
基于改进YOLOv4 的小目标行人检测算法
2023-02-20 09:39:34王程刘元盛刘圣杰
计算机工程 2023年2期
王程,刘元盛,刘圣杰
(1.北京联合大学 北京市信息服务工程重点实验室,北京 100101;2.北京联合大学 机器人学院,北京 100101)
0 概述
行人检测的目的是确定视频或图像中行人的位置,其对无人驾驶感知具有重要意义[1]。近年来,行人检测被广泛应用于无人车的行人跟踪、碰撞预防、行人路径规划等任务。由于硬件设备的不断优化以及各种先进算法的涌现,利用深度学习进行行人检测时准确率和速度提升明显,且具有很强的自适应性和鲁棒性[2]。当前,主要有Two-stage 行人检测算法[3]和One-stage 行人检测算法[4]这两种主流的深度学习行人检测方法,两种算法各有优势,但是仍然面临光照干扰、目标遮挡、小目标行人检测精度低等诸多挑战。
Two-stage 行人检测算法首先生成一系列行人候选框作为样本,通过卷积网络进行样本分类,其典型代表有Faster-RCNN[5]、Mask-RCNN[6]等算法。2021年,SHAO等[7]在Faster-RCNN 算法的基础上进行改进,采用基于级联的多层特征融合策略,提升网络对语义信息的特征提取能力,从而提高对小目标行人的检测准确率。2021年,LAI等[8]提出MSRCR-IF 算法,通过调整RPN 和删除实例掩码分支提高了弱光下行人的检测精度。2021年,音松等[9]在Mask R-CNN 算法中增加CFPN模块,融合不同特征层的输入信息生成行人掩膜,其降低了遮挡对于行人检测精度的影响。Two-stage行人检测算法在候选区域的提取过程中计算量大、过程复杂、检测速度慢,虽然拥有较高的准确度,但是无法满足实时性需求。
One-stage 行人检测算法主要利用端到端的思想,采用整张图像来回归预测出目标物体的类别和位置,其典型代表有基于回归的SSD 系列[10]、YOLO系列[11]等。2021年,DONG等[12]提出SSD 算法,该算法采用跨层特征自适应融合的方式,在增加感受野的同时增强重要特征并削弱次要特征,从而优化了小目标行人检测效果。2021年,BOYUAN等[13]将SPP 网络、K-means聚类算法与YOLOv4 模型相结合,在模型颈部采用Mish 激活函数,有效缓解了遮挡对于目标检测的影响。2021年,CAO等[14]为降低光照对行人检测的影响,在YOLOv4 算法的基础上,设计一种新的多光谱通道特征融合(MCFF)模块,用于集成不同照明条件下的颜色和热流信息,提高了行人检测精度。2021年,黄凤琪等[15]提出dcn-YOLO 算法,其使用k-means++算法重构目标锚框,构建残差可变形模块,提高了小目标行人的检测精度。One-stage行人检测算法对整张图像进行特征提取,具有较高的准确率和检测速度。但是,该类算法应用于无人车在小目标行人检测领域仍然面临挑战。
小目标行人是指输入视频或图像数据中占比相对较小的行人,COCO 数据集将小于32×32 像素的目标定义为小目标。考虑到行人具有特殊比例,本文将高度小于32 像素的行人目标视为小目标行人。小目标行人具有分辨率低、携带信息少等问题,导致其特征表达能力较差,在特征提取过程中,仅能提取到少量特征,不利于后续检测。基于YOLOv4 的算法特点,本文主要从通道和空间信息增强、多尺度学习两方面进行改进,提出一种小目标行人检测算法,从而提取更多针对小目标行人的特征信息。此外,无人车普遍采用低计算力的嵌入式设备,给实时检测带来了很大挑战,针对该问题,本文采用深度可分离卷积提高算法实时性。在行人检测过程中,随着行人行走距离变远,行人目标尺度逐渐变小,造成小目标行人特征过少,检测精度低,本文引入scSE(concurrent spatial and channel Squeeze &Excitation)注意力模块,以增强对重要通道和空间特征的学习,同时对特征金字塔网络(Feature Pyramid Network,FPN)进行改进。最终在VOC07+12+COCO[16-17]数据集上测试算法的有效性,并在北京联合大学北四环校区实际园区环境中使用无人车进行实时验证。
