
基于深度学习的图像融合方法综述
2023-02-18 03:06唐霖峰张浩徐涵马佳义
中国图象图形学报 2023年1期
唐霖峰,张浩,徐涵,马佳义
武汉大学电子信息学院,武汉 430072
0 引 言
由于成像设备硬件限制,单一类型或单一设置下的传感器通常无法全面地表征成像场景(Liu等,2018;Zhang等,2021b)。例如可见光图像通常包含丰富的纹理细节信息,但却容易遭受极端环境和遮挡的影响而丢失场景中的目标。与之相反,红外传感器通过捕获物体散发的热辐射信息成像,能够有效地突出行人、车辆等显著目标,但是缺乏对场景的细节描述(Ma等,2019a)。此外,具有不同ISO(international organization for standardization)和曝光时间的相机只能捕捉在其动态范围内的场景信息,而不可避免地丢失动态范围之外的信息。值得注意的是,不同类型或不同光学设置下的传感器通常包含大量互补信息,这也启发人们将这些互补信息集成到单一的图像中。因此,图像融合技术应运而生。
根据成像设备/成像设置的差异,图像融合通常可以分为3类,即多模图像融合、数字摄影图像融合和遥感影像融合。
1)多模图像融合。由于成像原理的限制,单一类型的传感器只能捕获部分场景信息。多模图像融合能够将多个传感器捕获的有用信息整合到单幅的融合图像中,以实现对场景有效且全面地表征。典型的多模图像融合包括红外和可见光图像融合以及医学图像融合。
2)数字摄影图像融合。由于光学器件的限制,数码相机通常无法在单一设置下收集成像场景中的所有信息。具体来说,数码相机拍摄的图像通常只能适应一定范围的光照变化,并且只能清晰地呈现在预定义景深中的场景。多曝光图像融合和多聚焦图像融合作为数字摄影图像融合中典型的任务能够将不同设置下拍摄的图像进行融合,并生成高动态范围、全聚焦的融合图像。
3)遥感影像融合。在保证信噪比的前提下,光谱与瞬时视场(instantaneous field of view,IFOV)是相互矛盾的(Zhang等,2021b)。这意味着,仅依靠一种传感器无法同时捕获高空间分辨率、高光谱分辨率的图像。遥感影像融合旨在将空间分辨率和光谱分辨率不同的图像进行融合,得到一幅高空间分辨率和高光谱分辨率兼备的融合图像。多光谱与全色图像融合是最具有代表性的遥感影像融合场景。从源图像的成像角度来看,遥感影像融合也属于多模图像融合。但是遥感影像融合相较于多模图像融合需要更高的空间和光谱保真度来提升分辨率。因此本文将遥感影像融合作为一个独立的范畴来讨论。
这3种图像融合场景示意图如图1所示。融合图像能够吸收源图像中的互补特性,并具有更好的场景表达和视觉感知效果,从而能够有效地促进诸如目标检测(Cao等,2019)、语义分割(Tang等,2022a)、场景感知(Zhang和Ji,2005)、临床诊断(Bhatnagar等,2013)和遥感监测(Zhang等,2020a)等实际计算机视觉应用。

图1 各类图像融合场景示意图
在深度学习席卷计算机视觉领域之前,图像融合问题已经得到了深入研究。传统的图像融合算法通常是在空间域或变换域(通过某种数学变换将图像转换至变换域)执行活动水平测量并手动设计融合规则来实现图像融合(Ma等,2019a)。经典的传统图像融合框架主要包括基于多尺度变换的融合框架(Liu等,2014;Zhang和Maldague,2016;殷明 等,2016;Liu等,2017a;楼建强 等,2017;焦姣和吴玲达,2019;Chen等,2020;Li等,2020b;霍星 等,2021)、基于稀疏表示的融合框架(李奕和吴小俊,2014;Liu等,2016;杨培 等,2021)、基于子空间的融合框架(Cvejic等,2007;Mou等,2013;Fu等,2016)、基于显著性的融合框架(Ma等,2017;霍星 等,2021;杨培 等,2021)、基于变分模型的融合框架(马宁 等,2013;周雨薇 等,2015;Ma等,2016)等。尽管现有的传统图像融合算法在多数情况下能够产生较为满意的结果,但是仍然存在一些阻碍其进一步发展的难题。首先,现有的方法通常使用相同的变换或表示从源图像中提取特征,却没能考虑不同源图像存在本质差异。其次,手工设计的活动水平测量和融合规则无法适应复杂的融合场景,而且为了追求更好的融合性能,活动水平测量和融合规则的设计变得越来越复杂(Li等,2017)。
近年来,深度学习以其强大的特征提取和表达能力主导了计算机视觉领域的发展,并在诸如图像分类(He等,2016;Huang等,2017)、目标检测(Redmon等,2016;Ren等,2017)和语义分割(Ronneberger等,2015;Chen等,2018)等视觉任务上展现了显著的性能优势。为了克服传统算法的不足,图像融合领域的研究者也探索了大量基于深度学习的图像融合算法。现有基于深度学习的图像融合算法主要致力于解决图像融合中3个关键问题:特征提取、特征融合和图像重建。根据采用的网络架构,基于深度学习的图像融合算法可分为基于自编码器(auto-encoder, AE)的图像融合框架、基于卷积神经网络(convolutional neural network,CNN)的图像融合框架和基于生成对抗网络(generative adversarial network,GAN)的图像融合框架3类。图2展示了这3类图像融合框架的整体流程。

