
多级特征引导网络的红外与可见光图像融合
2023-02-18 03:06王彦舜聂仁灿张谷铖杨小飞
中国图象图形学报 2023年1期
王彦舜,聂仁灿,张谷铖,杨小飞
云南大学信息学院,昆明 650505
0 引 言
在复杂现实应用条件下,捕获成像设备的传感器不能有效提取图像的各方面丰富信息,极大地限制了目标探测和识别等性能。图像融合一直是图像领域的重要研究部分,其通过对多个传感器采集到的不同类别的图像进行融合而获得一幅包含源图像完整信息的融合结果,主要包括多聚焦图像融合、多曝光图像融合、红外与可见光图像融合(infrared and visible image fusion,IVIF)等。其中,红外与可见光图像由于成像机制不同,在同一场景下可以形成良好的互补特性。红外图像反映物体的热辐射情况,不易受气候等环境影响,抗干扰能力强,在透雾、夜视等方面有着更为显著的效果。然而,红外图像缺乏对纹理细节的展现,对比度低,分辨率差,视觉效果模糊;可见光图像反映物体表面的反射特性,空间分辨率较高,且具有清晰的细节纹理信息,含有丰富的细节信息,更易被人眼视觉系统所理解,但其成像过程对外部环境依赖较大,有利于人眼对场景的认知,但成像效果对外界环境光照条件依赖性大,在低照度下成像效果会下降。通过红外与可见光图像融合任务,得到一幅既能突出红外目标信息,又能展现高分辨率细节信息的图像,对于军事民生具有重要意义,为目标检测(Zhang等,2020)、无人系统安防(李国梁 等,2022)、安全导航、交通监测和智能监控(Li和Wu,2019)等诸多领域提供了重要的基础。
IVIF现阶段主要分为传统方法和基于深度学习的融合方法。传统方法如基于多尺度变换方法(multiscale transform methods, MST)(Chen等,2020;杨勇 等,2015)是目前图像融合领域研究最多、应用最广的方法。首先将源图像在不同尺度上进行分解,然后设计融合策略对源图像不同尺度的信息特征进行融合,最后重建为融合结果。典型的方法包括拉普拉斯金字塔变换(Laplacian pyramid, LP)(Burt和Adelson,1987),该方法首先对每幅源图像进行金字塔分解得到不同层次(尺度)下的带通子图像(体现不同空间分辨率的信息),对各源图像的不同尺度分解系数采用特定规则进行融合,但由于其具有平移不变性,会产生大量的冗余信息。为了改进LP,有学者提出NSCT(non-subsampled contourlet transform)(陈木生,2016)与 NSST(non-subsampled shearlet transform)(Zhang等,2015),这两种方法可以提取更全面的细节信息,减少冗余量。