
红外与可见光图像分组融合的视觉Transformer
2023-02-18 03:06孙旭辉官铮王学
中国图象图形学报 2023年1期
孙旭辉,官铮,王学
云南大学信息学院,昆明 650500
0 引 言
图像融合作为信息融合的分支,是目前信息融合研究的热点。红外与可见光图像融合(infrared and visible image fusion,IVF)是图像融合领域最广泛的研究之一(Ma等,2019a)。可见光图像由捕获反射光的可见光传感器产生,具有丰富的细节信息,如颜色、对比度和纹理等,且更符合人眼的观察模式,但在一些恶劣天气环境下会严重影响人眼的观察,不利于获取有效信息。利用热传感器获取的红外图像具有强烈的热辐射信息,可以在背景中显著地突出目标,但缺少图像的细节纹理。因此,将同一场景的可见光图像和红外图像融合,可以有效地结合两者的优势,使融合图像既具有红外图像的热辐射目标信息,又能够具有可见光图像丰富的纹理细节。红外与可见光图像融合已广泛应用于目标追踪、自动驾驶和视频监测等领域。
对于IVF任务,理想目标是从红外和可见光样本中重构出一个完美的场景图像,这些样本提供了关于视觉内容的互补信息。为了实现这一目标,研究人员提出了许多IVF方法。这些方法主要分为基于传统方法和基于深度学习的方法两类。
传统的融合方法在空间域或变换域提取图像特征,根据特定的融合规则实现图像融合。典型的传统融合算法有基于多尺度变换的方法(Pajares和 de la Cruz,2004;霍星 等,2021;宫睿和王小春,2019)和基于稀疏表示(sparse representation,SR)的方法(Li等,2012)等。基于多尺度变换的方法通过多尺度变换提取源图像的特征,根据不同的融合任务,采用特定的融合规则进行特征融合,最后通过多尺度反变换生成最终的融合图像。显然,这类方法的融合结果高度依赖于特征提取手段。因此,研究者为了有效提取图像特征,提出了基于稀疏表示的方法。在基于稀疏表示的方法中,将源图像通过滑动窗口技术分解为图像块,利用这些图像块构造一个矩阵,矩阵的每一列都是一个重构后的图像块,通过该矩阵计算SR(sparse representation)系数,并将其视为图像特征。通过以上操作,可将图像融合问题转化为系数融合问题,融合系数由一个适当的融合策略产生并用于重建融合图像。这些传统方法取得了不错的融合表现,但也存在不足:1)融合图像的质量严重依赖人工设计的特征提取手段,导致提取的特征不具有广泛的通用性;2)对于不同的特征需要采用不同的特征融合规则。
基于深度学习的图像融合方法可以有效克服传统方法的缺点,逐渐成为一种更可靠的方法。这些方法首先利用神经网络强大的特征表示能力提取更丰富的图像特征,这些特征更具有通用性。然后采用适当的融合策略和重建策略得到最终的融合图像。基于生成性对抗网络(generative advisional networks,GAN)的方法在融合图像与源图像之间创建对抗性游戏以实现图像融合(Ma等,2019b),但网络结构和损失函数设计不合适时,会导致源图像信息丢失,降低融合性能。基于卷积神经网络(convolutional neural networks,CNN)的融合技术通过卷积提取图像特征(Zhang等,2020;Li等,2021),提高了特征的通用性,但由于卷积机制的限制,无法有效提取图像中的全局上下文信息,导致提取的图像特征信息不足,降低了融合图像的质量。
为了解决上述问题,本文提出一个基于视觉Transformer和分组渐进式融合策略的端到端无监督的红外与可见光图像融合网络。该网络包括两个主要模块,即局部—全局特征提取模块(local-global feature extraction module,LGFE)和分组渐进式融合模块(grouped progressive fusion module,GPF),分别用来提取图像特征和融合图像特征。局部—全局特征提取模块通过联合CNN和视觉Transformer组成混合模型来提取图像的局部细节特征和全局上下文特征(局部—全局特征),可以使提取到的图像特征既具有CNN提取特征的通用性,又具有视觉Transformer的全局性。另外,为了更充分有效地融合提取到的局部—全局图像特征,设计了分组残差式融合模块,该模块先对特征进行分组,然后构建一种分层残差式的结构对分组特征进行融合,这种分层残差式的结构可以在融合过程中体现多尺度性,并且减少融合过程中信息的丢失,从而获得更高质量的融合结果。
1 相关工作
1.1 基于深度学习的图像融合方法
早期研究人员使用预先训练好的网络提取图像特征,将特征进行适当的融合从而获取融合图像。Li等人(2018)将源图像分解为突出部分和基础部分,突出部分主要包含纹理和细节信息,基础部分主要是轮廓和亮度。通过预训练网络VGG-19(Visual Geometry Group 19)(Simonyan 和 Zisserman,2015)提取突出部分的多层次深度特征,并计算每一层深度特征中的特征突出部分,通过合理的融合策略将这些深度特征突出部分与基础部分进行融合,最后重建出融合后的图像。虽然这种基于预训练网络的方法取得了不错的效果,但VGG-19是为了图像分类任务设计的,可能对图像融合任务的适用性并不理想。Ma等人(2019b)提出了FusionGAN(generative adversarial network for infrared and visible image fusion), 首次将GAN用于红外与可见光图像的融合任务中。