图2 不同图像融合框架示意图
1)基于自编码器(AE)的图像融合框架首先在大型数据集上预训练一个自编码器,用来实现特征提取和图像重建。例如MS-COCO(Microsoft common objects in context)数据集(Lin等,2014)、ImageNet数据集(Deng等,2009)。然后采用手工设计的融合策略来整合从不同源图像中提取的深度特征以实现图像融合(Li和Wu,2019;Li等,2020a),然而这些手工设计的融合策略并不一定适用于深度特征,从而限制了基于AE的融合框架的性能。
2)基于卷积神经网络(CNN)的图像融合框架通过设计网络结构和损失函数来实现端到端的特征提取、特征融合和图像重建,从而避免手动设计融合规则的烦琐(Ma等,2021c)。图2(b)是一种主流的基于CNN的图像融合框架,通过度量融合图像与源图像之间的相似性来构造损失函数,指导网络进行端到端训练(Han等,2022)。也有方法利用先验知识设计一个伪标签图像与融合图像构造损失函数(Deng等,2021)。此外,有部分基于CNN的方法将卷积神经网络作为整体方法的一部分用于特征提取或活动水平测量(Liu等,2017c)。
3)基于生成对抗网络(GAN)的图像融合框架将图像融合问题建模为生成器与判别器之间的对抗博弈问题。如图2(c)所示,基于GAN的图像融合框架通过判别器来迫使生成器生成的融合结果在概率分布上与目标分布趋于一致,从而隐式地实现特征提取、融合和图像重建。现有基于GAN的融合方法通过源图像(Ma等,2020c)或者伪标签图像(Xu等,2020b)来构造目标分布。
根据训练过程中使用的监督范式,基于深度学习的图像融合算法还可分为无监督图像融合框架、自监督图像融合框架和有监督图像融合框架。
本文根据网络架构并辅以监督范式,全面系统地阐述基于深度学习的多模图像融合、数字摄影图像融合以及遥感影像融合的研究进展,以便人们能够更好地掌握深度图像融合领域的研究现状。本文结构框架如图3所示。首先结合网络架构和监督范式,讨论3大融合场景中有代表性的基于深度学习的方法以及通用的图像融合算法。然后简要介绍不同融合任务中的数据集和评估指标,并对有代表性的算法进行全面评估分析。最后,对全文进行总结,并结合图像融合中存在的挑战提出展望。
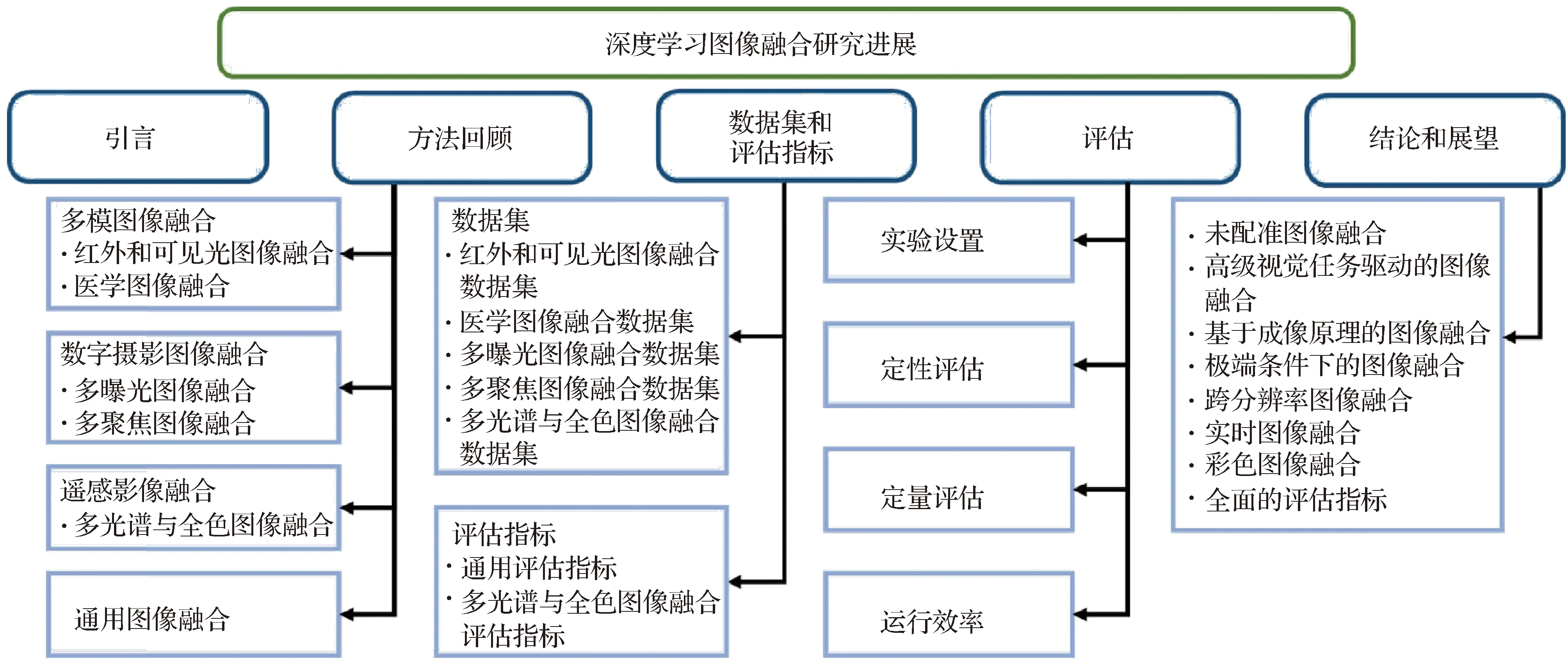
图3 本文结构框架
1 方法回顾
1.1 多模图像融合
多模图像融合旨在通过整合不同传感器捕获的互补信息来全面地表征成像场景,典型的多模图像融合任务主要包括红外和可见光图像融合以及医学图像融合。
1.1.1 红外和可见光图像融合
红外传感器通过捕获物体的热辐射信息成像,即使在极端条件、恶劣天气及部分遮挡情况下也能够有效地突出显著目标。但是红外图像无法提供足够的环境信息,如纹理细节、环境照明等。与之相反,可见光传感器通过收集物体表面的反射光成像,因此可见光图像包含丰富的纹理细节信息并更加符合人类的视觉感知。红外和可见光图像融合旨在整合源图像中的互补信息,并生成既能突出显著目标又包含丰富纹理细节的高对比度融合图像(Zhang等,2020c),主要包括基于AE、基于CNN和基于GAN的红外和可见光图像融合框架。
基于AE的方法首先在大规模自然图像数据集上训练一个自编码器,然后预训练的编码网络和解码网络分别用于实现特征提取与图像重建,最后一般使用手工设计的融合策略融合编码网络提取的深度特征来实现图像融合。为了强化编码网络提取特征的能力,Li和Wu(2019)、Li等人(2020a,2021a)和王建中等人(2021)在基于AE的图像融合框架中引入了密集连接、蜂巢连接以及残差密集块。此外,Liu等人(2022b)、Jian等人(2021)和俞利新等人(2022)在基于AE的融合框架中引入注意力机制,使网络能够更加关注显著目标以及纹理细节信息。为了提取更具可解释性的深度特征,Xu等人(2021b)将解离化表征学习注入到了基于AE的图像融合框架中。值得一提的是,上述算法均采用手工设计的融合策略(例如逐像素相加、逐像素加权求和以及最大选择策略)融合深度特征,在传统方法中取得了不错的融合效果,但是深度特征通常具有不可解释性,因此手工设计的融合策略无法为深度特征分配恰当的权重,以至于限制了这类算法的性能提升。Xu等人(2021c)基于像素级显著性和可解释重要性评估,提出一种可学习的融合策略,能够根据深度特征的重要性和显著性,为不同源图像的特征分配恰当的权重,自适应地融合这些深度特征,进而赋予深度融合算法更强的可解释性。然而,计算像素级显著性以及执行重要性评估十分耗时。所以,进一步研究实时的可学习融合策略将是未来基于AE的图像融合框架下的研究热点之一。
基于CNN的端到端图像融合框架是另一种避免手动设计融合规则弊端的技术路线。这类方法通常依靠设计的网络结构和损失函数隐式地实现特征提取、特征融合和图像重建。一方面,人们提出聚合残差密集网络(Long等,2021)、基于双注意力的特征融合模块(Li等,2021d)、梯度残差密集块(Tang等,2022a)、SE(squeeze-and-excitation)融合模块(陈国洋 等,2022)和跨模差分感知融合模块(Tang等,2022b)等网络结构来提升融合性能,但这些网络结构通常会增加网络复杂度,从而影响方法的运行效率。Liu等人(2021b)提出一种基于网络架构搜索的图像融合方法,能够针对不同融合任务的特点,自适应地构造高效且有效的特征提取、特征融合以及图像重建网络。另一方面,人们使用强度损失、梯度损失、结构相似性度量(structural similarity index measure, SSIM)损失、感知损失、对比度损失以及语义损失等损失函数从不同层面约束融合图像与源图像的相似性。值得一提的是,Li等人(2021b)结合元学习实现了不同分辨率条件下,只需重新训练一个学习模型便能生成任意大小的融合结果。此外,Tang等人(2022a)结合高层视觉任务(目标检测、语义分割等)的需求,提出一种高层视觉任务驱动的图像融合框架(SeAFusion)来集成尽可能多的语义信息,以提升高层视觉任务在融合图像上的性能。尽管SeAFusion(Tang等,2022a)在建模融合问题的过程中考虑了高层视觉任务的需求,但是作为初步的尝试只考虑了在损失函数上的改进。如何以一种更加自洽的方式探索图像融合问题与高层视觉任务之间的内在联系将是未来图像融合领域的发展趋势之一。
生成对抗网络(Goodfellow等,2014)在没有监督信息的情形下也能够有效地建模数据分布,该特性非常符合红外和可见光图像融合的需求。Ma等人(2019b)在FusionGAN中首次将图像融合问题定义为生成器与判别器之间的对抗博弈。具体来说,生成器负责捕获源图像样本中的潜在分布,并将这些分布特性充分集成到融合图像中。判别器负责从分布上判别输入的是源图像还是融合图像,从而迫使生成器合成的融合结果尽可能多地包含源图像的分布特性。在FusionGAN之后,细节损失、边缘增强损失(Ma等,2020b)、密集连接块(Fu等,2021b)、视觉显著性图(周祎楠和杨晓敏,2021)、条件GAN(Ma等,2020c)、Patch-GAN(Zhang等,2021c)、多分类生成对抗网络(Ma 等,2021d)、聚合纹理图以及引导滤波器(Yang等,2021a)等新颖的损失和网络相继引入到基于GAN的融合框架中,进一步提升了融合性能。然而单判别器容易在训练过程中造成模态失衡,导致融合结果无法保持红外图像的对比度或可见光图像中的纹理细节信息。Xu等人(2019)和Ma等人(2020c)提出利用双判别器维持不同模态间的信息平衡,并更好地约束融合结果的概率分布。在此基础上,Li等人(2021c,d)将注意力机制注入到基于GAN的图像融合框架中,以促使生成器和判别器更关注那些重要区域。类似于SeAFusion,Zhou等人(2021)将语义标签引入到基于GAN的图像融合框架中,从而迫使生成器保留更多的语义信息。尽管基于GAN的图像融合算法能够生成较好的融合结果,但如何在训练过程中维持生成器与判别器的平衡仍值得深入研究。
基于深度学习的多模图像融合算法归纳如表1所示。

