
基于多目标的能见度检测方法
2023-02-20 09:39:40唐榕李骞唐绍恩
计算机工程 2023年2期
唐榕,李骞,唐绍恩
(国防科技大学 气象海洋学院,长沙 410073)
0 概述
能见度是指人肉眼在没有任何帮助的情况下,所能识别物体的最大能见距离[1],是反映大气透明度的重要物理量[2]。能见度过低会给人类生产生活、交通运输安全等带来危害[3-4],因此加强对能见度的检测,尤其是低能见度的观测检测,具有十分重要的应用价值,已成为地面自动气象观测的重要内容之一。目前虽然已有各种能见度仪被投入业务使用,但与人工观测相比,其检测仍存在较大偏差[5],且能见度仪价格较为昂贵,难以进行密集布设。近年来,随着摄像机的广泛使用,基于图像的能见度检测方法成为解决能见度自动检测问题的一类重要方法[6]。然而现有基于图像的能见度检测方法未考虑场景中不同景深目标物对应子图像的质量受大气悬浮粒子衰减不同的影响,导致整体能见度检测精度下降。
本文提出一种基于多目标的能见度检测方法,在图像中选择多个不同景深的目标物,分别提取各目标物对应的子图像视觉特征,并利用各目标物视觉特征分别训练能见度映射模型。最后使用全局图像动态回归各目标物估计值的权重,通过加权融合得到场景能见度检测值。
1 相关工作
传统的能见度检测方法主要分为目测法和器测法[6]。目测法是指让观测员目测不同距离目标物的清晰程度来判断能见度,其观测结果易受到人的主观因素影响,测量精度较低[7]。器测法是指利用透射仪[8]或散射仪[9]自动估计能见度,这两种仪器均以测量局部能见度代替整体能见度,当空气分布不均匀时,其测量值易受到局部大气悬浮粒子特性的影响,导致存在较大偏差[10]。此外,由于仪器设备通常较为昂贵,难以进行密集布设,因此实现能见度的全方位实时监测[11-12]存在一定困难。
随着摄像机的普及以及各类图像处理算法[13]的快速发展,基于图像的能见度检测方法不断涌现。根据映射关系建立方式的不同,该方法又可以分为模型驱动法和数据驱动法[14]。模型驱动法是指根据大气对图像成像的衰减建立光传播物理模型,通过图像特征估计物理模型参数,以此反推能见度[15],如亮度对比法[16]、双亮度差法[17]、暗通道法[18]等。但由于大气中影响光传播的悬浮粒子种类较多,且粒子空间分布不均匀[15],因此精确的物理模型通常难以准确定义。数据驱动法则是指利用海量经标注的历史数据训练图像视觉特征与能见度的映射模型,由收敛后的模型来预测场景能见度值。如文献[19]将图像梯度和对比度作为反映能见度变化的特征,利用支持向量回归机和随机森林两种算法建立能见度值与视觉特征的关系模型;文献[20]提取兴趣域对比度作为特征向量,构建图像特征与能见度的支持向量回归机;文献[21]使用预训练的AlexNet 深度卷积神经网络提取图像的学习特征,训练多类非线性支持向量机对能见度范围进行分类。数据驱动法将能见度变化对图像的影响完全表征在视觉特征里,通过建立特征与能见度的映射模型来估计能见度值。该类方法通过大量的数据不断优化模型,从而避免物理模型难以准确定义的问题,已成为能见度检测领域的一个重要研究方向。
然而,现有数据驱动法未考虑场景中不同景深目标物对应的子图像质量衰减程度不同的问题,从全局图像提取特征,使得真正能反映能见度变化的局部关键特征被全局特征所平滑。针对该问题,文献[15]提出将样本图像均等分割成9 个子区域,利用预训练的VGG-16 网络对子区域进行编码;文献[22]将所有图像进行灰度平均,从场景中选择静态的有效子区域提取特征。这两种选择子区域的预处理方法在一定程度上增强了图像局部对整体检测效果的影响,但由于每个子区域是被均等或随机划分的,没有考虑实际场景内容、景深距离等,因此所提取的视觉特征仍不能准确反映能见度变化对不同景深目标子图像质量的实际衰减,导致图像中最能体现能见度变化的局部关键信息被忽略。针对上述问题,本文提出基于多目标的能见度检测方法,即选择多个不同景深目标物对应子图像提取视觉特征训练模型,有效融合各目标物的能见度估计值,并将其作为整幅图像的能见度检测值。
2 本文方法
图像中不同目标物因景深不同,对应子图像质量受到大气悬浮粒子衰减的程度也不同,其视觉特征也随之相应变化,例如近距离目标子图像视觉特征在低能见度条件下变化更剧烈,而远距离目标子图像视觉特征对高能见度变化更敏感。同样地,在人工观测过程中,观测员也常在观测点四周不同距离、不同方位选择若干固定目标物[5],再结合整个场景由各目标物可见与否以及其视觉清晰程度来综合判定场景能见度值。受上述过程启发,本文提出一种基于多目标的能见度检测方法,方法流程如图1所示,首先在图像中选取多个不同景深且具有显著细节特征的目标物,然后针对各目标物所在子图像以及整幅图像分别采用预训练神经网络提取视觉特征,由多个单目标物视觉特征回归能见度估计值,同时在估计过程中结合整幅图像视觉特征回归各目标物估计值的权重向量,最后根据权重进行融合得到整幅图像的能见度检测值。
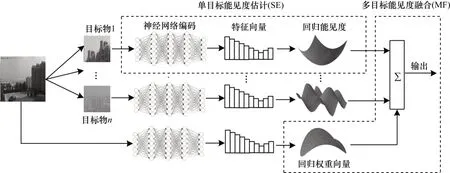
图1 本文方法的流程Fig.1 Procedure of the method in this paper
2.1 单目标能见度估计
为获得多个单目标能见度估计值,本文提取各目标物对应子图像视觉特征。考虑到基于图像的能见度检测方法由图像质量的衰减程度估计能见度值,与图像质量评估任务具有相似性。因此,本文迁移文献[23]中在AVA 数据集上预训练的神经图像评估(Neural Image Assessment,NIMA)网络提取能见度图像的视觉特征,以此来反映能见度变化对图像质量的影响。NIMA网络结构如表1 所示,其中dw 代表深度卷积,后面常跟逐点卷积;s2 表示该卷积核的移动步长为2。由表1可知,NIMA 神经网络由去除最后一层的MobileNet 网络[24]和一个具有10 个神经元的全连接神经网络(Fully Connected Neural Network,FCNN)组成,该网络模拟人类对图像的综合评价,预测图像质量评级分布,与真实评级更相关,且主体MobileNet网络采用深度可分离卷积(深度卷积+逐点卷积)代替标准卷积。通过以上卷积,使模型参数量和计算量均大幅减少,从而实现高效提取视觉特征的目的。

