
铀矿勘查数据湖分布式存储和计算系统构建*
2023-02-19 12:25孙远强蔡煜琦李晓翠孙雨鑫金鑫裕
数字技术与应用 2023年1期
孙远强 蔡煜琦 李晓翠 孙雨鑫 金鑫裕
1.核工业北京地质研究院;2.中国地质大学(北京)
本文在梳理和分析当前主流数据湖大数据平台技术体系构成的基础上,根据铀矿勘查数据来源、数据类型、数据结构等特征,选择PostgreSQL(关系型数据库)+MongoDB(非结构化数据库)+Ceph(存储组件)+Kafka(消息队列)+Spark(计算组件)等搭建铀矿勘查数据湖大数据技术平台。该平台即适用于地震、电磁、重力等体量巨大,又适用于地质图件、钻孔数据、化验分析测试等多源异构数据的存储;Spark 计算引擎即可以处理离线数据又可以处理实时流数据的分析,满足钻孔数据分析,物化探数据反演,遥感蚀变提取,成矿预测分析及钻探进尺统计等勘查业务的应用。
我国铀矿资源经过近几十年的勘查和研究工作,积累了大量数据资料,这些资料多源异构、格式多样。从来源来看,不同勘查手段获得的数据源不同,如地质观察、测量、钻探、槽探、物化探、遥感等数据;从存储形式看,有纸质格式(成果报告、图纸、附表)和电子表格,后者又可分为Word、Excel、TXT、MapGIS、AutoCAD 等;从数据的空间分布看,来自不同的铀成矿带、铀矿床、铀矿化点、成矿远景区等;从勘查主体看,来自不同的研究院、勘查大队、研究所和档案馆等;部分铀矿数据来自不同行业,如煤炭、石油、有色等行业。如何开展这些数据的转换集成,完成多源异构数据的融合,实现应用预测是当前铀矿领域最重要的需求之一。鉴于此,急需开展勘查领域数据湖的建设。
数据湖(DataLake)的概念是Pentaho 公司(开源商业智能软件公司)的创始人兼首席技术官詹姆斯·狄克逊(James Dixon)在2010 年首次提出,2011 年丹·伍兹(Dan Woods)在福布斯发表“大数据需要更大的新架 构 ”(Big Data Requires a Big New Architecture)的文章,数据湖技术开始在各类企业公司广泛应用。它可以存储结构化数据、半结构化数据、非结构化数据和二进制数据等多种数据类型,并且能够实现原始数据与转换后的数据统一存储,如用于数据可视化、数据分析和机器学习的数据。随着信息技术、大数据、云计算、软件算法的高速发展,为适应日益复杂的数据结构和业务应用环境,加快数据应用的部署速度,数据湖技术的应用逐渐成为各类企业大数据运营管理的重要手段和趋势。杜金虎(2020)在中国石油上游业务信息化建设总体蓝图中提出主数据湖和区域数据湖应用,通过连环湖架构,建立分级的数据存储与服务架构,实现数据逻辑统一、分布存储、互联互通、就近访问的开放数据生态系统[1]。马驰(2022)设计实现了一种基于Lambda 的飞机运行支持数据湖系统,解决了传统数据库、数据仓库无法满足航空数据指数级增长、豪秒级摄取、多维度应用的问题,为主制造商开展数据集中式数据管理,实现数字化转型提供支撑[2]。