融合图像由生成器生成,生成的图像与可见光图像之间的相似度由判别器判断。虽然设计了内容损失和对抗损失来约束网络,但保留可见光图像中的细节纹理的能力仍有欠缺。因此,Ma等人(2020)提出了FusionGANv2,通过设计细节损失和目标边缘增强损失来改善融合图像的细节信息和热辐射信息。Li等人(2021)提出RNF-nest(residual fusion network for infrared and visible images),分别为特征提取和特征融合阶段训练网络。首先将编码器和解码器网络训练成自动编码器,可以用来提取特征并重建它们。在固定编码器和解码器的情况下,设计适当的损失函数训练特征融合网络,并使用它代替手动融合策略。Fu和Wu(2021)通过设计细节和语义双分支的自动编码器分别提取图像中的细节信息和语义信息,为了获得全局语义信息,设计了一种快速降采样网络结构,该结构通过3次下采样并且扩展通道数,再将下采样之后的特征通过一次上采样还原到原始大小,最后与细节分支的特征拼接获得最终特征。虽然该方法考虑了图像的全局信息,但由于下采样操作会导致信息丢失,所以在本文中采用视觉Transformer来提取全局信息。
1.2 视觉Transformer
Transformer最初是用于自然语言处理(natural language processing,NLP)领域(Vaswani等,2017)。Transformer是一种基于自注意力(self-attention,SA)的结构,设计用于序列建模和转导任务,以其关注数据中的长期依赖性而闻名。受NLP中自注意力机制巨大成功的启发,一些基于CNN的模型使用空间注意力和通道注意力,或同时使用这两种方法捕捉图像中的显著特征。虽然这些注意力模型取得相当好的效果,但仍然不及CNN模型。
受NLP中Transformer的巨大成功的启发,许多工作将Transformer应用到计算机视觉(computer vision, CV)领域。Dosovitskiy 等人(2021)提出一种视觉Transformer,将完整图像分割成许多16×16像素的图像块作为网络的输入,使用与NLP中一样的Transfomer结构进行特征提取,并将其应用于图像分类任务,在许多图像分类基准上实现了最先进的表现。Liu等人(2021)提出一种称为Swin Transformer的视觉Transformer,其可以作为计算机视觉的通用主干,表现是通过移动窗口来计算自注意力。移位窗口方案通过将自注意力计算限制在不重叠的局部窗口上,同时允许跨窗口连接,从而提高计算效率。这种层次结构提供了在不同尺度下建模的灵活性,并且相对于图像大小具有线性计算复杂性。Swin Transformer在COCO(Microsoft common objects in context)对象检测和ADE20K语义分割方面取得了最好的性能,优于之前最好的方法。基于视觉Transformer的方法在图像恢复任务中也取得了优异的效果。Zamir等人(2022)提出了一种高效的Transformer模型Restormer用来处理图像恢复任务。Restormer通过在通道维度而不是空间维度上进行自注意力计算,不仅可以捕获图像的全局上下文信息,还能节省计算开销。它的输入可以是一幅完整的图像,而无需将图像分割为多个图像块。本文方法中的局部—全局特征提取模块中,借鉴使用了Restormer中的多头转置注意力(multi-dconv head transposed attention,MDTA)模块。在图像融合领域,Li等人(2022)设计了一种卷积引导的视觉Transfomer用于红外与可见光图像融合(convolution-guided transformer for infrared and visible image fusion,CGTF),运用CNN和视觉Transformer相结合的思想提取图像特征,以获得更出色的融合结果。Ma等人(2022)提出基于Swin Transformer的通用图像融合网络(cross-domain long-range learning for general image fusion via Swin transformer,SwinFusion),可以在统一的融合框架下实现多模态图像融合和数字图像融合,并且设计一种注意力引导的跨域融合模块,对同一域内和跨域的长依赖关系进行提取和集成。这两种方法都是在像素维度上进行自注意力计算,而本文是在通道维度上计算特征图之间的自注意力,这种做法可以避免自注意力的计算量随图像素大小增大而增大的问题,并且相比CGTF,本文方法不用固定输入图像的尺寸,可以灵活运用。
2 本文方法
2.1 网络总体结构
本文提出的端到端无监督图像融合网络的总体结构如图1所示。该网络的特征提取阶段采用两个支路分别提取红外图像特征和可见光图像特征,两个支路结构一样,但不共享参数。首先,通过两个卷积块提取输入图像的浅层特征,卷积块由3×3卷积、批归一化层(batch normalization,BN)和LeakyReLU激活函数组成。然后,通过LGFE模块提取局部—全局特征,并将提取的局部—全局特征通过分组渐进式融合模块进行融合。最后,将由3个卷积块组合的解码器解码得到最后的融合图像。