表1 多模图像融合研究归纳
1.1.2 医学图像融合
根据源图像表征的信息,医学影像可以分为结构图像和功能图像两大类。结构图像主要提供结构和解剖信息。例如,CT(computed tomography)图像可以很好地反映骨头和植入物等密质结构,MRI(magnetic resonance imaging)图像能够提供软组织的相关信息。功能图像主要包括PET(positron emission tomography)图像和SPECT(single-photon emission computed tomography)图像。PET图像表征肿瘤的功能和代谢,SPECT图像则反映组织器官和血流情况(Liu等,2017b;Xu和Ma,2021)。此外,绿色荧光蛋白(green fluorescent protein,GFP)图像能够反映与生物细胞分子分布相关的功能信息并展现细胞中的蛋白质分布。而高分辨率的相衬(phase contrast, PC)图像能够清晰地展现包括细胞核和线粒体在内的亚细胞结构信息(Tang等,2021)。医学图像融合旨在将多幅不同类型图像中重要的、互补的信息整合到一幅信息丰富的融合图像中,帮助医生快速准确地诊断疾病。本文通过基于CNN和基于GAN的图像融合框架介绍深度学习背景下医学图像融合的研究进展。
最初,基于CNN的医学图像融合方法只利用卷积神经网络实现活动水平测量或特征提取。一方面,部分方法基于拉普拉斯金字塔(Liu等,2017b)或对比度金字塔(Wang等,2020)实现图像分解和重建,然后使用暹罗卷积神经网络度量源图像的像素活动水平并生成融合权重图;另一方面,一些方法(Lahoud和Süsstrunk,2019)采用预训练的卷积神经网络从源图像中提取深度特征,并利用高斯滤波器融合这些深度特征来获得融合图像,然而采用的网络并未在医学图像上进行预训练,因而无法有效捕获不同类型医学图像中的特性。基于此,人们提出了基于CNN的端到端医学图像融合算法(Liang等,2019;Fu等,2021a)。类似于基于CNN的红外和可见光图像融合方法,基于CNN的医学图像融合算法也通过精心设计网络结构和损失函数,以端到端的方式实现特征提取、融合以及图像重建。具体来说,Tang等人(2021)提出了由结构引导的功能特征提取分支、功能引导的结构特征提取分支以及细节保留模块组成的细节保留交叉网络(detail preserving cross network,DPCN),实现端到端的GFP和PC图像融合。另外,Xu和Ma(2021)提出的无监督的端到端医学图像融合方法(enhanced medical image fusion network,EMFusion)能够通过施加表层约束和深层约束,实现信息增强以及互补信息聚合。
基于GAN的方法通过对抗学习将医学图像中重要信息的潜在分布进行建模,如功能图像中的强度分布和结构图像中的空间纹理细节等。GFPPC-GAN(green fluorescent protein and phase-contrast image fusion via generative adversarial networks)(Tang等,2019)首次将生成对抗网络引入到医学图像融合任务中,并设计了基于融合图像与PC图像之间的对抗学习来强化生成网络对结构信息保存的能力。此外,Zhao等人(2021a)将密集连接和编—解码结构注入到基于GAN的医学图像融合框架中,并设计了细节损失和结构相似度损失来强化生成网络对功能信息和边缘细节的提取能力,然而单个判别器无法在对抗过程中有效维持结构信息与功能信息的平衡。Ma等人(2020c)提出一个多判别器的条件对抗网络(dual-discriminator conditional generative adversarial network,DDcGAN),用于实现更加平衡的信息融合。具体来说,DDcGAN通过建立单个生成器与多个判别器的对抗博弈,促使生成网络同时捕获源图像中的功能信息和纹理细节。在此基础上,Huang等人(2020a)进一步设计了一个多生成器多判别器的生成对抗网络(multi-generator multi-discriminator conditional generative adversarial network,MGMDcGAN),在更加平衡地融合互补信息的同时,实现跨分辨率医学图像融合。尽管引入多个生成器和判别器能够提升融合网络的性能和功能,但有可能导致训练不稳定问题以及模式坍塌。
1.2 数字摄影图像融合
数字成像设备首先利用光学镜头捕获反射光,然后通过CCD(charge-coupled device)和CMOS(complementary metal oxide semiconductor)等元件记录场景信息,但是由于动态范围有限,CCD和CMOS等元件无法承受过大的曝光差异。因此,在曝光差异过大时,单幅图像无法准确呈现场景中的所有细节信息。此外,受光学镜头景深限制的影响,数码相机很难在一幅图像内保证场景中所有目标都在景深范围内。然而只有在景深范围内的物体才能在图像中清晰地呈现,景深外的物体将变得模糊不清。数字摄影图像融合旨在将不同光学设置下拍摄的多幅图像组合在一起,并生成具有高动态范围的全聚焦图像,这是解决上述难题的不二之选。
1.2.1 多曝光图像融合
通常成像场景中存在较大的光照变化,此时由于传感器捕获的动态范围有限,单一光学设置下拍摄的数字图像会因过度曝光或曝光不足而不可避免地丢失场景信息。多曝光图像融合能够将不同曝光程度图像中的有效信息整合起来并产生曝光合适、场景信息丰富的融合图像。本文通过介绍基于CNN和基于GAN的多曝光图像融合框架,回顾基于深度学习的多曝光图像融合的发展。
基于CNN的多曝光图像融合算法在损失函数的指导下,利用卷积神经网络直接学习多幅曝光不同的源图像到正常曝光图像的映射关系。根据是否使用监督信息,这类算法可以进一步分为有监督方案和无监督方案。有监督方案通常使用手动挑选的良好曝光图像作为监督信息指导融合网络的训练(Pan等,2020;Deng等,2021)。值得强调的是,Deng等人(2021)设计的深度反馈网络能够将多曝光图像融合与图像超分问题统一建模到一个框架中,在校正图像曝光水平的同时提升融合图像的分辨率。然而人工挑选正常曝光图像是非常主观的,会不可避免地为这类技术方案设置性能上限。为了避免人工挑选正常曝光图像带来的弊端,无监督多曝光图像融合方法受到广泛关注。无监督方案一般利用非参考指标(例如MEF-SSIM(multi-exposure fusion-structural similarity index))衡量融合结果的质量来构造损失函数,并引导融合网络生成高质量的正常曝光图像(Prabhakar等,2017;Ma等,2020d;Qi等,2021)。DeepFuse(Prabhakar等,2017)是首次提出的这类方法,在MEF-SSIM损失的指导下,利用简单的5层网络学习多曝光输入到单幅融合图像的映射关系。考虑到简单的网络无法提取深层语义特征,人们将一些新颖的学习方式如深度强化学习(Yin等,2022)以及网络架构如Transformer(Qu 等,2022)引入到多曝光图像融合任务中,进一步提升融合性能。与上述技术路线不同,Ma等人(2020d)提出上下文聚合网络(MEF-Net)来学习不同源图像的权重图,最后对源图像进行加权求和生成最终的融合结果。然而仅在像素层面对源图像进行线性加权会不可避免地在融合结果中引入伪影,因此在精心设计的损失函数的指导下,直接学习输入图像到融合结果的映射关系仍然是无监督方案的主流思想。然而MEF-SSIM度量指标只能衡量融合图像的对比度和结构信息,忽略了融合图像的色彩信息。所以上述方法的重心更多在于校正源图像的曝光水平,对于色彩信息只能采用简单方式处理。事实上,恰当的色彩对于提升数字图像的视觉效果尤为重要。对此,DPE-MEF(multi-exposure image fusion via deep perceptual enhancement)将视觉真实性纳入多曝光图像融合问题的建模过程中,并设计了两个独立的模块,分别负责内容细节信息收集和融合图像的色彩校正(Han等,2022)。值得注意的是,无监督方案的融合性能很大程度上取决于采用的非参考指标能否有效且全面地表征融合结果的质量。因此,研究一种能更加全面表征融合图像质量的评估指标是进一步提升融合效果的关键之一。此外,如何使融合网络自适应感知正常的曝光水平也是未来的研究思路之一。
基于GAN的多曝光图像融合算法将曝光条件建模为概率分布,通过对抗学习使融合结果的曝光水平趋于正常。因此,这类技术路线的关键在于如何构造目标分布来引导对抗学习。类似于基于CNN的方法,基于GAN的方法也分为有监督方案和无监督方案。其中,无监督方案将生成器输出的融合图像与手动挑选的伪标签图像(一般来自MEF数据集(Cai等,2018),标签图像是基于13种多曝光融合和基于堆栈的高动态范围算法挑选的)构造基于曝光分布的对抗博弈,使生成网络产生与伪标签图像具有近似曝光分布的融合结果(Xu等,2020b;Yin等,2022;Liu等,2022c)。在这类方法中,MEF-GAN(Xu等,2020b)引入了自注意力模块和局部细节模块来强化生成器对细节信息的提取和保留能力。而AGAL(attention-guided global-local adversarial learning)则通过由粗至精的方式实现极端曝光条件下的图像融合,并设计了一个全局与局部相结合的判别器来平衡融合图像的像素强度分布并校正色彩失真。但这类技术方案利用手动挑选的伪标签图像作为监督信息,往往面临性能受限的困境。为此,Yang等人(2021b)提出一种基于GAN的无监督多曝光图像融合方法,通过引入差分相关性之和(sum of correlation differences, SCD)损失,从信息组合的角度构造了融合图像与源图像之间的对抗博弈,认为融合图像与源图像的差分结果能够表征另一幅源图像的分布。尽管这样构造的对抗模型能够约束生成器保留尽可能多的信息,但这是基于融合图像是两幅源图像之和这样一个不准确的假设而实现的,因此研究如何有效利用源图像中的先验信息(如曝光条件、场景结构)来建立无监督对抗模型将是实现高质量多曝光图像融合的良好选择之一。
1.2.2 多聚焦图像融合
由于光学镜头的局限性,单一光学设置下的数码相机很难将不同景深下的物体都集中在一幅图像中(Zhang,2022)。多聚焦图像融合能够将不同聚焦区域的图像进行组合并生成全聚焦的融合图像。基于CNN和基于GAN的融合框架是两种主流的多聚焦图像融合框架。此外,由于多聚焦图像融合可以看做是清晰像素的选择问题,因此上述框架还可以进一步划分为基于决策图的方案和基于整体重建的方案。
基于决策图的CNN方法本质上是学习一个能够确定每个像素聚焦与否的二值分类器,然后进一步修正分类结果以生成融合决策图,最后根据融合决策图对源图像中的每一个像素进行选择组合来生成全聚焦的融合图像。这类方案通常使用高斯模糊核构造训练二值分类器的数据集并利用一致性验证(Liu等,2017c)、形态学开闭算子(Yang等,2019)、高斯滤波器、保边滤波器(Ma等,2021a)和条件随机场(Xiao等,2021a,b)等技术作为后处理来得到最终的融合决策图。其中,Xiao等人(2021a)将基于离散切比雪夫矩的深度神经网络引入到这类技术方案中,实现实时的多聚焦图像融合。但是上述方案通常需要使用手工设计的后处理操作来进一步修正神经网络输出的聚焦图,而无法实现端到端的图像融合。为了避免烦琐的后处理过程,Amin-Naji等人(2019)提出一种基于集成学习的方法,通过组合不同模型的决策图直接得到最终决策图。类似地,D2MFIF(depth-distilled multi-focus image fusion)将深度信息纳入到聚焦图的估计过程中,并提出一个直接从源图像估计决策图的深度蒸馏模型。除了利用高斯核构造训练数据外,Li等人(2020c)和Ma等人(2021b)提出利用二值掩膜来构造训练数据,并引入梯度损失来引导融合网络生成清晰的全聚焦图像。然而基于高斯模糊核或二值掩膜构造的训练数据集均无法模拟多聚集图像真实的成像方式,特别是这两种方法都没有考虑现实世界中多聚焦图像存在的散焦扩散效应。Ma等人(2020a)提出一种α-哑光边界散焦模型,用于精确模拟散焦扩散效应并生成更加逼真的训练数据。Xu等人(2020c)设计了一个多聚焦结构相似度(MFF-SSIM)指标来衡量融合结果的质量,并使用随机梯度算法在融合过程中最大化MFF-SSIM。与基于决策图的方法不同,基于整体重构的方法利用一些特殊的度量指标(例如MFF-SSIM)作为损失函数来引导融合网络以端到端、无监督学习的方式直接实现多聚焦图像融合(Yan等,2020)。但这类技术方案目前还未将散焦扩散效应纳入到建模过程中,因此结合多聚焦图像的成像原理,通过整体重构的技术路线,在实现有用信息保留的同时消除散焦扩散效应,或许是未来基于CNN的多聚焦图像融合框架的研究方向之一。
基于决策图的GAN方法通常利用生成器学习源图像到决策图的映射关系并生成融合结果,同时通过对抗学习迫使融合结果在分布上接近参考的全聚焦图像。具体来说,FuseGAN(Guo等,2019)将人工标注的聚焦掩膜与源图像堆叠在一起作为正样本,而生成器输出的决策图与源图像堆叠在一起作为负样本来构造对抗博弈关系,指导生成网络从两幅源图像中准确地估计决策图。在此基础上,MFIF-GAN(Wang等,2021b)引入前景区域的聚焦图应大于对应的目标这一先验来改善散焦扩散效应。基于GAN的整体重构方法则利用生成器直接输出全聚焦的融合图像,然后再利用参考图像和融合图像构造对抗关系来指导生成网络的优化(Huang等,2020b;Zhang等,2021a)。然而,以上大部分基于GAN的方法无法有效解决多聚焦图像融合任务中的散焦扩散效应,而散焦扩散效应会严重影响融合图像的视觉效果。因此如何从分布的角度充分建模散焦扩散效应,在生成更加逼真且细节清晰的融合图像的同时,进一步提升融合图像的视觉质量是一个值得进一步探索的研究方向。
基于深度学习的数字摄影图像融合算法归纳如表2所示,其中MEF表示多曝光图像融合场景,MFF表示多聚焦图像融合场景。

