
医学图像融合方法综述
2023-02-18 03:06黄渝萍李伟生
中国图象图形学报 2023年1期
黄渝萍,李伟生
重庆邮电大学计算机科学与技术学院,重庆 400065
0 引 言
医学图像是临床诊断的重要依据,广泛应用于治疗规划、手术导航中。临床诊断的准确性需要同时提取多幅不同模态的医学图像信息来保证。因此,图像融合技术受到广泛关注。图像融合是计算机视觉和图像处理领域的一个热门课题,包括多聚焦图像融合(Zhang 等,2018)、多曝光图像融合(Zhang,2021)和多模态图像融合(Zhang 等,2021)等。而多模态医学图像融合(multimodal medical image fusion,MMIF)是多模态图像融合中的代表性融合场景。通过将不同模态医学图像中的互补信息整合到一幅图像中,帮助放射科或肿瘤医生等加快诊断过程,提高决策能力,降低储存成本(Rajalingam和 Priya,2018b)。同时,由于医疗保健行业的巨大进步,医学成像传感器也飞速发展,加大了医疗系统对图像融合的需求。
图像融合过程由预处理、图像配准、图像融合和性能评价4部分组成。在预处理阶段,识别出图像中的噪声和伪影并完全去除,获得高质量的医学图像(Zhao和Lu,2017)。然后,选取一幅参考图像,对剩余图像进行几何变换,使其与参考图像同步,获得配准后的待融合图像(El-Gamal等,2016),这是与图像融合直接相关的步骤,它纠正了输入图像之间的偏差,补偿了原始信号重建、平移、旋转和缩放过程中造成的变化,从根本上保证了图像融合的精度。在融合过程中,图像融合等级按照作用的层次分为像素级、特征级和决策级(Du 等,2016),如图1所示。像素级融合对图像像素进行综合分析,能够保持尽可能多的现场数据;特征级融合对图像特征进行综合分析,可以压缩信息使其具有良好的实时性;决策级融合对图像进行特征提取和特征分类,通过大量的决策系统对分类后的图像特征进行融合。
融合性能评价分为主观评价和客观评价。主观评价基于人眼视觉系统。在医疗领域中,通过观察图像的失真情况、空间细节、颜色和亮度等,或结合主观的标准化分数计算来判断融合质量是简单而可靠的。客观评价则通过一系列与人类视觉系统高度一致的指标来定量评估融合算法的性能。
如图2所示,自2000年起,针对图像融合的算法研究文献数量迅速增加。其中,医学领域融合算法的文献数量占比逐渐升高。随着该研究领域的逐渐成熟和图像处理领域的阶段性停滞,每2—3年会迎来一个小幅度的上升期。这样增长的背后有3个原因:1)医学图像数据库的逐渐丰富;2)图像与信号处理技术的进步;3)医学图像融合算法得到实际应用(如多模态医学图像一体机的发展)。在每一个历史性的发展阶段都会涌现一些关于医学图像融合技术的调查或评论性文章。James等人(2014)总结了医学图像融合技术中待解决的问题。其中包括:1)现阶段的融合算法创新性有限,大部分MMIF算法都是从已有图像融合研究中衍生出来的;2)图像之间物体配准的不准确与MMIF算法的特征级或决策级融合性能不佳密切相关,需要医学领域知识和算法洞察力来提高融合的准确性;3)由于像素强度异常、特征缺失、传感器误差、空间误差和图像间变异性的存在而导致的特征处理和提取算法的主要问题仍然是医学图像融合中的一个开放问题。El-Gamal等人(2016)预测了未来几年医学图像融合技术的发展趋势。张俊杰等人(2016)对特征级多模态医学图像融合技术的研究进展进行深度讨论。Meher等人(2019)展示了对基于区域的图像融合技术的相似比较。周涛等人(2021)对多尺度变换的像素级医学图像融合进行综述,阐述了多尺度变换图像融合的基本原理和框架。Azam等人(2022)对医学图像的原理和分类进行概括,并对不同融合技术的优缺点进行总结。

