
2010-2021 年国内文本挖掘的文献计量分析*
2023-02-19 12:24川北医学院管理学院谭明亮蒋静
数字技术与应用 2023年1期
川北医学院管理学院 谭明亮 蒋静
本文以中国知网数据库收录的文本挖掘相关的研究文献作为研究对象,借助于知识可视化图谱分析工具CiteSpace 对研究文献进行多个维度的分析并以科学知识图谱的形式呈现,主要包括关键词分析、作者分析、研究机构分析和研究趋势分析。本文通过文献计量分析发现,2010—2021 年的12 年间,文本挖掘领域研究主题广泛,研究层次多样,研究人员数量众多,在不同时期有不同的研究重点。
近年来,随着移动通信和互联网技术的快速发展和广泛普及,文本数据的规模呈现出急剧增长的趋势,主要包括研究报告、学术论文、电子邮件、网页、公司内部公告等。非结构化文本是非常重要的数据资源,为了更好地处理和使用这些数量庞大、结构多样的文本数据,文本挖掘技术随之而诞生。文本挖掘作为自然语言处理、机器学习和数据挖掘等多项技术的交叉研究领域,其研究热度也逐年提升。本文从中国知网数据库上获取文本挖掘领域的相关研究文献,基于文献计量法和CiteSpace软件,主要从研究人员、研究机构、研究内容和研究趋势等多个维度,对收集到的文献数据进行全面综合的分析,以期为文本挖掘领域的研究人员提供一定的参考和借鉴。
1 数据选取
本文的研究数据来自于中国知网(CNKI)中文数据库,数据采集的检索条件设置如下:主题词设置为“文本挖掘”,研究文献的发表年份设置为2010—2021 年。经过检索,共得到4853 篇研究文献,其中包括了2326篇学术期刊论文、2222 篇学位论文和101 篇会议论文,剔除其中与本文研究相关度低的204 篇文献(包括年鉴、报纸等),得到有效文献共计4649 篇。
本文将文献数据以Refworks 的格式下载到本地文件夹data for CiteSpace 下的input 文件夹之中,文献输出信息以txt 文本文件形式存储,txt 文件以download_加数字命名,例如“download_1”,以download_加数字的格式命名文件是为了后续能够更便捷地将CNKI 文献导入CiteSpace 数据库中。
2 分析方法与分析工具
2.1 分析方法
文献计量法是一种定量分析方法,是以科技文献的各种外部特征作为研究对象,采用数学与统计学的方法来描述、评价和预测科学技术现状与发展趋势的一种方法,文献计量法的主要特点输出必是量化的信息内容[1]。文献计量法在科技评价、科研管理等领域有着非常广泛的应用,并在图书情报领域的应用尤为广泛,如测定学科核心期刊、建设情报检索系统、编制领域主题词表等[2]。
科学知识图谱分析法是文献计量学的一种重要分析方法,它将科研活动的主体(如研究人员、研究团队、研究机构等)或具有某种共同特征的学科领域群体作为研究对象,利用可视化技术描述知识资源及其载体,通过分析、挖掘和可视化知识及其之间的相互关系,将相关研究的发展进程和结构关系以直观图形的方式展现,从而帮助研究者了解领域研究现状和前沿动态[3]。