张芸(2021)阐述了石油勘探行业数据湖建设中的数据治理问题,解决了不同数据源在数据湖中的集成问题、非结构化和结构化数据管理问题、数据系统切换问题和数据同步原ID 记录机制[3]。刘志勇(2021)在“新基建”基础上对中国电信统一数据湖做了有益探索和实践,为31 省市大数据平台/数据仓库/ODS 建立了包括IaaS、PaaS、DaaS 能力的扎实“底座”[4]。数据湖平台在商业贸易、交通运输、信息通信、油气勘查与开发等领域实施了应用[5-7],在铀矿地质行业仅有少量科研项目开展示范性研究和探索性应用[8]。
针对铀矿勘查领域的地物化遥等不同勘查手段产生的数据结构特征,为解决该类多源异构数据的存储需求,本文提出铀矿勘查数据湖环境搭建所需要的基础构件和技术平台:(1)存储管理组件;(2)数据计算组件;(3)作为数据来源的数据库组件。经过对比分析和适用性研究,精心选择PostgreSQL(关系型数据)+MongoDB(非结构化数据库)+Ceph(存储组件)+Kafka(消息队列)+Spark(计算组件)等不同组件集成适用于铀矿勘查数据湖的大数据平台。
1 数据湖架构
以处理大型数据集,包括结构化、半结构化或非结构化数据,为主的一组软件组件构成了分布式大数据平台。这类平台随时间推移演进了以Hadoop 为代表的第一代离线数据平台、Lambda 架构的第二代平台、Kappa架构的第三代平台和最新一代的数据湖大数据技术平台。目前最主流的三大开源数据湖方案分别为:Databricks公司的Delta 数据湖架构、Uber 公司的Hudi 数据湖架构和Netflix 公司的Iceberg 数据湖架构。基于铀矿勘查的数据特征和勘查业务发展的需求,搭建以PostgreSQL+MongoDB+Ceph+Kafka+Spark 为组件的铀矿勘查数据湖大数据技术平台。
1.1 数据湖概念模型
铀矿勘查数据湖从硬件、软件和网络环境的需求分析,它需要支撑的软件平台包括存储组件、计算组件、数据治理组件以及作为数据来源的数据库组件等。在此基础上可以开展铀矿勘查业务应用,诸如钻孔数据分析应用、地球化学数据集成应用、重磁电震数据提取应用、成果可视化表达应用等。确保该类业务应用顺利开展的两条主线是质量控制和安全审计。实现数据实体存储和流转的服务器和网络通信设备。基于对数据湖平台构建逻辑的梳理,本文提出铀矿勘查数据湖概念模型(如图1所示),为搭建铀矿勘查数据湖大数据技术平台提供概念和逻辑支撑。
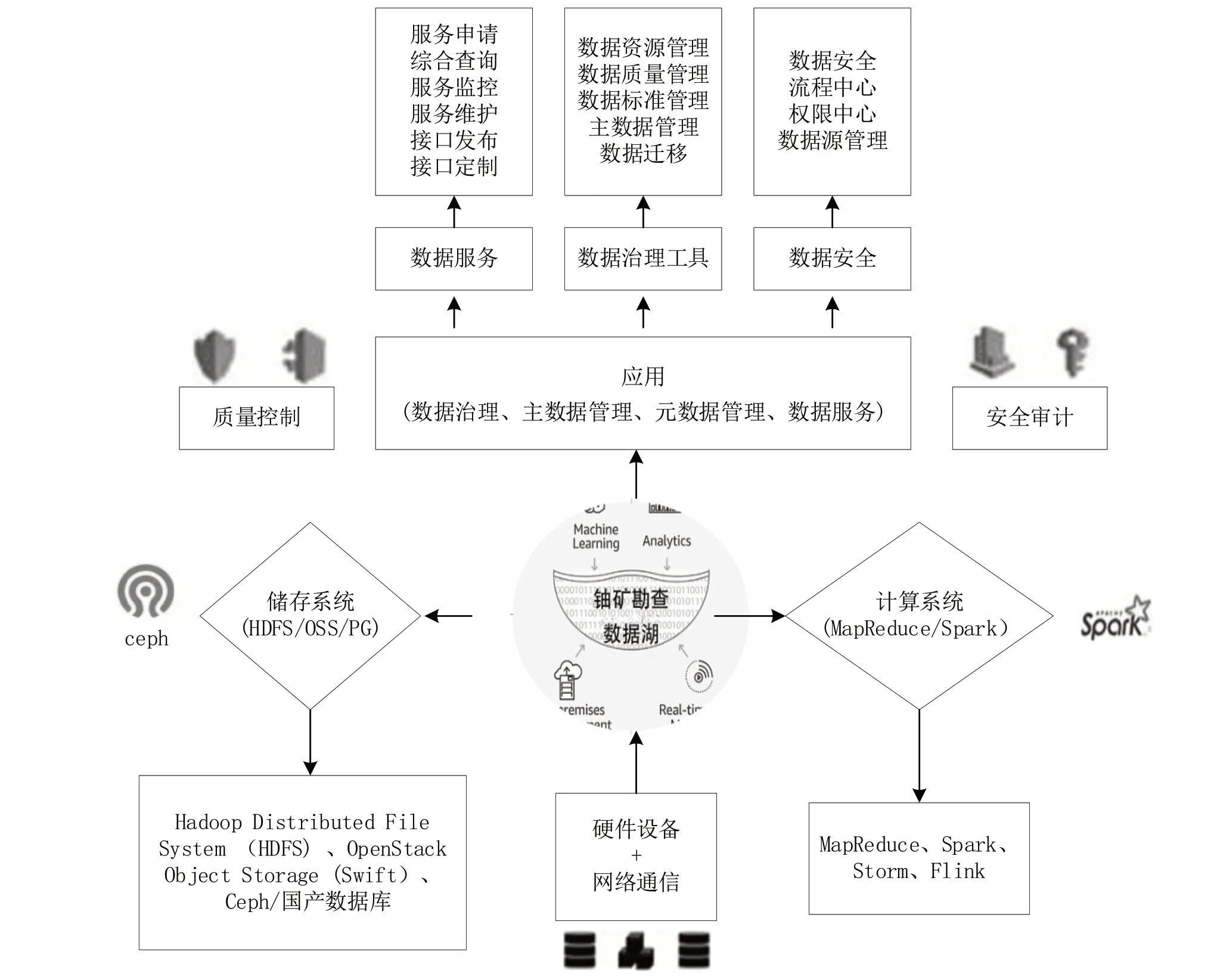
图1 铀矿勘查数据湖概念模型图Fig.1 Conceptual model of uranium exploration data Lake
1.2 数据湖技术架构
数据湖大数据平台的技术实现包括数据交互、质量检查、数据存储、数据分析与发现、元数据管理等环节(如图2 所示)。

图2 铀矿勘查数据湖技术架构Fig.2 Technical architecture of uranium exploration data lake