图2 以医学图像融合为主题的科学出版物(2000年—2022年第1季度)
与上述综述类文章相比,本文不仅对MMIF算法的文献进行比较与总结,还对不同疾病的MMIF研究进展进行了重点分析和总结,通过对比最新的MMIF方法的定性及定量指标,探索该课题的未来研究趋势,助力医疗领域新型成像传感器的发展。
1 医学图像模态
医学成像的研究目的在于借助各种科学技术可视化人体内部的结构和组织,为疾病诊断提供重要信息。不同的成像技术可以从不同方面互补地反映患者的信息,而图像融合技术可以将它们结合起来。医学图像是由能量和人体组织相互作用形成的。在医学领域中,成像技术主要分为利用电磁能成像和利用声能成像。利用声能成像是指利用超声波在不同介质中的传播速度不同来达到实时成像的效果,直接提供动态图像。而MMIF技术主要针对由电磁能成像技术形成的静态图像。如X射线计算机断层扫描成像(computed tomography,CT)、单光子发射型计算机断层成像(single photon emission computed tomography,SPECT)、正电子发射型断层成像(positron emission tomography,PET)和磁共振成像(magnetic resonance imaging,MRI)等。图3显示了基于电磁能成像技术各电磁波频谱上的可形成的医学图像。
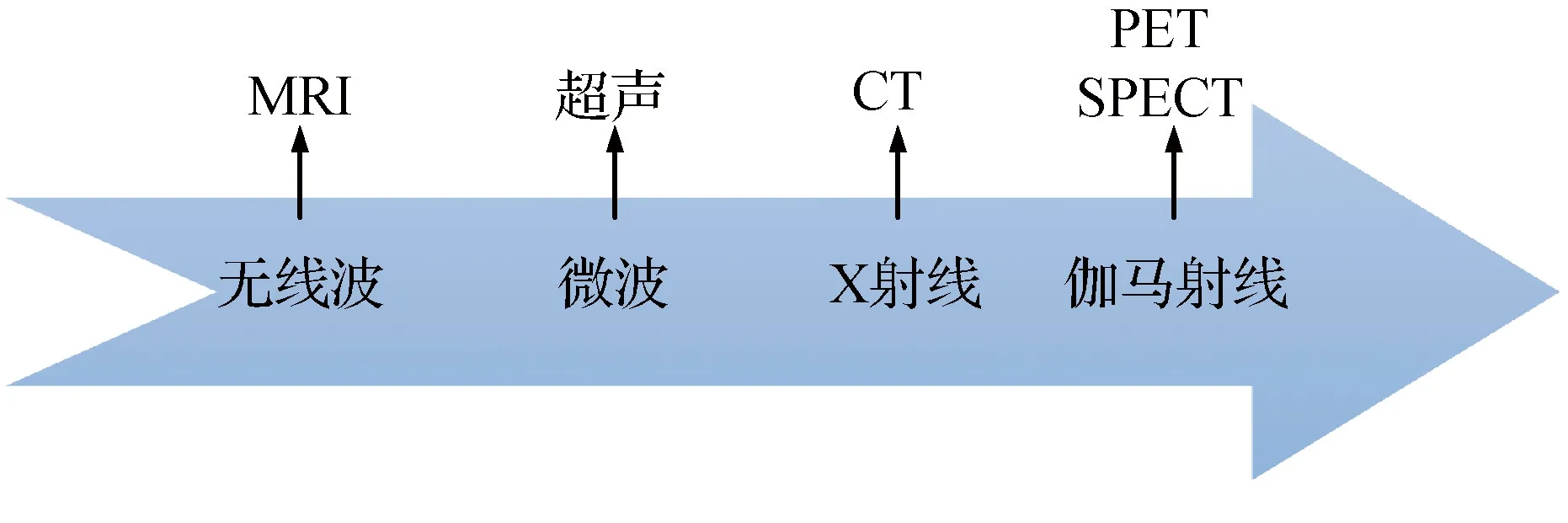
图3 各电磁波频谱上的可形成的医学图像
1.1 计算机扫描成像
1895年,W.K.Roentgen发现了X射线,人类历史上第一次实现用科学技术观察人体内部结构。X射线将3维目标投影在2维的检测平面上,但投影方向上信息相互重叠,成像的分辨率低,仅能区别密度差别很大的脏器。20世纪60年代,计算机断层扫描技术(CT)逐渐发展起来,并从根本上解决了上述问题。CT利用X射线对人体进行平移扫描,获取多个方向上的投影数据,然后用精确的数学公式重建出人体内部的剖面结构。而数字图像处理技术将感兴趣区域的细微灰度差变换为屏幕上人眼可分辨的灰度差,大幅提高了区分密度差异小的不同组织的能力,其灰度仅与组织的强度有关,与细胞的活性无关。CT图像的应用范围几乎涵盖了全身各个系统,特别是对于中枢神经系统、头颈部和呼吸系统病变的检出和诊断具有明显优势。对于心血管系统、生殖系统和骨骼肌肉系统病变也具有较高的诊断价值。但是,CT检查对某些病变的检出具有一定难度。例如,CT对骨骼肌肉系统中的骨骼敏感,但对软骨、关节盘和韧带等软组织的病变显示仍十分困难。
1.2 磁共振成像
磁共振成像(magnetic resonance imaging,MRI)利用与原子核共振波长相同的电磁波激发人体内部的原子核,使之处于受激的状态。原子核恢复到平衡态时会产生辐射,并携带核周围生化环境相关信息,它不仅可以显示解剖学形态的图像,还可以指示病理特征。据美国健康研究所(National Institute of Health,NIH)统计,现在全世界每年有6千多万人次接受MRI检查。MRI可以对人体所有器官成像,尤其是对大脑组织和脊髓的成像最为精细,在研究和临床上极有价值。如同CT图像,MRI图像也是数字化的模拟灰度图像,亦具有窗技术显示和能够进行各种图像后处理的特点。然而,MRI图像上的灰度并非表示组织和病变的密度,而是代表它们的信号强度,反应弛豫时间的长短。MRI检查对于癌症的诊断、治疗和病程跟踪非常有效,可以为手术和放射治疗精确定位肿瘤的位置、边界以及对周边组织浸润的情况。但是在临床应用中,MRI图像容易产生不同类型的伪影且有时不能完全消除,给图像解释带来困难,对某些系统疾病的检出和诊断的贡献有限,如MRI对于呼吸系统中大多数疾病诊断价值不高。
1.3 核医学成像
医学上放射性核素成像是将放射性核素标记在药物上,通过口服或注射方式引入人体内,检测体外该核素发射出来的能量形成图像。由于各脏器对同位素标记物的选择性吸收、正常组织与病变组织的吸收差异、代谢差异以及病变对标记物在体内循环产生影响等因素,使不同生理、病理的图像形成差异,故可以据此诊断疾病。临床应用的核素成像系统有两种,单光子发射型计算机断层成像(SPECT)和正电子发射型断层成像(PET),二者都用来测定人体各部位的生物化学和代谢过程。PET图像的成像质量更高,但其示踪剂较少,应用范围受到限制,而SPECT的示踪剂更易制作,可根据不同部位、不同症状选取合适的示踪剂进行成像。由于PET和SPECT图像的分辨率比较低,人们更强调其功能性研究。
1.4 融合模态
医学影像检查技术发展迅速,除了CT、MRI和核素显像,还有X射线、超声等常规成像技术。不同成像技术有各自优势和限度以及明确的范围。以脑部医学图像为例,CT获取的图像可以提供丰富的解剖细节,能够清晰分辨脑内颅骨、脑实质、脑脊液和非病理性钙化区域;MRI能够显示丰富的生理和生化信息,包括脑内神经、脑血管以及软组织;而PET/SPECT图像能够反映正常组织和病变组织对标记物的代谢情况以及脑部的血流信号。在实际的临床诊断中,对于某一系统疾病、某一类疾病通常需要综合应用几种成像技术才能满足诊断的需要。
图4是几种不同病例的多模态影像。图4(a)显示了生活中常见的一种脑变性疾病阿尔茨海默症,其早期症状表现为短期记忆障碍,随着时间推移逐渐出现语言障碍、生活无法自理等症状。针对该疾病的首选检查方法为MRI,其主要的影像依据是以海马为显著区域的脑萎缩,而导致脑萎缩的原因众多,如结合PET图像,则可明显观察到海马区域的血流信号减少、代谢降低等,从而确诊阿尔兹海默症。图4(b)显示了脑膜瘤的医学影像。CT可以扫出颅内的高密度区域(多为肿瘤区)以及其边界,肿瘤密度是否均匀等。而MRI图像可显示出肿瘤内是否存在条状流空血管、肿瘤内部信号是否均匀,亦可显示由脑膜瘤所致的骨改变。当脑膜瘤发生在功能区时,可有不同程度的神经性功能障碍,需结合PET或SPECT图像联合诊断。图4(c)为Ⅳ级星形细胞肿瘤患者的医学影像,MRI图像可体现其占位效应,瘤内坏死或出血以及微血管的密度和通透性,有助于评估肿瘤的病理分级。SPECT图像可标记其葡萄糖代谢情况,可对其进行良、恶性肿瘤的鉴定。
基于实际的临床需求和应用价值,可以将主流的融合模态归纳为灰度图像的融合以及灰度与伪彩图像的融合两种。其中,灰度图像的融合主要涉及CT和MRI图像,灰度与伪彩图像的融合主要涉及CT、MRI、PET、SPECT 4种模态。融合示例如图5所示。
2 融合方法
2.1 传统融合方法
传统MMIF方法着重处理源图像中的噪声、纹理、梯度、细节和颜色等信息,针对不同需求设计分解或重构策略和融合规则。这些方法按照对像素的处理方式和作用域的不同可分为基于空间域的融合方法、基于频率域的融合方法和基于梯度域的融合方法3类。
2.1.1 基于空间域的MMIF方法
空间域技术利用基础的像素级策略,对图像中的像元值起作用,得到的图像表现出更少的空间失真和较低的信噪比。基于空间域的方法主要包括简单最小/最大值、独立分量分析(independent component analysis,ICA)、主成分分析(principal component analysis,PCA)、加权平均、简单平均、模糊逻辑(fuzzy logic,FL)和云模型(cloud model,CM)等。其中,简单最小/最大值、简单平均方法相对原始,计算复杂度低,可以快速实现图像融合,然而融合效果并不理想。ICA为了区分待融合图像中的有用信息和无用信息,在ICA域对源图像进行分解,并将其独立分量系数进行融合。而PCA则按照信息量对各个成分进行排序,将彼此不相关的各主成分分量进行筛选,丢弃信息量少的分量。模糊逻辑通常应用在融合规则的构造中,利用模糊隶属函数对图像内部的不确定性进行描述,从而对图像系数进行分配。云模型具有考虑随机性和模糊性的优点,利用逆向云发生器自适应地生成点云模型,计算其隶属度,找到合适的云模型构建融合规则。
从多组数据中融合信息以提取一组最具特征的数据是融合任务的重点。而ICA提供一个简单的生成模型,对分解后的各个分量独立性进行度量,使多个模态充分交互以估计所有模态的潜在特征。Akhonda等人(2021)讨论了ICA在多集融合中的两个重要扩展,即联合ICA(joint independent component analysis,JICA)以及多集典型相关分析和联合ICA技术,两种方法都假设相同的混合矩阵,强调跨多个数据集通用的组件,提出一个通用的框架,使用ICA的不相交子空间分析,不仅识别和提取多个数据集的共同成分,还可以提取不同的成分。该方法的一个关键组成部分是在后续分析之前识别这些子空间并分离它们,这有助于建立更好的模型匹配,并在算法和顺序选择方面提供了灵活性。Faragallah等人(2021)提出一种基于主成分分析和奇异值分解(singular value decomposition,SVD)的多模态MMIF方法。该算法基于PCA与SVD的结合,将CT和MRI两种成像模式的所有相关信息整合在一起作为融合CT和MRI图像的预处理手段,可以减少融合过程的处理时间和对内存的需求,且图像质量与其他算法相同。Gao等人(2021)采用基于图形的视觉显著性算法(graph-based visual saliency,GBVS)计算两个配准源图像的视觉显著性,在非下采样剪切波变换(non-subsampled shearlet transform,NSST)域内对源图像进行分解,得到低频和高频子带。对于低频子带,以局部能量和GBVS图为输入,利用模糊逻辑系统分别得到融合后低频子带的权值。此外,利用粒子群算法优化模糊逻辑系统的隶属度函数,使其更好地适应于医学图像和特征提取。Liu等人(2015b)提出一种基于改进和修正的拉普拉斯矩阵的像素级融合方法,利用局部拉普拉斯滤波对解剖图像和功能图像进行处理,然后通过最大化局部能量对子图像进行融合,来克服阻塞效应和伪影。Li等人(2019b)提出一种基于自适应云模型(adaptive cloud model,ACM)的MMIF方法,利用ACM融合经过局部拉普拉斯金字塔分解后的近似图像,使用拟合曲线通过捕获拟合曲线的谷点来表示图像细节信息。
2.1.2 基于频率域的MMIF方法
在频域领域中,原始的手段是通过计算傅里叶变换将输入的图像从空域转换为频域,然后对转换后的图像应用融合算法,再进行傅里叶逆变换,得到最终的融合图像。常见的变换域中的融合算法有基于金字塔、基于小波和基于多尺度几何变换的融合算法。
