
基于场景对象注意与深度图融合的深度估计
2023-02-20 09:39:06温静杨洁
计算机工程 2023年2期
温静,杨洁
(山西大学 计算机与信息技术学院,太原 030006)
0 概述
深度估计被广泛应用于自动驾驶、无人机导航等各种智能任务。EIGEN等[1]提出利用深度学习进行深度估计的方法,该方法相较于传统方法的估计性能得到显著提升。LIU等[2]为简化训练过程并增强细节信息,提出一种新的深度估计算法,该算法将深度卷积神经网络与连续条件随机场相结合进行深度估计。LI等[3]在文献[2]的基础上,提出一种多尺度方法,结合超像素与像素来优化深度估计的预测性能。LAINA等[4]结合残差网络的优点,提出一种残差学习的全卷积网络架构,获得较优的估计结果。GARG等[5]提出一种类似于自动编码机的深度估计算法,利用立体图像对代替深度标签,从而实现无监督单目深度估计的目的。该方法虽然能够训练单目深度估计模型,但是依赖基于立体信息的训练数据。GODARD等[6]提出一种新的自监督单目深度估计方法,该方法不依赖基于立体信息的训练数据。信息损失是深度估计任务中的主要问题。GUIZILINI等[7]基于GODARD等[6]的工作,提出一种新的卷积网络结构,称为PackNet。针对深度估计方法的精度低、网络臃肿复杂的问题,王亚群等[8]设计了密集卷积网络。
针对深度估计任务中相邻深度边缘细节模糊以及对象缺失的问题,本文提出一种基于场景对象注意机制与加权深度图融合的深度估计算法。利用卷积网络计算特征图任意位置之间的相似度向量,以增大网络的感受野并增强特征图的上下文信息,有效解决对象缺失的问题。将不同网络层的深度图进行融合,在融合之前利用权重生成器为每一个深度图赋予权重,提高深度图的预测精度。
1 相关工作
自监督单目深度估计是深度估计算法研究的主流。GODARD等[6]提出的Monodepth2 模型具有较优的深度估计性能。为进一步提升算法的性能,GUIZILINI等[7]提出一种新的自监督单目深度估计模型,该模型由独特的卷积网络结构PackNet 组成,当传统编码器-解码器恢复原分辨率时,PackNet中的打包解包模块可以有效地解决信息量丢失问题。
近年来,注意力机制在计算机视觉领域具有重要作用。文献[9]提出将注意力机制引入计算机视觉中。文献[10]在图像分类模型中使用空间注意力,显著提高分类任务的准确率。HU等[11]提出一种通道注意力机制,该机制赋予各通道不同的权重,不同的权值代表不同的关注程度。WOO等[12]采用级联和并行的方式连接不同的注意力。YANG等[13]结合非局部均值与注意力机制的基本原理,提出一种可以捕获特征图中像素点间的长距离依赖关系模块,文献[14-15]详细介绍了该模块的的原理及应用。
HE等[16]提出一种全新的池化层,该池化层使用多个卷积窗口对特征图进行池化。ZHAO等[17]提出金字塔场景解析网络PSPNet,该网络采用步长和池化尺寸均不同的平均池化层进行池化。LIU等[18]提出ParseNet,通过全局池化提取图像的全局特征,并将全局特征与局部特征相融合。
WU等[19]提出一种多级上下文与多模态融合网络MCMFNet,用于融合多尺度多级上下文特征映射关系,并从深度信息中学习对象边缘。文献[20]提出低分辨率的深度图,在深度信息预测方面具有较优的性能。文献[21]提出的低分辨率深度图没有场景的空间信息和对象信息,在高分辨率深度图中存在丰富的场景信息和细节信息,但不含任何深度信息。文献[22]通过融合不同尺度的深度图得到包含深度信息和场景对象信息的深度图。本文基于以上原理,提出加权深度图融合模块。
2 本文算法
本文结合场景对象注意机制和加权深度图融合模块,提出一种自监督单目深度估计算法,通过场景对象注意机制有效地解决深度图中明显的对象缺失问题。加权深度图融合模块提高深度预测的准确度,同时,相邻深度边缘细节模糊的问题也得到有效解决。
2.1 网络模型整体结构
本文所提自监督单目深度估计网络模型的基线是PackNet,用于解决信息丢失问题。图1 所示为自监督单目深度估计网络结构。