但是在融合过程中没有充分考虑空间一致性,导致融合图像中可能会出现伪影。其他的传统方法还有基于稀疏表示(Liu等,2017)、基于子空间(Li等,2013)、基于引导滤波的图像融合方法(guided filtering fusion,GFF)以及利用显著性检测的可见光和红外图像双尺度融合方法(two-scale image fusion based on visual saliency,TSIFVS)(Bavirisetti和Dhuli,2016)等。Li等人(2020b)提出MDlatLRR(multi-level decomposition with latent low-rank representation),将图像分为基础和细节两部分,但融合策略的选择设计较为复杂,适应性差。Li等人(2021a)对红外图像预处理,提出IVFusion(infrared and visible image fussion)将红外图像目标背景对比度加上来,不采用传统加权方式,然而由于手工设计性强,融合图像在主观视觉上存在较大失真。Zhao等人(2020)提出Bayesian模型,将红外与可见光图像融合任务转换为回归问题,然而,算法设计复杂,图像细节不够清晰。刘明葳等人(2021)利用各向异性导向滤波从源图像获得多种尺度的序列细节图,利用各向异性导向滤波优化权重,取得了较为理想的融合结果。Chen等人(2020)提出TE-MST(target-enhanced multiscale transform decomposition),对红外图像热目标增强,然而,由于传统方法不能自适应地有效提取热目标信息,融合效果不够真实。这些方法为了避免亮度退化以及纹理缺失等问题,必须设计合适的分解方法与融合规则,导致融合效率下降。
基于深度学习的融合方法由于计算机强大的计算能力,广泛应用于IVIF任务中。Li等人(2018)利用卷积神经网络(convolutional neural network,CNN)提出了一种融合方法(VGG-lnorm)。然而,该网络不能提取足够的特征。因此,他们采用密集连接卷积网络(densely connected convolutional networks,DenseNet)(Iandola等,2014)对源图像特征进行深度提取,并设计了DenseFase(Li和Wu,2019)实现融合任务。