金字塔变换是最原始的图像分解手段之一,分解过程由连续滤波和下采样组成,产生一组类似金字塔结构的图像,过程如图6所示。首先将源图像分解为塔形结构的子图,随着分解层数的增加,子图尺寸逐渐减小,再将每一层的分解数据分别融合,最后重构成融合图像。在MMIF算法中,最流行的金字塔分解方法包括拉普拉斯金字塔(Laplacian pyramids,LP)、梯度金字塔(gradient pyramids,GP)和形态金字塔(morphological pyramids,MP)等。这些方法在面对有噪声干扰的图像时,容易产生块效应。形态金字塔边缘呈现的效率不高,而梯度金字塔会加入不需要的伪影(Lewis等,2007)。基于小波变换的融合算法成功克服了这些缺点。
在20世纪90年代中期,出现了第1种基于小波的图像融合方法,并且证明其性能优于金字塔变换,其过程如图7所示。处理的基本步骤如下:1)对已配准的源图像进行小波分解,相当于使用一组高低通滤波器进行滤波,分离出高频信息和低频信息;2)对每层分解得到的高频和低频信息依据得到的信息特点采取不同的融合策略,在各自的变换域进行特征信息抽取,分别进行融合;3)采用步骤1)小波变换的重构算法对处理后的小波系数进行反变换重建图像,即可得到融合图像。
小波域通过将图像进行分解来保存图像信息,其系数对应源图像中不同的图像特征(Pajares和 de la Cruz,2004)。由于小波分解的近似图像包含了图像的绝大部分能量,且小波系数的均值基本为零,因此,基于小波变换的MMIF算法可以保留源图像的基本亮度和色调(周朋 等,2006)。Shabanzade和Ghassemian(2017)为了解决小波变换在表示方向性特征时缺乏位移不变性的缺点(Dogra等,2017),提出了使用平稳小波变换(stationary wavelet transform,SWT)进行MRI与PET融合的算法框架,将非下采样轮廓波变换与SWT结合以发挥SWT的优势。Daniel(2018)利用同态小波(homomorphic wavelet,HW)对源图像进行多级分解,并提出了针对解剖图像和功能图像的最佳比例系数。Prakash等人(2019)利用双正交小波的线性相位特性来完成MMIF中的图像分解与重构。Ashwanth和Swamy(2020)利用散小波变换(discrete wavelet transform,DWT)和SWT对源图像进行多级分解,针对分解后的子带图像分别采用基于边缘和基于能量的融合规则进行特征融合。在MMIF中,小波变换的有方向性得到充分利用,且图像的频率信息利用率很高,但是小波变换本身不具有方向选择性和平移不变性,因此通常与其他频域变换方法结合来克服其局限性。而多尺度几何变换是通过定义特定的小波函数规则或在小波变换内进行特殊处理来克服这些限制。Bhateja等人(2015)提出小波变换和几何变换域中的脊波域(ridgelet domain,RD)具有一定的互补性。小波变换在边缘特征提取上能力较弱,而脊波却能很好地捕捉边缘信息。张鑫和陈伟斌(2014)提出基于曲线波变换(curvelet transform,CVT)的区域方差加权和条件加权融合算法并应用于CT和MRI图像融合。Mathiyalagan(2018)提出一种基于曲线波变换的融合算法,对低通子带图像进行小波变换,对高通子带图像进行脊波变换,利用子带图像的最大局部能量融合PET和MRI。Do和Vetterli(2005)提出轮廓波变换(contourlet transform,CRT)。CRT是利用拉普拉斯塔形分解和方向滤波器组实现的多分辨的、局域的、方向的图像表示方法。基于CRT的MMIF算法可以保持灰度图像的局部亮度,减少融合图像的失真。而CRT的平移可变性和方向混叠等缺陷促成了剪切波变换(shearlet transform,ST)的出现(Guo和 Labate,2007)。为了解决ST出现的伪吉布斯现象,Easley等人(2008)提出非下采样剪切波变换(non-subsampled shearlet transform,NSST),利用卷积代替下采样。目前,非下采样剪切波已经成为热门的图像分解和重构工具之一。
2.2 深度学习融合方法
深度学习(deep learning,DL)在计算机视觉领域取得了巨大成就,在图像融合、语义分割和图像分类等视觉任务中都有卓越表现。DL应用于图像融合的动机有两点(Liu 等,2018)。一是为了改进传统方法中多尺度和空间变换能力的局限性,DL可以提供新的特征表示方法;二是传统方法的融合策略设计面临发展的瓶颈期,DL能够更有效地映射输入与输出之间的相关性。深度学习领域内的融合方法主要包括卷积神经网络(convolutional Neural Networks,CNN)、生成对抗网络(generative adversarial networks,GAN)、卷积稀疏编码(convolution sparse coding,CSC)、自动编码器(auto encoders,AE)、循环神经网络(recurrent neural networks,RNN)和受限玻尔兹曼机(restricted Boltzmann machine,RBM)等。其中,以基于CNN和GAN的MMIF方法为主。
CNN可以有效处理输入图像中邻域内的空间和结构信息。CNN由一系列的卷积层、池化层和全连接层组成。卷积层和池化层可以提取源图像中的特征,全连接层完成从特征到最终输出的映射。图像融合在CNN中被视为一个分类问题,对应其特征提取、特征选择和输出预测的过程,融合任务则面对的是图像变换、活动水平测量和融合规则的设计。Liu等人(2017)首次将用于多聚焦图像融合的CNN扩展到MMIF中,其中,图像变换利用了频域的拉普拉斯金字塔方法进行多尺度的分解,图像的活动水平测量利用CNN生成的权重图来计算。不同于其他数据类型的丰富储备,医学图像常常面临着小样本的限制,而CNN可以从小样本的医学图像数据集中进行学习,并且不容易产生过拟合的模型。Hermessi等人(2018)提出了一种基于多通道CNN的MRI和CT图像的融合方法,先采用非下采样剪切波对图像进行高频和低频的子带分解,然后利用多通道CNN完成对高频子带图像的特征提取。Xia等人(2018)提出一种深度堆叠的CNN融合方法,该方法去除子采样层以获得与输入图像尺寸相同的输出大小,虽然用整个数据集作为输入所训练的网络可能忽略了模态之间的局部相似性,但该文献表明算法的融合能力受训练数据量的影响可以通过增加训练数据量来防止过拟合。Lahoud和Süsstrunk(2019)提出一种基于CNN的零学习快速融合算法,不需要对特定模态的数据集进行预先训练,对各种模态的输入图像都能够提供有效融合。该算法通过充分利用已经训练好的网络来检测图像中的显著区域,并提取描述这些区域的深度特征图。通过比较这些特征映射,生成融合权重来合并源图像。Wang等人(2020)在一个预先训练好的CNN模型下,采用对比金字塔分解源图像。Xu和Ma(2021)提出一种无监督增强融合模型,通过一个转换网络完成灰度图像到伪彩图像的映射,利用编码解码器提取出具有独特信息的通道作为融合网络的信息约束。
与CNN不同,GAN网络通过对抗性学习机制对医学图像中的显著性信息进行建模。GAN是具有两个多层网络的生成模型,第1个网络是用来生成伪数据的生成器,第2个网络是用来将图像进行真实数据和伪数据分类的判别器。基于反向传播的训练模式提高了GAN区分真实数据和生成数据的能力,尽管GAN在MMIF中应用不如CNN广泛,但具有深度研究的潜力。Tang等人(2019)通过GAN融合了绿色荧光蛋白(green fluorescent protein,GFP)和相位对比图(phase-contrast image,PC)两种图像,利用生成器与鉴别器之间的对抗博弈,提取GFP图像的功能信息,同时提取PC图像的结构信息,并且提高融合图像与源图像之间的整体相似性。Xu等人(2020)使用有密集连接的卷积层替换生成器中的U-Net,因为密集连接可以加强层之间特征图的传递,使特征图的利用过程更加高效。移除池化层后,没有了大步长的卷积核下采样造成的模糊,网络输出的融合图像更加清晰,并且判别器的输入不再是图像梯度,而是图像本身。对于生成器中不同分辨率源图像的输入,不再对低分辨率源图像进行上采样,而是使用反卷积层来学习从低分辨率到高分辨率的映射。Zhao等人(2021)构建了一个基于密集块和编码解码器的生成模块以及鉴别模块组成的GAN。并且在生成器的构造中,灵活设计了特征融合规则,扩大了算法的应用范围。
卷积稀疏编码(convolution sparse coding,CSC)起源于反卷积网络,该技术的主要目标是在稀疏性约束下实现图像的卷积分解。输入图像的多阶段特征表示是通过发展这种分解的层次结构来从反卷积网络中学习的。然后,利用这些多重分解层次对输入图像进行分层重构(Zeiler等,2010)。Liu等人(2015a)通过融合PET/MRI的感兴趣区域(region of interest,ROI)来研究阿尔茨海默病的进展。Shi 等人(2017)通过使用堆叠去噪和稀疏自动编码器(denoising and sparse auto-encoder,DSAE)融合MRI特征来判断阿尔茨海默症的发展程度。Islam等人(2019)比较了通过融合MRI/CT学习的SEA(stacked auto-encoder)的分类准确性,并基于单一模式,取得了更好的性能。循环神经网络(recurrent neural network,RNN)的主要应用领域是语音识别和文本分析,Chen等人(2018)融合了CNN和RNN结构,利用RNN从MRI中提取特征,根据上下文信息,利用全卷积网络推断病变的概率。受限玻尔兹曼机(restricted Boltzmann machine,RBM)是玻尔兹曼机(Boltzmann machine,BM)的一种变体,RBM是由对称连接的可见层和隐藏层组成的概率性、生成性、随机性和双向图形模型,动机是从隐藏层的向后传递中生成输入,并估计原始输入的概率分布。Suk等人(2014)使用深度玻尔兹曼机(deep Boltzmann machine,DBM)进行深度特征融合,从PET和MRI中提取层次特征以提供阿尔茨海默症的计算机诊断辅助,但由于融合概念的动机不足,在这一背景下开展的融合工作较少。
3 相关数据集及评价指标
3.1 多模态医学图像数据集
MMIF任务使用的数据需要通过配准注册,因此多数研究人员倾向于使用公开的免费数据集。
3.1.1 OASIS数据集