1 相关工作
1.1 YOLOv4 算法介绍
YOLOv1 是YOLO 系列的初始版本,由REDMON等[18]于2016 年提出,但是,该网络存在以下问题:只可输入与训练图像相同分辨率的图像;只检测单格中多物体中的一个物体;检测定位准确性较差。2017年,REDMON等[19]对YOLOv1 进行改进,设计了YOLOv2 网络,其提高了算法检测性能。此后,REDMON等[20]对YOLO 进一步优化,于2017年提 出YOLOv3,YOLOv3 在YOLOv2 的基础上引入FPN,使用Darknet-53 网络进行特征提取,使其检测性能更加完善。2020年,BOCHKOVSKIY 等[11]设计了YOLOv4 网络,其在YOLOv3 的基础上总结所有检测技巧,排列组合出最优算法,在检测速度和精度上达到了更好的平衡。
YOLOv4 网络主要包含输入(Input)、骨干网络(Backbone)、颈部(Neck)、头部(Head)四部分。骨干网络采用CSPDarknet53,CSPNet 结构可以降低网络计算量,消除网络反向优化时梯度信息冗余现象,增强卷积网络学习能力,在实现网络轻量化的同时能够保证准确率,此外,骨干网络采用Mish 激活函数,增强深层信息的传播;颈部网络采用空间金字塔池 化(Space Pyramid Pool,SPP)模块和FPN+PAN(Path Aggregation Network)模式的结构,有效提高了网络预测的准确性;头部采用与YOLOv3 类似的多尺度预测方式,分别检测小、中、大3 种目标。
1.2 注意力机制
近年来,注意力机制[21]广泛应用于自然语言处理、统计学习等领域,其形式与人类的视觉注意力相似。人类视觉通过快速浏览图像全局信息,获得其中的重要目标区域,将注意力集中于目标区域,以获取更多细节信息。2018年,HU等[22]提出SENet通道注意力机制,通过学习各通道的权重提高重要通道特征对网络的影响,同时抑制不重要的特征。ROY等[23]在同年提出基于SE 注意力模块的3 种变体,分别为cSE 注意力模块、sSE 注意力模块和scSE 注意力模块。cSE 注意力模块沿空间域挤压,并沿通道激励重新加权,依据不同的通道关系来动态调整特征图,从而提高网络提取通道特征的能力。sSE 注意力模块主要压缩特征图的通道特征,对重要的空间特征进行激励,提高网络提取空间特征的能力。scSE 注意力模块由cSE 和sSE 注意力模块组成而成,两种模块采用并行的方式,同时对输入特征图进行通道信息和空间信息的提取,融合所提取的特征并对融合后的特征进行激励,从而促使网络学习到更重要的特征信息。
本文对YOLOv4 骨干网络的特征传递过程进行实验分析,发现此过程中仍有许多对于小目标行人检测极其重要的中、浅层纹理和轮廓信息没有被提取到,对小目标行人的特征学习产生重要影响。本文引入scSE 注意力模块提高网络提取中、浅层纹理和轮廓信息的能力,从而提升小目标行人检测效果。
2 本文方法
针对无人车对小目标行人检测精度低、实时性差等问题,本文提出一种YOLOv4-DBF 算法,其网络结构如图1 所示。引入深度可分离卷积代替YOLOv4 中的传统卷积(见图1 中实线框①区域),降低模型的参数量和计算量,提升检测速度,提高算法实时性;为解决小目标行人学习特征过少的问题,在YOLOv4 骨干网络中的特征融合部分(即add 和concat 层后)引入scSE 注意力模块(见图1 中实线框②、③区域),增强对输入行人特征图中重要通道和空间特征的学习;对YOLOv4 颈部中的FPN 进行改进,将网络的融合方式add 改进为concat,并使用1×1卷积调节通道数,在少量增加计算量的同时增强对图像中目标多尺度特征的学习,从而提高小目标行人的检测精度。