Zhao等人(2021)设计了一个自编码器,提取源图像的背景与纹理特征,然后设计融合策略对特征进行融合,方法命名为DIDF-use(deep image decomposition for infrared and visible image fusion)。Fu和Wu(2021)提出DualFuse(dual-branch network for infrared and visible image fusion),在通道策略上分解,与传统方法相比融合质量较好,但亮度信息提取不明显。然而,自编码器没有改变特征图的尺寸,导致编码器中存在恒等映射,不能提取出足够的有用特征。因此,研究人员利用蜂巢网络(UNet)(Ronneberger等,2015)对源图像进行多尺度特征提取,同时设计基于巢连接模型的红外与可见光图像融合架构(NestFuse)(Li等,2020a)与基于残差端到端融合网络结构RFN-Nest(residual fusion network)(Li等,2021b)实现了IVIF任务。尽管他们的方法有效地避免了上述问题,但是,特征图尺寸的变化可能会导致关键信息的缺失。此外,他们的方法由较为简单的损失函数来约束,导致融合结果在亮度以及细节纹理上存在缺陷。Tang等人(2022)将图像融合与视觉任务结合起来,提出语义感知的实时图像融合网络(semantic-aware real-time infrared and visible image fusion network,SEAFusion),设计了一个梯度残差密集块来提高融合网络对细粒度细节的描述能力,并采用高级视觉算法对融合过程进行优化,得到了较好的融合结果,但融合框架的设计较为简单,不能充分地提取源图像的纹理特征。李云飞等人(2022)在深度学习的基础上提出一种单样本对融合算法,该方法利用卷积神经网络建立高、低空间分辨率图像间的超分关系,得到了具有更丰富的场景信息的融合结果。
本文设计了一个新颖的端到端融合框架,包括编码器与解码器。利用编码器提取源图像的特征,并将编码器提取的多级特征引导至解码器中以对结果进行融合重建。在训练阶段,提出一组混合损失,包括加权保真项和结构张量损失。其中,前者利用显著性检测算法(Saliency_LC)产生的显著性图与源图像相结合生成权值对保真项进行改进,在像素层面约束融合图像与源图像的相似度,有效地避免了融合结果的亮度退化问题;而后者允许融合结果包含更多的结构细节。
1 本文融合方法
本文提出的融合框架由编码器和解码器组成。其中,编码器对源图像进行特征提取并融合;解码器对融合结果进行重建,生成融合结果。
1.1 编码器