图1 本文网络结构Fig.1 Structure of the proposed network
本文网络基于传统的编码器-解码器结构,在编码器-解码器中加入场景对象注意机制和加权深度图融合模块。输入图片首先经过一个5×5 的卷积层,通过编码器获取高维特征。深度估计网络结构将不同层的深度图输入到加权深度图融合模块中进行融合。编码器模块Enc_Block 的结构如图2 所示,该结构由三个Conv2D 3×3 的卷积层、场景对象注意模块和PackingBlock 模块[7]顺序连接组成。

图2 Enc_Block 网络结构Fig.2 Structure of Enc_Block network
解码器模块主要由Dec_Block 组成,Dec_Block的结构如图3 所示。从图3 可以看出:Dec_Block 由UnpackingBlock 模块、场景对象注意模块和Conv2D 3×3 组成。
模型中采用反向映射原理合成目标图像,根据目标图像的二维像素点坐标,利用相机内参矩阵和位姿网络得到的变换矩阵进行坐标变换,进而计算出与原图像对应的坐标,根据得到的坐标在原图像中进行采样,将采样值作为目标图像对应位置的像素值。整体过程如式(1)所示:

其中:t′为源图像;t为目标图像;It′→t为利用深度和相机位姿对源图像进行采样的图像为采样符号;Dt为深度信息;K为相机内参;Tt→t′为旋转矩阵;proj()为依据深度投影到源图像It′上的二维坐标。
在得到合成目标图像后,结合原目标图像计算整体光度损失,整体光度重投影误差[6]如式(2)所示:

其中:pe 为单张光度重投影误差。其表达式如式(3)所示:

因图片边缘信息的重要性,本文利用边缘感知平滑损失LS来改善边缘预测结果,如式(4)所示[20]:

其中:为平均归一化逆深度。
本文参考文献[7],将高于合成目标图相应未扭曲的光度损失像素进行移除操作,通过这种方式来掩盖静态像素。自动遮罩会移除外观在帧之间不发生变换的像素,使得本文实验具有场景和场景对象较小的光度损失。移除操作过程如式(5)所示:
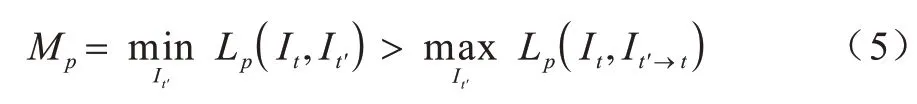
如果不对相机位姿进行约束,那么会导致估计深度的准确率降低。因此,本文使用瞬时速度对估计出相机位姿中的平移分量进行约束。速度监督损失如式(6)所示[7]:

其中:为位姿网络预测的位姿平移分量;v为瞬时速度;ΔTt→t′为目标帧与源帧之间的时间差。
2.2 场景对象注意机制
2D 和3D 卷积只能处理局部像素领域的图像信息,无法探索全局环境上下文信息。本文所提的场景对象注意机制可以学习到上下文中具有相似语义的特征组及其之间的关系,因此,能够更加充分地利用全局上下文信息。当使用标准卷积时,由于这些信息可能位于卷积无法到达的非连续位置,因此模型未得到用于预测像素深度的正确上下文信息。
此外,光照、姿态、纹理、形变、前后遮挡等信息的处理都与上下文信息密切相关。场景对象注意机制能增强属于同一对象的像素相关性,以确保同一对象深度具有一致性、连续性,从而提高深度估计的准确性,减少对象缺失的视觉错误。
场景对象注意模块的结构如图4 所示。利用1×1 卷积层调整特征图通道数,再将特征图的维度进行变换,使得特征图矩阵符合矩阵点乘的维度要求,通过激活函数处理特征图矩阵点乘后的结果,进而得到全局任意两个元素之间的依赖关系。