1.2.1 数据交互(Data Ingesting)
凡数据入湖对象,均以元数据标准化模型为依据,启用相应的校验规则和质量验证,可深度影响或者关联原始数据的形态,同时打上明确的标签和版本。
在数据治理的整体体系中,能够依据元数据管理模型,及主数据的规则文件,快速的洞察数据的质量,识别其数据风险,并在必要节点(按预定义的自动化流程)触发数据的治理流程。
能够对于接入的数据质量进行实时管控。可提供数据字段校验、数据完整性分析等功能;同时,可监控数据处理任务,避免未执行完成任务生成不完备的数据。
1.2.2 原始数据(数据存储)
基于原始数据,会依照元数据标准模型,通过数据湖里的既定工作流引擎对其进行有针对性的数据清洗、转换、并回写数据目录。
1.2.3 数据聚合(数据发现与分析)
针对文本、视频、音频、图片、文字及其他一些固定格式文件,通过预定义模型所进行的数据挖掘(Data Mining)和分析,且可将其分析或发觉的成果,或回写,或更新数据目录。
使其数据的脉络(血缘)、层次,关系更加的清晰,为进一步的可视化展示及智能化应用方面的实现,提供切实、可靠的依据。同时,兼具对最终学术科研成果等隐性知识的显化功能。
1.2.4 元数据管理
通过对元数据所采取的管理措施,对于数据的入湖动作,尽可能的采取智能化入湖操作,即可按照预先定义模式,将极少的人为干预或者完全不需要人为干预进行数据入湖工作。
1.3 数据湖数据架构
铀矿勘查数据湖的数据架构由数据计算、数据存储、数据源等3 个独立而又相互联系的功能组件组成。数据架构可以实现对数据源的统一抽取与迁移、数据集中存储与分析、数据质量的统一治理,同时支持数据智能分析及数据内容的共享应用(如图3 所示)。
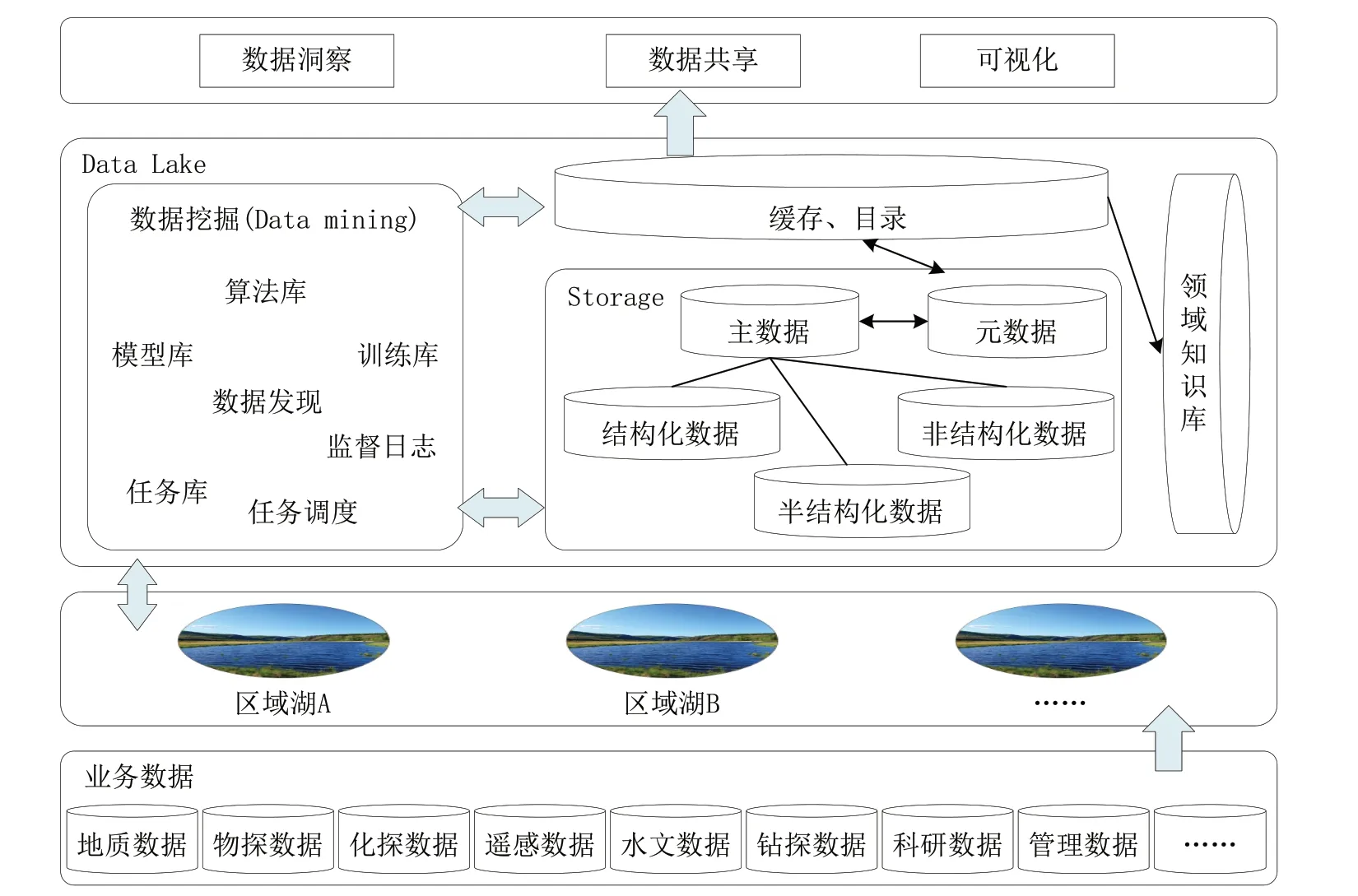
图3 铀矿勘查数据湖数据架构Fig.3 Data architecture of uranium exploration data lake
2 基础组件
2.1 存储组件
近几十年来,数据存储由直连存储、中心化存储,发展到分布式存储的阶段。直连存储是存储和数据直接连通,表现为拓展性和灵活性较差;中心化存储是通过IP/FC 网络互通互连,存储设备类型多样化,具有一定的扩展性和拓展性,但数据迁移成本较高;分布式存储是基于标准分布式架构系统和标准硬件设备,实现千节点级别的扩展,同时可以统一管理块类型、对象类型和文件类型的存储。目前,分布式存储框架包括Hadoop Distributed File System(HDFS)、OpenStack Object Storage(Swift)、Ceph 等。每一种分布式存储技术都有各自的特点和应用场景,由于铀矿勘查数据多为数量巨多的小文件,且结构化和非结构化并存,因此选择Ceph式分布存储框架。其可以实现块存储、文件存储和对象存储。Ceph 的核心组件有Ceph Monitor、Ceph MDS和Ceph OSD,它们架构分布如图4 所示。