图1 网络总体结构
2.2 局部—全局特征提取模块
局部—全局特征提取模块结构如图2(a)所示,有一个上分支(局部细节分支)和一个下分支(全局结构信息分支)。局部细节分支的结构类似于DenseNet(densely connected convolutional network)(Huang 等,2017),由4层密集块结构组成,这种密集连接的网络结构可以使细节分支更好地学习原始图像的浅层细节特征。卷积每一层的输入与前几层的输出相连接,第q层的输出Xq=Fq(cat(X0,X1,X2,…,Xq-1)),其中,Fq表示非线性变换,包括3×3卷积和LeakyReLU激活函数。cat(X0,X1,X2,…,Xq-1)表示将之前所有层的输出进行拼接操作。
在全局分支中,使用MDTA和SE模块(squeeze and excitation network)(Hu等,2020)组合作为视觉Transformer。MDTA模块如图2(b)所示。MDTA解决了SA的计算工作量随着输入的空间分辨率呈二次增长的问题。MDTA减少计算工作量的关键在于跨通道而非空间维度应用SA。

图2 局部—全局特征提取模块


FA(Q,K,V)=V×Fsm(K×Q/α)
(1)
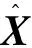

(2)
式中,Y代表最终的输出特征图,FAVG(·)表示平均池化(average pooling)操作,COV3×3(·)表示3×3的卷积操作加上LeakyReLU激活函数,FS(·)表示sigmoid激活函数。
2.3 分组渐进式融合模块
将提取的特征图进行高质量的融合也是至关重要的,但大部分端到端的图像融合网络都只是简单地将特征图拼接在一起,无法有效融合特征,受Res2Net(Gao等,2021)的启发,本文将输入的特征图分为多个组,然后融合相应的组,最后通过渐进策略将不同组的特征融合在一起。分组渐进式融合模块如图3所示。
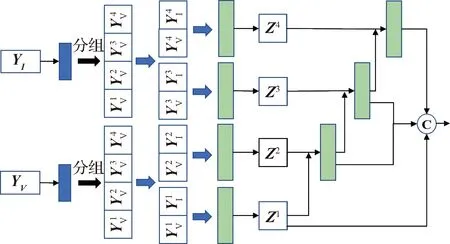
图3 分组渐进式融合模块