3.1.2 TCIA数据集
肿瘤免疫图谱数据库(the cancer immunome atlas,TCIA)提供了20个癌种的免疫数据分析。肿瘤免疫图谱数据库由美国国家癌症研究所(National Cancer Institute,NCI)癌症影像计划资助,合同由美国阿肯色大学医学科学院管理。TCIA分别对每个病人进行分析,数据也提供下载,DICOM(digital imaging and communications in medicine)是TCIA用于图像存储的主要文件格式。网站还提供与图像相关的支持数据,如患者结果、治疗细节、基因组学、病理学和专家分析。大多数数据以DICOM格式存储的CT、MRI和核医学(例如PET)图像为主,也提供或链接其他类型的支持数据,以增强研究效用。网页中可以看到患者的ID、疾病、性别和年龄信息。该数据库还提供了总共52个解剖器官的图像,如乳房、胸部、大脑和结肠。
3.1.3 AANLIB数据集
美国哈佛医学院提供了全脑图谱的脑图像数据集(the whole brain atlas,AANLIB),该数据集是在线公共访问的,AANLIB数据集主要分为基于正常和病变的脑图像。正常的脑图像是2维或3维的,而病变图像则进一步分为脑下疾病,包括脑卒中和肿瘤、退行性和感染性疾病,以及许多其他脑相关疾病。这个数据库中的所有图像都是GIF文件格式,易于使用。AANLIB数据库专注于大脑图像,并包含MRI、CT、PET和SPECT等成像方式。针对MRI图像,AANLIB数据集提供了T1和T2加权的图像,并且在网页中可直接查看PET和MRI的叠加图像。同一单元的不同模态病例图像均已经过配准,是目前MMIF使用的最广泛的数据集。
3.1.4 ANDI数据集
阿尔茨海默症神经影像数据(the Alzheimer’s disease neuroimaging initiative,ADNI)研究的目标是使用生物标志物以及临床措施来跟踪疾病的进展,以评估疾病变化过程中的大脑结构和功能。ADNI研究人员生成的所有数据都输入到美国南加州大学神经影像实验室的数据存储库中。全球的研究人员可以提交在线数据访问请求,并且通常在提交请求几天后即可开始使用ADNI数据,包括认知/神经心理学、图像、生物流体和遗传数据集。ADNI主要针对正常衰老、早期轻度认知障碍和阿尔兹海默症的医学数据,其中包括MRI、CT和PET 共3种医学影像。
3.1.5 JIC数据库
英国约翰英尼斯中心(John Innes Centre,JIC)是一个独立的国际植物科学、遗传学和微生物学研究中心。该研究中心将细胞生物学、化学、遗传学和分子生物学等学科作为主要研究内容。在细胞和分子生物学中,GFP图像暴露在蓝—紫外光下时显示出明亮的绿色荧光,并提供了与生物活细胞中的分子分布相关的功能信息。然而,GFP图像的空间分辨率较低,导致细胞缺乏特定的结构细节。PC图像通过将透明标本的光相位移转换为图像的振幅或对比度的变化来可视化相位差,显示了具有高空间分辨率的结构信息,如细胞核和线粒体。GFP和PC的融合图像可以同时显示相关生物活细胞的分子分布和结构信息中的细胞核和线粒体。在近几年的图像融合文献中,针对医学图像的融合算法也常常在该数据集上进行验证。
上述5个多模态医学图像数据集的主要信息如表1所示。