首先将一对红外与可见光图像采用卷积操作得到一对通道数为16的特征图。然后将特征图输入到融合框架中,通过多个参数共享的卷积块对其进行特征提取,其中每个卷积块由CNN-ReLU-CNN-ReLU组成。如图1所示,当经过EB10,EB11,EB12这3个卷积块后,采用最大池化操作(maxpooling)将特征图的尺寸减半,去除冗余信息、对特征进行压缩,简化网络复杂度,对网络主要特征保留的同时防止过拟合,提高模型的泛化能力,实现多尺度网络结构。然后继续采用EB20,EB21这2个卷积块与最大池化提取源图像的深度特征。最后,使用1个卷积块(EB30)和最大池化获得源图像的多级特征。具体来说,每个CNN函数的卷积核大小(kernel size)设为3,步长(stride)与填充(padding)均设为1,每级特征的输出通道分别为56,80,208(每层通道维数见表1)。当提取特征后,将每一级的红外图像特征与可见光图像特征进行拼接融合(concatenation),在图1中,为了充分引导特征信息,编码器除了最终输出作为解码器的输入外,在编码器每部分均进行特征引导,获得多级的融合结果。

图1 本文网络结构
1.2 解码器
Li等人(2020a)提出NestFuse蜂巢网络用于红外与见光图像融合,该网络是一种常见的编解码结构。与其不同的是(由图1可见),本文提出的编码器对每层的每一部分均进行特征引导。同时,采用池化操作,避免冗余信息在深层网络中的无效训练,对应编码器池化操作,解码器采用上采样进行尺寸还原,提高有效特征信息的分辨率,体现多尺度构造。
如图1所示,解码器首先通过DB10,DB20,DB30卷积块对多级特征进行充分融合,获得特征图。然后,对编码器中的每一级特征进行拼接融合,同时将融合结果引导至解码器中。再者,对深层次的特征采取上采样操作(upsampling)并与上一级特征进行融合,再经过DB14卷积块得到多级特征的融合结果。最终,通过一个卷积操作对结果进行重建,得到一幅融合图像。与编码器中的卷积块相似,解码器中的卷积块同样由两组卷积与ReLU激活函数组成,每个卷积块的具体通道数如表1所示。
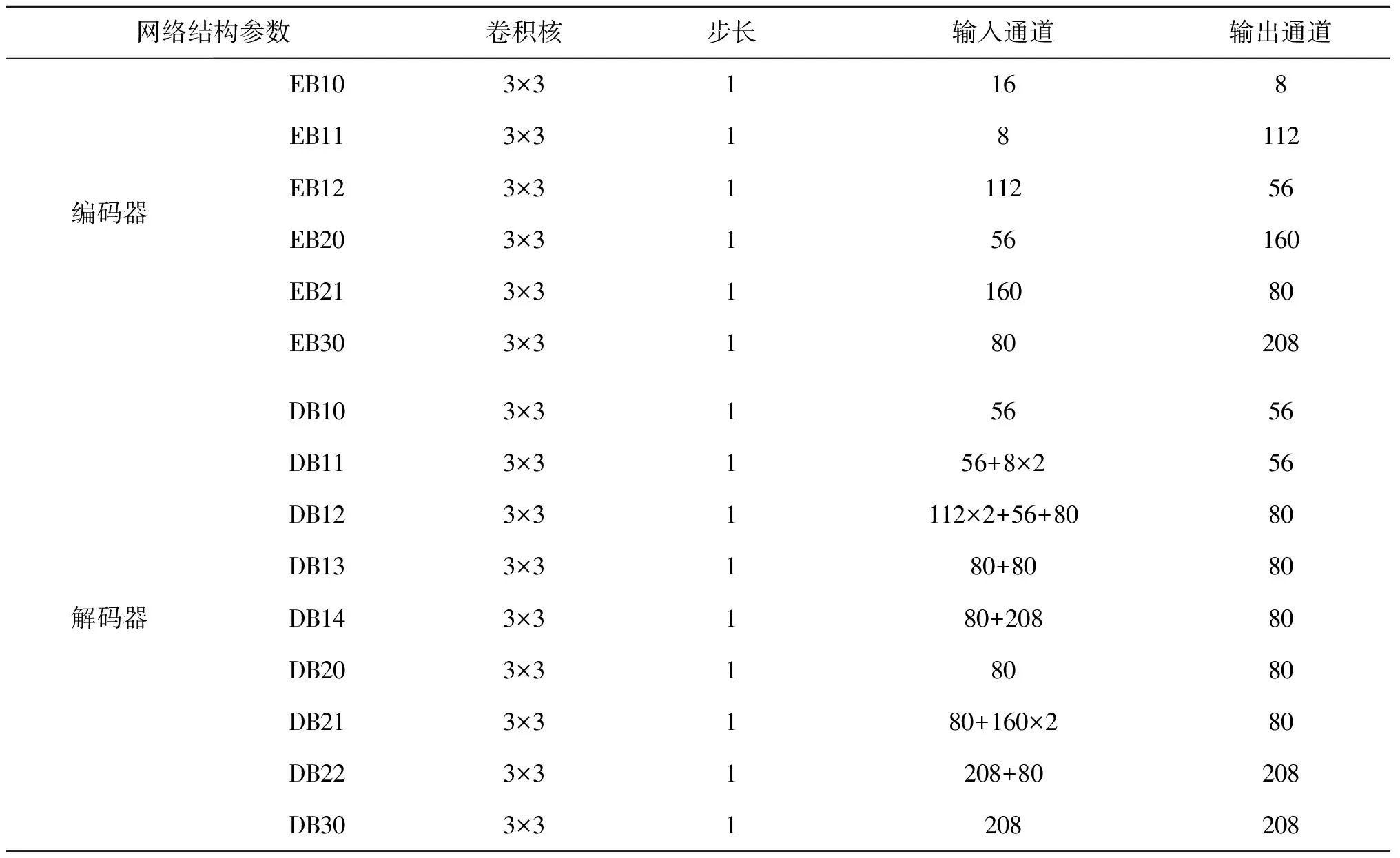
表1 网络结构中各部分卷积核详细参数
相较于现有的深度学习方法,本文的融合框架有以下3点优势:1)通过池化和上采样设计的多尺度网络结构,允许编码器提取更多的源图像的重要特征;2)将编码器中的多级特征引导至解码器中,多极特征体现在编码器每层的每一部分,EB10,EB11,EB20输出的特征图拼接后馈送至DB11,DB12,DB21,多尺度的融合弥补了信息的丢失,有效地避免了因池化特征图尺寸变化导致的信息缺失问题;3)多深度、多层次、多引导的多尺度的重建过程能够让解码器获得更好的融合结果。