M=cat(Z1,Z2,…,Zi)
(3)
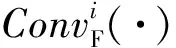
2.4 损失函数
为了使融合图像信息丢失最小化,获得更好的融合表现,本文采用3种不同的损失函数训练网络,分别为均方误差损失函数、结构相似性损失函数以及感知损失函数(Johnson等,2016)。这3种损失函数分别从像素强度、结构相似性和特征图差异3个方面约束融合图像和源图像之间的差异性。总损失函数表达为
LT=LS+λ1LM+λ2LP
(4)
式中,LT表示网络的总损失函数,LS、LM和LP分别代表结构相似性损失函数、均方误差损失函数和感知损失函数。λ1和λ2为超参数,用来控制3种损失之间的比例大小。根据以往的经验,本文设置λ1= 10,λ2= 1。
LS计算融合图像和源图像(红外图像和可见光图像)之间的结构相似性。公式描述为
LS=fSSIM(IF,II)+fSSIM(IF,IV)
(5)
式中,IF为融合图像,II为红外图像,IV为可见光图像。fSSIM(x,y)表示x与y之间的结构相似性,具体为
(6)
式中,μx和μy分别为x和y的平均数,σx和σy分别为x和y的方差,σxy为x与y之间的协方差,c1和c2为两个不同的常数。
LM可以计算融合图像与输入图像之间的像素误差,红外图像以像素强度为特征,因此为了保留红外图像中更多的红外像素强度信息,本文方法只计算融合图像与红外图像之间均方误差。LM详细描述为
LM=fMSE(IF,II)

(7)
式中,fMSE(x,y)表示计算x与y之间的均方误差。
LP为感知损失,利用预训练的VGG-19提取图像多个的特征图,再通过计算特征图之间的均方误差得到最终损失。详细描述过程为
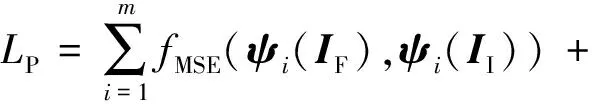

(8)
式中,m为4,ψi(·)表示第i层特征。
3 实 验
3.1 实验设置
实验使用的训练集和测试集都来自公开可用的数据集。本文提出的网络在TNO(TNO image fusion dataset)图像融合数据集上进行训练和测试。TNO数据集是标准红外和可见光图像对数据集,包括大约60对红外和可见光图像,主要描绘军事场景内容。训练深度学习网络需要大量数据,60对图像显然不够,因此在训练阶段,从TNO数据集中随机选择20对图像,然后按步长为14裁剪成128 × 128像素大小,最终获得30 360对图像作为训练集。网络参数由Adam优化器更新,初始学习率为0.000 1,使用自适应学习率下降法作为学习率调度器,忍耐系数为15个周期,调整系数为0.1。批大小设置为32,历元设置为50。本文网络模型在Pytroch中实现。实验在NVIDIA GeForce RTX 3090 GPU和2.80 GHz Intel Core i9-10900F CPU上进行。
在测试阶段,从TNO数据集中选择20对图像作为测试数据集。此外,为了证明模型的泛化性,还使用RoadScene数据集作为测试集,这是Xu等人(2022)创建的一个图像融合数据集,其中有221对红外和可见光图像精确对齐,这些图像对是FLIR(free flir thermal dataset)视频中具有高度代表性的场景。数据集中的主要场景是道路,包括车辆、行人、建筑物和其他目标。实验选择40对具有代表性的图像作为测试集。
3.2 TNO数据集对比实验
3.2.1 定性比较
TNO数据集上5个典型图像的定性比较结果如图4所示。

图4 各种方法在TNO数据集上的结果
从图4可以看出,在视觉效果方面,本文方法较对比方法有优势。首先,本文方法可以有效保留可见图像中的纹理细节,丰富的纹理细节可以提供更多的信息,使融合图像的视觉效果更加清晰。与此同时,还可以有效保留红外图像中显著的热辐射信息,使热辐射目标在背景中突出显示。
在第1、2列图像中,本文方法很好地保留了红外图像和可见光图像的互补信息,第1列图像中的楼梯以及第2列图像中的人和车辆在可见光图像中并不明显,但在红外图像中显著突出,本文方法很好地保留了这些信息。在DenseFuse、FusionGAN和MDLatLRR方法中,红外目标并不突出,并且存在一些伪影。在DRF中,第1、2列图像背景中的云都消失了。而本文方法有效避免了这些缺陷。第3列图像中的可见光图像十分模糊,而红外图像相对清晰,6种对比方法的结果从整体上看都有轻微的模糊现象,而本文方法从整体上看更清楚,并且很好地保留了路灯、帐篷等细节信息。第4、5列的图像结果证明了本文方法在保持边缘能力上较其他对比方法更具有优势。DRF和FusionGAN在第5列图像中的灌木丛并不清晰,说明保留边缘能力不强。DenseFuse和DualFuse方法在图像整体对比度上有所欠缺。而本文方法在整体对比度上效果更好,并且能更好地保留边缘信息。
根据图4的结果对比分析,可以发现本文方法可以充分保留红外图像和红外图像中的互补信息,将这些有用的信息有效融合,避免了融合图像红外目标不显著、边缘和背景模糊等缺陷。
3.2.2 定量比较
为进一步说明本文方法的有效性,在TNO数据集中的20对图像上进行定量分析,20对图像的指标结果如图5所示,表1表示20对图像在6个评价指标上的均值。从表1可以看出,本文方法在NMI、QNICE、AG和SD指标上取得了最佳结果。在指标QAB/F和VIF中排名第2,分别仅次于MDLatLRR和DRF。