表1 多模态数据库比较
3.2 评价指标
融合图像的质量需要从主观定性和客观定量两方面评价,目前没有统一的评价标准。在定性评价中,根据每个算法的可视化结果,对其相关区域进行突出显示以反映差异,这种评价方法相对主观,主要基于人眼视觉观察。对于定量评价,根据不同的方法特征和融合场景,选择不同的客观指标。目前已有数十个评价指标,例如结构相似性、空间频率和平均梯度等。图像融合的度量指标可分为4种类型,即基于信息理论的指标、基于图像特征的指标、基于图像相似性的指标和基于人类视觉感知的指标(Liu等,2012b)。
3.2.1 基于信息理论的指标
1)交叉熵(cross entropy,CE)。CE(Bulanon 等,2009)表达的是融合图像与两幅源图像信息的差异度,一般是大于0的数,其定义为
(1)
式中,CEX,F表示计算图像X与融合图像F之间的交叉熵。X代表源图像A或B,CEX,F的计算定义为
(2)
式中,hX(i)代表图像的归一化直方图。较小的CE值意味着融合图像与源图像具有相当的相似性,表明融合图像具有良好的性能。
2)熵(entropy,EN)。EN(Roberts等,2008)测量融合图像中包含的信息,其定义为
(3)
式中,L代表灰度级的数量,pl表示融合图像中相应灰度级的归一化直方图。较大的EN值表示更好的融合表现。
3)互信息(mutual information,MI)。MI(Singh和Khare,2014)测量从源图像传输到融合图像中的信息量,其定义为
MI=MIA,F+MIB,F
(4)
其中,MIA,F和MIB,F表示源图像A和B向融合图像中传输的信息量。MIX,F的定义为
(5)
式中,pX(x)和pF(f)分别代表源图像X和融合图像F的边缘直方图。pX,F(x,f)为源图像X和融合图像F的联合直方图。MI的值越大,代表越多的源图像信息传输到融合图像中,同时说明融合性能越好。
4)峰值信噪比(peak signal-to-noise ratio,PSNR)。PSNR(Jagalingam和Hegde,2015)表示融合图像中的峰值功率与噪声功率的比值,可以测量图像融合过程中的失真。其定义为
(6)
式中,r为融合图像的峰值,MSE为均方误差,其计算式为
(7)
(8)
PSNR值较大,表示融合后的图像更接近源图像,失真程度较小。因此,PSNR值越大,融合性能就越好。
5)非线性相关信息熵(nonlinear correlation information entropy,NCIE)。NCIE(Wang 等,2008)测量源图像A、B与融合图像F之间的非线性相关性。首先,基于源图像与融合图像之间的非线性相关系数(nonlinear correlation coefficient,NCC)(Wang 等,2005),构造一个非线性相关矩阵R,具体为
(9)
利用R计算NCIE值,其值为
(10)
式中,λi是矩阵R的特征值。NCIE的取值范围为封闭区间[0,1],其中,0表示最小非线性相关,1表示最大非线性相关。
6)空域和光谱信息熵(spatial-spectral entropy based quality,SSEQ)。SSEQ(Liu 等,2014)在图像失真类型未知的情况下衡量融合图像在空域信息和光谱信息两方面的失真程度。其定义为
SSEQ=libsvm(mean(Sc),skew(S),
mean(Fc),skew(F))
(11)
式中,S和Sc分别表示局部空域特征和池化处理后的空域特征。F和Fc分别表示局部光谱特征和池化处理后的光谱特征。libsvm是一个支持向量机库,mean指计算数据均值,skew指计算数据的偏斜度。SSEQ值越小,融合图像的空域信息和光谱信息保留越好。
7)基于色调映射(tone mapped image quality index, TMQI)。TMQI(Yeganeh 和 Wang,2013)度量融合图像相比于输入图像在亮度信息和对比度信息两方面的丢失程度。其定义为
TMQI(IR,IF)=aTα+(1-a)Mβ
(12)
式中,IR为输入的源图像,IF为融合图像,T为结构保真度,M为图像的统计特性,常数的取值为a=0.801 2,α=0.304 6,β=0.708 8。MQI值越大,表示其保留信息的能力越好。
8)归一化的加权边缘信息(normalized weighted edge information,QAB/F)。QAB/F(Sengupta 等,2020)是一种基于分数阶微分、逻辑函数的融合图像边缘信息的度量指标。利用3个特征几乎相同的S型函数,以边缘强度和方向强度作为输入,估计归一化的加权融合度量。其定义为
QAB/F=
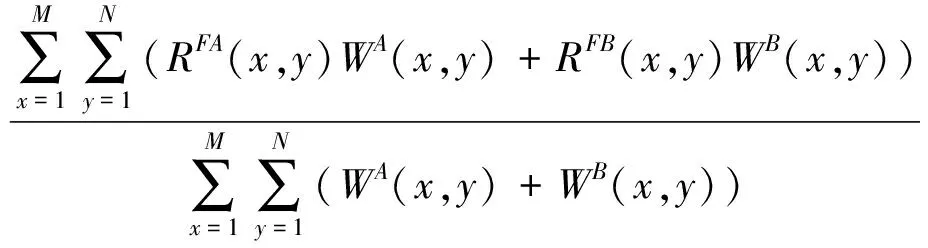
(13)
式中,A和B为源图像,F为融合图像。WA(x,y)和WB(x,y)分别为相对强度值RFA(x,y)和RFB(x,y)的权重,M和N为图像尺寸。QAB/F值的典型范围是从0到1。较低的值即接近于0对应较差的融合算法,而较高的值即接近于1表示更好的融合算法。
9)Arimoto熵度量(metric based on Arimoto entropy,AEN)。AEN(Li 等,2019a)是香农熵的一种推广,基于Arimoto熵的性质,测量融合图像中包含的来自两个输入图像的信息量。其定义为
AEN(A,B;F)=Iα(F,A)+Iα(F,B)
(14)
(15)
式中,X代表源图像A和B,Iα(F,X)表示F与X之间的联合Arimoto熵。该值与融合结果的主观效果相关,其值越大,融合性能越好。
10)梯度—强度混合信息指数(gradient-intensity mixed information index,GIMI)。GIMI(Wang 等,2018)是一种基于图像强度互信息(MI)的度量指标。GIMI指数将梯度与强度结合在一起,以捕获两个体积之间的空间相似性,其中都涉及强度分布、类别和边界信息。其定义为
(16)
式中,Hig(A,F)为源图像A和融合图像F之间的联合熵,Hig(B,F)为源图像B和融合图像F之间的联合熵。该值越高,说明其融合效果越好。
3.2.2 基于图像特征的指标
1)平均梯度(average gradien,AG)。AG(Cui 等,2015)能够测量融合图像的梯度信息,并表示其细节和纹理。其定义为
(17)