1.3 损失函数
本文方法损失函数由加权保真项与结构张量损失组成,其定义为
L=L1+λL2
(1)
式中,L1表示加权保真项,在像素级层面约束融合结果与源图像的像素相似度,其表达式为

(2)

算法 1: 图像显著性检测算法(Saliency_LC)
1)输入: 完整的红外与可见光图像对;
2)对每幅图像,图像I中某个像素Ik的显著值计算为
Ik-I1+Ik-I2+…+Ik-IN
3)令I1=a0,I2=a1,Ik=am
4)得SalS(Ik)=am-a0+…+am-a1+…
5)输出:最终表达式

SIR=SalS(Iir)
(3)
SVIS=SalS(Ivis)
(4)
W1=SIR/(SIR+SVIS+eps)
(5)
W2=1-W1
(6)
式中,SIR表示红外图像显著性值,SVIS表示可见光图像显著性值,W1表示红外图像权重,W2表示可见光图像权重,eps=10-7,如图2所示。

图2 权值估计示例
此外,为了更好地保留融合图像的细节纹理,采用结构张量损失(Jung等,2020)。首先,在源图像的每个邻域内,分别在水平与竖直方向上进行梯度求导,得到结构矩阵Tvis与Tir。然后在整幅图像范围内重复该操作,得到图像的结构张量矩阵。其次,为了有效地平衡两种结构张量,对二者的结构张量计算平均值,得到Ti,具体公式为
(7)
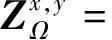

(8)
Ti=(Tvis+Tir)/2
(9)

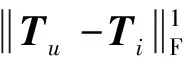
(10)
2 实验结果
2.1 实验设置
实验数据集来自TNO数据集(https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029)和RoadScene数据集(https://github.com/hanna-xu/RoadScene)。TNO数据集广泛应用于红外与可见光图像融合任务,素材采集于自然生活各个场景,该数据集作为主要训练集。TNO图像来源广泛,在TNO上进行实验能够确保本文方法的应用范围合理性,为了避免单一数据集的实验结果说服力不强,还采用RoadScene数据集作为泛化数据集,该数据集取材于道路、车辆等,是一个新颖的用于红外与可见光图像的数据集,素材来源于日常生活。这两种数据集涵盖了自然生活各领域。由于这两种数据集素材来源不尽相同,两类数据集共同使用能够保证模型对红外与可见光融合任务的适用性。