表2 数字摄影图像融合研究归纳
1.3 遥感影像融合
在遥感成像中,光谱传感器的光谱/滤波机制需要较大的瞬时视场(IFOV)来满足信噪比的要求,这意味着在保证成像光谱分辨率的同时必然降低空间分辨率。然而在高精度遥感应用中,空间分辨率和光谱分辨率同等重要,前者描述地物的物理形态,后者反映地面的物质组成。因此空间和光谱分辨率不可兼得的特性极大制约了高层遥感任务的精度提升。在此背景下,多光谱与全色图像融合技术应运而生,通过将全色图像中的空间信息及多光谱图像中的光谱信息相融合,生成空间和光谱分辨率并存的高质量遥感图像。基于采用的监督范式,深度多光谱与全色图像融合方法分为有监督的方案和无监督的方案两类。两类方案采取的网络架构主要有CNN和GAN两种。
有监督的多光谱与全色图像融合方法在锐化结果与参考图像间构造最小距离损失,引导神经网络的输出不断趋近于参考图像对应的理想分布。PNN(pan-sharpening neural network)(Masi等,2016)是使用深度学习解决多光谱与全色图像融合问题的开创之作,首次引入CNN提取和融合全色和多光谱图像中的有效信息。然而仅在l2距离损失的约束下,PNN的结果往往存在局部空间结构平滑的现象。此外,简单的3层结构限制了PNN的非线性拟合能力,导致一定程度的光谱失真。后续方法主要从网络架构和约束条件两方面进行改进来提升融合性能。首先,通过改进网络架构使融合过程中信息的提取和聚合更具针对性。例如PanNet(deep network architecture for pan-sharpening)(Yang等,2017)使用残差学习将网络的训练转换到高通域进行,使网络专注于高频结构信息的学习,极大提升了融合结果的空间质量。同时,PanNet引入ResNet加深网络深度,强化了非线性拟合能力,在一定程度上缓解了光谱失真。Liu等人(2021a)使用GAN架构提升融合性能,提出一个多光谱与全色图像融合框架PSGAN(generative adversarial network for pan-sharpening),将参考图像的概率分布定义为目标分布,并使用连续的对抗学习迫使融合结果在分布上逼近参考图像,保证了信息保留质量。与此不同,SRPPNN(super-resolution-guided progressive pansharpening neural network)(Cai和Huang,2021)引入超分辨率模块和渐进学习两种特定的结构设计,使网络能够不断捕获不同尺度上的空间细节,并连续注入到上采样的多光谱图像中。类似地,基于网络架构改进的有监督方法还包括DPFN(dual-path fusion network)(Wang等,2022a)、TFNet(two-stream fusion network)(Liu等,2020)、DI-GAN(detail injection based on relativistic generative adversarial network)(Benzenati等,2022)以及MDCNN(multiscale dilated convolutional neural network)(Dong等,2021)。然而上述方法在设计网络架构时未考虑输入数据与融合结果间的内在关系,更多的是从图像超分辨率这个角度进行的。GPPNN(gradient projection networks for pan-sharpening)(Xu等,2021d)从全色图像与多光谱图像的生成模型出发,探讨空间和光谱退化过程,并将其作为先验来指导神经网络的优化,极大提升了融合性能。与上述方法不同,另外一些多光谱与全色图像融合方法通过额外设计一些更合理的约束条件来改善融合结果中空间和光谱信息的保留质量。SDPNet(Xu等,2021a)除了在参考图像与融合结果间建立常用的表观一致性损失外,还通过训练两个多光谱与全色模态互相转换网络以及一个自编码网络来定义模态相关的独特特征,然后在定义的独特特征上建立一致性损失,进一步保证了融合性能的提升。Zhang(2022)认为只约束融合结果与参考图像的一致性无法有效利用全色图像中的空间信息,且会因为空间结构缺乏显式约束引发光谱与空间信息的不平衡,为此提出了GTP-PNet(gradient transformation prior for pansharpening network),使用特定的TNet拟合光谱退化过程,在梯度域中建立了更加准确的多光谱与全色图像的非线性回归关系,并将此非线性回归关系作为一种先验来约束空间结构的保留,从而保障光谱与空间信息的平衡。然而有监督的多光谱与全色图像融合方法本质上是学习输入图像到参考图像的非线性映射,实际性能很大程度上依赖于参考图像构建的合理性。在有监督方法中,参考图像的构建遵循Wald协议,该协议将全分辨率多光谱与全色图像进行空间下采样,得到降分辨率数据并作为网络的输入,而将原始的全分辨率多光谱图像作为参考图像监督网络的优化。这种策略可能会从两方面限制有监督方法的性能。一方面,采取的空间退化模式可能与真实的遥感数据退化模式不一致,使网络学到的映射关系无法推广到真实遥感数据上;另一方面,有监督方法遵循的尺度不变性假设可能并不成立,使得在降分辨率数据上训练的模型无法有效地推广到全分辨率数据上。
为了摆脱网络对参考图像的依赖,进而解决上述难题,无监督多光谱与全色图像融合方法受到了广泛关注。具体来说,无监督方案通过建立融合结果与输入多光谱和全色图像之间的联系来分别约束光谱分布与空间结构的保留,生成光谱和空间分辨率兼具的理想图像。从技术路线来看,无监督方案的优势包括两方面。首先,无监督方法不再需要合成配对数据,使网络优化和学习更加便捷;其次,网络训练直接在卫星真实捕获的全分辨率数据上进行,在保证数据可信度的同时,能够充分利用有监督方法中忽视的全分辨率全色图像包含的信息。无监督方法的研究主要在于如何完善约束光谱保留的空间退化模型和约束空间结构保留的光谱退化模型。Pan-GAN(Ma等,2020d)是首个探索无监督多光谱与全色图像融合的方法,引入了两个判别器在融合结果与两幅源图像间建立对抗,分别判定光谱与空间信息是否保真。在Pan-GAN中,光谱退化模型定义为平均池化操作,空间退化模型定义为插值采样操作。类似地,UCGAN(unsupervised cycle-consistent generative adversarial networks)(Zhou等,2022)将光谱退化模型定义在高通域并使用最大池化来实现通道合并,空间退化模型定义在低通域并使用插值采样实现空间分辨率降低。然而这两种方法都采样相对粗糙的方式模拟光谱退化模型和空间退化模型,在一定程度上限制了融合质量的提升。Luo等人(2020)将光谱退化模型建模为多谱段全局线性加权,并使用最小二乘法求解加权系数。对于空间退化模型,采用与MTF相关的高斯模糊以及插值采样操作来模拟该过程,取得了一定的性能提升。需要强调的是,光谱退化模型更倾向于局部非线性而不是全局线性,使用最小二乘求解系数所依赖的尺度不变性假设也可能并不成立。为了实现更准确地估计观测模型,BKL(blur kernel learning)(Guo等,2020)采用卷积神经网络和全连接网络分别估计空间模糊核以及光谱模糊核,然后结合插值采样操作在退化一致性的约束下估计空间和光谱退化模型。值得注意的是,这种无监督退化模型估计的解空间是非常大的,仅依赖退化一致性非常容易陷入平凡解或局部最优解。类似地,无监督多光谱与全色图像融合还包括LDP-Net(pansharpening network based on learnable degradation processes)(Ni等,2021)、UPSNet(unsupervised pan-sharpening network)(Seo等,2020)以及MSGAN(multi-scale generative adversarial network)(Wang等,2022b)等。相较于有监督方法,对于无监督多光谱与全色图像融合方法的研究还相对较少,如何估计更准确的观测模型是未来进一步提升融合性能的关键。
基于深度学习的遥感影像融合算法归纳如表3所示,其中,Pansharpening表示多光谱与全色图像融合场景。