2.2 分析工具
大数据背景下,文献信息的规模与日俱增,如何在这些文献中找出值得深入阅读和作为参考的关键文献,挖掘学科前沿,找到相关领域的研究热点成为科研工作中的重要问题。为了有效地分析研究文献,各种绘制科学知识图谱的工具纷至沓来。其中,美国德雷塞尔大学陈超美教授开发的用于文献数据分析和可视化的Java 应用程序CiteSpace(其中文名为“引文空间”)成为了目前最流行的知识图谱绘制工具之一[4]。
CiteSpace 以共引分析理论(Co-ciation)、寻径网络算法(PathFinder)、结构洞理论(Structural Holes)等理论作为基础,将某一特定领域的文献进行计量和可视化,以期探求出学科领域演化的关键路径和知识拐点,再结合绘制的一系列可视化知识图谱,对学科领域内潜在的演化动力机制进行分析和对学科发展前沿进行探测[5]。目前,国内外的研究者们已经将CiteSpace 软件广泛应用于图书情报、医疗卫生、经济管理等领域的文献计量与可视化分析中。
3 文本挖掘研究文献的可视化图谱分析
3.1 关键词分析
本文对文本挖掘研究文献的关键词进行统计分析,筛选出7 个频次大于100 的关键词。除去本文选取的检索词“文本挖掘(频次为2340)”,其余的关键词分别是“数据挖掘(频次为242)”“情感分析(频次为217)”“文本分类(频次为204)”“主题模型(频次为173)”“文本聚类(频次为168)”“机器学习(频次为102)”,这些关键词代表了文本挖掘研究领域最核心的问题主要包括文本的分类、聚类、主题分析和情感分析等。
本文利用CiteSpace 软件绘制2010-2021 年文本挖掘研究文献关键词的突现图谱,选取其中突变率最高的20 个关键词进行展示,如图1 所示。2010年,文本挖掘的研究主要集中于文本分类和本体;到2011-2014 年之间,文本挖掘领域的研究热点逐渐向医学方面倾斜,逐步应用于西药、中成药以及中药方面;在2014-2018 年这5 年中,文本挖掘涉及的领域不断增多,在证候、网络评论、短文本、微博、图书馆等领域都有所涉及;在2018-2021 年间,文本挖掘的研究主要集中于人工智能、知识图谱、情感分析、金融科技、政策评论、政策工具等方面。总体而言,文本挖掘研究领域的变化,与我国经济迅速发展和信息技术日新月异的时代背景紧密相关。
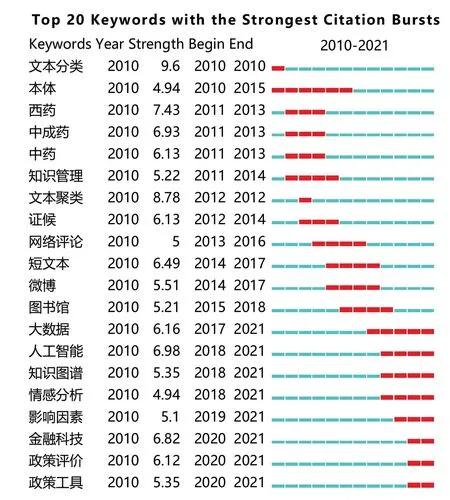
图1 关键词突现图谱Fig.1 Keywords emergence map