图4 场景对象注意模块结构Fig.4 Structure of scene object attention module
2.3 加权深度图融合模块
在深度学习中,高层网络的语义信息表达能力较强,但是几何信息的表达能力较弱,并缺乏空间几何特征细节信息。由于低层网络的特征图具有与高层网络特征图互补的特点,因此本文将不同尺度的特征图相融合,得到具有较优的语义表达能力和多种空间特征细节信息的融合特征。该融合特征有助于深度网络学习更准确的深度,缓解相邻深度的细节模糊问题。
本文基于多尺度特征图融合的优点,设计加权深度图融合的网络结构。从深度估计网络模型中可以得到不同分辨率的深度图,每一个不同分辨率的深度图都有不同的细节特征,通过融合不同分辨率的深度图,不仅有助于网络模型估计出更精确的深度信息,还可以得到具有丰富轮廓信息的深度图。
在融合深度图之前,本文所提的网络结构给每个深度图赋予权值,即给深度图中每一个像素级单位一个权值。加权深度图融合网络模型通过对不同分辨率的深度图调整分辨率大小,使用Resize 模块将三种不同大小分辨率的深度图调整到相同分辨率,利用深度图计算权值。为保证赋予深度图的每个权值都是非负数,且满足三个权值和为1,本文在上述卷积层后增加一个Softmax 函数。在得到权值后与深度图进行逐元素相乘,得到加权后的深度图,最后把三幅加权深度图进行逐元素相加,得到最终的深度图。加权深度图融合模块如图5 所示,图中D_A 表示深度图,D_A1 表示调整分辨率后的深度图,DepthMap 表示最终得到的加权深度图。

图5 加权深度图融合模块结构Fig.5 Structure of weighted depth map fusion module
为增强特征之间的空间信息和通道信息的依赖性,本文在加权深度图融合网络模型中加入CBAM模块[11]。
3 实验结果与分析
3.1 实验数据集与评估指标
本文实验采用的数据集是KITTI[23]和DDAD[7]。KITTI 数据集是自动驾驶场景下最大的计算机视觉算法评测数据集。本文采用EIGEN 等使用的训练协议,并使用文献[24]所提的预处理去除静态帧,使用39 810 张图像用于训练,4 424 张用于验证。
DDAD 数据集包含单目视频和准确的地面深度,这些深度是由安装在自动驾驶汽车车队上的高密度LiDAR生成的。本文实验使用两组指标来评估模型[25]:第一组指标分别是绝对相对误差(AbsRel)、平均相对误差(SqRel)、均方根误差(RMSE)、对数均方根误差(RMSElog);第二组指标是精确度σ1、σ2、σ3。第一组指标的数值越小表明模型性能越好,则第二组指标相反,其数值越大表明网络模型的性能越优。评估指标如下:

其中:N表示像素总数;Di表示第i个像素的深度估计值;表示第i个像素真实深度值。
3.2 网络参数设置
本文网络模型的输入图片大小为640×192 像素,深度估计网络模型首先将一个卷积核大小设置为5×5,调整输入图片的维度,然后将调整维度后的图片输入到编码器中。编码器中的残差块是由3 个2D 卷积组成的序列,2D 卷积层的卷积核大小均为3。Packing 模块中卷积层的卷积核大小为3×3,场景对象注意模块中卷积层的卷积核大小为1×1,3×3,其中1×1 卷积的作用是修改特征图的通道大小并增加非线性。解码器模块由Unpacking 模块、卷积层和场景对象注意机制网络模块组成。Unpacking 模块和卷积层的卷积核大小均为3×3。在加权深度图融合模块中有两种不同大小的卷积,分别是1×1和3×3。以上网络模型的超参数都是通过实验手动进行调参,得到的最优参数。
本文在开源的深度学习框架PyTorch 上实现并训练所提的网络模型,并在两个NVIDIA1080 TI 上训练模型。在实验过程中使用Adam 优化器,指数衰减率β1=0.9,β2=0.999,初始深度和姿态网络学习率分别为2×10-4和5×10-4。每40个迭代次数学习率会衰减1/2,SSIM 中权重值α=0.85。批处理大小设置为4,训练的最大迭代次数设置为100。本文每经过一个迭代次数测试一次模型的预测性能,依据当前测试结果和之前的测试结果对网络模型的参数进行调整。
3.3 结果分析
本文的基线网络PackNet 利用深度估计网络来估计目标图像逐像素点的深度信息,采用姿态网络估计相机旋转和平移的分量,通过变换关系建立自监督关系,从而实现训练与收敛。相比之前的自监督单目深度估计算法,基线算法具有较优的性能。
在数据集DDAD 上不同算法的评价指标对比如表1 所示,加粗表示最优数据。从表1 可以看出:本文算法的评估指标优于现有算法的评估指标。

表1 在数据集DDAD 上不同算法的评价指标对比 Table 1 Evaluation indicators comparison among different algorithms on dataset DDAD
在数据集KITTI 上不同算法的评价指标对比如表2 所示,M 表示使用单目图像,M+v 表示附加速度的弱监督模式,K 表示在数据集KITTI 上进行训练,CS+K 表示使用CityScapes 和KITTI 数据集进行训练。从表2 可以看出:本文算法的平均相对误差明显优于对比算法。

表2 在数据集KITTI 上不同算法的评价指标对比 Table 2 Evaluation indicators comparison among different algorithms on dataset KITTI
图6 所示为在KITTI 数据集上不同算法的可视化结果对比。从图6 可以看出:本文算法能够捕捉更加清晰的结构,改善相邻深度边缘细节模糊的问题,有效地解决场景对象缺失的问题。本文所提的自监督单目深度估计算法预测的深度图具有更加完整的场景对象轮廓和精确的深度信息。

图6 不同算法的深度预测结果对比Fig.6 Depth prediction results comparison among different algorithm
3.4 网络模型中每个模块的作用
本文所提的场景对象注意机制通过计算非连续位置的相似特征向量,利用相似特征向量增强场景中对象之间的相关性,以有效解决场景对象缺失的问题。场景对象注意机制对预测结果的影响如图7所示。

图7 场景对象注意机制对预测结果的影响Fig.7 Influence of scene object attention mechanism on prediction results
以第一行的三幅图为例,在文献[7]算法预测结果中第三幅图像缺失了路边的路标,而本文算法预测的深度图能够清晰展现出路标。此外,相比文献[7]算法,本文算法在第三行的第一幅图中预测的广告牌形状更符合原图广告牌的形状。
加入和未加入速度的弱监督模式下的消融实验结果分别如表3 和表4 所示。从表3 和表4 可以看出:场景对象注意机制和加权深度图融合模块能有效改进现有深度估计网络的预测性能。加权深度图融合模块的加入对模型的预测性能有所改善,但场景对象注意机制的加入对模型性能的改进效果更加明显。

表3 加入速度的弱监督模式下消融实验结果 Table 3 Results of ablation experiment under weak supervision mode with speed

表4 弱监督模式下消融实验结果 Table 4 Results of ablation experiment under weak supervision mode
3.5 网络模型保留细节信息的能力对比
为对比不同网络模型的细节信息保留能力,本文设计3 组图像重建实验:第1 组是由最大池化和双线性上采样构成的网络模型;第2 组是由编码块和解码块组成的网络模型;第3 组是由编码块和解码块结合场景对象注意网络结构组成的模型。3 组实验的损失函数均采用L1 损失函数。第1~3 组网络的图像重建结果如图8~图10 所示。