图1 YOLOv4-DBF 网络结构Fig.1 YOLOv4-DBF network structure
2.1 深度可分离卷积
YOLOv4 中使用了大量传统卷积,将各通道的输入特征图与相应卷积核进行卷积相乘后累加,最后输出特征。传统卷积结构如图2 所示,在图2中:Ik和Oy分别为输入和输出图像的尺寸,Ik=Oy;Dk为卷积核的尺寸;C和N分别为输入和输出的通道数。传统卷积的计算方式如式(1)所示:


图2 传统卷积结构Fig.2 Traditional convolution structure
深度可分离卷积是2017 年由HOWARD等[24]提出,使用深度可分离卷积代替传统卷积,可以降低模型的参数量和计算量,提高算法实时性。深度可分离卷积将传统卷积中的部分卷积分离成一个3×3 的深度卷积和一个1×1 的逐点卷积,结构如图3所示。

图3 深度可分离卷积结构Fig.3 Deeply separable convolution structure
在图3 中:Ik和Oy分别是输入和输出数据的尺寸,Ik=Oy;Dk是卷积核的尺寸;C和N分别为输入和输出的通道数。深度可分离卷积的计算公式如式(2)所示:

深度可分离卷积计算量与传统卷积计算量的比值为:

由式(3)可知,使用深度可分离卷积可将模型参数量和计算量降至传统卷积的1/左右,模型速度将显著提升,更有利于部署在嵌入式设备中。
2.2 scSE 注意力模块
scSE 注意力模块通过提取输入特征图的通道和空间信息,进行相加处理以对其增强激励,提高网络学习重要特征的能力,该模块由cSE 和sSE 注意力模块并行组合而成。
cSE 注意力模块通过全局平均池化排除空间依赖性,学习特定于通道的描述符,用于重新校准功能图,具体方式为:通过全局平均池化压缩空间,产生一个i向量(维度是1×1×C,C为通道数,i∈C),通过一个权重为W1(维度是C×C/2)的全连接层和ReLU激活函数δ(·)以及一个权重为W2(维度是C/2×C)的全连接层对通道依赖项进行编码,计算方式如式(4)所示:

为了获取不同通道的激活值,使其介于[0,1]得到新的特征图通道,通过Sigmoid 对输入特征图U1=[u1,u2,…,uc]进行归一化处理σ(·),其中,C为通道数,通道ui(i∈C)的维度为H×W(H和W分别是输入特征图的高和宽),计算方式如式(5)所示:
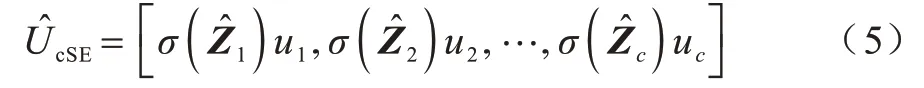
通过计算各通道信息的重要程度,激励并重新校准通道值,以提高网络学习重要通道特征的能力。
sSE 注意力模块通过压缩特征图的通道特征,激励重要空间特征,提高网络对空间特征的学习能力。输入特征图U2=[u1,1,u1,2,…,ui,j,…,uH,W],其中,每个ui,j的维度为1×1×C,ui,j表示位置在(i,j)处的通道特征信息。通过通道数为C、权重为Wsq的1×1 卷积对特征图的通道进行压缩,得到通道数为1、尺寸为H×W的特征图q(q=Wsq*U)。使用Sigmoid 对输入特征图U2进行归一化处理σ(·),得到特征图中每个空间位置(i,j)的空间信息重要程度,以提高对重要空间位置信息的学习,得到新的特征图通道sSE,计算方式如式(6)所示:

scSE 注意力模块计算方式如式(7)所示:

小目标行人在图像中所占像素很少,因此,骨干网络中提取到的有效特征有限。本文将scSE 注意力模块嵌入骨干网络中的特征融合部分(即add 和concat层后),增强小目标行人的通道信息和空间信息,促使网络学习更有意义的小目标行人特征信息,降低其特征学习过少所带来的影响,从而提高检测精度。改进后的网络结构如图1 中实线框②、③区域所示。
2.3 特征金字塔网络FPN
FPN 由LIN等[25]于2017 年提出,其中设计了更有效的高层特征和低层特征融合方式,增强了对图像中多尺度特征信息的学习。FPN 由bottom-up(自底向上)的线路横向连接top-down(自顶向下)的线路而构成,其网络结构如图4 所示。bottom-up 的每层特征图采用Ci标记,top-down 的每层特征图采用Pi标记。P2代表对应C2大小的特征图,P2由C2经过1×1 卷积降采样和P3经过2 倍上采样进行add 操作而得到,以此类推。FPN 通过构造一种独特的金字塔结构来避免计算量高的问题,同时能较好地处理尺度变化对目标检测所造成的影响。

图4 FPN 网络结构Fig.4 Network structure of FPN
借鉴YOLOv4 对PAN 网络改进的思想,本文对其颈部网络中的FPN 进行优化,如图5 所示。