表3 遥感影像融合研究归纳
1.4 通用图像融合
任务特定的图像融合算法均通过挖掘不同融合问题中的先验知识来提升融合性能,但忽略了不同融合任务之间的内在联系。因此,人们致力于开发通用的图像融合框架。IFCNN(image fusion framework based on convolutional neural network)(Zhang等,2020d)是首个基于深度学习的通用图像融合方法,该方法参考DeepFuse(Prabhakar等,2017)设计网络结构,并在大型的多聚焦图像数据集上通过端到端的方式训练网络。特别地,IFCNN通过改变融合层的融合策略,将不同图像融合任务统一到一个框架下。PMGI(proportional maintenance of gradient and intensity)(Zhang等,2020b)将不同图像融合问题定义为梯度和强度的比例维持,并设计一个统一的损失函数形式,根据不同任务的先验知识,手动调整各项损失函数的加权系数,能够在一个统一框架下解决不同的图像融合问题。为了避免手动调整超参数,Zhang和Ma(2021b)进一步提出了挤压分解网络(squeeze-and-decomposition network,SDNet)和自适应决策块来提升融合性能。类似地,Jung等人(2020)将多种图像融合问题统一为对比度保持问题,并引入结构张量来表征图像对比度以及构造损失函数。Deng和Dragotti(2021)将图像融合问题定义为独特特征与公共特征的集合,并基于多模卷积稀疏编码模型提出一种用于解决通用多模图像恢复和多模图像融合难题的深度卷积神经网络(Cu-Net)。类似地,IFSepR(image fusion based on separate representation learning)(Luo等,2021)结合对比学习和解纠缠表示学习将源图像分解为私有特征和公有特征,并提出一种空间自适应策略融合来自不同源图像的私有特征,在统一的基于自编码器的框架下实现多种图像融合任务。为了学习到特定任务的特征,Li等人(2021e)提出使用多个面向任务的编码器和一个通用的解码器来实现多任务图像融合,并设计一个自适应损失函数来指导网络训练。值得一提的是,考虑到不同的融合任务能够相互促进,Xu等人(2020a,2022a)结合可学习信息测量和弹性权重固化,开发了一种无监督图像融合模型用于解决多场景图像融合问题。其中,弹性权重固化用于克服多任务持续学习中的遗忘难题。Ma等人(2022)提出一种基于跨域长距离依赖和Swin Transformer 的通用图像融合框架(SwinFusion),通过充分挖掘同一幅源图像的域内上下文信息,以及多源图像的域间全局交互以充分整合互补信息,在多模图像融合以及数字摄影图像融合上都取得了较好的性能表现。
综合考虑各类图像融合任务的共性并设计统一的融合框架来同时解决多种融合问题能够增加融合算法的实用性。因此,设计通用的图像融合框架仍然是未来的研究热点之一。基于深度学习的通用图像融合算法如表4所示。
2 数据集与评估指标
2.1 数据集
各类图像融合任务中常用的数据集主要包括红外和可见光图像融合数据集、医学图像融合数据集、多曝光图像融合数据集、多聚焦图像融合数据集和多光谱与全色图像融合数据集,如图4所示。
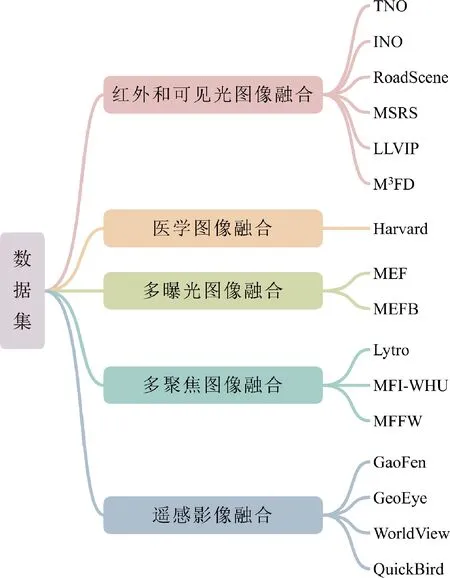
图4 图像融合常用数据集汇总
2.1.1 红外和可见光图像融合数据集
TNO(Toegepast-Natuurwetenschappelijk-Onder-zoek)数据集(https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029)是红外和可见图像融合常用数据集之一,包含60对军事相关场景的红外和可见光图像。INO(Institute National D’optique)数据集(https://www.ino.ca/en/technologies/video-analytics-dataset/videos/)由加拿大光学研究所提供,包含12对不同天气条件拍摄的红外和可见光视频。TNO数据集和INO数据集只包含少量图像对,无法用来训练性能优异的融合网络。为此,Xu等人(2022a)基于FLIR(forward-looking infrared)视频发布RoadScene数据集(https://github.com/hanna-xu/RoadScene),该数据集由221对已配准的红外和可见光图像组成,包含丰富的道路、车辆以及行人场景。此外,Tang等人(2022b)基于MFNet数据集(Ha等,2017)发布一个新的多光谱数据集MSRS(multi-spectral road scenarios)(https://github.com/Linfeng-Tang/MSRS),用于红外和可见光图像融合评估。其中,训练集包含1 083对图像,测试集包含361对图像,该数据集为每一对图像提供了语义分割标签,并提供了80对有目标检测标签的图像。该数据集能够促进高层视觉任务驱动的图像融合和基于高层视觉任务的图像融合评估的发展。借助于海康威视摄像机,Jia等人(2021)在夜间场景收集了15 488对红外和可见光图像对,发布了LLVIP(visible-infrared paired dataset for low-light lision)数据集(https://bupt-ai-cz.github.io/LLVIP/)。LLVIP数据集为每一个场景提供了相应的行人检测的标签,能够用于图像融合、行人检测和图像转换等多项任务。此外,Liu等人(2022a)基于构建的同步红外和可见光传感器成像系统,发布了一个多场景多模态数据集,即M3FD数据集(https://github.com/JinyuanLiu-CV/TarDAL)。M3FD数据集包含4 177对已配准的红外和可见光图像并标注了23 635个目标检测对象,场景覆盖白天、阴天、夜间以及一些具有挑战性的情形。值得强调的是,LLVIP数据集和M3FD数据集的发布能够促使研究者开展极端条件下的红外和可见光图像融合的研究。
2.1.2 医学图像融合数据集
Harvard数据集(http://www.med.harvard.edu/AANLIB/home.html)是一个用于机器学习的权威医疗数据集,涵盖医学影像、电子健康记录、UCI数据和生物医学文献,提供了大量CT-MRI,PET-MRI、SPECT-MRI、CT-SPECT图像对,用于医学图像融合模型的训练和评估以及智慧医疗诊断。
2.1.3 多曝光图像融合数据集
Cai等人(2018)利用7种相机在室内和室外场景收集了589个图像序列4 413幅不同曝光水平的高分辨率图像,并发布MEF数据集(https://github.com/csjcai/SICE),用于单幅图像曝光校正或多曝光图像融合任务的训练和测试。对每一个序列,采用13种多曝光图像融合算法或基于堆栈的HDR(high dynamic range)算法来生成对应的高质量参考图像。Zhang(2021)从互联网以及现有的多曝光图像融合数据库中收集了100对具有不同曝光水平的图像对,并发布了一个新的基准数据集MEFB(multi-exposure image fusion benchmark)(https://github.com/xingchenzhang/MEFB),用于多曝光图像融合算法的评估。
2.1.4 多聚焦图像融合数据集
Lytro数据集(https://mansournejati.ece.iut.ac.ir/content/lytro-multi-focus-dataset)是一个广泛用于评估多聚焦图像融合算法性能的数据集(Nejati等,2015),包含20对大小为520×520像素的彩色多聚焦图像以及4个具有3种焦距的多聚焦图像序列。MFI-WHU数据集(https://github.com/HaoZhang1018/MFI-WHU)是Zhang等人(2021a)基于MEF数据集以及MS-COCO数据集建立的多聚焦图像融合数据集,包含120对由高斯模糊和手动标注的决策图合成的多聚焦图像。值得注意的是,Lytro和MFI-WHU数据集都没能明显突出散焦扩散效应对多聚焦图像融合任务的影响。MFFW(multi-focus image fusion in the wild)(https://www.semanticscholar.org/paper/MFFW%3A-A-new-dataset-for-multi-focus-image-fusion-Xu-Wei/4c0658f338849284ee4251 a69b3c323908e62b45)数据集是Xu等人(2020d)提出的一个新基准数据集,用于测试多聚焦图像融合算法能否有效处理散焦扩散效应。与Lytro数据集相似,该数据集仅包含19对多聚焦图像。
2.1.5 多光谱与全色图像融合数据集

2.2 评估指标
各种定量评估图像融合算法的性能指标包括通用的评估指标和为多光谱与全色图像融合特别设计的评估指标。
2.2.1 通用评估指标
通用的图像融合评估指标能够用于评估多模图像融合和数字摄影图像融合,其中部分指标也能够用于评估多光谱与全色图像融合。根据其定义的不同,通用的指标可以分为基于信息熵的指标、基于图像特征的指标、基于相关性的指标、基于图像结构的指标以及基于人类感知的指标等5类。图5汇总了主流的通用图像融合评估指标。在通用图像融合评估指标中,A和B分别表示源图像A和源图像B,X泛指所有的源图像,F代表融合图像,M和N分别表示图像的宽和高。
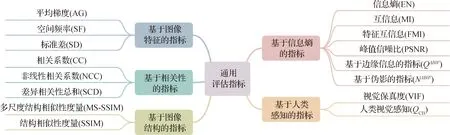
图5 通用图像融合评估指标汇总
1)基于信息熵的指标。
(1)信息熵(entropy, EN)是基于信息论计算融合图像中包含的信息量(Roberts等,2008)。具体定义为
(1)
式中,L为灰度级数,pl为融合图像中对应灰度级的归一化直方图。EN越高,意味着融合图像包含的信息越丰富。
(2)互信息(mutual information, MI)指标是基于信息论度量从源图像转移到融合图像的信息量(Qu等,2002)。具体定义为
MI=MIA,F+MIB,F
(2)
式中,MIA,F和MIB,F分别表示从源图像A和源图像B中转移到融合图像F的信息。特别地,MIX,F的具体定义为
(3)
式中,PX(x)和PF(f)分别表示源图像X和融合图像F的边缘直方图,PX,F(x,f)表示源图像与融合图像的联合直方图。融合图像的MI越高,意味着相应的融合算法从源图像中转移到融合图像中的信息越多。
(3)特征互信息(feature mutual information,FMI)是在MI和特征信息的基础上,度量从源图像中传输到融合图像的特征信息的量(Haghighat等,2011)。具体定义为
(4)

(4)峰值信噪比(peak signal-to-noise ratio,PSNR)表征融合图像中峰值功率与噪声功率的比值,能够从像素层面反映融合过程中的失真情况(Jagalingam和Hegde,2015)。具体定义为
(5)
式中,r表示融合图像的峰值,MSE表示均方误差,具体计算为
(6)


QAB/F=

(7)

(6)基于伪影的指标(NAB/F)用于衡量融合过程中引入的伪影(Petrovic和Xydeas,2005)。具体定义为

(8)

2)基于图像特征的指标。
(1)平均梯度(average gradient,AG)是通过测量融合图像的梯度信息并以此表征融合图像的纹理细节(Cui等,2015)的指标。具体定义为
(9)
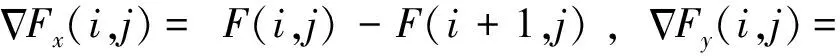
(2)空间频率(spatial frequency,SF)类似于AG,是通过测量融合图像的梯度分布揭示融合图像的细节和纹理信息(Eskicioglu和Fisher,1995)的指标。具体定义为
(10)
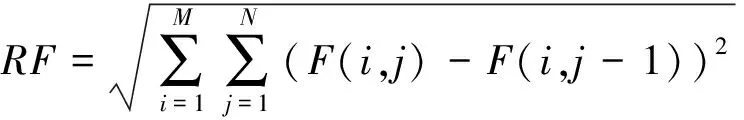
(3)标准差(standard deviation,SD)是反映融合图像的对比度及分布(Rao,1997)的指标。具体定义为
(11)
式中,μ表示融合图像的均值。人类视觉系统往往更能被具有高对比度的区域所吸引,因此具有更高SD的融合结果具有更好的对比度。
3)基于相关性的指标。
(1)相关系数(correlation coefficient, CC)是用于测量融合图像与源图像的线性相关程度的指标。具体定义为
(12)
式中,

