],其能减少参数量,节约计算成本。通过这些操作进一步提高语义分割的精度与效率。本文通过最近邻上采样增加分辨率,并利用深度可分离卷积整合特征信息。由于在解码器进行上采样的过程难以避免信息丢失,本文利用1×1 的卷积操作,通过解码器跳连连接将编码器提取的特征整合进来,在3 个解码器模块后通过2 个上采样模块将特征层恢复到原始大小。
2.4 损失函数
为提高网络训练效果,本文在每一个解码器模块后加入一个输出,将不同分辨率的输出和最后结果输入到网络末端并最终得到损失函数,损失函数选择交叉熵函数,如式(3)所示:

其中:class 表示像素i的真实标签;x表示像素i在模型输出中相应类别所得分数;N表示输出的整体分辨率。由于还有3 个解码器模块的输出,因此总的损失函数为4 部分损失函数的和,且由于不同输出的分辨率不同,本文根据分辨率的大小分配了不同的权重,从小到大分配比例为1∶2∶3∶4。
3 实验结果与分析
3.1 实验设置及数据集
本文实验环境选择CPU 为AMD Ryzen 9 处理器,内存为64 GB,GPU 使用RTX3090,采用梯度下降法训练模型,优化器选择Adam 并动态调整学习率,初始学习率设置为0.002。
本文数据集采用剑桥驾驶标注视频数据集(Cambridge-driving Labeled Video Database,CamVid)[22],这是一个从驾驶汽车的角度拍摄的、具有目标类别语义标签的场景视频数据集。该数据集共有5 个视频片段,语义类别共有32个,训练集图像367张,测试集图像233张。训练前对图像进行水平与垂直翻转,从而增强数据。
为更好地评估本文模型的效果,本文选择平均交并比(Mean Intersection over Union,MIoU)作为结果的评价标准,其表达式如式(4)所示:

其中:pij表示真实值为i,被预测为j的数量;k+1是类别个数(包含空类别);pii是真正的数量。MIoU 一般基于类别进行计算,将每一类的IoU 计算后累加再进行平均得到的就是基于全局的评价。
3.2 模型对比
本文将现有的几种注意力模型与本文注意力模型在CamVid 数据集上进行对比实验,骨干网络都选择ResNet-34,具体设计与实验结果如表1 所示。

表1 不同注意力模型的对比实验结果 Table 1 Comparative experimental results of different attention networks
在表1中,ResNet网络的MIoU为54.03%,SENet网络比ResNet网络约增加了0.6 个百分点。CBAM 网络的加入使MIoU 提高了1.25个百分点,但参数量也有所提升。FcaNet网络在没有额外增加参数量的情况下MIoU提高了3.44个百分点,这说明提取不同的频域信息对网络分割效果有提升作用。本文设计的多尺度小波变换注意力网络得益于小波变换不额外添加参数量的优点,通过保留不同的高频信息,有效整合了多尺度特征,并提高了网络在多分辨率多尺度下的特征感知能力。
本文在CamVid 数据集上与现有的其他语义分割模型进行对比,实验结果如表2 所示。
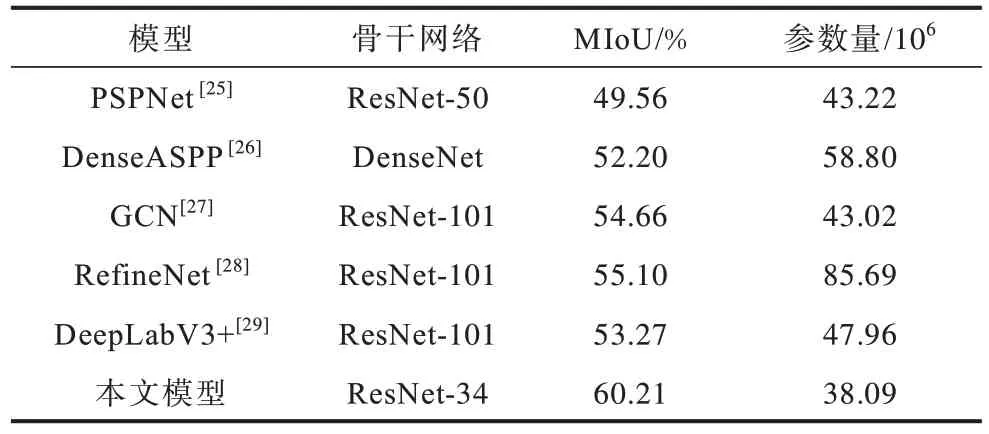
表2 不同语义分割模型的结果对比 Table 2 Comparison of results of different semantic segmentation models
在表2中,与使用密集连接DenseNet 作为骨干网络的DenseASPP 模型相比,本文模型的MIoU 提升了8.01 个百分点,且参数量下降了约2×107。与使用ResNet-50 作为骨干网络的PSPNet 模型以及使用更深特征提取层作为骨干网络的GCN、RefineNet 以及DeepLabV3+模型相比,本文模型在使用网络层数较少的ResNet-34 作为骨干网络的情况下,不仅MIoU 有所提升,而且网络参数量也有所减少。
3.3 消融实验
为对比不同模块与多级损失函数对分割结果的影响,本文针对不同模块进行了消融实验,对比了注意力模块、改进的金字塔池化模块以及多级损失函数的有效性,实验结果如表3 所示,其中“√”表示使用该模块,“×”表示不使用该模块。