本文利用CiteSpace 软件对研究文献的关键词进行共词分析,结果如图2 所示。在关键词共现图谱中分布着许多大小不一的圆圈,圆圈的大小代表着关键词的频次,圆圈越大,频次越多。在图2中,有5 个明显的圆圈,其代表的关键词分别为文本挖掘、主题分类、数据挖掘、文本分类和情感分析。关键词共现图谱中的线条代表着关键词之间的联系,通过线条颜色能看出哪一年有哪些关键词,线条颜色越鲜艳标志着该研究内容的年份越靠近当下。可以看出,在文本挖掘领域发展的各个时间段都有着不同的研究侧重点和研究热点,在颜色最鲜艳的时间线上的关键词有深度学习、主题模型、语义分析、知识发现、推荐系统、人工智能、政策工具等,最近几年文本挖掘领域的研究重点主要集中在智能服务、语义深度挖掘、政策分析等领域。图2 线条众多,连接复杂,说明在文本挖掘研究领域中各关键词之间联系紧密,文本挖掘研究涉及的领域广泛。
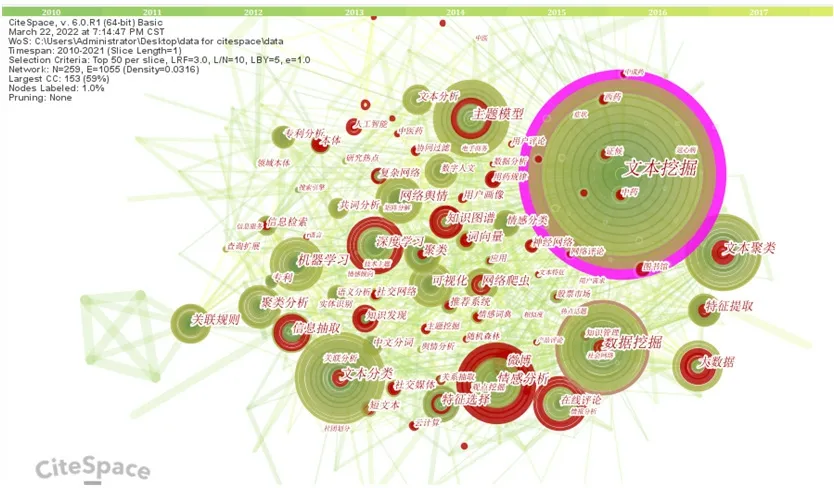
图2 关键词共现图谱Fig.2 Keywords co-occurrence map
3.2 作者分析
为了发现文本挖掘领域研究的中坚力量,探寻该领域的核心作者群体,本文利用CiteSpace 软件绘制了文本挖掘研究领域的作者共现图谱,如图3 所示。图中最突出的合作关系是以吕爱平为中心的研究团体,该团体中研究人员众多,包括张弛、姜春燕、赵宁、王耀献、崔赵丽等人;汪雪锋、任惠超、刘玉琴、张磊等人组成了一个研究团体,在这个团体中,以作者汪雪峰为中心;除此之外,还有黄敏婷、刘芳羽、赵秉元、李泽、古超等人组成的研究团体;以及白卫国、王跃溪、王丽颖、韩学杰、赵学尧等人组成的研究团体。
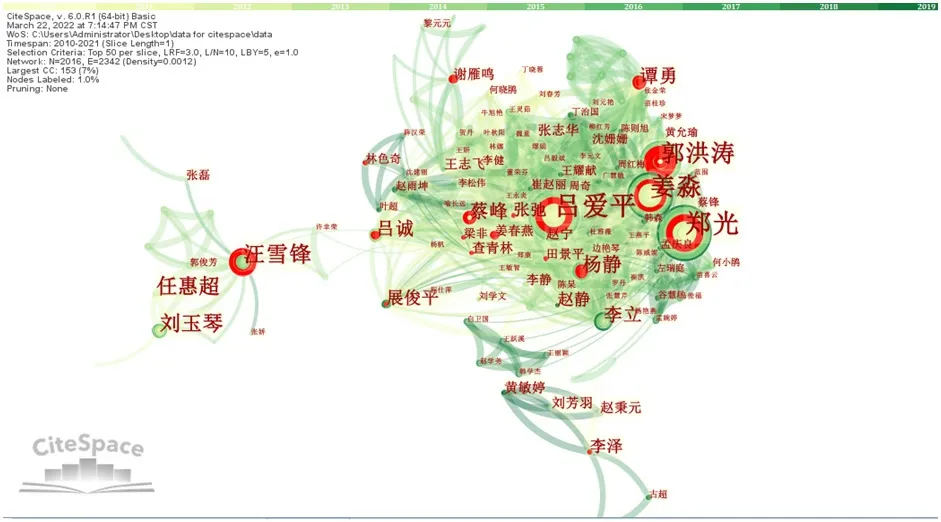
图3 作者共现图谱Fig.3 Authors co-occurrence map
从事文本挖掘领域研究的专家学者不胜枚举,其中,郭洪涛、姜淼、吕爱平、郑光、汪雪锋所发表的文献被引次数最多;吕爱平、郑光发表的文献被引次数为69次;姜淼发表的文献被引次数为56 次;郭洪涛发表的文献被引次数为45 次。这几位作者是文本挖掘研究领域的带头人,在文本挖掘研究领域内具有重要影响。
通过作者突显分析,可以发现在2010—2021 年之间各个阶段的主要研究人员。在2011—2013 年中,作者郭洪涛、谭勇、杨静发表文献最多;2015—2017年,作者张永安发表文献最多;2017—2021 年之间,作者黄名选、黄鲁成、崔雷、武帅发表文献最多,其中作者黄鲁成在2016—2021 年都保持着较高的发文量。以上这些作者在文本挖掘研究领域都保持着较高的活跃度,在文本挖掘研究领域都具有重要的影响。作者吕爱平、郑光、姜淼在总体上发文最多,但论文的主要发表年限都集中在2013年,论文发表年限比较早,是文本挖掘研究领域的开拓者之一。
3.3 研究机构分析
通过对研究机构的分析,可以看出哪些机构在文本挖掘研究领域发挥着重要的作用,哪些机构之间联系比较紧密,哪些机构为文本挖掘的研究做出了重要贡献[6]。本文利用CiteSpace 软件绘制了文本挖掘研究领域的研究机构共现图谱,如图4 所示。