表1 NIMA 网络结构 Table 1 Structure of the NIMA network
为提取视觉特征,反映能见度图像的质量和内容,而不涉及NIMA 网络原本的分类任务,本文选取NIMA 网络全连接层前的输入值作为各目标物对应子图像的视觉特征(如表1 加粗数字所示),然后将各视觉特征并行输入到多个全连接网络分支,如图2所示,则对于第j个目标,其视觉特征fj所在分支包含两个隐藏层,每个隐藏层有64 个节点,输出层节点数为1,输出单个能见度估计值j。
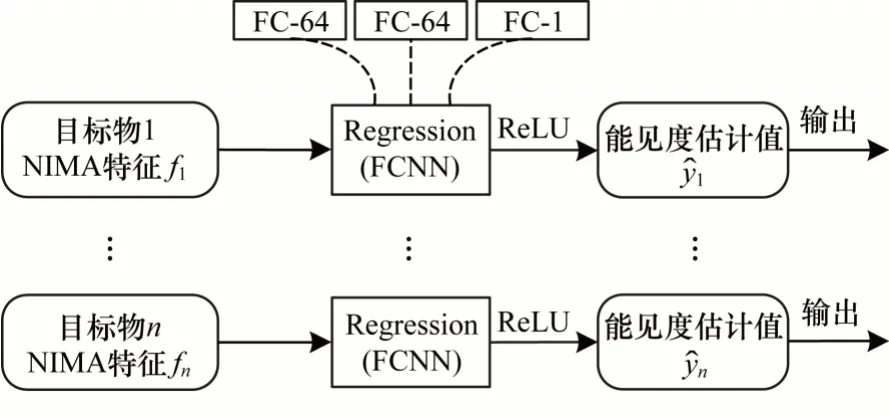
图2 单目标能见度估计网络的结构Fig.2 Structure of single-object visibility estimation network
2.2 多目标能见度融合
对场景能见度的检测通常需要综合场景中的多个目标物,是一个多目标能见度值融合的过程。为融合多个单目标的能见度估计值,本文设计了一个目标权重估计网络。考虑到人工观测过程中结合整幅图像信息综合判定场景能见度值的作用,本文同样提取整幅图像的NIMA 视觉特征,根据该视觉特征回归各目标物估计值权重。如图3 所示,将视觉特征输入到全连接网络,网络包含2 个隐藏层,每个隐藏层有64 个节点,输出层节点数为所选目标物个数,即输出融合权重向量W={1,2,…,n}。