2)边缘强度(edge intensity,EI)。EI(Rajalingam 和Priya,2018a)测量图像的边缘强度信息。EI值越高,表示图像越清晰,图像质量越高。EI可以使用Sobel算子(Vincent和 Folorunso,2009)进行计算,其定义为
(18)


ESM=

(19)

4)标准偏差(standard deviation,SD)。SD(Rao,1997)反映了融合图像的分布和对比度。其定义为
(20)
式中,μ表示融合图像的平均值。人类的视觉系统对于对比度很敏感,因此高对比度图像中的区域总是能吸引人类的注意。由于融合图像的高对比度导致SD值较大,因此SD越大,说明融合图像具有良好的视觉效果。
5)空间频率(spatial frequency,SF)。SF(Eskicioglu和 Fisher,1995)可以测量图像的梯度分布,从而揭示图像的细节和纹理。其定义为
(21)

6)自然图像质量评价指标(natural image quality evaluator,NIQE)。NIQE(Mittal 等,2013)从自然图像库提取特征,再利用多元高斯模型对这些特征进行建模以衡量融合图像在多元分布上的差异。其定义为
NIQE=

(22)
式中,μF和μN分别代表融合图像和自然图像的高斯模型均值。covF和covN分别表示融合图像和自然图像的高斯模型协方差。NIQE值越小,表示其分布差异越小,融合效果越好。
7)基于相位一致性和标准差的联合度量(joint measurement based on phase consistency and standard deviation,QPSD)。QPSD(Tang 等,2018)结合了一致性度量和标准差,提取图像的显著性特征来度量融合图像的视觉质量。其定义为
QPSD=a(QP)b+(1-a)(QSD)c
(23)
式中,QP表示相位一致性度量,QSD表示标准差。a,b,c用来调整两者之间的相关性。QPSD值越大,说明算法的融合性能越好。
3.2.3 基于图像相似性的指标
1)结构相似性度量(structural similarity index measure,SSIM)。SSIM(Wang 等,2004)用于建模图像的丢失和失真程度,从而重新反映图像之间的结构相似性。SSIM由3部分组成,即相关性损失、亮度和对比度失真。源图像X与融合图像F之间的SSIM值定义为这3部分的乘积,其值具体为


(24)
式中,x和f分别表示滑动窗口中源图像和融合图像的图像块。另外,σx,f是源图像和融合图像的协方差,σx和σf表示标准差,μx和μf分别为源图像和融合图像的平均值。C1,C2,C3是当分母非常接近于零时用来避免不稳定性的参数。融合图像与两个源图像之间的结构相似性SSIM定义为
SSIM=SSIMA,F+SSIMB,F
(25)
SSIM值越大,说明融合性能越好,最优值为1。
2)杨氏度量(Yang’s metric,QY)。QY(Li等,2008)是一种基于SSIM的融合质量度量指标,表示来自两个源图像的融合图像F中保留的结构信息的量。其定义为
QY=

(26)
式中,w是一个局部窗口,而λ(w)定义为
(27)
式中,s是窗口w内图像方差的局部度量。QY值越大,说明融合图像中保留的源图像信息越多,从而说明融合性能越好,QY的最大值为1。
3)特征相似性度量(feature similarity index mersure,FSIM)。FSIM(Zhang 等,2011)通过使用相位一致性特征(phase comgruency,PhC)和梯度幅值(gradient magnitude,GM)两个特征进行质量评价。PhC刻画图像局部结构,GM计算图像梯度特征,两者互为补充。其定义为
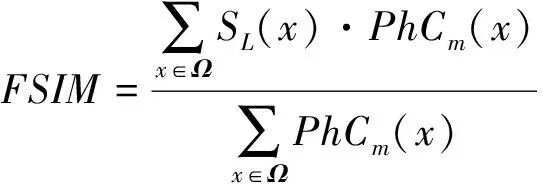

(28)
式中,Ω是整个图像像素空间,PhCm(x)=max(PhC1(x),PhC2(x))。FSIM值越大,则融合图像和输入图像越相似,且融合质量越高。
4)梯度相似性(gradient similarity measure,GSM)。GSM(Liu等,2012a)用于衡量融合图像与输入图像梯度信息之间的相似程度。其定义为
(29)
式中,C4=10-5,gF和gX分别为融合图像F和输入图像X的中心像素梯度值。
5)多尺度加权融合质量度量(multi-scale weighted fusion quality index,MS-QW)。MS-QW(Martinez 等,2019)用于评估融合图像的保真度,由多尺度计算和结构相似性评分组成。其定义为
(30)
式中,L为尺度总数,Il表示源图像在尺度l上的多值图。QW计算源图像与融合图之间的全局多尺度融合度量。其定义为
(31)
式中,λn(w)为局部权值,n为源图像数量。MS-QW值越靠近1,说明融合性能越好。
3.2.4 基于人类视觉感知的指标
1)人类视觉感知(human visual perception,CB)。CB(Chen 和 Blum 等,2009)主要衡量人类视觉系统中主要特征的相似性。其定义为

βB(i,j)WB,F(i,j))
(32)
式中,WA,F(i,j)和WB,F(i,j)表示从源图像转换到融合图像的对比度,βA和βB分别为WA,F(i,j)和WB,F(i,j)的显著性映射。CB取值范围为[0,1],CB值越大,说明融合图像中保留的源图像信息越多,从而说明融合性能越好。
2)视觉信息保真度(visual information fidelity,VIF)。VIF(Han 等,2013)是一种基于视觉信息保真度的图像质量评价指标。VIF模拟了人类视觉原理,取得了较高的评价精度。其定义为