图5 改进后的FPNFig.5 Improved FPN
将FPN 融合方式中的add 改进为concat,融合经多次卷积后提取的特征。考虑到concat 会增大网络的计算量,本文在此基础上进行1×1 的卷积,调节通道数。对FPN 进行改进后,在少量增加计算量的同时可以加深网络层数,使网络学习到更多的特征,从而提高对小目标行人的检测效果。
3 实验结果与分析
本文实验环境为Ubuntu16.04,ROS 操作系统,显卡Intel®Xeon®Silver 4216 CPU @2.10 GHz,188.6GiB RAM,GPU RTX3090 以及cuda v11.0.207、cudnn v8.2、pytorch v1.8.0 和python v3.6.13 的软件平台。实验中使用Adam 优化器,对模型设置的初始学习率为0.001,分别在140 个和170 个周期时将其衰减为0.000 1 和0.000 01,动量因子为0.9,训练过程在第180 个周期时结束。
3.1 数据集说明
本文实验统一在VOC07+12+COCO 数据集上进行训练并验证。VOC07和VOC12数据集共20个小类,含有超过3 万张图片,近8 万个实例目标。COCO 数据集是一个大型且丰富的目标检测、分割和字幕数据集,其中包含自然图片以及生活中常见的目标图片,背景比较复杂,目标数量较多,目标尺寸小,共含80 个类别,有超过33 万张图片,其中20 万张图片有标注,平均每张图片包含3.5 个类别和7.7 个实例目标,整个数据集中的个体数目超过150 万个。
3.2 评估标准
实验采用精确率P(Precision)、召回率R(Recall)、平均精度AP(Average Precision)(IoU 等于0.5)、FPS(画面每秒传输帧数)这4 项性能指标评判网络性能,P、R、AP 的计算方式如下:

其中:TP为模型正确检测到的目标数量;FP为系统错误检测到的目标数量;FN为系统错误检测以及漏检的数量;PR曲线下的面积就是对某一类别计算的平均精度AP。
3.3 训练及测试结果分析
在训练过程中,可以通过Loss 值的变化判断网络训练效果。图6 展示了本文算法在180 Epoch 训练过程中Loss 值的变化,可以看出,本文YOLOv4-DBF 算法在训练过程中Loss 值随着训练周期增多而逐渐呈现下降趋势,最终稳定在0.912 左右,说明本文算法在训练过程中已达到稳定和最优。
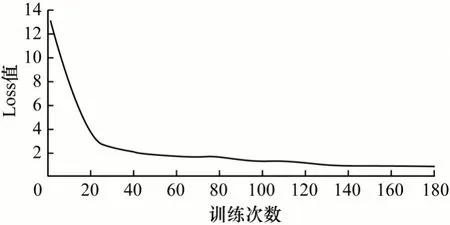
图6 本文算法在训练过程中Loss 值的变化Fig.6 The change of Loss in the training process of the algorithm in this paper
本文YOLOv4-DBF 算法引用深度可分离卷积提高算法实时性,同时在YOLOv4 的骨干网络特征融合部分引入scSE 注意力模块,增强对重要通道和空间特征的学习,并改进颈部网络中的FPN,增强对小目标行人多尺度特征信息的融合。
从表1 可以看出,本文算法的AP 相比YOLOv4算法提高4.16 个百分点,速度提升27%,说明本文算法在小目标检测精度和速度方面能取得更好的平衡,检测效果更好。相较Two-stage 网络Faster-RCNN,本文算法在验证集上的AP 提高了14.63 个百分点,速度提高了33FPS;与One-stage 网络的SSD、YOLOv3 相比,本文算法的AP 和FPS 都有较大提升。综上所述,本文算法能够大幅提升小目标行人的检测精度和实时性。

表1 不同算法在测试数据集上的实验结果 Table 1 Experimental results of different algorithms on test dataset
将本文算法和YOLOv4 算法在VOC07+12+COCO 验证集上的结果进行可视化,如图7 所示。通过可视化效果图可以看出,本文算法适用于不同情境下的小目标行人检测任务,并能取得显著效果。

图7 YOLOv4 和YOLOv4-DBF 的可视化效果Fig.7 Visualization effect of YOLOv4 and YOLOv4-DBF
在北京联合大学北四环校区使用“小旋风”四代无人车进行实时验证,如图8 所示,车载设备为仅拥有6 核CPU 架构、256 核Pascal 架构GPU核心、8 GB内存的Jetson TX2。

图8 “小旋风”四代无人车Fig.8 A fourth-generation whirlwind smart car
综合考虑各种因素,在降低一定的图像输入分辨率后,YOLOv4 算法在无人车实时检测时速度仅为8FPS,本文算法经加速部署后的实时速度可达23FPS,大幅提高了算法在嵌入式设备上的实时运行速度。2 种算法的检测效果如图9 所示,通过图9 可以看出,相较YOLOv4 算法,本文算法在应用于低计算力的嵌入式设备时小目标行人检测效果更好。