图5 不同融合方法在TNO数据集中20对红外与可见光图像的定量比较
通过表1可得出以下结论:首先,较大的NMI和QNICE证明本文方法可以很大程度上保留红外图像和可见光图像中的信息,这是本文最初的设计意图。此外,在指标AG和SD上获得最高值,表明本文方法得到的融合图像在清晰度和对比度方面有更好表现。指标QAB/F主要反映融合图像保留梯度的程度,本文方法的QAB/F指标略低于MDLatLRR。MDLatLRR通过将图像多级分解,得到多个细节图像块和基础图像块,细节图像块主要包含图像梯度细节纹理,将多个细节图像块之间通过核范数融合,可以很好地保留图像梯度细节,因此MDLatLRR具有较高的QAB/F,但因为这种操作,造成了计算时间增加。本文方法虽然设计了细节分支,但可能由于全局分支提取的全局特征弱化了部分梯度细节,导致QAB/F值低于MDLatLRR。总体而言,本文方法在客观定量分析方面取得了优异的表现。

表1 不同融合方法在TNO数据集上各指标均值
3.3 RoadScene数据集的对比实验
3.3.1 定性比较
为了证明本文方法的泛化性和有效性,在TNO数据集上训练,在RoadScene数据集进行测试,同样选取5幅具有代表性图像,结果如图6所示。
图6中,通过第1列图像中的人物和轮胎以及第2列图像中的人物可以发现,本文方法在RoadScene数据集上保留红外显著性目标的能力是优异的,保留的红外人物轮廓都是清楚且高亮的。通过后3幅图像中的树叶、树枝可以证明本文方法在保留细节纹理方面同样具有优势。