(33)
式中,FVID是扭曲的融合视觉信息,FVIND是非扭曲的融合视觉信息,pi是权重。
3)视觉显著性指标(visual saliency-induced index,VSI)。VSI(Zhang 等,2014)利用显著特征图变化来计算图像质量。研究发现,图像失真会引起视觉显著性改变,且两者具有强关联性。该指标包含3部分,即梯度SG、色度SC和视觉显著图VS,其定义为
(34)
式中,Ω是整个图像像素空间,VSm(x)=max(VS1(x),VS2(x))作为S(x)的权重。
综上所述,本文总结了图像融合领域代表性的度量指标。需要注意的是,这些指标用于评价图像融合性能,而不是产生融合图像。也就是说,在应用这些指标之前,MMIF算法已经生成了融合的图像F。所有的MMIF算法都以某些形式结合了源图像A和B的信息,所以在实践中,A=F或B=F通常不会发生。此外,两个源图像都包含重要的信息,因此有许多评价指标用于度量融合图像F与源图像之间的相似性。一个好的图像融合算法应该从两个源图像向融合的图像同时传递重要的信息。除此之外,UQI(universal quality index)、FMI(feature mutual information)、SCD(sum of the correlations of differences)、RMSE(root mean square error)、BIQI(blind image quality indices)、QM(multiscale feature based metric)、QS(Piella’s metric)、VAR(variance)、CC(correlation coefficient)、QG(the gradient-based metric)、QP(phase congruency-based metric)、QAC(quality-aware clustering)、LPIPS(learned perceptual image patch similarity)等也是图像融合的度量指标。
4 实验和结果分析
本文进行大量实验评估MMIF算法的性能。实验在具有NVIDIA RTX2080 GPU和i9-9900K CPU的计算机进行,各算法采用原文献使用的参数。
4.1 实验设置
实验对22种MMIF算法进行比较,分别是EMFusion(enhanced medical image fusion)(Xu和Ma,2021)、FusionDN(densely connected network for image fusion)(Xu等,2020)、IFCNN(convolutional neural network for image fusion)(Zhang等,2020)、U2Fusion(unified unsupervised image fusion network)(Xu等,2022)、MSENet(multi-scale enhanced network)(Li等,2022b)、DPCN(detail preserving cross network)(Tang等,2021)、MSRPAN(multiscale residual pyramid attention network)(Fu等,2021a)、FusionGAN(Ma等,2019)、MSDRA(multiscale double-branch residual attention network)(Li等,2022c)、TL-SR(three-layer decomposition and sparse representation)(Li等,2021c)、NSST-CNPS(coupled neural p systems)(Li等,2021a)、NSCT-DTNP(dynamic threshold neural P systems)(Li等,2021b)、Cloud(Wang等,2022b)、GED(gradient enhanced decomposition)(Wang等,2022a)、TL-ST(three-layer representation with structure tensor)(Du等,2020a)、CFL(coupled feature learning)(Veshki 等,2021)、JBF-LGE(joint bilateral filter and local gradient energy)(Li等,2021d)、Re-LP(redecomposition Laplacian)(Li等,2020)、EIB(three-layer representation with enhanced illumination fusion rule)(Du等,2020b)、LLF-IJF(local Laplacian decomposition and iterative joint filter)(Li等,2022a)、DDcGAN(dual-discriminator conditional generative adversarial network)(Ma等,2020)和DSAGAN(generative adversarial network based on dual-stream attention mechanism)(Fu等,2021b)。其中,基于深度学习的方法11种,基于传统的方法11种,部分算法可用于执行多种数据的图像融合任务,如IFCNN和U2Fusion。FusionDN和FusionGAN尽管在设计时并不针对医学图像,但近期的MMIF算法文献常用其作为对比算法。这22种方法的详细信息如表2所示。

表2 对比方法详细信息
本研究使用公开的美国哈佛医学院提供的脑图像数据集。该数据集包含多个模态的脑部疾病图像,每幅图像都经过图像配准,大小均为256 × 256像素。采用6种病例图像对以上方法进行实验,每种病例分别收集10对模态对,共60对,120幅单一模态图像,分别为脑弓形虫病、多发栓塞性梗死的MRI-CT融合;莱姆脑病、轻度阿尔茨海默症的MRI-PET融合;脑胶质瘤、海绵状血管瘤MRI-SPECT融合的主观效果。共采用15种客观指标,分别为基于信息理论的EN、MI、TMQI、PSNR、SSEQ;基于图像特征的AG、EI、QAB/F、SD、SF;基于相似性的SSIM、FSIM、GSM;基于人类视觉的VIF、VSI等指标。
4.2 融合性能比较
4.2.1 定性评价
图8—图13展示了上述22种MMIF算法的主观效果。从6组实验结果来看,基于传统方法的MMIF具有更稳定的融合性能,主观效果几乎与文献描述一致。传统算法对于灰度图像的信息保留相对较好,对于像素重叠区域容易受到伪彩图像的高能量影响,使得融合结果更倾向于伪彩图像而丢失了重叠区域的解剖细节。基于结构张量和颜色张量的TL-ST在多个病例中均未展示较好的融合性能,产生了不同程度的颜色失真。在多尺度几何变换域中,NSST和NSCT两种图像分解方法表现出了较好的颜色保留能力。而基于局部拉普拉斯和重构拉普拉斯的方法在多个数据集上均产生了颜色失真。3种基于GAN网络的方法经过代码迁移后未能表现出与原文献一致的主观效果,融合结果在多个数据集上都产生了严重的颜色失真、信息丢失以及大量的图像伪影。两种基于通用框架的深度学习方法U2Fusion和IFCNN在医学图像数据集上出现了丢失灰度图像细节的问题,尤其是在重叠区域较多的MRI-PET融合中,伪彩图像拥有的能量大于灰度图像,在进行特征融合时,伪彩图像能获得较大的权重,使融合结果向某一模态倾斜。基于细节保留交叉网络的DPCN方法在主观效果上未能达到保留细节的目的,融合结果在多个数据集中都表现得过度平滑。EMFusion利用灰度图像生成人工的伪彩图像补充真实伪彩图像进行颜色空间转换后的马赛克现象,但主观效果产生了严重的颜色失真。FusionDN和FusionGAN不是针对医学图像设计的融合方法,在医学图像上没有产生适应性和鲁棒性。基于多尺度注意力机制和残差网络的MSDRA和MSRPAN在两种模态的重叠区域较小时,能够有效保留灰度图像的信息,产生高对比度的融合效果以及保留伪彩图像的颜色信息,但是在重叠区域较多的病例数据上,融合结果同样倾向伪彩图像。

图8 多发栓塞性脑梗死病例的CT-MRI融合结果
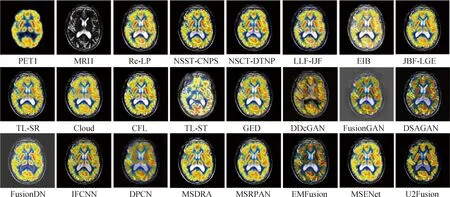
图10 阿尔茨海默症的PET-MRI融合结果
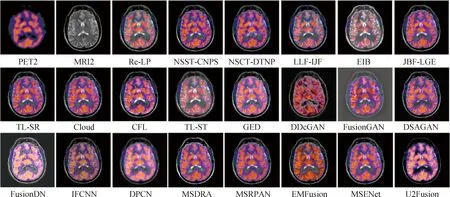
图11 莱姆病的PET-MRI融合结果

图12 海绵状血管瘤的SPECT-MRI融合结果

图13 脑胶质瘤的SPECT-MRI融合结果
4.2.2 定量评价
表3—表5展示了22种MMIF算法在CT-MRI、PET-MRI和SPECT-MRI 3组融合模态上的15组客观指标,每组数据由每个模态的20个模态对取均值所得,文中仅展示至小数点后两位,实际最优值以原始指标为依据给出。可以看出,最优指标大多集中在使用深度学习的算法中。其中,FusionGAN在3种数据集上均能保持最高熵,表明其融合结果包含丰富的图像信息。MSENet在MI指标上有良好表现,说明其能够有效地将源图像信息传输至融合图像中。FusionDN在3种数据集上保持最优的TMQI值,说明该方法具有良好的亮度信息和对比度信息提取能力。DDcGAN和DSAGAN分别在CT-MRI和SPECT-MRI融合中取得最优的AG和EI值。说明这两种方法对图像梯度信息和边缘信息具有较好的提取能力。EMFusion在PET-MRI融合中取得了最高的基于人类视觉特征的指标。从整体指标来看,基于GAN网络的MMIF方法在提取图像基本信息方面具有一定优势;基于CNN的MMIF方法在提取和保留图像特征上有明显优势。而传统算法虽然没有获取最优指标,但结合可视化结果来看,传统算法能够提供更符合人眼视觉观察的主观效果。