(2)非线性相关系数(nonlinear correlation coefficient,NCC)是测量融合图像与源图像的非线性相关程度(Adu等,2013)的指标。具体计算为
(13)

(3)差异相关性总和(sum of correlation differences,SCD)是通过测量融合图像与源图像的差异来表征融合算法优劣(Aslantas和Bendes,2015)的指标。具体定义为
SCD=r(A,DA,F)+r(B,DB,F)
(14)
式中,DX,F表示融合图像F与源图像X的差分图像。SCD越高,意味着融合图像包含源图像中的信息越丰富。
4)基于图像结构的指标。
(1)结构相似性度量(structural similarity index measure, SSIM)是用于对融合过程中的信息损失和失真进行建模,并以此反映融合图像与源图像之间结构相似性(Wang等,2004)的指标。SSIM由相关性损失、亮度和对比度失真3部分构成。融合图像F与源图像X之间的结构相似性SSIMX,F定义为


(15)
式中,x和f分别表示源图像和融合图像在一个滑动窗口内的图像块。σxf表示源图像与融合图像的协方差,σx和σf分别表示源图像和融合图像的标准差,μx和μf分别表示源图像和融合图像的均值。C1、C2和C3是用来防止除数为零的常量。SSIM指标的计算式为
(16)
SSIM越大,说明融合图像越接近源图像,即融合过程中的信息丢失和失真越小。
(2)多尺度结构相似性度量(multi-scale structural similarity index measure,MS-SSIM)是在SSIM基础上,结合多尺度下的结构相似度综合评估融合图像失真情况(Wang等,2003)的指标。具体定义为
MS-SSIM(x,f)=[lM(x,f)]αM′×

(17)

5)基于人类感知的指标。
(1)视觉保真度(visual information fidelity,VIF)是基于自然场景统计和人类视觉系统(human vision system,HSV)量化融合图像F与源图像X之间共享的信息量(Han等,2013)的指标。使用融合图像信息源图像信息比值定义VIFX,F,具体为
(18)

(19)
VIF越高,意味着融合结果越符合人类视觉感知。
(2)人类视觉感知(QCB)是基于人类视觉系统衡量融合图像与源图像中主要特征的相似性(Chen和Blum,2009)的指标。具体定义为
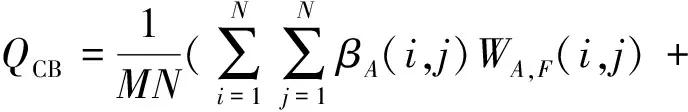
βB(i,j)WB,F(i,j))
(20)
式中,WA,F(i,j)和WB,F(i,j)表示从源图像A和B中转移到融合图像F的对比度,βA和βB分别代表WA,F(i,j)和WB,F(i,j)的显著图。QCB越大,意味着融合图像保留了源图像中更多的信息。
在上述指标中,EN、MI、FMI、PSNR、QAB/F、AG、SF、SD、CC、NCC、SCD、SSIM、MS-SSIM、VIF和QCB均为正向指标,即指标越高意味着越好的融合性能;而NAB/F为逆向指标,即指标越低意味着越好的融合性能。值得注意的是,上述指标都是仅从某一个角度反映算法的融合性能。因此在实际研究中,通常需要综合多种类别的评估指标来全面衡量融合算法的性能。为了便于研究者全面评估各种融合算法的性能,上述指标的MATLAB实现已开源至https://github.com/Linfeng-Tang/Evaluation-for-Image-Fusion。
2.2.2 多光谱与全色图像融合指标
通用图像融合评估指标中有部分指标,如PSNR、CC、SSIM和VIF也能够用来评估多光谱与全色图像融合,但是这些指标用于评估多光谱与全色图像融合任务时,都使用全分辨率多光谱(full resolution multi-spectral,FRMS)图像作为参考图像。
为多光谱与全色图像融合特别设计的指标通常分为全参考指标和无参考指标两类。用于定量评估多光谱与全色图像融合性能的指标如图6所示。在评估多光谱与全色图像融合性能的指标中,MS和PAN分别表示多光谱图像和全色图像,R代表参考图像,即全分辨率多光谱图像,F代表融合图像,M、N和B分别表示FRMS图像的宽、高和波段数。

图6 多光谱与全色图像融合评估指标汇总
1)全参考指标。
(1)均方根误差(root mean squared error,RMSE)是从像素层面反映融合结果与参考图像,即全分辨率多光谱图像之间差异的指标。具体定义为
RMSE=RMSE(F,R)=
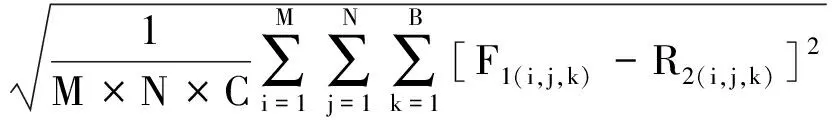
(21)
用于计算两幅图像之间的误差,B表示图像的波段数。RMSE越小,说明融合结果与参考图像之间的像素越接近,即性能更好。
(2)相对平均光谱误差(relative average spectral error, RASE)是在考虑所有光谱波段的情形下衡量融合算法平均性能的指标。具体定义为
(22)
式中,Fk和Rk分别表示融合图像和全分辨率多光谱图像第k个波段。r表示多光谱图像所有波段的平均辐射半径。
(3)相对全局误差(relative dimensionless global error in synthesis,ERGAS)是一个测量融合结果与全分辨率多光谱图像之间的平均误差和动态范围变化的全局指标(Ranchin和Wald,2000)。具体定义为
(23)

(4)光谱角映射(spectral angular mapper,SAM)是通过计算融合图像与参考图像之间的夹角来反映融合结果的光谱质量的指标,SAM将每个光谱通道视为坐标轴来计算相角(Yuhas等,1992)。假设F{i}=[F{i},1,…,F{i},B]为融合图像中的某个像素向量,R{i}=[R{i},1,…,R{i},B]是参考图像的某个向量,则F{i}和R{i}之间的SAM指标定义为
(24)
(5)通用图像质量评估指标(universal image quality index,UIQI)通过量化融合结果与参考图像的相关性、亮度和对比度相似度来表征融合性能(Wang和Bovik,2002)。UIQI指标也称Q指标,具体定义为
(25)
式中,σF和σR分别表示融合图像F和参考图像R的标准差,σFR表示融合图像F与参考图像R的协方差。μF和μR分别表示融合图像F和参考图像R的均值。从左至右各项的物理含义分别为相关性、平均亮度相似度和对比度相似度。UIQI越高,意味着融合图像与参考图像越相似。
(6)Q4指标是将Q指标扩展到4个通道向量上,即在Q指标的基础上,Q4指标进一步考虑了光谱失真(Alparone等,2004)。首先,Q4指标将每一个像素F{i}建模为四元数的组合,具体表示为
F{i}=F{i},1+K1F{i},2+K2F{i},3+K3F{i},4
(26)
式中,K1、K2和K3表示对应通道的加权系数。Q4指标的具体计算为
Q4(F{i},R{i})=

(27)
类似地,进一步将通道数推广到大于4,可以得到Q2n指标(Garzelli和Nencini,2009)。
2)无参考指标。
(1)光谱失真指标(Dλ)是度量融合图像与多光谱(MS)图像之间的光谱损失的指标(Alparone等,2008),其数学定义为
Dλ=