从图4 可以直观地看出,文本挖掘领域的研究主要以中国科学院大学经济与管理学院、中国科学院文献情报中心、中国科学院大学、北京理工大学管理与经济学院、北京工业大学经济与管理学院、武汉大学信息管理学院这几个研究机构为中心。其中,以中国中医科学院中医临床基础医学研究所为中心,兰州大学信息学院、兰州大学应用数学与统计学院、上海中医药大学、河南中医学院第一附属医院等研究机构参与了文本挖掘领域内的研究;以北京理工大学管理与经济学院为中心,中国船舶信息中心、北京印刷学院新闻出版学院、中国政法大学商学院等研究机构进行了合作;以中国科学院大学为中心,中国科学院国家科学图书馆、北京大学信息管理系、上海市浦东新区人民检察院、中国科学院大数据挖掘与知识管理重点实验室等机构对文本挖掘进行了研究与合作;以武汉大学信息管理学院为中心,武汉大学信息资源研究中心、武汉大学遥感信息工程学院、武汉纺织大学会计学院等机构进行了合作。
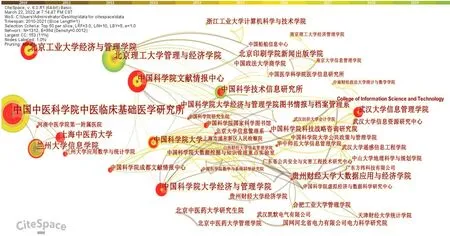
图4 研究机构共现图谱Fig.4 Research institutions co-occurrence map
本文对文本挖掘领域的主要研究机构的文献发表数量进行统计,大连理工大学发表了相关论文112篇,中国中医科学院发表了相关论文90篇,北京邮电大学发表了相关论文89篇,电子科技大学发表了相关论文83篇,武汉大学发表了相关论文81篇,北京工业大学发表了相关论文80篇,吉林大学发表了相关论文72篇,中国科学院大学发表了相关论文71篇,兰州大学发表了相关论文71篇,北京交通大学发表了相关论文68 篇。由以上数据可以得出,在文本挖掘研究领域文献的发表机构以高等院校为主,主要集中在理工类院校,也有少部分高等医学院校。在这些高等院校中,大连理工大学发表的相关论文数量最多。这些研究机构主要集中在中国经济发展水平比较高、学术研究力量较为雄厚的大城市,如北京、武汉、大连、长春等。这些研究机构学术型人才多,学术水平较高,研究视野开阔。
3.4 研究趋势分析
为了分析出文本挖掘领域在2010-2021 年的研究趋势,本文利用CiteSpace 工具,绘制有关文本挖掘领域的关键词时区图,如图5 所示。可以看出,在2010年,文本挖掘研究重点在文本分类、情感分析、数据挖掘以及主题模型这几个方面;2011年,文本挖掘研究重点在可视化、主题分析、指标体系、西药、神经网络等几个方面;2012年,文本挖掘研究重点在文本分析、数字人文、情感分类、社交网络、情感词典等几个方面;2013年,文本挖掘研究重点在股票市场、共词分析、微博、图书馆、推荐系统等几个方面;2014年,文本挖掘研究重点在大数据、网络爬虫、短文本、社交媒体、知识图谱等几个方面;2015年,文本挖掘研究重点在词向量、复杂网络、主题挖掘等几个方面;2016