图8 最大池化与双线性上采样构成网络模型的重建结果Fig.8 Reconstruction results of the network model composed of maximized pooling and bilinear upsampling

图9 编码块与解码块构成网络模型的重建结果Fig.9 Reconstruction results of network model composed of encoding block and decoding block

图10 编码块与解码块结合场景对象注意结构的重建结果Fig.10 Reconstruction results of encoding block and decoding block combining scene object attention structure
第1 组实验最终的损失值为0.040 8。第2 组网络模型的最终图像重建损失值为0.006 9,第3 组实验的图像重建损失值为0.006 1。
3.6 模型收敛性与执行效率对比
在模型训练过程中,本文所提模型的损失函数值在训练迭代次数中会逐渐减小至稳定值,未出现损失函数不下降或剧烈抖动的现象。因此,本文所提模型具有较优的收敛性。
为对比模型的执行效率,本文对不同网络的测试时间和预测性能进行对比,预测性能指标选取均方根误差(RMSE)。在KITTI 数据集上不同网络的测试时间与均方根误差的对比如图11 所示。从图11 可以看出:本文网络的计算时间远低于文献[6,28]网络,虽然本文网络单张图像的测试时间略高于文献[7]网络,但是本文网络的均方根误差最小,且远小于其他网络的均方根误差。因此,基于场景对象注意机制和加权深度图融合的深度估计模型具有更高的执行效率。
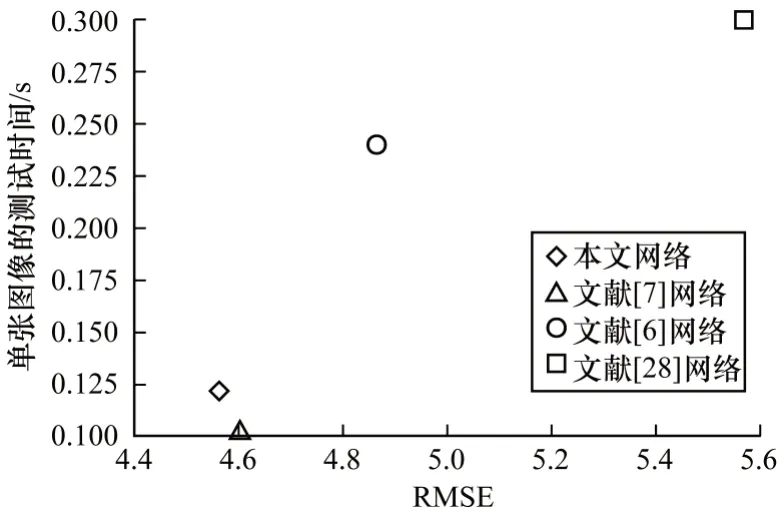
图11 不同网络的测试时间与均方根误差对比Fig.11 Test time and root mean square error comparison among different networks
4 结束语
本文提出一种基于场景对象注意机制与深度图融合的深度估计算法。利用场景对象注意机制来增强图像、深度和场景语义之间的相关性,增强上下文信息与属于同一对象的像素相关性。通过相似深度区域的上下文信息来指导自监督单目深度估计网络中的几何表示学习,解决场景对象缺失的问题。此外,本文提出加权深度图融合模块,有助于网络预测包含丰富目标信息的深度图。在KITTI 和DDAD 数据集上的实验结果表明,相比Monodepth2 和PackNet-SfM 算法,本文算法的绝对相对误差和平均相对误差均较低。后续将通过增强语义信息来提高预测精度,在保证预测精度的前提下,减少网络模型的参数和缩短模型的训练时间。
猜你喜欢
睿士(2023年2期)2023-03-02 02:01:09
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
计算机应用(2019年3期)2019-07-31 12:14:01
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
意林(2018年3期)2018-03-02 15:17:24
厦门理工学院学报(2016年1期)2016-12-01 04:50:48
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