图9 YOLOv4-DBF 和YOLOv4 在校园实时检测的效果对比Fig.9 Comparison of real-time detection effects between YOLOv4-DBF and YOLOv4 on campus
3.4 消融实验结果分析
本节通过消融实验验证scSE 注意力模块嵌入到YOLOv4 网络结构不同位置中的性能提升效果,以及算法设计的合理性。除2.2 节提到的将scSE 注意力模块嵌入到骨干网络中,还可将其嵌入到网络的其他特征融合位置,即颈部SPP 网络前、中小目标(38×38、76×76)检测头前,从而进行多尺度特征融合,具体结构如图10、图11 所示。将scSE 注意力模块嵌入模型不同位置后在验证集上的结果如表2 所示。其中,D 代表深度可分离卷积;BscSE 代表在骨干网络引入scSE 注意力模块;F 代表改进FPN 融合方式;NscSE 代表在颈部网络引入scSE 注意力模块;HscSE 代表在检测头网络引入scSE 注意力模块。

图10 颈部网络嵌入scSE 注意力模块的网络结构Fig.10 Structure of neck network embedded with scSE attention module

图11 中小目标检测头网络嵌入scSE 注意力模块的网络结构Fig.11 Structure of small and medium targets detection head network embedded with scSE attention module

表2 scSE 注意力模块嵌入模型不同位置后的实验结果 Table 2 Experimental results of scSE attention module embedded in different positions of the model
从表2 可以看出,使用深度可分离卷积代替YOLOv4 中的传统卷积后,检测速度可达51FPS,AP仅降低了0.54 个百分点。在引入深度可分离卷积的基础上,将scSE 注意力模块嵌入网络模型中的不同位置,所产生的结果不同,分析可知,骨干网络提取的特征图语义信息并不丰富,会缺失许多中、浅层纹理和轮廓信息,这些信息对小目标行人检测极其重要,因此,将scSE 注意力模块嵌入骨干网络中能更好地增强对小目标行人的空间和通道特征的提取和学习能力。将scSE 注意力模块嵌入骨干网络中相比YOLOv4+D 算法,检测速度有所下降,但是AP 提升了3.60 个百分点,牺牲的速度不会影响模型的实时效果。在模型颈部SPP 网络前嵌入scSE 注意力模块,网络对多尺度特征进行融合,小目标行人检测精度相比YOLOv4+D 提升1.19 个百分点。在模型的中小目标检测头网络前嵌入scSE 注意力模块,小目标行人检测精度几乎没有变化,这是由于检测头网络已得到丰富的语义信息,即使再嵌入scSE 注意力模块,也不会产生明显的提升效果。综上,将scSE注意力模块嵌入骨干网络中可以得到最佳性能。
此外,本文还针对在引入深度可分离卷积基础上将sSE、cSE、scSE 三种注意力模块分别嵌入骨干网络中以及是否改进FPN 进行消融实验,结果如表3所示。其中,BsSE 代表在骨干网络中引入sSE 注意力模块;BcSE 代表在骨干网络中引入cSE 注意力模块。

表3 不同注意力模块嵌入骨干网络及是否改进FPN 的消融实验结果 Table 3 Ablation experiment results of different attention modules embedded in backbone network and whether FPN is improved
从表3 可以看出:将sSE、cSE、scSE 三种注意力模块分别嵌入骨干网络后,scSE 注意力模块相比其他两种模块在速度近乎相同的情况下得到了最优的性能,AP 达到92.85%;改进FPN后,在牺牲少量速度的情况下可将检测精度提升至93.95%。
4 结束语
本文针对YOLOv4 算法应用于嵌入式设备时实时性不高、对小目标行人检测效果差的问题,提出一种改进的小目标行人检测算法YOLOv4-DBF。采用深度可分离卷积替换原YOLOv4 算法中的传统卷积,同时引入scSE 注意力模块并对FPN 进行改进,以降低模型参数量和计算量,增强对小目标行人重要通道和空间特征以及多尺度特征的学习。在VOC07+12+COCO 数据集上的实验结果表明,该算法能有效提高小目标行人检测精度及实时性,将本文算法加速部署在无人车上进行校园场景的实时测试时,其实时性较好且性能稳定。行人检测应用于更加复杂的无人驾驶场景时,仅依靠视觉传感器将难以取得良好效果,如何对多传感器进行融合以实现实时准确的小目标行人检测,将是下一步的研究方向。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
意林(2021年5期)2021-04-18 12:21:17
当代水产(2019年11期)2019-12-23 09:02:54
扬子江(2019年1期)2019-03-08 02:52:34
知识经济·中国直销(2017年5期)2017-06-15 20:28:19
传媒评论(2017年3期)2017-06-13 09:18:10
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国学校体育(2014年11期)2014-05-10 09:57:04
上海理工大学学报(2012年2期)2012-03-20 13:54:30