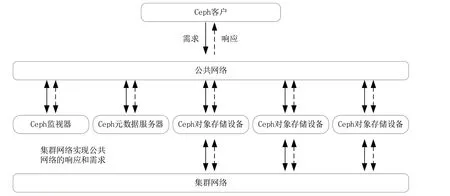
图4 Ceph 分布式框架的主要组件Fig.4 The main components of the Ceph distributed framework
(1)Ceph OSD 作为对象存储设备(Object Storage Device),其主要功能是存储数据、平衡数据、复制数据、恢复数据等,同时负责响应客户端请求返回具体数据的进程。多个OSD 可以耦合到一个Ceph 集群,实现数据的海量规模存储。
(2)Ceph MDS 作为元数据服务器(Ceph Meta Data Server),其主要保存文件系统服务的元数据,但对象存储和块存储设备是不需要使用该服务的。
(3)Ceph Monitor 作为Ceph 的监视器,负责管理Ceph 集群相关系统的健康状态,集群内的成员及其属性和关系以及数据的分发都属于监视器的管理范畴。
Ceph 系统为了对OSD、Monitor、MDS 的管理和应用协调,引入Reliable Autonomic Distributed Object Store(RADOS)系统,该系统又由5 部分组成(如图5 所示),基于RADOS 层的是LIBRADOS,在LIBRADOS 之上又分为RADOSGW、RBD 和CEPH FS。LIBRADOS 作为一个内置库,外部应用程序访问该库实现与RADOS系统交互通信;RADOSGW 是基于RESTFUL 协议的网关,与亚马逊的S3 和Spark 的Swift 兼容,该层实现对象存储;RBD 利用Linux 内核客户端和QEMU/KVM驱动实现分布式的块存储;CEPH FS 利用Linux 内核客户端和FUSE 提供文件系统的功能。至此Ceph 实现了对象存储、块存储和文件存储。

图5 Ceph 系统分层关系图Fig.5 Hierarchical diagram of the Ceph system
2.2 计算组件
基于分布式框架的计算引擎主要有MapReduce、Spark、Storm、Flink 等。MapReduce 是Hadoop 分布式计算的核心组件,谷歌引入MapReduce 作为一种编程模型来促进其搜索过程。Spark 于2009 年诞生于加州大学伯克利分校的AMP 实验室,并于2013 年捐献给阿帕奇软件基金会(Apache Software Foundation)作为开源代码。Storm 是由Twitter 公司提出的处理实时大数据的流式计算的分布式框架。Flink 于2010 年起源于柏林大学的Stratosphere 项目,后期被阿里巴巴公司收购,它成为双十一商业活动大规模数据实时处理的利器。
基于铀矿勘查数据分析与挖掘应用实际情况,多以离线数据计算为主,对实时数据流的处理要求不高,因此选择Spark 引擎作为铀矿勘查数据湖的计算组件(如图6 所示)。
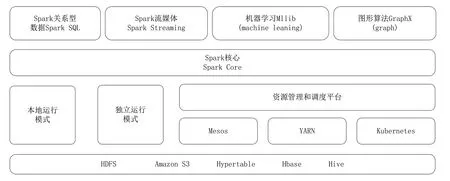