图3 多目标能见度融合网络的结构Fig.3 Structure of multi-object visibility fusion network
在训练阶段,为了使网络能够根据当前能见度真值动态估计各目标在融合过程中所占权重,本文设定联合损失函数并行训练单目标能见度估计网络和权重融合网络,将各目标能见度估计值与对应权重加权进行求和,作为整个网络的联合输出,其损失函数设定为式(1)所示:
其中:m为训练集样本数量为第i个样本图像的能见度估计值;yi表示第i个样本图像的能见度真值;n为样本图像中所选择目标物数量;()i是第i个样本图像中第j个目标的能见度估计值;(j)i为第i个样本图像中第j个目标估计值的融合权重。

3 实验结果与分析
3.1 实验数据集与设置
为验证本文方法的有效性,本文采用固定的主动摄像机按照预定义的云台旋转策略获取图像数据集,选取3 个具有代表性的场景,每个场景包含多个不同距离的显著对象,示例如图4 所示。由于低能见度天气主要发生在秋冬季,图像采集时间为2019年2 月6 日—2019年3月13日、2020年12月1日—2021年3月13日,从上午6 点到下午18点,每小时采集一次,时长大约5 min,包含所有场景的视频数据。在每个场景下随机抽取图像,并将图像分辨率缩放至1 000×1 000 像素。剔除掉受飞虫、雨滴遮挡等干扰的图像后,选取22 952帧图像作为样本数据集,其中场景1 有7 376 帧图像,场景2 有7 609 帧图像,场景3 有7 967 帧图像。在能见度真值方面,根据人工观测结果对当地透射仪的测量值进行修正,最后将修正值作为能见度真值。

图4 不同场景在不同能见度条件下的图像示例Fig.4 Image examples of different scenes under different visibility conditions
为训练能见度映射模型,从3 个场景中分别随机选择70%样本图像作为训练集,10%样本图像作为验证集,20%样本图像作为测试集,并将能见度真值划分为4 个区间,各能见度区间训练集、验证集和测试集样本数量分布如表2 所示。

表2 不同能见度区间的样本数量分布 Table 2 Distribution of sample number at different visibility ranges
在方法实现方面,本文在CPU 为Intel i7-3700X 3.6 Hz、内存为8 GB 的PC 机上基于python 开展实验。针对所选择的3 个场景,在每个场景下划分如图5 所示的3 个不同景深的目标物,加上整幅图像,则共需要训练4 个全连接网络分支的279 430 个权重参数。在训练过程中,各全连接层参数采用标准差为0.01 的截断正态分布生成的随机数来初始化。为了防止过拟合,对参数应用scale 为0.003 的L2 正则化约束,将batch_size 设置为32,学习率设置为0.001,epoch 设置为120,损失函数定义为平均绝对误差,并采用Adam 算法进行优化。

图5 不同场景下不同景深目标物划分示例Fig.5 Examples of target division with different depth of field in different scenes
3.2 视觉特征有效性验证
首先,为验证所选取的NIMA 视觉特征对能见度变化的敏感性,本文对场景1 的采样样本做了视觉特征有效性验证,在0.01 km、2 km、8 km 和15 km 能见度条件下分别随机抽取120 帧样本图像,并选择感兴趣区域作为特征提取对象,如图6 所示。