图6 各种方法在RoadScene数据集上的结果
3.3.2 定量比较
在RoadScene数据集上的定量分析结果如图7所示,各指标在RoadScene数据集上的40对图像的均值如表2所示。根据表2得知,与其他6种对比方法进行比较,本文方法在指标NMI、QNICE、AG和SD上依然取得了最好的结果,与在TNO数据集上取得的结果是一样的。在指标QAB/F上只取得了第2的成绩,落后于MDLatLRR。值得注意的是,在指标VIF上,本文方法在RoadScene数据集超越了DRF,而在TNO数据集上要略低于DRF。可能原因是DRF通过解耦表示来解耦图像中的场景表示和属性表示,而TNO数据集和RoadScene数据集中的场景差异较大,从而无法有效解耦图像中的场景表示,导致信息保真度下降,以至于VIF值低于本文方法。总结来说,通过主观的定性分析和客观的定量分析,本文方法在RoadScene数据集上同样能够取得优秀的融合效果,这足够证明本文方法的有效性和优越性。
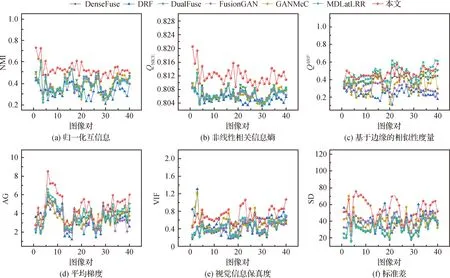
图7 不同融合方法在RoadScene数据集中40对红外与可见光图像的定量比较
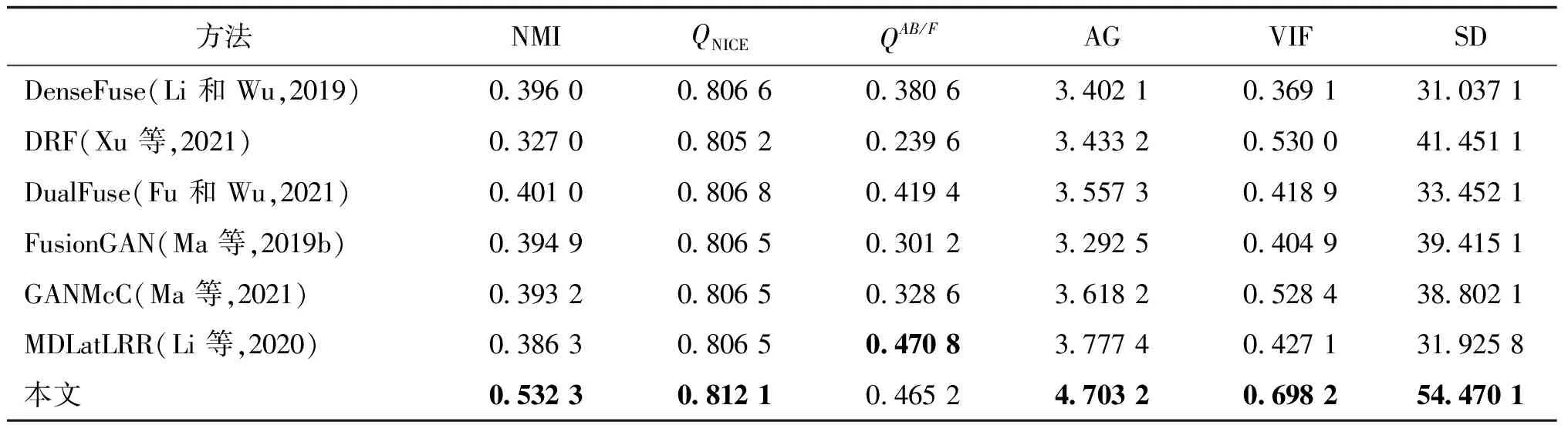
表2 不同融合方法在RoadScene数据集上各指标均值
3.4 消融实验
为了进一步表明本文方法的有效性,验证提出模块的作用,对局部—全局特征提取模块中的Transformer模块和分组渐进式模块进行消融实验,结果如表3所示,表中无Transformer表示去除局部—全局特征提取模块中的Transformer模块,仅保留局部细节分支。无分组渐进式融合模块表示直接将特征图拼接在一起。通过表3可以得出,本文方法无论去除任何一部分,融合结果都会有所下降,都无法达到最佳效果。因此进一步证实了本文提出的Transformer模块和分组渐进式融合模块的有效性。

表3 消融实验结果
3.5 运行效率对比
融合方法的运算效率是衡量其价值的重要方面,不同方法在TNO和RoadScene数据集上测试花费的平均运行时间如表4所示。由表4可以发现,6种基于深度学习的方法的运行效率都远好于传统算法MDLatLRR,这得益于GPU的加速。本文方法在运行时间上不是最优的,在TNO数据集上与最优的方法DualFuse相差约0.2 s,在RoadScene数据集与最快的方法DenseFuse相差约0.06 s。这是因为本文方法使用了自注意力机制,所以会导致计算时间加长。但本文方法在6个定量指标上都远好于这两种方法。为了提升融合图像的质量,略微牺牲运行时间是值得的。综上所述,本文方法具有良好的应用价值。

表4 不同方法在两个数据集上运行时间的平均值
4 结 论
同一场景的红外与可见光图像的融合图像可以有效弥补单一图像的不足,并且具有更丰富的信息,更符合人类视觉效果。本文根据CNN和视觉Transformer相结合的思想,提出了一种基于视觉Transformer的端到端无监督图像融合网络,并通过对比实验和消融实验证明了该网络的有效性。针对基于CNN图像融合方法的不足,本文采用引入视觉Transformer和CNN共同提取图像特征的方法,使提取的图像特征更全面、更通用。为了减少融合过程中信息的丢失,进一步提高融合质量,本文提出将特征分组,构造分层渐进式的结构将特征进行多尺度的融合。在与6种先进方法对比中,本文的融合结果无论客观定量评价还是主观定性评价都取得了更好的结果。
但是,本文的工作只限于红外与可见光图像的融合,不适用于其他图像任务。下一步的工作方向是面向更多样性的图像融合任务,以及提高模型的运算效率,节省运算时间。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
环球时报(2022-05-23)2022-05-23
数学物理学报(2022年2期)2022-04-26
金桥(2021年4期)2021-05-21
家庭影院技术(2020年10期)2020-12-14
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
小学生优秀作文(低年级)(2018年10期)2018-10-13
金桥(2018年4期)2018-09-26
Coco薇(2016年10期)2016-11-29