为了避免同一完整数据集全部用来模型训练带来的泛化能力不强、模型可移植性低等问题,在数据集中选取一部分作为训练集,另一部分作为测试集,有效避免了单一数据集整体作为训练集导致模型过拟合及泛化性差等问题。实验从TNO数据集图像库中选择72对清晰的红外与可见图像,其中包括51对训练图像和21对测试图像。为了验证本文方法的泛化能力,采用21对RoadScene测试图像对网络进一步实验。本文方法使用PyTorch框架,并采用Adam优化器,学习率初始值设置为10-2,并随着迭代次数而衰减,最终降低为10-5。此外,将训练集中的51对源图像尺寸裁剪为256×256像素,batch_size设置为1,实验共训练800轮,并在每10轮保存一次模型。
2.2 实验结果
本文选取了TNO测试集中典型的21对红外与可见光图像对与RoadScene数据集中21对分别作为测试集进行对比分析,训练和测试的部分图像如图3所示。分别从两个数据集中各取出一幅图进行局部放大与伪彩展示分析,如图4和图5所示。图4中圈出位置行人处可以看到本文方法亮度较高,同时兼顾了背景信息的完整,图5中圈出的树干可以看出本文方法树干纹理细节较为清晰。从视觉上看,如图6所示,相对于Bayesian方法,例如行人、直升机等图像,可以明显看出融合图像亮度信息不够,DIDFuse方法视觉背景信息较暗,如森林、行人等图像背景基本看不清,RFN-Nest方法融合图像较为模糊,如雨伞的背景、椅子等物品已经不可见,U2Fusion图像背景细节不够明显,IVFusion由于手动设计融合策略导致融合结果失真严重,如吉普车、村庄、汽车等,MDlatLRR由于传统设计的局限性,不能充分吸收红外图像的亮度信息,导致融合图像亮度不高,融合图像不够真实,如直升机、汽车等图片,SEAFusion取得了较为理想的融合结果,但与本文方法相比细节纹理信息保留不够好,如吉普车背景的云彩已经消失,本文方法的融合图像视觉效果较好,亮度上有提升,图像细节纹理较好地进行了保留。

图3 训练和测试数据示例

图4 TNO数据集部分结果视觉对比

图5 RoadScene数据集部分结果视觉对比

图6 两个数据集中一些视觉结果实例
在TNO与RoadScene数据集均取21对红外与可见光图像作为测试图像,然后分别在两个数据集求21幅融合图像的各指标平均值,指标均值如表2所示,结果如图7和图8所示。可以看到,与其他9种方法相比,本文方法在4个评价指标中有3个为最优,另外一个次优,验证了本文方法的有效性。同时,在TNO和RoadScene数据集各取一幅融合图像进行详细展示,如图4和图5所示,取局部放大与伪彩展示,可以看出,本文融合方法在纹理细节、亮度、图像平滑度、结构相似度和信息保真度等方面均有不错效果,指标均值表明了本文方法的有效性,同时,在TNO和RoadScene数据集各取一幅融合图像进行详细展示,可以看出本文方法达到了较为理想的融合效果。