(28)
式中,p是强调较大光谱差异的正整数,在本文中,p设置为1。Dλ越小,意味着融合图像相较于多光谱图像的光谱失真越小。
(2)空间失真指标(Ds)是用于衡量融合图像与全色(PAN)图像之间的细节损失(Alparone等,2008)的指标。具体定义为
(29)
式中,PANLP表示多光谱图像具有相同尺寸的全色图像。在计算过程中应确保下采样的PAN图像与MS图像空间严格对齐,避免该指标产生偏差。
由式(29)可知,Ds与差分向量Q(Fi,PAN)-Q(MSi,PANLP)的q范数成正比,通过调整q的取值可以在计算过程中强调大的差分值。遵循Alparone等人(2008)方法,q取值为1。
(3)无参考指标(quality with no reference, QNR)是评估多光谱与全色图像融合算法最为主流的无参考指标,综合考虑了光谱失真和空间失真(Alparone等,2008)。QNR的具体定义为
QNR=(1-Dλ)α(1-Ds)β
(30)
式中,α和β是用于平衡光谱失真和空间失真的参数。当QNR=1时,意味着光谱失真和空间失真均为0。
(4)空间相关系数(spatial correlation coefficient SCC)是可以有效衡量融合图像与全色图像的空间信息相似性(Zhou等,1998)的指标。具体来说,SCC首先利用2D的高通滤波器提取全色图像和融合图像的高频细节信息,然后利用相关系数(CC)计算融合图像和全色图像的高频细节相关性。SCC越大,表明融合图像保留了更多的空间信息。
在上述指标中,UIQI、Q4、QNR和SCC属于正向指标,即指标越高意味着融合性能越好;RASE、ERGAS、SAM、Dλ和Ds属于逆向指标,即指标越低意味着融合性能越优异。
3 评 估
3.1 实验设置
为了全面分析不同算法的性能,在各类融合场景进行实验。在上述5类融合任务上对6种代表性算法进行定性和定量评估,并进一步分析运行效率。对红外和可见光图像融合,选取两种基于AE的算法,即DenseFuse(Li和Wu,2019)和RFN-Nest(Li等,2021a)、1种基于CNN的算法,即SeAFusion(Tang等,2022a)、1种基于GAN的算法,即FusionGAN(Ma等,2019b)和两种通用的图像融合框架,即IFCNN(Zhang等,2020d)和U2Fusion(Xu等,2022a)进行实验。其中,两种通用的融合框架也用于医学图像融合、多曝光图像融合和多聚焦图像融合任务的性能评估。用于评估医学图像融合任务的4种特定算法分别是3种基于CNN的方法,即Zero-LMF(zero-learning fast medical image fusion)(Lahoud和Süsstrunk,2019)、EMFusion(Xu和Ma,2021)和DPCN-Fusion(detail preserving cross network fusion)(Tang等,2021)以及1种基于GAN的算法,即DDcGAN(Ma等,2020c)。用于评估多曝光图像融合任务的4种特定算法分别是两种基于CNN的算法,即DeepFuse(Prabhakar等,2017)和DPE-MEF(Han等,2022)以及两种基于GGAN的算法,即MEF-GAN(Xu等,2020b)和AGAL(Liu等,2022c)。用于评估多聚焦图像融合任务的4种特定算法分别是两种基于CNN的算法,即DPRL(deep regression pair learning)(Li等,2020c)和SESF-Fuse(Ma等,2021a)以及两种基于GAN的算法,即MFF-GAN(Zhang等,2021a)和MFIF-GAN(Wang等,2021b)。用于评估多光谱与全色图像融合的6种算法分别是4种基于CNN的算法,即PNN(Masi等,2016)、PanNet(Yang等,2017)、SDPNet(Xu等,2021a)和GTP-Pnet(Zhang和Ma,2021a)以及两种基于GAN的算法,即Pan-GAN(Ma等,2020d)和PSGAN(Liu等,2021a)。用于评估红外和可见光图像融合算法的图像来自TNO数据集,同时使用Harvard数据集的PET图像和MRI图像评估医学图像融合算法的性能。评估多曝光图像融合算法和多聚焦图像融合算法的图像分别来自MEFB数据集和Lytro数据集。同时本文从这些数据集中各随机选取20对图像进行定量评估。QuickBird卫星捕获的全色图像和多光谱图像用于评估多光谱与全色图像融合算法的性能。需要注意的是,对于降分辨率测试,全色图像裁剪为132幅264×264像素的图像块,多光谱图像裁剪为132幅66×66像素的图像块。对于全分辨率测试,全色图像裁剪为74幅1 056×1 056像素的图像块,多光谱图像裁剪为74幅264×264像素的图像块。所有的源图像都是事先配准好的,即所有的源图像在空间上严格对齐。实验选择6种通用评估指标用于定量评估多模图像融合和数字摄影图像融合任务。分别是两种基于信息熵的指标MI和PSNR、1种基于图像特征的指标SF、1种基于相关性的指标CC、1种基于图像结构的指标SSIM和1种基于人类感知的指标VIF。由于多光谱与全色图像融合任务的特殊性,因此6种针对多光谱与全色图像融合任务设计的指标包括3种全参考指标即ERGAS、SAM和SSIM以及3种无参考指标即Dλ、Ds和QNR,用来全面评估多光谱与全色图像融合算法的性能。需要注意的是,3种全参考指标是基于降分辨率测试统计的,而3种无参考指标是基于全分辨率测试计算的。
3.2 定性评估
图7—图9展示了不同算法在各类融合任务上的可视化结果,每类融合任务选择了两个代表性的场景反映不同融合算法的差异。
多模图像融合的可视化结果如图7所示,对于红外和可见光图像融合任务,所有算法在一定程度上集成了源图像中的互补特性。FusionGAN有效保持了红外图像的显著对比度和显著目标,但忽略了可见光图像中的纹理细节。DenseFuse、RFN-Nest和U2Fusion将部分可见光图像中的细节信息注入到融合图像中,却在一定程度上削弱了红外目标的强度。IFCNN保持了红外图像的显著目标,却丢失了部分纹理细节信息。特别地,上述算法在第1行天空区域均遭受不同程度的热辐射污染。值得强调的是,SeAFusion在保持显著目标强度的同时,有效保留了可见光图像中的丰富纹理细节。对于医学图像融合,6种对比算法在一定程度上整合了MRI图像中的结构信息以及PET图像中的功能信息。但不同算法的表现仍有所差异。特别地,Zero-LMF在融合过程中引入了伪影,而DDcGAN没能有效保留MRI图像中的结构信息。类似现象也发生在IFCNN和U2Fusion算法上,如第3行中的绿色矩形框所示,上述两种算法削弱了MRI图像中的结构信息。

图7 多模图像融合定性对比结果
图8是数字摄影图像融合的可视化结果。对于多曝光图像融合,大部分算法能够校正源图像的曝光,但有所差异。其中,DeepFuse、MEF-GAN、IFCNN和U2Fusion虽然能够在一定程度上点亮欠曝区域,但是效果并不显著。相对来说,DPE-MEF和AGAL能够以较好的曝光水平呈现源图像中的场景信息,DPE-MEF甚至能够在过曝图像的基础上进一步提升暗处的细节信息,如第1行红色矩形框所示。此外,DPE-MEF、MEF-GAN和AGAL在融合过程中考虑了色彩信息,因此这些算法生成的融合结果具有更加鲜艳的色彩。对于多聚焦图像融合而言,不同算法均能结合源图像中聚焦区域的信息并生成一幅全聚焦的清晰图像。各种算法的主要区别在于能否有效处理散焦扩散效应。如图8第3行所示,基于决策图像的方案DPRL、SESF-Fuse和MFIF-GAN能够有效避免散焦扩散效应造成的视觉效果退化,主要由于这类算法在融合过程中考虑了散焦扩散效应。而基于整体重构的方案,如MFF-GAN、IFCNN和U2Fusion则遭受了不同程度的散焦扩散效应的影响。特别地,MFF-GAN和U2Fusion在融合过程中改变了源图像中的强度分布,从而导致某些纹理细节信息被淹没,如第4行红色矩形框所示。

图8 数字摄影图像融合定性对比结果
遥感影像融合的可视化结果如图9所示。从图中可以看到,除Pan-GAN外,其他算法得到的融合结果的色彩均能与FRMS图像(或MS图像)保持一致,这意味着Pan-GAN的光谱失真较为严重。此外,PNN、PanNet、SDPNet、GTP-PNet和PSGAN能够在一定程度上维持较好的空间结构,其中PNN和PSGAN效果最为突出。但是以上算法均无法像FRMS图像那样将场景中细节信息清晰地呈现。

图9 遥感影像融合定性对比结果
3.3 定量评估
多模图像融合和数字摄影图像融合的定量比较结果如表5和表6所示。

表5 多模图像融合定量比较结果

表6 数字摄影图像融合定量比较结果
对于红外和可见光图像融合任务,DenseFuse在CC和SSIM指标上均是最优的,意味着DenseFuse生成的融合结果与源图像的相关性最高,同时其空间结构与源图像保持最为一致。此外,SeAFusion在MI指标上远远领先其他算法,意味着SeAFusion在融合过程中尽可能多地将源图像中的信息转移到了融合图像中。SeAFusion取得了最高的VIF,表明SeAFusion获得的融合结果更加符合人类的视觉感知,这与定性分析的结果高度吻合。作为通用图像融合框架,IFCNN在SF和PSNR指标上均取得了最好效果,意味着有IFCNN生成的融合图像包含更多的细节信息,同时在融合过程中的失真较小。另一种通用图像融合框架U2Fusion在CC、VIF和PSNR指标上均取得了次优效果,说明尽管是针对多种融合任务设计的通用融合框架,在特定任务上仍能取得较好表现。
对于医学图像融合任务,各类算法的性能优势在不同指标上有所差异。特别地,作为通用图像融合框,U2Fusion在CC和PSNR指标上取得了最好的表现,而IFCNN在SSIM指标上达到了最优的性能,并且在CC和PSNR上的性能也是次优的。此外,Zero-LMF、DPCN-Fusion和DDcGAN分别在MI、VIF和SF指标上取得了最好效果。与定性评估有所出入的是,EMFusion在定量评估中表现略为普通,只在VIF和SSIM指标上取得了次优效果。
对于多曝光图像融合任务,DeepFuse在MI、CC、VIF和SSIM等大部分指标上取得了最优效果。而定性评估中表现颇好的DPE-MEF仅在SF指标上取得了最好效果,意味着DPE-MEF获得的融合图像能够呈现更多的纹理细节信息,这与可视化结果相吻合。而通用图像融合框架之一,IFCNN在PSNR指标上取得了最好效果,并在VIF和SSIM指标上取得了次优效果。
对于多聚焦图像融合任务,不同融合算法在定量评估中表现大同小异,在SF指标上,大部分算法取得了较好结果。SESF-Fuse在VIF和SSIM指标上取得了最好效果,IFCNN在PSNR和SSIM上取得了最好效果。MFIF-GAN和U2Fusion分别在MI和CC指标上取得了最好效果。DRPL在MI、SF、VIF和PSNR上取得了次优结果。由于不同算法在多聚焦图像融合任务上的定量评估差异并不特别明显,因此定性评估对于该任务更为重要。
多光谱与全色图像融合任务的定量评估结果如表7所示。由表7可知,PSGAN在全参考指标ERGAS、SAM和SSIM上达到最优性能,意味着PSGAN获得的锐化图像在像素层面和图像结构上都最接近参考图像。最好的SAM意味着PSGAN在降分辨率测试上具有最小的光谱失真。此外,PNN在降分辨率测试中取得了次优的ERGAS和SSIM,与定性评估结果保持一致。在无参考指标中,Pan-GAN取得最优的Ds和QNR,意味着Pan-GAN在全分辨率测试中具有最小的空间失真。而PNN在Dλ指标上取得了最好效果,表明PNN具有最小的光谱失真。