图6 Spark 分布式计算引擎主要组件Fig.6 The main components of the Spark distributed computing engine
(1)Spark Core 作为Spark 计算组件的核心,主要负责任务调度等管理功能。Spark Core 依赖弹性分布式数据集(Resilient Distributed Datasets,RDDs)实现分布式计算。
(2)Spark SQL 是处理结构化数据的模块,其支持SQL、HiveQL 等数据库查询及复杂算法的分析;还支持JDBC 和ODBC 连接,能够直接连接现有的数据库。
(3)Spark Streaming 支持流数据的可伸缩和容错处理,集成了Kafka 和Flume 平台,前者提供消息队列功能,后者实现日志数据优化处理。该集成平台使其为流数据的处理能够更灵活,也更容易实现。
(4)MLlib 主要应用于机器学习领域,实现了分类、回归、聚类、主成分分析等相关算法。
(5)GraphX 可支持数据图的分析和计算,包含了许多被广泛理解的图形算法,并支持图形处理的Pregel API 版本。
Spark 集群分为Master 节点和Worker 节点。Master节点管理其系统下的所有Worker 节点。Worker 节点负责与Master 节点信息通信并管理Executors。Driver 是用户编写的Spark 应用程序的进程,其可以在Master 和Worker 节点上同时运行(如图7 所示)。

图7 Spark 分布式计算引擎工作原理(据spark.apache.org 修改)Fig.7 Working principle diagram of the spark distributed computing engine (after spark.apache.org)
Spark 在一个节点上计算的流程:Master 定时检查与接收任意Worker 节点的发送消息,然后将消息保存起来,并向Worker 返回一个注册成功的消息;Worker接收到Master 注册成功的消息后,启用定时器,定时向Master 发送下一次响应,更新Worker 上一次的响应时间。RDD 将信息集通过一系列转换,生成有向无环图(Directed Acyclic Graph,DAG),DAG 将多个Task任务进行封装到Executor 实施执行,所有Task 运行结束之后,Executor 向Worker 注销自身,释放资源。多个Worker 节点可以并行计算,从而实现了分布式高效计算。
2.3 数据源组件
铀矿勘查数据湖平台可支持的数据库类型包括PostgreSQL、MongoDB 等不同类型数据库。支持的文件类型包括文本文件(TXT、CSV 等)、Excel 文件、JSON 文件、XML 文件等、MapGIS 格式、ArcGIS 格式、AutoCAD 格式、栅格数据JPG、BMP 等图片。支持WebService、RestFul等接口类型,接口格式支持JSON、XML 等。