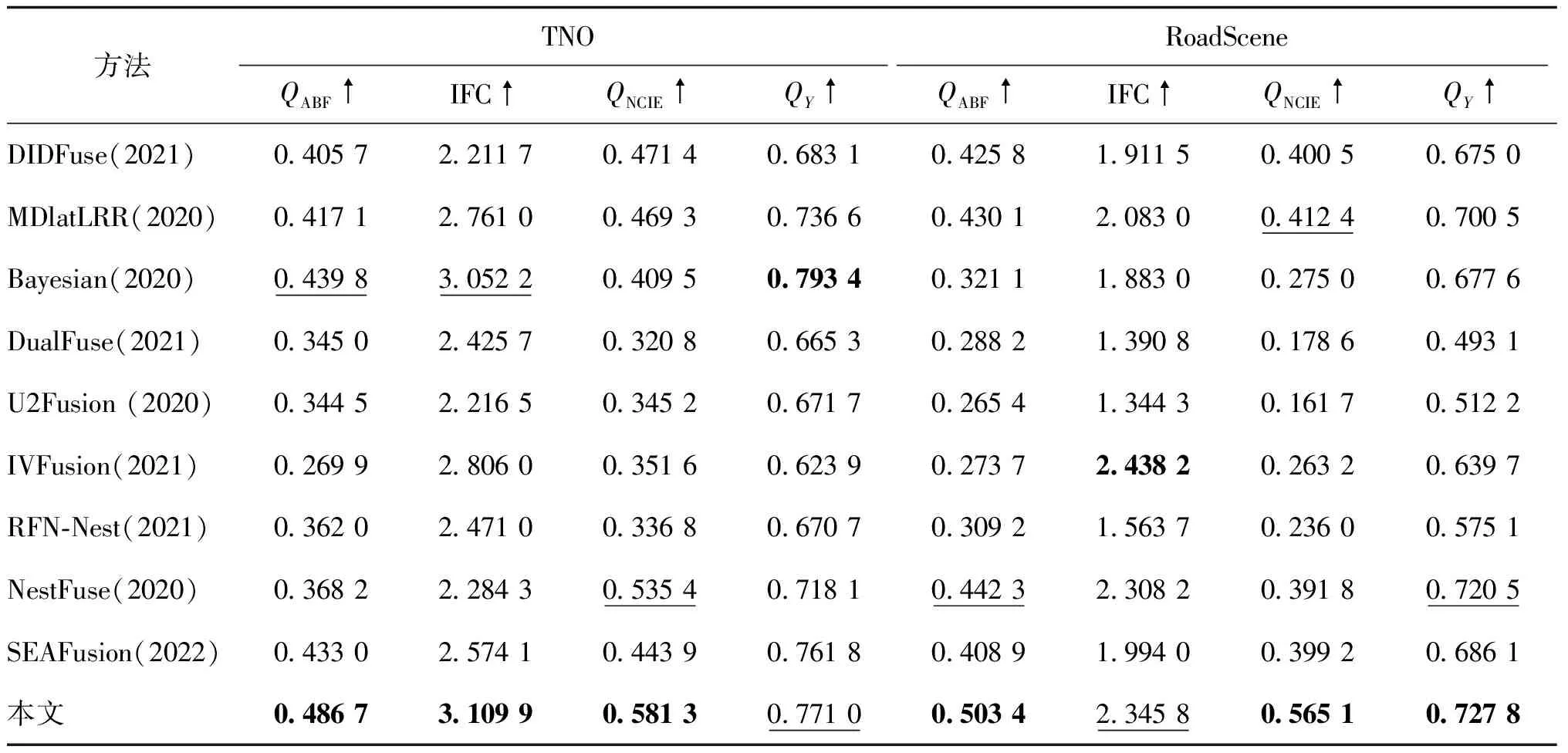
表2 TNO/RoadScene数据集不同融合方法的21对图像各指标平均值

图7 TNO数据集下的指标折线图
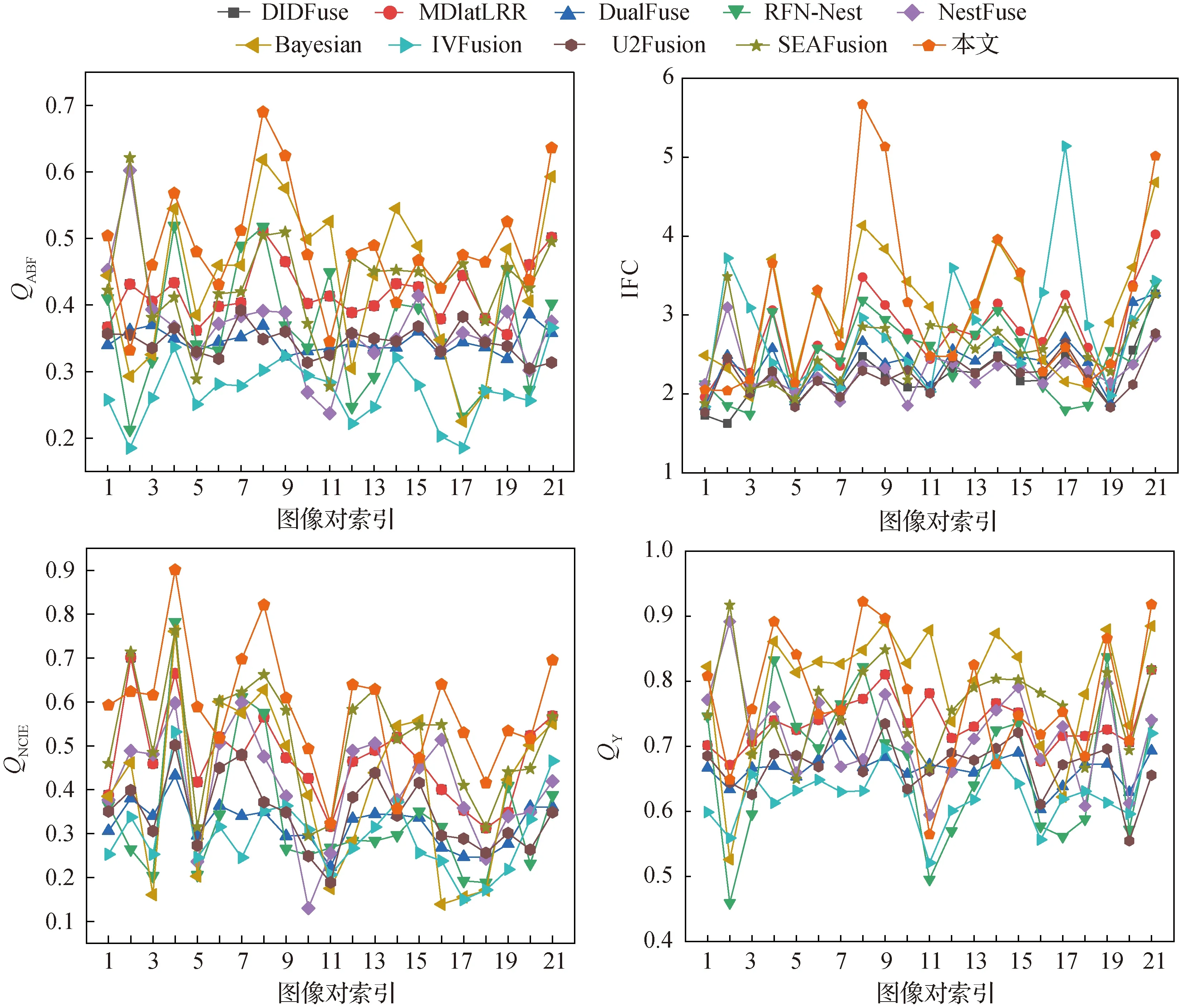
图8 RoadScene数据集下的指标折线图
2.3 讨论
为了说明本文融合方法的完备性,对损失函数中平衡因子λ做参数讨论,取不同值进行指标评价;同时对网络结构和损失函数进行消融分析,对网络结构中多尺度引导与无多尺度引导进行对比,说明本文方法引导的必要性,对亮度加权损失和结构张量损失分别进行消融实验,对比表明两类损失函数设计的有效性。
对损失函数表达式中λ做参数分析,结果如表3所示。可见,λ取1时结果较好。
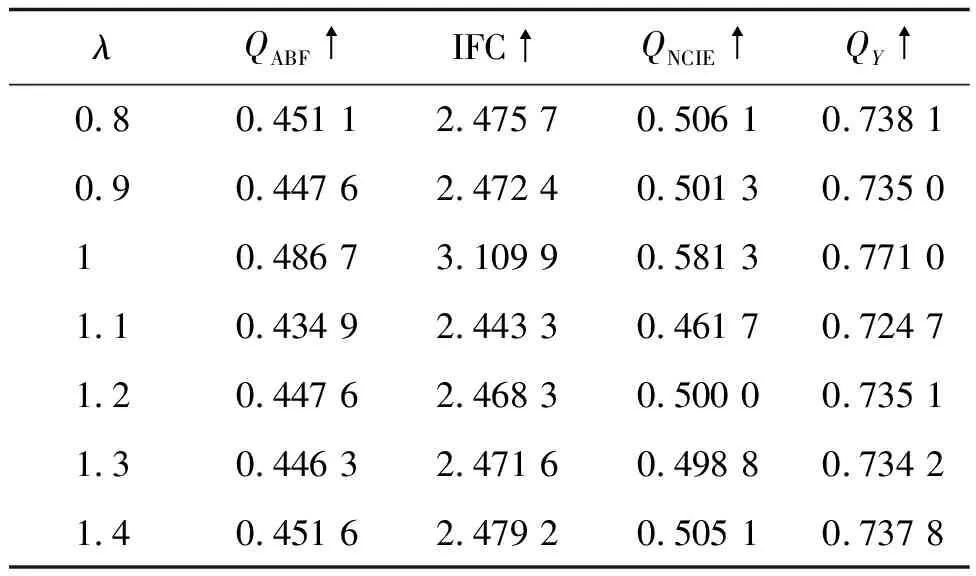
表3 TNO数据集下λ不同取值对应的指标均值
分别对网络结构中的引导和损失函数进行消融。对网络结构消融分析时,去除网络引导部分,单纯进行编解码器的图像融合;对损失函数消融时,分别对L1与L2消融,验证保证项与结构张量的有效性,消融实验结果如表4和表5所示。结果表明,本文方法中网络结构的多尺度引导实现了较为充分的信息交互,对于编码部分的信息及时加以引导,融入解码网络,对于融合图像起到了积极的作用;对于损失函数中亮度的加权,能够表明,本文方法对红外显著的提取有效约束了目标的显著性,对于融合图像的目标捕获起到促进作用,体现在视觉上,本文方法融合图像亮度较为突出;对于损失函数中结构张量的约束,本文方法在融合图像纹理细节上较为友好。通过主观和客观对比,融合图像背景较大保留,融合指标较为优越。本文方法从红外与可见光图像自身特点出发,对红外的亮度信息有效提取,对可见光纹理细节有效保留,在网络结构上,多尺度、多层次引导实现特征图尺寸变化以及特征信息有效融合,较好地实现了红外与可见光图像融合任务。

表4 TNO数据集下对结构消融分析

表5 TNO数据集下对损失消融分析
本文方法主要对红外与可见光图像融合做了分析,损失函数的设计对红外图像的亮度显著信息作为加权保真项,可见光图像较好的纹理信息作为正则项。然而,对其他多模态图像融合任务没有详细讨论,如遥感图像融合,但本文的网络结构原理依旧适用于该任务,因此,未来还将积极探索遥感图像融合,设计基于此的损失函数并优化网络结构。