图6 场景1 样本图像的感兴趣区域示例 Fig.6 Example of region of interest of sample image in scene 1
由于15 km 能见度条件下的图像质量衰减程度最弱,因此将其感兴趣区域作为基准图像集合,分别计算其他3 个能见度条件下样本图像与基准图像特征的欧氏距离,结果如图7(a)所示。可以看到,能见度越高,图像质量衰减程度越弱,其与基准图像的特征相似度越高,欧氏距离越小。从图7(a)可知,8 km、2 km、0.01 km 能见度条件下的样本图像与基准图像的特征距离呈现逐渐增大的趋势,且垂直分层较为明显,这表明NIMA 特征能较好地通过其值变化反映图像质量的不同退化程度。为了验证特征的泛化能力,本文还计算了任意两两能见度条件下样本图像特征距离的平均值,结果如图7(b)所示。从图7(b)中可以看出,随着相比较的两个能见度值相差越大,其对应样本特征距离平均值也越大,这表明NIMA 特征对能见度变化敏感。
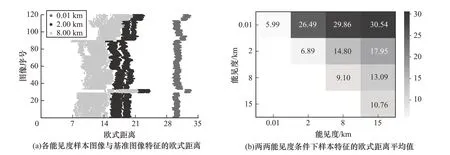
图7 特征有效性验证的实验结果Fig.7 Experimental results of verification of feature
3.3 能见度检测方法验证
本节从样例分析和量化分析两个方面验证本文方法的有效性。首先针对多个场景单个样例图给出能见度检测结果,然后统计测试样本集的预测平均绝对误差、正确率等,最后考察方法目标物选择和融合策略的有效性。
3.3.1 本文方法能见度检测分析
针对图4 给出的3 个场景样例图,通过本文方法回归得到每帧样例图中各目标物能见度估计值及其权重值,有效融合得到场景能见度检测值,结果如表3所示。

表3 样例图能见度检测结果 Table 3 Visibility detection results of sample image
从表3 可以看出,在3 个场景的9 帧图像样本中,本文方法融合得到的能见度检测值与标注值基本一致。为进一步量化分析本文方法的预测性能,在场景1 下统计本文方法在不同能见度区间预测值与标注值的均值和标准差,并计算预测正确率。其中当能见度在[0,1 km)区间时,若预测值在标注值的20%误差范围内,则视为正确预测的值;当能见度在[1 km,3 km)区间时,所允许的误差范围是15%;当能见度在[3 km,+∞)区间时,所允许的误差范围是10%。统计结果如表4 所示。从表4 可以看出,在任意能见度区间内,本文方法预测值与标注值的平均绝对误差均控制在标注均值的10%以内,表明预测值的集中趋势和离散程度与标注值基本一致。在正确率方面,除了[3 km,10 km)区间,其他区间的正确率均超过了90%,表明本文方法在各能见度区间预测的可信度均较高,而在[3 km,10 km)区间预测正确率偏低的主要原因是在高能见度条件下,影响图像质量的外部干扰因素较多。

表4 场景1 下的能见度预测值 Table 4 Visibility prediction value under scene 1
3.3.2 目标物选择对比实验
为进一步分析不同景深目标物选择对本文方法的影响,本文选取了另外两组目标物,如图8 所示,图8(a)的目标物相对摄像机距离较近,在0.5 km 之内;图8(b)的目标物相对摄像机距离较远,在3 km之外。对比本文方法(不同景深),统计各目标物在各能见度区间的预测平均绝对误差,结果如表5所示。