表7 遥感影像融合定量比较结果
3.4 运行效率
运行效率是另一个衡量基于深度学习的融合算法优劣的重要因素。不同算法在各类融合任务上的平均运行时间如表8所示。其中,多光谱与全色图像融合是在降分辨率测试上统计的平均运行时间。由结果可知,IFCNN在医学图像融合、多曝光图像融合和多聚焦图像融合等任务上达到最高的运行效率。而SeAFusion和PSGAN分别在红外和可见光图像融合以及多光谱与全色图像融合等任务上具有最快的运行效率。以上算法都具有网络结构简单、模型参数量少等特点,因而能够在保证融合性能的条件下实现实时图像融合。所有对比算法中,除了Zero-LMF、MEF-GAN和MFIF-GAN,其他算法均能在1 s内生成一幅融合图像。
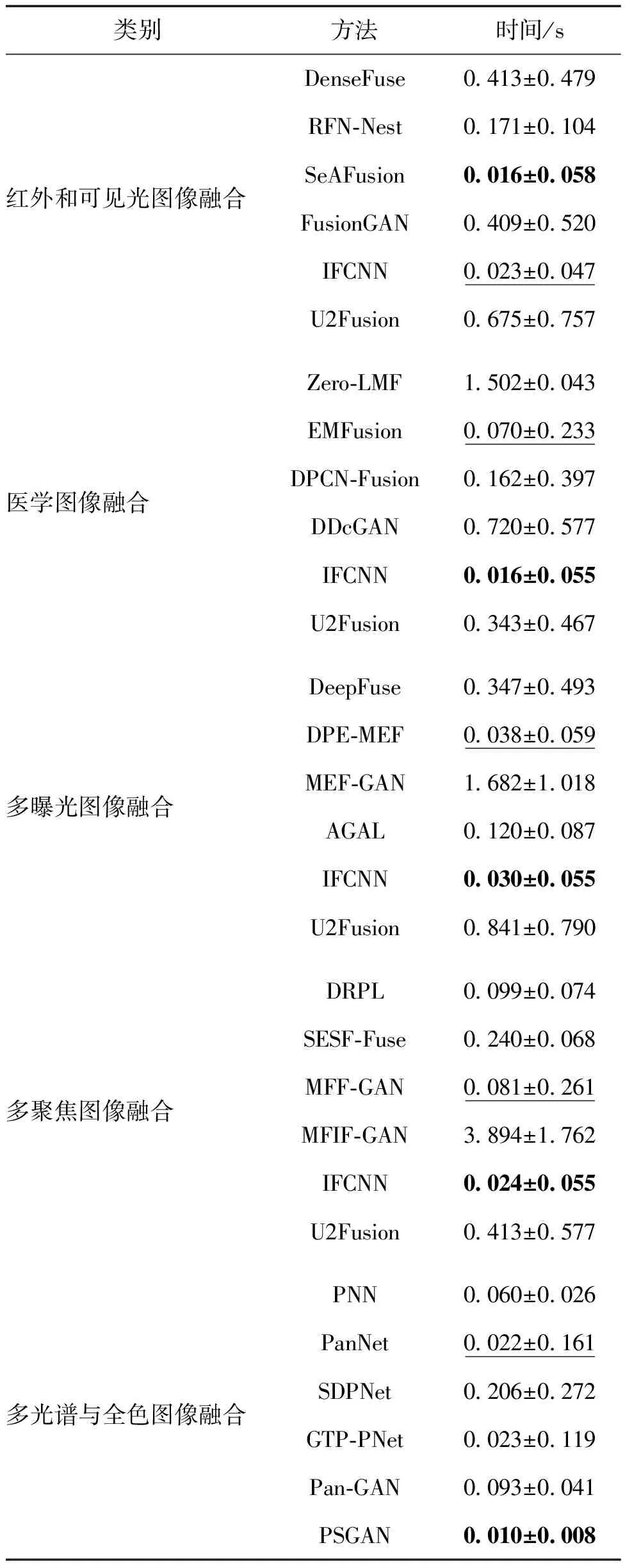
表8 不同算法在各类融合任务上的平均运行时间
4 结 语
作为一项重要的图像增强技术,图像融合在目标检测、语义分割、临床诊断、遥感监测、视频监控和军事侦察等任务中发挥着至关重要的作用。随着深度学习技术的不断进步,基于深度学习的各类图像融合算法不断涌现。为使相关领域的研究人员快速了解基于深度学习的融合算法,把握基于深度学习的图像融合研究的发展脉络,本文综合分析了图像融合领域最前沿的基于深度学习的图像融合算法。结合具体的融合场景,本文从网络架构和监督范式等多个角度详细阐述了各类方法的基本思想并讨论了各类方法的特点,同时针对现有算法的局限性,提出了进一步的改进方向。此外,为了方便相关人员开展研究,详尽介绍了不同融合任务中常用的数据集和评估指标。对每一类融合任务,从定性评估、定量评估以及运行效率等多个角度分析了代表性方法的性能。
尽管深度学习在图像融合领域取得了巨大成功,但仍存在一些严峻挑战和难题。
1)未配准图像融合。现有图像融合算法均要求源图像在空间上是严格对齐的。然而在实际应用中,由于镜头畸变、尺度差异、视差以及拍摄位置的影响,无论是不同传感器拍摄的图像还是数码相机在不同设置下拍摄的图像都无法实现严格的空间对齐。通常情况下,需要使用成熟的图像配准算法或手工标注在融合前配准源图像(Jiang等,2021)。已有的配准算法能够成功配准相同模态的图像,但对于多模图像,尚未有对大规模多模图像鲁棒的配准算法。事实上,多模图像融合能够削弱多模数据中的模态差异,并降低冗余信息对配准过程的影响。尽管已有算法,如RFNet(Xu等,2022b)在近红外和可见光图像融合任务中充分利用了上述特性,但是近红外和可见光模态差异相对较少,且RFNet仅能应对相对简单的场景。因此,期待在模态差异更显著的融合场景(如红外和可见光图像融合、医学图像融合)中开发图像配准—图像融合相辅相成的鲁棒算法。
2)高层视觉任务驱动的图像融合。图像融合能够充分集成源图像中的互补信息以全面表征成像场景,为提升后续视觉任务的性能提供了可能。然而,大部分融合算法通常忽略了后续视觉任务的实际需求,只是片面追求更好的视觉效果和评估指标。尽管SeAFusion(Tang等,2022a)进行了初步探索,但是图像融合与高层视觉任务仅通过损失函数建立连接。因此,未来应该进一步将高层视觉任务的需求建模到整个图像融合过程中,进一步提升高层视觉任务的性能。
3)基于成像原理的图像融合。不同类型传感器或不同设置的传感器通常具有不同的成像原理。在成像原理上的差异虽然为网络结构和损失函数的设计带来了障碍,但也为融合算法的设计提供了更多的先验信息。深入剖析不同类型传感器或不同成像设置的传感器的成像原理,并将其建模至融合过程中有助于进一步提升融合性能,尤其是从成像角度建模多聚焦图像中的散焦扩散效应值得深入探索。
4)极端条件下的图像融合。现有的图像融合算法均是基于正常成像场景设计的。然而在实际应用中往往需要应付极端情形,例如欠曝、过曝以及严重噪声等。对于红外和可见光图像融合,往往需要在夜间通过综合红外图像和可见光图像中的信息全面感知成像场景,然而此时可见光图像中的信息往往淹没在黑暗中并伴随严重噪声。因此,设计有效的融合算法在聚合互补信息的同时挖掘隐藏在黑暗和噪声中的信息至关重要。此外,现有的多曝光图像融合算法大多未针对极端的曝光情形设计,当这些融合算法应用至极端曝光情形时往往会出现严重的性能退化,如何充分挖掘极度欠曝图像中的信息并有效抑制极度过曝图像造成的不良影响将是一重大挑战。
5)跨分辨率的图像融合。由于成像原理的差异,不同类型传感器捕获的图像往往具有不同的分辨率,如何克服分辨率差异并充分整合不同源图像中的有效信息是一个严峻挑战。虽然已有算法(Huang等,2020a;Ma等,2020c;Li等,2021b)解决跨分辨率的图像融合,但仍存在一些问题。例如,采用何种上采样策略以及上采样层在网络中的位置等。将图像超分与图像融合有机结合并设计网络结构和损失函数是解决这一难题的思路之一。
6)实时图像融合。图像融合通常作为高层视觉任务的预处理手段或摄影设备的后处理过程。对于高层视觉任务,往往对预处理过程具有较高的实时性要求。对于摄影设备,人们期望能够在不可察觉的时间内实现多幅输入图像到单幅融合图像的转换。但是,摄影设备的硬件能力往往有限。因此,在保障融合性能的前提下,开发轻量级的实时图像融合算法对于扩宽图像融合算法的应用场景具有至关重要的作用。
7)彩色图像融合。大部分现有的图像融合算法通常将彩色图像转换至YCbCr空间,然后仅使用亮度(Y)通道作为深度网络的输入得到融合后的亮度通道,而色度通道(Cb和Cr通道)采用传统的策略进行简单融合。事实上,色度通道也包含对全面表征成像场景有用的信息,在融合过程中考虑色彩信息将为网络提供更加丰富的互补信息。而基于深度网络自适应调整融合结果的色彩信息有助于获得更加生动的融合结果,这对于提升数字摄影图像融合的视觉效果尤为重要。
8)全面的评估指标。由于大部分图像融合(多模图像融合和数字摄影图像融合)任务缺乏参考图像,因此如何全面评估不同算法的融合性能是一个巨大挑战。现有的评估指标往往仅能从某一个角度出发,片面地评估融合性能。而一种融合算法往往无法兼顾所有的评估指标。因此,设计具有更强表征能力的无参考指标全面评估不同融合算法的性能对于图像融合领域来说至关重要。首先,一个全面的评估指标能够更加公平地评估不同融合结果的优劣,从而更好地引导后续研究。其次,能够全面评估融合性能的无参考指标有助于更好地构造损失函数来引导深度网络的优化。
基于以上回顾和展望,可以发现已有融合算法的性能并未达到图像融合任务的上限。基于成像原理的图像融合、彩色图像融合以及全面评估的图像融合指标能够使融合性能进一步提升,未配准图像融合、高层视觉任务驱动的图像融合以及跨分辨率的图像融合能够使图像融合获得更大的应用价值,实时图像融合研究能够使图像融合任务具有更广阔的应用前景。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
家庭影院技术(2021年7期)2021-08-14
空间科学学报(2021年1期)2021-05-22
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
家庭影院技术(2020年8期)2020-09-11
作文小学中年级(2020年6期)2020-07-24
收藏界(2019年4期)2019-10-14
中国光学(2015年5期)2015-12-09
太空探索(2014年11期)2014-07-12
食品工业科技(2014年23期)2014-03-11