基于对当前主流的大数据存储组件、计算组件、数据源组件的工作原理及技术参数的分析,认为Ceph 分布式存储平台适合铀矿勘查数据的存储。地震、重力、电磁等勘查数据体量大且结构多样,适合块存储;地质图件、钻孔勘查数据等多为体量小且分散的数据,适合文件存储;铀矿勘查数据中的音视频文件可以保存成对象存储。铀矿勘查业务应用方面主要集中在钻孔数据分析,如砂体厚度、泥岩埋深、蚀变规模、断裂类型、物化探数据反演、遥感蚀变提取、成矿预测分析等离线数据计算;铀矿勘探钻孔进尺统计等实时数据计算;Spark计算引擎可完全满足铀矿勘查数据的离线和实时计算需求。Spark 的MLlib 模块和GraphX 算法为铀矿勘查数据的知识图谱构建和智能分析提供强有力的支撑。
3 结论
当前构建的铀矿勘查数据湖是一个集中式存储库,可以存储结构化和非结构化数据。可实现原样存储,并运行不同类型的分析,可以做出更好的决策。
(1)灵活的底层存储功能且可存储原始数据。具有大规模数据存储能力和多种存储平台,多种数据存储格式(结构化、非结构化、非结构化)并存,实现数据缓存加速。
(2)丰富的计算引擎。本文构建的铀矿勘查数据湖可实现批量数据计算、实时数据计算和交互式数据查询。
(3)完善的数据管理。通过元数据可实现数据生命周期的全管理;满足数据的迁移、质量控制、数据治理和数据发布的需求。
引用
[1] 杜金虎,时付更,杨剑锋,等.中国石油上游业务信息化建设总体蓝图[J].中国石油勘探,2020,25(5):1-8.
[2] 马驰.民机运行支持数据湖设计与实现[J].计算机测量与控制,2021,29(7):175-179.
[3] 张芸.浅谈石油勘探行业数据湖建设中的数据治理问题[J].中国管理信息化,2021,24(9):122-124.
[4] 刘志勇,何忠江,刘敬龙,等.统一数据湖技术研究和建设方案[J].电信科学,2021,37(1):121-128.
[5] 赵志远.AWS的“数据湖”观[J].网络安全和信息化,2020(5): 8-9.
[6] 胡军军,谢晓军,石彦彬,等.电信运营商数据湖技术实施策略[J].电信科学,2019,35(2):84-94.
[7] 时付更,王洪亮,孙瑶,等.梦想云在油气精益生产管理中的应用[J].中国石油勘探,2020,25(5):9-14.
[8] 黄家凯.地质数据湖构建方法浅析[J].数字技术与应用,2020,38 (11):135-138.
猜你喜欢
林业勘查设计(2022年2期)2022-03-21
林业勘查设计(2022年2期)2022-03-21
林业勘查设计(2021年6期)2021-11-26
河北理科教学研究(2021年4期)2021-04-19
矿产勘查(2020年9期)2020-12-25
河北地质(2020年1期)2020-09-16
计算机教育(2020年5期)2020-07-24
四川地质学报(2020年3期)2020-05-22
世界核地质科学(2018年2期)2018-07-05
世界核地质科学(2018年2期)2018-07-05