图8 两组目标物划分示例Fig.8 Division examples of two groups of targets

表5 3 组目标物在不同能见度区间的预测平均绝对误差 Table 5 Mean absolute errors of prediction of the three groups of targets at different visibility ranges
由表5 可知,选择3 个不同景深的目标物在任意能见度区间预测的平均绝对误差均最小;在[0,1 km)和[1 km,3 km)能见度区间内,选择近景深目标比选择远景深目标预测平均绝对误差要小;在[3 km,10 km)和[10 km,+∞)区间内,选择远景深目标预测平均绝对误差较小,这表明目标物的选择与在各能见度区间的预测误差是相关的,且选择具有代表性景深的目标物提取视觉特征有利于提高模型在各能见度区间的预测精度。
3.3.3 权重融合实验
为验证本文方法从整幅图像的视觉特征中动态回归各目标物估计值权重的有效性,本文做了3 组对照实验,具体如下:
1)多目标局部加权法。与本文方法不同,该方法通过联合多个目标物视觉特征,动态回归各目标物估计值权重。
2)多目标平均法。该方法将多目标估计值进行简单求和取平均值,并作为最终能见度检测值。
3)全局图像法。该方法为传统的基于数据驱动的能见度检测方法[25],通过直接建立整幅图像视觉特征与能见度的关系映射模型来预测场景能见度值。
以上3 种对比方法的流程如图9 所示。统计包含本文方法在内的4 种方法在各能见度区间的预测正确率,其结果如表6 所示。
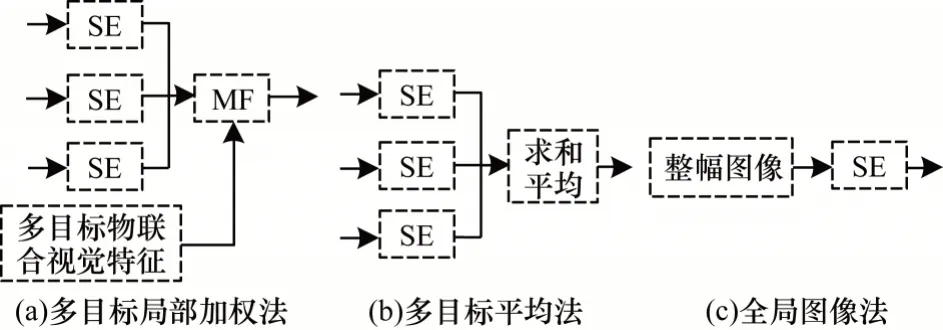
图9 3 种对比方法的流程Fig.9 Procedures of three comparison methods
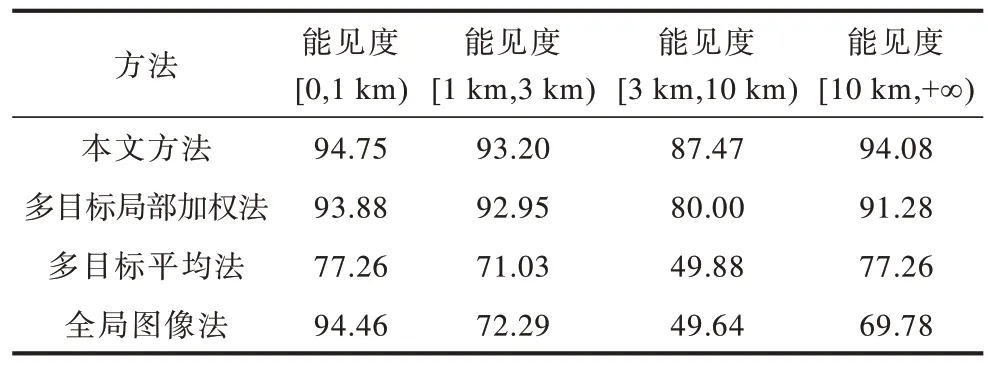
表6 4 种方法的检测正确率 Table 6 Detection accuracies of four methods %
由表6 可知,多目标平均法和全局图像法在[1 km,3 km)、[3 km,10 km)以及[10 km,+∞)能见度区间的预测正确率均小于80%,在[3 km,10 km)区间,预测正确率甚至不足50%,而本文方法除在[3 km,10 km)区间外,预测正确率均大于90%,能较好地适用于低能见度检测。
4 结束语
针对传统基于数据驱动的能见度检测方法未考虑场景中不同景深目标物对应子图像的质量衰减程度不同的问题,提出一种基于多目标的能见度检测方法。通过在图像中选择多个不同景深的目标物,分别提取各目标物对应子图像的视觉特征,并用其训练能见度估计模型。提取整幅图像视觉特征训练融合权重,按照权重融合各目标能见度估计值,得到全局能见度检测值。实验结果表明,与多目标局部加权法、多目标平均法、全局图像法相比,该方法能有效提高能见度检测精度。下一步将模拟人眼瞳孔变化,利用调整焦距的方式获取各目标物高分辨率图像,以更好地通过量化视觉特征因图像变化而产生的差异估计能见度值。
猜你喜欢
成都信息工程大学学报(2021年4期)2021-11-22 07:44:48
中学生数理化·高一版(2019年12期)2019-12-31 06:52:24
Advances in Meteorological Science and Technology(2019年6期)2019-12-30 11:45:42
当代石油石化(2018年1期)2018-08-10 06:50:54
中国钢铁业(2018年6期)2018-07-26 06:55:00
中国交通信息化(2016年6期)2016-06-06 07:11:30
海洋气象学报(2016年3期)2016-02-28 14:27:42
气象研究与应用(2016年4期)2016-02-27 12:23:16
中国钢铁业(2014年7期)2014-01-26 05:18:12
数码摄影(2009年8期)2009-10-14 06:37:54