年,文本挖掘研究重点在用户画像、数据分析、协同过滤、分词等几个方面;2017年,文本挖掘研究重点在满意度、文献计量、影响因素、用户要求等方面;2018年,文本挖掘研究重点在人工智能、新浪微博等几个方面;2019年,文本挖掘研究重点在词云图、网络新闻、商业银行、服务质量等几个方面;2020年,文本挖掘研究重点在政策文本、电力设备、金融科技、形象感知等几个方面;2021年,文本挖掘研究重点在评论数据、微博评论等几个方面。
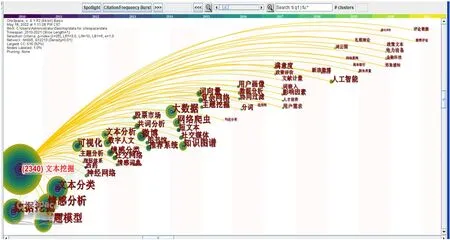
图5 关键词时区图Fig.5 Keywords time zone map
4 结语
本文从关键词、作者、研究机构、研究趋势这四个方面,对文本挖掘研究领域的相关文献进行分析总结。无论是从时间的横向还是纵向来看,文本挖掘领域的研究可以总结如下:文本挖掘的研究热点主要集中在大数据、评论挖掘、情感分析等方面,文本挖掘研究涉及领域广泛,包括计算机领域、医学领域、管理领域以及政治领域等;文本挖掘的研究人员和研究机构众多,主要研究机构为高等院校,也有少部分企业对文本挖掘进行研究;文本挖掘在社会科学和自然科学的研究中得到了充分利用,且呈现不断上升的趋势,主要涉及计算机科学、图书情报和经济管理等学科领域,文本分类、文本聚类和情感分析是文本挖掘的核心技术。
引用
[1] 吴爱芝,肖珑,张春红,等.基于文献计量的高校学科竞争力评估方法与体系[J].大学图书馆学报,2018,36(1):62-67+26.
[2] 朱亮,孟宪学.文献计量法与内容分析法比较研究[J].图书馆工作与研究,2013(6):64-66.
[3] 冯新翎,何胜,熊太纯,等.“科学知识图谱”与“Google知识图谱”比较分析——基于知识管理理论视角[J].情报杂志,2017,36 (1):149-153.
[4] 陈悦,陈超美,刘则渊,等.CiteSpace知识图谱的方法论功能[J].科学学研究,2015,33(2):242-253.
[5] 侯剑华,胡志刚.CiteSpace软件应用研究的回顾与展望[J].现代情报,2013,33(4):99-103.
[6] 蒋海刚.词向量文本挖掘技术在建筑设施管理应用研究[J].电脑知识与技术,2021,17(33):22-25.
猜你喜欢
少先队活动(2020年12期)2021-01-14
大东方(2019年12期)2019-10-20
青年生活(2019年23期)2019-09-10
科学与财富(2017年22期)2017-09-10
中成药(2017年3期)2017-05-17
商情(2017年1期)2017-03-22
中共南宁市委党校学报(2015年4期)2015-02-28
中国音乐教育(2014年7期)2014-02-06
杭州科技(2013年5期)2013-03-11
杂草学报(2012年1期)2012-11-06