3 结 论
针对传统图像融合方法中手工设计导致图像失真问题,针对现有深度学习方法中图像融合信息交互不充分问题,提出一种基于多尺度的细节保留与显著性检测的红外与可见光图像融合方法。此外,本文设计的多级引导结构不同于传统的编解码结构,对特征图进行多级融合与有效引导,从红外与可见光图像自身现实出发,本文方法设计的损失函数包括加权保真项和正则项,其中加权保真项对红外热显著信息有效提取,保证融合图像热目标不丢失,另一个损失通过结构张量对可见光细致的纹理进行保留,使得融合结果包含丰富的纹理细节信息。本文方法在两个数据集上进行了实验验证,从视觉效果和定量分析两方面证明了该方法的有效性。与其他红外与可见光算法相比,本文方法的融合图像在视觉保真度、亮度凸显等方面表现卓越,在有效亮度提取的前提下,还对图像纹理细节进行了保留,场景信息、纹理信息更为丰富。并通过实验验证了方法的有效性、可靠性和优越性。实验结果表明:1)本文方法采用多层次、宽领域和多尺度的网络结构,能够全方位捕获图像的关键信息,造成的信息丢失较小;2)对红外的亮度进行有效提取,有效针对有用信息进行加权;3)从人眼视觉出发,对图像纹理细节通过结构张量进行有效保存,使得融合图像更为真实,给人视觉上的舒适感。从视觉出发,能够主观看到本方法融合图像质量较高;从客观出发,与其他9种融合方法(包含传统方法3种,深度学习方法6种)进行对比,在指标评价上表明本文方法融合质量较好。
本文方法目前的实验数据仅限于红外与可见光图像,下一步的工作是优化目前的网络结构,使之能够自适应根据源图像不同特点提取不同的有效信息,适应其他的多模态融合任务,并使模型具有更强的泛化性与可移植性。在损失函数的设计上,不局限于红外与可见光图像,可用于其他多模态图像,例如遥感图像融合。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
软件(2020年3期)2020-04-20
摄影之友(影像视觉)(2018年12期)2019-01-28
制造技术与机床(2017年7期)2018-01-19
Coco薇(2017年8期)2017-08-03
西安工程大学学报(2016年6期)2017-01-15
系统工程与电子技术(2016年7期)2016-08-21
Coco薇(2015年5期)2016-03-29
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
智能系统学报(2015年4期)2015-12-27