表3 不同方法的CT-MRI融合指标对比

表4 不同方法的PET-MRI融合指标对比

表5 不同方法的SPECT-MRI融合指标对比
表6展示了22种融合方法在3种模态上的平均融合时间,传统方法中基于多尺度变换的方法整体运行时间较长。在实际的临床应用中,高效的融合算法更有利于医学成像设备的发展。
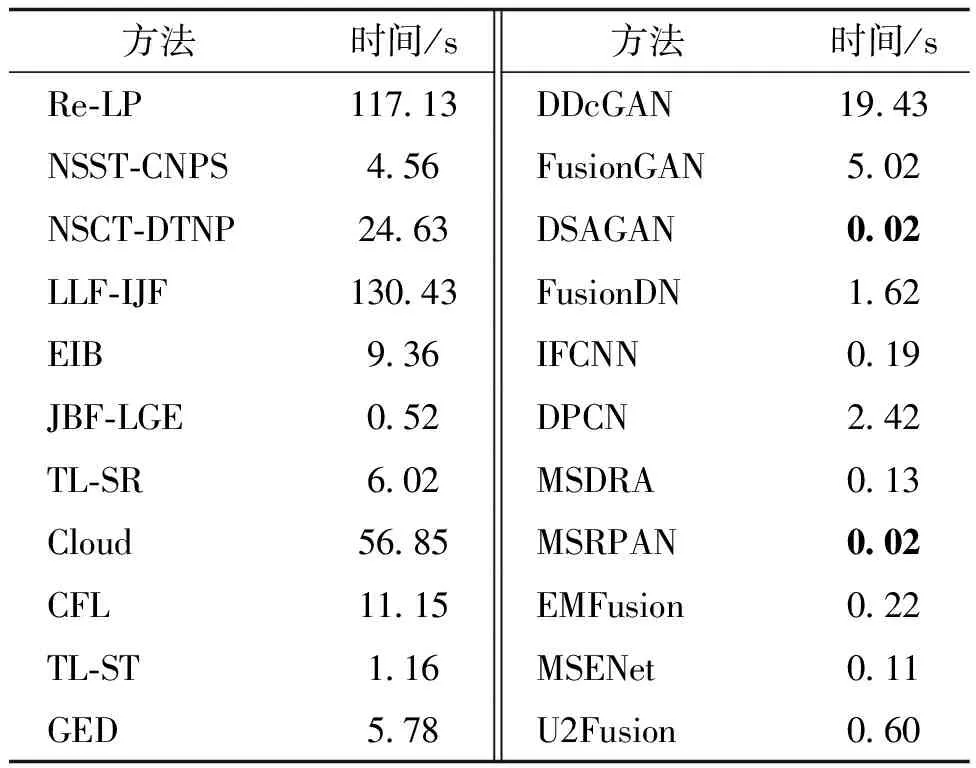
表6 不同融合方法的平均融合时间的比较
5 当前挑战与研究趋势
根据以上内容可得出,无论是传统方法还是深度学习方法都能够在一定程度上取得优越的融合表现。随着算法的不断优化和医学图像数据集的不断丰富,出现了越来越多融合效果好且模型鲁棒性高的医学图像融合方法。但是,在医学图像融合领域仍存在一些问题。本文通过总结上述研究工作,提出在MMIF领域中一些尚未解决的挑战和未来研究趋势。
5.1 现有挑战
现有MMIF算法主要面临以下问题:1)有限的算法创新没有推动MMIF产生质的飞跃,在助力图像融合系统、图像融合硬件设备发展过程中,算法创新性和性能提升带来的推动力远远不够。2)现有MMIF算法高度依赖图像配准,配准的精确程度直接影响融合的结果。3)像素强度异常、特征缺失、传感器误差、空间误差和图像间的变异性导致的特征处理和提取算法中的主要问题仍是医学图像融合中的一个开放问题。4)在近几年的MMIF算法中,对设备在采集图像过程中造成的噪声影响没有过多研究,多数MMIF算法未验证噪声鲁棒性。5)传统的MMIF算法中仍然存在计算量大、自适应性差和高度依赖人工设计融合策略的问题。6)基于深度学习的MMIF算法对数据集的量级和模态类别多样性的需求远大于目前可获取的内容,而网络的构建、损失函数的设计以及实验数据的设置同样缺乏合理的可解释性。7)图像融合结果的评价高度主观,针对其客观指标没有统一的标准,且目前没有针对医学图像融合结果评价的客观指标。
5.2 研究趋势
深度学习方法具有非常好的特征提取能力,能够完成绝大多数图像处理任务,但在没有ground truth的图像融合领域,传统方法仍然占据着一席之地。传统方法基于图像像素操作进行空间变换或系数变换。近几年,越来越多的学者将两者结合起来,充分利用两者的优势,其共同的研究趋势在于:拓展多种部位多种病例的医学图像、提出适合医学图像融合的客观指标以及拓展图像融合的研究范围。
6 结 语
本研究对国内外医学图像融合方法相关文献进行归纳,将医学图像融合技术分为传统方法和深度学习方法两类。在传统医学图像融合方法中,基于空间域和频率域的融合算法是近年的研究热点。空间域技术利用底层像素级策略作用于图像中的图像元素值,融合过程相对简单,算法复杂度低,通常计算量较少,在降低融合图像的光谱失真方面具有较好的性能。缺点是融合结果在清晰度和对比度上并不优越,时常导致空间分辨率较低。在频域,原始手段是通过计算傅里叶变换将输入图像从空域转换到频域,然后对转换后的图像应用融合算法,再进行傅里叶逆变换得到最终的融合图像。这类方法通常采用多级分解来增强融合图像的细节保持能力。输出的融合结果具有较高的空间分辨率和高质量的光谱成分。然而,这种算法也依赖于细粒度的融合规则设计。基于深度学习的方法主要是CNN和GAN网络,主要优点是不再依赖于细粒度的融合规则设计,减少了人工在融合过程中的参与,更强的特征提取能力使融合结果可以保留更多的源图像信息。然后,对现有多模态医学图像数据库和融合质量评价指标进行全面概述。包括5个开源和免费访问的医学图像数据库OASIS、TCIA、AANLIB、ANDI和JIC。常用的融合图像评价指标可以归纳为4类,即基于信息论的指标、基于图像特征的指标、基于图像结构相似性的指标和基于人类视觉感知的指标。此外,本研究进行大量实验比较基于深度学习的图像融合方法与传统医学图像融合方法的性能。通过对定性和定量结果的分析,对医学图像融合技术的现状、重点难点进行讨论,并指出未来发展前景。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
动漫星空(兴趣百科)(2020年12期)2020-12-12
作文小学中年级(2020年6期)2020-07-24
祝您健康(2020年4期)2020-05-20
新校长(2016年5期)2016-02-26
科学中国人(2015年13期)2015-02-28
自然资源遥感(2014年3期)2014-02-27