表3 不同模块的对比实验 Table 3 Comparative experiment of different wmodules %
由表3 可知,仅添加注意力模块时MIoU 为57.88%,仅使用改进的金字塔池化模块时MIoU 为56.20%,同时添加注意力模块与改进的金字塔池化模块后MIoU 相较于未添加或添加单一模块时的MIoU 均有所提升。实验结果表明,对比其他语义分割模型,得益于小波变换不额外增加参数量,以及整合了多分辨率多尺度不同特征信息的优点,本文模型提高了MIoU,并减少了参数量,在无人驾驶中能够更好地适配移动端计算设备。
为更好地展示模型的分割效果,本文选择具有代表性的DeepLabV3+与DenseASPP 和本文模型进行对比,结果如图4 所示(彩色效果见《计算机工程》官网HTML 版本),小尺度细节对比如图5 所示(彩色效果见《计算机工程》官网HTML 版本)。

图4 不同模型的分割结果对比Fig.4 Comparison of segmentation results of different models

图5 不同模型分割结果的细节对比Fig.5 Comparison of details of segmentation results of different models
图4 为大尺度场景,在场景1(图4 中第1 行)中行人较少,车辆集中在右侧,路面较空旷。大尺度目标检测的难点在于左右两侧的人行道检测。原始图像中人行道长、宽且一直连续,过长的目标增加了模型分割的难度。DenseASPP 模型在左侧人行道检测中只有远处一小部分,丢失了大面积目标特征。DeepLabV3+模型虽检测出了左右两侧人行道,但并不连续且左侧植物部分出现大面积空缺。本文模型不仅在两侧人行道检测连续,在左侧植物检测部分也相对密集。场景2(图4 中第2 行)中车辆较多,植物景观与建筑重叠且密集,给语义图像的连续性分割增加了难度。DenseASPP 模型在远处绿色植物的分割上有不规则的斑块;DeepLabV3+模型在建筑物上有明显的色块;本文模型在植物部分的语义信息饱满,建筑物与天空的语义检测填充也相对密集。场景3(图4 中第3 行)中路面相对空旷,行人集中在图像左侧,大尺度检测目标为天空、道路、人行道、右侧植物以及近端的墙面。DenseASPP 模型在道路、天空和左侧建筑墙面都做出了精确分类,但右侧植物与墙面出现了不规则的斑块,不能很好地将长距离大尺度目标分割开;DeepLabV3+模型虽然在植物与墙面的分割上表现不错,但左侧墙面下的人行道并没有有效分割,并且还有一些误分;本文模型在左侧墙面以及右侧植物的分割上都做出了有效分类。
图5 为不同模型分割结果的小尺度细节对比。在场景1(图5 中第1 行和第2 行)中,难点在于右侧突出的4 个广告牌以及路灯这种小轮廓物体,它们在整体图像中并不突出但边缘轮廓明显,DenseASPP 模型对路灯的检测并不连续,且右侧4 个广告牌只检测出了1 个;DeepLabV3+模型完整检测出了远处的路灯,但广告牌也只检测出了远处的一个,上述2 种模型都没有完整地检测出右侧近端的路灯;本文模型不仅检测出远点和近点的路灯杆,还分割出右侧墙壁的广告牌。场景2(图5 中第3 行和第4 行)中车辆较多,且远处还有行人,难点在于行人之间轮廓重叠的检测与识别,以及在众多车辆之间交通灯的识别,可以看到DenseASPP 模型在右侧远处路灯的识别上不够准确,距离较近的交通灯会出现漏检误检现象。DeepLabV3+模型在检测远侧行人时轮廓不够清晰,没能把行人与周围场景分割开来,且以上2 种模型对灯杆的分割不连续。本文模型在灯杆的分割以及行人轮廓的清晰度上都比上述2 种模型的表现优异。场景3(图5 中第5 行和第6 行)较空旷,只有近处的3 个行人,难点在于右侧贴近墙边的小目标物体,即自行车与交通信号灯的识别,对比本文模型,DenseASPP 和DeepLabV3+模型都没有完全检测出自行车和路灯,对比可知本文模型在小目标物体的分割上要优于DenseASPP 和DeepLabV3+模型。综上可知,本文模型在简单场景的道路分割、复杂场景的重叠目标检测,以及远处小目标物体的识别上均有良好的分割效果,在不同场景下的鲁棒性较好。
4 结束语
本文提出一种基于多尺度注意力机制的语义分割模型,利用小波变换具有多尺度多频率信息分析的特征,设计一种多尺度小波注意力模块,提升对不同尺度特征的感知能力,保留更多边缘轮廓细节。改进金字塔池化操作使网络充分联系上下文特征信息,并通过多级损失函数加速网络收敛。在CamVid数据集上的实验结果表明,本文模型在提升道路场景语义分割精度的同时降低了模型参数量。下一步将通过知识蒸馏、降低模型参数量等手段,实现语义分割网络的轻量化,使其能够部署在移动端设备中。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
家庭影院技术(2019年8期)2019-12-04 14:43:19
计算机技术与发展(2019年1期)2019-01-21 00:56:38
太空探索(2016年5期)2016-07-12 15:17:55
